1.1 Malicious Attacks
With the remarkable advances in computer technologies, our social, financial and professional existences become increasingly digitized, and governments, healthcare and military infrastructures rely more on computer technologies. They, meanwhile, present larger and more lucrative targets for malicious attacks [81]. A malicious attack is an attempt to forcefully abuse or take advantage of a computer system or a network asset. This can be done with the intent of stealing personal information (logins, financial data, even electronic money), or to reduce the functionality of a target computer. According to statistics, worldwide financial losses due to malicious attacks averaged $12.18 billion per year from 1997 to 2006 [50] and increased to $110 billion between July 2011 and the end of July 2012 [167].
Typical malicious attacks include viruses, worms, Trojan horses, spyware, adware, phishing, spamming, rumors, and other types of social engineering. Since the first computer virus surfaced in the early 1980s, malicious attacks has developed into thousands of variants that differ in infection mechanism, propagation mechanism, destructive payload, and other features [51].
Malware, short for “malicious software”, is a broad term that refers to a variety of malicious programs designed to compromise computers and devices in several ways, steal data, bypass access controls, or cause harm to the host computers. Malware comes in a number of forms, including viruses, worms, Trojans, spyware, adware, rootkits and more.
Social Engineering is the art of getting users to compromise information systems, where the attackers use human interaction (i.e., social skills) to obtain or compromise information about an organization or its computer systems. Instead of technical attacks on systems, social engineers target humans with access to information, manipulating them into divulging confidential information or even into carrying out their malicious attacks through influence and persuasion. Technical protection measures are usually ineffective against this kind of attack. Social engineering attacks are multifaceted and include physical, social and technical aspects, which are used in different stages of the actual attack. Pretexting, Phishing and Baiting are the most common social engineering tactics.
1.2 Examples of Malicious Attacks
ILOVEYOU is considered one of the most virulent computer virus ever created. The virus managed to wreck havoc on computer systems all over the world, causing damages totaling in at an estimate of $10 billion. Ten percent of the world’s Internet-connected computers were believed to have been infected. It was so bad that governments and large corporations took their mailing system offline to prevent infection. The virus used social engineering to get people to click on the attachment; in this case, a love confession. The attachment was actually a script that poses as a TXT file. Once clicked, it will send itself to everyone in the user’s mailing list and proceed to overwrite files with itself, making the computer unbootable.
- CryptoLocker [119] is a form of Trojan horse ransomware targeted at computers running Windows. It uses several methods to spread itself, such as email, and once a computer is infected, it will proceed to encrypt certain files on the hard drive and any mounted storage connected to it with RSA public key cryptography. Figure 1.1 illustrates the infection chain of CryptoLocker. While it is easy enough to remove the malware from the computer, the files will still remain encrypted. The only way to unlock the files is to pay a ransom by a deadline. If the deadline is not met, the ransom will increase significantly or the decryption keys deleted. The ransom usually amount to $400 in prepaid cash or bit coin. From data collected from the raid, the number of infections is estimated to be 500,000, with the number of those who paid the ransom to be at 1.3%, amounting to $3 million [176].
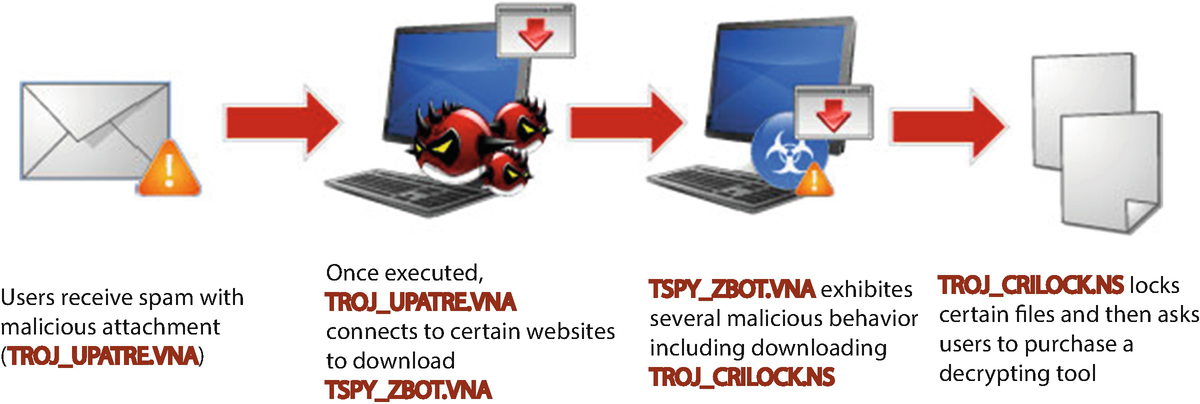 Fig. 1.1
Fig. 1.1CryptoLocker infection chain [6]
Code Red first surfaced on 2001. The worm targeted computers with Microsoft IIS web server installed, exploiting a buffer overflow problem in the system. It leaves very little trace on the hard disk as it is able to run entirely on memory, with a size of 3569 bytes. Once infected, it will proceed to make a hundred copies of itself but due to a bug in the programming, it will duplicate even more and ends up eating a lot of the systems resources. It will then launch a denial of service attack on several IP address, famous among them the website of the White House. It also allows backdoor access to the server, allowing for remote access to the machine. It was estimate that it caused $2 billion in lost productivity. A total of 1–2 million servers were affected.
