1 Introduction
These days, cyber attacks are targeting almost all our digital infrastructure and services from banking [1] and cloud computing [2, 3] and big data analytics platforms [4] to Windows [5] and Mac [6] machines and mobile devices [7]. Emerging Distributed Denial of Services attack [8], Malware [9] and Ransomware [10, 11] attacks and Botnets [12] along with ever increasing software and hardware vulnerabilities [13] made security a significant barrier in wider deployment of new technologies including Internet of Thing (IoT). In many cases, especially in the Internet of Things (IoT) domain bugs and security flaws are found after software have been released [14], which make them vulnerable to exploits that can compromise security of devices running such vulnerable applications [15]. IoT applications vulnerabilities may expose the entire network to attacker [16] and cause a significant damage [17]. A range of techniques from utilisation of machine learning [18] and deep learning [19] to the development of novel key generation methods [20] and intrusion detection mechanisms [21] were suggested for securing IoT environments. However, still software defects such as buffer overflows, logic flaws, inconsistent error handling are the major source of security issues in IoT [22]. Software quality assurance plays a key role, especially in IoT environment where a device might not be updated for considerably long time [23] or devices are deployed in the safety critical environments [24]. Testing processes have evolved over time and even though there have been significant improvements in methods, techniques and tools, there are difficulties to keep up with the increasingly rapid evolution of software engineering and trends of development paradigms [25].
Fuzzing is a technique used to find bugs in a specific software. By feeding the targeted software some random and invalid input, we can monitor and observe the software for behavioural anomaly, such as a crash or a denial of service. We can also record the input data used to cause this crash, in order to investigate the exact location of the data responsible for the application malfunctioning within the program stack. This process is often repeated with different data types each time to discover flaws in the software.

Fuzzing
Two fuzzers namely FileFuzz and Peachfuzz representing the two main fuzzing approaches are used in this study to determine the most effective and how fuzzing process can be improved for a better efficiency. While analysing fuzzing tools, key parts of these tools will be given more attention in terms of trying to enhance fuzzing efficiency. The information and the results achieved from this project will be in terms of no previous knowledge required about the target internal structure as on mutational fuzzing, or with a previous research about the target structure as in the generational fuzzing approach. This approach helps to test software embedded in IoT application where no knowledge of its internal structure is common as well as the underlying operating system.
The rest of the paper is organised as follows: Sect. 2 highlights various terminologies, fuzzers and the fuzzing strategies. In Sect. 3, we describe the research methodology, along with the required fuzzer programs used in this study. Section 4 presents the experiment and discusses the results. Summary of the study and future works are discussed in Sect. 5.
2 Background
This section describes the basic terminologies, tools, techniques and strategies of using fuzzing and how it impacts the quality of the software. It also gives various benefits of fuzzing a software periodically.
2.1 Fuzzing
Fuzzing is a software testing technique, which basically consist of finding security flaws by injecting randomly generated input in an automated manner. A fuzzer program can be used to fuzz applications running on computer systems or devices which requires user input to be supplied to detect software bugs in order to improve the security of the software or exploit the system running it [27]. It is an automated or semi-automated technique aimed at finding security flaws in a software by providing unexpected and manipulated data to a target and monitor the impact on the target for any irregular behaviour.
Due the automated processes of deploying fuzzers to test running applications without knowledge or access to the underlying source code, it is one of the preferred method of black box testing for penetration testers. The technique is often used by malicious hackers to test applications for vulnerabilities and then write exploits for the identified vulnerabilities.
There are two categories of fuzzers: Mutation-based fuzzers, which takes a valid data input from an existing data sample by the user and mutate it in some types to build a test case,1 but does update the corresponding cyclic redundancy check. The second is the generation-based fuzzers, which create random data input from the scratch from data model, but generate a correct corresponding in cyclic redundancy check [27, 28]. A further discussion on the techniques and strategies utilised by both categories is described in the following subsection.
2.2 Fuzzing Techniques and Strategies
Fuzzing can be used on different types of applications such as database, multimedia, word processing, simulation software and application suites.
Mutation-based fuzzer, also known as dumb fuzzing or protocol-unaware fuzzing, describes a technique used when a valid test case which contains invalid input is used to fuzz a target. The test case of this method is changed and mutated to contain anomalies without proper understanding of the input data or the target software format. A fuzzer program such as “File Fuzz” automates this process by taking a valid template from the user and mutates it to create test cases required to cause the target software to malfunction.
Generation-based fuzzer, also known as intelligent fuzzing or protocol-aware fuzzing, requires previous knowledge of the target, as the test case should be built from the scratch based on the format. For instance, targeting a program which requires a request for comments (RFC) through user input, we need to search for some knowledge of the software by looking through the software documentation or by reverse engineering the software to have an understanding of the software structure and format. Then the journey starts for building the test case which includes adding anomalies to the information extracted. Adjusting test cases is very difficult to do manually. However, a few fuzzing tools exits will make this process easier. Both methods will be discussed further in this paper.
All the methods covered so far counts as black-box fuzzing. According to Microsoft Forefront Edge Security team [29], black-box fuzzing requires sending malformed data without actual verification of which code paths were hit and which were not. In black-box testing, it is not important to have knowledge about the target source code, which gives it a strength and wider usage among developers and attackers. However, the testing efficiency will not meet developer expectations when testing a software with complicated logics and because of the minimum knowledge about the target. In addition, black-box test provides low code coverage and can miss security bugs [30].
White-box techniques or smart fuzzing, different names but shares the same principle of extending the scope from unit testing as on black-box test to a whole-software testing searching for negative paths, where it can cover millions of instruction, execution traces and lines of code [29, 30]. Symbolic execution used during white box test [31]. Where symbolic values are used instead of normal data, this method allows you to know how the software is going to behave when it fed by infinite inputs and to explore the unfeasible spaces of input if a random test was performed. A new command is given to mutate the inputs used when the branch reached satisfiability modulo theories SMT2 solver. If the problem was solved, the software runs again with a new input. The mechanism performed at this technique focus on discovering new paths to lead to whole-software security testing. However, white-box fuzz requires high effort, skills set and expensive.
2.3 Seed Selection
One of the most important aspect during fuzzing is the valid samples3 used to fuzz a target. Basically, fuzzers required a large number of samples to be able to cover more paths on our target. Depending to the target, these samples could be larger than anticipated and may require lot of time and computer processing power to complete. This issue could hinder the opportunity to discover more vulnerabilities.
Therefore, it is highly recommended to find a method to minimize the selections seeds required to fuzz a program as the program normally repeat running the same code blocks each time [32]. By removing the samples that use the same paths or have the same coverage on the target code, without reducing the coverage quality on our target code. Thus, if this process is achieved, the time and effort required for fuzzing process will be reduced.
