One of the most difficult questions to answer when building out a BigQuery implementation is how much it will cost. In a traditional model, you would answer questions about scale and storage before you began provisioning the system. With BigQuery, as we saw in Chapter 1, you can start loading and querying immediately without even understanding the cost model.
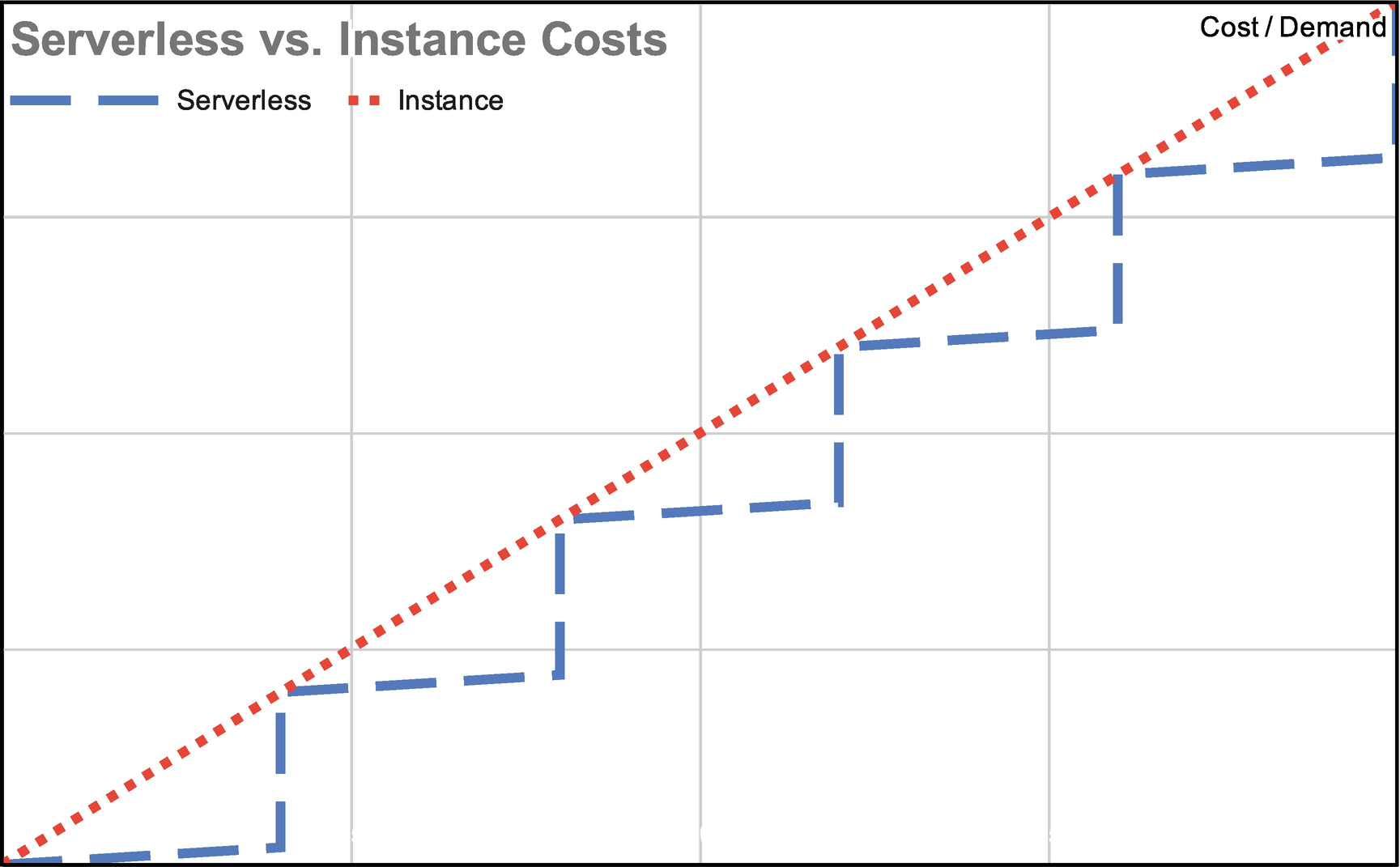
Step function showing compute costs as you add more servers and a steadier line for serverless costs
This introduces the problem of high cost variability. No one is going to object to spending less money, but it’s hard to budget if you don’t know what to expect. In this chapter, we’ll cover how costs work in BigQuery and how you can predict, optimize, and monitor your usage. We’ll also cover reservation pricing, the newest BigQuery model specifically intended to add predictability to your spend.
