One slow evening when the Middleton Theater was showing Weekend at Bernie’s, the manager told Alex to answer the phone and give a new name for the movie each time a caller asked what was playing. The first call went like this:
“What’s showing tonight?”
“We’re showing Weekend at Fred’s at 7:30 and 9:45.”
*Pause* Caller asks again: “What’s that title??”
“Weekend at Ned’s.”
The caller’s voice got louder, but Alex kept going, under the manager’s supervision: “Wait. Weekend at Jed’s.” *Pause* “Wait; I’m sorry. It’s Weekend at Zed’s.”
Finally, the caller’s voice got very loud, and he slammed the receiver down. With cheeks of beet red, Alex looked at the silent earpiece for a second.
“Nice!” the manager said. “That was hilarious! Let’s go back to the normal way now. You never know when Jerry [the regional supervisor] might be calling to test us.”
Here we have an example of influence under a simple chain of command: Alex worked for the manager, who worked for Jerry. A dominance hierarchy like this is pretty normal for social primates. “The weak are often exploited by the powerful,” writes primatologist Joan Silk. “Strong alliances and lasting bonds are formed; dynasties are established, but are occasionally toppled.” Over the past thirty years in Gombe National Park, Tanzania, where Jane Goodall worked, male chimpanzees have been observed to compete over rank and otherwise pursue alliances with high-ranking males. High rank means priority mating access. It also means you can often prevent lower-ranking males from mating at all. Females, on the other hand, have more stable dominance relationships and tend to move up in rank with age, so there is not as much turnover. Daughters frequently rank just below their mothers.
Turnover in dominance is the essence of human drama. “Preferment goes by letter and affection,” complains Iago in Shakespeare’s Othello, “and not by old gradation, where each second stood heir to th’ first.” Yet dominance networks are just one of many networks of influence at every scale in human society. All people have insiders and peripheral people in their social network—what sociologists call strong and weak ties. We saw in chapter 1 that during their lifetime, a Hadza individual might interact with a thousand or so people but that the number of close trading ties is much smaller, perhaps on the order of six individuals. Those weak ties become essential at a larger scale of society, where gift exchange becomes prone to hierarchy. In antiquity, chiefs competed for supporters through lavish feasts, violence, or precious gifts, which evolved into networks of trade that came to pervade the ancient world. By 2000 BC, trade vessels crisscrossed the Indian Ocean from East Asia to southern Europe and Africa. Centuries later, the first Polynesians were trading obsidian across thousands of miles of the South Pacific. In the Near East, trade networks—copper from Oman, lapis lazuli from Afghanistan, and blue cotton clothes from Harappa—became foundations for the earliest state societies.
Trade networks manifested into hierarchies of place, from hinterlands to regional markets, to major cities. In the Bronze Age Mediterranean, trade in olive oil, wine, and fish sauce turned otherwise-obscure islands such as Thera into important hubs of maritime trade because of their centrality relative to other Aegean seaports. These hubs were vulnerable, however. If your seaport volcanically erupts sky-high—as happened to Thera in the sixteenth century BC—you’re done.
More than a spatial metaphor, networks are everywhere in human life, directing the flow of wealth, information, and ultimately influence. In every modern organization, some network structure directs the evolution of information. Across human cultures, most households have had an inherent hierarchy, reinforced by daily rituals such as eating meals together. A hierarchy usefully funnels expert information from specialists into a community.
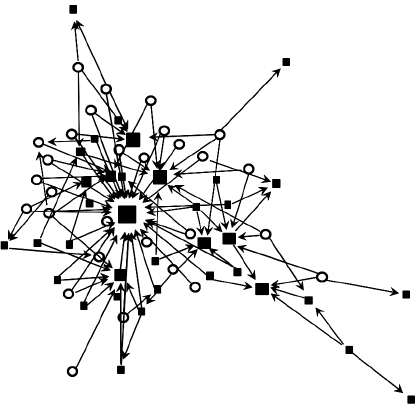
Joe Henrich and James Broesch asked people on the lovely Yasawa Islands of the South Pacific to identify their village experts in specific knowledge areas, such as medicinal plants, fishing, or growing yams. Representing each person as a node, they drew an arrow pointing to the expert named by each person. Like a trade network with hubs, each of their network diagrams revealed a hub-and-spoke pattern. The figure shows their network for yam experts, with the size of nodes being proportional to the number of individuals who selected that person as a model. Different shapes represent individuals’ villages.
