Almost every activity in the world now leaves numerous digital traces. What if a „wise king“ or „benevolent dictator“ had real-time access to all the data in the world? Could he take perfect decisions to benefit society? Could he predict the future? Could he control the world’s path? What would be the limits and side effects of such an approach? Or is the attempt to create a digital „crystal ball“ to predict the future and a digital „magic wand“ to control the world a dangerous dream?
Historically, human civilization developed by establishing mechanisms to promote cooperation and social order. One such mechanism is based on the idea that everything we do is seen and judged by God. Bad deeds will be punished, while good ones will be rewarded. This might be seen as one of the mechanisms through which religion has established social order. More recently, the information age has inspired the dream of some keen strategists that we might be able to know everything about the world ourselves, and to shape it as desired. Would it be possible to acquire God-like omniscience and omnipotence fueled by Big Data? There are now hopes and fears that such power lies within the reach of technology and data giants such as Google or Facebook, or secret services such as the CIA or the National Security Agency (NSA). In 2013, CIA Chief Technology Officer Ira “Gus” Hunt1 explained how easy it is for such institutions to gather a great deal of information about each of us:
“You’re already a walking sensor platform… You are aware of the fact that somebody can know where you are at all times because you carry a mobile device, even if that mobile device is turned off. You know this, I hope? Yes? Well, you should… Since you can’t connect dots you don’t have, it drives us into a mode of, we fundamentally try to collect everything and hang on to it forever… It is really very nearly within our grasp to be able to compute on all human generated information.”
Will this massive data-collection process be good for the world, helping us to eliminate terrorism, crime, and other societal ills? Will it allow us to turn our society into a perfect clockwork and overcome the mistakes that people make? Or will so much information create even bigger problems?
4.1 Technology to Empower a “Wise King”?
Imagine you are the president of a country and aim to maximize the welfare of its people. What would you do? You would probably want to prevent financial crashes, economic crises, social problems and wars. You would like to ensure a safe and reliable supply of food, water and energy. You would perhaps try to prevent environmental degradation. You may wish people to be rich, happy and healthy. You may further like to avoid problems such as traffic jams, corruption, and drug abuse. In sum, you would probably like to create a prosperous, sustainable and resilient society.
What would it take to achieve all of this? You would certainly need to take the right decisions and avoid those that would imply harmful, unintended side effects. For each impending decision you would need to know alternative courses of action that could be taken and their associated opportunities and risks. For your country to thrive, you would need to avoid ideological or impulsive decision-making and let data-based evidence guide your actions. In order to have enough information for this type of decision-making, you would need a lot of data about all quantifiable aspects of life and society, and excellent data analysts to interpret it. You might even decide to collect all the data in the world (as much as this can be done), just in case it might be useful one day to counteract threats and crises, or to exploit opportunities that might arise.
In the past, rulers and governments haven’t had this possibility: they often lacked the quality or quantity of data needed to take well-informed decisions. But this is now changing. In recent decades, the processing power of computers has exploded, and the volume of stored data has dramatically increased. Each year, we are now generating as much data in the world as in the entire history of humankind.2 What could we do with all this data?
4.2 A Digital “Crystal Ball”?
Until recently, we have successfully used supercomputers for almost everything, except for understanding our economy, society and politics. Every new car or airplane is designed, simulated and tested on a computer before they are built. Increasingly, the same is true for the research and development of medical drugs. Thus, why shouldn’t we use computers to understand and guide our economy and society, too? In fact, we are moving in this direction. As a minor (yet illustrative) example, computers have been used for traffic control since their early days. In the meantime, also modern production and supply chain management would be inconceivable without computerized control. Already since some time, airplanes are controlled by a majority decision among a few computers, and driverless, computer-controlled cars will soon traverse our streets. In all of these cases, computers do a better job than humans. If they are better pilots, drivers, and chess players, why shouldn’t computers eventually make better policemen, administrators, lawyers, and politicians, too?
Given today’s data volume and computational power, it seems no longer unreasonable to imagine a gigantic computer system that tries to simulate the actions and interactions of all humans globally. In such a digital mirror world our virtual doubles might be even equipped with cognitive abilities and decision-making capacities. If we fed these virtual humans with our own personal data, how similar to us would they behave?3 Would it eventually be possible to create a digital copy of our world, a virtual reality as realistic as life itself?
Recent studies using smartphone data and GPS records suggest that the activity of a person at a particular time can often be forecast with an accuracy of more than 90%.4 Our lives are surprisingly predictable due to our repetitive daily and weekly schedules and routines. It is also possible to determine our personality traits and attributes.5 There are even companies such as Palantir and Recorded Future, which have developed sophisticated tools for predictive analytics and are trying to build a digital “crystal ball”. The military in the USA is engaged in similar projects,6 and it is likely that the same applies to other countries.
