
Figure 1 — Concordance unilingue en format KWIC produite par TextStat
Le monde moderne apparaît comme une immense machine à traduire.
EDMOND CARY
AU SENS LARGE, on entend par «traductique» tout ce qui concerne la conception, l’exploitation, l’évaluation et l’optimisation des logiciels destinés à faciliter le travail du traducteur. Ces logiciels trouvent aussi des applications chez d’autres langagiers, notamment les lexicographes, les rédacteurs et les terminologues. Ils s’ajoutent au poste de travail du traducteur et complètent les outils de bureautique, tels que les logiciels de traitement de texte, les correcteurs orthographiques et grammaticaux (ou correcticiels), les tableurs, les dictionnaires électroniques et les banques de données terminologiques (v. l’OS 14).
Il est utile, aux fins de description, de diviser la traductique en deux grands sous-domaines: la traduction automatique (TA) et la traduction assistée par ordinateur (TAO). En TA, un logiciel prend en charge le processus de traduction du début à la fin; c’est la machine qui traduit (bien que l’humain ait sa place dans le processus, comme nous le verrons). En TAO, la traduction est réalisée par l’humain avec l’aide de la machine. C’est l’humain qui traduit et il est aidé dans son travail par des logiciels qui portent bien leur nom: «outils d’aide à la traduction». Voyons maintenant brièvement les principaux enjeux de la TA.
Lorsque des chercheurs ont commencé à explorer le traitement informatique des langues à partir des années 1930, mais surtout des années 1950, ils ont tenté de concevoir une machine à traduire. Ils ont cru, un peu naïvement, qu’une langue était un simple code et que la traduction consistait à passer d’un code à l’autre. Or, il n’en est rien, d’une part, parce qu’une langue est bien plus qu’un code et, d’autre part, parce que traduire est une opération mentale fort complexe.
L’histoire de la TA a évolué en dents de scie. Après avoir connu des périodes d’optimisme suivies de grandes déceptions, la TA se cantonne de nos jours dans des applications particulières et peut difficilement se passer entièrement du jugement de l’humain, qui compense les insuffisances de la machine.
Il existe deux principales approches en TA: par règles (la machine, alimentée au préalable de dictionnaires, applique au texte un ensemble de règles d’analyse et de transfert prédéfinies), et statistique (la machine explore de vastes corpus à la recherche de correspondances). L’utilisateur, lui, y voit peu de différences dans la marche à suivre: dans les deux cas, il soumet un texte à traduire au logiciel qui lui livre automatiquement une ébauche de traduction dans la langue d’arrivée.
Les logiciels gratuits de TA en ligne sont certainement les plus connus et les plus facilement accessibles aux usagers d’Internet. Cependant, il existe aussi des programmes commerciaux, dont certains, très spécialisés, sont conçus pour la traduction de textes dans des domaines bien précis (l’exemple par excellence étant les bulletins de météo canadiens), ce qui permet de contourner bon nombre des lacunes et faiblesses inhérentes à la TA.
Exemples de logiciels de traduction automatique gratuits en ligne
Babel Fish Yahoo!
http://cf.babelfish.yahoo.com/
Google traduction
http://translate.google.ca/?hl=fr&tab=wT
Reverso
http://www.reverso.net/text_translation.aspx?lang=FR
Systran
Avant d’opter pour la TA, l’utilisateur doit se poser un certain nombre de questions afin de déterminer si ce mode de traduction est adapté au genre de textes qu’il a à traduire et s’il répond bien à ses besoins. Quelle est la nature des textes? À qui s’adresse la traduction? Quel usage veut-on en faire? Une traduction approximative et inélégante peut très bien satisfaire tel utilisateur désireux de connaître uniquement la pertinence d’un texte ou de déterminer s’il vaut la peine d’en faire une traduction de bonne qualité. Tel autre utilisateur pourra se contenter lui aussi d’une traduction imparfaite s’il veut simplement obtenir une idée générale du contenu d’un document. Enfin, une autre application très courante de la TA est la production d’une ébauche de traduction révisable. La TA est une approche productive lorsqu’il est nécessaire de traduire rapidement un volume important de documents, une situation à laquelle sont confrontées un nombre croissant de grandes entreprises.
Il est clair qu’il s’agit ici de textes pragmatiques plus ou moins spécialisés et nullement de textes ayant une forte composante esthétique. Les textes purement informatifs dans lesquels le style est secondaire (ex.: un manuel d’utilisateur) se prêtent mieux à la TA que les textes publicitaires, par exemple.
