
All living things possess an astonishing degree of organization. From the simplest single-celled organism to the largest mammal, millions of reactions and events must be coordinated precisely for life to exist. This coordination is directed by DNA, which is the hereditary blueprint of the cell.
DNA is made up of repeated subunits of nucleotides. Each nucleotide has a five-carbon sugar, a phosphate, and a nitrogenous base. Take a look at the nucleotide below.
The name of the pentagon-shaped sugar in DNA is deoxyribose. Hence, the name deoxyribonucleic acid. Notice that the sugar is linked to two things: a phosphate and a nitrogenous base. A nucleotide can have one of four different nitrogenous bases:
adenine—a purine (double-ringed nitrogenous base)
guanine—a purine (double-ringed nitrogenous base)
cytosine—a pyrimidine (single-ringed nitrogenous base)
thymine—a pyrimidine (single-ringed nitrogenous base)
Any of these four bases can attach to the sugar. As we’ll soon see, this is extremely important when it comes to the message of the genetic code in DNA.
The nucleotides can link up in a long chain to form a single strand of DNA. Here’s a small section of a DNA strand.

The nucleotides themselves are linked together by phosphodiester bonds between the sugars and the phosphates. This is called the sugar-phosphate backbone of DNA and it serves as a scaffold for the bases.
Each DNA molecule consists of two strands that wrap around each other to form a long, twisted ladder called a double helix. The structure of DNA was brilliantly deduced in 1953 by three scientists: Watson, Crick, and Franklin.
Now let’s look at the way two DNA strands get together. Again, think of DNA as a ladder. The sides of the ladder consist of alternating sugar and phosphate groups, while the rungs of the ladder consist of pairs of nitrogenous bases.

The nitrogenous bases pair up in a particular way. Adenine in one strand always binds to thymine (A–T or T–A) in the other strand. Similarly, guanine always binds to cytosine (G–C or C–G). This predictable matching of the bases is known as base pairing.
The two strands are said to be complementary. This means that if you know the sequence of bases in one strand, you’ll know the sequence of bases in the other strand. For example, if the base sequence in one DNA strand is A–T–C, the base sequence in the complementary strand will be T–A–G.
The two DNA strands run in opposite directions. You’ll notice from the figure above that each DNA strand has a 5’ end and a 3’ end, so-called for the carbon that ends the strand (i.e., the fifth carbon in the sugar ring is at the 5’ end, while the third carbon is at the 3’ end). The 5’ end has a phosphate group, and the 3’ end has an OH, or “hydroxyl,” group. The 5’ end of one strand is always opposite to the 3’ end of the other strand. The strands are therefore said to be antiparallel.
The DNA strands are linked by hydrogen bonds. Two hydrogen bonds hold adenine and thymine together, and three hydrogen bonds hold cytosine and guanine together.
Before we go any further, let’s review the base pairing in DNA:
Adenine pairs up with thymine (A–T or T–A) by forming two hydrogen bonds.
Cytosine pairs up with guanine (G–C or C–G) by forming three hydrogen bonds.
The order of the four base pairs in a DNA strand is the genetic code. Like a special alphabet in our cells, these four nucleotides spell out thousands of recipes. Each recipe is called a gene. The human genome has around 20,000 genes.
The recipes of the genes are spread out among the millions of nucleotides of DNA, and all of the DNA for a species is called its genome. Each separate chunk of DNA in a genome is called a chromosome.
Prokaryotes have one circular chromosome, and eukaryotes have linear chromosomes. In eukaryotes, the DNA is further structured, likely since linear chromosomes are more likely to get tangled. To keep it organized, the DNA is wrapped around proteins called histones, and then the histones are bunched together in groups called a nucleosome. Not all DNA is wound up equally, because it must be unwound in order to be read. How tightly DNA is packaged depends on the section of DNA and also what is going on in the cell at that time. When the genetic material is in a loose form in the nucleus, it is called euchromatin, and its genes are active, or available for transcription. When the genetic material is fully condensed into coils, it is called heterochromatin, and its genes are generally inactive. Situated in the nucleus, chromosomes contain the recipe for all the processes necessary for life, including passing themselves and their information on to future generations. In this chapter, we’ll look at precisely how they accomplish this.
We said in the beginning of this chapter that DNA is the hereditary blueprint of the cell. By directing the manufacture of proteins, DNA serves as the cell’s blueprint. But how is DNA inherited? For the information in DNA to be passed on, it must first be copied. This copying of DNA is known as DNA replication.
Because the DNA molecule is twisted over on itself, the first step in replication is to unwind the double helix by breaking the hydrogen bonds. This is accomplished by an enzyme called helicase. The exposed DNA strands now form a y-shaped replication fork.

Now each strand can serve as a template for the synthesis of another strand. DNA replication begins at specific sites called origins of replication. Because the DNA helix twists and rotates during DNA replication, another class of enzymes, called DNA topoisomerases, cuts, and rejoins the helix to prevent tangling. The enzyme that performs the actual addition of nucleotides to the freshly built strand is DNA polymerase. But DNA polymerase, oddly enough, can add nucleotides only to the 3’ end of an existing strand. Therefore, to start off replication, an enzyme called RNA primase adds a short strand of RNA nucleotides called an RNA primer. After replication, the primer is degraded by enzymes and replaced with DNA so that the final strand contains only DNA.
During DNA replication, one DNA strand is called the leading strand, and it is made continuously. That is, the nucleotides are steadily added one after the other by DNA polymerase. The other strand—the lagging strand—is made discontinuously. Unlike the leading strand, the lagging strand is made in pieces of nucleotides known as Okazaki fragments. Why is the lagging strand made in small pieces?