Although the prospect of building a digital crystal ball might sound ominous to some, we should carefully discuss it. The potential benefits are obvious, as there are many huge problems that might be solved with such predictive capabilities. The financial crisis has created global losses of at least $15 trillion. Crime and corruption consume about 2–5% of the gross domestic product (GDP) of all nations on earth—about $2 trillion each year. A major influenza pandemic infecting 1% of the world’s population might cause losses of $1–2 trillion per year. The wars post September 11 have cost many trillion dollars. And cybercrime costs more than €750 billion a year in Europe alone.
If a computer simulation of the entire global socio-economic system could produce just a 1% improvement in dealing with these problems, the benefits to society would be already immense. But if the management of smaller complex social systems provides any guide, even an improvement of 10–30% seems possible. Overall, this would amount to savings of more than $1 trillion annually. Even if we had to invest billions in creating such a system, we could see a hundred-fold return on investment nevertheless. Even if the success rates were significantly smaller, this would represent a substantial gain. Thus, a digital crystal ball seems to be a worthwhile investment. But how could one ensure that the world stays on the predicted path, and individual decision-makers don’t mess it up?
4.3 The Digital “Magic Wand”: A Remote Control for Humans?
Whenever we spend time on the Internet, we leave digital traces that are collected by electronic “cookies” and other means, often without our consent. But the more data is generated about us, stored and interpreted, the easier it becomes to find out things about us, which were not intended to be shared. Our computers and smart devices leave unique digital fingerprints—such as their configuration, our wireless network logins, behavioral patterns, and movement records. As a result, it is now possible for data analysts to infer our interests, passions, ways of thinking, and even our feelings. Some companies analyze “consumer genes” to offer personalized products and services. 3000–5000 different kinds of metadata derived from personal data have already been collected from almost a billion people worldwide, including names, contact data, incomes, consumer habits, medical information and more.7 Therefore, everyone with a certain level of income and an Internet connection has been mapped to some extent.
This raises a controversial, but unavoidable question. Would it be good if a company or well-intentioned government had access to all this data? Would it help politicians and administrations to make decisions that reduce terrorism, crime, energy consumption, environmental degradation, traffic congestion, financial meltdowns and recessions? Furthermore, could the data be used to optimize our health and education systems and to provide public services which are tailored to the needs of the citizens?
The question is to what extent can this idea be realized? If one had enough data about every aspect of life, could one be omniscient? Would it even become possible to predict the world’s future? For this, one would certainly have to determine people’s choices to avoid deviations from what was predicted before. How could this be done? This is easier than one might think! One could use information specifically tailored to us in a way that is made to manipulate our choices. Personalized ads do this every day. They let us buy certain products or services that we wouldn’t have cared about otherwise. The more personal data is collected about us, the more efficient do personalized ads get.
It would be surprising if such possibilities to manipulate our choices weren’t attractive to politicians, too. Given the overwhelming amount of data available today, information needs to be filtered to be useful for us. Such filtering will inevitably be done in the interests of those who do the filtering or pay for it. A recent Facebook experiment involving almost 700,000 users showed that it is, in fact, possible to manipulate people’s feelings and moods.8
Therefore, will it soon be possible to turn “omniscience” into “omnipotence”? In other words, could those who have access to all the data finally control everything? Let’s call the hypothetical tool creating such power a digital “magic wand”. Suppose again you were the president of a country and had such a magic wand. Could you be “omnibenevolent”, i.e. take the best decisions for society and every single one of us? Many people might say that forecasting societal trends is different from forecasting the weather. While the weather will not react to a forecast, people will. This seems to suggest that societal predictions will be unreliable (or even “self-defeating prophecies”), if the predictions are published. But what if a secret institution evaluated our data and advised the government about the right decisions to be made? The magic wand would then be used to manipulate people’s behavior based on the evidence provided by the crystal ball. Could such a scheme work?
4.4 A New World Order Based on Information?
A wishful “benevolent dictator” or “wise king” would probably see the crystal ball and the magic wand as perfect tools to create the desired societal outcomes. Of course, the “wise king” could not fulfill our wishes all the time, but he might be able to create better outcomes on average for everyone as long as we obey him. So, a “wise king” would sometimes interfere with our individual freedom, if the autonomous decisions of people would otherwise obstruct his plan. This, however, would result in a form of totalitarian technocracy, where all of us would have to follow personalized instructions, as if they were commands from God. One might distinguish two kinds of such “big government” approaches. The “Big Brother” society would build on mass surveillance and the punishment of people, who don’t obey the commands or are unlikely to obey them as determined by “predictive policing” algorithms (even though the effectiveness is questionable9). The “Big Manipulator” society would build on mass surveillance and mass manipulation using personalized information. Of course, these approaches could also be combined.