Lorsque la TA se révèle un mode opératoire approprié compte tenu de la situation, il importe d’examiner les moyens à prendre pour atteindre la qualité de traduction désirée. Le succès de la TA repose, en effet, sur une bonne organisation du travail dès l’étape de la rédaction (comme nous le verrons plus loin), ce qui peut nécessiter le paramétrage du système ainsi que la préédition et postédition des textes. En procédant ainsi, de grandes entreprises ayant intégré la TA dans leur processus de documentation ont obtenu des résultats très satisfaisants. Néanmoins, il ne faut pas sous-estimer les limites de la TA.
Les nombreux exemples de traductions loufoques résultant de la TA témoignent à l’évidence de ses limites. Seule une machine dénuée de jugement peut traduire Machine wash cold/Lay flat to dry par «*La machine lave le froid/Poser l’appartement pour vous sécher» ou encore He’s the teacher’s pet par «*Il est l’animal de l’enseignant». Cependant, au lieu de nous attarder aux faiblesses de la TA, il nous paraît plus utile d’examiner quelques-unes des principales causes de ses ratés.
Tout traducteur sait qu’il est primordial de connaître la provenance du texte original, le contexte de sa production, son auteur ou tout au moins l’organisme duquel il émane, ses destinataires et sa finalité. Cette information non linguistique est essentielle, car elle dicte les choix à faire lors de l’établissement des équivalences (v. l’OS 21). Il va de soi que les programmes de TA n’ont pas cette connaissance du monde, puisque les ébauches de traduction qu’ils proposent sont produites presque uniquement à partir d’éléments linguistiques.
Généralement, les logiciels de TA procèdent phrase par phrase et sont ainsi privés des renseignements indispensables à l’interprétation du sens fournis par le contexte ou la situation d’énonciation (v. l’OS 20). Il en résulte que la machine a du mal à lever les ambiguïtés. Ainsi, pour elle, dans la phrase Time flies like an arrow, les trois premiers mots peuvent être des verbes, ce qui aboutit à trois traductions possibles: a) *Chronométrez les mouches comme vous le feriez pour une flèche. b) Le temps file comme une flèche. c) *Les mouches du temps aiment une flèche2. Étant incapable de désambiguïser certaines phrases, la machine ne peut pas choisir celle qui est pertinente en fonction du contexte.
La variation lexicale et la créativité posent aussi des embûches à la machine. Un système de TA produira souvent une mauvaise traduction s’il rencontre un mot inconnu ou rare ou s’il doit traiter une phrase longue et complexe, car sa «connaissance» de la langue est insuffisante.
Pour accroître la qualité de la TA et pallier ses lacunes, l’humain peut intervenir avant la traduction (préédition), ou après celle-ci (postédition).
Une façon d’augmenter la qualité de la TA consiste à fournir au système le plus d’information possible sur le vocabulaire et les structures syntaxiques des textes à traduire ainsi qu’une liste des correspondances terminologiques du domaine d’activité de l’entreprise ou de l’utilisateur.
On peut aussi, à cette étape, faire ce qu’on appelle la préédition, c’est-à-dire anticiper les erreurs que la machine risque de commettre en simplifiant, par exemple, les phrases complexes ou en faisant en sorte que le système connaisse le vocabulaire utilisé. On réduit ainsi le risque d’erreurs que pourrait commettre la machine. En fait, dans certaines grandes entreprises, les textes sont souvent adaptés à la traduction automatique dès l’étape de la rédaction: on impose aux rédacteurs des règles lexicales et syntaxiques rigoureuses qui forment ce qu’on appelle un «langage contrôlé».
Toutefois, l’approche la plus utilisée pour améliorer la qualité de la TA demeure la postédition, c’est-à-dire la correction par un réviseur (ou postéditeur) des erreurs et des imprécisions émaillant les textes d’arrivée. La postédition peut être plus ou moins légère. On dit qu’elle est minimale ou rapide si elle porte sur la correction des erreurs sémantiques ou grammaticales les plus graves, et maximale ou classique si elle porte à la fois sur le sens, la grammaire et le style. Dans ce dernier cas, le produit fini est alors de qualité comparable à celle d’une traduction réalisée par un traducteur professionnel. Dans beaucoup d’applications, la postédition débouche sur un texte de très bonne qualité, de sorte que la frontière séparant la traduction automatique assistée par l’humain et la traduction humaine assistée par l’ordinateur tend à s’estomper. On pourrait placer les travaux de traduction sur un axe continu, en fonction du niveau d’intervention de l’humain, d’une part, et d’apport de la machine, d’autre part. Nous verrons plus loin d’autres exemples de cette «collaboration» entre l’humain et la machine.
Comme nous l’avons déjà vu, en TAO, c’est la machine qui est au service du traducteur et non l’inverse. Celui-ci joue un rôle actif dans l’utilisation des outils d’aide à la traduction. Il est maître à bord et génère lui-même ses traductions, alors que, TA, il ne peut le plus souvent intervenir qu’avant ou après l’étape de la traduction proprement dite.
