1 Introduction
Human dependence on technology has become an inadvertent side-effect of the transition into the digital age, which has subsequently resulted in an exponential increase in data production [1]. This growth of heterogeneous data has led to a relatively new computing paradigm evolving in recent years, this paradigm aptly being named Big Data [2]. Günther et al. [3] explicitly evaluated the current literature associated with the importance of Big Data, highlighting the value of Big Data for organisations as a means of building data-driven business models. Consequently, popularity surrounding Big Data environments has led to its widespread adoption, with many different types of industry utilising the environments for their own means. Companies like the Bank of America, Deutsche Bank and other large financial conglomerates are known users of Hadoop, utilising data analytics to fight against fraudulent activity and present customers with tailored packages based on transactions [4, 5]. The Hadoop ecosystem is developing significant popularity, largely due to Hadoop’s efficiency in parallel data-processing and low fault tolerance [6]. Yu and Guo [7] emphasise the extent of Hadoop adoption when they make reference to the large percentage (79%) of investment in Hadoop by companies attending the Strata Data conference. Demand for Big Data analytics has become so vast that major business intelligence companies like that of IBM and Oracle have developed their own Big Data platforms as a means of allowing companies without extensive infrastructure to take advantage of Big Data analytics [8]. In addition to these elastic Big Data environments, Vorapongkitipun and Nupairoj [9] state that the Hadoop Distributed File System is extremely lightweight and can therefore be hosted using commodity hardware, thus making it more accessible to the average user for storing smaller file types in a distributed manner.
There is a cornucopia of forensic problems associated with the adoption of Big Data environments from both the perspective of companies and individuals alike [10]. Tahir and Iqbal [1] specify that Big Data is one of the top issues facing forensic investigators in coming years due to the complexity and potential size of Big Data environments. As taxonomized by Fu et al. [11], criminals with access to a company’s confidential Hadoop environment can perform data leakage attacks from different platform layers within the Hadoop ecosystem. The authors also extend the problem of permissions to the Hadoop audit logs, specifying that attackers can make changes to these logs as a means of anti-forensics. Moreover, Big Data storage have been targeted by a range of attack vectors from Ransomware [12–14] and Trojans [15] to Distributed Denial of Service (DDoS) [16] attacks.
Malicious actors may also utilise Hadoop and the HDFS environment as a means of performing a criminal activity as they have done previously in cloud platforms such as Mega [17] and SugarSync [18]. Almulla et al. [19] illustrate how criminals can use such settings as a means of hiding and distributed illicit content with generalised ease. This consensus is also shared by Tabona and Blyth [20], in which the authors indicate that complex technologies like that of Hadoop have become readily available to criminals, subsequently resulting in crimes with digital trails that are not so easily discovered. Gao and Li [21] emphasise this complexity by identifying the difficulty in forensic extraction.
As well as problems attributed to the criminals themselves, Guarino [22] outlines problems associated with the sheer size of an HDFS environment. The potential area for analysis in an HDFS environment can be substantial, therefore making it extremely difficult to interpret information of forensics significance efficiently. This enormity can be an inherent problem during the data collection phase of forensic analysis, as the gigantean size of the dataset can correlate positively with the potential for errors during collection. Subsequently, errors in the collection can propagate in the latter stages of the investigation, therefore invalidating the integrity of the overall investigation [23].
If the HDFS environment is not already difficult to forensically interpret, the proposal of a secure deletion method by Agrawal et al. [24] may further complicate the forensic practices associated with Hadoop and the distributed file system.
As outlined above, there is a requirement for the analysis of HDFS forensically as a means of determining all the forensically viable information that may be extracted from an environment. The potential for anti-forensic techniques creates a need for more forensic analysis to take place to ensure that forensic examiners are always one step ahead of criminals. In its infancy, Big Data is a paradigm that relatively unexplored regarding forensics. Therefore there is an evident need for in-depth digital forensic analysis of the environment.
- 1.
Does the Hadoop Distributed File System offer any forensic insight into data deletion or modification, including the change of file metadata?
- 2.
Can the memory and file systems of the Nodes within the HDFS cluster be forensically analysed and compared as a means of gaining forensic insight by obtaining forensic artefacts?
- 3.
Can forensically significant artefacts be obtained from auxiliary modules associated with HDFS, i.e. web interfaces?
- 4.
Does any network activity occur in HDFS between the respective nodes that may attribute valuable forensic information?
It is expected that the findings of this research will help the forensic communities further understanding of the forensic significant components of the Hadoop Distributed File System.
This paper is structured as follows; Sect. 2 begins by giving an overview of current related research on Big Data forensics with an emphasis on Hadoop, focusing primarily on HDFS. This overview will allow the forensic investigation performed in this paper to become contextualised, emphasising the importance of research into this field. Following the literature review, Sect. 3 outlines the research methodology that will be employed in this paper, ensuring that the investigation coincides with accepted forensic frameworks. Section 4 encompasses the main experimental setup and collection of the testing data. Section 5 presents the experimental results and analysis, discussing the findings of the investigation in this research. Finally, Sect. 6 concludes the investigation and extrapolates the findings to develop ideas about future work.
2 Related Work
Despite the relatively new adoption of Big Data analytics, several researchers have begun to forensically uncover HDFS and other distributed file system environments as a means of broadening the forensic community’s insight into these systems. Majority of Big Data forensics efforts were based on procedures developed previously for cloud investigation [25] such as those used for analysing end-point devices [26, 27], cloud storage platforms [28, 29], and network traffic data [30, 31]. Forensic guidelines have also been developed as a means of building acceptable frameworks for the use of distributed file system forensics [32].
Martini and Choo [33] use XtreemFS as a big data forensics case study with an emphasis on performing an in-depth forensic experiment. The authors focus on the delineation of certain digital artefacts within the system itself, in conjunction with highlighting the issues regarding the collection of forensic data from XtreemFS.
Thanekar et al. [34] have taken a holistic approach to Hadoop forensics by analysing the conventional log files and identifying the different files generated within Hadoop. The authors made use of accepted forensic tools, e.g. Autopsy to recover the various files from the Hadoop environment.
Leimich et al. [35] utilise a more calculated method of forensics by performing triage of the metadata stored within the RAM of the Master NameNode to provide cluster reconnaissance, which can later be used at targeted data retrieval. This research focusses predominately on establishing an accepted methodology for use by forensic investigators with regards to RAM of the Master NameNode of a multi-cluster Hadoop environment. Despite the promising results gained by the investigators in data retrieval of the DataNodes, the research itself does not provide a means of identifying user actions within the environment itself.
A range of forensic frameworks for significant data analysis has been proposed in contrast to convention methods of forensic analysis and frameworks. Gao et al. [36] suggest a new framework for forensically analysing the Hadoop environment named Haddle. The purpose of this framework is to aid in the reconstruction of the crime scene, identifying the stolen data and more importantly, the user that perpetrated the action within Hadoop. Like the work mentioned above, the authors use Haddle and other tools to create custom logs to identify users performing specific actions, thus identifying the culprit.
Dinesh et al. [37] propose a similar incident-response methodology is utilising logs within the Hadoop environment. The analysis of these logs aids in determining the timeline at which an attack occurred as subsequent comparisons can be made with previous logs that encompass the current state of the systems at that time.
The use of an HDFS specific file carving framework is proposed by Alshammari et al. [38], in which the authors identify the difficulties of file carving in bespoke distributed file systems that do not utilise conventional methods of storing data. This research sets out specific guidelines for the retrieval of HDFS data without corruption, summarising that to retrieve data from HDFS using file carving that the raw data needs to be treated not unlike that found in conventional file systems with only the initial consolidation being an issue.
As mentioned the current state of Big Data forensics is relatively unexplored due to the infancy of the area [39]. However, it is evident that researchers are moving into this area of forensics as a means of understanding all aspects of new systems relevant to Big Data with an emphasis on distributed systems [40]. It is plain to see from the current research that areas of the Hadoop infrastructure are yet to be explored on a comprehensive level, as most researchers seem to stick to what they can see as appose to what they can’t. A general trend in Hadoop and other file system forensics seems to be the analysis of log files. Despite the inarguable richness of forensic data contained with system logs, the majority of papers mentioned above hold scepticism over the heavy reliance on these files in forensics. Where mentioned in the papers above, logs are deemed as a fragile source of forensic information, as these files can be easily tampered with or deleted. Inspired by this fact and for the further advancing the Big Data forensic research, there is a need to explore the Hadoop Distributed File System to retrieve forensic artefacts that may appear in the infrastructure. The emphasis should be on determining such aspects like the perpetrating user of action or time associated with any of actions with the Hadoop environment. Our work proposed in this research took the first step to address this need in the community.
3 Methodology
Digital forensic frameworks play a significant role during a forensics investigation. The previous research presents many reasons why a digital forensics investigation would face challenges and failures. As mentioned by Kohn et al. [41], the main concern is due to lack of upfront planning subsequently avoiding best security practices. To ensure best security practices, an investigator must adhere to security guidelines and standards, and this can be achieved by following a suitable framework.
As outlined by the National Institute of Standards, digital forensics is divided into four stages; collection, examination, analysis, and reporting. Alex and Kishore [42] have also followed a very similar structure to the NIST with their stages including identification, collection, organisation and presentation.
- 1.
Evidence source identification and preservation: In this stage, we identified the main components of the environment within HDFS. A forensic copy of the VMEM, VMDK and FSimages (secondary NameNode checkpoint) were generated for each of the respective nodes at each interval of action. Also, network captures were carried out during each action as a means of analysing the network transactions. We verified the integrity of each of the data files (including the dataset) by calculating the hash value associated with them. Windows PowerShell was selected to verify the integrity of each of the files collected using the command Get-FileHash -Algorithm MD5.
- 2.
Collection: During this stage, we collected a varied array of different evidence from the files outlined in the previous section. Each piece of granular evidence retrieved from the main evidence files was attributed its hash.
- 3.
Examination and Analysis: The purpose of this stage was to examine and analyse the data collected. Due to the composition of the metadata of the NameNode and data-blocks in HDFS string searching was the effective tool used for analysis in both the VMEM captures, network captures and the VMDK captures. The string searching involved finding appropriate information with regards to aspects such as block IDs, dataset file name or text within the sample dataset. A secondary stage of the analysis is to analyse log information within the NameNode and FSimage information supplied by the secondary NameNode, as a means of discovering more information that can validate findings within the environment.
- 4.
Reporting and presentation: This stage will contain all the evidence found during the investigation carried out within this paper, including a legal document that can be used in a real-life court environment.