The BigQuery Model
In order to understand what your costs are likely to be, it’s important to understand how BigQuery is architected. Google generally prices a service in a way that matches how it consumes resources under the hood.
The key concept here is that BigQuery and other recent data storage systems separate storage from compute. This means that you pay one cost for the amount of data storage you’re using and another cost for the compute resources you consume to query it. There are lots of other benefits to this scheme, but it can complicate your budgeting model.
Whenever you use compute power on GCP, you are essentially renting idle CPU cores—thousands and thousands of them—for the time you are running the query. Google chooses the most convenient place for the query to run. This means that running multi-region is actually cheaper; Google may route your query to any server in any data center it owns. BigQuery is also built so that a query can jump between places in a data center as it progresses through stages. In fact, it can jump to another data center, so even if the center your query is running in goes down, it can move to another.
A side effect of this system distribution is that BigQuery can also take advantage of idle cores to perform normal maintenance operations at no cost to you. Some normal maintenance operations don’t exist in BigQuery at all. BigQuery doesn’t have indexes, so there is no process to rebuild them. It also has no concept of “vacuuming,” which is a sort of database defragmentation that moves blocks around to save space. (A Google employee shared with me that some customers thought their performance would degrade since they were never charged for vacuuming. Google had been doing automatic reclustering for quite a while, but hadn’t thought to announce it.)
BigQuery Cost Models
Before you can figure out how much your BigQuery bill is going to be, you should understand the way in which Google charges for it. Throughout these sections, I will talk about the model, but I’ll refrain from giving the actual pricing. Google has a habit of changing costs on a regular basis, although they change models less frequently.
For example, Google only published a flat-rate model with a minimum of 500 slots. Recently, they have begun offering lower flat-rate minimums, and I would expect this trend to continue. As a result, I suggest you consult the live BigQuery documentation for current pricing.
Storage Pricing
As mentioned earlier, storage and compute for queries are managed separately. As a result of this, you will also be billed for these things separately. In the case of storage, you will be billed directly for the amount of data you have. This data is billed at pennies per gigabyte, with a free monthly tier limit of 10 GB.
(It’s worth noting that Google uses the binary form of gigabyte, often called “gibibyte.” This represents 2^30 bytes, not 10^9 bytes.)
Google also offers “long-term storage,” which is charged at half price. (In Chapter 15, we’ll go over the storage tiers; the Google Cloud Storage equivalent of this level is “nearline.”) Any table that you do not modify for 90 days is placed into long-term storage. As soon as you touch the table in any material way, either by altering it, inserting data, or streaming data, it is moved back to regular storage and the regular price goes back into effect.
You may want to take advantage of long-term storage by loading all your lookup tables at the beginning and leaving them static, but in practice it may be difficult to account for this just to save a penny here or there. If you have large amounts of static data, that is, historical datasets, you will probably end up taking advantage of this discount without specifically preparing for it.
Loading data from Cloud Storage into BigQuery doesn’t cost anything. As soon as it arrives in BigQuery, you will begin to pay the storage price for it. Similarly, copying a table is free, but you will then pay for the copy at the storage rate. Note: Streaming data is not free. One cost optimization we’ll discuss later in the chapter is choosing carefully when to stream.
On-Demand Pricing
On-demand pricing is the default model used by BigQuery. In this model, you pay by “bytes processed.” This number is not the same as bytes returned to you—it’s whatever the query needs to access in order to return all the data.
On the bright side, cached queries don’t cost anything. So once you run a query, you don’t have to worry about being charged for it if it is run over and over again. This is useful in user analytics scenarios where the user may be refreshing or revisiting the report and would ordinarily get the same data. (It runs a lot faster too.)
You may have already noticed that when you write a query, BigQuery estimates how much data that query will return. You can translate this directly into how much that particular query will cost.
Google allows 1 monthly terabyte of query processing data for free. After that, you are charged per terabyte. Two caveats: One, the minimum query size is 10 MB. If you run a lot of tiny queries, you may use more data than you intend. Two, since you are charged for data processing, if you cancel a query or apply a row limit to it, you will still be charged.
Flat-Rate Pricing
Flat-rate pricing is offered primarily as a path to cost predictability. In this model, you purchase a certain number of “slots,” which are used to execute your query. You are charged a flat monthly rate for the number of slots you make available.
