The first technique of feature selection that we will learn about is removing dummy features with low variance. The only transformation that we have been applying so far to our features is to transform the categorical features using the encoding technique. If we take one categorical feature and use this encoding technique, we get a set of dummy features, which are to be examined to see whether they have variability or not. So, features with a very low variance are likely to have little impact on prediction. Now, why is that? Imagine that you have a dataset where you have a gender feature and that 98% of the observations correspond to just the female gender. This feature won't have any impact on prediction because almost all of the cases are just of a single category, so there is not enough variability. These cases become candidates lined up for elimination and such features should be examined more carefully. Now, take a look at the following formula:
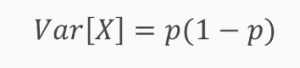
You can remove all dummy features that are either 0 or 1 in more than x% of the samples, or what you can do is to establish a minimum threshold for the variance of such features. Now, the variance of such features can be obtained with the preceding formula, where p is the number or the proportion of 1 in your dummy features. We will see how this works in a Jupyter Notebook.