Parmi les outils les plus courants que le traducteur utilise pour produire ses traductions figurent les quatre genres de logiciels suivants: 1. les concordanciers; 2. les extracteurs de termes; 3. les gestionnaires de terminologie; 4. les gestionnaires de mémoires de traduction (souvent appelés simplement «mémoires de traduction», terme qui sera évité dans ce sens ici à cause de son ambiguïté). Au moyen de ces logiciels, le traducteur repère et «recycle» des équivalences existantes qu’il extrait soit de corpus de traductions déjà constitués, soit de diverses sources documentaires. Ces outils (et d’autres encore) peuvent être intégrés dans des environnements de traduction, qui seront décrits plus loin.
Les concordanciers sont des logiciels qui cherchent des chaînes de caractères ou des suites de chaînes de caractères (mots, suites de mots, parties de mots) dans un ou plusieurs textes à la fois, puis affichent ces occurrences entourées d’une portion plus ou moins grande du texte d’où elles proviennent. On s’en sert pour réaliser une variété de tâches d’analyse linguistique dans divers domaines: études littéraires, lexicologie, lexicographie, terminologie, stylistique comparée et, bien sûr, traduction.
Les collections de textes (corpus) que dépouillent les concordanciers sont constituées de textes rédigés en langue générale ou spécialisée. Le dépouillement s’effectue sur des corpus existants ou sur des textes stockés au préalable par l’utilisateur dans son ordinateur. Cette dernière possibilité est particulièrement intéressante pour le langagier qui travaille dans un domaine spécialisé, car il peut ainsi établir des concordances en fonction de ses besoins.
On distingue deux types de concordancier: unilingue et bilingue. Comme son nom l’indique, le concordancier unilingue scrute une seule langue à la fois. Certains concordanciers affichent les résultats en format KWIC (Key Word In Context) (figure 1), d’autres dans le texte intégral, d’autres encore offrent les deux possibilités.
Figure 1 — Concordance unilingue en format KWIC produite par TextStat
Les concordanciers bilingues effectuent la recherche dans des textes alignés, c’est-à-dire des paires de textes mis côte à côte, l’un étant la traduction de l’autre. Le résultat de la recherche s’affiche généralement sur deux colonnes parallèles (figure 2). Avant que l’on puisse utiliser un concordancier bilingue, il faut d’abord procéder à l’alignement de deux textes, autrement dit, disposer d’un bitexte. L’opération consiste à diviser un texte original et sa traduction en segments. L’unité retenue est généralement la phrase. Ce travail est effectué par un logiciel appelé «aligneur de textes».

Figure 2 — Recherche de la difficulté de traduction to deal with dans TransSearch (corpus: Débats de la Chambre des communes)
Les concordanciers présentent de multiples avantages. Grâce à eux, les recherches dans de vastes corpus de bitextes sont rapides, systématiques et efficaces. Le repérage et la comparaison des nombreuses occurrences d’une unité donnée s’en trouvent aussi grandement facilités. Les concordanciers bilingues permettent de chercher un mot ou une expression en langue de départ et de trouver presque instantanément une ou plusieurs correspondances dans la langue d’arrivée. Cette fonction se révèle si utile que certains traducteurs utilisent des concordanciers au lieu des dictionnaires bilingues. Certains outils récents repèrent automatiquement d’éventuelles correspondances du terme cherché et les proposent à l’utilisateur, qui n’a (en principe) plus qu’à valider la meilleure.
Les fonctions de recherche avancées permettant de construire des requêtes complexes (ex.: chercher plusieurs unités à la fois) ou approximatives (ex.: trouver des unités similaires, mais non identiques, à une chaîne donnée) sont d’autres avantages qui font des concordanciers un outil de travail précieux pour le langagier.
Exemples de concordanciers
a) unilingues
AntConc. Laurence Anthony
http://www.antlab.sci.waseda.ac.jp/software.html
TextStat. Matthias Hüning, Freie Universität Berlin
http://neon.niederlandistik.fu-berlin.de/en/textstat/
WordSmith Tools. Lexical Analysis Software Ltd./Oxford University Press
http://www.lexically.net/wordsmith/index.html
b) bilingues
Linguee. Linguee GmbH
TradooIT. Logosoft Technologies
TransSearch. Terminotix
WeBiText. Terminotix
Les concordanciers ne sont pas les seuls outils qui offrent au langagier la possibilité de repérer des chaînes de caractères. Les extracteurs de termes ont aussi la capacité d’isoler automatiquement des suites de mots (et parfois des mots simples) susceptibles de constituer des unités terminologiques.