Nucleotides are added only in the 5’ to 3’ direction since nucleotides can be added only to the 3’ end of the growing chain. However, when the double-helix is “unzipped,” one of the two strands is oriented in the opposite direction—3’ to 5’. Because DNA polymerase doesn’t work in this direction, the strand needs to be built in pieces. You can see in the figure below that the leading strand is being created toward the opening of the helix and the helix continually opens ahead of it to accommodate it. The lagging strand is built in the opposite direction of the way the helix is opening, so it can build only until it hits a previously built stretch. Once the helix unwinds a bit more, it can build another Okazaki fragment, and so on. These fragments are eventually linked together by the enzyme DNA ligase to produce a continuous strand. Finally, hydrogen bonds form between the new base pairs, leaving two identical copies of the original DNA molecule.

When DNA is replicated, we don’t end up with two entirely new molecules. Each new molecule has half of the original molecule. Because DNA replicates in a way that conserves half of the original molecule in each of the two new ones, it is said to be semiconservative.
An interesting problem is that a few bases at the very end of a DNA molecule cannot be replicated because DNA polymerase needs space to bind template DNA. This means that every time replication occurs, the chromosome loses a few base pairs at the end. The genome has compensated for this over time, by putting bits of unimportant (or at least less important) DNA at the ends of a molecule. These ends are called telomeres. They get shorter and shorter over time.
Many enzymes and proteins are involved in DNA replication. The ones you’ll need to know for the AP Biology Exam are DNA helicase, DNA polymerase, DNA ligase, topoisomerase, and RNA primase:
Helicase unwinds our double helix into two strands.
DNA Polymerase adds nucleotides to an existing strand.
Ligase brings together the Okazaki fragments.
Topoisomerase cuts and rejoins the helix.
RNA primase catalyzes the synthesis of RNA primers.
The reason that we know that the DNA is the inheritable material is because of several key experiments. The first turning point was achieved by Avery, MacLeod, and McCarty. They isolated various cellular components from a dead virulent strain of bacteria. Then they followed up on a previous experiment by Griffiths and added each of these cellular components to a stain of living non-virulent bacteria. Only the DNA component of the deadly bacteria was able to change the second bacteria into a deadly strain capable of reproducing. This means that DNA must be responsible for passing traits and is inheritable.
The next important experiment was done by Hershey-Chase. They used bacteriophages, which are a special type of virus. They labeled the protein parts of some viruses with radiolabeled sulfur and they labeled the DNA parts of other viruses with radiolabeled phosphorus. When the viruses infected bacteria, only the labeled DNA was inside, but they were still able to replicate and make progeny viruses. Thus they proved that only DNA is required to pass on information. The protein was not required.
DNA’s main role is directing the manufacture of molecules that actually do the work in the body. DNA is just the recipe book, not the chef or the meal. When a DNA recipe is used, scientists say that that DNA is expressed.
The first step of DNA expression is to turn it into RNA. The RNA is then sent out into the cell and often gets turned into a protein. Proteins are the biggest group of “worker-molecules,” and most expressed DNA turns into proteins. These proteins, in turn, regulate almost everything that occurs in the cell.
The process of making an RNA from DNA is called transcription, and the process of making a protein from an RNA is called translation. In eukaryotic cells, transcription takes place in the nucleus (where the DNA is kept), and translation takes place in the cytoplasm.
Obviously, in prokaryotes, both occur in the cytoplasm because prokaryotes don’t contain a nucleus; this allows transcription and translation to occur at the same time.
The flow of genetic information, the Central Dogma of Biology, is therefore:

Before we discuss transcription of RNA, let’s talk about its structure. Although RNA is also made up of nucleotides, it differs from DNA in three ways.
RNA is single-stranded, not double-stranded.
The five-carbon sugar in RNA is ribose instead of deoxyribose.
The RNA nitrogenous bases are adenine, guanine, cytosine, and a different base called uracil. Uracil replaces thymine as adenine’s partner.
Here’s a table to compare DNA and RNA. Keep these differences in mind—the testing board loves to test you on them.
|
DIFFERENCES BETWEEN DNA AND RNA |
||
|
|
DNA (double-stranded) |
RNA (single-stranded) |
|
Sugar |
deoxyribose |
ribose |
|
Bases |
adenine guanine cytosine thymine |
adenine guanine cytosine uracil |
There are three main types of RNA: messenger RNA (mRNA), ribosomal RNA (rRNA), and transfer RNA (tRNA). All three types of RNA are key players in the synthesis of proteins:
Messenger RNA (mRNA) is a temporary RNA version of a DNA recipe that gets sent to the ribosome.
Ribosomal RNA (rRNA), which is produced in the nucleolus, makes up part of the ribosomes. You’ll recall from our discussion of the cell in Chapter 5 that the ribosomes are the sites of protein synthesis. We’ll see how they function a little later on.
Transfer RNA (tRNA) shuttles amino acids to the ribosomes. It is responsible for bringing the appropriate amino acids into place at the appropriate time. It does this by reading the message carried by the mRNA.
There is also another class of RNA, called interfering RNAs, or RNAi. These are small snippets of RNA that are naturally made in the body or intentionally created by humans. These interfering RNAs, called siRNA and miRNA, can bind to specific sequences of RNA and mark them for destruction. This will be discussed more later in this chapter. Now that we know about the different types of RNA, let’s see how they direct the synthesis of proteins.
Transcription involves making an RNA copy of a bit of DNA code. The initial steps in transcription are similar to the initial steps in DNA replication. The obvious difference is that, whereas in replication we end up with a complete copy of the cell’s DNA, in transcription we end up with only a tiny specific section copied into an mRNA. This is because only the bit of DNA that needs to be expressed will be transcribed. If you wanted to make a cake, but your cookbook couldn’t leave your vault (a.k.a. the nucleus), you wouldn’t copy the entire cookbook! You would copy only the recipe for the cake.
