Chapter 2
Defining the Role of Data
IN THIS CHAPTER
 Seeing data as a universal resource
Seeing data as a universal resource
Obtaining and manipulating data
Looking for mistruths in data
Defining data acquisitions limits
There is nothing new about data. Every interesting application ever written for a
computer has data associated with it. Data comes in many forms — some organized, some
not. What has changed is the amount of data. Some people find it almost terrifying
that we now have access to so much data that details nearly every aspect of most people’s
lives, sometimes to a level that even the person doesn’t realize. In addition, the
use of advanced hardware and improvements in algorithms make data the universal resource
for AI today.
To work with data, you must first obtain it. Today, applications collect data manually,
as done in the past, and also automatically, using new methods. However, it’s not
a matter of just one to two data collection techniques; collection methods take place
on a continuum from fully manual to fully automatic.
Raw data doesn’t usually work well for analysis purposes. This chapter also helps
you understand the need for manipulating and shaping the data so that it meets specific
requirements. You also discover the need to define the truth value of the data to
ensure that analysis outcomes match the goals set for applications in the first place.
Interestingly, you also have data acquisition limits to deal with. No technology currently
exists for grabbing thoughts from someone’s mind through telepathic means. Of course,
other limits exist, too — most of which you probably already know about but may not
have considered.
Finding Data Ubiquitous in This Age
More than a buzzword used by vendors to propose new ways to store data and analyze
it, the big data revolution is an everyday reality and a driving force of our times.
You may have heard big data mentioned in many specialized scientific and business
publications and even wondered what the term really means. From a technical perspective,
big data refers to large and complex amounts of computer data, so large and intricate that
applications can’t deal with the data by using additional storage or increasing computer
power.
Big data implies a revolution in data storage and manipulation. It affects what you
can achieve with data in more qualitative terms (in addition to doing more, you can
perform tasks better). Computers store big data in different formats from a human
perspective, but the computer sees data as a stream of ones and zeros (the core language
of computers). You can view data as being one of two types, depending on how you produce
and consume it. Some data has a clear structure (you know exactly what it contains
and where to find every piece of data), whereas other data is unstructured (you have
an idea of what it contains, but you don’t know exactly how it is arranged).
Typical examples of structured data are database tables, in which information is arranged
into columns and each column contains a specific type of information. Data is often
structured by design. You gather it selectively and record it in its correct place.
For example, you might want to place a count of the number of people buying a certain
product in a specific column, in a specific table, in a specific database. As with
a library, if you know what data you need, you can find it immediately.
Unstructured data consists of images, videos, and sound recordings. You may use an
unstructured form for text so that you can tag it with characteristics, such as size,
date, or content type. Usually you don’t know exactly where data appears in an unstructured
dataset because the data appears as sequences of ones and zeros that an application
must interpret or visualize.
 Transforming unstructured data into a structured form can cost lots of time and effort
and can involve the work of many people. Most of the data of the big data revolution
is unstructured and stored as it is, unless someone renders it structured.
Transforming unstructured data into a structured form can cost lots of time and effort
and can involve the work of many people. Most of the data of the big data revolution
is unstructured and stored as it is, unless someone renders it structured.
This copious and sophisticated data store didn’t appear suddenly overnight. It took
time to develop the technology to store this amount of data. In addition, it took
time to spread the technology that generates and delivers data, namely computers,
sensors, smart mobile phones, the Internet, and its World Wide Web services. The following
sections help you understand what makes data a universal resource today.
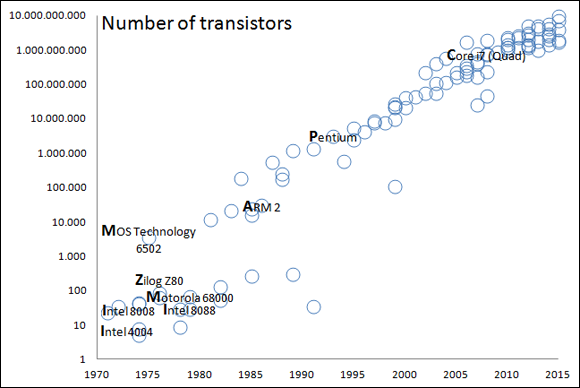
Understanding Moore’s implications
In 1965, Gordon Moore, cofounder of Intel and Fairchild Semiconductor, wrote in an
article entitled “Cramming More Components Onto Integrated Circuits” (http://ieeexplore.ieee.org/document/4785860/) that the number of components found in integrated circuits would double every year
for the next decade. At that time, transistors dominated electronics. Being able to
stuff more transistors into an Integrated Circuit (IC) meant being able to make electronic
devices more capable and useful. This process is called integration and implies a
strong process of electronics miniaturization (making the same circuit much smaller).