It turns out that both approaches are already on their way. Predictive policing is now trying to anticipate the hotspots of criminal activities, but it also puts people in jail who are assumed to potentially commit a crime in future.10 We must be aware that, in an over-regulated society, almost everyone violates some laws or regulations within the course of a year.11 One day, we may have to pay for all these little mistakes, because it’s easy to record them now. With new, section-based speed controls, such technologies are already being tested. The principle of “assumed innocence” which has been the basis of democratic legal systems for ages, is now called into question. With the use of mass surveillance, the assumption that most people are good citizens has effectively been replaced by the assumption that everyone is violating rules or may become an obstacle to the plans of the “wise king”, “big government”, or “benevolent dictator”. In many countries, specialized police forces have increasingly been equipped like soldiers, and it seems that new, coercive strategies are being tested during demonstrations, also when people didn’t behave in a criminal, violent or improper way. So far, however, this tended to cause a public outcry or even countrywide protests.12 But what about the “Big Manipulator” approach? Wouldn’t it be just perfect to reach good societal outcomes in a way that doesn’t hurt? While we still don’t have sufficient data to understand the way humans decide, there are now enough metadata about everyone to manipulate people’s choices.
4.5 Nudging: When the State Takes Care of Our Decisions
In times of mass collection of personal data, everyone is not only a potential suspect, but also susceptible to manipulation attempts. While Big Data analytics is far from being able to understand the complexity of human behavior, it is advanced enough to manipulate our decisions based on a few thousand metadata that have been collected about every one of us. Some companies earn many billions each year for influencing us with personalized ads. Google, for example, one of the most valuable companies in the world, is making more than 90% of their money with ads. One might, therefore, think that they are making money mainly with manipulation, not information.13
With the huge amounts of personal data that such companies are storing about us, they probably know us better than anybody else, including our closest friends. Therefore, it is easy for these companies to manipulate our choices with personalized information. Some of this information may even affect our actions subconsciously by “subliminal messaging”.14 As a consequence, we might do many things without our conscious control.15 To some extent we are now remotely controlled by others, and with increasing amounts of personal information and powerful machine learning algorithms, attempts to manipulate our behavior will become ever more successful.16
Possibilities to influence peoples’ decisions are not only extremely attractive for business, but also for politics. In political contexts, this method is known as “nudging” or “liberal paternalism”, and it has been promoted as the perfect tool to improve peoples’ choices.17 It must be very appealing to political leaders to have an instrument allowing them to make us behave in healthier and environmentally friendly ways without having to convince us. However, the same approach may be used to promote nationalism, reservations against minorities, or pro-war sentiments. So far, one can certainly say that the use of nudging hasn’t reduced the number of problems in our society—on the contrary.
Nevertheless, it may be tempting to use nudging to influence our voting behavior. In fact, experts think that companies such as Google and Facebook can affect election outcomes.18 Most likely, this has happened several times already.19 At least, it is publicly known that our personal data (which has been accumulated largely without our consent) is being used to win elections.20 It is clear that such attempts to manipulate millions of people in ways that are neither transparent nor well regulated undermine our conscious and autonomous decision-making.21 In addition, they endanger the fundament of democracies, which is based on pluralism and a fair competition of the best ideas for our votes. Are personal freedom and democracy perhaps outdated?22 (see Appendix 4.1).
Besides the use of nudging, many governments also pay special agents and deploy computer bots to produce fake information in order to make us believe and do certain things.23 There are even “cybermagicians” working for secret services, who change Web and social media contents.24 In other words, facts are being manipulated, but the outcomes can sometimes be quite unexpected. For example, while the United Kingdom tried to strengthen its central government powers, there is now a trend towards greater regional autonomy. Moreover, even though Turkey “streamlined” the reporting in the public media to support the candidacy of the president, his power is being questioned more than ever. The public reporting was so biased that nobody expected the 2015 election outcome. This caused significant disruptions of the financial markets.25
I am deeply convinced that the digital society can only thrive, if we learn to reduce manipulation and information pollution. The more information we must process and assess, the more we must be able to rely on it.26 If we don’t have trustable information systems, almost nobody will finally be able to judge the situations we are faced with. Consequently, we will probably make more mistakes even though we could use a quickly growing amount of information.27
One problem of today’s information systems is their lack of transparency. We have usually no idea of the quality of results that search engines are delivering. These algorithms determine the ranking of results, when we make Internet searches: they decide what information appears on the top and what information is hidden. This has dramatic consequences: it can ruin peoples’ lives28 and cause the bankruptcy of companies.29 It’s no wonder that there are currently a number of lawsuits,30 which challenge the manipulation of search results.31 Is this manipulation just a business model, or is it more?