A hub-and-spoke hierarchy is a natural outcome of many forms of network growth, including the early Internet. In the late 1990s, network scientists witnessed the Internet evolve into an elegant hierarchical form, in which most hyperlinks pointed to a minority of websites, and most websites had few links. Without external design, the World Wide Web evolved into something like an airline network, with hubs that allowed any two sites to be linked with just a dozen clicks.
Online social networks also evolved in this way for some platforms but not for others. It depends if you’re investing real time or just posing as a website. US teenagers average only 150 Facebook friends each, which, as we saw in chapter 1, is the same as what Robin Dunbar proposed as the stable number of social relationships a person has on average. The distribution in the number of real friends, or Facebook friends, follows a normal distribution, or bell curve, with a distinct average number of friends per person.
Unlike real friendships, Twitter exhibits proportionate advantage, with no characteristic average. The more Twitter followers you have, the more you gain in the future, with almost no constraint. With over 90 million followers, Katy Perry herself follows only 170 people. Like the Internet, Twitter has evolved a highly hierarchical distribution in the number of followers per user. Known as a log-normal distribution, it is the same form of distribution for the number of links per website, the number of followers per Twitter user, or the number of citations per scientist.
Even networks within the Internet evolved hierarchically. Try this game. Look up any subject on Wikipedia and then click on the first hyperlinked word in the Wikipedia entry on that subject. In a relatively short number of clicks, you’ll wind up at the topic of philosophy. Starting at the Wikipedia page for “Kermit the Frog,” for example, the first hyperlinked word on the page is “Muppets.” On the Muppets page, the first hyperlinked word is “ensemble cast,” which then leads to “cast members,” then “actor,” followed by “character,” “representation,” “semantics,” “linguistics,” “science,” and “knowledge.” A few more steps lead to “logic” in the Wikipedia series on “philosophy.” As all roads eventually lead to philosophy, we might say it has indirect influence on a vast tree of knowledge.
Online, though, people follow a lot more than Wikipedia. When everyone professes to be an expert at something or other, people struggle to discriminate fake news from real news, science from political punditry, and accomplished careers from professional celebrities. Many blame social media, where everyone has a voice, for flattening what had been a hierarchical information network, paradoxically rendering it simultaneously siloed and globalized.
There is an important distinction to make between social relationship media, such as Facebook and Snapchat, and follower-broadcast platforms such as a blog or Twitter. A Twitter account with just a handful of direct followers can successfully feed information to thousands. Competing against all that content from humans and their chatbots, the magnitude of which we discuss in chapter 9, smart bloggers know how to scaffold their limited direct influence into mainstream media. A prominent political blogger, interviewed in 2016, revealed his strategy for getting his hashtags picked up first by the Drudge Report, followed by a mention on Fox News, and then, with luck, discussion on CNN. In other words, he didn’t need millions of followers himself; he just needed what New York University researchers Flaviano Morone and Hernán Makse called “collective influence”—a handful of direct followers who ultimately feed the information to thousands.
Collective influence is not just how many friends are connected but also how many followers of followers, followers of followers of followers, and so on. It captures how true influencers can be all but invisible in terms of node connectivity. Take a major corporation, for instance. Among the half-million e-mails among 156 employees of Enron, the Houston-based energy company bankrupted by internal corruption in 2001, neither Jeff Skilling nor Ken Lay—the two Enron leaders—featured prominently in the message network in terms of node degree or PageRank metric. Having collective influence, without being highly connected, was used in their defense. During the Enron trial of 2006, Lay told the prosecutor that he was part of important decisions only “if I was reachable. Quite often, if I was traveling, they had to go ahead and kind of do whatever they could do.” As we know, this “invisibility” defense failed miserably. Both were convicted, with Skilling receiving twenty-four years in federal prison (later reduced to fourteen years). Lay died three months before his sentencing.