Today’s computers aren’t all that much smaller than computers of a decade ago, yet
they are decisively more powerful. The same goes for mobile phones. Even though they’re
the same size as their predecessors, they have become able to perform more tasks.
What Moore stated in that article has actually been true for many years. The semiconductor
industry calls it Moore’s Law (see http://www.mooreslaw.org/ for details). Doubling did occur for the first ten years, as predicted. In 1975,
Moore corrected his statement, forecasting a doubling every two years. Figure 2-1 shows the effects of this doubling. This rate of doubling is still valid, although
now it’s common opinion that it won’t hold longer than the end of the present decade
(up to about 2020). Starting in 2012, a mismatch began to occur between expected speed
increases and what semiconductor companies can achieve with regard to miniaturization.
Physical barriers exist to integrating more circuits on an IC using the present silica
components because you can make things only so small. However, innovation continues,
as described at http://www.nature.com/news/the-chips-are-down-for-moores-law-1.19338. In the future, Moore’s Law may not apply because industry will switch to a new technology
(such as making components by using optical lasers instead of transistors; see the
article at http://www.extremetech.com/extreme/187746-by-2020-you-could-have-an-exascale-speed-of-light-optical-computeron-your-desk for details about optical computing). What matters is that since 1965, the doubling
of components every two years has ushered in great advancements in digital electronics
that has had far-reaching consequences in the acquisition, storage, manipulation,
and management of data.
Moore’s Law has a direct effect on data. It begins with smarter devices. The smarter
the devices, the more diffusion (as evidenced by electronics being everywhere today).
The greater the diffusion, the lower the price becomes, creating an endless loop that
drives the use of powerful computing machines and small sensors everywhere. With large
amounts of computer memory available and larger storage disks for data, the consequences
are an expansion of data availability, such as websites, transaction records, measurements,
digital images, and other sorts of data.
Using data everywhere
Scientists need more powerful computers than the average person because of their scientific
experiments. They began dealing with impressive amounts of data years before anyone
coined the term big data. At this point, the Internet didn’t produce the vast sums
of data that it does today. Remember that big data isn’t a fad created by software
and hardware vendors but has a basis in many scientific fields, such as astronomy
(space missions), satellite (surveillance and monitoring), meteorology, physics (particle
accelerators) and genomics (DNA sequences).
Although AI applications can specialize in a scientific field, such as IBM’s Watson,
which boasts an impressive medical diagnosis capability because it can learn information
from millions of scientific papers on diseases and medicine, the actual AI application
driver often has more mundane facets. Actual AI applications are mostly prized for
being able to recognize objects, move along paths, or understand what people say and
to them. Data contribution to the actual AI renaissance that molded it in such a fashion
didn’t arrive from the classical sources of scientific data.
The Internet now generates and distributes new data in large amounts. Our current
daily data production is estimated to amount to about 2.5 quintillion (a number with
18 zeros) bytes, with the lion’s share going to unstructured data like videos and
audios. All this data is related to common human activities, feelings, experiences,
and relations. Roaming through this data, an AI can easily learn how reasoning and acting more human-like works. Here are some examples of the more interesting
data you can find:
- Large repositories of faces and expressions from photos and videos posted on social
media websites like Facebook, YouTube, and Google provide information about gender,
age, feelings, and possibly sexual preferences, political orientations, or IQ (see
https://www.theguardian.com/technology/2017/sep/12/artificial-intelligence-face-recognition-michal-kosinski).
- Privately held medical information and biometric data from smart watches, which measure
body data such as temperature and heart rate during both illness and good health.
- Datasets of how people relate to each other and what drives their interest from sources
such as social media and search engines. For instance, a study from Cambridge University’s
Psychometrics Centre claims that Facebook interactions contain a lot of data about
intimate relationships (see
https://www.theguardian.com/technology/2015/jan/13/your-computer-knows-you-researchers-cambridge-stanford-university).
- Information on how we speak is recorded by mobile phones. For instance, OK Google,
a function found on Android mobile phones, routinely records questions and sometimes
even more:
https://qz.com/526545/googles-been-quietly-recording-your-voice-heres-how-to-listen-to-and-delete-the-archive/.