Choosing the best seed files can greatly increase the number of bugs found during fuzzing. In order to minimize the samples required to cover most of the target blocks, the first step is to generate the best samples set and the code coverage for each sample used in our target will be saved and extracted using one of the instrumentation tools. Secondly, the information extracted will be compared to other coverage achieved from different sample. The best ones according to its coverage will be chosen until covering the majority of our target paths. The other samples will be excluded from our data set.
This phase can be done using different techniques. However, in this paper, an automated python script called (minset.py4) which makes use of the Microsoft Research Phoenix Project to find the basic blocks in an application was used. It is part of the generational fuzzer tool (Peach) libraries and has the ability to perform code coverage of a target application as it consumes a set of sample files and select the set of files that generates the most coverage of the target application. Feeding the chosen script, the directory of original samples and the path to the software where these sample supposed to be tested on, showed the result contains fewer samples but with the same efficiency as the original samples and will be saved in a new folder.
The script was seen to be the most suitable to work with generational fuzzers. This type of fuzzers required high volume of samples to be downloaded or created manually simply, because lack of knowledge of quality of these samples. Therefore, it takes more time and effort if these samples were not filtered appropriately, which may not be commensurate with the time allocated for this project. However, the process is different for Mutational-fuzzing approach, where fuzzers from this category required one valid sample only “template” to generate the seeds/test cases from. In this case, the fuzzer add, delete or replace part of the template inputs to generate the seeds required during fuzzing. The number of the seeds generated will be according to the selected scope as it is shown in Fig. 11.
2.4 Instrumentation
- Dynamic instrumentation: Which is a technique applies when an emulated process is required to be modified dynamically while program is running, by executing the new instrument5 code just before the target code being analyse in two separate processes. The power of using dynamic instrumentation relies on its ability for manipulating each instruction in an existing binary before execution [34]. Figure~2 describe the basic operation for dynamic instrumentation framework.
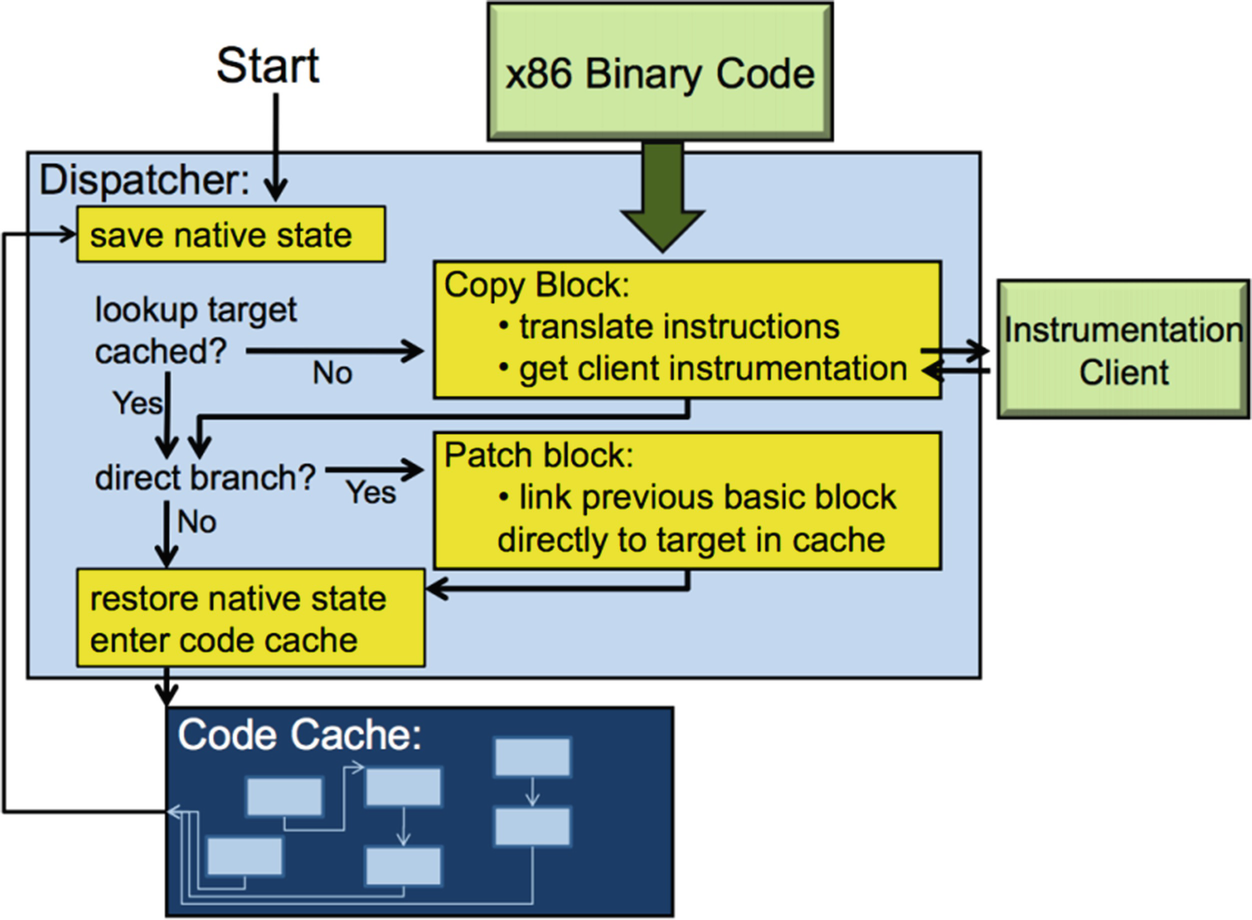 Fig. 2
Fig. 2Dynamic instrumentation framework
Static Instrumentation: This is an approach for adding instrument code to the software before running it. Essentially the probes are baked in to you binary. There are two ways this can be done. One is to have the compiler put the probes in. Visual C++ takes this approach to implement Profile Guided Optimizations (PGO). The other method takes the binary which has been emitted by a compiler, crack and discover all the methods, instrument and modified the binary like it never been touched.
3 Methodology
This section describes two categories of fuzzers representing two fuzzing approaches used in this study in order to improve speed, accuracy and efficiency during fuzzing with less user interaction. In addition, several fuzzing steps and supporting tools will be analysed and explained in detail as the results in the next section will be based on them.
3.1 Metrics
Code coverage: also known as fuzzer tracking is an important metric used to measure the efficiency during the fuzzing process. [29], has defined code coverage as a technology which allows inspection of which code paths were executed during fuzz testing. Which is important during the verification of test effectiveness and to improve sample coverage. Code coverage gathered the lines of the software code which was instrumented and make a comparison of what of these codes was reached by a fuzzer and which was not, and give a percentage according to this preforming. According to this information, code coverage will be used as a method to make a comparison between the two fuzzers used in this project.
