1 Introduction
The emergence of the Cloud technology and its services offers an effective solution for many companies [1]. The amount of data that organisations deal with increases rapidly. It is becoming more and more complicated to keep up to speed with various technological solutions for organisations that want to focus on developing their business instead of investing in technology. Therefore, Cloud services are likely to become the next thriving technology business of the twenty-first century [2, 3].
However, because of its many functions and broad capabilities, Cloud may become an attractive tool for cybercriminals who may use any of its services to launch attacks over legitimate businesses [4, 5]. Various individuals as well as organised crime groups are also likely to breach Cloud services used by legitimate businesses in attempt to steal valuable data or disrupt their services [6, 7].
- 1.
Cloud is not forensics-friendly. Since it is a relatively new feature it does not have built-in forensics capabilities [8]. The data may be stored in various locations and accessed by multiple devices and users that forensic investigators may have no access to [9].
- 2.
Cloud forensics is fundamentally different from other forensic investigations. The tools, approach and training required is very different in other cases [10]. Frameworks for cyber investigations are essential and it is imperative to use them at all times while carrying out an investigation, yet Cloud forensics is a new concept and the amount of various Cloud services is rapidly growing [2, 6].
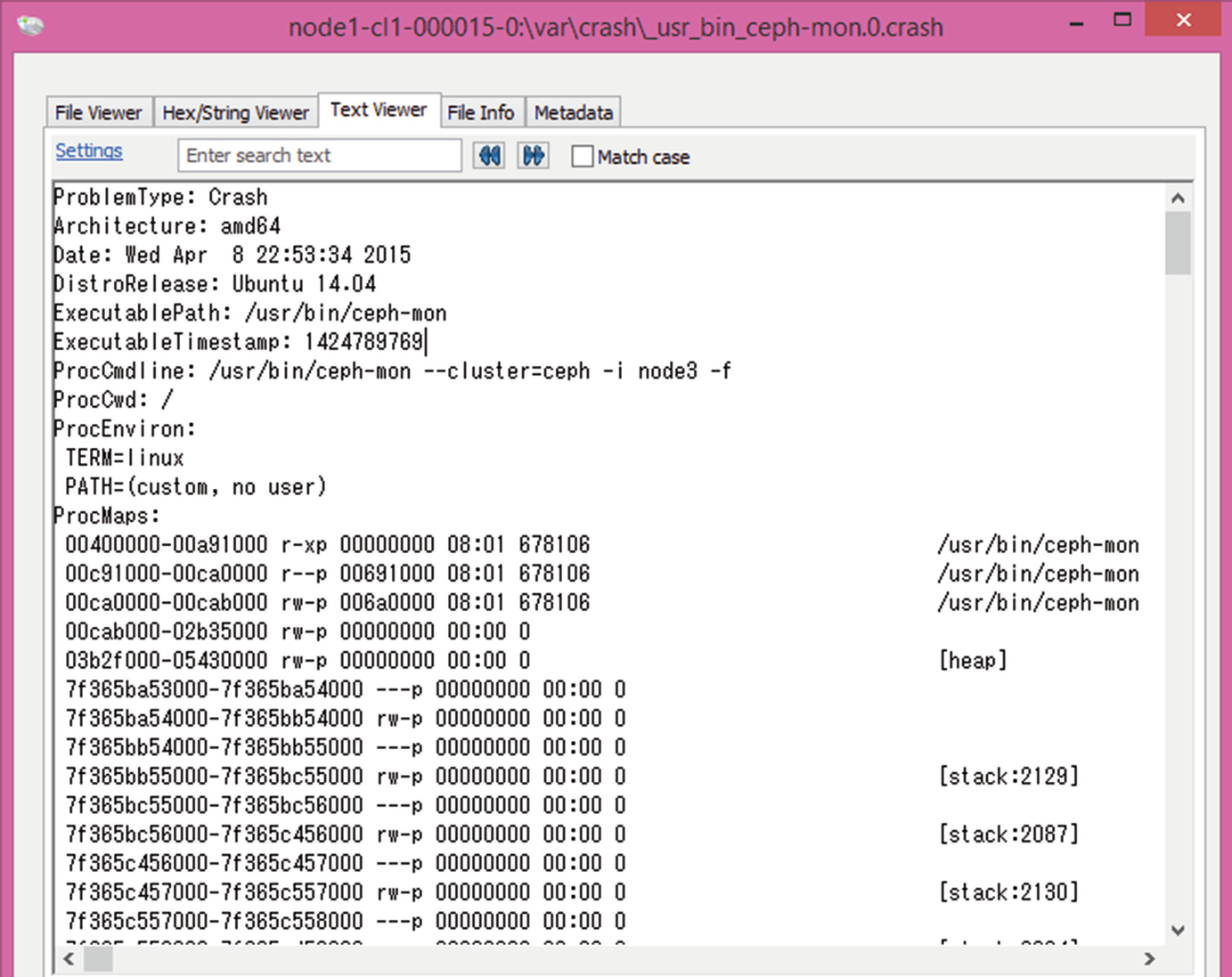
From a forensics investigator point of view, investigation of Infrastructure-as-a-Service (IaaS) will prove to be most beneficial as it includes Platform-as-a-Service (PaaS) and Software-as-a-Service (SaaS) investigation as well [11]. Ceph is presented as “a distributed object store and file system designed to provide excellent performance, reliability and scalability” [12]. Moreover, it provides object, block and file system storage in a single platform and is based on a Linux kernel. Ceph is idea for managing large amounts of data that can be easily retrieved. Among many of its advantages is its ability to self-manage and self-heal, which means that data will never be lost or damaged. Unified storage results in no silos of data and only one system must be scaled meaning that the system capacity is easier to manage. Moreover, Ceph is open source and extremely expandable. It consists of three main components: DIRectory service (DIR) or the client, Object Storage Device (OSD), and a metadata server.
- 1.
Examine what kind of configuration files, volatile and non-volatile data can be retrieved from DIR, OSD and metadata server.
- 2.
Propose processes for the collection of electronic evidence from Ceph.
- 3.
Validate the applicability of the proposed model by B. Martini and R. Choo [2] to a forensic investigation of the Ceph distributed file system.
The rest of the paper is organised as follows. Section 2 overviews the related work on previous researches and analysis of relevant existing issues in IaaS forensics. Section 3 describes the investigative framework that is devised for the investigation of Ceph file system. The environment and experimental setup are explained in Sect. 4. Section 5 reports and analyses the results and findings. Lastly, Sect. 6 gives the conclusion and provides recommendation for future research.
