There are a lot of things to consider when building a deep learning model in an multilayer perceptron. You have to consider the architecture, the activation function, the optimization algorithm, the loss function, the weight initialization strategy, the regularization strategy, and the training strategy. We will discuss more about them in the following list:
- Architecture: The first element that you need to consider when building deep learning models is the architecture of your MLP. When we say architecture, we are talking about the number of layers and the number of neurons per layer. The number of neurons in the input layer is determined by the number of features that you have in your dataset. The same thing is true for the number of output values. So, they are basically determined by your problem in a classification setting. The number of output values is usually the number of classes in your classification problem, and in a regression problem you will have only one output in your output layer. The choice that you have to make is how many hidden layers you are going to use and the number of neurons per hidden layer. There are not easy rules to set these numbers; in practice, what we do is we use a few layers at first. If a few layers don't work, maybe we add more layers, and the number of neurons for each layer is a number between the number of input values and the number of outputs, [n_inputs, n_outputs].
This is just a rule of thumb. However, there are more formal methods to choose the number of hidden layers and the number of neurons, and researchers are constantly trying to come up with better methods for choosing these values.
- Activation function: The activation function is the function that is used in every neuron in the hidden layers. There are many choices; sigmoid was the first function used when these models were developed, but then researchers found that there are many problems with using this function, so they came up with other activation functions such as the rectified Linear Unit (ReLU), the hyperbolic tangent, the leaky ReLU, and some other choices that we will use in the examples as we progress.
- Optimization algorithm: This is the algorithm that will be used to learn the weights of the networks. Each algorithm that you choose has different hyperparameters that need to be chosen by you, the modeler. The most basic algorithm to train these networks is gradient descent. However, gradient descent can be slow and also has some problems, so researchers have come up with other algorithms such as momentum optimizers, AdaGrad, RMSProp, and the Adam moment algorithm. In TensorFlow, we have a lot of algorithms that we can choose from, including the Adam moment algorithm, and this is actually the one that we are going to use in the examples.
- Loss function: This is the function that will produce the quantity that will be minimized by the optimizer. The choice of loss function depends on the problem. If we are doing a regression problem, you can choose the mean squared error or the mean pairwise squared error. For classification problems, there are more choices such as cross entropy, square loss, and hinge loss. This is similar to trial and error; sometimes, one loss function will work for your problem and sometimes it will not. So, this is why you have to consider a lot of different loss functions. However, keep in mind that the loss function will produce the quantity that will be used for the optimization algorithm to adjust the different weights for the different perceptrons that will be part of your network. Hence, this is the function that will produce the quantity, and the goal of the optimizer is to make this quantity as small as possible.
- Weight initialization strategy: The weights for each perceptron in your network must be initialized with some values, and these values will be progressively changed by the optimization algorithm to minimize the loss. There are many ways in which you can initialize these values. You can initialize with all zeros. For many years, researchers used to initialize using a random normal distribution but, in recent years, researchers have come up with better choices, including Xavier initialization and He initialization.
- Regularization strategy: This is an optional but highly recommended function because deep learning models tend to overfit data due to the quantity of parameters that they calculate. You can use many choices, including the L1 regularization, L2 regularization, and dropout regularization strategies. In this book, we are not going to use regularization in our examples, but keep in mind that, if you want to build really effective deep learning models, you will very likely need a regularization strategy.
- Training strategy: The training strategy refers to the way the data will be presented to the training algorithm. This is not part of the model itself, but it will have an influence on the results and the performance of the model. When talking about training deep learning models, you will hear the word epoch. One epoch is one pass of all training examples through the network. In these deep learning models, you will have to present the data to the network many times so the network can learn the best parameters for the model. There is another concept here: batch size. This is the number of elements presented simultaneously to the training algorithm. So in the case of deep learning models, we don't present the whole training dataset to the model. What we do is we present batches of the dataset and, in each batch, we send just a few examples, maybe 100 or 50, and this is the way we train deep learning models. Now, you can use epoch and batch size to calculate the number of iterations that you will have in your model, and this is the number of training steps, which is the number of adjustments that the optimization algorithm makes to the weight in your model. So, for example, if you have 1,000 training examples and the batch size that you will use is 100, it will take 10 iterations to complete one epoch. You can get the total number of iterations with the following formula:
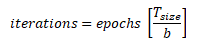
So, there are a lot of decisions that you have to make as a modeler. These are very complex models and they can be very tricky to train. So, here is some guidance to consider before you start using these models:
- Because of the number of choices that we have in these models, they can be very tricky to build. So, they shouldn't be your first choice when trying to do predictions. Always begin with simpler and more understandable models, and then, if those models don't work, move to more complex models.
- There are best practices for all of the choices that we have seen, but you need more knowledge about these elements if you want to build effective deep learning models.
- For these models to perform really well, you need a lot of data. So, you cannot use these models with very small datasets.
- Learn more about the theory of these models to understand how to use them better. So if you really want to use these models for solving real-world problems, learning more about the theory behind these models is a must.