HDFS cluster showing the FSimage checkpoint communication between the NameNode and Secondary NameNode, as well as the replication of the dataset over the two DataNodes
4 Experimental setup
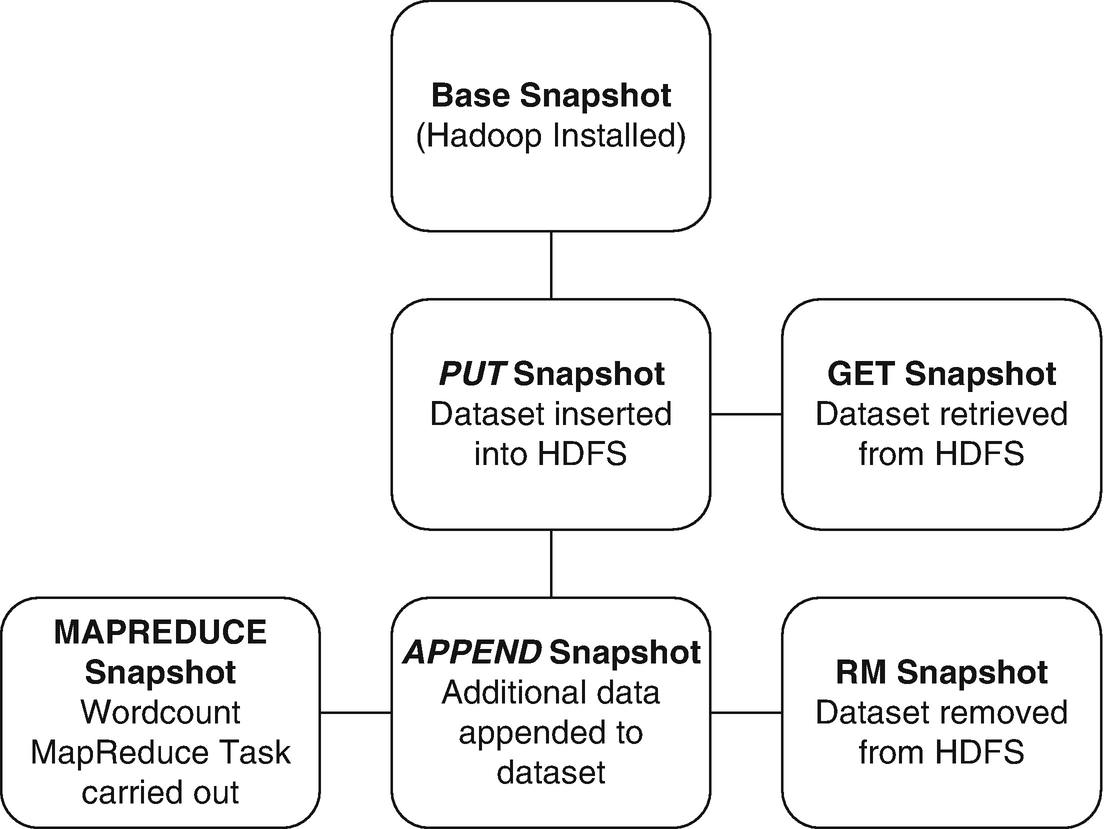
The snapshots taken within each stage of the HDFS forensic analysis. All systems will be snapshotted during each interval if action
The cluster itself was housed within a virtual environment using VMware Workstation as a means of saving time in analysis, as to create a physical Hadoop cluster with all the intermediate components involved would be an overly time-consuming exercise. Each VM was also given its minimum running requirements and disk space to save time during the analysis of the VMDKs. As stated by Rathbone [44], HDFS is designed only to take a small range of file types for use in its analysis; these include; plain text storage such as CSV or TSV files, Sequence Files, Avro or Parquet. To reduce complications, the use of a CSV dataset was chosen from U.S. Department of Health that contained information of Chronic Disease Indictors; this would aid in string searching later.
Tools used during analysis
Tool (Incl. Version) | Usage |
|---|---|
Access Data FTK Imager 3.4.3.3 | To analyse the file system structures and files of VMDK files recovered from the virtual machine snapshots |
HxD (Hexeditor) 1.7.7.0 | To analyse the VMEM files recovered from the virtual machine snapshots using string searches of the Hex data |
Offline Image Viewer (Hadoop Tool) | To analyse the secondary NameNode FSimages for each of the snapshots |
Offline Edits Viewer (Hadoop Tool) | To analyse the secondary NameNode edit logs for each of the snapshots |
Wireshark 2.4.2 | To analyse network capture files |
VMware Workstation Pro 12.5.0 | To host the virtual machines |
Snapshot specification
Snapshot | Details |
|---|---|
Base snapshot | A base snapshot with Hadoop installed, no data within cluster |
PUT snapshot | Copy of the base snapshot with data inserted into the cluster using the PUT command in HDFS |
GET snapshot | Copy of the PUT Snapshot with the HDFS data retrieved using the GET command m HDFS |
APPEND snapshot | Copy of the PUT Snapshot with the jellyfish.mp4 file appended to the original dataset |
REMOVE snapshot | Copy of APPEND Snapshot with the data removed from HDFS |
MAPREDUCE snapshot | Copy of PUT Snapshot with MapReduce configured |
5 Results and Discussion
The following section is structured using each of the prominent actions performed in HDFS, showing the step-by-step analysis of the environment relevant to these actions.
5.1 Forensic Analysis of HDFS PUT
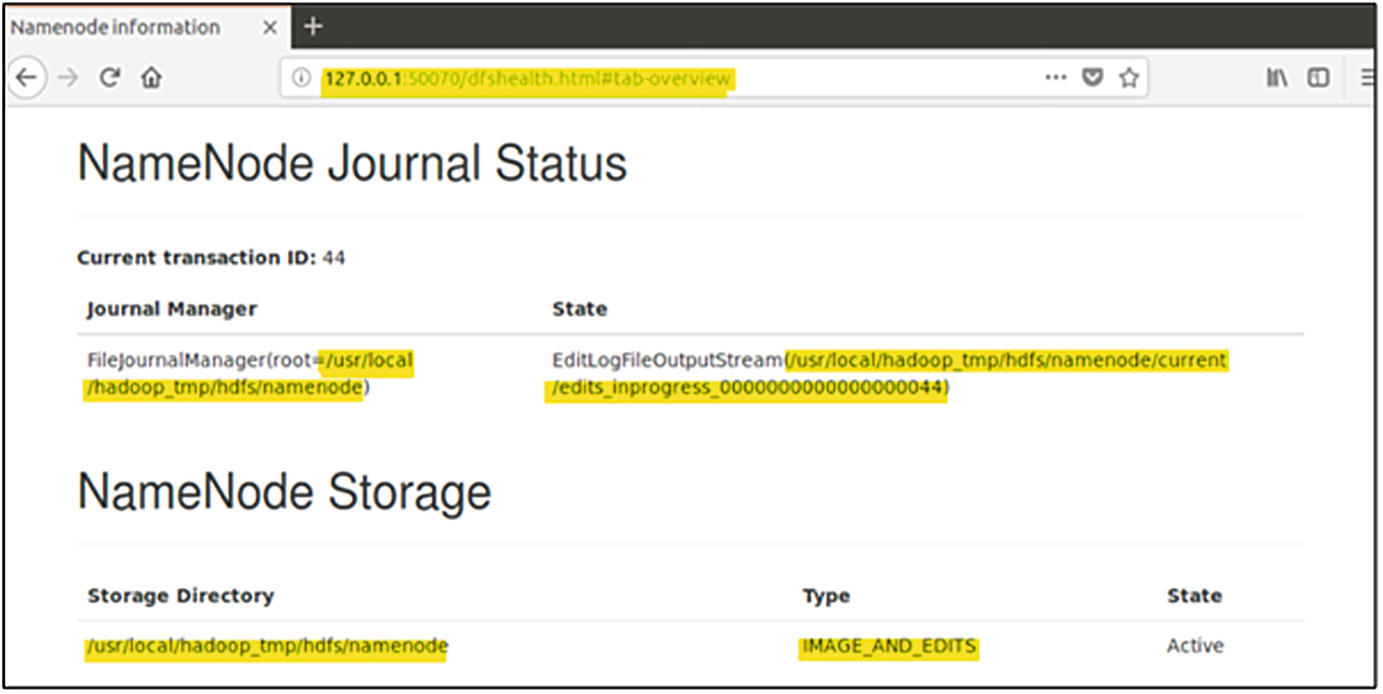
Hadoop web interface showing location of NameNode Edit Log Files
Upon browsing to this location within the VMDK image file using FTK Imager, the files edits_00000000000000000xx-00000000000000000xx, fsimage_00000000000000000xx and VERSION were found to exist. These files play a significant role in the forensic analysis of the environment as when analysed correctly they offer an abundance of information relative to the environment. This information includes certain forensically significant information such as timestamps (accessed time etc.), transaction owner as well as the names of files blocks etc. Using the inbuilt Hadoop tools Offline Image Viewer (OIV) and Offline Edits Viewer (OEV) the FSimage can be consolidated into both text and XML files that show actions within Hadoop, as well as the metadata associated with these actions. Whilst on the live Master NameNode, the command “hdfs our -i /usr/local/hadoop_tmp/hdfs/namenode/ fsimage_00000000000000000xx -o /Desktop/oivfsput.txt” was utilised to interpret the current FSimage.