Every day, users connect even more devices to the Internet that start storing new
personal data. There are now personal assistants that sit in houses, such as Amazon
Echo and other integrated smart home devices that offer ways to regulate and facilitate
the domestic environment. These are just the tip of the iceberg because many other
common tools of everyday life are becoming interconnected (from the refrigerator to
the toothbrush) and able to process, record, and transmit data. The Internet of Things
(IoT) is becoming a reality. Experts estimate that by 2020, six times as many connected
things will exist as there will be people, but research teams and think tanks are
already revisiting those figures (http://www.gartner.com/newsroom/id/3165317).
Putting algorithms into action
The human race is now at an incredible intersection of unprecedented volumes of data,
generated by increasingly smaller and powerful hardware. The data is also increasingly
processed and analyzed by the same computers that the process helped spread and develop.
This statement may seem obvious, but data has become so ubiquitous that its value
no longer resides only in the information it contains (such as the case of data stored
in a firm’s database that allows its daily operations), but rather in its use as a means to create new values; such data is described as the “new
oil.” These new values mostly exist in how applications manicure, store, and retrieve
data, and in how you actually use it by means of smart algorithms.
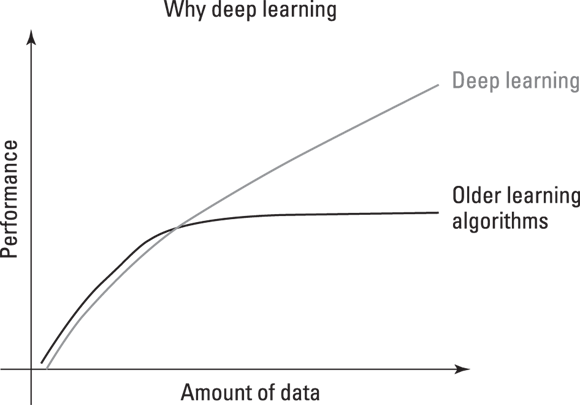
Algorithms and AI changed the data game. As mentioned in the previous chapter, AI
algorithms have tried different approaches along the way, passing from simple algorithms
to symbolic reasoning based on logic and then to expert systems. In recent years,
they became neural networks and, in their most mature form, deep learning. As this
methodological passage happened, data turned from being the information processed
by predetermined algorithms to becoming what molded the algorithm into something useful
for the task. Data turned from being just the raw material that fueled the solution
to the artisan of the solution itself, as shown in Figure 2-2.
Thus, a photo of some of your kittens has become increasingly useful not simply just
because of its affective value — depicting your cute little cats — but because it
could become part of the learning process of an AI discovering more general concepts,
such as what characteristics denote a cat, or understanding what defines cute.
On a larger scale, a company like Google feeds its algorithms from freely available
data, such as the content of websites or the text found in publicly available texts
and books. Google spider software crawls the web, jumping from website to website,
retrieving web pages with their content of text and images. Even if Google gives back
part of the data to users as search results, it extracts other kinds of information
from the data using its AI algorithms, which learn from it how to achieve other objectives.
Algorithms that process words can help Google AI systems understand and anticipate
your needs even when you are not expressing them in a set of keywords but in plain,
unclear natural language, the language we speak every day (and yes, everyday language is often unclear). If you currently try to pose questions, not just
chains of keywords, to the Google search engine, you’ll notice that it tends to answer
correctly. Since 2012, with the introduction of the Hummingbird update (http://searchengineland.com/google-hummingbird-172816), Google became better able to understand synonyms and concepts, something that goes
beyond the initial data that it acquired, and this is the result of an AI process.
An even more advanced algorithm exists in Google, named RankBrain, which learns directly
from millions of queries every day and can answer ambiguous or unclear search queries,
even expressed in slang or colloquial terms or simply ridden with errors. RankBrain
doesn’t service all the queries, but it learns from data how to better answer queries.
It already handles 15 percent of the engine’s queries, and in the future, this percentage
could become 100 percent.
Using Data Successfully
Having plentiful data available isn’t enough to create a successful AI. Presently,
an AI algorithm can’t extract information directly from raw data. Most algorithms
rely on external collection and manipulation prior to analysis. When an algorithm
collects useful information, it may not represent the right information. The following
sections help you understand how to collect, manipulate, and automate data collection
from an overview perspective.
Considering the data sources
The data you use comes from a number of sources. The most common data source is from
information entered by humans at some point. Even when a system collects shopping-site
data automatically, humans initially enter the information. A human clicks various
items, adds them to a shopping cart, specifies characteristics (such as size) and
quantity, and then checks out. Later, after the sale, the human gives the shopping
experience, product, and delivery method a rating and makes comments. In short, every
shopping experience becomes a data collection exercise as well.
Many data sources today rely on input gathered from human sources. Humans also provide
manual input. You call or go into an office somewhere to make an appointment with
a professional. A receptionist then gathers information from you that’s needed for
the appointment. This manually collected data eventually ends up in a dataset somewhere
for analysis purposes.