Since each recipe is a gene, transcription occurs as-needed on a gene-by-gene basis.
The exception to this is prokaryotes because they will transcribe a recipe that can be used to make several proteins. This is called a polycistronic transcript. Eukaryotes tend to have one gene that gets transcribed to one mRNA and translated into one protein. Our transcripts are monocistronic.
Transcription involves three phases: initiation, elongation, and termination. As in DNA replication, the first initiation step in transcription is to unwind and unzip the DNA strands using helicase. Transcription begins at special sequences of the DNA strand called promoters. You can think of a promoter as a docking site or a runway. We will talk about how promoters are involved in regulating transcription later in the chapter.

Because RNA is single-stranded, we have to copy only one of the two DNA strands. The strand that serves as the template is known as the antisense strand, the non-coding strand, minus-strand, or the template strand. The other strand that lies dormant is the sense strand, or the coding strand.

Just as DNA polymerase builds DNA, RNA polymerase builds RNA, and just like DNA polymerase, RNA polymerase adds nucleotides only to the 3’ side, therefore building a new molecule from 5’ to 3’. This means that RNA polymerase must bind to the 3’ end of the template strand first (which would be the 5’ end of future mRNA).
RNA polymerase doesn’t need a primer, so it can just start transcribing the DNA right off the bat. The promoter region is considered to be “upstream” of the actual coding part of the gene. This way the polymerase can get set up before the bases it needs to transcribe, like a staging area before an official parade starting point. The official starting point is called the start site.
When transcription begins, RNA polymerase travels along and builds an RNA that is complementary to the template strand of DNA. It is just like DNA replication except when DNA has an adenine, the RNA can’t add a thymine since RNA doesn’t have thymine. Instead, the enzyme adds a uracil.
Once RNA polymerase finishes adding on nucleotides and reaches the termination sequence, it separates from the DNA template, completing the process of transcription. The new RNA is now a transcript or a copy of the sequence of nucleotides based on the DNA strand. Note that the freshly synthesized RNA is complementary to the template strand, but it is identical to the coding strand (with the substitution of uracil for thymine).
In prokaryotes, the mRNA is now complete, but in eukaryotes the RNA must be processed before it can leave the nucleus.
In eukaryotes, the freshly transcribed RNA is called an hnRNA (heterogeneous nuclear RNA) and it contains both coding regions and noncoding regions. The regions that express the code that will be turned into protein are exons. The noncoding regions in the mRNA are introns.

The introns—the intervening sequences—must be removed before the mRNA leaves the nucleus. This process, called splicing, is accomplished by an RNA-protein complex called a spliceosome. This process produces a final mRNA that is shorter than the transcribed RNA. The way that a transcript is spliced can vary, and alternative splicing variants will result with different exons included.
In addition to splicing, a poly(A) tail is added to the 3’ end and a 5’ GTP cap is added to the 5’ end.
Translation is the process of turning an mRNA into a protein. Remember, each protein is made of amino acids. The order of the mRNA nucleotides will be read in the ribosome in groups of three. Three nucleotides is called a codon. Each codon corresponds to a particular amino acid. The genetic code is redundant, meaning that certain amino acids are specified by more than one codon.
The mRNA attaches to the ribosome to initiate translation and “waits” for the appropriate amino acids to come to the ribosome. That’s where tRNA comes in. A tRNA molecule has a unique three-dimensional structure that resembles a four-leaf clover:

One end of the tRNA carries an amino acid. The other end, called an anticodon, has three nitrogenous bases that can complementarily base pair with the codon in the mRNA. Usually, the normal rules of base pairing are set in stone, but tRNA anticodons can be a bit flexible when they bind with a codon on an mRNA, especially the third nucleotide in an anticodon. The third position is said to experience wobble pairing. Things that don’t normally bind will pair up, like guanine and uracil.
Transfer RNAs are the “go-betweens” in protein synthesis. Each tRNA becomes charged and enzymatically attaches to an amino acid in the cell’s cytoplasm and “shuttles” it to the ribosome. The charging enzymes involved in forming the bond between each amino acid and tRNA require ATP.

Translation also involves three phases: initiation, elongation, and termination. Initiation begins when a ribosome attaches to the mRNA.
What does the ribosome do? It helps the process along by holding everything in place while the tRNAs assist in assembling polypeptides.
Ribosomes contain three binding sites: an A site, a P site, and an E site. The mRNA will shuffle through from A to P to E. As the mRNA codons are read, the polypeptide will be built. In all organisms, the start codon for the initiation of protein synthesis is A–U–G, which codes for the amino acid methionine. Proteins can have AUGs in the rest of the protein that code for methionine as well, but the special first AUG of an mRNA is the one that will kick off translation. The tRNA with the complementary anticodon, U–A–C, is methionine’s personal shuttle; when the AUG is read on the mRNA, methionine is delivered to the ribosome.
Addition of amino acids is called elongation. Remember that the mRNA contains many codons, or “triplets,” of nucleotide bases. As each amino acid is brought to the mRNA, it is linked to its neighboring amino acid by a peptide bond. When many amino acids link up, a polypeptide is formed.