The tool described Sect. 2.4 will be used mainly to measure the code coverage/traces on my target. In addition, to the branch purpose of reducing the selecting set samples.
Time: Using code coverage as a metric has nothing to provide to the end customer about the test quality [35]. It is therefore required another measurement guidance while working on the research objectives. The time required to perform a certain process will be use as metric, because it will show how long the process will take, which will be used to differentiate between the two fuzzers, to record the optimal time each of them consumed for a specific fuzzing process.
This metric will be performed on the mutational fuzzer by looking into the time before and after fuzzing is finished. However, the generational fuzzer will record the time itself.
3.2 Fuzzing Methods
In this section, the two fuzzing approaches (mutational and generational) are explained. In addition, the two fuzzers and the supporting tools will be described in detail, to make a valid comparison between the two main approaches/tools used to fuzz my research target program.
3.2.1 Mutational Fuzzing
Mutational fuzzing phases
FileFuzz
A well-known mutational-fuzzing tool written by Michael Sutton was chosen called FileFuzz. This fuzzer was chosen because it works on the three mutational-fuzzing phases separately, as this allows proper test and analysis of the fuzzing process, most importantly when generating the test cases and using it. In addition, the fuzzer has a graphic user interface which provides a user-friendly interface to monitor the fuzzing progress in order to observe the memory location, registry value and the types of the error that occur during the crash.
3.2.2 Generational Fuzzing
Generational fuzzing phases
Peach Fuzzing Framework
Peachfuzz is one of the industry’s most advanced security testing platforms written in python [36]. Peach can be used to fuzz almost everything starting from Programs, ActiveX, Network application, SQL … Etc. This tool provides a quick service to generate a fuzzer depend on the target’s format method. The smart platform requires Peach Pit Packs that contained a definition of the target specifications to meet our target requirements before fuzzing starts. This pack store in a file where Peach calls the required Pit based on the target the user selects to fuzz, by defining the relation between the data format and the data structure. The outcome of this definition will be used by Peach to add anomalies to the collected data in a smart way.
3.3 Experiment Tools
Dynamic Binary Instrumentation
The power of using dynamic instrumentation during fuzzing is its ability to add/delete from the code while it is running. The tool chosen for this research was PIN3.2 [37], to record and deeply monitor the activities while fuzzing the target “Sumatra PDF”. The tool was chosen because not only is it produced from Intel but it is a portable version and supports almost all the platforms including Linux.
Although debuggers require to be paused for tracing, dynamic instrumentation and provides the flexibility to trace without interruption, Pintools provides a rich application programming interface (API) and its ability to instrument per block or per function. The test bed environment in this study was done using a Windows Operating System. It required using Microsoft Visual Studio to support running the tool and the files attached to it.
! exploitable 1.6.0
Fuzzing our target it is likely to crash several times at one or different locations, this will be logged at one package by the fuzzer for further analysis. However, it is possible to use another automatic debugging tool for more advance properties such as: prioritising the crashes based on its severity to distinguish between different crashes. In this study, we used !exploitable, a windows debugging extension tool attached with Peach fuzzer. This tool was first published by Microsoft after 14 months of fuzzing effort when Windows Vista released in 2009 [38]. This tool is able to prioritise and assigns the vulnerabilities, according to its exploitability such as: exploitable, probably not exploitable or unknown.
!exploitable debugger depends on crash logs with the ability to analyse any crashes that occur. Peach fuzzer uses this tool to classify the discovered vulnerabilities and differentiate amongst them based on predefined rules.
Interactive Disassembler IDA Pro 5.0
A tool which was used to dissemble the target code, produce and record disassembled database (.idb). It contains all the structures and functions of the target software application, where the tester can return to it during the investigation process. In addition, the output from this tool can be used for more analysis through different tools such as: BinDiff which supports exporting IDA output files, was used to discover the instructions executed while running different mutated samples on the target “Sumatra PDF” application. The main goal of this tool is to reverse engineer the target application source code. All the target functions and variable names will be uncovered with the ability to display the result in different methods, which will make it easy to link between functions, subroutines and source code.
3.4 Test Environment
VMs configuration
System configuration | Value |
|---|---|
OS | Windows XP, Windows 7 |
CPU | 2 Core each |
Ram | 4 GB for each |
Virtual hard disk capacity | 40 GB |
Host specification
System configuration | Value |
|---|---|
OS | MacOS 10.12.6 |
CPU | 2.9 GHz Intel Core i7 |
RAM | 16 GB 2133 MHz LPDDR3 |
Hard disk capacity | 500 GB |
During fuzzing, both VMs are required to work continuously for long periods until you get satisfactory results, the laptop was configured not to sleep, the fan increased to 4500 rpm as the laptop temperature raised to higher 70 °C and the screen will not turn off, as this may cause interruption and waste the time already spent on fuzzing specially during mutational-fuzzing approach when FileFuzz tool is used. In addition, both VMs have shared folder with the main host, to share files and facilitate the coordination among them.
Sumarta PDF
The target software in this study is Sumarta PDF. It is an open source pdf viewer which can run both on Windows and Linux platforms. The graphical user interface on our target is required, as this will add some complexity to be attached with. In addition, the target required a PDF file format as an input, which is not difficult to collect. The target size for the latest Sumarta version is 5.2 MB and below 2 MB for earlier version which will add simplicity to reach code blocks during our fuzz testing. The earlier version Sumatra1.5.1 is used in this study as target should not be an up to date version (mature), as this will result in less bugs and a robust software. My target consists of one executable file only, where no libraries are required to execute it.