Data is also collected from sensors, and these sensors can take almost any form. For
example, many organizations base physical data collection, such as the number of people
viewing an object in a window, on cellphone detection. Facial recognition software
could potentially detect repeat customers.
However, sensors can create datasets from almost anything. The weather service relies
on datasets created by sensors that monitor environmental conditions such as rain,
temperature, humidity, cloud cover, and so on. Robotic monitoring systems help correct
small flaws in robotic operation by constantly analyzing data collected by monitoring
sensors. A sensor, combined with a small AI application, could tell you when your
dinner is cooked to perfection tonight. The sensor collects data, but the AI application
uses rules to help define when the food is properly cooked.
Obtaining reliable data
The word reliable seems so easy to define, yet so hard to implement. Something is reliable when the
results it produces are both expected and consistent. A reliable data source produces
mundane data that contains no surprises; no one is shocked in the least by the outcome.
Depending on your perspective, it could actually be a good thing that most people
aren’t yawning and then falling asleep when reviewing data. The surprises make the
data worth analyzing and reviewing. Consequently, data has an aspect of duality. We
want reliable, mundane, fully anticipated data that simply confirms what we already
know, but the unexpected is what makes collecting the data useful in the first place.
Still, you don’t want data that is so far out of the ordinary that it becomes almost
frightening to review. Balance needs to be maintained when obtaining data. The data
must fit within certain limits (as described in the “Manicuring the Data” section, later in this chapter). It must also meet specific criteria as to truth
value (as described in the “Considering the Five Mistruths in Data” section, later in this chapter). The data must also come at expected intervals,
and all the fields of the incoming data record must be complete.
To some extent, data security also affects data reliability. Data consistency comes
in several forms. When the data arrives, you can ensure that it falls within expected
ranges and appears in a particular form. However, after you store the data, the reliability
can decrease unless you ensure that the data remains in the expected form. An entity
fiddling with the data affects reliability, making the data suspect and potentially
unusable for analysis later. Ensuring data reliability means that after the data arrives,
no one tampers with it to make it fit within an expected domain (making it mundane
as a result).
Making human input more reliable
Humans make mistakes — it’s part of being human. In fact, expecting that humans won’t
make mistakes is unreasonable. Yet, many application designs assume that humans somehow won’t make mistakes of any sort. The design expects that
everyone will simply follow the rules. Unfortunately, the vast majority of users are
guaranteed to not even read the rules because most humans are also lazy or too pressed
for time when it comes to doing things that don’t really help them directly.
Consider the entry of a state into a form. If you provide just a text field, some
users might input the entire state name, such as Kansas. Of course, some users will
make a typo or capitalization error and come up with Kansus or kANSAS. Setting these
errors, people and organizations have various approaches to performing tasks. Someone
in the publishing industry might use the Associated Press (AP) style guide and input
Kan. Someone who is older and used to the Government Printing Office (GPO) guidelines
might input Kans. instead. Other abbreviations are used as well. The U.S. Post Office
(USPS) uses KS, but the U.S. Coast Guard uses KA. Meanwhile, the International Standards
Organization (ISO) form goes with US-KS. Mind you, this is just a state entry, which
is reasonably straightforward — or so you thought before reading this section. Clearly,
because the state isn’t going to change names anytime soon, you could simply provide
a drop-down list box on the form for choosing the state in the required format, thereby
eliminating differences in abbreviation use, typos, and capitalization errors in one
fell swoop.
Drop-down list boxes work well for an amazing array of data inputs, and using them
ensures that human input into those fields becomes extremely reliable because the
human has no choice but to use one of the default entries. Of course, the human can
always choose the incorrect entry, which is where double-checks come into play. Some
newer applications compare the ZIP code to the city and state entries to see whether
they match. When they don’t match, the user is asked again to provide the correct
input. This double-check verges on being annoying (see the “More annoying than useful
input aids” sidebar for details), but the user is unlikely to see it very often, so
it shouldn’t become too annoying.
Even with cross-checks and static entries, humans still have plenty of room for making
mistakes. For example, entering numbers can be problematic. When a user needs to enter
2.00, you might see 2, or 2.0, or 2., or any of a variety of other entries. Fortunately,
parsing the entry and reformatting it will fix the problem, and you can perform this
task automatically, without the user’s aid.
Unfortunately, reformatting won’t correct an errant numeric input. You can partially
mitigate such errors by including range checks. A customer can’t buy –5 bars of soap.