2 Related Work
The concept of Cloud forensics is to assist the forensic community to create suitable approaches and frameworks to analyse various Cloud connected services, data stored on the Cloud and devices connected to the cloud infrastructure [13]. Attempts to cover various fields and techniques in Cloud forensics have contributed to the body of knowledge in the field [14]. Cloud offers increasingly more services and there is a growing number of devices connected to the Internet. It is safe to predict that with the dawning era of the Internet of Things (IoT) and the Internet of Everything (IoE) there will be even more devices and tools that generate big data [15, 16], which further complicates forensics challenges [17, 18]. The increasing use of Cloud services to host all these data inevitably presents digital investigators with a growing amount of data for a forensic investigation [19]. This is likely to become the main problem of services that are specifically meant for processing or storage of big data, and Ceph is exactly this kind of service [20]. Moreover, emergence of new vectors of attack such as Distributed Denial of Services [10], Ransomware [21], malware [15, 22, 23] and Trojans [24] further complicated cloud forensics activities.
Out of all the researches published so far, only a handful of studies [2, 25–27] currently exist in the area of distributed filesystem forensics. It is evident in the literature that the majority of existing research focus on client side analysis [28–30]. One explanation may be the difficulty in getting cloud server logs for examining historical user actions [31]. Service providers do not want to release this information for their client’s protection as logs may provide information across multiple tenants [32].
Some researchers have already suggested the concepts of digital Forensics-as-a-Service (FaaS), where forensic investigation would be carried out by certain software, ridding an investigator of time consuming processing of terabytes and petabytes of information [6, 33]. No doubt, it will be beneficial for the necessary data crunching and forensic data storage, however it is hard to predict if the currently available software will satisfy the requirements of a forensics investigation where the environment is rapidly changing [34].
Creating frameworks and methodologies for the investigation of Cloud services and devices available will require significant efforts in comparison to the speed that the new technology is created and introduced to the consumer market. No doubt, a unified approach and framework is something that forensic investigators should be looking for [35] as it will not only cover all possible areas where valuable information could be found, but also help to make sure that data is collected in the order of volatility and can be presented in the court of law in a credible manner [36]. There have been attempts to create high level framework for Cloud forensics, specifically a more detailed framework has been introduced by B. Martini and R. Choo [2] as part of their investigation of XtreemeFS. This research aims to validate their framework by carrying out an empirical investigation of CephFS according to their methodology, this way supporting the emergence of a broadly accepted cloud forensics investigation framework.
3 Cloud Forensics Framework
- 1.
Evidence Source Identification and Preservation. The primary objective of this stage is to identify sources of evidence. The main sources of information will be the client system, either stored locally on physical devices or on server nodes, which would form part of the back-end service infrastructure.
- 2.
Collection. This stage will involve collection of data identified in stage one above, from locations such as memory, virtual and physical disks. The disparate deployment model means that this phase can be more complex with a distributed file system than it would be with other models (such as client server).
- 3.
Examination and Analysis. The examination phase will glean an understanding of the component parts of the file system and their inter-relationships. Analysis will provide the intelligence required to achieve reconstruction of the data collected in stage two, which should facilitate forensically sound recreation of the original user data.
- 4.
Reporting and Presentation. Whilst not intended for legal scrutiny, we plan to document all processes tools and applications used, together with any known limitations.
For identifying and collecting evidence from the Ceph file system, we follow the method proposed by Martini and Choo [2], which comprises the following stages:
3.1 Stage 1: The Location, Collection and Examination of DIR
- 1.
Identifying the location(s) of the directory services
- 2.
Preserving and collecting data from these locations
- 3.Analysis of the Directory service metadata data to identify
- (a)
The file system components being utilised by Ceph such as stored data, metadata and clusters architecture
- (b)
The locations of these file system components
- (a)
- 4.
Post-analysis documentation to support any subsequent analysis, reporting and enquiry related to provenance and chain of custody. In this stage, details for each of the component nodes, such as IP addresses and unique id’s and node type, are recorded.
It is essential to not that prior to commencing the investigation, we did not know whether the Directory Services for Ceph are stored within a centralised location, such as dedicated directory server(s), or distributed across multiple peer to peer nodes within the system.
3.2 Stage 2: The Location, Collection and Examination of Metadata Cluster
Within distributed file systems, Metadata (all types of data other than file content), are commonly stored in a Metadata Replica Catalogue (MRC) [1]. The MRC is therefore likely to contain metadata related to the volumes including filenames, ownership and permissions, access and modification information.
- 1.
Locating any server(s) storing metadata
- 2.
Collection of the identified metadata from these locations
- 3.
Analysis the collected metadata to identify items (files, directories or volumes) of interest to forensic investigation
3.3 Stage 3: The Location, Collection and Examination of OSD
- 1.
The location, selection and collection of those specific devices or logical datasets containing data of interest to our investigation
- 2.
Potential reassembly of any fragmented data sets into the original source files
We intend to pay particular attention to forensic preservation techniques, the analysis of temporal data and log collection. Consideration will also be given on whether to make logical collection from client nodes or physical collection from the underlying data repositories, which is likely to require file re-assembly to recreate the original user data.
4 Environment and Experimental Setup
4.1 Ceph Overview
Ceph is an open source, scalable, software-defined storage system [40] in 2006, as an alternative to existing data storage projects. Its main goals are to deliver object, block, and file storage in one unified system, which is highly reliable and easy to manage. Ceph is characterised by its high scalability without a single point of failure and high fault tolerance, due to the fact that all data are replicated.
4.2 Ceph Filesystem
The Ceph file system, is also known as CephFS and it is a POSIX-compliant file system that uses the Ceph storage cluster to store data. CephFS provides increased performance and reliability as its store data and metadata separately.
Ceph file system library (libcephfs) works on top of the RADOS library (librados), which is the Ceph storage cluster protocol, and is common for file, block, and object storage. CephFS requires at least one Ceph metadata server (MDS), which is responsible for storage of metadata to be configured on any cluster node.
It is worth of highlighting the fact that CephFS is the only component of the Ceph storage system, which is not currently production-ready.
4.3 Ceph Storage Cluster
The Ceph Storage Cluster is the main part of each Ceph deployment and is based on RADOS (Reliable Autonomic Distributed Object Store). Ceph Storage Clusters consist of two types of daemons: a Ceph OSD Daemon (OSD) and a Ceph Monitor (MON). There is no limit to the number Ceph OSD’s, but it is recommended to have at least one Ceph Monitor and two Ceph OSD Daemons for data replication. Ceph OSD Daemon is responsible for storing user data. It also handles data replication, recovery, backfilling and rebalancing. It also provides monitoring information to Ceph Monitors by checking other Ceph OSD Daemons for a heartbeat. Ceph Monitor maintains maps of the cluster state, including the monitor map, the OSD map, the Placement Group (PG) map, and the CRUSH map. Ceph maintains a history of each state change in the Ceph Monitors, Ceph OSD Daemons and PGs.
4.4 Environment Configuration
Environment configuration
Ceph node configuration | Environment |
|---|---|
Operating system | Linux Ubuntu 12.4 |
Ceph distribution | Giant |
Utilised forensics tools
Used software | Version | Function |
|---|---|---|
HxD Hexeditor | 1.7.7.0 | Helped to see text in hex |
CapLoader | 1.2 | Used for carving out information from memory files |
Wireshark | 1.12.4 | Used for network traffic analysis |
Vmware Workstation | 11 | Used to collect the disk images |
OSFMount | 1.5 | Used to mount the images as physical drives on the computers. |
Ext2 Volume Manager | 0.53 | Helped to read Linux drive on Windows machines |
OSForensics | 3.1 | Used for majority of DIR, Metadata and OSF investigations |
Autopsy | 3.1.2 | Used for investigation of DIR and the way data is distributed across the filesystem |
Meld | 3.12.3 | Used for GUI comparison of disks |
5 Findings and Analysis
- 1.