While this has the advantage of being predictable, it creates another challenge, namely, knowing how many slots a particular query will consume. Roughly speaking, slots are a unit of computational power combining CPU, RAM, and memory, and BigQuery’s query processor will determine the optimum number for maximum parallelization. Slots are requested by BigQuery based on the number of stages in the query.
When you run a query in the UI, you will see the number of stages the query is using to get the results. Each stage will then request the number of slots it deems necessary. If a query stage requests more slots than you have allocated, additional units will queue until slots become available.
This means that flat-rate pricing can also cause performance degradation under heavy load, as all slots become occupied by simultaneous queries in flight. This may be preferable over an unpredictably high cost under heavy volume.
BigQuery Reservations
BigQuery Reservations is the newest model for managing cost. In essence, it combines both the flat-rate model and the on-demand model, allowing for both predictable spend and unlimited capacity within the same organization.
Commitments
With the introduction of reservations, it became possible to use a GCP administration project to directly reserve slots with a monthly or annual commitment. You can make multiple commitments for different purposes or departments. This enables you to budget in an enterprise-scale environment and create different reservations for each use case. You can also take the same commitment and use it as you would have a regular flat-rate plan. However, there are additional benefits to commitments.
Reservations
Once you have created a commitment, you can split its slots up into separate pools called “reservations.” When you first make a commitment, you will get a single reservation called default, with zero slot assigned. This means it will behave as a regular flat-rate plan. You can then add more reservations with specific departments or use cases in mind. For example, your finance team may need 200 slots for its daily usage, so you could create a reservation named “finance” and assign 200 slots.
Idle slots will automatically be shared across the full commitment. So if you’ve reserved 200 slots to “finance” out of a full capacity of 1000 and no one else is actively using the system, that reservation will be permitted to use the full commitment.
Assignments
Assignments are how you attach specific projects (or full organizations) to a reservation. BigQuery provides two types of job assignments to segregate load: QUERY and PIPELINE. QUERY is your standard slot processing as would have been used in a flat-rate plan. PIPELINE is for batch loading. Using these three concepts, you can ensure full predictability of your costs while constraining usage appropriately such that an individual department or process can’t hog all of your resources.
Cost Optimization
You can see why cost is such an integral part of using BigQuery. If you are only running small workloads, you may be able to run exclusively in the free tier and never worry about this. Even if you are running in the sub-terabyte range, your costs will generally be fairly manageable. But petabyte workloads are not uncommon for BigQuery, and at that level you will want to be fairly aggressive about cost management. Reservations are a great tool to keep costs predictable, but there are also plenty of things you can do to optimize your costs.
Annualization
Both flat-rate and reservation-based pricing are discounted if you make an annual commitment, as opposed to a monthly one. If you are already seeking cost predictability, it probably makes sense to take the extra step to make it on an annual basis once you have begun moving your workloads to BigQuery.
Partitioned Tables
You will see the recommendation for partitioned tables appear in several places, as they perform better and allow for logical access to only the ranges that you need. They are less expensive for the same reason—you will be charged only for the range that the query accesses.
As an example, if you are typically accessing data on a daily basis, you can query the partition just for the current date. No data stored in the other partitions will be accessed at all. In the non-partitioned version of the query, it would hit every row in the entire table only to filter by the same date range.
Loading vs. Streaming
Loading data to BigQuery is free. Streaming, on the other hand, is billable. We’ll talk more about the use cases for loading or streaming, but as a rule of thumb, prefer loading unless real-time availability is required.
In a scenario where you have a NoSQL data store that needs an analytics back end, you may be streaming data solely to query it. Or you may have a real-time logging solution that is immediately piped to BigQuery for analysis. In these cases, you will still want to stream; the cost is just something to be aware of in these cases.
Query Writing
This may seem obvious, but avoid SELECT * in all cases. Besides the fact that it is poor practice for consuming services, it is especially costly in a column-based store such as BigQuery.
When you request unnecessary columns either by using * or explicitly naming them, you immediately incur the additional cost of scanning those columns. This adds up quickly. As with any SQL-based systems, request only the data you need.
Google also recommends “SELECT * EXCEPT” to return columns using a negative filter, but I would also discourage this. This creates the same unpredictability in returns, and if another user adds a large column, those queries immediately become more expensive.