The legitimate way to show the customer returning the bars of soap is to process a
return, not a sale. However, the user might have simply made an error, and you can
provide a message stating the proper input range for the value.
Using automated data collection
Some people think that automated data collection solves all the human input issues
associated with datasets. In fact, automated data collection does provide a number
of benefits:
- Better consistency
- Improved reliability
- Lower probability of missing data
- Enhanced accuracy
- Reduced variance for things like timed inputs
Unfortunately, to say that automated data collection solves every issue is simply
incorrect. Automated data collection still relies on sensors, applications, and computer
hardware designed by humans that provide access only to the data that humans decide
to allow. Because of the limits that humans place on the characteristics of automated
data collection, the outcome often provides less helpful information than hoped for
by the designers. Consequently, automated data collection is in a constant state of
flux as designers try to solve the input issues.
Automated data collection also suffers from both software and hardware errors present
in any computing system, but with a higher potential for soft issues (which arise when the system is apparently working but isn’t providing the desired
result) than other kinds of computer-based setups. When the system works, the reliability
of the input far exceeds human abilities. However, when soft issues occur, the system
often fails to recognize that a problem exists, as a human might, and therefore the
dataset could end up containing more mediocre or even bad data.
Manicuring the Data
Some people use the term manipulation when speaking about data, giving the impression that the data is somehow changed
in an unscrupulous or devious manner. Perhaps a better term would be manicuring, which makes the data well shaped and lovely. No matter what term you use, however,
raw data seldom meets the requirements for processing and analysis. To get something
out of the data, you must manicure it to meet specific needs. The following sections
discuss data manicuring needs.
Dealing with missing data
To answer a given question correctly, you must have all the facts. You can guess the
answer to a question without all the facts, but then the answer is just as likely
to be wrong as correct. Often, someone who makes a decision, essentially answering
a question, without all the facts is said to jump to a conclusion. When analyzing
data, you have probably jumped to more conclusions than you think because of missing
data. A data record, one entry in a dataset (which is all the data), consists of fields that contain facts used to answer a question. Each field contains a single kind of
data that addresses a single fact. If that field is empty, you don’t have the data
you need to answer the question using that particular data record.
As part of the process of dealing with missing data, you must know that the data
is missing. Identifying that your dataset is missing information can actually be quite
hard because it requires you to look at the data at a low level — something that most
people aren’t prepared to do and is time consuming even if you do have the required
skills. Often, your first clue that data is missing is the preposterous answers that
your questions get from the algorithm and associated dataset. When the algorithm is
the right one to use, the dataset must be at fault.
A problem can occur when the data collection process doesn’t include all the data
needed to answer a particular question. Sometimes you’re better off to actually drop
a fact rather than use a considerably damaged fact. If you find that a particular
field in a dataset is missing 90 percent or more of its data, the field becomes useless,
and you need to drop it from the dataset (or find some way to obtain all that data).
Less damaged fields can have data missing in one of two ways. Randomly missing data
is often the result of human or sensor error. It occurs when data records throughout
the dataset have missing entries. Sometimes a simple glitch will cause the damage.
Sequentially missing data occurs during some type of generalized failure. An entire
segment of the data records in the dataset lack the required information, which means
that the resulting analysis can become quite skewed.
Fixing randomly missing data is easiest. You can use a simple median or average value
as a replacement. No, the dataset isn’t completely accurate, but it will likely work
well enough to obtain a reasonable answer. In some cases, data scientists used a special
algorithm to compute the missing value, which can make the dataset more accurate at
the expense of computational time.
Sequentially missing data is significantly harder, if not impossible, to fix because
you lack any surrounding data on which to base any sort of guess. If you can find
the cause of the missing data, you can sometimes reconstruct it. However, when reconstruction
becomes impossible, you can choose to ignore the field. Unfortunately, some answers
will require that field, which means that you might need to ignore that particular
sequence of data records — potentially causing incorrect output.
Considering data misalignments
Data might exist for each of the data records in a dataset, but it might not align
with other data in other datasets you own. For example, the numeric data in a field
in one dataset might be a floating-point type (with decimal point), but an integer
type in another dataset. Before you can combine the two datasets, the fields must
contain the same type of data.
All sorts of other kinds of misalignment can occur. For example, date fields are notorious
for being formatted in various ways. To compare dates, the data formats must be the
same. However, dates are also insidious in their propensity for looking the same,
but not being the same. For example, dates in one dataset might use Greenwich Mean
Time (GMT) as a basis, while the dates in another dataset might use some other time
zone. Before you can compare the times, you must align them to the same time zone.
It can become even weirder when dates in one dataset come from a location that uses
Daylight Saving Time (DST), but dates from another location don’t.