Une des compétences les plus importantes que l’on s’attend de trouver chez un traducteur spécialisé, c’est la connaissance approfondie de la terminologie du secteur d’activité dans lequel il travaille. Les extracteurs de termes ont pour utilité de repérer automatiquement des termes présents dans les textes. Cette extraction fournit au traducteur un aperçu du contenu des textes à traduire et un bon point de départ pour ses recherches terminologiques, ce qui se traduit par un gain de temps et une efficacité accrue. C’est surtout le cas lorsqu’un projet de traduction est réalisé en équipe. L’extracteur de termes permet d’uniformiser la terminologie dès le début et allège d’autant la révision finale (v. l’OS 11).
Pour accomplir cette tâche, les extracteurs de termes analysent les textes fournis par l’utilisateur en faisant appel à la fréquence d’occurrence et à différents repères formels typiques de termes et, à partir de ces analyses, dressent une liste de candidats-termes, c’est-à-dire de mots ou syntagmes susceptibles d’être des termes (ex.: fibrome ou vaisseau sanguin, en médecine), par opposition aux unités lexicales non spécialisées de la langue courante (ex.: soleil, table, sable). Dans la liste produite par l’extracteur, chaque candidat-terme est habituellement accompagné de sa fréquence dans le ou les textes analysés, la liste étant généralement triée par fréquence, par ordre alphabétique ou par un «score» représentant la probabilité que le candidat soit effectivement un terme, tel que calculé par l’outil (figure 3).

Figure 3 — Liste de candidats-termes extraits au moyen de TermoStat Web, triée par score
On peut se servir des extracteurs bilingues pour analyser des textes alignés et repérer non seulement les candidats-termes dans la langue de départ, mais aussi leurs équivalents probables dans la langue d’arrivée.
Les chercheurs préfèrent parler de «candidats-termes», car les extracteurs sont pour l’instant incapables d’identifier un terme avec certitude. En fait, même les humains ne s’entendent pas toujours à ce sujet, les uns considérant telle unité comme un terme là où d’autres y voient un non-terme. Les extracteurs savent reconnaître les traits formels typiques des termes, mais sont incapables de juger de caractéristiques fondamentales telles que la désignation d’un concept ou un sens spécifique à un domaine spécialisé. Les candidats-termes ne sont donc pas tous des termes ni même des unités entières; c’est le cas, par exemple, de yellow folder (figure 3), où l’adjectif de couleur n’est pas pertinent. De là découle la nécessité pour l’utilisateur de procéder à un tri afin de ne retenir que les unités pertinentes, après quoi il peut les stocker en vue d’un usage ultérieur.
Exemples d’extracteurs de termes
Synchroterm. Terminotix
TermoStat Web. Patrick Drouin, Université de Montréal
Le temps et l’effort consacrés aux recherches de vocabulaire ne sont vraiment optimisés que si le fruit des recherches est conservé pour usage ultérieur, sinon le langagier risque de refaire constamment les mêmes recherches. On peut stocker ces données dans un fichier d’un logiciel de traitement de texte (ex.: Word), dans une feuille de calcul ou dans une base de données générique. Il existe, en outre, des logiciels conçus spécialement pour permettre à l’utilisateur d’emmagasiner la terminologie, de l’organiser, de la mettre à jour et d’y accéder facilement. Ces logiciels sont appelés «gestionnaires de terminologie».
Ces derniers proposent un modèle de fiche terminologique généralement modifiable selon les besoins et préférences de l’utilisateur et sur lequel l’information est consignée dans divers champs (figure 4). Un atout important des gestionnaires de terminologie est la facilité avec laquelle il est possible d’ajouter des champs au modèle de base. Un traducteur pourra, par exemple, indiquer sur ses fiches le nom d’un client, le titre du projet de traduction ou tout autre renseignement pertinent. La consignation de l’information est à la fois personnalisée et uniformisée. Les différents éléments stockés sont le plus souvent consignés dans des champs distincts: la vedette (l’unité terminologique), son ou ses équivalents, le contexte ou une définition, le domaine, la source, les marques grammaticales, les marques d’usage, la date de création de la fiche, le nom de son auteur, etc.
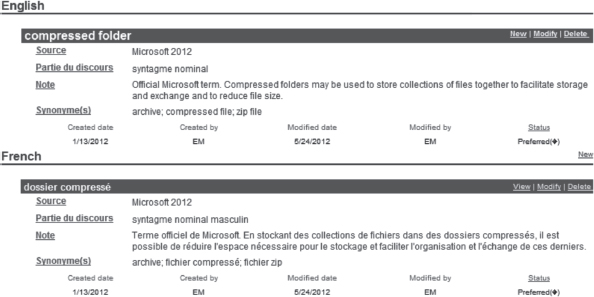
Figure 4 — Fiche terminologique créée dans MultiTrans
Il va de soi que l’utilisateur doit définir avec soin ses besoins au moment de créer une base terminologique s’il veut en tirer tous les avantages. Enfin, notons que, dans un environnement de traduction, les unités stockées ne se limitent pas aux «vrais» termes, mais peuvent inclure également toute autre unité lexicale susceptible d’être réutilisée (ex.: une phrase ou un syntagme récurrent, une adresse, un slogan). Il peut donc être souhaitable de distinguer ces deux catégories d’entrées.