Node set up
- 2.
Data copied to cluster
- 3.
Data copied from Filesystem to a local folder
- 4.
Data moved to cluster
- 5.
Data moved from Filesystem to a local folder
- 6.
Ceph removed
A VMware snapshot of each virtual machine was taken following completion of every activity. In order to examine the drives, we then recreated the 30 disk drives (VMDKs) for each node as they would have been at the point of snapshot creation (using VMware’s 11 utility). For each of the 30 drives, we then generated hashes to identify where changes had occurred on each respective. A comparison of these hashes using a signature comparison highlighted modified, deleted and new files between any two virtual machine states. The drives were then mounted in read only mode and examined using hex editor, file comparison tools and forensic frameworks.
- 1.
The configuration of our Ceph cluster
- 2.
The parts of the local drives affected during normal Ceph operation
- 3.
The locations in which user data is stored within a Ceph cluster
- 4.
The ability to read and recover data from within the Object Storage Devices
- 5.
The Object Storage Devices themselves
- 6.
The location of Metadata
This procedure provided a better insight into how Ceph stores data and how it moves around the Filesystem when a variety of actions are performed there. We believe that these various actions should cause the system to behave in a certain way and leave traces of system information that could be valuable for a forensic investigator. It is also a way to identify whether the suggested framework can be applied to every file system or is there any variation and to what extent. Framework recommends paying attention to the three kinds of data, while conducting the investigation that could be of interest across all the parts of a file system, including, volatile environment metadata, non-volatile environment data and configuration files.
5.1 Directory Services

File title search within raw data on OSForensics
The framework suggests that in DIR we should be looking to find IP addresses that accessed the data after the installation of the file system, the Unique User Identifiers (UUID) and the Service Registry and Configuration files. It was possible to identify the IP addresses of the nodes that were used for the configuration of Ceph.
With CapLoader, we were able to see the IP addresses as well as ports and hosts used within Ceph cluster. Moreover, we were able to recover data associated with the copy, move and delete operations such as the name of the file and its content and this will be detailed in the last section on OSD.
The results with Autopsy showed that there are multiple retrievable IP addresses, email addresses and URLs remaining on Ceph. The tool also shows the image snapshots these addresses remained on or their correlation with the actions performed on the original data. This is particularly interesting because in our case the snapshot −000015.vmdk was the snapshot after files have been removed from Ceph and all data should have been removed.
In addition to this, the original data have been discovered on one node, while the email addresses were found in each disk. This gave us an understanding that the contents of the data in the original files will not be stored in one location and therefore are spread across multiple nodes. As a consequence, we made an assumption that this was what happened with all of the data, as well as metadata, and we tried to prove or reject our assumption as we went along investigating Ceph.
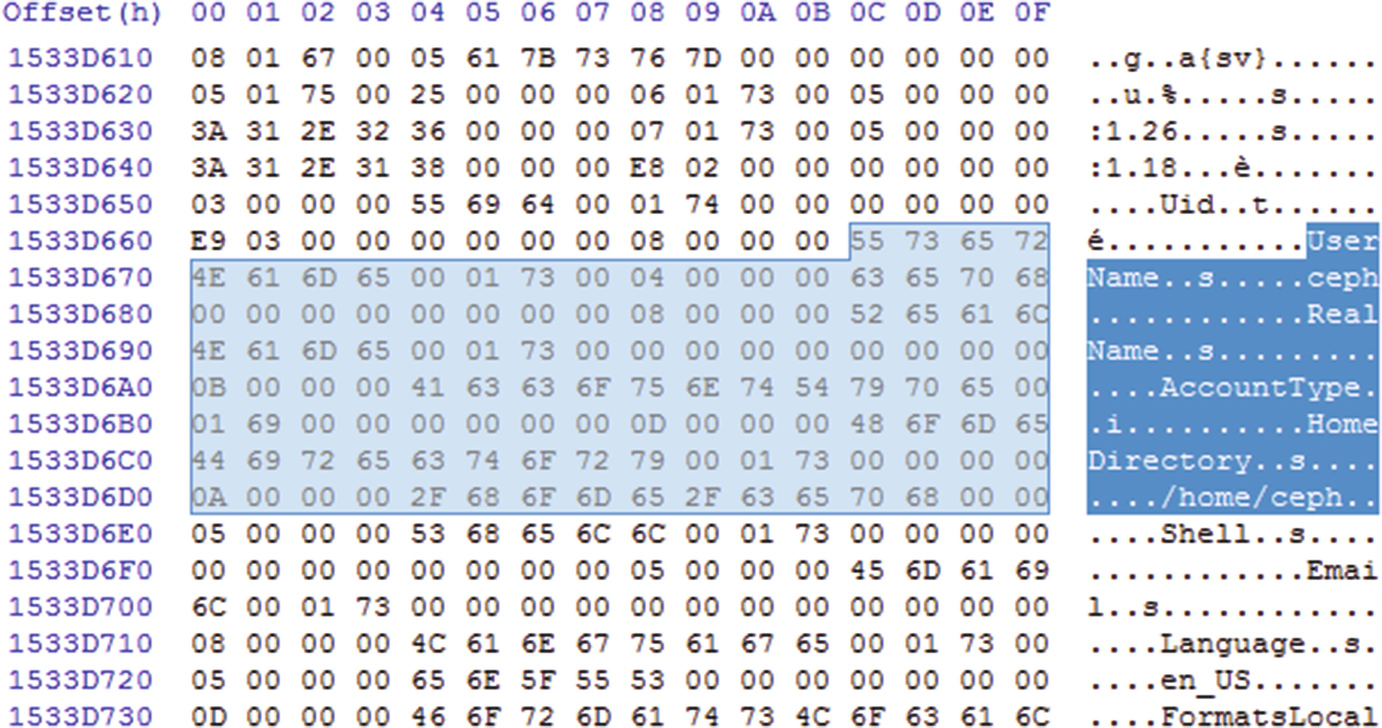
Ceph user credentials
Martini and Choo [2] also suggest that the service registry data which is of interest resides within one main directory. However this is not the case with Ceph. Having analysed the signatures of each image and compared them manually, we discovered that there are two main directories together with their subdirectories where most of the changes have been identified within all of the nodes, i.e., /etc and /var.
As researchers have identified, /var may contain some valuable logging data and should be analysed. In the case of XtreemFS it did not provide any valuable information. However, in the case of Ceph it contains the metadata as well as OSD details and this will be discussed in the next section. /etc normally contains configuration files for programs that run on Linux. We were also able to determine that network connection files and the details in these two directories are replicated across all of the nodes.