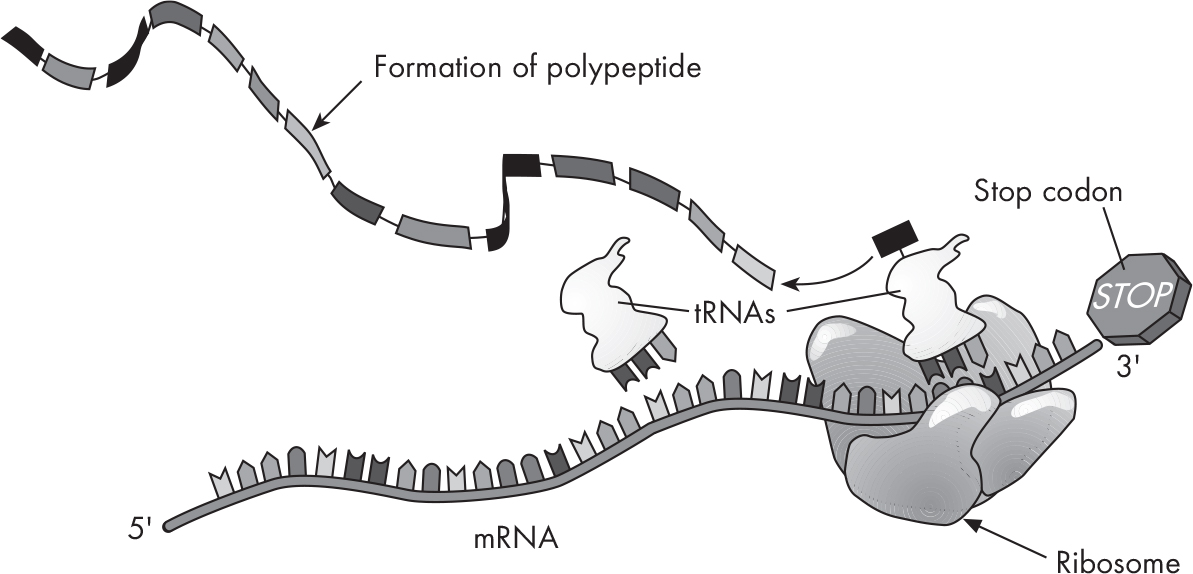
How does this process know when to stop? The synthesis of a polypeptide is ended by stop codons. A codon doesn’t always code for an amino acid; there are three that serve as a stop codon. Termination occurs when the ribosome runs into one of these three stop codons.
How about a little review?
In transcription, mRNA is created from a particular gene segment of DNA.
In eukaryotes, the mRNA is “processed” by having its introns, or noncoding sequences, removed. A 5’ cap and a 3’ tail are also added.
Now, ready to be translated, mRNA proceeds to the ribosome.
Free-floating amino acids are picked up by tRNA and shuttled over to the ribosome, where mRNA awaits.
In translation, the anticodon of a tRNA molecule carrying the appropriate amino acid base pairs with the codon on the mRNA.
As new tRNA molecules match up to new codons, the ribosome holds them in place, allowing peptide bonds to form between the amino acids.
The newly formed polypeptide grows until a stop codon is reached.
The polypeptide or protein folds up and is released into the cell.

What controls gene transcription, and how does an organism express only certain genes? Regulation of gene expression can occur at different times. The largest point is before transcription, or pre-transcriptional regulation. It can also occur post-transcriptionally or post-translationally.
The start of transcription requires DNA to be unwound and RNA polymerase to bind at the promoter. The process is usually a bit more complicated than that because there is a group of molecules called transcription factors that can either encourage or inhibit this from happening. This is often accomplished by making it easier or more difficult for RNA polymerase to bind or to move to the start site.
Sometimes changes to the packaging of DNA will alter the ability of the transcription machinery to access a gene. These types of changes are called epigenetic changes, and they usually occur through a modification to a histone protein that is involved in winding up the DNA. A tighter wrap around a histone makes the DNA more difficult to access and a looser wrap makes it easier to access.
The following examples are famous models of regulation. You do not need to memorize them, but you should be familiar with the big picture of how things can come together to regulate transcription. Most of what we know about gene regulation comes from our studies of E. coli. In bacteria, a cluster of genes can be under the control of a single promoter; these functioning units of DNA are called operons. One of the best-understood operons is the lac operon, which controls expression of the enzymes that break down (catabolize) lactose.
The operon consists of four major parts: structural genes, promoter genes, the operator, and the regulatory gene:
Structural genes code for enzymes needed in a chemical reaction. These genes will be transcribed at the same time to produce particular enzymes. In the lac operon, three enzymes (beta galactosidase, galactose permease, and thiogalactoside transacetylase) involved in digesting lactose are coded for.
The promoter gene is the region where the RNA polymerase binds to begin transcription.
The operator is a region that controls whether transcription will occur; this is where the repressor binds.
The regulatory gene codes for a specific regulatory protein called the repressor. The repressor is capable of attaching to the operator and blocking transcription. If the repressor binds to the operator, transcription will not occur. On the other hand, if the repressor does not bind to the operator, RNA polymerase moves right along the operator and transcription occurs. In the lac operon, the inducer, lactose, binds to the repressor, causing it to fall off the operator, and “turns on” transcription.
The two diagrams on the next page show the lac operon when lactose is absent (A) and when lactose is present (B).

Other operons, such as the trp operon, operate in a similar manner except that this mechanism is continually “turned on” and is “turned off” only in the presence of high levels of the amino acid, tryptophan. Tryptophan is a product of the pathway that codes for the trp operon. When tryptophan combines with the trp repressor protein, it causes the repressor to bind to the operator, which turns the operon “off,” thereby blocking transcription. In other words, a high level of tryptophan acts to repress the further synthesis of tryptophan.
The following two diagrams show the trp operon when tryptophan is absent (C) and when tryptophan is present (D).

Post-transcriptional regulation occurs when the cell creates an RNA, but then decides that it should not be translated into a protein. This is where RNAi comes into play. RNAi molecules can bind to an RNA via complementary base pairing. This creates a double-stranded RNA (remember RNA is usually single stranded). When a double-stranded RNA is formed, this signals to some special destruction machinery that the RNA should be destroyed. This would prevent it from going on to be translated.