Exemples de gestionnaires de terminologie
i-Term. DANTERMcentret
http://www.i-term.dk/index.php
MultiTerm. SDL Trados
TermStar. Star Hungary Kft
Les gestionnaires de mémoires de traduction sont parmi les outils d’aide à la traduction qui ont suscité le plus d’intérêt chez les traducteurs au cours des dernières années; ils constituent généralement le «cœur» des environnements de traduction (décrits ci-dessous). Un gestionnaire de mémoires de traduction offre la possibilité de créer, d’exploiter et de mettre à jour des «mémoires de traduction», c’est-à-dire des bases de données linguistiques qui enregistrent des segments au fur et à mesure qu’ils sont traduits en vue d’une réutilisation ultérieure. Tout comme un bitexte, les mémoires de traduction sont constituées de segments appariés (figure 2). Certaines d’entre elles conservent les liens entre les différents segments de textes, préservant une sorte de bitexte intégral, tandis que d’autres stockent des segments alignés isolément, sans lien avec leur contexte original.
Le succès de ces outils s’explique, notamment, par le fait qu’ils réduisent au minimum les tâches répétitives, comme la traduction de phrases récurrentes, tant à l’intérieur d’un même document que d’un document à un autre. Autres avantages importants: les mémoires de traduction éliminent le dédoublement des recherches et facilitent énormément l’uniformisation de la terminologie. Bon nombre de traducteurs qui les utilisent n’ont pas tardé à constater une nette augmentation de leur productivité et de la qualité du produit final.
C’est en grande partie par le niveau d’automatisation qu’un gestionnaire de mémoires de traduction se distingue d’un concordancier bilingue. En effet, dans un concordancier bilingue, le traducteur interroge les textes alignés «manuellement» et choisit quelle chaîne chercher à quel moment. En revanche, le gestionnaire explore automatiquement la mémoire de traduction dès que l’utilisateur s’apprête à traduire une phrase. Il compare automatiquement la phrase à traduire à celles qui sont stockées dans la mémoire et tente de repérer les phrases qui lui sont identiques ou semblables.
Si le gestionnaire détecte une phrase identique (mêmes mots, mêmes formes, même ordre et, idéalement, même mise en forme), il s’agit d’une «correspondance exacte» ou «correspondance parfaite». Le gestionnaire propose alors au traducteur d’insérer dans son texte le segment correspondant dans la langue d’arrivée consigné dans la mémoire de traduction. Le traducteur peut décider a) soit de valider cette solution et de l’insérer telle quelle dans sa traduction; b) soit de la modifier pour qu’elle convienne au nouveau texte; c) soit de traduire lui-même le segment ou de chercher ailleurs un autre équivalent.
Lorsque le gestionnaire repère dans la mémoire de traduction une phrase similaire mais non identique, on dit qu’il s’agit d’une «correspondance floue». Pour chacune d’elles, le logiciel calcule le degré de similitude entre la phrase à traduire et la phrase conservée dans la mémoire. Les correspondances dont la similitude est relativement élevée (ex.: deux phrases de même structure, mais dont un ou deux mots seulement diffèrent) sont proposées au traducteur avec indication des différences afin de l’aider à cibler les modifications nécessaires. Les phrases présentant un faible degré de similitude sont le plus souvent écartées, car il serait plus long et moins rentable de les modifier que de les traduire «manuellement».
Les gestionnaires de mémoires de traduction permettent généralement à l’utilisateur de fixer lui-même le seuil de similitude en dessous duquel les correspondances floues ne sont plus proposées. Bien sûr, ce paramétrage ne règle pas toutes les difficultés associées à l’évaluation automatique de l’utilité relative d’une correspondance floue. Des correspondances jugées faibles, par exemple lorsqu’on calcule le degré de similitude sur le plan de la phrase, peuvent inclure des propositions entières ou des segments de texte plus ou moins longs qui sont très similaires, voire presque identiques à la phrase à traduire, et ces correspondances sont donc récupérables. Certains outils offrent maintenant des fonctions qui permettent de récupérer ces correspondances de «sous-segments». L’impuissance des gestionnaires de mémoires actuels à reconnaître la correspondance entre différentes formes (flexions) d’un même mot constitue une autre faiblesse qui nuit à l’identification de segments potentiellement utiles.