4 Experiments and Results
4.1 Generating a Minimum Set of the Chosen Templates
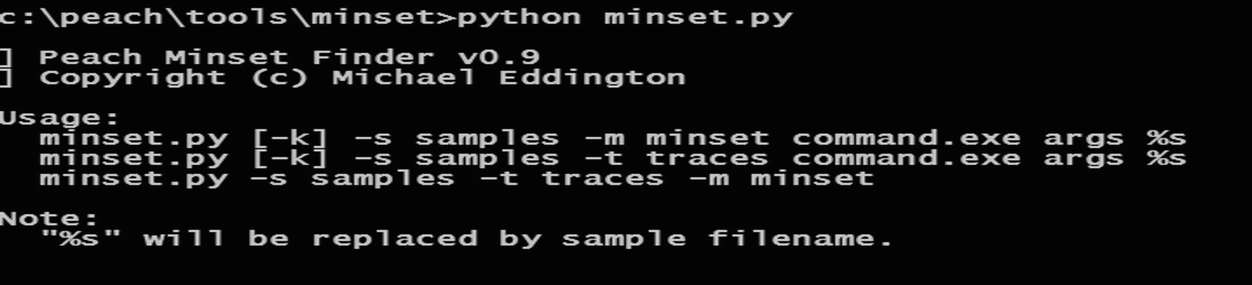
Minset script commands

Screenshot while generating the dataset
4.2 Fuzzing Tests
FileFuzz Strategy
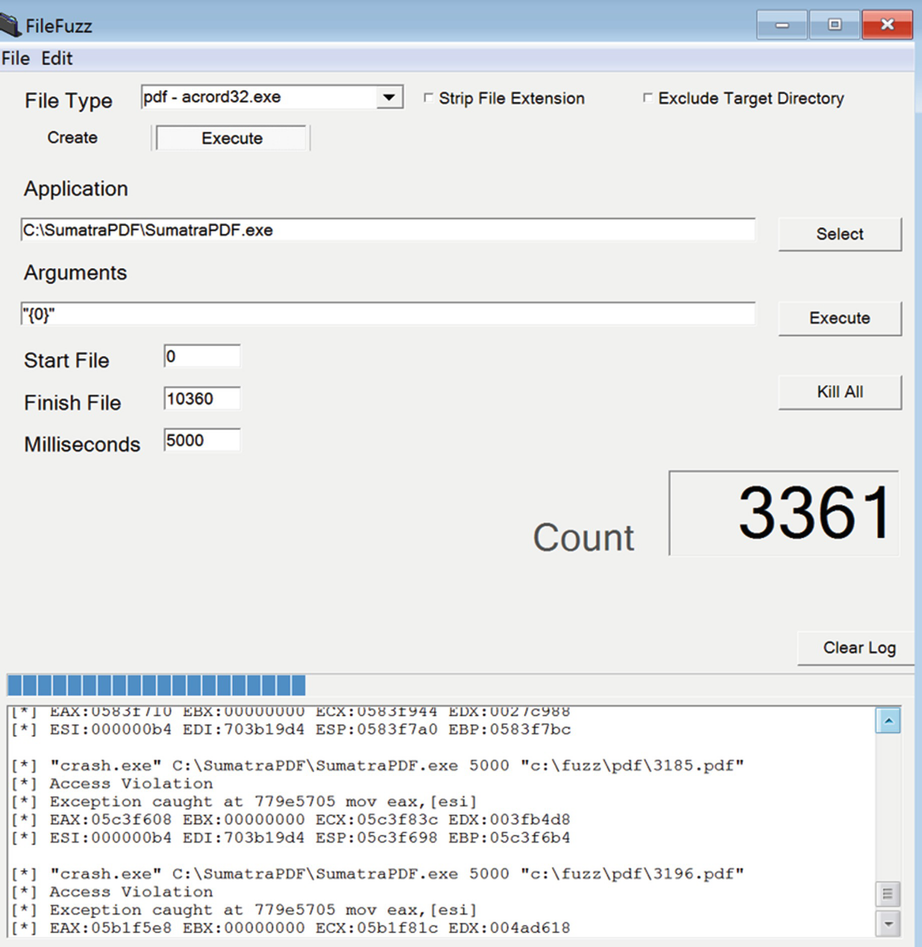
FileFuzz fuzzing process
Peachfuzz Strategy
From the new dataset generated using the python script, the script was then attached to Peach. Knowledge of the internal structure of the target software was carried out using IDA Pro and PIN. Peach required pit file (.xml) to begin the fuzzing process. The pit file was generated and modified according the Sumatra PDF functions and the input stream supported was linked to the minimum data set.
