I have loads of duplicate files littering my computers. In an effort to tame this, let’s write a duplicate-file finder. Well call it Duper (so we can later create a paid version called SuperDuper). It’ll work by scanning all the files in a directory tree, calculating a hash for each. If two files have the same hash, we’ll report them as duplicates.
Let’s start asking the questions.
We’re going to run this on a typical computer. It’ll have roughly two orders of magnitude more file storage than main memory. Files will range in size from 100 to 1010 bytes, and there will be roughly 107 of them.
We need to allow for the fact that although we have to load files into memory to determine their hashes, it is possible we won’t have enough memory to load the largest files in whole. We definitely will not be able to process all the files at once.
It also means that our design will need to cater to both big and small files. Big files will take more time to read into memory than small files, and they will also take longer to hash.
A focal point represents a responsibility of the application. By considering the focal points now, we can start to reduce coupling in the application as a whole: each focal point can be tightly coupled internally but loosely coupled to the others. This coupling can be both structural (for example, the representation of data) and temporal (for example, the sequence in which things will happen).
In Duper, we can fairly easily identify some key focal points:
We need to have a place where we collect results. We are calculating a hash value for each file, so this results store will need to hold all of these. As we are looking for duplicate hashes, it would make sense for this to be some kind of key/value store internally, where the key is the hash and the value is a list of all files with that hash. However, this is an implementation detail, and the implementation shouldn’t leak through our API.
We need to have something that can traverse the filesystem, returning each path just once.
We need to have something that can take a path and calculate the hash of the corresponding file. Because an individual file may be too big to fit in memory, we’ll have to read it in chunks, calculating the hash incrementally.
Because we know we will need to be processing multiple files concurrently in order to maximize our use of the CPU and IO bandwidth, we’ll need something that orchestrates the overall process.
This list may well change as we start to write code, but it’s good enough to get us to the next step.
At the very least, each focus we identify is an Elixir module. My experience is that it’s wise to assume that most if not all are going to end up being servers. I’m also coming to believe that many should even be separate Elixir applications, but that’s not something I’m going to dig into here.
Our code will be structured into four servers. Although we could do it with fewer, using four means we can have specific characteristics for each. The four are as follows:
The Results. This is the most important server, as it holds the results of the scanning in memory. We need it to be reliable, so we won’t put much code in it.
The PathFinder. This is responsible for returning the paths to each file in the directory tree, one at a time.
The Worker. This asks the PathFinder for a path, calculates the hash of the resulting file’s contents, and passes the result to the gatherer.
The Gatherer. This is the server that both starts the ball rolling and determines when things have completed. When they do, it fetches the results and reports on them.
Our application is going to spend the vast majority of its time in the workers, as this is where we read the files and calculate the hash values. Our goal is to keep both the processors and the IO bus as busy as possible in order to maximize performance.
If we have just one worker, then it would read a file, hash it, read the next, hash it, and so on. We’d alternate between being IO bound and CPU bound. This doesn’t come close to maximizing our performance.
On the other hand, if we had one worker for each file, then they could be reading and hashing at the same time. However, we’d run out of memory on our machine, as we’d effectively be trying to load our filesystem into memory.
The sweet spot lies in between.
One approach is to create n workers, and then divide the work equally between them. This is the typical push model: plan the work up front and let it execute. The problem with this approach is that it assumes that each file is about the same size. If that’s not the case (and on my machine it certainly isn’t), then it would be possible to give one worker mostly small files and another mostly large files. The first would finish early, and would then sit idle while the second chewed through its workload.
The approach I prefer in this scenario is what I call hungry consumer. It’s a pull model, where each worker asks for the next thing to do, processes it, and then asks for more work. In this scheme a worker that has a small file to process will get it done quickly, then ask for more work. One with a bigger file will take more time. There’ll never be an idle worker until we get to the very last files.