Conficker is a worm for Windows that made its first appearance in 2008. It infects computers using flaws in the OS to create a botnet. The malware was able to infect more than 9 millions computers all around the world, affecting governments, businesses and individuals. It was one of the largest known worm infections to ever surface causing an estimate damage of $9 billion. The worm works by exploiting a network service vulnerability that was present and unpatched in Windows. Once infected, the worm will then reset account lockout policies, block access to Windows update and anti-virus sites, turn off certain services and lock out user accounts among many. Then, it proceeds to install software that will turn the computer into a botnet slave and scareware to scam money off the user.
Mydoom surfacing in 2004, was a worm for Windows that became one of the fastest spreading email worm since ILOVEYOU. The worm spreads itself by appearing as an email transmission error and contains an attachment of itself. Once executed, it will send itself to email addresses that are in a user’s address book and copies itself to any P2P program’s folder to propagate itself through that network. The payload itself is twofold: first it opens up a backdoor to allow remote access and second it launches a denial of service attack on the controversial SCO Group. It was believed that the worm was created to disrupt SCO due to conflict over ownership of some Linux code. It caused an estimate of $38.5 billion in damages and the worm is still active in some form today.
Flashback is one of the Mac malware. The Trojan was first discovered in 2011. A user simply needs to have Java enabled. It propagates itself by using compromised websites containing JavaScript code that will download the payload. Once installed, the Mac becomes part of a botnet of other infected Macs. More than 600,000 Macs were infected, including 274 Macs in the Cupertino area, the headquarters of Apple.
1.3 Propagation Mechanism of Malicious Attacks
As we can see from the above examples of malicious attacks, a malicious attack propagation starts from one or few hosts and quickly infects many other hosts. For example, the ILOVEYOU worm attached in Outlook Mails mailed itself to all addresses on the host’s mailing list. The Code Red performed network scanning and propagated to IP addresses connected to the host. In order to fight against malicious attacks, it is important for cyber defenders to understand malicious attack behavior, such as membership recruitment patterns, the size of botnets, distribution of bots, especially the propagation mechanism of malicious attacks.
In the first stage, the malware developer creates one or more fake profiles and infiltrates them into the social network. The purpose of these fake profiles is to make friends with as many real OSN users as possible. Infiltration has been shown to be an effective technique for disseminating malicious content in OSNs such as Facebook [22].
In the second stage, the malware developer uses social engineering techniques to create eye-catching web links that trick users into clicking on them. The web links, which are posted on the fake users’ walls, lead unsuspecting users to a web page that contains malicious content. A user simply needs to visit or “drive by” that web page, and the malicious code can be downloaded in the background and executed on the user’s computer without his/her knowledge. When security flaws are absent [198], malware creators resort to social engineering techniques to get assistance from users to activate the malicious code.
In the third stage, after a user is infected, the malware also posts the eye-catching web link(s) on the user’s wall to “ecruit” his/her friends. If a friend clicks on the link(s) and, as a result, unknowingly executes the malware, the friend’s computer and profile will become infected and the propagation cycle continues with his/her own friends.

Example of Trojan malware propagation in online social networks [55]
A susceptible node is a node that is vulnerable to malicious attack but otherwise “healthy”. We use S(t) to denote the number of susceptible nodes at time t.
An infected node is a node that became infected and may potentially infect other nodes. We use I(t) to denote the number of infected nodes at time t.