Post-translational regulation can also occur if a cell has already made a protein, but doesn’t yet need to use it. This is an especially common regulation for enzymes because when the cell needs them, it needs them ASAP. It is easier to make them ahead of time and then just turn them on or off as needed. This can involve binding with other proteins, phosphorylation, pH changes, cleavage, etc. Remember, even if a protein is made, it might need other things to be made (or not made) in order for the protein to be functional.
How does a tiny, single-celled egg develop into a complex, multicellular organism? By dividing, of course. The cell changes shape and organization many times by going through a succession of stages. This process is called morphogenesis.
When an egg is fertilized by a sperm, it forms a diploid cell called a zygote.
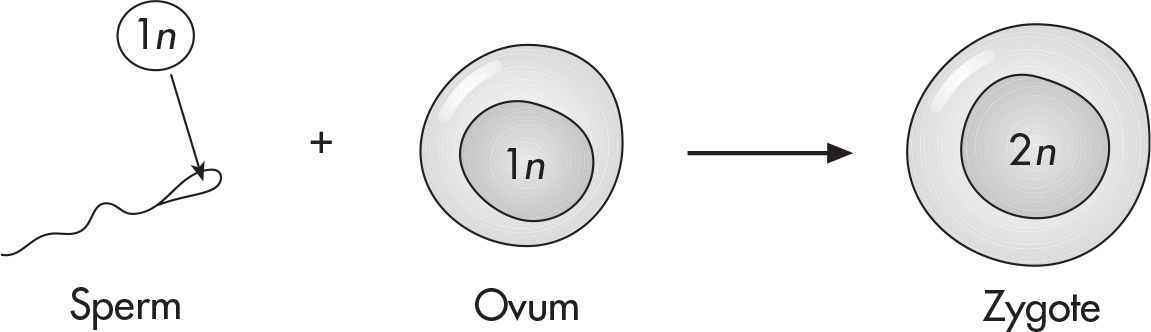
Fertilization triggers the zygote to go through a series of cell divisions. As these occur, the embryo becomes increasingly differentiated, or specialized. An undifferentiated cell is like a blank slate—it can become any type of cell. Once a cell begins to specialize, it is limited in its future options.
In order for a cell to differentiate, it must change. Certain genes will be expressed, and other genes might be turned off. Cells called organizers release signals that let each cell know how they should develop. As an over-simplified example, a cell destined to become a muscle might have an increase in things that make it flexible, while something destined to become bone might have a decrease in those things. Once the change has been made, the future muscle cell can’t change its mind and become a bone cell. In other words, cells don’t typically go backwards, or dedifferentiate.
The early genes that turn certain cells in the early embryo into future-this or future-that are called homeotic genes. A subset of homeotic genes are called Hox genes. Timing is essential for the induction (activation) of these genes. Exactly the right bit of the embryo must be modified at exactly the right time. Otherwise, the embryo may develop with the brain in the wrong place, with too many limbs, or with limbs on only one side of the body. Severely damaged embryos will typically stop developing and die.
An interesting additional tool that the developing embryo uses is apoptosis, or programmed cell death. Certain bits of the developing embryo are used as a scaffold for development (like the cells that used to exist in the spaces between your fingers and toes), and when they are no longer necessary, those cells undergo apoptosis. Think of it like an eraser coming along and erasing the webbing tissue between fingers and toes.
A mutation is an error in the genetic code. Mutations can occur because DNA is damaged and cannot be repaired or because DNA damage is repaired incorrectly. Damage can be caused by chemicals or radiation. It can also occur when a DNA polymerase or an RNA polymerase makes a mistake. DNA polymerases have proofreading abilities, but RNA polymerases do not. This is because RNA is only a temporary molecule and if a mistake is made, it is not usually as problematic. DNA is important now and in the future, since it is passed on from cell to cell in somatic cells and from parent to offspring. If the mistake occurs in a germline cell, that will become a gamete. Mistakes in DNA can last forever.
It is important to know that just having an error in the DNA is not a problem unless that gene is expressed AND the error causes a change in the gene product (RNA or protein). Think of it like an error in a recipe in a cookbook; an error won’t harm anyone unless the recipe is actually made AND the error causes a big change in the recipe. As we will see, a mutation can cause different types of effects. Often, the result will be a change to the gene product and the phenotype of the individual. This can be beneficial, detrimental, or neutral to the individual depending on the specific mutation that occurs.
Base substitution (point) mutations result when a single nucleotide base is substituted for another. There are three different types of point mutations:
Nonsense mutations cause the original codon to become a stop codon, which results in early termination of protein synthesis.
Missense mutations cause the original codon to be altered and produce a different amino acid.
Silent mutations happen when a codon that codes for the same amino acid is created and therefore does not change the corresponding protein sequence.
Gene rearrangements involve DNA sequences that have deletions, duplications, inversions, and translocations.
Insertions and deletions result in the gain or loss, respectively, of DNA or a gene. They can involve either the addition (insertion) or removal (deletion) of as little as a single base or much larger sequences of DNA. Insertions and deletions may have devastating consequences during protein translation because the introduction or deletion of bases often results in a change in the sequence of codons used by the ribosome (called a frameshift mutation) to synthesize a polyprotein.

In this example, the insertion of an additional cytosine nucleotide resulted in a frameshift and a premature stop codon.
Duplications can result in an extra copy of genes and are usually caused by unequal crossing-over during meiosis or chromosome rearrangements. This may result in new traits because one copy of the gene can maintain the original function and the other copy may evolve a new function.