Output of the Offline Image Viewer text file outlining a range of information regarding the dataset and associated blocks

Output of the Offline Edits Viewer showing the transaction summary for the checkpoint
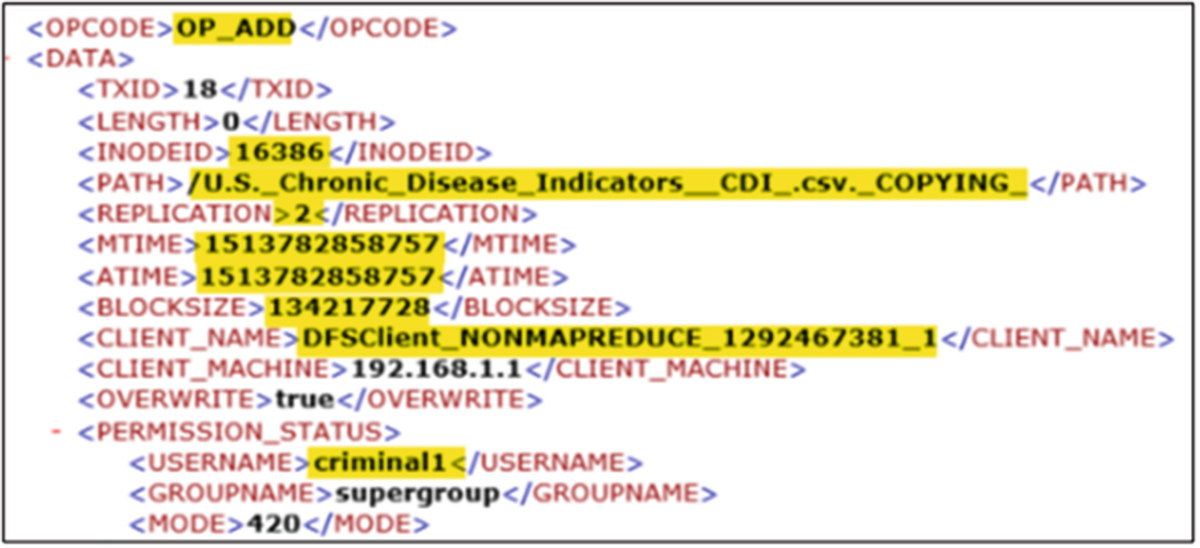
Granular output of the Offline Edits Viewer showing detailed information of HDFS PUT transaction
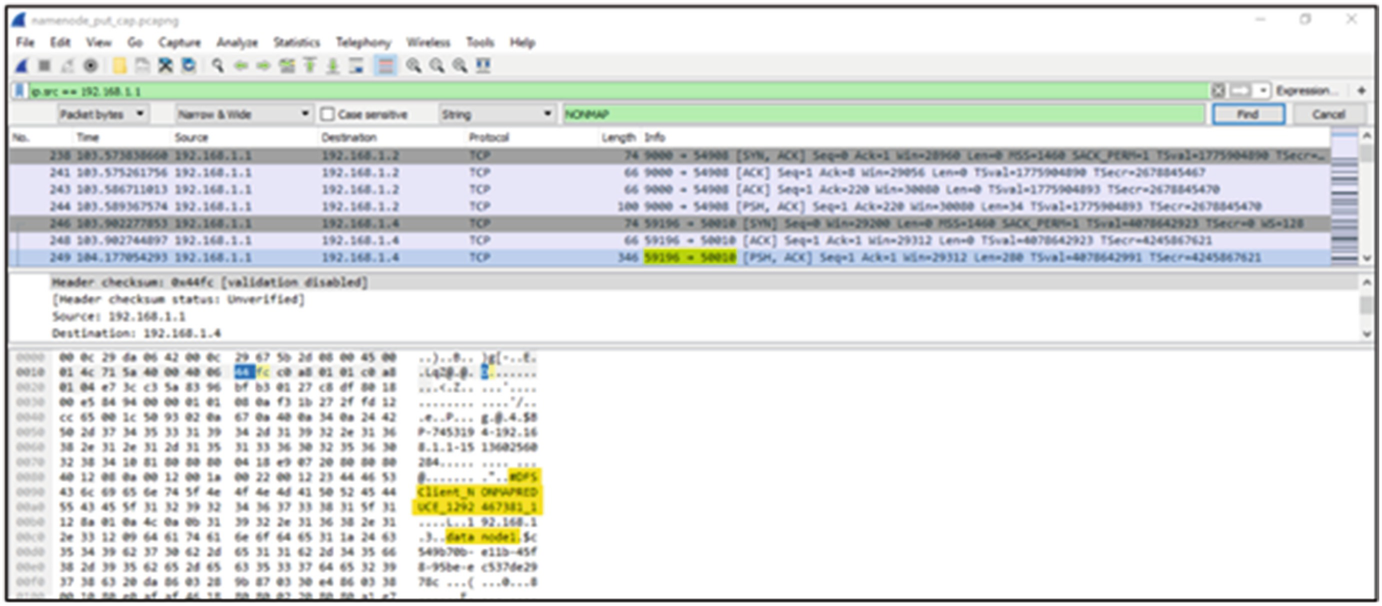
Network capture occurring between the NameNode and DataNode