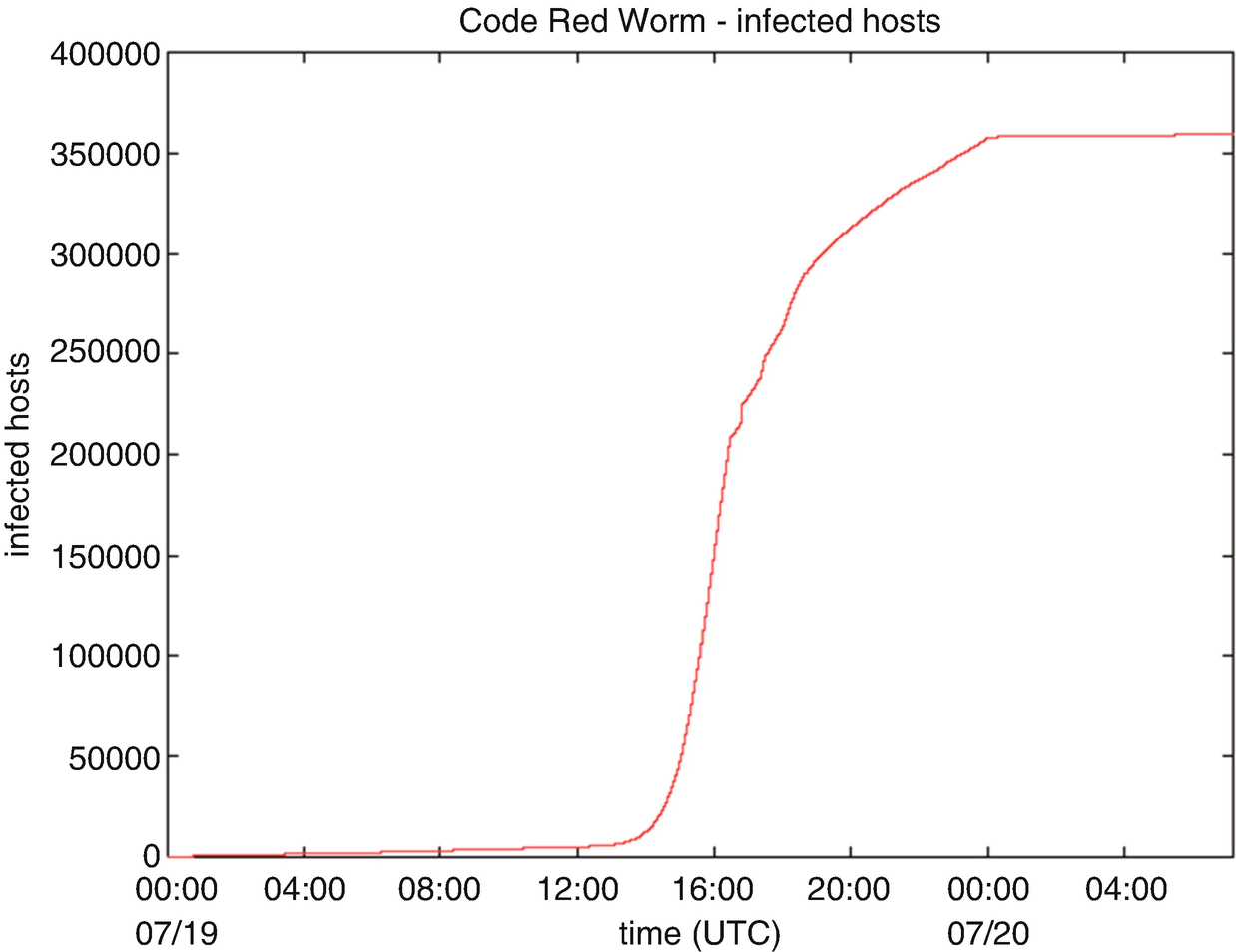
Observed Code Red propagation (from www.Caida.org)
Many other models are derivations of this basic SI form. For example, the Susceptible-Infected-Recovered (SIR) models the propagation that node can get recovered or immune from the infectious state and if a node get recovered it will never again become susceptible. The Susceptible-Infected-Susceptible (SIS) models the propagation in which recovered node can become susceptible again.
1.4 Source Identification of Malicious Attack Propagation
From both practical and technical aspects, it is of great significance to identify propagation sources of malicious attacks. Practically, it is important to accurately identify the ‘culprit’ of the malicious attack for forensic purposes. Moreover, seeking the malicious attack as quickly as possible can find the causation of the attack, and therefore, mitigate the damages. Technically, the work in this field aims at identifying the sources of malicious attacks based on limited knowledge of network structures and the states of a small portion of nodes. In academia, traditional identification techniques, such as IP trace back [156] and stepping-stone detection [157], are not sufficient to seek the sources of malicious attacks, as they only determine the true source of packets received by a destination. In the propagation of malicious attacks, the source of packets is almost never the source of the malicious attack propagation but just one of the many propagation participants [191]. Methods are needed to find propagation sources higher up in the application level and logic structures of networks, rather than in the IP level and packets.
Identifying the source of a malicious attack is an extremely desirable but challenging task, because of the large-scale of networks and the limited knowledge of hosts’ infection statuses. In general, only a small fraction of hosts can be observed. Thus, the main difficulty is to develop tractable estimators that can be efficiently implemented, and that perform well on multiple topologies.