Une fois la traduction terminée, il reste encore à la vérifier minutieusement afin qu’elle ne souffre pas d’un manque de cohésion. Seule une relecture attentive permet de faire en sorte que la suite de segments isolés traduits plus ou moins séparément forme bien un texte fluide, logique et cohérent (v. les OS 9, 10 et 73).
Il est essentiel que le flux de travail exécuté au moyen d’outils d’aide à la traduction soit fluide et cohérent. Des suites de logiciels appelés «environnements de traduction» servent à optimiser ce flux. L’environnement de traduction offre le double avantage a) d’intégrer divers outils d’aide à la traduction dans une suite cohérente et b) d’automatiser la consultation de ressources documentaires et de bases de données terminologiques, le stockage de nouvelles données, ainsi que l’insertion des solutions trouvées dans les dictionnaires ou les textes en cours de traduction. Le flux de travail est ainsi relativement linéaire et grandement simplifié.
L’environnement de traduction se compose habituellement d’un aligneur de textes, d’un extracteur de termes et d’un gestionnaire de terminologie, ainsi que d’un gestionnaire de mémoires de traduction, d’une fonction d’analyse de textes et d’un traducteur de vocabulaire (défini plus loin). L’environnement inclut souvent aussi une fonction similaire à un concordancier bilingue (voire unilingue).
Pour accéder rapidement à toutes les composantes de son environnement de traduction, le traducteur peut généralement ajouter une barre d’outils ou un menu à son logiciel de traitement de texte. Certains environnements comportent un éditeur de textes intégré dans lequel le traducteur peut rédiger directement ses traductions. Dans un cas comme dans l’autre, l’utilisateur accède facilement aux composantes clés de l’environnement.
Les mémoires de traduction sont généralement couplées à une base terminologique. Au moment de la traduction a lieu ce qu’on appelle la «reconnaissance active de la terminologie». Lorsqu’il repère des correspondances dans la mémoire de traduction, le système cherche aussi des termes connus dans le texte à traduire et, lorsqu’il en trouve, affiche l’entrée correspondante provenant de la base terminologique. Lorsque le traducteur modifie des propositions ou traduit lui-même des segments, il peut alors insérer facilement les équivalents issus de cette base. Cette fonction accélère les recherches et facilite grandement l’uniformisation de la terminologie dans les documents traduits. Cela exige, toutefois, une bonne gestion préalable de la terminologie. Toute nouvelle correspondance terminologique peut aussi venir enrichir la base terminologique au fur et à mesure que la traduction avance.
Par ailleurs, il existe sur le marché des logiciels qui traduisent automatiquement les segments pour lesquels un gestionnaire de mémoire de traduction ne fournit aucune correspondance. De plus en plus d’environnements de traduction intègrent un module de TA (en ligne ou non, gratuit ou non) au processus de travail pour ces segments orphelins. L’utilisateur reste toujours libre d’accepter, de modifier ou de rejeter les propositions suggérées par le logiciel. Il s’agit ici d’un autre exemple de progrès qui brouille la frontière entre la TA et la TAO.
Exemples d’environnements de traduction
Déjà Vu. Atril
Heartsome. Heartsome Technologies
JiveFusion Suite. JiveFusion Technologies
LogiTerm. Terminotix
MemoQ. Kilgray Translation Technologies
MetaTexis. MetaTexis Software and Services
MultiTrans. MultiCorpora
OmegaT
SDL Trados Studio. SDL Trados
WordFast. WordFast LLC
Comme nous venons de le voir, la rapidité d’exécution d’une traduction au moyen d’un gestionnaire de mémoires de traduction dépend du nombre de correspondances et du degré de similitude entre le contenu du texte à traduire, la mémoire de traduction et la base terminologique. Aussi, les environnements de traduction intègrent généralement une fonction d’analyse de textes grâce à laquelle il est possible de déterminer s’il sera avantageux ou non d’utiliser une mémoire de traduction et une base terminologique pour traduire un document donné.
Cette fonction calcule le nombre de segments pour lesquels il existe une correspondance parfaite ou floue dans la mémoire ainsi que le nombre de termes connus dans la base terminologique. Cette évaluation guide le traducteur dans sa décision. Elle facilite aussi le calcul du temps qu’il faudra pour traduire un texte. Cette indication se révèle tout particulièrement utile pour les traducteurs indépendants et les cabinets lorsqu’ils négocient des échéances avec un client ou planifient leur calendrier de travail.