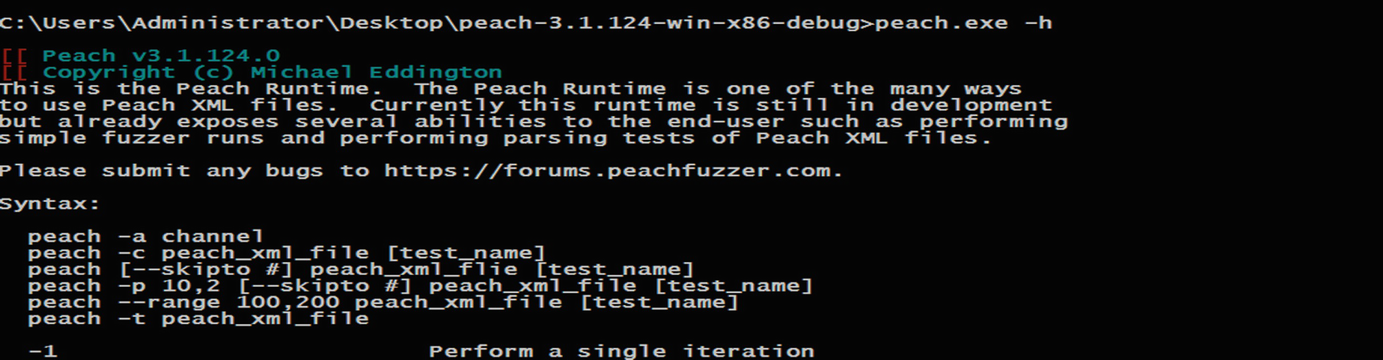
Peachfuzz commands

Peach fuzzing process
4.2.1 PIN Extract Tracer
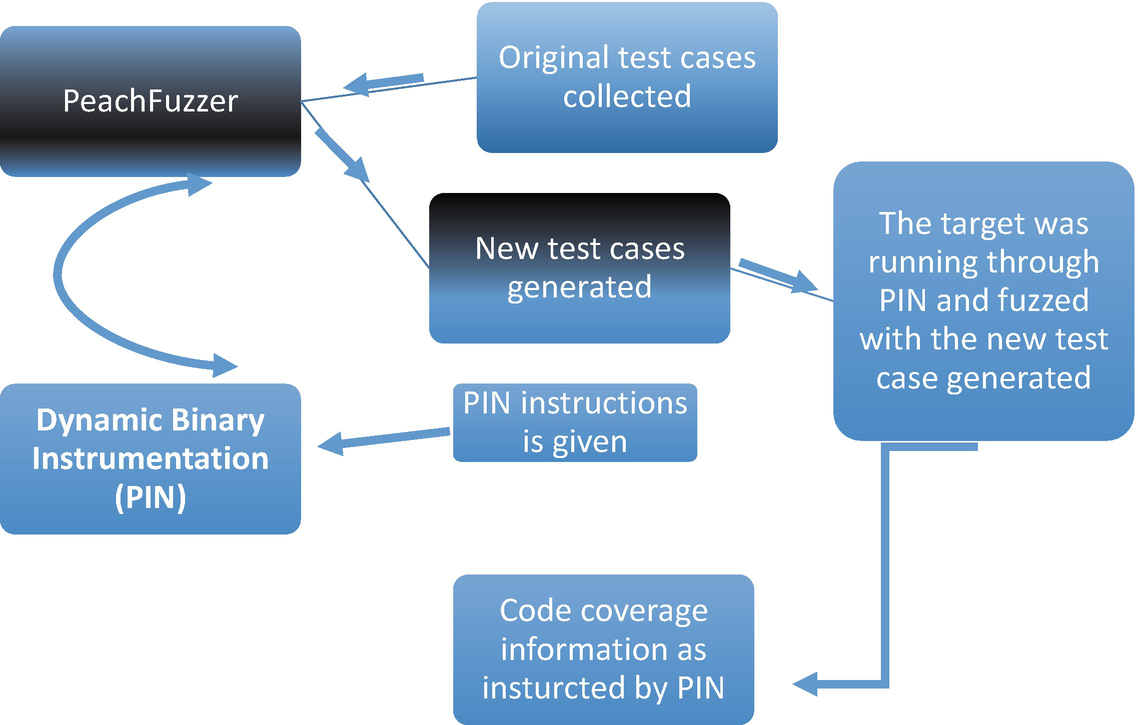
Getting code coverage information
4.3 Test Results
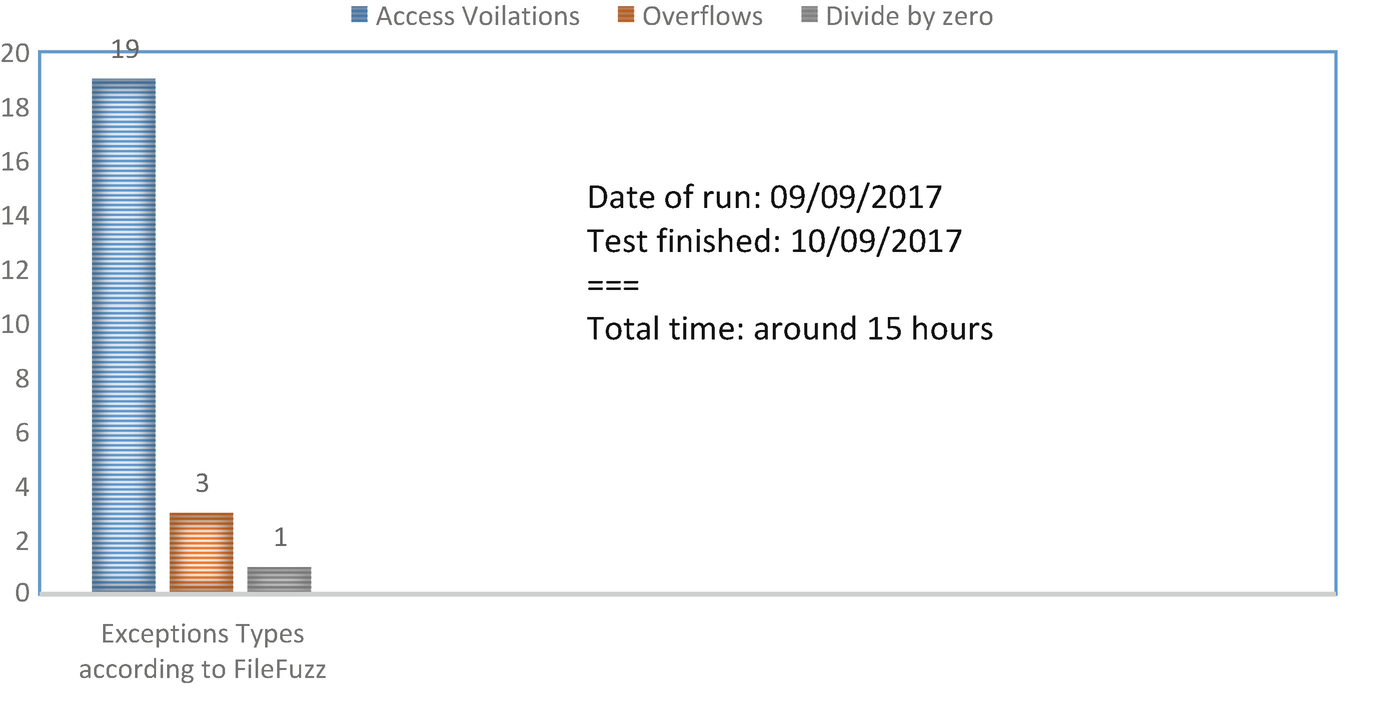
FileFuzz fuzzing results
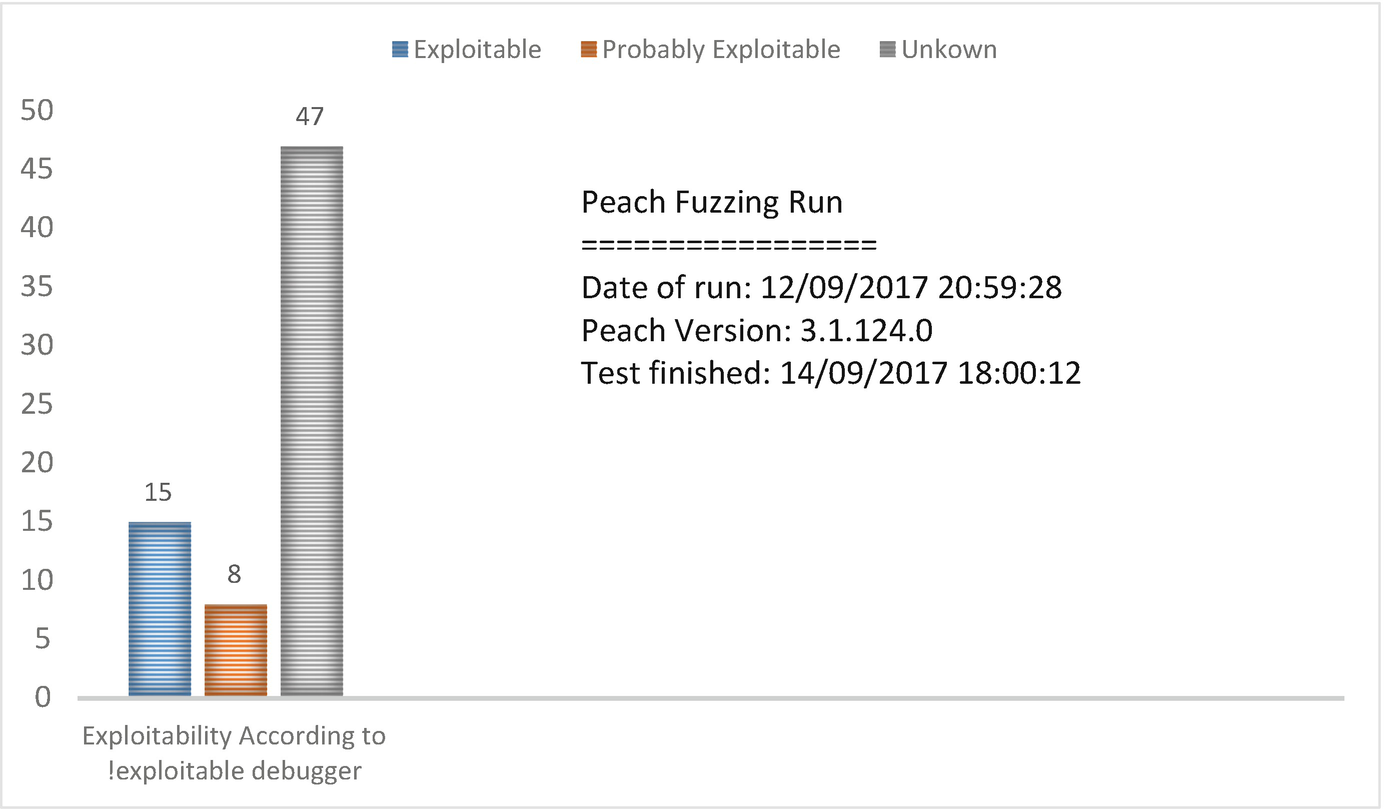
Peach fuzzing results
Peachfuzz crashes were categorized as described before by using the built-in debugger (!exploitable), which store and classified each of the faults at logs folder.6 The Chart below provides a summary of these results based on !exploitable classifications.