In the past few years, researchers have proposed a series of methods to identify the diffusion sources of malicious attacks. The first widely discussed research on this subject has been done by Shah and Zaman [161]. In social networks, Shah and Zaman introduced rumor centrality of a node as the number of distinct ways a rumor can spread in the network starting from that node. They showed that the node with maximum rumor centrality is the Maximum Likelihood Estimator of the rumor source if the underlying graph is a regular tree. They studied also the detection performance for irregular geometric trees, small-word networks and scale-free networks. This method assumes that we know all the connections between nodes and additionally the infection states of all nodes. Researchers [84, 85, 146, 200] later relaxed some of these constraints since their algorithm requires information about state of not every node, but only about some fraction of nodes called observers.
Based on the types of observations on the attacked underlying network, the approaches of identifying malicious attack sources can be divided into three main categories: the complete observation based source detection, the snapshot based source detection, and the detector/sensor based source detection. The first category requires a complete observation of the attacked network after a certain time of the malicious propagation. The second category requires the snapshot (partial observation) of the attacked network at a certain time instance. The third category needs to monitor a small set of nodes but all the time in the attacked network. Regardless of the above division, researchers considered also different epidemic models [24, 202], spreading at weighted or time-varying graphs [11, 23, 84, 163] and multi-source detection problems [58, 68, 86].
1.5 Outline and Book Overview
Networks portray a multitude of interactions among network assets. Researchers have found that unsolicited malicious attacks spread extremely fast through influential spreaders [42]. Hence, analyzing the influence of network hosts and identifying the most efficient ‘spreaders’ in a network becomes an important step towards identifying the propagation source of malicious attacks and restraining the propagation. Indeed, the propagation of malicious attacks is in an epidemic way (one host can infect multiple hosts simultaneously). However, previous methods in measuring the influence of network hosts focus on the dissemination of information from one host to only one other host. In this book, we explore different influence measures and their application of capturing influential nodes in the epidemics.
Restraining the propagation of malicious attacks in a underlying network has long been an important but difficult problem. Currently, there are mainly two types of methods: (1) blocking malicious attacks at the most influential users or community bridges, and (2) spreading the corresponding countermeasures to restrain malicious attacks. Given a fixed budget in the real world, how can we manage different methods working together to optimize the restraint of the propagation of malicious attacks. In this book, we explore the strategy of different methods working together and their equivalence, so as to find out a better strategy to restrain the propagation of malicious attacks.
The underlying networks are often of time-varying topology. For example, in human contact networks, the neighborhood of individuals moving over a geographic space evolves over time, and the interaction between the individuals appears/disappears in online social network websites (such as Facebook and Twitter) [151]. Indeed, the spreading of malicious attacks is affected by duration, sequence, and concurrency of contacts among nodes [27, 170]. Then, can we model the way that malicious attack spreads in time-varying networks? Can we estimate the probability of an arbitrary node being infected by a malicious attack? How do we detect the propagation source of a malicious attack in time-varying networks? Can we estimate the infection scale and infection time of the malicious attack?
Malicious attacks often emerge from multiple sources. However, current methods mainly focus on the identification of a single attack source in networks. A few approaches are proposed for identifying multiple attack sources but they all suffer from extremely high computational complexity, which is not practical to be adopted in real-world networks. In this book, we will answer the following questions corresponding to multi-source identification. How many sources are there? Where did the diffusion emerge? When did the diffusion start?
Another critical challenge in this research area is the scalability issue. Current methods generally require scanning the whole underlying network of malicious attack spreading to locate attack sources. However, real-world networks of malicious attack diffusion are often of a huge scale and extremely complex structure. Thus, it is impractical to scan the whole network to locate the attack sources. We develop efficient approaches to identify attack sources by taking the structural features of networks and the diffusion patterns of malicious attacks into account, and therefore address the scalability issue.
- Part I: Malicious Attack Propagation
- 1.
Primary knowledge of modeling malicious attack propagation.
- 2.
Spreading influence analysis of network hosts in the propagation of malicious attacks.
- 3.
Restraining the propagation of malicious attacks.
- 1.
- Part II: Source Identification of Malicious Attack Propagation
- 1.
Source identification under complete observations: a maximum likelihood (ML) source estimator.
- 2.
Source identification under snapshots: a sample path based source estimator.
- 3.
Source identification under sensor observations: a Gaussian source estimator.
- 1.
- Part III: Critical Research Issues in Source Identification
- 1.
Identifying propagation source in time-varying networks.
- 2.
Identifying multiple propagation sources.
- 3.
Identifying propagation source in large-scale networks.
- 1.