Inversions can result when changes occur in the orientation of chromosomal regions. This may cause harmful effects if the inversion involves a gene or an important regulatory sequence.
Translocations occur when two different chromosomes (or a single chromosome in two different places) break and rejoin in a way that causes the DNA sequence or gene to be lost, repeated, or interrupted.
Transposons are gene segments that can cut/paste themselves throughout the genome. The presence of a transposon can interrupt a gene and cause errors in gene expression.
Bacteria and viruses are common pathogens. Bacteriophages are viruses that infect bacteria. Viruses require a host to replicate and sometimes lyse the host cell during infection.
Bacteria, common pathogens, are prokaryotes that come in many shapes and sizes. They can infect many things, and sometimes they cause harm and sometimes they do not. You may have heard of “gut bacteria” before; this is a special colony of bacteria that lives inside each one of us. It helps us with some digestion and makes some things we need. We have a mutualistic relationship with our gut bacteria.
Bacteria divide by fission; however, this does not increase their genetic diversity. Instead, they can perform conjugation with other bacterial cells and swap some of their DNA. Genetic variety among bacteria is leading to increased antibiotic resistance.
Viruses are nonliving agents capable of infecting cells. Why are viruses considered nonliving? They require a host cell’s machinery in order to replicate. A virus consists of two main components: a protein capsid and genetic material made of DNA or RNA, depending on the virus. Viruses are all very specific in which type of cells they infect, and the thing infected by a virus is called a host.
Viruses have one goal: replicate and spread. In order to do this, a virus needs to make more genome and make more capsid. They then assemble together into new viral particles.
The viral genome carries genes for building the capsid and anything else the virus needs that the host cannot provide. Sometimes, if two viruses infect the same cell, there will be mixing of the genomes, especially if the viruses have genomes split between several chromosome-like segments. A new virus particle might emerge that is a blend of the two viruses.
A commonly studied virus is a bacteriophage (a virus that infects bacteria). Bacteriophages undergo two different types of replication cycles, the lytic cycle and the lysogenic cycle. In the lytic cycle, the virus immediately starts using the host cell’s machinery to replicate the genetic material and create more capsid proteins. These spontaneously assemble into mature viruses and cause the cell to lyse, or break open, releasing new viruses into the environment. In the lysogenic cycle, the virus incorporates itself into the host genome and remains dormant until it is triggered to switch into the lytic cycle. A virus can hide in the genome of a host cell for a very long time. During this time, the cell may divide and replicate the virus as well. By the time the lytic cycle is triggered, the virus may have been replicated many many times as the cell hosting it divides.
When a virus excises from a host genome (becomes unintegrated), it sometimes accidentally takes some of the bacterial cell’s DNA with it. Then, the host DNA accidentally gets packaged into new viral particles with the viral genome. The next cell that gets infected is not only getting infected with the viral genome, but also with that stolen chunk of bacterial DNA. If that chunk held a gene for something like antibiotic resistance, the next cell that gets infected will gain that trait. The transfer of DNA between bacterial cells using a lysogenic virus is called transduction.
Viruses that infect animals do not have to break their way out of the cell the same way that a bacteriophage does. Since animals cells don’t have a cell wall, viruses often just “bud” out of the membrane in a process similar to exocytosis. When a virus does this, it becomes enveloped by a chunk of host cell membrane that it takes with it. Viruses with a lipid envelope are called enveloped viruses.
Retroviruses like HIV are RNA viruses that use an enzyme called reverse transcriptase to convert their RNA genomes into DNA so that they can be inserted into a host genome. RNA viruses have extremely high rates of mutation because they lack proofreading mechanisms when they replicate their genomes. This high rate of mutation will create lots of variety, which makes these viruses difficult to treat. They evolve quickly, as drug-resistant mutations become naturally selected. New drugs must constantly be identified to treat the resistance.
Viruses can sometimes change quickly if two viruses infect the same cell. The gene segments of each virus can recombine and mix with each other and package into mixed viruses that are a chimera of the original two viruses. This can increase genetic variation among viruses.
Scientists have learned how to harness the Central Dogma in order to research and cure diseases. Recombinant DNA is generated by combining DNA from multiple sources to create a unique DNA molecule that is not found in nature. A common application of recombinant DNA technology is the introduction of a eukaryotic gene of interest (such as insulin) into a bacterium for production. In other words, bacteria can be hijacked and put to work as little protein factories. This branch of technology that produces new organisms or products by transferring genes between cells is called genetic engineering.
A few decades ago, it would have taken weeks of tedious experiments to identify and study specific genes. Today, thanks to polymerase chain reaction (PCR), we are able to make billions of identical copies of genes within a few hours. For a PCR, the process of DNA replication is slightly modified. In a small PCR tube, DNA, specifically designed primers, a powerful and heat-resistant DNA polymerase, and lots of DNA nucleotides (As, Cs, Gs, and Ts) are mixed together.
In a PCR machine, or thermocycler, the tube is heated, cooled, and warmed many times. Each time the machine is heated, the hydrogen bonds break, separating the double-stranded DNA. As it is cooled, the primers bind to the sequence flanking the region of the DNA we want to copy. When it is warmed, the polymerase binds to the primers on each strand and adds nucleotides on each template strand. After this first cycle is finished, there are two identical double-stranded DNA molecules. When the second cycle is completed, these two double-stranded DNA segments will have been copied into four. The process repeats itself over and over, creating as much DNA as needed.
Insulin, the protein hormone that lowers blood sugar levels, can now be made for medical purposes by bacteria. Yes, bacteria can be induced to use the universal DNA code to transcribe and translate a human gene! The process of giving bacteria foreign DNA is called transformation.