4.4 Analysis of Both Fuzzing Results
This section demonstrates FileFuzz exceptions analysis and Peach fault analysis using different crashes presented in Sect. 4.3. By illustrating how the data input used during fuzzing affect the fuzzing results.
4.4.1 Crash Analysis
From both of the charts presented, it was clear how insufficient FileFuzz test was. The temporary method FileFuzz used to record the exceptions on the fuzzer main interface led to loss of results already been displayed in the event of any failure and therefore, all the samples had to be tested again. In addition, the total exceptions FileFuzz produced was less than Peach fuzzer. However, it is very important to mention that the result presented from FileFuzz was tested once against our target Sumarta PDF.
Therefore, this type of fuzzing requires different rounds and different samples to achieve a better and consistent result. Furthermore, to have a valid comparison between both fuzzers this test was performed once on both fuzzers.

Display the raw hex bytes for 3196.pdf, 3084.pdf, 3185.pdf and 3160.pdf samples
After analysing the new results generated from PIN tool which displayed all the instructions and functions executed when the target ran by each of the samples mentioned at Fig. 10, by searching for the function address where crash occurs. Four different instructions were founded which caused four unique access violation exceptions, but within the same function”779e5705”.
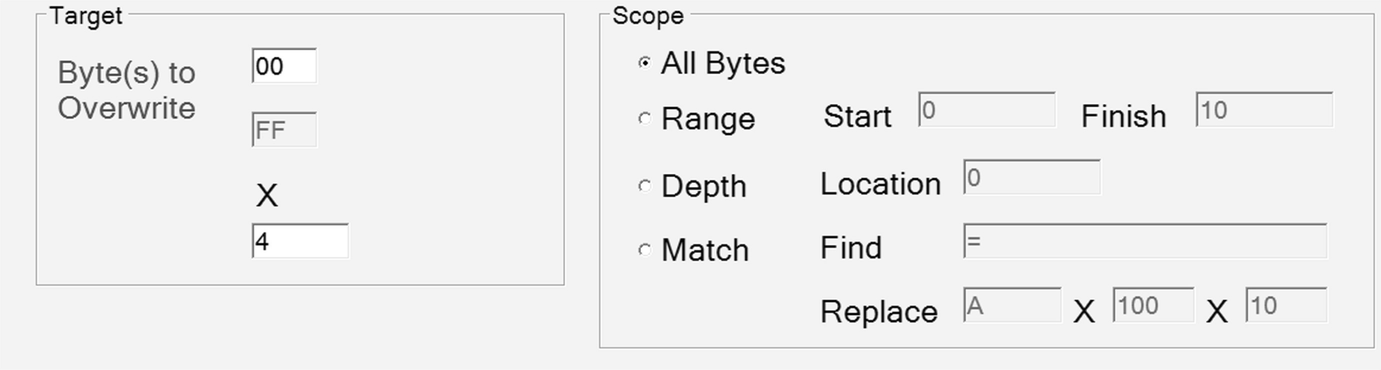
Mutation option selected to generate seed samples
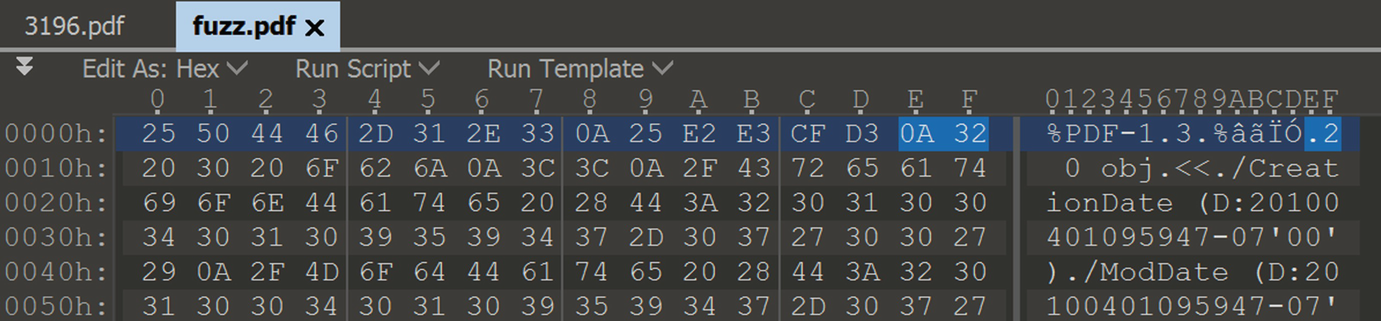
Display the raw hex bytes for fuzz.pdf
The mutational-fuzzing required a template to start fuzzing, which meant that the fuzzer will not produce codes not exists at the mother sample. For instance, PDF file format used ten types of chunks but the main template which was selected used only five of them, FileFuzz cannot produce the other five missing chunks and therefore, only the available chunks are going to be modified.