Dans les pages qui précèdent, nous avons décrit une approche interactive dans un environnement de traduction: le texte à traduire est traité segment par segment et les décisions sont prises par le traducteur au cas par cas. Dans certaines situations, il est aussi possible d’obtenir une prétraduction. Pour ce faire, il suffit de demander au gestionnaire de mémoires de traduction d’insérer automatiquement toutes les correspondances parfaites et au traducteur de vocabulaire de faire la même chose pour toutes les correspondances terminologiques présentes dans la base terminologique.
Le traducteur de vocabulaire fonctionne plus ou moins comme la reconnaissance active de la terminologie, sauf qu’il insère (quasi) automatiquement les équivalents de termes trouvés dans la base terminologique.
Le traducteur obtient ainsi un texte hybride, constitué de phrases et de vocabulaire dans les deux langues. Sa tâche consiste à traduire tout ce que l’environnement de traduction n’a pas traduit et, surtout, à s’assurer que le texte produit est conforme aux consignes, uniforme et cohérent. Cette méthode est souvent privilégiée pour des raisons d’uniformisation lorsque la traduction d’un document est réalisée par une équipe de traducteurs, surtout si cette équipe est formée de traducteurs indépendants qui ne connaissent pas les exigences ni les préférences du client.

Figure 5 — La traductique: TA et TAO
Si la traductique est en constante évolution, c’est en grande partie grâce aux suggestions des traducteurs, principaux utilisateurs des produits qui automatisent en tout ou en partie la traduction et les tâches connexes. Nous pouvons évoquer certaines améliorations récentes ou imminentes portant sur les aligneurs de textes (ex.: alignement de mots), les concordanciers bilingues (ex.: identification automatique des équivalents) et les environnements de traduction (ex.: traitement des formes fléchies, intégration de la TA). De nombreux autres progrès à venir rendront ces logiciels encore plus conviviaux et plus performants.
Bien que ces outils de travail soient puissants, polyvalents et utiles et qu’ils contribuent à accroître la productivité et la qualité des traductions, il faut néanmoins apprendre à les utiliser efficacement et intelligemment. Leur utilisation optimale exige de bien connaître leurs forces, leurs faiblesses et leurs limites. Nul besoin de préciser, en terminant, que toutes ces aides à la traduction ne sont que des «aides» et qu’elles ne dispensent aucunement de l’aptitude à traduire. Autrement dit, il faut savoir traduire pour les utiliser à bon escient.
Centre de recherche en technologies langagières, Gatineau, «LinguisTech. Les technologies langagières au bout des doigts!», http://www.linguistech.ca.
Austermühl, Frank (2001), Electronic Tools for Translators.
Bowker, Lynne (2002), Computer-Aided Translation Technology. A Practical Introduction.
L’Homme, Marie-Claude (2008), Initiation à la traductique.
V. aussi: Arnold (2003); Bédard (1998a, 1998b, 2001); Bowker (2006); Bowker et Pearson (2002); Cohen (2002); Dillon et Fraser (2006); Lanctôt (2001); L’Homme (2004); Pym (2011); Taravella (2011).
Exercice 1. — Extracteurs de termes et concordanciers bilingues
1. Commencez par copier à partir du site du Commissariat aux langues officielles le texte «Performance Report 2006-2007 — Statistics Canada», http://www.ocol-clo.gc.ca/html/statscan_06_07_e.php, et collez-le dans un fichier de votre logiciel de traitement de texte. Sauvegardez une seconde copie en format .TXT seulement. Faites de même pour le texte «Bulletin de rendement 2006-2007 — Statistique Canada», http://www.ocol-clo.gc.ca/html/statscan_06_07_f.php.
2. Faites traiter le texte «Performance Report» sauvegardé en format .TXT par un extracteur de termes (ex.: «TermoStat Web», http://termostat.ling.umontreal.ca). Parcourez les résultats pour évaluer si vous trouvez que l’extraction a produit une liste d’unités intéressantes pour un traducteur dans ce domaine.
3. Repérez, parmi les résultats, certaines unités qu’il pourrait être intéressant d’examiner de plus près (ex.: des candidats-termes tels que linguistic duality, language of work, language of choice, ou des syntagmes récurrents tels que implementation of section, positive measure).
4. Parcourez aussi le document et cherchez d’autres candidats-termes que vous trouvez intéressants et qui mériteraient plus de recherches, mais qui n’ont pas été identifiés par l’extracteur de termes. En trouvez-vous? Pouvez-vous dire pourquoi ces unités n’ont pas été relevées par l’extracteur de termes?
5. Alignez les documents anglais et français afin de repérer les façons possibles de traduire ces unités. Par exemple, vous pouvez utiliser les différentes fonctions intégrées dans un environnement de traduction ou faire appel à un outil tel que «YouAlign», http://www.youalign.com, pour faire l’alignement et télécharger le produit en format .HTML (qui peut ensuite être visualisé et interrogé grâce aux fonctions de recherche d’un texteur ou d’un fureteur).