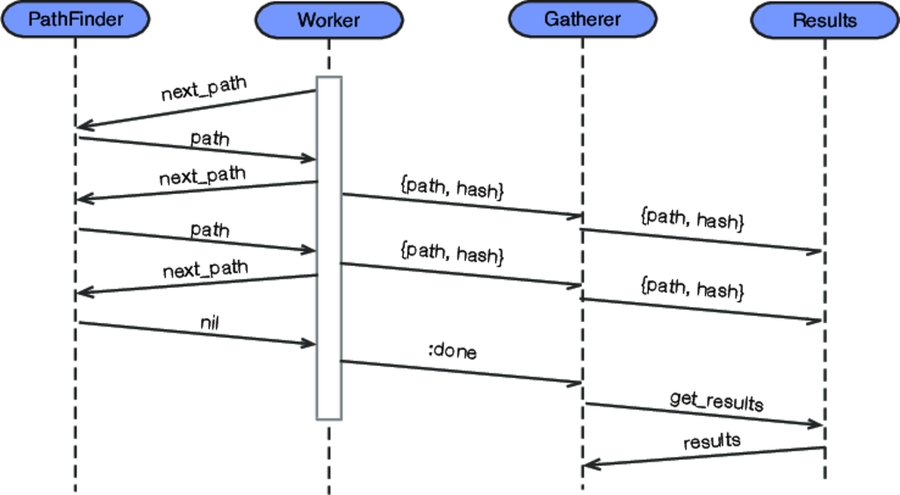
The following sequence diagram shows how messages flow in this system. Notice that we have a mixture of synchronous messaging (the pairs of arrows going in opposite directions) and asynchronous messaging.
This is where we get to be pragmatic!
In an ideal world, nothing will fail, and everything should be protected from errors.
The real world is different—we can only do so much protecting. How much do we need? It depends. If we’re writing software for a pacemaker, then I’d suggest the vast majority of the implementation effort should go into error protection. If we’re writing a duplicate-file finder, then not so much.
We can assume that running our finder across 500 GB of files will take minutes, not seconds. That means that if we have a failure reading one file, we don’t want to stop the whole application and lose the work done so far—it is good enough to continue ignoring that file.
We want to protect the accumulating results, but we’re not as worried about the individual workers—workers can simply restart on failure and process the next file.
Sequential programs are easy to start: you just run them. Applications that have many moving parts are more complex: you have to make sure that the various servers are started so that if server A needs to call server B, then B is running before A makes that call.
How should our four servers be started?
The sequence diagram tells us most of the answer.
Pathfinder and Results should be started first, followed by Gatherer, and then by the workers.
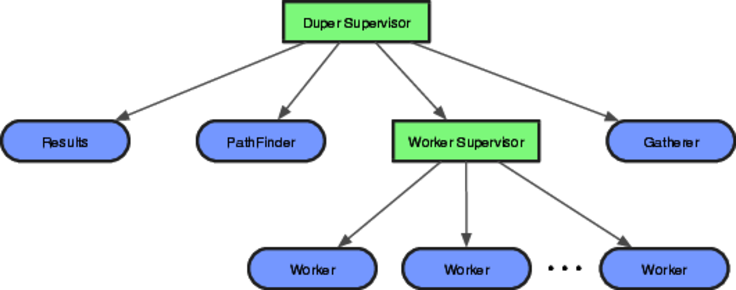
In terms of implementation, this is fairly straightforward. We simply list the servers in this order as children of a supervisor, and the supervisor will make sure each child is running before starting the next.
But we also know that we will have multiple workers. Rather than try to find a way of creating them up at the top level, we’ll add something new: a subsupervisor. This subsupervisor is responsible for just the pool of workers.
Adding this supervisor opens up an interesting possibility. If all the children of a supervisor are the same, then that supervisor can be used to create them dynamically. Our gatherer server could create a pool of workers when it kicks off the application. This would let us experiment with the effect the number of workers has on elapsed time.
Our new dependency structure looks like this:
This gives us a supervision structure that looks like this:
Of course, all this is just theory. Let’s start getting some feedback by writing code.