Even when the data types and format are the same, other data misalignments can occur.
For example, the fields in one dataset may not match the fields in the other dataset.
In some cases, these differences are easy to correct. One dataset may treat first
and last name as a single field, while another dataset might use separate fields for
first and last name. The answer is to change all datasets to use a single field or
to change them all to use separate fields for first and last name. Unfortunately,
many misalignments in data content are harder to figure out. In fact, it’s entirely
possible that you might not be able to figure them out at all. However, before you
give up, consider these potential solutions to the problem:
- Calculate the missing data from other data that you can access.
- Locate the missing data in another dataset.
- Combine datasets to create a whole that provides consistent fields.
- Collect additional data from various sources to fill in the missing data.
- Redefine your question so that you no longer need the missing data.
Separating useful data from other data
Some organizations are of the opinion that they can never have too much data, but
an excess of data becomes as much a problem as not enough. To solve problems efficiently,
an AI requires just enough data. Defining the question that you want to answer concisely
and clearly helps, as does using the correct algorithm (or algorithm ensemble). Of
course, the major problems with having too much data are that finding the solution (after wading through all that extra data) takes longer, and
sometimes you get confusing results because you can’t see the forest for the trees.
 As part of creating the dataset you need for analysis, you make a copy of the original
data rather than modify it. Always keep the original, raw data pure so that you can
use it for other analysis later. In addition, creating the right data output for analysis
can require a number of tries because you may find that the output doesn’t meet your
needs. The point is to create a dataset that contains only the data needed for analysis,
but keeping in mind that the data may need specific kinds of pruning to ensure the
desired output.
As part of creating the dataset you need for analysis, you make a copy of the original
data rather than modify it. Always keep the original, raw data pure so that you can
use it for other analysis later. In addition, creating the right data output for analysis
can require a number of tries because you may find that the output doesn’t meet your
needs. The point is to create a dataset that contains only the data needed for analysis,
but keeping in mind that the data may need specific kinds of pruning to ensure the
desired output.
Considering the Five Mistruths in Data
Humans are used to seeing data for what it is in many cases: an opinion. In fact,
in some cases, people skew data to the point where it becomes useless, a mistruth. A computer can’t tell the difference between truthful and untruthful data — all it
sees is data. One of the issues that make it hard, if not impossible, to create an
AI that actually thinks like a human is that humans can work with mistruths and computers
can’t. The best you can hope to achieve is to see the errant data as outliers and
then filter it out, but that technique doesn’t necessarily solve the problem because
a human would still use the data and attempt to determine a truth based on the mistruths
that are there.
A common thought about creating less contaminated datasets is that instead of allowing
humans to enter the data, collecting the data through sensors or other means should
be possible. Unfortunately, sensors and other mechanical input methodologies reflect
the goals of their human inventors and the limits of what the particular technology
is able to detect. Consequently, even machine-derived or sensor-derived data is also
subject to generating mistruths that are quite difficult for an AI to detect and overcome.
The following sections use a car accident as the main example to illustrate five types
of mistruths that can appear in data. The concepts that the accident is trying to
portray may not always appear in data and they may appear in different ways than discussed.
The fact remains that you normally need to deal with these sorts of things when viewing
data.
Commission
Mistruths of commission are those that reflect an outright attempt to substitute truthful
information for untruthful information. For example, when filling out an accident
report, someone could state that the sun momentarily blinded them, making it impossible to see someone they hit. In reality, perhaps the person was distracted
by something else or wasn’t actually thinking about driving (possibly considering
a nice dinner). If no one can disprove this theory, the person might get by with a
lesser charge. However, the point is that the data would also be contaminated. The
effect is that now an insurance company would base premiums on errant data.
Although it would seem as if mistruths of commission are completely avoidable, often
they aren’t. Human tell “little white lies” to save others embarrassment or to deal
with an issue with the least amount of personal effort. Sometimes a mistruth of commission
is based on errant input or hearsay. In fact, the sources for errors of commission
are so many that it really is hard to come up with a scenario where someone could
avoid them entirely. All this said, mistruths of commission are one type of mistruth
that someone can avoid more often than not.
Omission
Mistruths of omission are those where a person tells the truth in every stated fact,
but leaves out an important fact that would change the perception of an incident as
a whole. Thinking again about the accident report, say that someone strikes a deer,
causing significant damage to their car. He truthfully says that the road was wet;
it was near twilight so the light wasn’t as good as it could be; he was a little late
in pressing on the brake; and the deer simply ran out from a thicket at the side of
the road. The conclusion would be that the incident is simply an accident.