A decade later, nefarious online networks elude authority not necessarily by network structure but instead by aggregate behavior. For example, network researchers at the University of Miami used text analysis to examine the European social media site Kontakte, identifying almost two hundred Islamic State of Iraq and Syria aggregates, with over a hundred thousand followers, marked by hashtags such as #khilafah or #fisyria. They showed that each aggregate evaded authority by disappearing for a while and then being reincarnated with a new handle. As the new versions often became bigger than the original, they adapted to efforts to shut them down, continuing the cycle of acquiring followers, disappearing, and then reincarnating.
These aggregates were hub-and-spoke networks, which tend to be resilient against the random loss of followers but vulnerable to targeted attack on their most highly connected nodes. Targeting collective influence, however, works even better. By removing a mere 6 percent of the most influential nodes, Morone and Makse, whom we mentioned above, broke up a Twitter network into isolated, impotent fragments. You’d have to remove twice as many high-degree nodes for the same impact. Their collective influence algorithm was also good at ignoring “fake influencers” on Twitter because high degree is easier to fake then high collective influence. We can see the new potential for online cat-and-mouse coevolution between users and policers.
Since collective influence assumes hierarchy, though, it will be less effective at disrupting highly embedded social networks. For a pair of nodes, embeddedness is just their number of mutual friends. For a whole network, embeddedness is the average of that number across all possible pairs of nodes. Unlike hierarchy, embedded networks have multiple alternate routes: if you sever my link with you, I can just reach you through our mutual friend. We keep our friends’ friends close, too.
If Enron’s Skilling and Lay had been on Facebook, perhaps their special business relationship might have been identified by a simple algorithm. Researchers at Facebook use embeddedness versus another metric, called dispersion, to identify special partners in a network. Dispersion is the number of a pair’s mutual friends who can be reached only through the pair. A bride and groom, say, could have both high embeddedness and high dispersion if their respective families know each other only through the married couple. In fact, these two metrics alone—embeddedness and dispersion—can identify a social media user’s spouse almost two-thirds of the time and also distinguish close family members from friends about three-quarters of the time. Change in embeddedness versus dispersion can even predict the probability that partners will separate.
Whereas hierarchical networks are good at sorting information, nonhierarchical ones, such as small groups, feed into large populations and encourage the random drift of information. Drift is good for fake news and conspiracy theories. Poor at filtering, highly embedded social networks also favor the indiscriminate spread of information through redundancy. People frequently need to hear the message a few times, or at least sense that most of their friends have adopted the idea, before they adopt it themselves. This is what the pop-up message “eighteen people are looking at this hotel right now” wants you to feel.
Researchers have quantified this kind of online conformity among sixty million Facebook users, who were shown two different kinds of banner ads encouraging people to vote. One version showed all their friends who had voted, and the other had the same message but not showing any friends. What is surprising is not that the social “nudge” helped but how little it helped. The social message boosted the rate of clicking “I Voted” by only 2 percent over the information-only message. Across a range of studies, other nudging efforts rarely increase response rates by more than 10 percent, and usually less.
Yet changing the actual social network can transform the spread of ideas. This was shown by an online innovation game played by pairs of players who were connected within a network. In each round of the game, a random pair of connected players was shown an image of an object and asked to provide, independently, a name for it. If the two names matched, the pair won points. In the next round, each played again with new partners from their network. As players saw which names were scoring points in their network, they would often pick those successful names. After multiple rounds of play in a heavily embedded network, where only neighbors were connected, different names became locally popular in the network. With random pairings, however—effectively a nonhierarchical, global network—a single name would ultimately sweep across the entire population, crushing all variation.
One lesson from the random network is that the idea that sweeps through the population is nothing special; any idea can win in the next run of games. Also, the source of the influence—whoever first invented the winning name—could be anyone. If this sounds like online memes, it should; over the years, Microsoft’s Duncan Watts has shown this in experiments and models: if people make decisions based primarily on conformity, then a random innovation can occasionally sweep through the social network like an unexpected wildfire.