The row-based equivalent of this is the LIMIT operator, designed to only return a certain number of rows maximum. In relational systems, it’s often used in combination with OFFSET for paging. In BigQuery, using LIMIT does nothing to affect the number of bytes processed, as it is applied after all rows in the table have been scanned. (Note that there are some exceptions to this rule when using clustered tables.)
Check Query Cost

Picture of query data estimate
Google Cloud Platform Budget Tools
Google Cloud Platform Pricing Calculator
Screenshot of the pricing calculator
To use the calculator, plug in a descriptive name (for your reference only), the amount of storage it uses, and the amount of query processing data you think you will need. The calculator will use the prevailing rate and come back with an estimate.
For flat-rate pricing, you simply give it the number of slots you intend to reserve, and it will give you the rate. I would say that if you are really planning on spending a huge amount of money on this and you already know this, contact Google directly, get a sales representative, and negotiate some discounts. You may be able to obtain a lower rate than what the calculator returns.
Setting On-Demand Limits
The brute-force method of limiting your costs, even when using an on-demand model, is to set your own custom quotas. Effectively, you treat it as a traditional fixed-capacity system—when the allocation runs out, BigQuery no longer works until the next day starts in Pacific Time.
This is a good approach if your cost sensitivity outweighs your availability needs. It is also good if you know roughly how much processing your average workload should use, and you would want to restrict any unusual usage anyway. Neither of these models will be effective if you have any external users of your system or if stakeholders need potentially continuous access to the system.
You can also create a hybrid model, where you use one project with quotas set for some users and another project with shared access to the datasets and no quotas. In a scenario this complex, you should probably move to the reservations system unless your budget restrictions are so strict that you don’t want to purchase even the smallest commitment.
Usage per day
Usage per user per day
Once a user hits their quota, they can no longer run queries until the next day. As mentioned earlier, if the project quota itself is hit, BigQuery stops working altogether until midnight Pacific the following day.
If you use this as well as the pricing calculator, you can obtain pricing predictability without using flat-rate or reservation pricing. As a trade-off, availability may be too much of a sacrifice to make.
Setting a Reservations Quota
Reservations comes with a new type of quota, which is the total number of slots permitted by a reservation. If you intend to allow multiple users to reserve slots, you can use this quota to set that upper limit.
You are only billed for the commitments you actually make, but this will allow you to set a price ceiling based on your budget.
Loading Billing Information to BigQuery
When you need very fine-grained control of your billing information for BigQuery or other Google Cloud services, the best option is to export your bill into BigQuery itself and analyze it there. An example of this would be when you want to bill usage back to a client or another internal department.
To do this, go to Billing in the cloud console, and click “Billing export” on the left tab. This will open a window that allows you to edit your export settings. This will default to a BigQuery export page. Specify the project you want to export and choose a dataset in that project to receive the exports. Save this and you should see “Daily cost detail” showing that it is enabled with a green checkbox.
If you have multiple billing accounts and/or projects, you can go to each and enable the feature. From this point forward (no historical data is retrieved), a table in this dataset will begin to receive your billing data. Don’t look right away; it takes some time for the results to appear.
The results will show up in a table of the form gcp_billing_export_v1_, followed by some hex values. You can immediately inspect your data usage. Of note are the service.description, cost, credits, and usage.units. Especially be sure to add the credits field (it will be a negative number) to show what you will actually be charged, if you are running against a free trial or other offset programs.
The Google documentation for this process is quite good, should you need further information.1
Summary
Measuring the cost of BigQuery can be challenging. Using an on-demand pricing model ensures you only pay for what you use, but cost variability can be high. Unpredictable spend can be difficult for enterprise organizations to understand and manage. You can increase cost predictability as a trade-off to efficiency or availability, but you should understand the equations at play before making a decision. Reservations allow you to get the best of both worlds. Regardless of how you structure your costs, some simple rules of thumb can help you to optimize your usage of BigQuery. Google provides tools to measure and limit spend; you may wish to use these to measure ongoing costs.
This concludes Part 1 of the book. In the first four chapters, you learned about the advantages of BigQuery over traditional data warehouses and how to design your BigQuery warehouse to optimally service your organization. You also learned how to prepare a migration or new data load into your newly built warehouse and how to understand the cost over time. In the next part, we will learn how to load, stream, and transform data from myriad sources into your new warehouse. We’ll discuss how to set up pipelines for both relational and unstructured data and how to ensure your warehouse is populated with all the data your organization needs.