6. Cherchez les occurrences des unités intéressantes et repérez les équivalents proposés dans le bitexte que vous avez créé. Pour compléter la recherche dans ce document, cherchez les mêmes unités dans au moins un concordancier bilingue qui offre un corpus intégré (ex.: «WeBiText», http://www.webitext.com, «Linguee», http://www.linguee.fr, ou «TradooIT», http://www.tradooit.com).
7. Trouvez-vous un ou plusieurs équivalents potentiels pour chacune des unités étudiées? Lesquels? Comparez entre eux les résultats des analyses, puis comparez-les avec ce que vous trouveriez dans des sources documentaires classiques comme les dictionnaires ou les banques de données terminologiques. Quelles différences notez-vous entre ces sources? Quelles sont leurs forces et leurs faiblesses respectives?
8. À votre avis, quelles données identifiées dans ces recherches seraient intéressantes à stocker dans une base terminologique personnelle? Pourquoi?
Exercice 2. — Mémoires de traduction et traducteurs de vocabulaire
1. Reprenez le bitexte et la liste de termes et équivalents de l’Exercice 1.
2. Copiez et sauvegardez dans un fichier le «Report Card 2007-2008» (la version anglaise du «Bulletin de rendement 2007-2008») de Public Works and Government Services Canada (PWGSC, Travaux publics et Services gouvernementaux Canada, http://www.ocol-clo.gc.ca/html/pwgsc_tpsgc_07_08_e.php).
3. Comparez les deux documents en anglais (Statistics Canada et PWGSC): quelle proportion du texte et de la terminologie est la même? (Si vous le désirez, vous pouvez utiliser les fonctions de comparaison de documents de votre logiciel de traitement de texte ou créer un bitexte à partir de ces deux documents afin de faciliter la comparaison. Dans un environnement de traduction, vous pourriez également utiliser l’outil d’analyse de textes pour calculer le degré de similitude.)
4. Sachant qu’un environnement de traduction permettrait de recycler les traductions de phrases similaires et identiques à celles trouvées dans la mémoire de traduction et la terminologie bilingue tirée d’anciennes traductions, croyez-vous que cet outil permettrait d’accélérer et de faciliter la traduction du nouveau document?
5. Répétez l’exercice avec des documents de votre choix. Comment les résultats se comparent-ils avec ce que vous avez vu dans les textes suggérés pour l’exercice?
6. À votre avis, dans quelles circonstances et avec quels genres de documents les environnements de traduction sont-ils le plus utile? Le moins utile?
Exercice 3. — Traduction automatique
1. Dans un fureteur, ouvrez le document «Facts about Official Languages» du Commissariat aux langues officielles (http://www.ocol-clo.gc.ca/html/facts_faits_2008_09_e.php), qui décrit le statut du bilinguisme au Canada.
2. Copiez l’adresse du document et collez-la dans la fenêtre Traduction de Google (http://translate.google.ca/?hl=fr). Choisissez l’anglais comme langue de départ et le français comme langue d’arrivée, puis cliquez sur le lien paraissant dans la fenêtre de droite pour voir la traduction. Ou encore, copiez le contenu du document et faites-le traduire par Google ou un autre système de traduction automatique en ligne.
3. Analysez la traduction produite: trouvez-vous des erreurs de sens? Des erreurs de vocabulaire ou de grammaire? Des fautes de style? De quel type?
4. En général, croyez-vous que la qualité de la traduction est suffisante pour vous permettre de comprendre le sens du texte de départ? La qualité est-elle suffisamment élevée pour que le texte soit publié sans révision?
5. Combien de temps pensez-vous qu’il vous faudrait pour corriger ces erreurs? Uniquement les erreurs les plus graves (par exemple, pour des fins de compréhension seulement)? Toutes les erreurs (par exemple, pour fin de publication)? Serait-il plus long ou moins long de faire la traduction sans l’aide d’un traducteur automatique?
6. Comparez maintenant la traduction automatique avec la traduction officielle en ligne «Faits saillants sur les langues officielles», http://www.ocol-clo.gc.ca/html/facts_faits_2008_09_f.php. (Si vous le désirez, pour faciliter la comparaison, vous pouvez enregistrer une copie des deux traductions et utiliser les fonctions «Comparaison de documents» de votre logiciel de traitement de texte ou utiliser un aligneur de textes pour les mettre côte à côte.)
7. Comment la qualité des deux traductions se compare-t-elle? Comment caractérisez-vous les différences observées? S’agit-il d’erreurs ou de simples divergences dans les choix de traduction?
8. Répétez l’exercice avec des documents de votre choix. Comment les résultats se comparent-ils avec ce que vous avez vu dans le texte suggéré pour l’exercice?