Let's take an example of the diamond dataset to understand hyperparameter tuning in scikit-learn.
To perform hyperparameter tuning, we first have to import the libraries that we will use. To import the libraries, we will use the following code:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.metrics import mean_squared_error
%matplotlib inline
Then, we perform the transformations to the diamond dataset that we will use in this example. The following shows the code used to prepare data for this dataset:
# importing data
data_path= '../data/diamonds.csv'
diamonds = pd.read_csv(data_path)
diamonds = pd.concat([diamonds, pd.get_dummies(diamonds['cut'], prefix='cut', drop_first=True)],axis=1)
diamonds = pd.concat([diamonds, pd.get_dummies(diamonds['color'], prefix='color', drop_first=True)],axis=1)
diamonds = pd.concat([diamonds, pd.get_dummies(diamonds['clarity'], prefix='clarity', drop_first=True)],axis=1)
diamonds.drop(['cut','color','clarity'], axis=1, inplace=True)
After preparing the data, we will create the objects used for modeling. The following shows the code used to create the objects for modeling:
from sklearn.preprocessing import RobustScaler
from sklearn.model_selection import train_test_split
target_name = 'price'
robust_scaler = RobustScaler()
X = diamonds.drop('price', axis=1)
X = robust_scaler.fit_transform(X)
y = diamonds[target_name]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=123)
After performing and creating the objects used for modeling, we perform the train_test_split function. In the preceding codeblock, we will set 0.1(10%) of the data for testing, so this portion of the dataset will be used for model evaluation after tuning the hyperparameters.
We will tune the RandomForestRegressor model using the following parameters:
- n_estimators: This parameter represents the number of trees in the forest.
- max_features: This parameter represents the number of features to consider when looking for best split. The possible choices are n_features, which corresponds to the auto hyperparameter, or the square root of the log2 of the number of features.
- max_depth: This parameter represents the maximum depth of the tree.
Different values with a grid search will be used for these parameters. For n_estimators and max_depth, we will use four different values. For n_estimators, we will use [25,50,75,100] as values, and for max_depth, we will use [10,15,20,30] as values. For max_features, we will use the auto and square root.
Now we will instantiate the RandomForestRegressor model explicitly without any hyperparameters. The following shows the code used to instantiate it:
from sklearn.ensemble import RandomForestRegressor
RF = RandomForestRegressor(random_state=55, n_jobs=-1)
The parameter grid is basically a dictionary where we pass the name of the hyperparameter and the values that we want to try. The following code block shows the parameter grid with different parameters:
parameter_grid = {'n_estimators': [25,50,75,100],
'max_depth': [10,15,20,30],
'max_features': ['auto','sqrt']}
In total, we have four values for n_estimators, four values for max_depth, and two for max_features. So, on calculating, there are in total of 32 combinations of hyperparameters.
To perform hyperparameter tuning in scikit-learn, we will use the GridSearchCV object. The following shows the code used to import the object from scikit-learn:
from sklearn.model_selection import GridSearchCV
Here, we pass the estimator we want to tune, in this case, RandomForestRegressor. The following screenshot shows the code used and the output that we get:
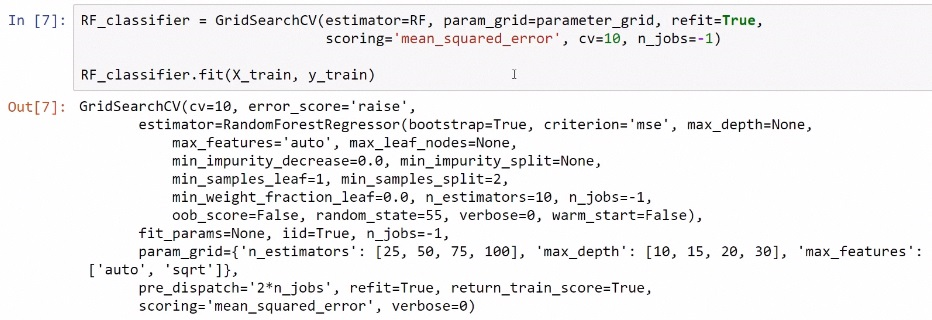
Then we pass the parameter grid that we want to try. Here, refit means that this estimator object will refit using the best parameters that it found using this process of grid-search and cross-validation. This is the evaluation metric that will be used by this object to evaluate all of the possible combinations of hyperparameters. In this case, we will use tenfold cross-validation. So after creating that, we can use the fit method and pass the training object. Since we are using tenfold cross-validation with 32 combinations, the model will evaluate 320 models.
We can get the results using the cv _results_ attribute from the object that we created using the GridSearchCV method. The following screenshot shows the code used to get the result and output showing the result:

Here, the most important thing is to get best_params_. So with best_params_, we can see the combination of parameters of all 32 combinations. The following screenshot shows the input used to get the parameters and the output showing combination of parameters that can give the best result:

Here, we can see that the combination that can give best_params_ is max_depth with a value of 20, max _features with a value of auto, and n_estimators with a value of 100. So this is the best possible combination of parameters.
We can also get the best_estimator_ object, and this is the complete list of hyperparameters. The following screenshot shows the code used to get best_estimator_ and output showing the result:

So, as we tuned the hyperparameters of the random forest model, we got different values from the values that we got before; when we had values for n_estimators as 50, max_depth as 16, and max_features as auto, the parameters in that model were untuned.