Genes of interest are first placed into a small circular DNA molecule called a plasmid. Often, a plasmid is predesigned to have some special helpful genes in it, and together, these are called a vector. Plasmid vectors often contain genes for antibiotic resistance and restriction sites. Plasmids and the gene of interest are cut with the same restriction enzyme (restriction enzymes cut DNA at very specific predetermined sequences), creating compatible sticky ends. When placed together, the gene is inserted into the plasmid creating recombinant DNA.
The bacteria are then transformed (given the recombinant DNA to take up). In most AP Biology courses, this is done by the heat shock method.
Not all bacteria will be transformed, but the ones that did not take up the plasmid are not needed. This is where the antibiotic resistance gene on the vector comes in. By growing all bacteria in the presence of an antibiotic, only those with the resistance gene (a.k.a. those that have been transformed) will survive.
Not only has this laboratory technique been used to safely mass-produce important proteins used for medicine, such as insulin, but it also plays an important role in the study of gene expression. A technique similar to transformation is transfection, which is putting a plasmid into a eukaryotic cell, rather than a bacteria cell. This is a bit trickier than transformation. Because eukaryotic cells do not grow like bacteria do, transfection is not as useful for making large quantities of something, but sometimes it is important to use eukaryotic cells.
An important part of DNA technology is the ability to observe differences in different preparations of DNA.
DNA fragments can be separated according to their molecular weight and charge with gel electrophoresis. Because DNA and RNA are negatively charged, they migrate through a gel toward the positive pole of the electrical field. The smaller the fragments, the faster they move through the gel. Restriction enzymes are also used to create a molecular fingerprint. The patterns created after cutting with restriction enzymes are unique for each person because each person’s DNA is slightly different. Some people might have sequences that are cut many times, resulting in many tiny fragments, and others might have sequences that are cut infrequently, producing a few large fragments. When restriction fragments between individuals of the same species are compared, the fragments differ in length because of polymorphisms, which are slight differences in DNA sequences. These fragments are called restriction fragment length polymorphisms, or RFLPs. In DNA fingerprinting, RFLPs produced from DNA left at a crime scene are compared to RFLPs from the DNA of suspects.
An important tool of modern scientists is the process of DNA sequencing. This allows scientists to determine the order of nucleotides in a DNA molecule. By knowing this, scientists could design their own DNA plasmid and use it to study a gene of interest.
nucleotide
five-carbon sugar
phosphate
nitrogenous base
deoxyribose
adenine
guanine
cytosine
thymine
phosphodiester bonds
double helix
Watson, Crick, and Franklin
base pairing
complementary
antiparallel
hydrogen bonds
gene
genome
chromosome
histone
nucleosome
euchromatin
heterochromatin
DNA replication
helicase
replication fork
origins of replication
topoisomerase
DNA polymerase
RNA primase
RNA primer
leading strand
lagging strand
Okazaki fragments
DNA ligase
semiconservative replication
telomeres
Avery, MacLeod, and McCarty
Hershey-Chase
transcription
translation
Central Dogma of Biology
ribose uracil
messenger RNA (mRNA)
ribosomal RNA (rRNA)
transfer RNA (tRNA)
RNA interference (RNAi)/silencing RNA (siRNA)
polycistronic transcript
monocistronic transcript
promoter
antisense/non-coding/template strand
sense/coding strand
RNA polymerase
start site
exons
introns
splicing
spliceosome
poly(A) tail
5’ GTP cap
codon
anticodon
wobble pairing
initiation
elongation
termination
A site, P site, E site
start codon
stop codons
pre-transcriptional regulation
transcription factors
epigenetic changes
operon
structural genes
promoter genes
operator
regulatory gene
inducer
post-transcriptional regulation
post-translational regulation
morphogenesis
zygote
fertilization homeotic genes
Hox genes
mutation
base substitution
nonsense mutation
missense mutation
silent mutation
gene rearrangements
insertions
deletions
frameshift mutation
duplications
inversions
translocations
transposons
bacteria
conjugation
viruses
host
bacteriophage
lytic cycle
lysogenic cycle
transduction
enveloped virus
retrovirus
reverse transcriptase
recombinant DNA
genetic engineering
polymerase chain reaction (PCR)
thermocycler
transformation
plasmid
vector
restriction enzyme
sticky end
transfection
gel electrophoresis
restriction fragment length polymorphism (RFLP)
DNA fingerprinting
DNA sequencing
DNA is the genetic material of the cell.
DNA structure is composed of two antiparallel complementary strands, including:
Deoxyribose sugar and phosphate backbone connected by phosphodiester bonds with nitrogenous bases hydrogen bonded together pointing toward the middle. The two strands are oriented antiparallel with 3’ and 5’ ends and twist into a double helix.
Adenine always pairs with thymine, and guanine always pairs with cytosine.
All the DNA in a cell is the genome. It is divided up into chromosomes, which are divided up into genes that each encode a particular genetic recipe.
DNA replication provides two copies of the DNA for cell division, which involves the following steps:
Helicase begins replication by unwinding DNA and separating the strands at the origin of replication.
Topoisomerases reduce supercoiling ahead of the replication fork.
RNA primase places an RNA primer down on the template strands.
DNA polymerase reads DNA base pairs of a strand as a template and lays down complementary nucleotides to generate a new complementary partner strand.
Replication proceeds continuously on the leading strand.
The lagging strand forms Okazaki fragments, which must be joined later by DNA ligase.
Transcription involves building RNA from DNA.
RNA polymerase reads one of the DNA strands (the antisense/non-coding/template strand) and adds RNA nucleotides to generate a single strand of mRNA that will be identical to the other strand of DNA (the coding/sense strand) except it will have uracil instead of thymine.
mRNA, rRNA, tRNA, and RNAi are all types of RNA that can be created.
mRNA gets processed in eukaryotic cells: introns are removed (spliced out), and a 5’ GTP cap and a 3’ poly(A) tail are added.
