At the start of the chapter, I somewhat cavalierly said Elixir processes were very low overhead. Now it’s time to back that up. Let’s write some code that creates n processes. The first will send a number to the second. It will increment that number and pass it to the third. This will continue until we get to the last process, which will pass the number back to the top level.
| 1: | defmodule Chain do |
| - | def counter(next_pid) do |
| - | receive do |
| - | n -> |
| 5: | send next_pid, n + 1 |
| - | end |
| - | end |
| - | |
| - | def create_processes(n) do |
| 10: | code_to_run = fn (_,send_to) -> |
| - | spawn(Chain, :counter, [send_to]) |
| - | end |
| - | |
| - | last = Enum.reduce(1..n, self(), code_to_run) |
| 15: | |
| - | send(last, 0) # start the count by sending a zero to the last process |
| - | |
| - | receive do # and wait for the result to come back to us |
| - | final_answer when is_integer(final_answer) -> |
| 20: | "Result is #{inspect(final_answer)}" |
| - | end |
| - | end |
| - | |
| - | def run(n) do |
| 25: | :timer.tc(Chain, :create_processes, [n]) |
| - | |> IO.inspect |
| - | end |
| - | end |
The counter function on line 2 is the code that will be run in separate processes. It is passed the PID of the next process in the chain. When it receives a number, it increments it and sends it on to that next process.
The create_processes function is probably the densest piece of Elixir we’ve encountered so far. Let’s break it down.
It is passed the number of processes to create. Each process has to be passed the PID of the previous process so that it knows who to send the updated number to.
The code that creates each process is defined in a one-line anonymous function, which is assigned to the variable code_to_run. The function takes two parameters because we’re passing it to Enum.reduce on line 14.
The reduce call will iterate over the range 1..n. Each time around, it will pass an accumulator as the second parameter to its function. We set the initial value of that accumulator to self, our PID.
In the function, we spawn a new process that runs the counter function, using the third parameter of spawn to pass in the accumulator’s current value (initially self). The value spawn returns is the PID of the newly created process, which becomes the accumulator’s value for the next iteration.
Putting it another way, each time we spawn a new process, we pass it the previous process’s PID in the send_to parameter.
The value that the reduce function returns is the accumulator’s final value, which is the PID of the last process created.
On the next line we set the ball rolling by passing 0 to the last process. The process increments the value and so passes 1 to the second-to-last process. This goes on until the very first process we created passes the result back to us. We use the receive block to capture this, and format the result into a nice message.
Our receive block contains a new feature. We’ve already seen how guard clauses can constrain pattern matching and function calling. The same guard clauses can be used to qualify the pattern in a receive block.
Why do we need this, though? It turns out there’s a bug in some versions of Elixir.[32] When you compile and run a program using iex -S mix, a residual message is left lying around from the compilation process (it records a process’s termination). We ignore that message by telling the receive clause that we’re interested only in simple integers.
The run function starts the whole thing off. It uses a built-in Erlang library, tc, which can time a function’s execution. We pass it the module, name, and parameters, and it responds with a tuple. The first element is the execution time in microseconds and the second is the result the function returns.
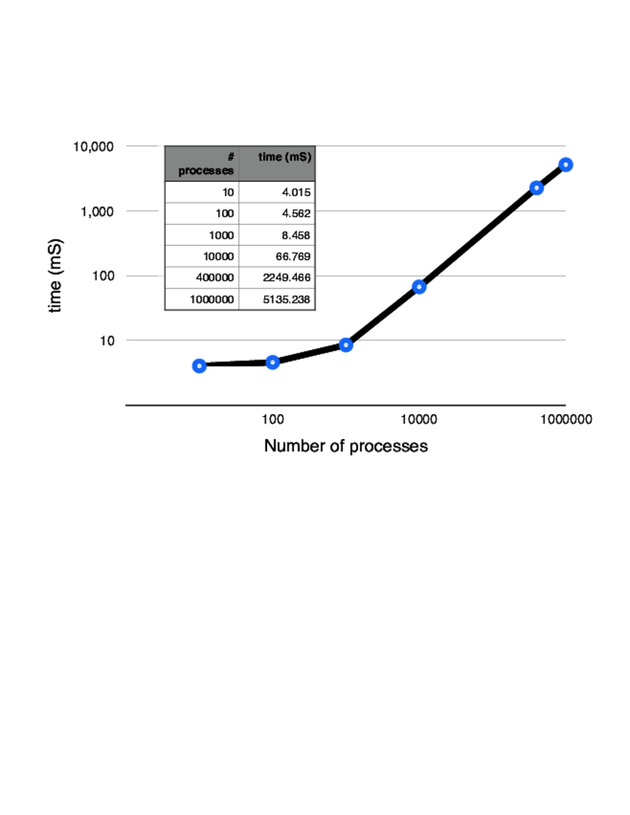
We’ll run this code from the command line rather than from IEx. (You’ll see why in a second.) These results are on my 2011 MacBook Air (2.13 GHz Core 2 Duo and 4 GB of RAM).
| | $ elixir -r chain.exs -e "Chain.run(10)" |
| | {4015, "Result is 10"} |
We asked it to run 10 processes, and it came back in 4 ms. The answer looks correct. Let’s try 100 processes.
| | $ elixir -r chain.exs -e "Chain.run(100)" |
| | {4562, "Result is 100"} |
Only a small increase in the time. There’s probably some startup latency on the first process creation. Onward! Let’s try 1,000.
| | $ elixir -r chain.exs -e "Chain.run(1_000)" |
| | {8458, "Result is 1000"} |
Now 10,000.
| | $ elixir -r chain.exs -e "Chain.run(10_000)" |
| | {66769, "Result is 10000"} |
Ten thousand processes created and executed in 66 ms. Let’s try for 400,000.
| | $ elixir -r chain.exs -e "Chain.run(400_000)" |
| | =ERROR REPORT==== 25-Apr-2013::15:16:14 === |
| | Too many processes |
| | ** (SystemLimitError) a system limit has been reached |
It looks like the virtual machine won’t support 400,000 processes. Fortunately, this is not a hard limit—we just bumped into a default value. We can increase this using the VM’s +P parameter. We pass this parameter to the VM using the --erl parameter to elixir. (This is why I chose to run from the command line.)
| | $ elixir --erl "+P 1000000" -r chain.exs -e "Chain.run(400_000)" |
| | {2249466, "Result is 400000"} |
One last run, this time with 1,000,000 processes.
| | $ elixir --erl "+P 1000000" -r chain.exs -e "Chain.run(1_000_000)" |
| | {5135238, "Result is 1000000"} |
We ran a million processes (sequentially) in just over 5 seconds. And, as the graph shows, the time per process was pretty much linear once we overcame the startup time.
This kind of performance is stunning, and it changes the way we design code. We can now create hundreds of little helper processes. And each process can contain its own state—in a way, processes in Elixir are like objects in an object-oriented system (but they’re more self-contained).