9 Proactive Problem
Management
Problem Management:
The investigation into causes of technical incidents. An incident will be closed off when service is restored but its underlying cause may remain unresolved and result in re-occurrence. When the fire has been put out, problem management is all about identifying what caused it in the first place.
This chapter will help you:
• recognise the cornerstones for good problem management
• formulate a strategy for managing problems in your organisation
• understand how to use problem data to drive the process
Sometimes using the right words can be very important. Most people would talk about their weight in kilograms but engineers and scientists would be more precise about the definition. Mass is measured in kilograms and weight is a force that is measured in Newtons. In common conversation it doesn’t particularly matter, but if you were doing some engineering calculations for a bridge design it could make a huge difference.
The word problem is also prone to semantic misuse. When talking about managing problems we must differentiate between (i) an incident and a problem, and (ii) a symptom and a cause.
An incident is best thought of as the fire that needs putting out. It is the period during which the service is degraded or unavailable.
It should be relatively short lived. The primary aim is to restore the service to full working order as quickly as possible.
It won’t always be possible to spot what triggered the issue during the life of the incident, so this must be done after the event. Problem refers to the follow-up investigation and may take a lot longer than the incident itself. The aim being to identify the original cause – the conditions or actions that resulted in the service degradation.
It is not uncommon for people to treat a symptom in the mistaken belief it is the cause. For example, a technician could repeatedly configure additional storage when a database runs out of space. However, the data volume is growing because of a very badly coded reporting routine. Allocating more space will not stop this recurring. It is an indication - a symptom - of a deeper problem. The code is the cause.
A problem arises when
-
an incident leaves behind the need to investigate its cause, or
-
multiple incidents point at a common, underlying theme
The latter often arises from picking up on trends in incident volumes, such as help desk statistics. Alternatively, it could be prompted by an individual observing some suspicious, recurring behaviours or conditions. Whatever the stimulus, the problem requires someone with strong analytical skills.
CORNERSTONES OF SUCCESSFUL PROBLEM MANAGEMENT
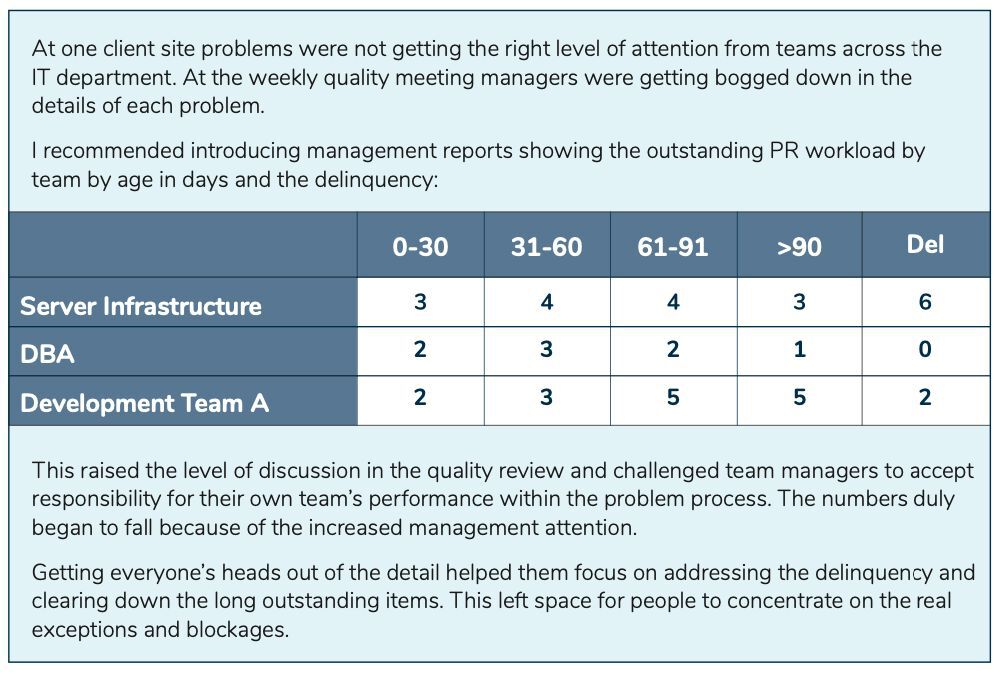
Use management information reports to drive the process
In my experience most people would prefer to be working on new projects and researching new products rather than digging into last month’s problems. As issues age, the memory of the service outage drops down people’s priority lists and it becomes harder to get teams to put more focus on problem investigation. Tackling other managers head on can be both frustrating and fruitless.