However, the person has left out an important fact. He was texting at the time. If
law enforcement knew about the texting, it would change the reason for the accident
to inattentive driving. The driver might be fined and the insurance adjuster would
use a different reason when entering the incident into the database. As with the mistruth
of commission, the resulting errant data would change how the insurance company adjusts
premiums.
Avoiding mistruths of omission is nearly impossible. Yes, someone could purposely
leave facts out of a report, but it’s just as likely that someone will simply forget
to include all the facts. After all, most people are quite rattled after an accident,
so it’s easy to lose focus and report only those truths that left the most significant
impression. Even if a person later remembers additional details and reports them,
the database is unlikely to ever contain a full set of truths.
Perspective
Mistruths of perspective occur when multiple parties view an incident from multiple
vantage points. For example, in considering an accident involving a struck pedestrian,
the person driving the car, the person getting hit by the car, and a bystander who
witnessed the event would all have different perspectives. An officer taking reports from each person would understandably get different facts
from each one, even assuming that each person tells the truth as each knows it. In
fact, experience shows that this is almost always the case and what the officer submits
as a report is the middle ground of what each of those involved state, augmented by
personal experience. In other words, the report will be close to the truth, but not
close enough for an AI.
When dealing with perspective, it’s important to consider vantage point. The driver
of the car can see the dashboard and knows the car’s condition at the time of the
accident. This is information that the other two parties lack. Likewise, the person
getting hit by the car has the best vantage point for seeing the driver’s facial expression
(intent). The bystander might be in the best position to see whether the driver made
an attempt to stop, and assess issues such as whether the driver tried to swerve.
Each party will have to make a report based on seen data without the benefit of hidden
data.
Perspective is perhaps the most dangerous of the mistruths because anyone who tries
to derive the truth in this scenario will, at best, end up with an average of the
various stories, which will never be fully correct. A human viewing the information
can rely on intuition and instinct to potentially obtain a better approximation of
the truth, but an AI will always use just the average, which means that the AI is
always at a significant disadvantage. Unfortunately, avoiding mistruths of perspective
is impossible because no matter how many witnesses you have to the event, the best
you can hope to achieve is an approximation of the truth, not the actual truth.
There is also another sort of mistruth to consider, and it’s one of perspective. Think
about this scenario: You’re a deaf person in 1927. Each week, you go to the theater
to view a silent film, and for an hour or more, you feel like everyone else. You can
experience the movie the same way everyone else does; there are no differences. In
October of that year, you see a sign saying that the theater is upgrading to support
a sound system so that it can display talkies — films with a sound track. The sign says that it’s the best thing ever, and almost
everyone seems to agree, except for you, the deaf person, who is now made to feel
like a second-class citizen, different from everyone else and even pretty much excluded
from the theater. In the deaf person’s eyes, that sign is a mistruth; adding a sound
system is the worst possible thing, not the best possible thing. The point is that
what seems to be generally true isn’t actually true for everyone. The idea of a general
truth — one that is true for everyone — is a myth. It doesn’t exist.
Bias
Mistruths of bias occur when someone is able to see the truth, but due to personal
concerns or beliefs is unable to actually see it. For example, when thinking about
an accident, a driver might focus attention so completely on the middle of the road
that the deer at the edge of the road becomes invisible. Consequently, the driver
has no time to react when the deer suddenly decides to bolt out into the middle of
the road in an effort to cross.
A problem with bias is that it can be incredibly hard to categorize. For example,
a driver who fails to see the deer can have a genuine accident, meaning that the deer
was hidden from view by shrubbery. However, the driver might also be guilty of inattentive
driving because of incorrect focus. The driver might also experience a momentary distraction.
In short, the fact that the driver didn’t see the deer isn’t the question; instead,
it’s a matter of why the driver didn’t see the deer. In many cases, confirming the
source of bias becomes important when creating an algorithm designed to avoid a bias
source.
Theoretically, avoiding mistruths of bias is always possible. In reality, however,
all humans have biases of various types and those biases will always result in mistruths
that skew datasets. Just getting someone to actually look and then see something —
to have it register in the person’s brain — is a difficult task. Humans rely on filters
to avoid information overload, and these filters are also a source of bias because
they prevent people from actually seeing things.
Frame of reference
Of the five mistruths, frame of reference need not actually be the result of any sort
of error, but one of understanding. A frame-of-reference mistruth occurs when one
party describes something, such as an event like an accident, and because a second
party lacks experience with the event, the details become muddled or completely misunderstood.