The folder structure and SSH key on OSForensics
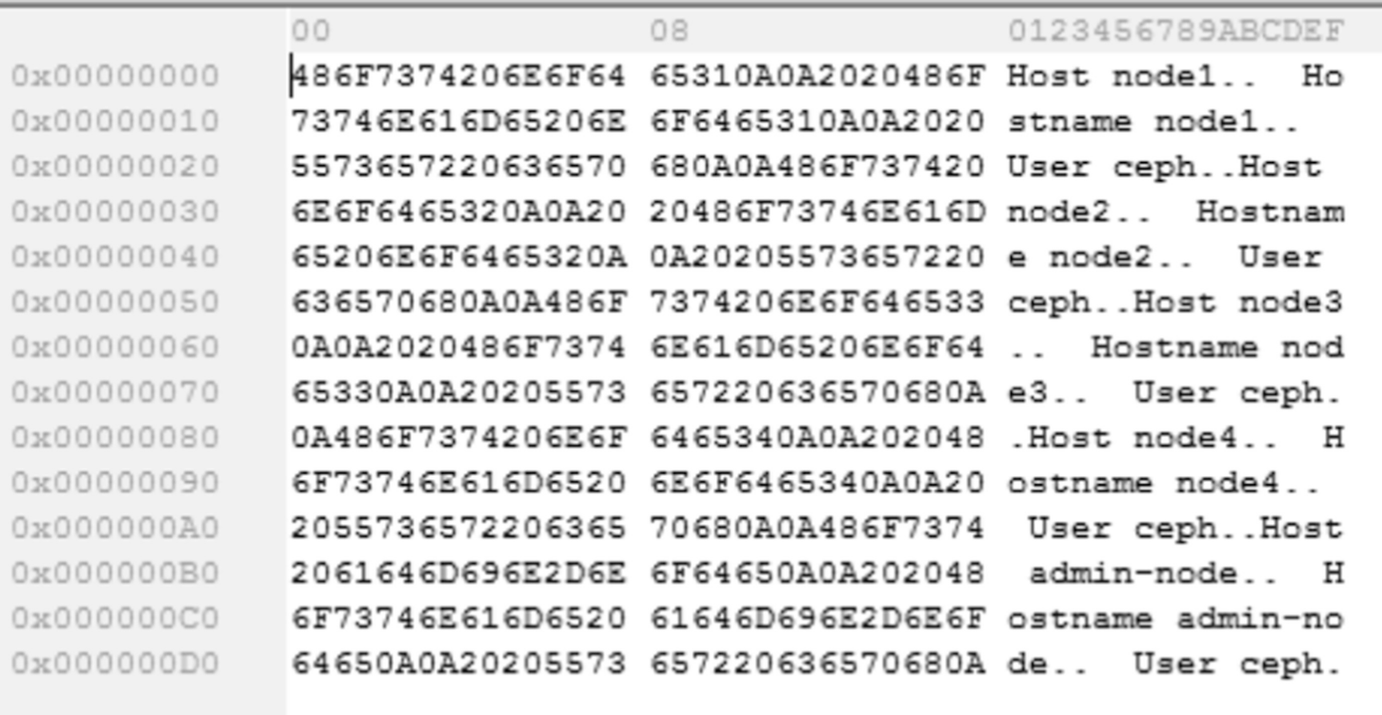
Hosts and user names displayed in SSH config file

5.2 Metadata Cluster
The forensics framework of interest identifies one location where metadata information could be stored on a file system and gives a variety of data to look for. However, Ceph seems to be sharing several folders within /var directory with OSD. It required a manual process of looking through the directories and files to be able to discover metadata as it seems to be spread across several folders. However, this snippet of data is available on all nodes probably because of the nature of the system itself as the data are called by monitors on each node and they must know where it is located.

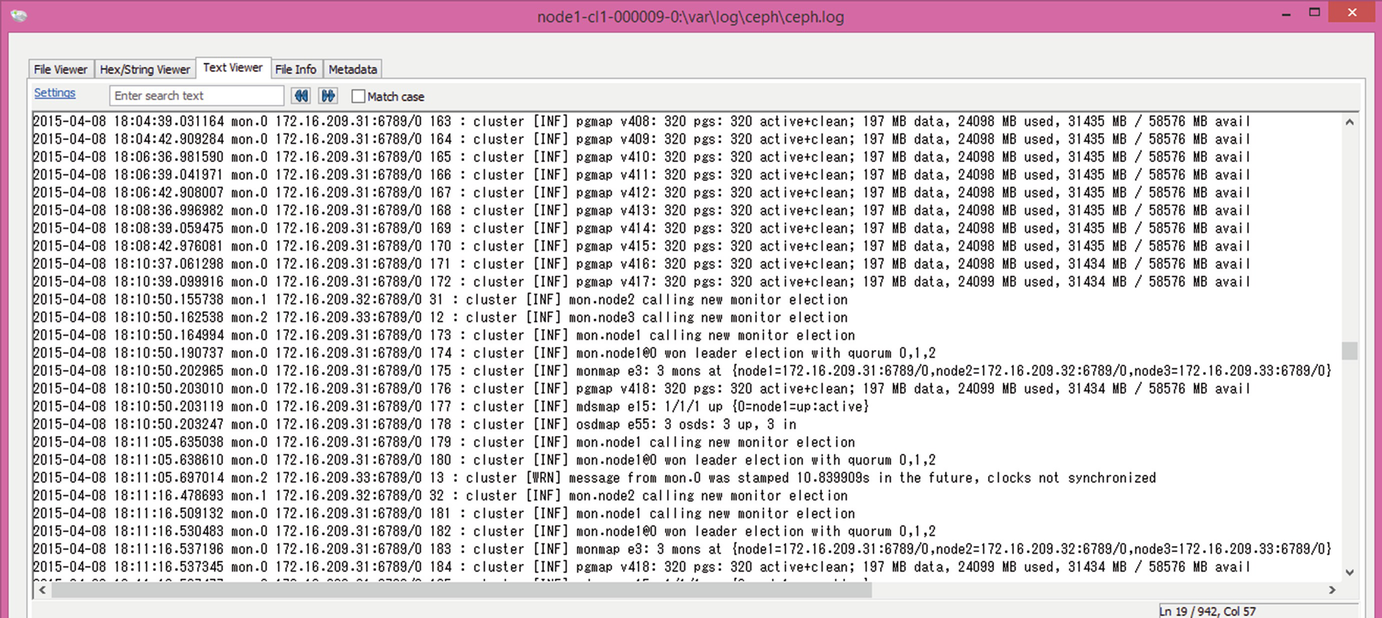
Folders that contain metadata with monitor log data
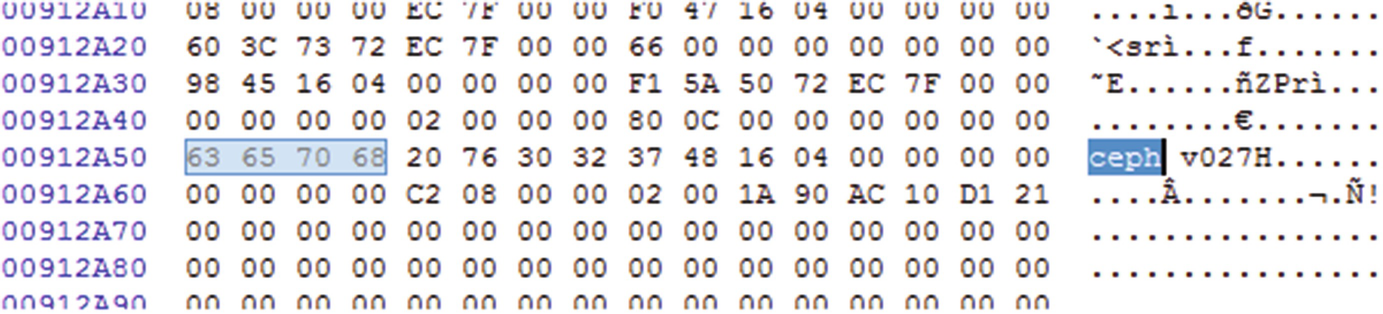
Monitor election in metadata logs
For a long time we were unable to discover the database where metadata is stored because the location was not that obvious: /var/lib/ceph/mon/ceph-node3/store.db/.