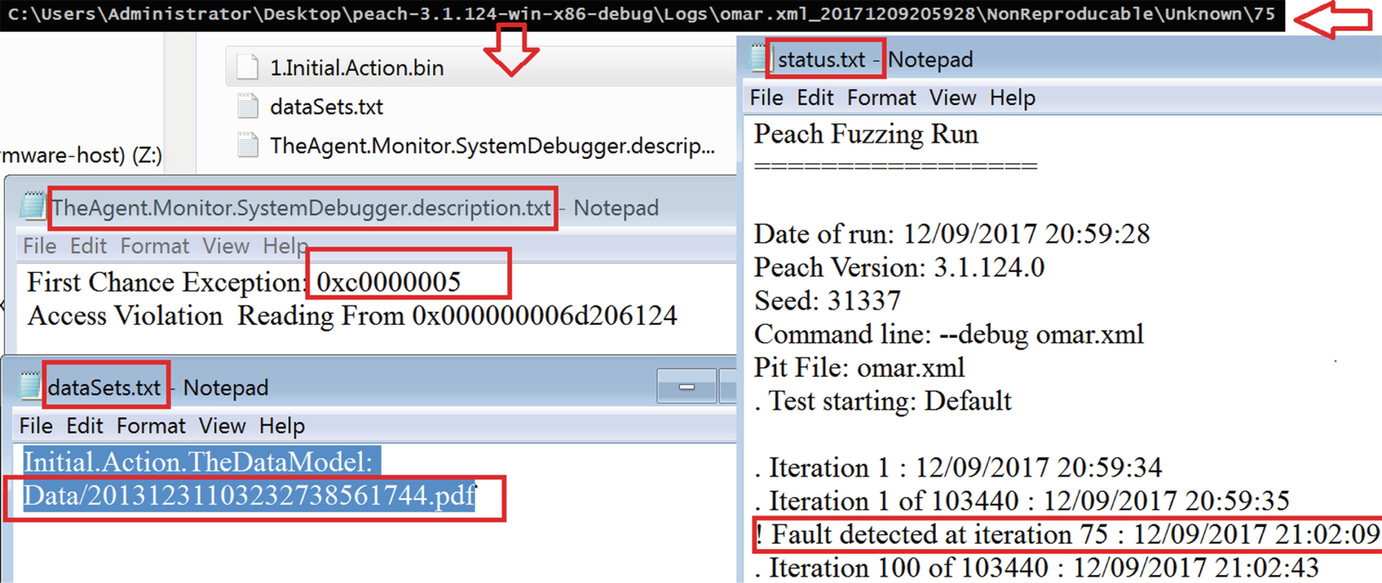
First fault Peach detected
The case is not different while investigating Peach results, as explained before, the difference between mutational and generational approaches is based on the approach used to generate the samples required for fuzzing. However, Peach required some knowledge about the target functions and the test cases required to be downloaded, which led to a higher code coverage because of the sample varieties, which has been proven by the number of vulnerabilities discovered compared to the FileFuzz fuzzer.

Find the coverage for three of the samples produced crashes
This is because of the different smart Mutators Peach support when anomalies added to the test cases, in a way that it did not affect the majority of the samples input. In contrast to FileFuzz, which generate samples according to one line only for each of the samples, as it showed in Fig. 11, which justifies the large number 10,360 of the samples that have been created.
From both fuzzer results, it can be seen that the code coverage changed based on the test cases contents, which reflects on the target features and the number of faults discovered eventually.
4.4.2 Reconstruction of Test Cases
Based on the understanding which has been concluded from previous analyses and results which illustrate a positive correlation between code coverage and detection of vulnerabilities. At this section, five different PDF samples will be created, to analyse how different features can reflect on my fuzzing results.
Discover Different Contents Coverage
This task will start by analysing the coverage of a blank PDF sample which was generated, by running the sample and each further sample against Sumatra PDF using Pin tool and additional python script.7 The result will be generated in a text file according to the instructions each sample used during execution. The blank sample coverage will be used as a metric to compare it coverage with other created samples to extract and measure the differences easily.

Sumatra PDF instructions recorded using PIN tool
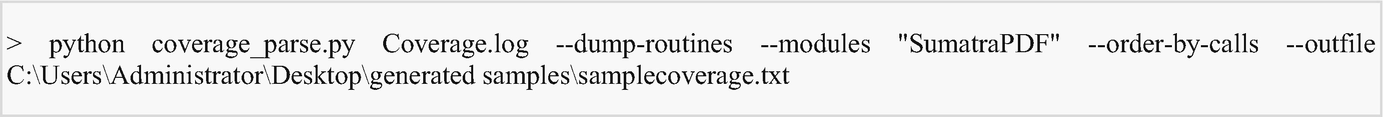
PIN tool commands
The second phase will be repeated for each of the samples created. The following figure provided a summary of the features for five different samples I have created using Microsoft word and saved as PDF.
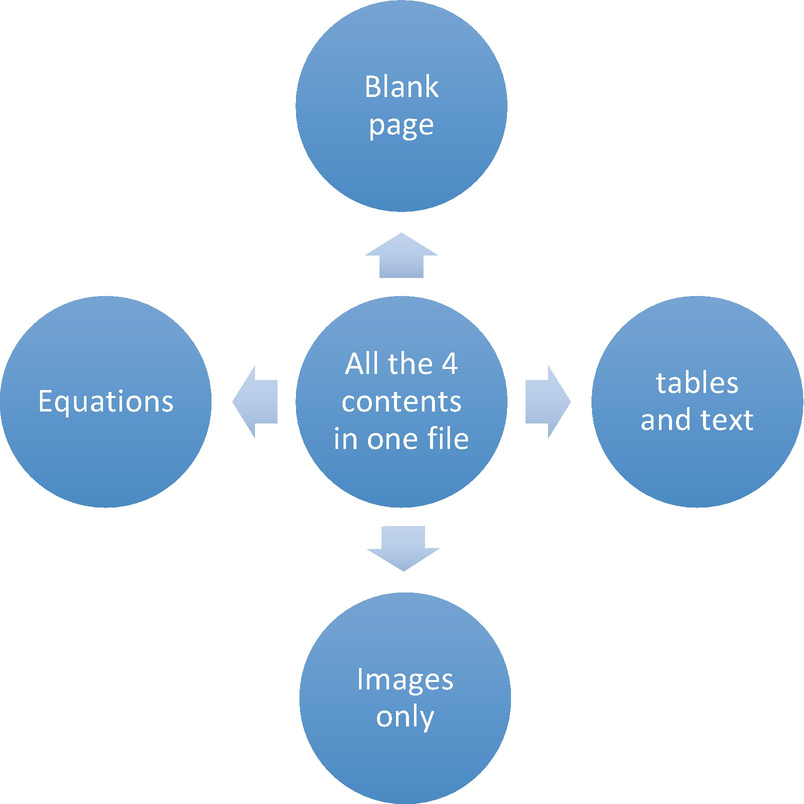
Sample features to be analysed
Coverage Results and Analysis
Based on our target structure which endeavours of displaying PDF sample content on the application main interface. According to this fact, the sample with different features in theory will result in a better coverage as this will require more functions and resources to work in parallel to display such contents.