Offline Edits Viewer output showing the block allocation ID associated with the file being added
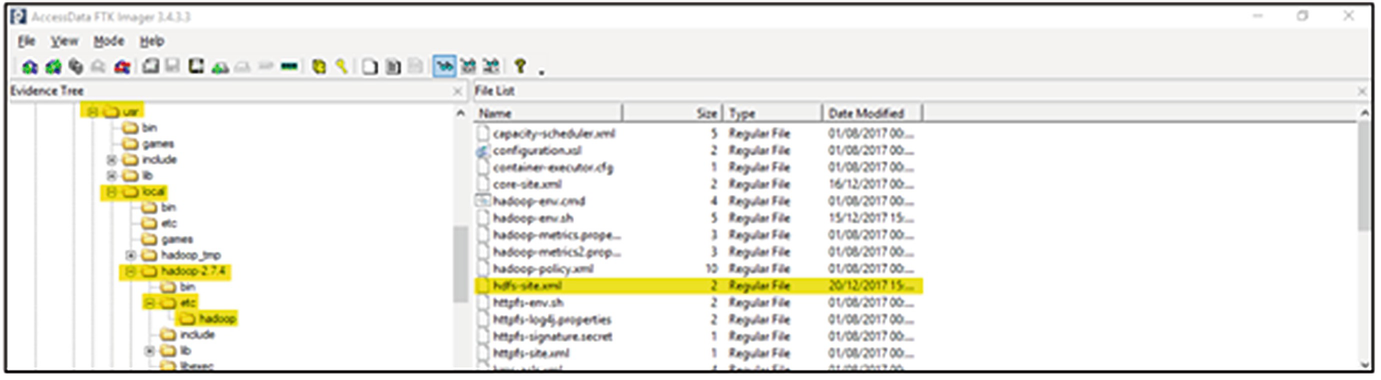
File structure of NameNode showing the location of the Hadoop configuration files
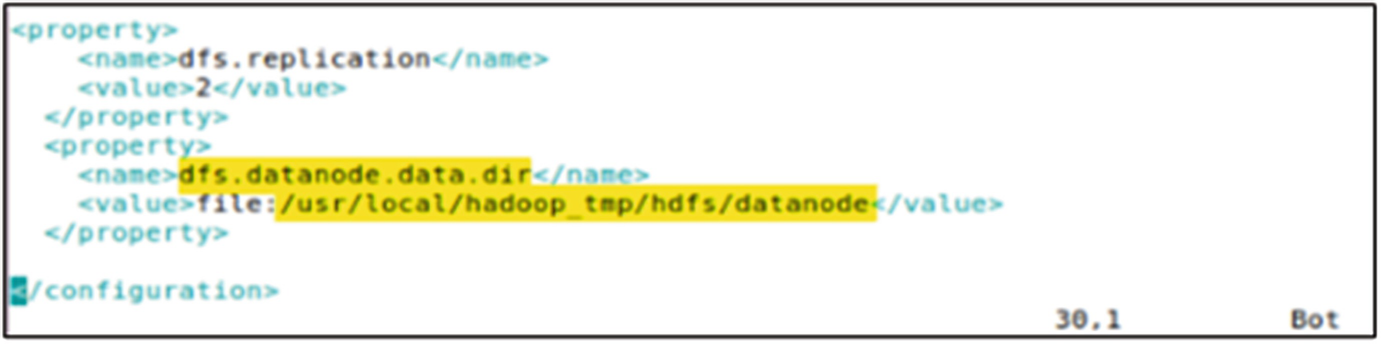
Contents of the hdfs-site.xml file showing the DataNode data directory
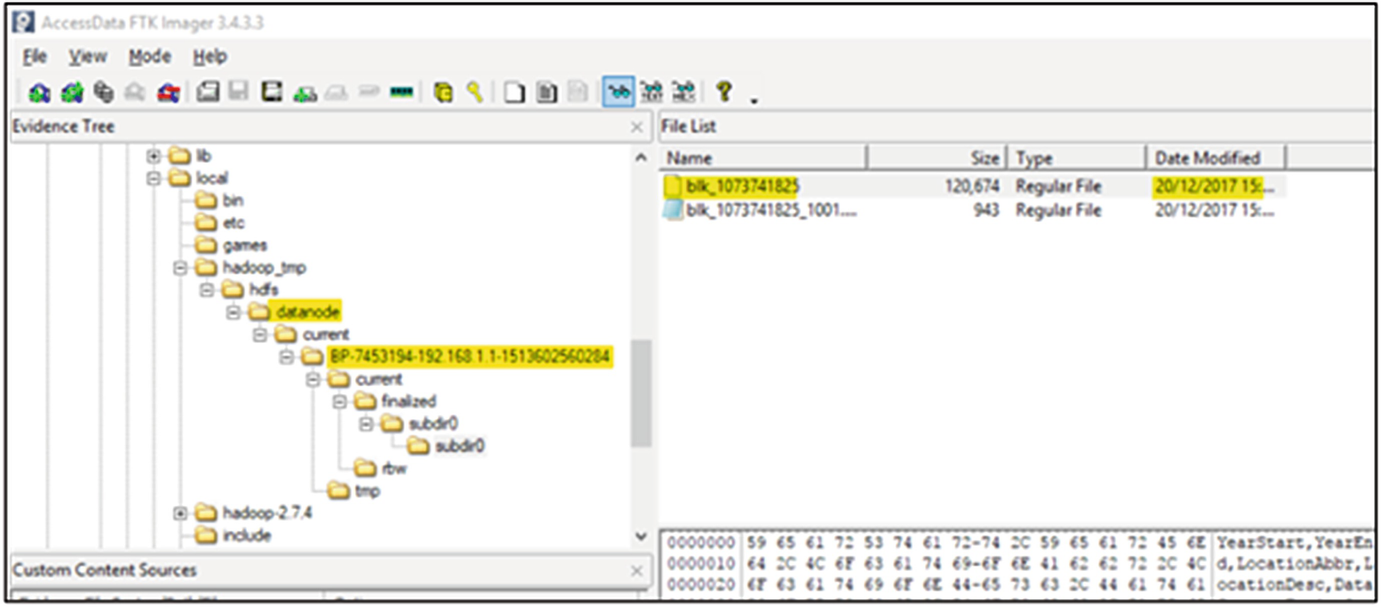
The DataNode file structure with the block files present
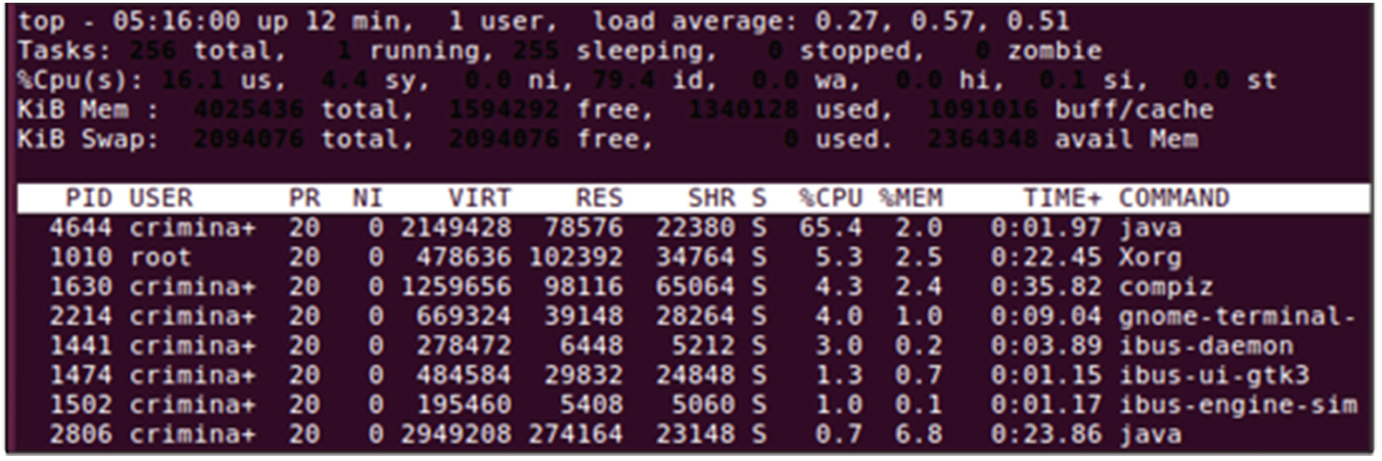
Output of Linux top command following real time analysis of memory processes
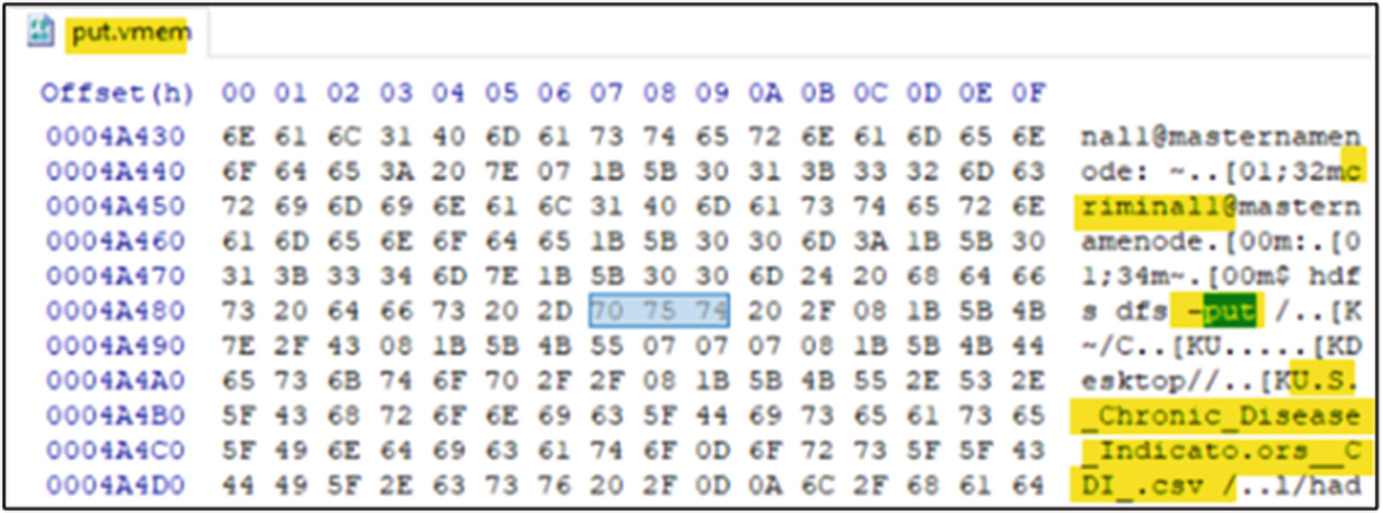
Raw volatile memory file analysed in HxD
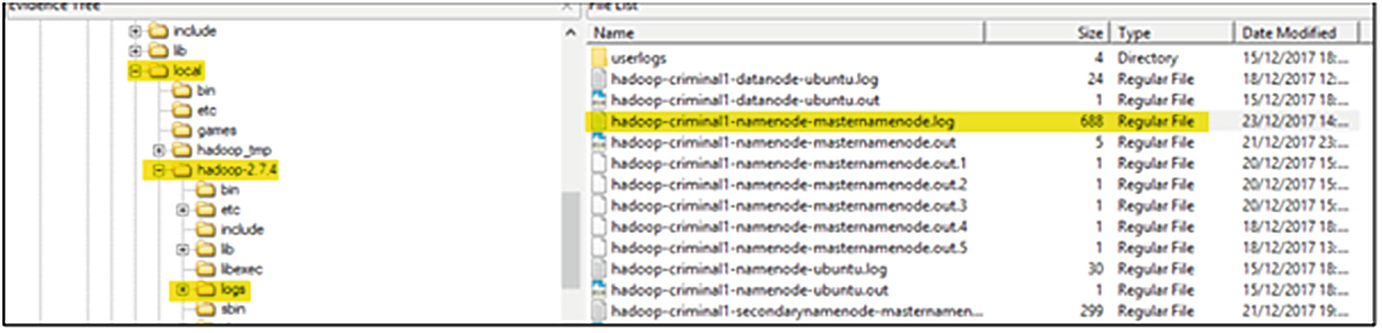
NameNode VDMK file within FTK Imager showing the location of log files

grep output of the Hadoop-criminal1-namenode-masternamenode.log file following the PUT command
5.2 Forensic Analysis of HDFS GET