Permission levels on Ceph
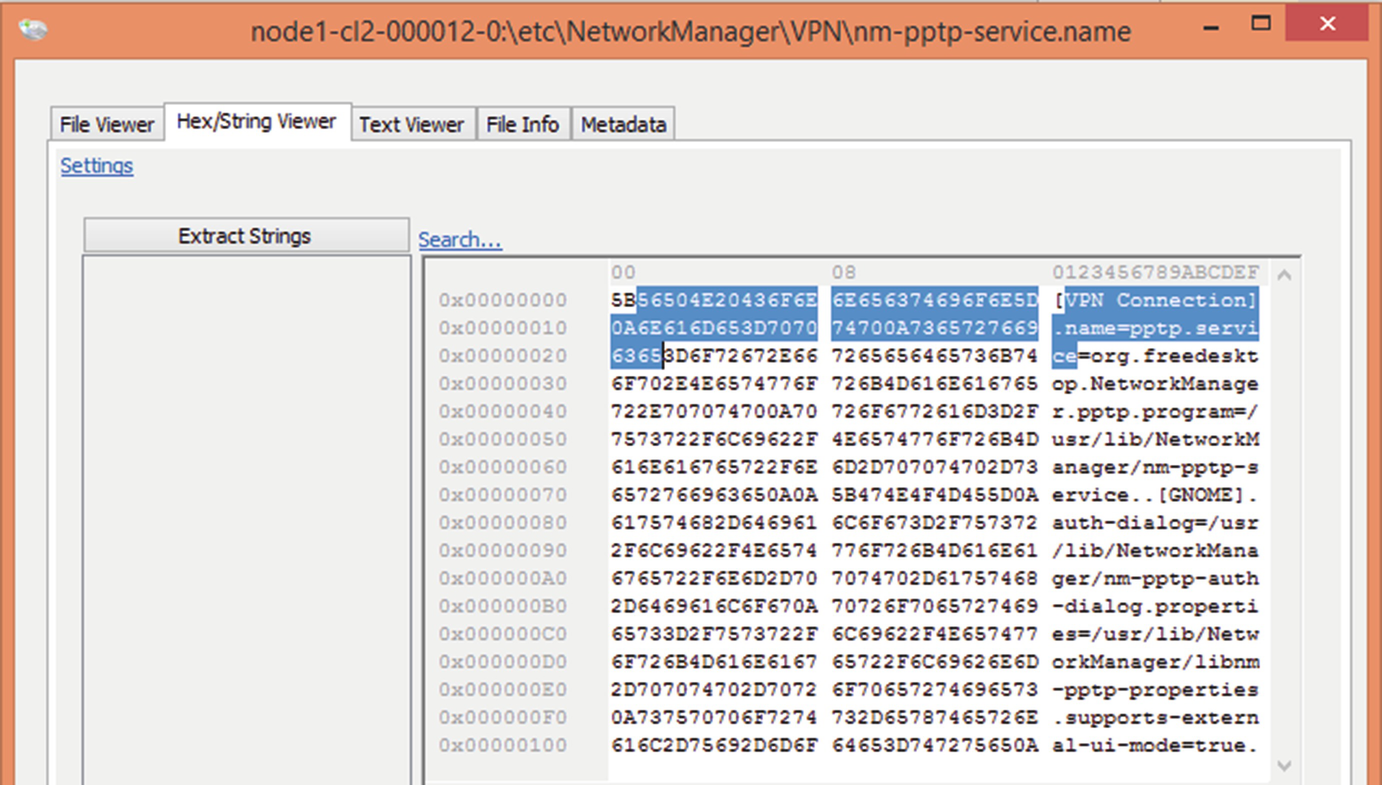
VPN connection information with PPTP protocol listed
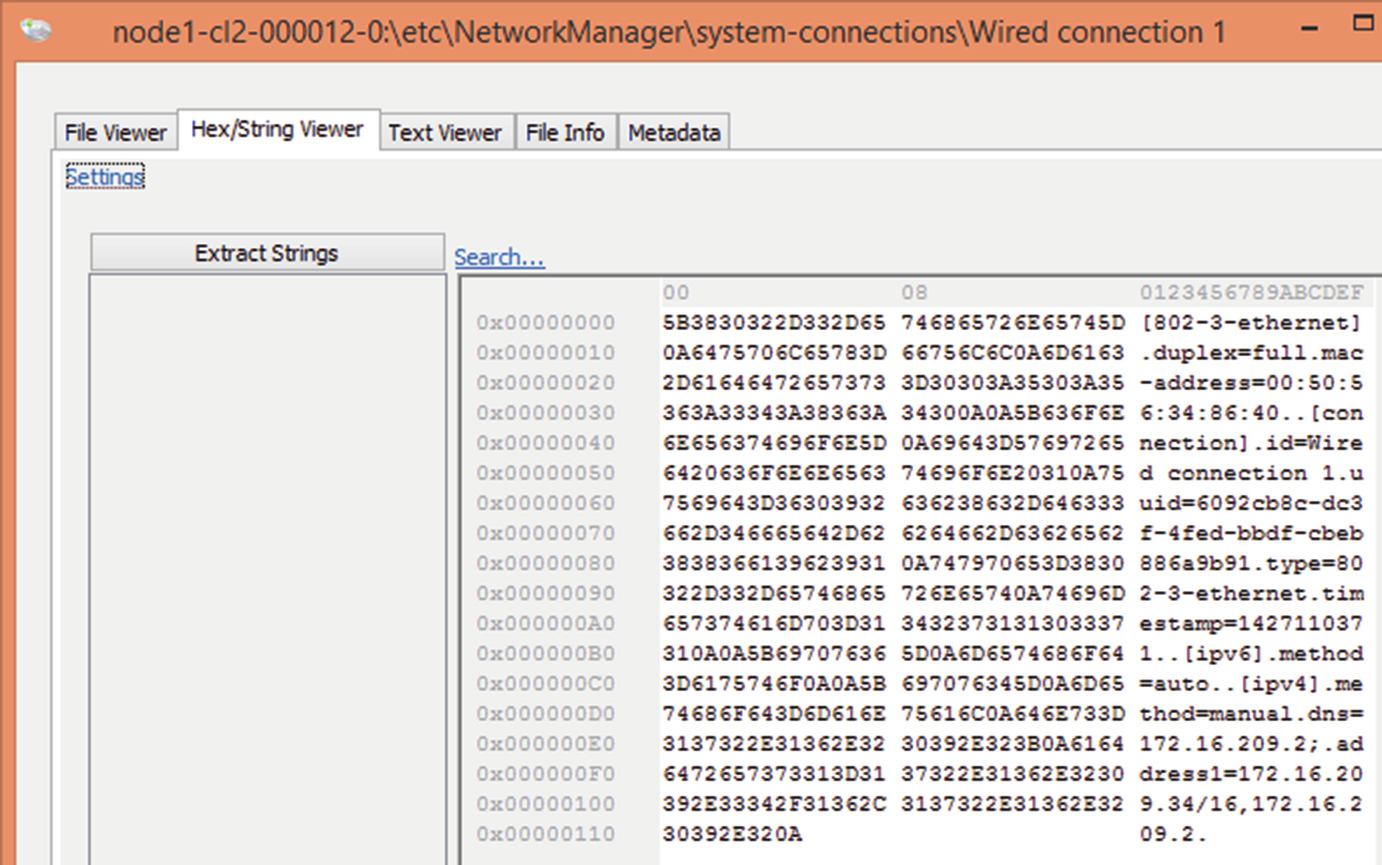
Network information on /etc
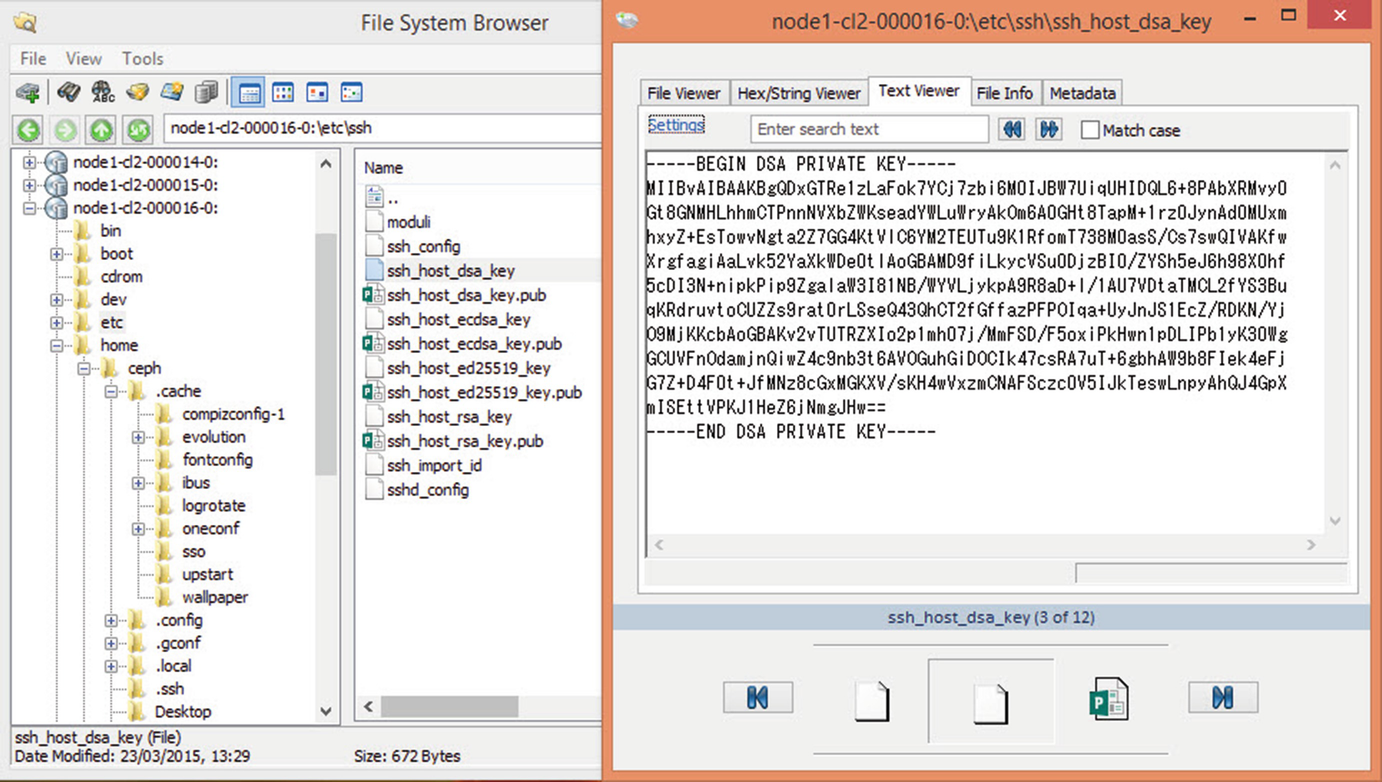
Ceph authentication private key
5.3 Object Storage Device
The proposed framework was not very helpful in trying to identify how Ceph stores its data or where it is actually located. The framework rather addresses what is applicable for XtreemFS, but Ceph seems to be behaving in a slightly different way. The way Ceph distributes the data and replicates it, does not seem to fit into any type of RAID levels. It stripes the data like RAID 0, yet the data do not take physical space and is not shared or distributed on any other disk. Data objects are stored on one disk, yet the system registers each file in so called journals using CRUSH algorithm. Objects are assigned to individual OSDs using CRUSH, which is defined by a CRUSH map and determined at the point of installation.
The distributed nature of the CRUSH algorithm is designed to remove a single point of failure and is distributed across the nodes within the cluster. CRUSH is predictable meaning that, given certain inputs (a map and a placement group), any node with access to the CRUSH algorithm can calculate the names and locations of the individual objects, which comprise a file loaded to the Ceph File system by a given user(s). To locate an object within the Ceph filesystem, CRUSH requires a placement group and an Object Storage Device cluster map. This eliminates the need for the distribution of location based metadata across nodes within the cluster and the requirement for a central single metadata repository, which would form a bottleneck.
- 1.
In a “free block”. In this example within sector 1086152, which is most likely to be the Ceph object.
- 2.
Within a journal file stored in in var\local\osd\journal.