4.6 Google as God?
We have seen that, powered by the giant masses of information, a crystal ball to predict the future and a magic wand to shape it are already being built, used, and further improved. It’s not anymore far-fetched to imagine that companies such as Google or the USA’s National Security Agency (NSA) might try to take the role of a “wise king” or “benevolent dictator”. Or do they have even bigger ambitions?
There is no doubt that many people in the Silicon Valley believe in their ability to change and re-invent the world. Companies like Google aren’t just building powerful search engines, smart software tools, and self-driving cars. It seems they are also trying to create omnipresence (with the Google Loon project32) and omniscience (by collecting the world’s knowledge with a giant search engine). Given that “knowledge is power”, Google may also be striving for omnipotence (by manipulating peoples’ choices—after all the company makes most of its money with personalized ads). It is further known that Google wants to overcome death33 (e.g. with Google Calico) and that the company wants to create Artificial Intelligence (e.g. with their Google Brain project).34 In other words, one may get the impression that Google wants to build or be a “digital God”. What kind of God would this be? A God that watches us, a God that controls our destiny, or a God that gives us responsibility and freedom? And how well would such a plan work?
For the time being, let’s make the naive assumption that a company or government having all these digital powers would like to act in a benevolent way and not selfishly at all (i.e. it would take care of us rather than trying to exploit us). Would such an approach be able to optimize the state of the world? This is actually more tricky than one might think.
4.7 Errors or First and Second Kind: Doing Good Isn’t Easy
First of all, what’s the goal function one should optimize? Money? Happiness? Health? Security? Innovation? Peace? Or sustainability? Surprisingly, there is no scientific method that can give a definite answer, but if we chose the wrong goal, it could end in disaster.35 Therefore, choosing and implementing a single solution everywhere is highly dangerous.36 But even if the goal function was clear, distinguishing “good” from “bad” solutions is often difficult, for statistical reasons. For example, good and bad risks or behaviors can hardly ever be perfectly separated, as all measurements are noisy. Consequently, there is the problem of false positive classifications (false alarms, so-called type I errors) and of false negatives (type II errors, where the alarm is not triggered when it should be).
Imagine a population of 500 million people, in which there are 500 terrorists. Let’s assume that we can identify terrorists with an extremely impressive 99% accuracy. In this scenario, there are 1% false negatives (type II error), which means that 5 terrorists are not detected, while 495 will be discovered. Newspapers reported that about 50 terrorist acts in Western countries were prevented over the past 12 years or so, while the attack on the Boston marathon and on the Charlie Hebdo editorial office in Paris could not be prevented, even though the perpetrators were listed in databases of terrorist suspects (in other words, they turned out to be false negatives).
How many false positives (false alarms) could we expect? If the type I error is just 1 in 10,000, there will be 50,000 innocent suspects, while if it is 1 in 1000 there will be 500,000 innocent suspects. If it is 1% (which is entirely plausible), there will be 5 million innocent suspects! Indeed, it has been reported that there are between 1 and 8 million people on the various lists of suspects in the USA.37 If these figures are correct, this means that for every genuine terrorist, around 10,000 innocent citizens will be wrongly categorized as potential terrorists, perhaps even more. Since the 9/11 attacks, about 40,000 suspects have had to undergo special questioning and screening procedures at international airports. In 99% of these cases, it was later concluded that the suspect was innocent. And yet the effort needed to reach even this level of accuracy is considerable and costly: according to media reports, one million people with National Security Agency (NSA) clearance on the level of Edward Snowden are employed by the USA alone.38
Thus, large-scale surveillance doesn’t seem to be an effective means of fighting terrorism. Indeed, this conclusion has been reached by several independent empirical studies.39 Attempting to keep the entire population under surveillance is not sensible for the same reason why it is generally not useful to screen the entire population for a particular disease or to administer a particular preventative drug nationwide; since such mass screenings imply large numbers of false positives, millions of people would be needlessly treated, often resulting in negative side effects for their health.40 Thus, for most diseases, patients should only be tested if they show worrying symptoms.
Apart from these type I and type II errors, a third type of error may be encountered: the application of wrong models. For example, models which did not sufficiently account for rare, extreme events were one of the reasons for the recent financial and economic crisis. The risks of many financial products turned out to be much greater than anticipated, creating immense losses. Adair Turner, head of the UK Financial Service Authority, pointed out that there is
“a strong belief … that bad or rather over-simplistic and overconfident economics helped create the crisis. There was a dominant conventional wisdom that markets were always rational and self-equilibrating, that market completion by itself could ensure economic efficiency and stability, and that financial innovation and increased trading activity were therefore axiomatically beneficial.”
4.8 Limitations of the “Crystal Ball”
One might think that these three kinds of errors could be overcome if we just had enough data. But is this really true? There are a number of fundamental scientific factors that will impair the predictive power of the crystal ball. For example, the problem, which is known as “Laplace’s Demon”, posits that all future developments are determined by the world’s history. As a result, our ability to make predictions is fundamentally constrained by our inability to measure all historical information needed to predict the future41 (assuming that the world would change according to deterministic rules at all, 42 which is questionable).