Output of the Offline Image Viewer showing a difference in access time
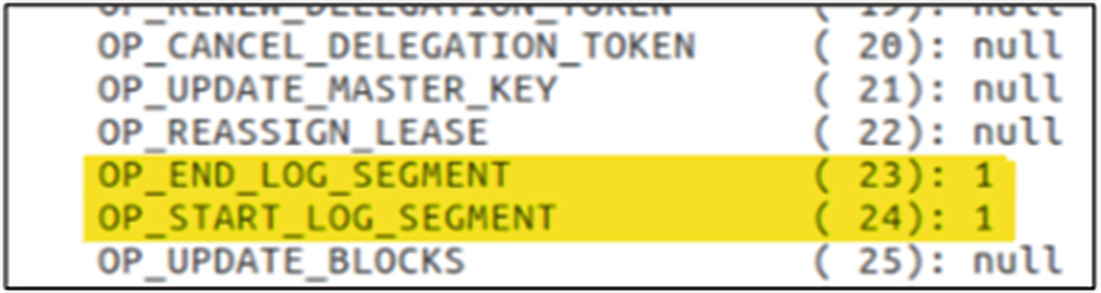
Overview of the Offline Edits Viewer
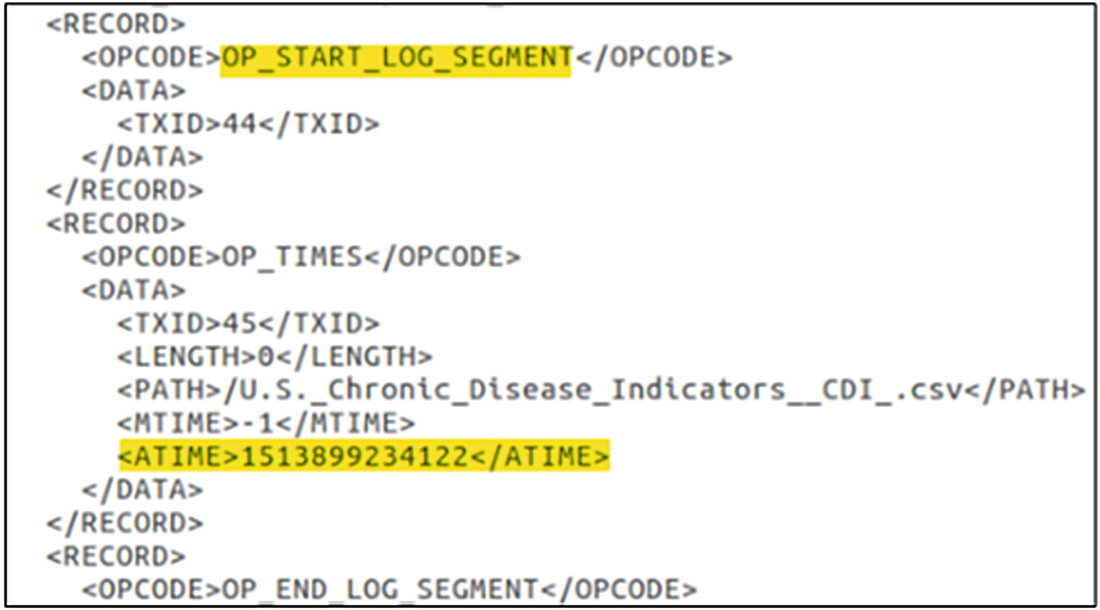
Edits log showing the change in access time for the dataset
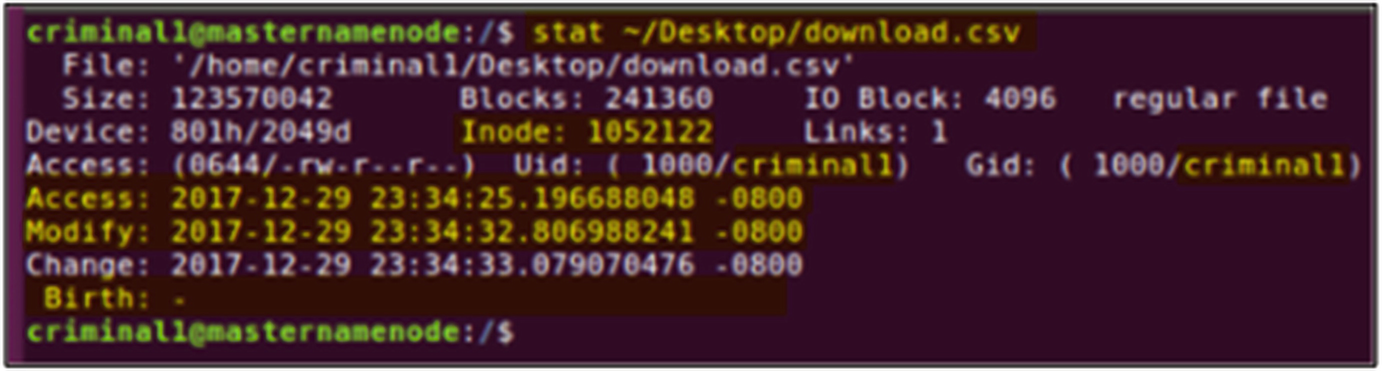
Terminal output for the statistics of the newly created download.csv
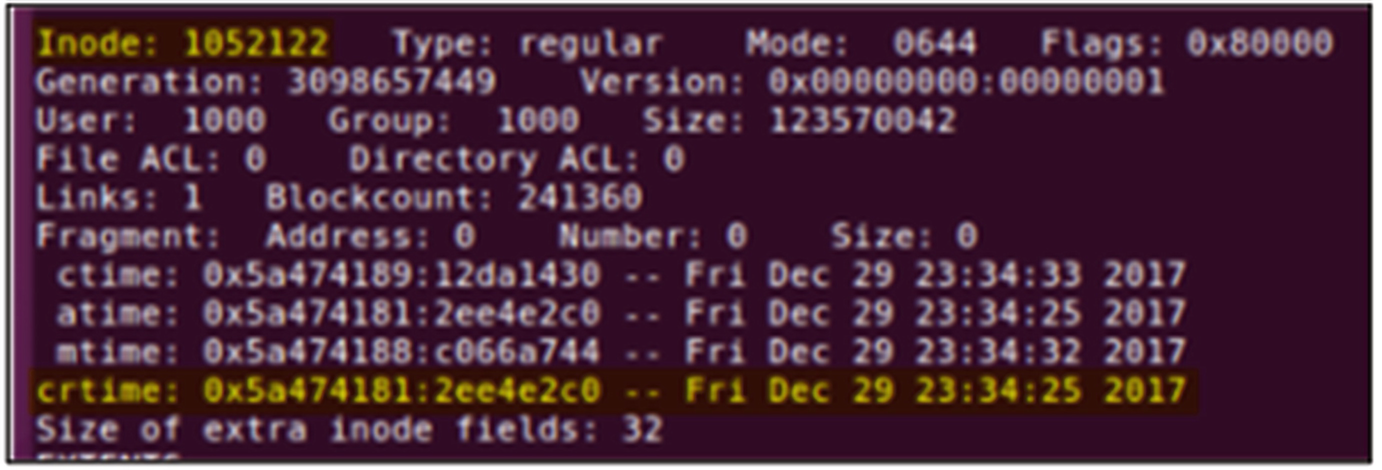
Terminal output from the debugfs command showing the creation time of the file relative to the Inode
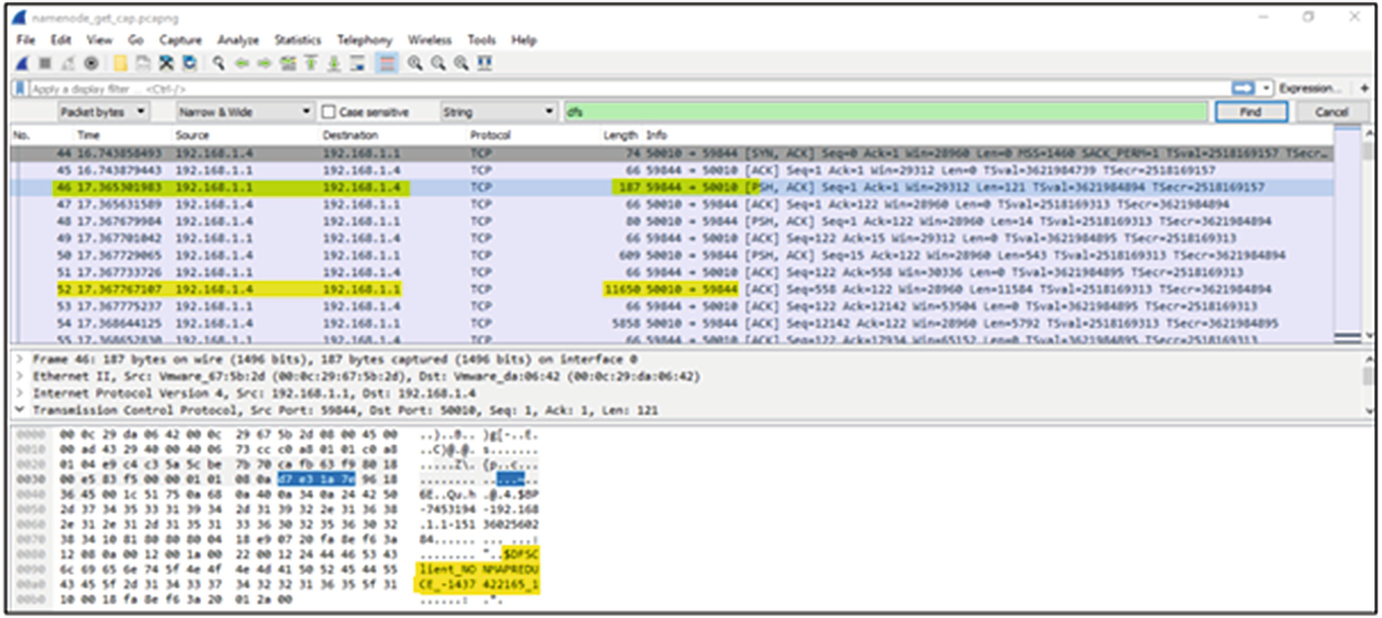
Presence of the DFSClient ID in the network capture followed by data transfer
5.3 Forensic Analysis of HDFS APPEND
As HDFS does not allow the modification of files once they are populated within the filesystem. The use of the APPEND (hdfs dfs -append) command is therefore needed to add