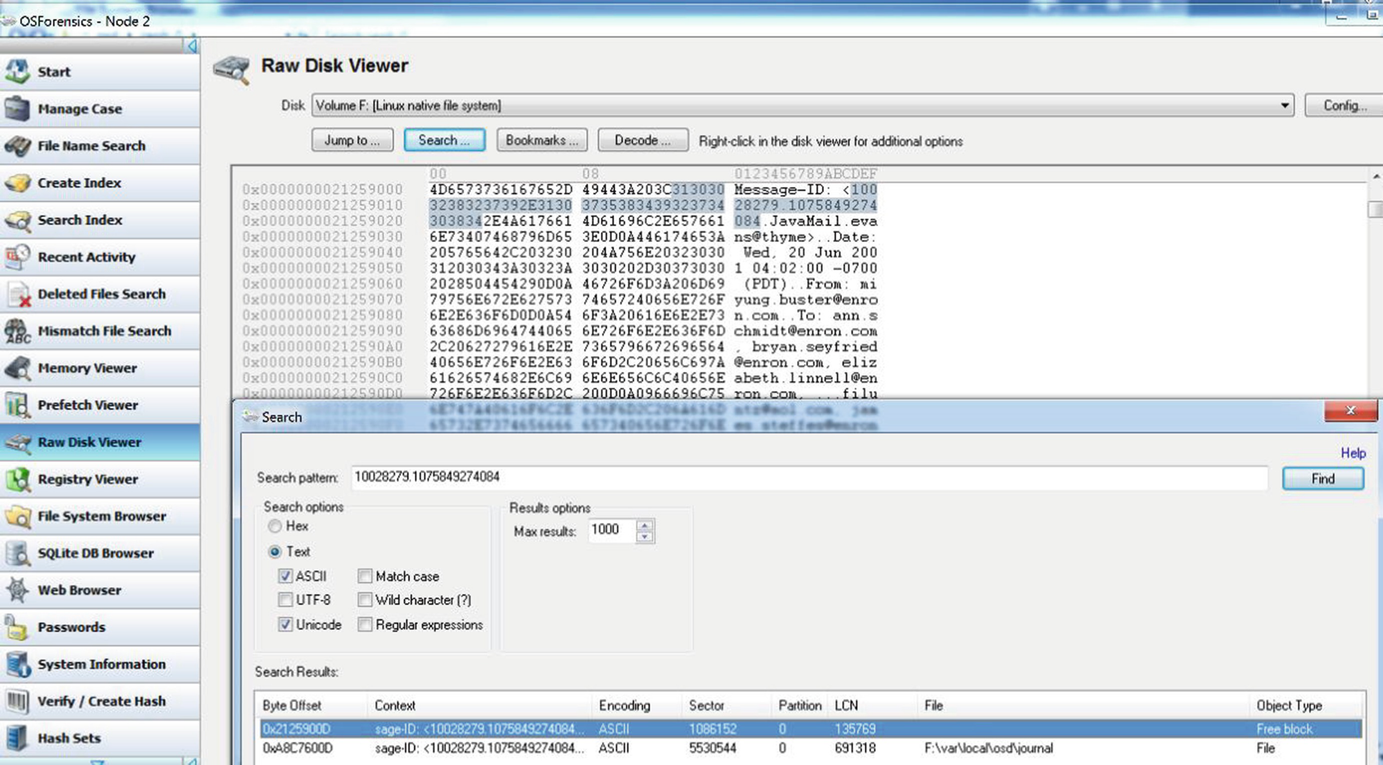
Message visible in plain text if stored in a block/Ceph object
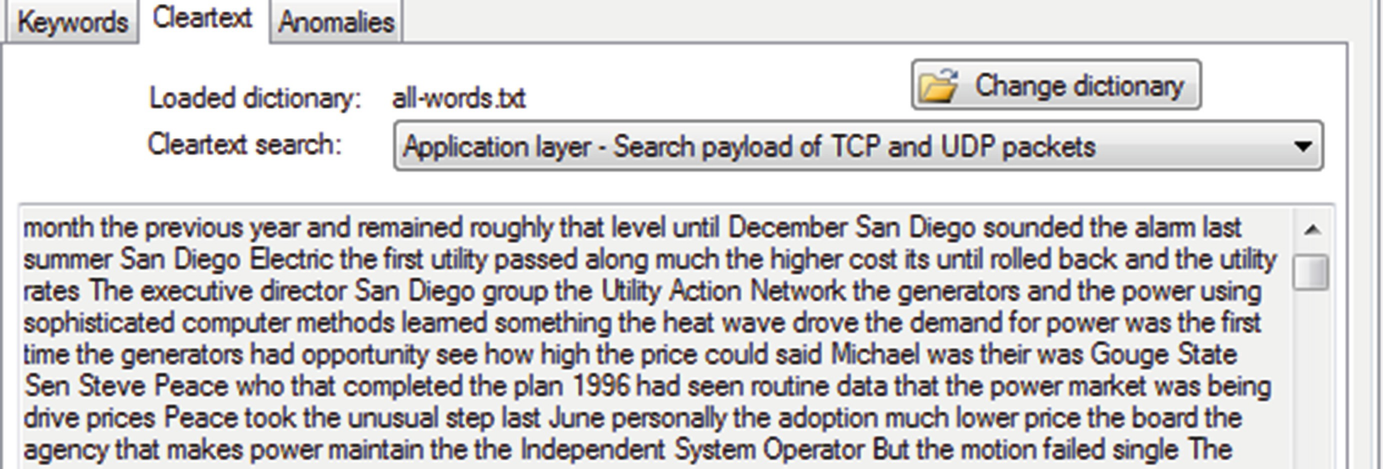
Plain text data via Network Miner

Message displayed in plaintext on Autopsy
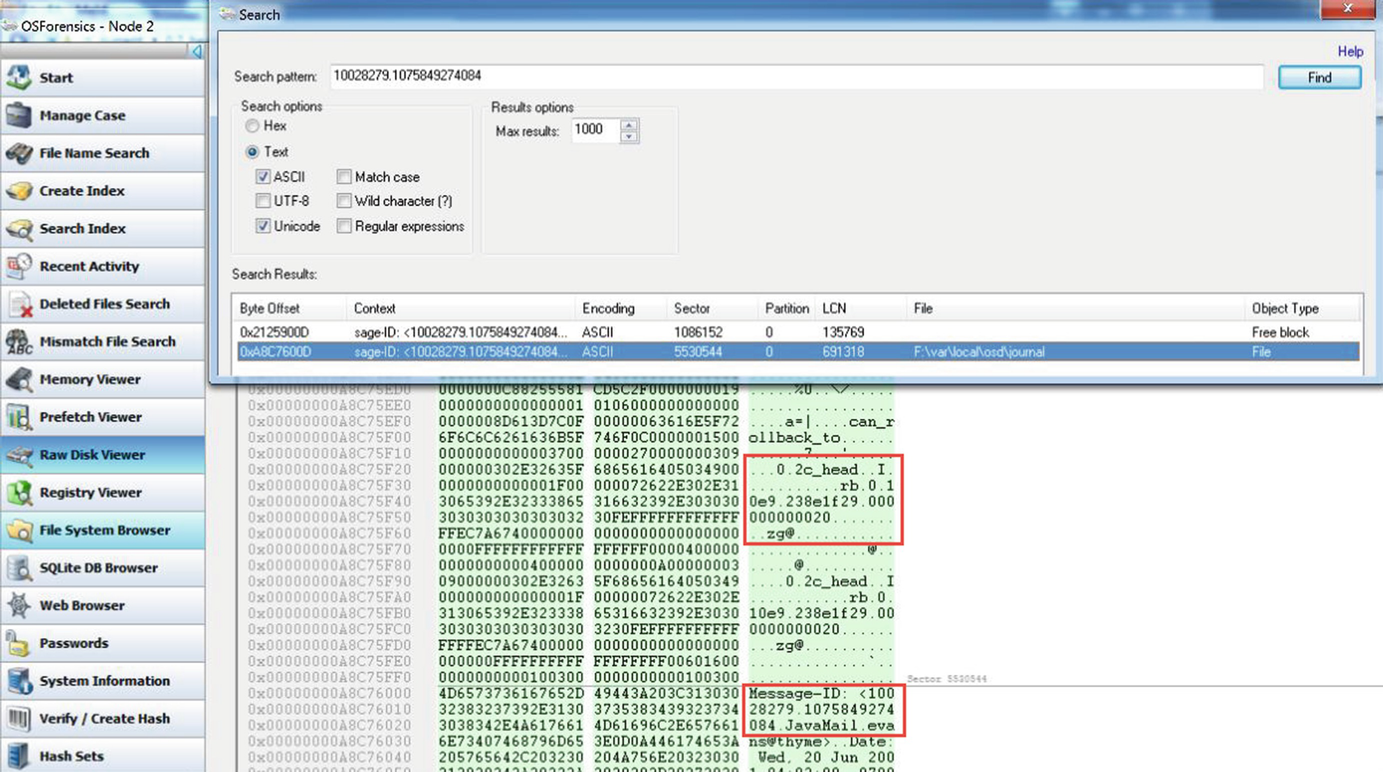
The message and RADOS header is nex to each other
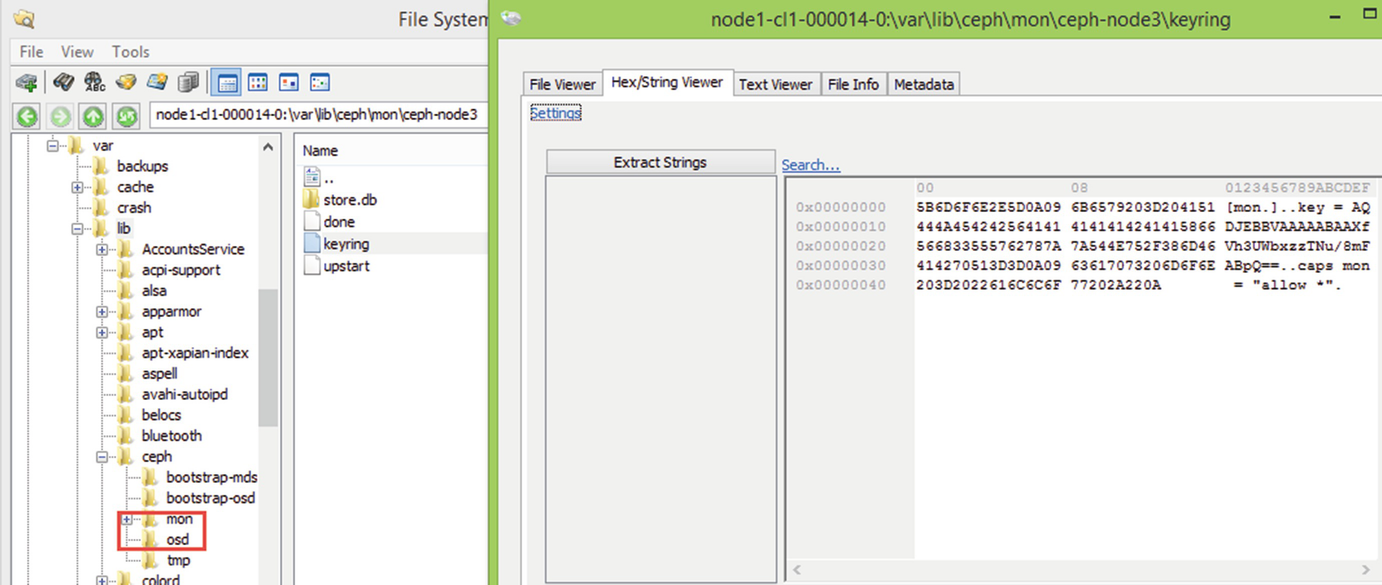
OSD and Monitor directories with keyring file open

Monitor data
The free block entries contain reference to what seems to be the user ID and Epoch (0.2c_epoch). The Epoch string (in image 34 “0.2c_epoch”) refers to an OSD map. The first part of the RADOS object ID refers to the RBD (the Rados Block Device) and rollback references.
6 Conclusion and Recommendations for Further Research
The extensive labour in trying to collect large amount of data produced by ten simple text files is not only unfriendly for a forensic investigator, but it also leaves no doubt about the need of a Could forensics framework as well as an automated tool that would help to process all this data without the need for a lot of manual process. However, at the same time the problem remains regarding the behaviour of different file systems. Just like Ceph and XtremeFSone, file system may be different from another in that they try to offer better product and better service using innovative and improved solutions. This way one particular Cloud forensics solution can be applicable to a particular system, but fail while using another.
The tools used for this investigation were helpful in identifying relevant information, however, there should be more automation in place to avoid manual search for documents. They may be helpful in identifying any further gaps in the framework as the automated tool would discover data no matter where it is recommended to look for it. This could be one of the further research areas.