In general, the parameters of a computer model representing certain aspects of our world can only be determined with a certain accuracy. But even a small variation of the assumed model parameters within their respective “confidence intervals” may fundamentally alter the model predictions. In complex anthropogenic systems, such “parameter sensitivity” is often expected to be large. While the confidence intervals may be narrowed down, if enough data are available, having too much data can be a problem, too: it may reduce the quality of predictions due to “over-fitting”, “spurious correlations” or “herding effects”.
Furthermore, many complex dynamical systems show phenomena such as “turbulence” or “(deterministic) chaos”, for which even the slightest difference may fundamentally change the outcome sooner or later. This well-known property is sometimes called the “butterfly effect”. It imposes a time limit beyond which no useful forecast can be made. The particular physics of weather phenomena is the reason why meteorologists cannot forecast the weather reasonably well for more than a few days,43 and even a million times more data could not fundamentally change this.
In social systems there is the additional problem of ambiguity: the same information may have several different meanings depending on the context, and the way we interpret it may influence the future course of the system. Beyond this, since Kurt Gödel (1906–1978) it is known that some questions are fundamentally undecidable in that the correctness of certain statements can neither be proved nor disproved with formal logic. Appendix 4.2 explains the above problems in more detail.
Thus, it is safe to say that Big Data is not the universal panacea it is often claimed to be.44 Attempts to predict the future will be mostly limited to probabilistic and short-term forecasts. This particularly applies to unstable systems. It is, therefore, dangerous to suggest that a crystal ball could be built that might reliably predict the future. As a consequence, any real-world application of Big Data requires critical assessment and particular care.
4.9 Limitations of the “Magic Wand”
If the crystal ball is “cloudy”, it doesn’t augur well for the magic wand that depends on it. Therefore, using the magic wand would often have unintended consequences.45 It is questionable, whether we would ever learn to use it well. In fact, top-down control is still very ineffective, as the abundance of problems in our world shows. To control our complex world, i.e. to make it change in the desired ways, we would need to understand it much better than today. In many cases, attempts to control a complex dynamical system in a top-down way will miserably fail, as this tends to undermine the normal functionality of the system (for example, the guidance of our behavior by socio-cultural cues46). The result may be a “broken” system, for example, an instability or crisis. An example of the failure of top-down control is the fact that the greatest improvement of airplane flight safety was not reached by technical control mechanisms but by introducing a non-hierarchical culture of collaboration in the cockpit, where co-pilots were encouraged to question the decisions and actions of the pilot. In another example, the Fukushima nuclear disaster in Japan, the official investigation report stresses that it was not primarily the earthquake and tsunami that were responsible for the nuclear meltdowns, but
“our reflexive obedience; our reluctance to question authority; our devotion to ‘sticking with the program’; our groupism.”
Unfortunately, there are many more examples that illustrate the failure of top-down control. In spite of 45 million arrests, the US “war on drugs” was largely ineffective. Similarly, many attempts to enforce “law and order” in the world after September 11, 2001 failed. The wars in Afghanistan and Iraq didn’t reach the goal of stabilizing the geopolitical region. Instead, the world is faced with a chaotic situation in the aftermath of the Arab Spring and the war of the Islamic State. Torture that was used to win the “war on terror” was found to be ineffective, and drone strikes seem to trigger new conflict rather than reducing it.47
Why do these control attempts fail despite all the power that some governments have? The issue is that a complex dynamical system such as our society cannot be steered like a bus. Let’s compare this with our body, which is a complex dynamical system, too. Here, we know very well that taking more medicine doesn’t help more, but it might poison our body. In our economy and society, therefore, power needs to be applied in the right dose, in the right place, in the right way. Typically, we don’t need more power but more wisdom. In many cases, too much top-down control is a problem, not the solution. It is also quite expensive, and we find it increasingly hard to pay for it: most industrialized countries already have debt levels of at least 100 or 200% of their gross domestic product.
4.10 Complexity Is the Greatest Challenge
The complexity of today’s human-influenced systems is the main reason why the concept of a “super-government”, “wise king” or “benevolent dictator” can’t work for a long time. There are at least four kinds of complexity that matter: dynamic complexity, structural complexity, functional complexity and algorithmic complexity. I have already addressed the problem of complex dynamics. In the following, I will focus on implications of structural, functional and algorithmic complexity. Within a centralized super-computing approach we can only solve those optimization problems, which have sufficiently low algorithmic complexity. But many problems are “NP-hard”, i.e. computationally so demanding that they cannot be handled in real-time even with today’s super-computing. This problem is particularly acute in systems that are characterized by a large variability. In such cases, top-down control can often not reach optimal results. In a later chapter, I will illustrate this by the example of traffic light control.