additional information to a file already within HDFS, lest the user must delete the entire file and repopulate the environment with the modified version of the file. In this instance, a sample MP4 file was appended to the original dataset to simulate a criminal trying to hide information within another HDFS based file. Again, drawing on the detailed logging capabilities of the FSimage and edit logs, the HDFS OIV and OEV commands were utilised to analyse the logs following the use of the APPEND command.
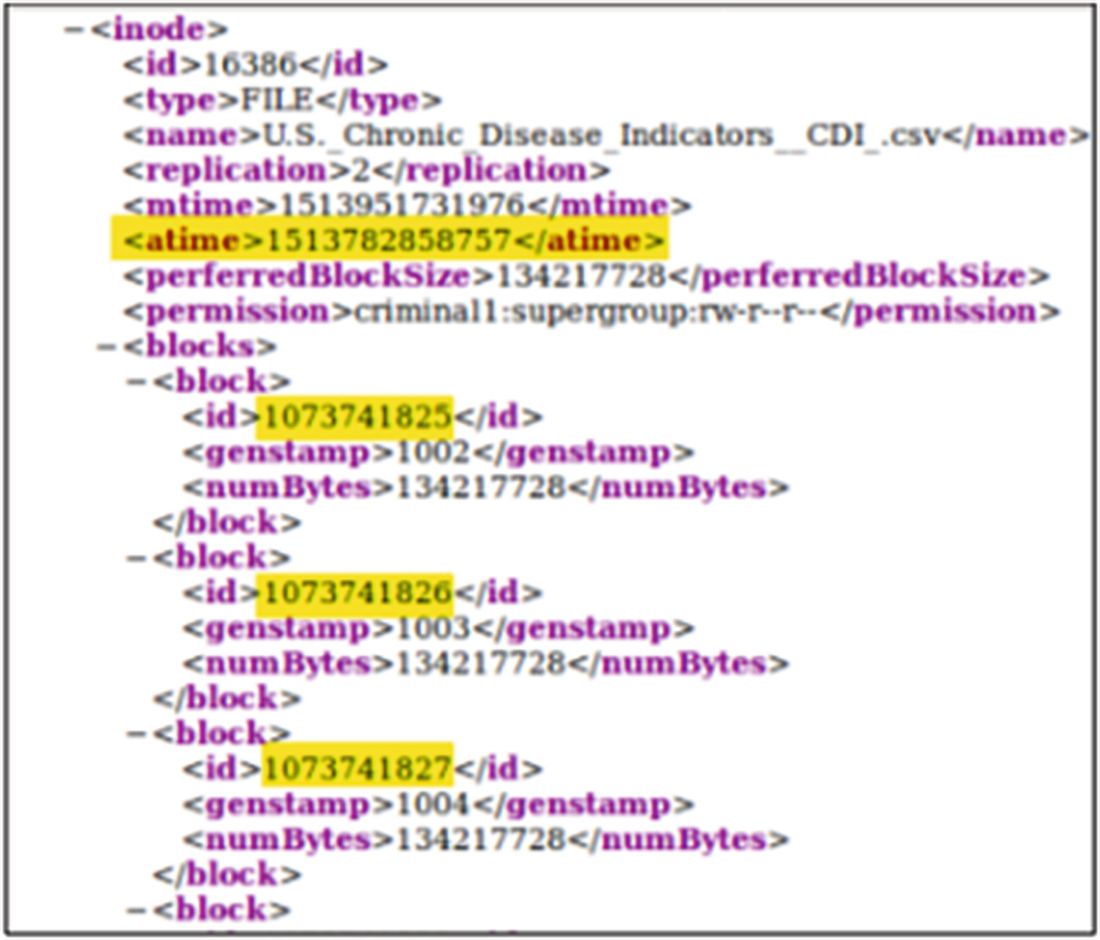
Output of the Offline Image Viewer proceeding an append operation
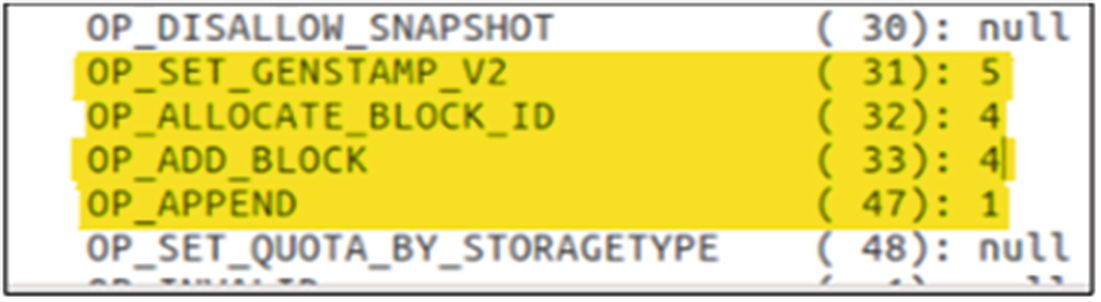
Output of the Offline Image Viewer proceeding an append operation
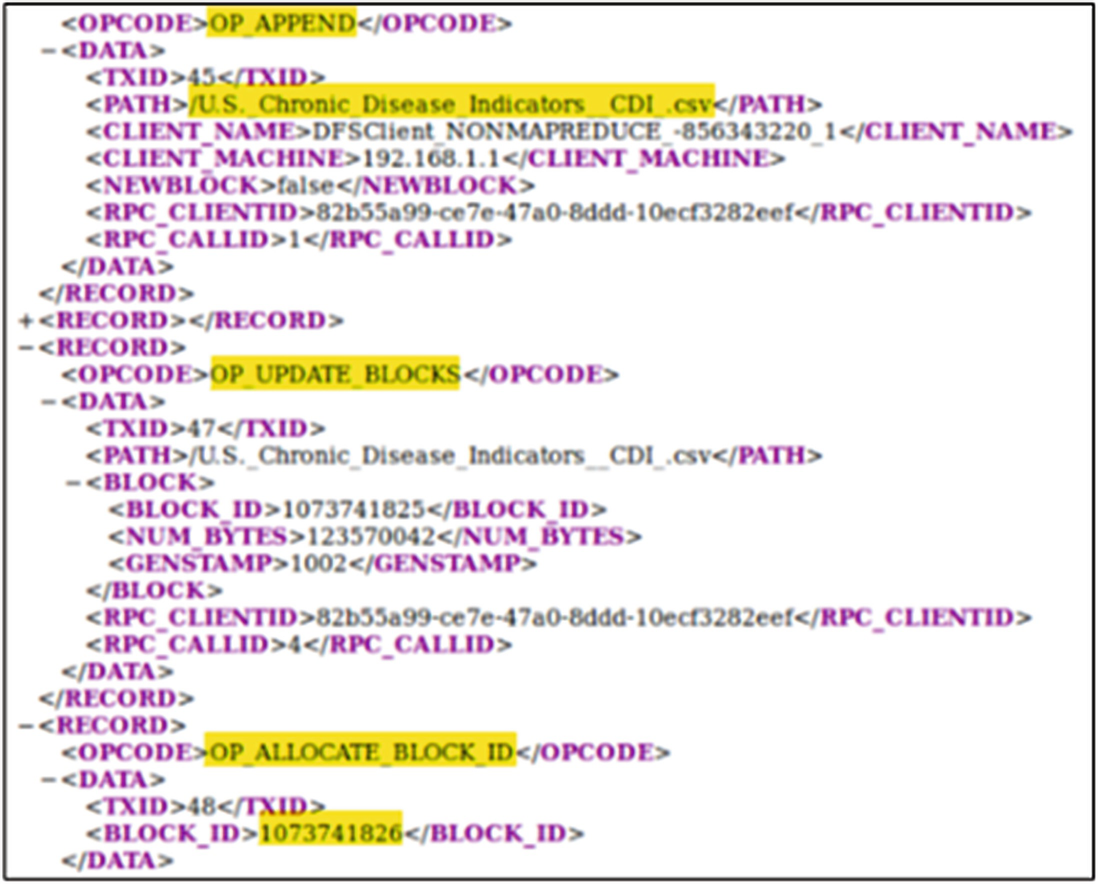
Block allocations and updates contained within the detailed edits log

