GitHub provides a nice web API for fetching issues.[19] Simply issue a GET request to
| | https://api.github.com/repos/user/project/issues |
and you’ll get back a JSON list of issues. We’ll reformat this, sort it, and filter out the oldest n, presenting the result as a table:
| | # | created_at | title |
| | ----+----------------------+----------------------------------------- |
| | 889 | 2013-03-16T22:03:13Z | MIX_PATH environment variable (of sorts) |
| | 892 | 2013-03-20T19:22:07Z | Enhanced mix test --cover |
| | 893 | 2013-03-21T06:23:00Z | mix test time reports |
| | 898 | 2013-03-23T19:19:08Z | Add mix compile --warnings-as-errors |
Our program will run from the command line. We’ll need to pass in a GitHub user name, a project name, and an optional count. This means we’ll need some basic command-line parsing.
We’ll need to access GitHub as an HTTP client, so we’ll have to find a library that gives us the client side of HTTP. The response that comes back will be in JSON, so we’ll need a library that handles JSON, too. We’ll need to be able to sort the resulting structure. And finally, we’ll need to lay out selected fields in a table.
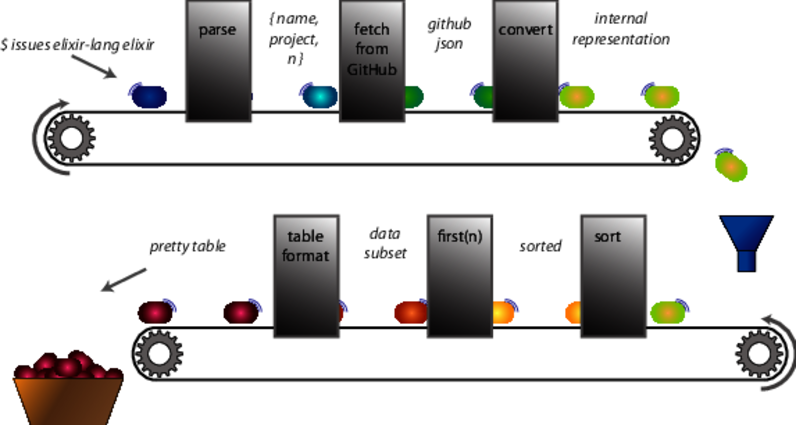
We can think of this data transformation in terms of a production line. Raw data enters at one end and is transformed by each of the stations in turn.
Here we see data, starting at the command line and ending at pretty table. At each stage, it undergoes a transformation (parse, fetch, and so on). These transformations are the functions we write. We’ll cover each one in turn.