One way to overcome this is to take a step back and drive the process through good use of management information
reports. Getting the right data into the right format and demonstrating it in the right forum can drive adherence to the problem management process. Highlighting relative performance can give team managers the impetus to take greater responsibility for their team’s backlog of problem records (PRs).
Ultimately, this requires top down support and it works best in organisations where managers have objectives relating to IT service availability and systems quality.
Encourage a strong sense of problem ownership
As with most things, problem investigations can often require some degree of coordination between people in different teams, or even different divisions of an organisation. In larger IT departments specialist teams can be very siloed to a point where some people believe their responsibilities can’t possibly extend beyond the boundaries of their own team. Any coordination outside their tight unit must be done through their line manager, or via a project manager, or – in the case of problems – by the problem managers.
Whilst this might be a sensible approach for certain high profile, high priority, complex problem situations, it shouldn’t become the default. Routing communications through another individual simply puts an unnecessary link in the chain and inevitably adds delays. That is why it is always refreshing – and far more effective – when individuals step up and take ownership. This frees up the problem manager to focus on the issues that really do need their involvement.
Deploy strong analytical skills to find hidden causes
In chapter 8, Measures and Continuous Improvement, I stressed the need for strong analytical skills to make sense of incident volumes in the Help Desk. Analysing the data to identify underlying themes is the connection into problem management. The themes are the problems.
A good analytical mind will probe with questions to establish the root cause that needs to be addressed. Earlier in this chapter we talked about finding the root cause of a database space issue. It is important to continue questioning until you are comfortable you have gone beyond the symptoms and found the actual trigger.
Why did the service fail? Why did the database run out of space? What is causing the data to grow at an abnormal rate? When did its rate of growth start to accelerate?
What happened at that time that would have caused that to happen?
Five questions later you have arrived at a change that was implemented four months ago. It introduced some end of
month reporting which uses lots of transient data but doesn’t delete it all afterwards.
PROACTIVE STRATEGIES FOR LARGER IT DEPARTMENTS
In larger IT departments it helps to set out a proactive strategy for driving the problem management process. Even if you have a team of problem managers the number of open PRs will be too high to give dedicated attention and management to each one, so you must set out an approach that will encourage every team to follow the process.
I was responsible for managing the Problem Management team inside a 4,500 strong IT division at a large corporate. At the time, the problem managers weren’t very visible and the executive Head of IT Operations considered the team to be ineffective. The objective was clear – change the team from problem administration to proactive problem management.
The strategy involved:
• Stopping mundane tasks such as phoning team leaders to let them know one of their PRs was about to go delinquent
• Manage priority 3 and 4 PRs in bulk by using simple but effective management reports and influencing resolver team performance
• Step up proactive management of priority 2 PRs, focusing on exceptions
• Strong involvement in priority 1 and Major Incident Review situations
• Carry out service availability analysis to identify underlying trends affecting production services
• Get in front of the senior management across the whole of the IT organisation to promote the problem management process, using relevant service quality data
In smaller organisations this level of strategic direction may be some way beyond what is required. However, the principles mentioned in this chapter will still be applicable.
For example – getting the right data in front of the right people in the right forum is one such principle that must be applied when dealing with 3rd party service providers. If you outsource any of your IT provision, make sure you get the problem list on the agenda at your supplier liaison meeting. That is the best place to escalate them and get the right visibility.