DFSClient ID present followed by data transfer of APPEND operation

grep output of the NameNode log file, using DFSClient ID as a search parameter
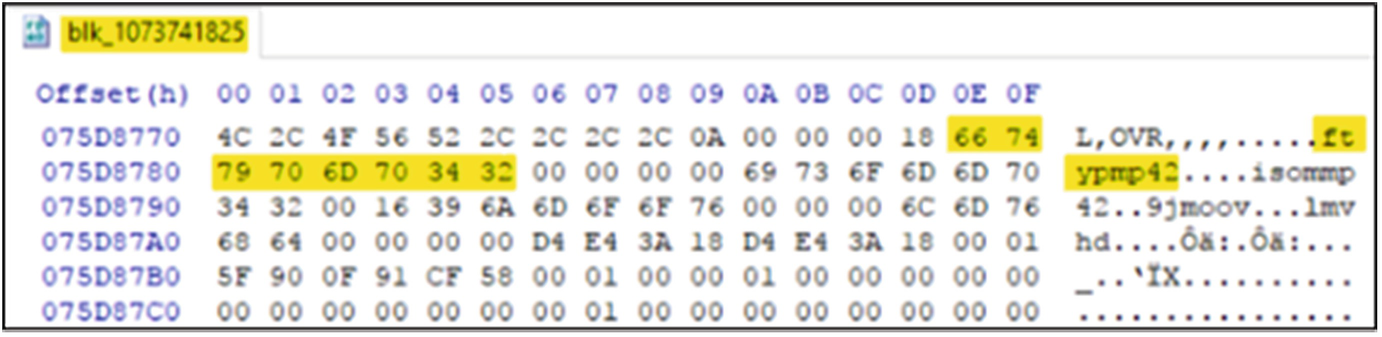
MP4 file signature located in the dataset file block proceeding the append

Output of the “top” command in Linux during the APPEND process
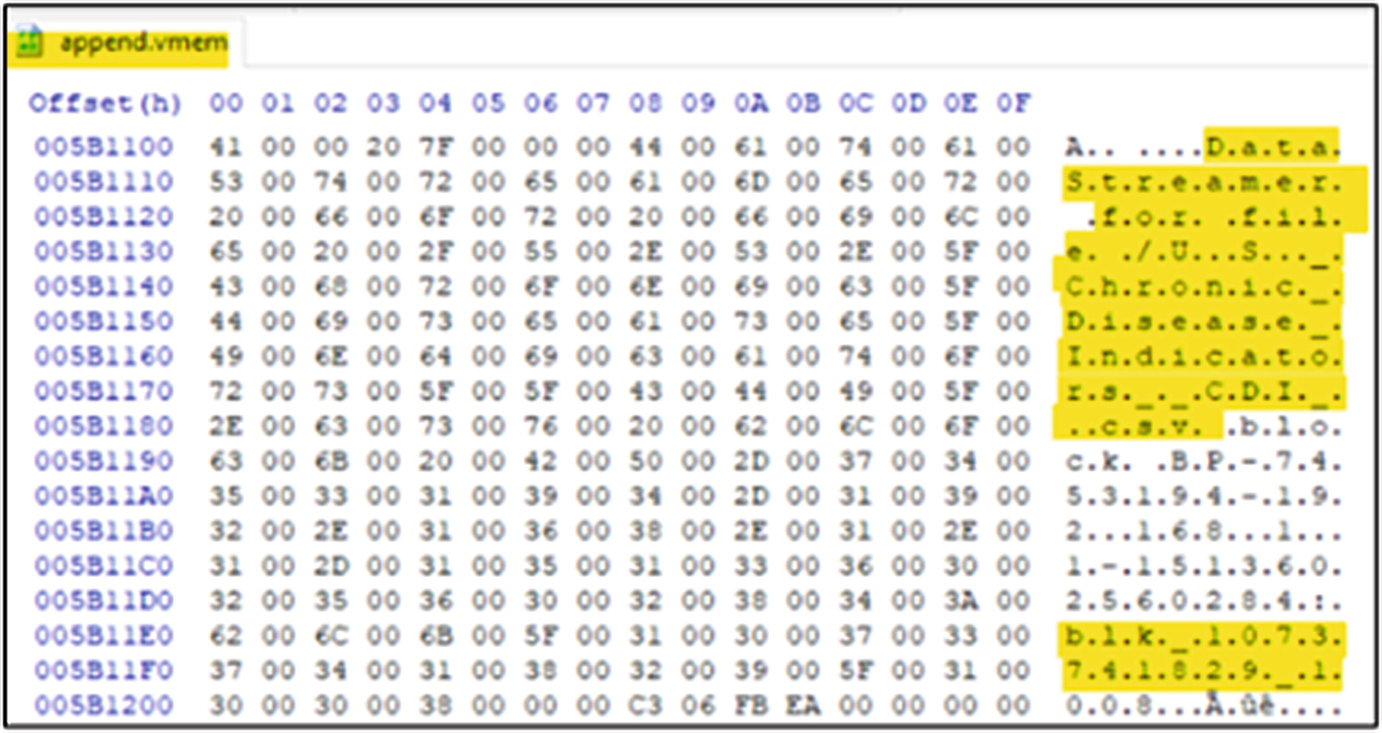
Data stream information regarding the dataset and the blocks associated with it
5.4 Forensic Analysis of HDFS REMOVE

Offline Image Viewer output showing the creation of the .Trash directory

Overview of Offline Edits Viewer output showing the absence of a delete operation

Offline edits viewer output showing the rename of the dataset with the addition of the TO_TRASH option

Offline edits viewer showing the creation of the Trash directory

Newly created .Trash directory within HDFS containing the deleted dataset
When analysing the network traffic in Wireshark during the deletion, no traffic of note was recorded. This concluded that only the NameNode was aware of the deletion and that with the DataNodes unaware of the deletion this meant that the data saved on the respective blocks were stored within the same place as before and was only logically moved to trash in the logical file structure of HDFS.
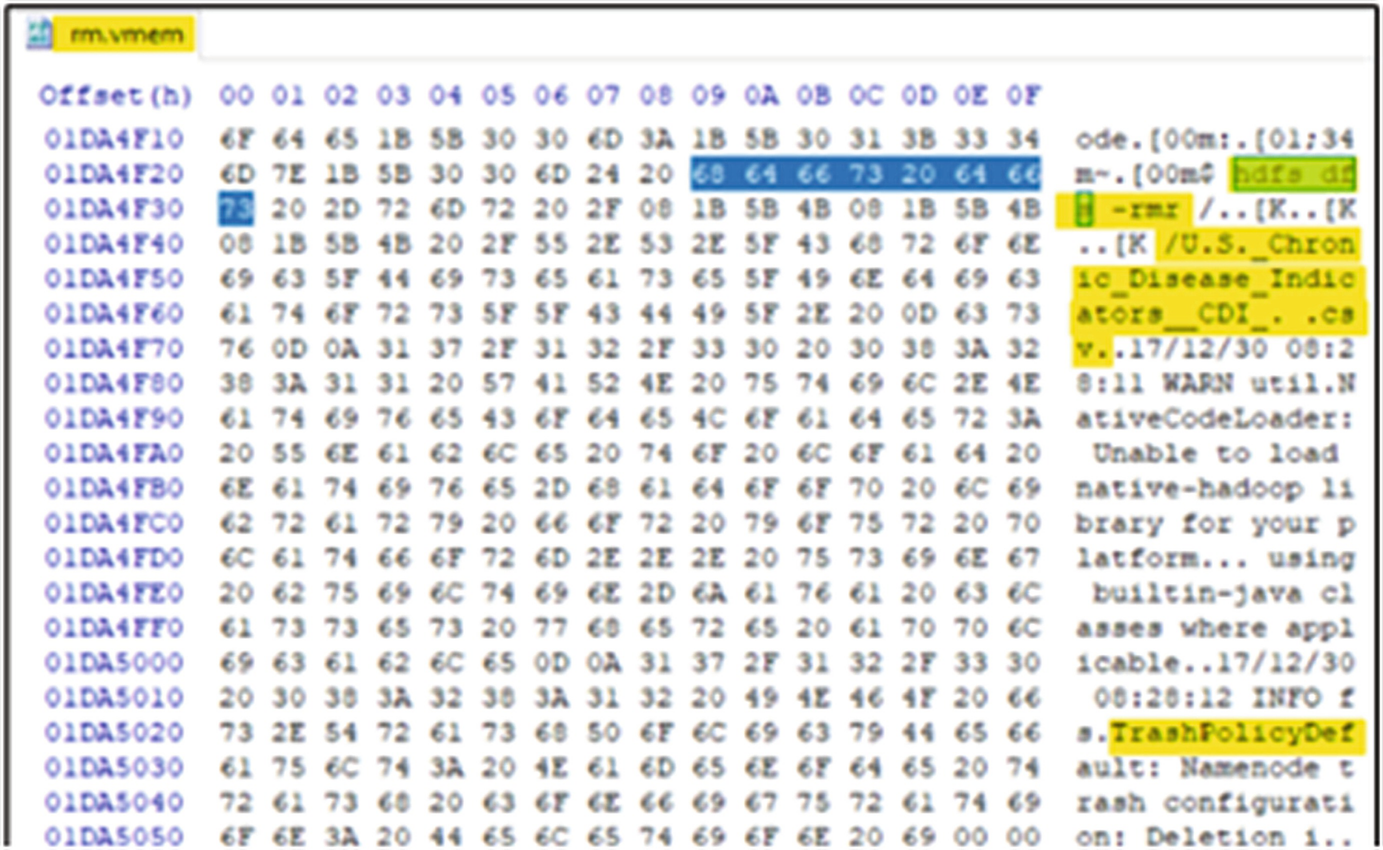
RAW memory file showing the trash policy default time
5.5 Forensic Analysis of a Basic MapReduce Task