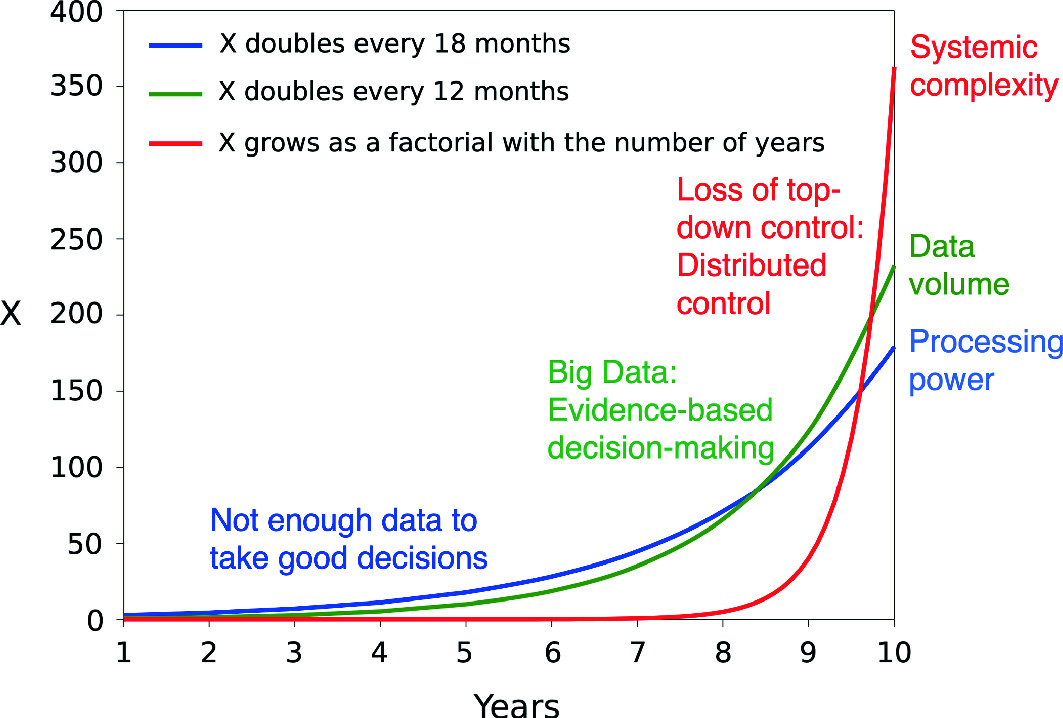
Schematic illustration of the increase of processing power, data volume and systemic complexity with time. (Reproduced from Helbing [9] with kind permission of Springer Publishers.)
The “flashlight effect” creates a new kind of problem: paying too much attention to some problems, while neglecting others. Sometimes we overlook really big problems. For example, while the world focused on fighting post-9/11 terrorism, the biggest financial crises ever emerged. While governments were trying to overcome the financial crisis, they didn’t see the Arab Spring coming. While they were busy with its aftermath, they didn’t see the crisis in the Ukraine emerge. Later on, they failed to anticipate the conflict with the Islamic State. Thus, keeping a well-balanced overview of everything will get progressively more difficult. Instead, politics will be increasingly driven by problems that suddenly happen to gain attention. Therefore, decisions will often be made in a reactive way rather than in a proactive way, as it should be.
But let’s now have a look at the question of how the complexity of the world is expected to grow. The possibility to network the components of our world creates ever more options. We have, in fact, a combinatorial number of possibilities to produce new systems and functionalities. If we have two kinds of objects, we can combine them to produce a third one. Connecting them in various ways, these three kinds of objects allow us to create six ones, and those already 720. This is mathematically reflected by a factorial function, which grows much faster than exponential (see the red curve in Fig. 4.1). For example, we will soon have more devices than people communicating with the Internet. In about 10 years from now, 150 billion (!) “things” will be communicating with the Internet. Thus, even if we realize just every thousandth or millionth of all combinatorial possibilities, the factorial curve will eventually overtake the exponential curves representing data volumes and computational power. It has probably overtaken both curves already for some time. Due to limited communication bandwidth, an even smaller fraction of data can be processed centrally, such that a lot of local information, which is needed to produce good solutions, is ignored by centralized optimization approaches.