The critical mass effect also means that passive slacktivists are not useless after all. Slacktivists catalyze the spread of innovation, online or on the ground. They tend to be informed, if not proactive. MIT sociologists showed that in rural India, “passive participants” were actually crucial to microfinancing being adopted by a village, even when the village leader was on board and promoting microfinancing among the village women.
Though eighty years old, network studies have only recently stormed the social sciences. In just a couple generations, the trend in behavioral science has shifted from the classically rational omniscient actors to flawed strategists of behavioral economics, to the social butterflies of network science. In their book Connected, Nicholas Christakis and James Fowler argued that everything from happiness to nonstop giggling spreads through social influence. Their most consequential claim has been that obesity spreads this way. As Christakis implied in a TED talk, becoming obese carries the personal responsibility of influencing others, helping to make them obese.
But what if it’s not influence at all? Christakis and Fowler showed that a person is 57 percent more likely to be obese if a friend is obese, but does this mean they must have influenced one another? What if they live in the same neighborhood, facing the same food choices, all of them fast foods? The clustering of like-minded people is called homophily. What if people are merely self-aggregating into “echo chambers” of like-minded people through polarized social media networks and personalized news feeds? In digital markets, advertisers target their messages to niche categories of customers rather than broadcasting the same message to all. In academia, ResearchGate and Academia.com introduce researchers to like-mined peers, clustering similar academic interests in the network without necessarily involving influence. In business, LinkedIn serves the similar purpose of aggregating as opposed to influencing people.
Usually if we have only a static network, we’ll never be able to distinguish true influence from homophily. We need to observe people actually influencing each other, not just clumping together in a social network. One of the best studies was done some years ago by Sinan Aral, who obtained time-stamped data on a network of twenty-seven million social media friends who downloaded the same instant messaging app from Yahoo! called Go. Plotting adoptions in the network through time, plus matching characteristics of users to distinguish similar preferences from social influence, Aral and his colleagues found that about half the adoptions of Go were the result of influence and the other half of homophily.
To really identify influence, however, the gold standard is to observe it in real time. This brings us back to chimpanzees. In the Budongo Forest of Uganda, where the Sonso chimpanzee community has been studied since 1990, chimpanzees regularly used leaves to collect water—enough so that primatologists considered it their universal behavior. Yet on November 14, 2011, an alpha male made a sponge out of moss to get water out of a water hole. As he invented this new technique, he was observed by a dominant female. Over the next six days, seven other chimps from the community made and used moss sponges. Primatologist Catherine Hobaiter caught it all on video. She and her colleagues drew a network diagram with arrows to represent one chimp observing another doing a behavior, along with an indication of when each individual chimpanzee adopted the new behavior. Social influence is visible in the time-elapsed network of each chimp’s conversion to moss sponging following direct observation of another chimp doing it.
Real-time analysis was the missing element in mass observation. Soon it will be much easier to identify genuine social influence. Vedran Sekara and his Danish colleagues got downright microscopic by following a hundred first-year university students through Bluetooth on their mobile phones, which can report physical proximity of users within ten meters of each other. These Bluetooth data showed the same people meeting in the same places—classrooms—on weekdays and engaging in recreational exploration on weekends. Nothing revolutionary there, but by updating their colocation data every five minutes, it got a bit better (or creepier, depending on your perspective): identifiable groups emerged from the Bluetooth data revealing people colocating for a time, even if their meetings were ephemeral. Within each group, certain core members attended all or most (75 percent or more) of the meetings, whereas others attended only occasionally (often less than 10 percent of the time).
Now there is not only a network to analyze but also change in that network. That’s all Sekara’s team needed to predict that a meeting would soon take place if two core members of a group had just gotten together. Also, the closer a meeting approached, the faster the text messages and phone calls were traded among core members, giving researchers a way of predicting when a meeting would occur. Can we predict more than this—say, conflicts rather than meetings? We’ll come to this in chapter 10, but first, let’s look at prediction in general.