Also, there is still much more to discover about Ceph, because the way it operates generally is very effective and convenient for any business that needs high availability. However, the data that it leaves behind could potentially be an information security concern if the information on Ceph Cluster is sensitive. It would be good to find out how could this be improved.
There could be more research done on forensic tools and how useful they are for investigating a Cloud platform. How much of storage and processing power does a forensic investigator need in order to be able to use them, and most importantly how long would all this take. Obviously, a bigger amount of data would produce far greater amount of data for forensic analysis and it could take a very long time to carefully investigate it or for a forensic investigator to build their own tools.
It would be interesting to see if there are any similar file systems like Ceph or is it one of a kind and what way is the market going towards. Would it be useful to build tools and create frameworks for such file systems or are they quickly passing and evolving solutions that we should not dwell on? Such and similar research could no doubt be useful for forensic investigators working on such projects as well as for anyone considering or choosing their Cloud solutions. Ceph seems to be providing an out of the box solution that could find its place where a very high availability and integrity of data is a key. However, just like any other Cloud service, it would serve very poorly in ensuring confidentiality and security of sensitive data. Moreover, it is interesting to find out how developed guidelines of this research can be applied when investigating real-world attacks in cloud computing environments such as Malware [41] and Botnet [42] attacks, exploit-kits [43], crypto-ransomware [44], or even exploiting network infrastructure devices such as SDN routers [45].