In other words, attempts to optimize systems in a top-down way will become less and less effective—and cannot be executed in real time. Even revolutionary new technologies such as quantum computing are unlikely to change this (see Appendix 4.3). Paradoxically, as economic diversification and cultural evolution progress, a “big government”, “super-government” or “benevolent dictator” would increasingly struggle to take good decisions, as it becomes more difficult to satisfy the diverse local expectations and demands.51 This means that any attempt to govern our increasingly complex world in a top-down way by centralized control is probably destined to fail. Given the situation in Afghanistan and Iraq, Syria, Ukraine, and the states experiencing the Arab Spring, and given the financial, economic and public debt crisis, have we perhaps lost control already? Are we fighting a hopeless battle against complexity?52
4.11 Appendix 1: Democracy and Freedom—Outdated Concepts?
These days, many people seem to be asking: “Are the concepts of freedom and democracy obsolete?” Let us look into this. The “freedom of will” or “freedom of decision-making” has, in fact, been questioned many times and for various reasons. For example, some religions believe that our destiny is predetermined. If this were true, then our life would basically be like playing back a 3D movie. We would not have any possibilities to choose, but also no responsibility for what we do. Consequently, people would be sent to prison not for wrongdoing, but for disturbing public order. There would be also no freedom of press. However, in such a framework, business leaders and policy-makers couldn’t take any decisions as well. We would just have to accept what is happening to us.
In other cultures, it is being recognized that people can make their own decisions, but everyone is expected to subordinate personal decisions to the interests of higher-level institutions or to those who are more powerful. Such societies are hierarchically organized. Compared to this, in Western democracies the power of people and institutions has been limited by law in favor of individual freedom. This has boosted entrepreneurial activities, growth, prosperity, and social well-being for a long time. Remarkably, the most developed economies are the most diverse ones (and vice versa).53
New critique of the “freedom of decision-making” comes from some neurobiologists.54 Their experiments suggest that the feeling of free decision-making arises after the decision was actually made in the brain. However, this does not prove anything. Decision, execution and conscious recognition are separate things.55 The feeling of having taken a free decision might be just a conscious confirmation of execution.
Of course, our decisions are often influenced by external factors. However, the old idea of behavioralism that people would be programmed like a computer (by education and other external influences such as public media) and that they would execute what they have been programmed for has failed long ago.
There is little doubt that most people can learn to take different decisions in identical situations (if they are not in a deprived state). A conscious decision resulting from a deliberation process compares possible alternatives from a variety of perspectives, before a decision is made. In a sense, it is the art of decision-making to consider many aspects that might matter, and some people are very good at simulating possible decision outcomes in their brain.
From a societal perspective, it does not matter much whether different decision outcomes in practically identical situations are the consequence of free will, randomness, or other mechanisms (such as “deterministic chaos” or “turbulence”). What really matters is to have socio-economic institutions that support innovation and the spreading of good ideas.
New scientific ideas are produced primarily in democratic societies supporting freedom of thought, speech, and markets. (Reproduced from Mazloumian et al. [13] with kind permission of the Springer Nature Publishing Group.)
4.12 Appendix 2: Limitations to Building a Crystal Ball
4.12.1 Laplace’s Demon and Measurement Problems
Laplace’s Demon is a hypothetical being that could calculate all future states of the world, if it knew the exact positions and speeds of all particles in the universe and the physical laws governing their motion and interactions. But Laplace’s Demon cannot exist in reality, not least because measurements to determine all particle speeds would be impossible due to the restriction of Einstein’s theory of special relativity: all velocities must be less than the speed of light. This would prevent one from gathering all the necessary data.
4.12.2 Parameter Sensitivity
How close can computer-modeled behavior ever come to real human social behavior? I would say, a digital mirror-self wouldn’t resemble us more than two “identical twins” resemble each other. To specify the parameters of a computer double (digital twin), they are varied by calibration procedures until the difference between measurement data and model predictions does not get smaller anymore. However, the best-fitting model parameters are usually not the correct parameters. These parameters are typically located within a certain “confidence interval”. If the parameters are randomly picked from the confidence interval, however, the model predictions may vary a lot. This problem is known as “sensitivity”. To illustrate the problem: such parameter sensitivity could make some people rich over night, while others may lose their property.56
4.12.3 Instability, Turbulence and Chaos: When All the Data in the World Can’t Help
Two further problems of somewhat similar nature are “turbulence” and “chaos”. Rapid flows of gases or liquids produce swirly patterns—the characteristic forms of turbulence. In chaotically behaving systems, too, the motion becomes unpredictable after a certain time period. Even though the way a “deterministically chaotic” system evolves can be precisely stated in mathematical terms, without any random elements, the slightest change in the starting conditions can eventually cause a completely different global state of the system. In such a case, no matter how accurately we measure the initial conditions of the system, we will effectively not be able to predict the behavior after some time. This also holds for the formation of “phantom traffic jams”. Even if we would collect huge masses of information about the behavior of each driver, we could not predict who causes the traffic jam. It’s a collective phenomenon produced by the interactions of drivers, which occurs whenever the vehicle density grows beyond a certain critical density. We have made a similar observation in a decision experiment under well-controlled laboratory conditions. Here, we could predict 96% of all individual decisions based on a theory called the “best response rule”. Nevertheless, the rule failed to predict the macro-level (systemic) outcome, as even small deviations from this deterministic theory caused a different result.57 Surprisingly, adding noise to the highly accurate decision model (i.e. making it less accurate) improved the macro-level predictions, because this could reproduce effects of small deviations in situations of systemic instability.