Comedy routines abound that rely on frame-of-reference errors. One famous example
is from Abbott and Costello, Who’s On First?, as shown at https://www.youtube.com/watch?v=kTcRRaXV-fg. Getting one person to understand what a second person is saying can be impossible
when the first person lacks experiential knowledge — the frame of reference.
Another frame-of-reference mistruth example occurs when one party can’t possibly understand
the other. For example, a sailor experiences a storm at sea. Perhaps it’s a monsoon,
but assume for a moment that the storm is substantial — perhaps life threatening.
Even with the use of videos, interviews, and a simulator, the experience of being
at sea in a life-threatening storm would be impossible to convey to someone who hasn’t
experienced such a storm first hand; that person has no frame of reference.
The best way to avoid frame-of-reference mistruths is to ensure that all parties
involved can develop similar frames of reference. To accomplish this task, the various
parties require similar experiential knowledge to ensure the accurate transfer of
data from one person to another. However, when working with a dataset, which is necessarily
recorded, static data, frame-of-reference errors will still occur when the prospective
viewer lacks the required experiential knowledge.
An AI will always experience frame-of-reference issues because an AI necessarily lacks
the ability to create an experience. A databank of acquired knowledge isn’t quite
the same thing. The databank would contain facts, but experience is based on not only
facts but also conclusions that current technology is unable to duplicate.
Defining the Limits of Data Acquisition
It may seem as if everyone is acquiring your data without thought or reason, and you’re
right; they are. In fact, organizations collect, categorize, and store everyone’s
data — seemingly without goal or intent. According to Data Never Sleeps (https://www.domo.com/blog/data-never-sleeps-5/), the world is collecting data at the rate of 2.5 quintillion bytes per day. This
daily data comes in all sorts of forms, as these examples attest:
- Google conducts 3,607,080 searches.
- Twitter users send 456,000 tweets.
- YouTube users watch 4,146,600 videos.
- Inboxes receive 103,447,529 spam emails.
- The Weather Channel receives 18,055,555.56 weather requests.
- GIPHY serves 694,444 GIFs.
Data acquisition has become a narcotic for organizations worldwide, and some think
that the organization that collects the most somehow wins a prize. However, data acquisition,
in and of itself, accomplishes nothing. The book The Hitchhiker’s Guide to the Galaxy, by Douglas Adams (https://www.amazon.com/exec/obidos/ASIN/1400052920/datacservip0f-20/), illustrates this problem clearly. In this book, a race of supercreatures builds
an immense computer to calculate the meaning of “life, the universe, and everything.”
The answer of 42 doesn’t really solve anything, so some of the creatures complain
that the collection, categorization, and analysis of all the data used for the answer
hasn’t produced a usable result. The computer, a sentient one, no less, tells the
people receiving the answer that the answer is indeed correct, but they need to know
the question in order for the answer to make sense. Data acquisition can occur in
unlimited amounts, but figuring out the right questions to ask can be daunting, if
not impossible.
The main problem that any organization needs to address with regard to data acquisition
is which questions to ask and why the questions are important. Tailoring data acquisition
to answer the questions you need answered matters. For example, if you’re running
a shop in town, you might need questions like this answered:
- How many people walk in front of the store each day?
- How many of those people stop to look in the window?
- How long do they look?
- What time of day are they looking?
- Do certain displays tend to produce better results?
- Which of these displays actually cause people to come into the store and shop?
The list could go on, but the idea is that creating a list of questions that address
specific business needs is essential. After you create a list, you must verify that
each of the questions is actually important — that is, addresses a need — and then
ascertain what sorts of information you need to answer the question.
Of course, trying to collect all this data by hand would be impossible, which is
where automation comes into play. Seemingly, automation would produce reliable, repeatable,
and consistent data input. However, many factors in automating data acquisition can
produce data that isn’t particularly useful. For example, consider these issues:
- Sensors can collect only the data that they’re designed to collect, so you might miss
data when the sensors used aren’t designed for the purpose.
- People create errant data in various ways (see the “Considering the Five Mistruths in Data” section of the chapter for details), which means that data you receive might be
false.
- Data can become skewed when the conditions for collecting it are incorrectly defined.
- Interpreting data incorrectly means that the results will also be incorrect.
- Converting a real-world question into an algorithm that the computer can understand
is an error-prone process.
Many other issues need to be considered (enough to fill a book). When you combine
poorly collected, ill-formed data with algorithms that don’t actually answer your
questions, you get output that may actually lead your business in the wrong direction,
which is why AI is often blamed for inconsistent or unreliable results. Asking the
right question, obtaining the correct data, performing the right processing, and then
correctly analyzing the data are all required to make data acquisition the kind of
tool you can rely on.