Translation occurs in the cytoplasm as mRNA carries the message to the ribosome.
mRNA passes through three sites on the ribosome, the A-site, the P-site, and the E-site.
The mRNA is read in triplets of three nucleotides, called codons. Each tRNA has a region called the anticodon that is complementary to a codon. Sometimes the pairing is not the normal base-pairing. This is called wobble pairing.
When a tRNA binds, it brings the corresponding amino acid to add to the growing polypeptide.
Gene expression is regulated primarily by transcription factors influencing transcription (pre-transcriptional regulation), RNAi after transcription (post-transcriptional regulation), and by various reactions and regulators after translation (post-translational regulation). This regulation is dynamic and can either increase or decrease gene expression, RNA levels, and protein levels according to the needs of the cell.
Mutations can result from changes in the DNA message or the mRNA message.
Mutations can be small (single nucleotide swaps, additions, or deletions) or large (big chunks or entire chromosomes are swapped, duplicated, or deleted).
Some examples of biotechnology are:
recombinant DNA
polymerase chain reaction (PCR)
transformation of bacteria
gel electrophoresis
Bacteria and viruses are common pathogens. Bacteriophages are viruses that infect bacteria. Viruses require a host to replicate and sometimes lyse the host cell during infection.
Answers and explanations can be found in Chapter 15.
1. A geneticist has discovered a yeast cell, which encodes a DNA polymerase that may add nucleotides in both the 5ʹ to 3ʹ and 3ʹ to 5ʹ directions. Which of the following structures would this cell NOT likely generate during DNA replication?
(A) RNA primers
(B) Okazaki fragments
(C) Replication fork
(D) Nicked DNA by topoisomerases
2. A eukaryotic gene, which does not normally undergo splicing, was exposed to benzopyrene, a known carcinogen and mutagen. Following exposure, the protein encoded by the gene was shorter than before exposure. Which of the following types of genetic rearrangements or mutations was likely introduced by the mutagen?
(A) Silent mutation
(B) Missense mutation
(C) Nonsense mutation
(D) Duplication
3. DNA replication occurs through a complex series of steps involving several enzymes. Which of the following represents the correct order beginning with the earliest activity of enzymes involved in DNA replication?
(A) Helicase, ligase, RNA primase, DNA polymerase
(B) DNA polymerase, RNA primase, helicase, ligase
(C) RNA primase, DNA polymerase, ligase, helicase
(D) Helicase, RNA primase, DNA polymerase, ligase
4. If a messenger RNA codon is UAC, which of the following would be the complementary anticodon triplet in the transfer RNA?
(A) ATG
(B) AUC
(C) AUG
(D) ATT
5. During post-translational modification, the polypeptide from a eukaryotic cell typically undergoes substantial alteration that results in
(A) excision of introns
(B) addition of a poly(A) tail
(C) formation of peptide bonds
(D) a change in the overall conformation of a polypeptide
6. Which of the following represents the maximum number of amino acids that could be incorporated into a polypeptide encoded by 21 nucleotides of messenger RNA?
(A) 3
(B) 7
(C) 21
(D) 42
7. A researcher uses molecular biology techniques to insert a human lysosomal membrane protein into bacterial cells to produce large quantities of this protein for later study. However, only small quantities of this protein result in these cells. What is a possible explanation for this result?
(A) The membrane protein requires processing in the ER and Golgi, which are missing in the bacterial cells.
(B) Bacteria do not make membrane proteins.
(C) Bacteria do not use different transcription factors than humans, so the gene was not expressed.
(D) Bacteria do not have enough tRNAs to make this protein sequence.
8. BamHI is a restriction enzyme derived from Bacillus amyloliquefaciens that recognizes short palindromic sequences in DNA. When the enzyme recognizes these sequences, it cleaves the DNA. What purpose would restriction enzymes have in a bacterium like Bacillus?
(A) They are enzymes that no longer have a purpose because evolution has produced better enzymes.
(B) They destroy extra DNA that results from errors in binary fission.
(C) They protect Bacillus from invading DNA due to viruses.
(D) They prevent, or restrict, DNA replication when the cell isn’t ready to copy its DNA.
9. Viruses and bacteria have which of the following in common?
(A) Ribosomes
(B) Nucleic acids
(C) Flagella
(D) Metabolism
10. Griffith was a researcher who coined the term transformation when he noticed that incubating nonpathogenic bacteria with heat-killed pathogenic bacteria produced bacteria that ultimately became pathogenic, or deadly, in mice. What caused the transformation in his experiment?
(A) DNA from the nonpathogenic bacteria revitalized the heat-killed pathogenic bacteria.
(B) Protein from the pathogenic bacteria was taken up by the nonpathogenic bacteria.
(C) DNA from the pathogenic bacteria was taken up by the nonpathogenic bacteria.
(D) DNA in the nonpathogenic bacteria turned into pathogenic genes in the absence of pathogenic bacteria.
11. A biologist systematically removes each of the proteins involved in DNA replication to determine the effect each has on the process. In one experiment, after separating the strands of DNA, she sees many short DNA/RNA fragments as well as some long DNA pieces. Which of the following is most likely missing?
(A) Helicase
(B) DNA polymerase
(C) DNA ligase
(D) RNA primase
Respond to the following questions:
Which topics from this chapter do you feel you have mastered?
Which content topics from this chapter do you feel you need to study more before you can answer multiple-choice questions correctly?
Which content topics from this chapter do you feel you need to study more before you can effectively compose a free response?
Was there any content that you need to ask your teacher or another person about?