4.12.4 Ambiguity
Information can have different meanings. In many cases, the correct interpretation can be found only with some additional piece of information: the context. This contextualization is often difficult and not always available when needed. Different pieces of information may also be inconsistent, without any chance to resolve the conflict.
Another typical problem of “data mining” is that data might be plentiful, but nevertheless incomplete and non-representative. Moreover, a lot of data might be wrong, because of measurement errors, data manipulation, misinterpretations, or the application of unsuitable procedures.
4.12.5 Information Overload
Having a lot of data does not necessarily mean that we’ll see the world more accurately. A typical problem is known as “over-fitting”, where a model with many parameters is fitted to the fine details of a data set in ways that are actually not meaningful. In such a case, a model with less parameters might provide better predictions. Spurious correlations are a somewhat similar problem: we tend to see patterns that actually don’t have a meaning.58
It seems that we are currently moving from a situation where we had too little data about the world to a situation where we have too much. It’s like moving from darkness, where we can’t see enough, to a world flooded with light, in which we are blinded. We will, therefore, need “digital sunglasses”: information filters that will extract the relevant information for us. But as the gap between the data that exists and the data we can analyze increases, it might become harder to pay attention to those things that really matter. Although computer power increases exponentially, we will only be able to process an ever-decreasing fraction of data, since the storage capacity grows even faster. In other words, there will be increasing volumes of data that will never be touched (which I call “dark data”). To reap the benefits of the information age, we must reduce information biases and pollution, otherwise we will increasingly make mistakes.
4.12.6 Herding
In many situations, which are not entirely well defined, people tend to follow the decisions and actions of others. This produces undesirable herding effects. The Nobel laureates in economics, George Akerlof (*1940) and Robert Shiller (*1946), have called this problematic behavior “animal spirits”, but the idea of herding goes back at least to the French mathematician Louis Bachelier (1870–1946). Bubbles and crashes in stock markets are examples of undesired consequences of such herding effects.
4.12.7 Randomness and Innovation
Randomness is a ubiquitous feature of socio-economic systems. However, even though we would often like to reduce the risks it generates, it would be unwise to try to eliminate randomness completely. Randomness is an important driver of creativity and innovation, while predictability excludes positive surprises (“serendipity”) and cultural evolution. We will later see that some important social mechanisms can only evolve in the presence of randomness. While newly emerging behaviors are often costly in the beginning (when they are in a minority position), the random coincidence or accumulation of such behaviors in the same neighborhood can enable their success (such that new behaviors may eventually spread).
4.13 Appendix 3: Will New Technologies Make the World Predictable?
How can we know that the processing power, data volumes, and complexity will always grow according to the same mathematical laws, which I have assumed above (in Fig. 4.1)? In fact, we can’t, but Moore’s law for the computational processing power has been valid for many decades. A similar thing applies to the curve for the stored data volumes. In future, quantum computers may potentially change the game. They are based on a different computing architecture and concept. For example, classical data encryption would become easily breakable, but new encryption schemes would become available, too. Thus, could such a paradigm shift in computing make optimal top-down control possible? I doubt it, because there are also new technologies that will dramatically increase data production rates, such as the Internet of Things.59 Moreover, the production of hardware devices, both of computers and communicating sensors, might be a limiting factor, as are data transmission rates. Finally, when computer power and data rates are increasing, this is promoting complexity, too, as new devices and functionalities can be produced.
We must also realize that a small subsystem of our universe such as a quantum computer can, by its very nature, not evaluate and simulate the entire world, including its own state and temporal evolution. Simplifications will always be needed. Unfortunately, sheer data mining and machine learning are often quite bad at predicting future changes such as paradigm shifts due to systemic instabilities or innovations, which may fundamentally change the system and its properties. If we wanted to change this, we would have to forbid innovations, but then our world would become as boring as a graveyard, and could not adjust to environmental, social and technological change that is happening.
I believe, we could also not be interested in creating an information infrastructure that creates a broadband information exchange between all brains in the world, or in creating a computer having the computational capacity of all brains. Why? Because it would create strongly coupled networks of networks, which would be highly prone to showing undesirable cascading effects. Harmful mass psychology, as it occurred in many totalitarian regimes, riots, and revolutions are some examples illustrating the danger of too much connectivity between people’s minds. As I pointed out before, many of our anthropogenic systems are vulnerable to cascading effects already, which often makes them uncontrollable. Privacy may be seen as a mechanism to avoid such undesirable socio-psychological cascading effects. Without it, we would probably be involved in many more conflicts.