Analysing the five samples coverage
The coverage results for each of the created features produced after conducting all the steps mentioned above were it compared to the blank sample coverage as a metric and summarised into a simple Chart below.
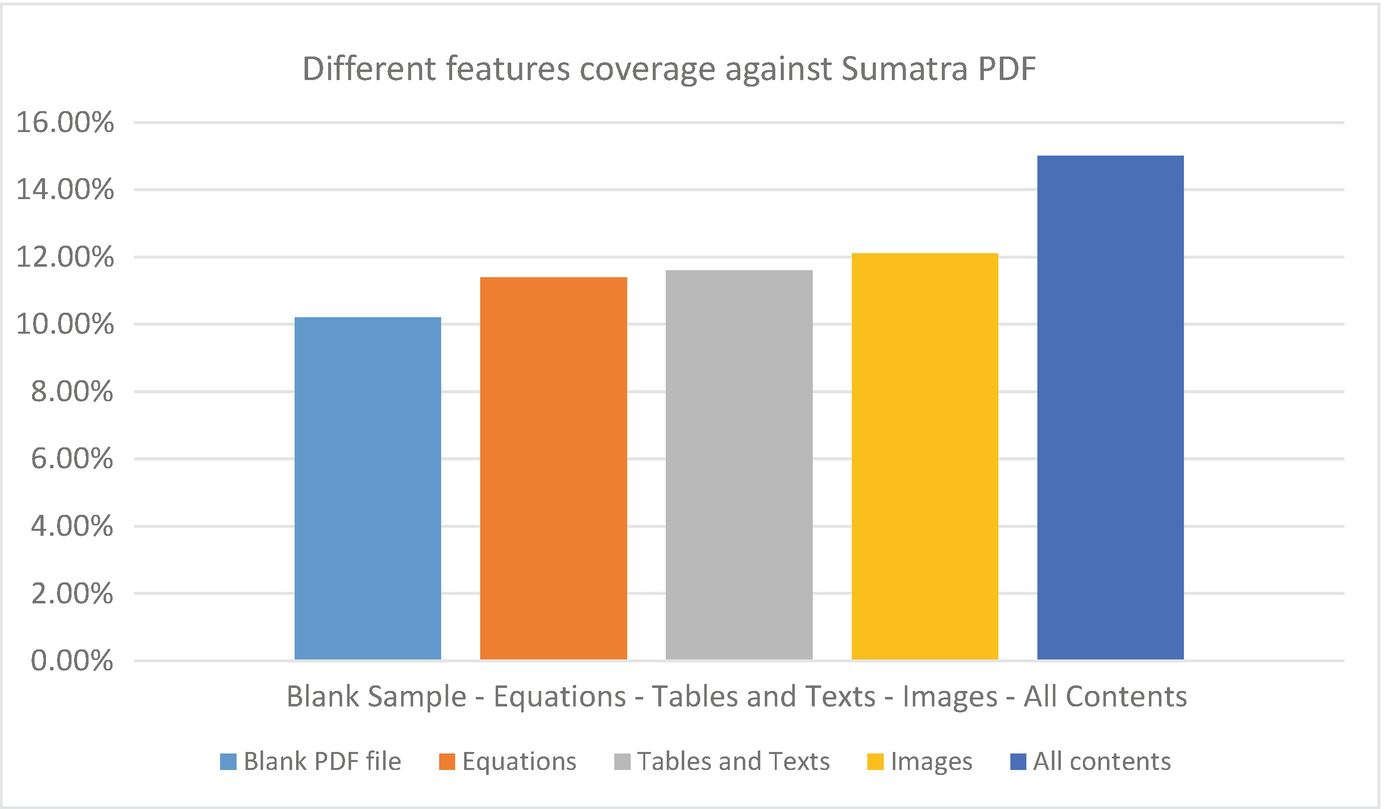
Different features coverage
To achieve a better fuzzing result after conducting multiple experiments in this research, the samples should be reconstructed and the fuzzing should be performed according to the new enhanced dataset. However, in case of using FileFuzz, different created samples should be chosen after measuring the code coverage for each and the highest will be selected. In addition, different rounds of fuzzing are required to cover as much as possible at our target functions. The research results obtained can be the basis for further researches. Especially in the process of creating sophisticated and complex samples and to create advance fuzzer with the ability to concentrate the code modifications at specific locations inside the provided sample, such idea can be applied using Peach platform, as it allows users to create their own fuzzer.
5 Conclusion and Future Work
This study demonstrated an attempt to improve fuzzing software for anomalies and how show how test cases can play a crucial role for this purpose. This provides a scope for future development of fuzzers which can be used to fuzz applications running on emerging platforms such as embedded systems running real time operating systems (RTOS) built on Windows Operating Systems. For instance, the Windows IOT, formerly Windows Embedded takes on core features of the Windows preloaded on hardware devices. In this study, different features were created and analysed for two types of fuzzers. The first task was to create five new samples with different contents, then analyse the code coverage for each of these samples. Finally, we discovered the best feature which provides the highest coverage. The result presented in Chart 3, “Different features coverage”, shows clearly that for any feature added to test cases, it would be better than a sample with no contents. Results from the combined features yielded the highest coverage compared to other samples. However, before fuzzing is started, it is necessary to work on samples according to a clear understanding of the target’s functionalities. For instance, the display contents of the target Sumatra PDF viewer are different to other document readers which reads the text from file input or console program. Therefore, the target and the sample format are important and extra consideration should be taken during the fuzz test, as this reduces the test time and the effort by inserting the correct mutated samples directly to the target functions.
Although performing generational-fuzzing approach using Peach, improves the effectiveness of mutational-fuzzing approach, it requires much effort, time and processing power. Although, FileFuzz generated the samples with one click, Peach required the samples to be download, and the time spent to complete the test is considerable higher than FileFuzz as demonstrated in Charts 1 and 2, “test Results”. The test cases generated by FileFuzz produce low code coverage and therefore less effectiveness when compared to Peach samples. In addition, FileFuzz requires one sample to begin fuzzing, while the other 10,360 samples created partially from the mother sample, as shown in the sample presented in Fig. 7. Peach required different samples to be downloaded with different features from different resources, which may not lead to realistic comparison. However, with consideration in the number of crashes discovered and the number of samples tested, it shows that some prior knowledge about the target application’s structure is required and the sample coverage which makes Peach fuzzer take precedence on this comparison. The approach could be implemented to enhance testing software embedded in IoT devices.
This work serves as a baseline for future research in which researchers could extend and develop datasets to include other samples and enhance the sample features by adding additional attributes. There are several areas of research that could be undertaken, for example: by testing the target based on a database of specific vulnerabilities built in different test cases and contained simple execution instructions.