grep output of the yarn-criminal1-resourcemanager-masternamenode.log file showing successful submission by the criminal1 user

Output of the grep command against the masternamenode.log file
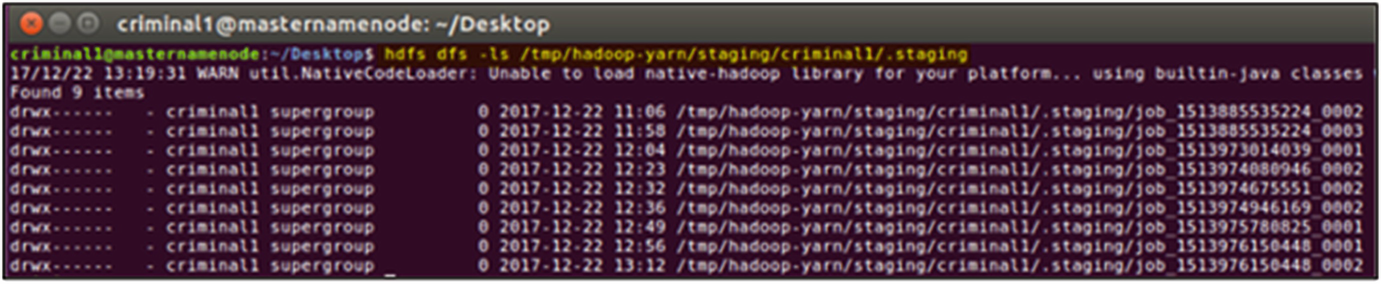
Temporary directories created for each Hadoop job within HDFS

Job username of the MapReduce job contained in the job.xml file of the job directory
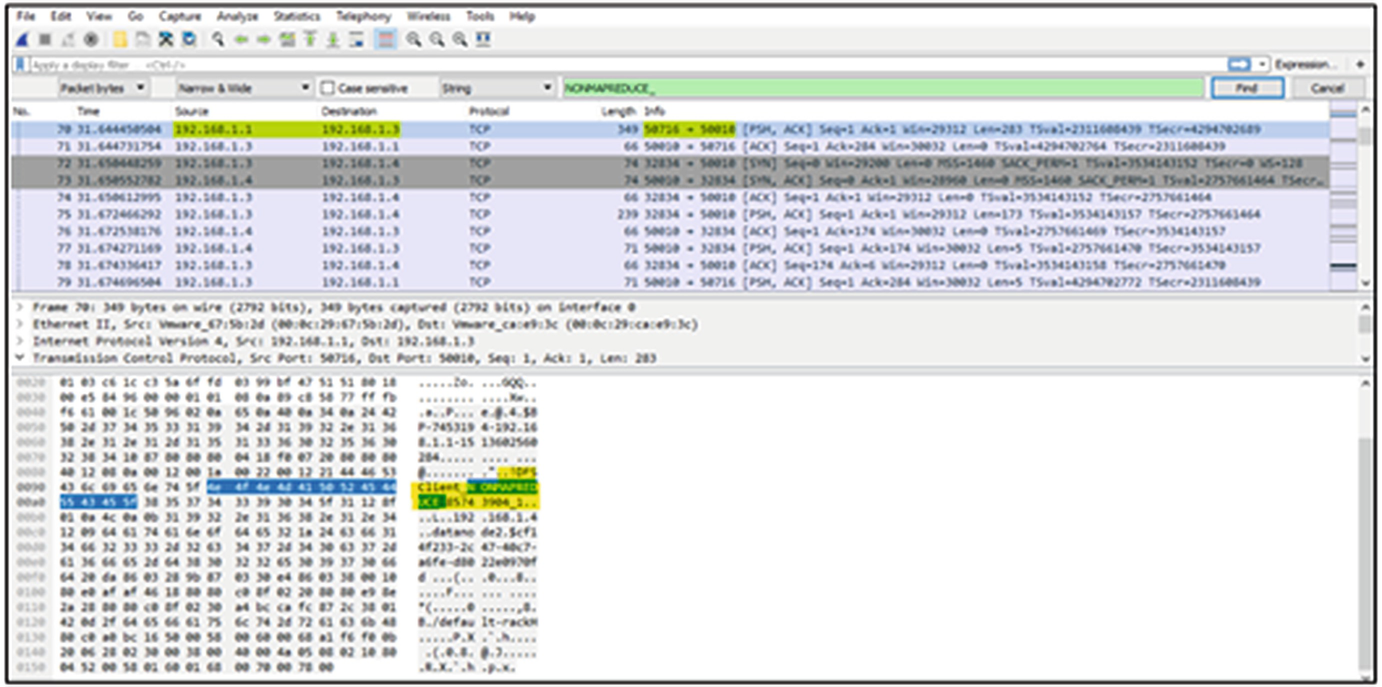
Network capture during the MapReduce Task
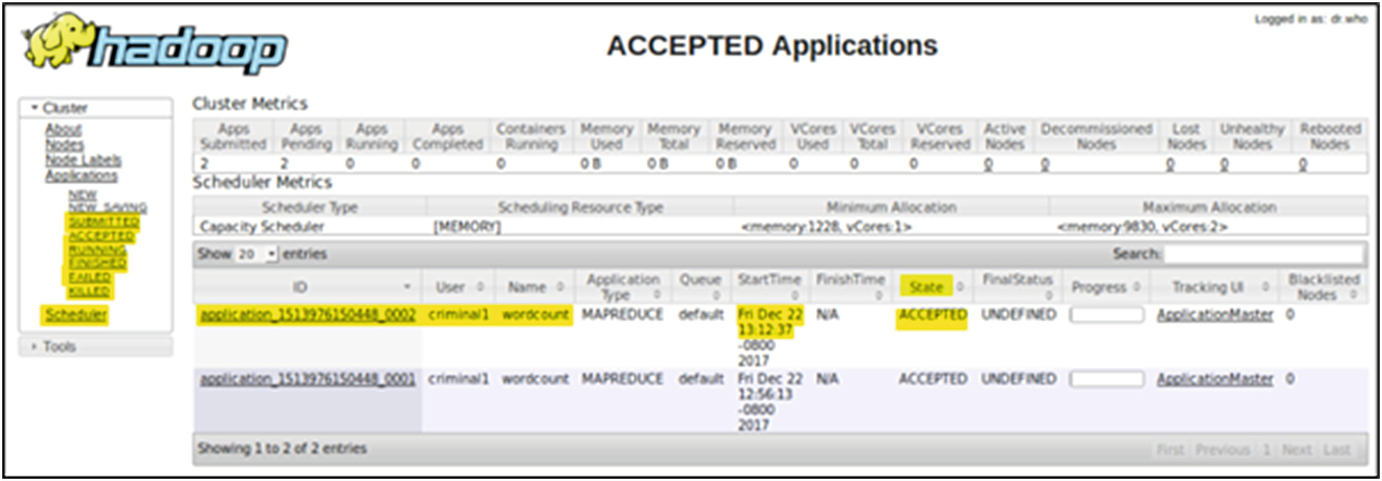
Hadoop web interface showing the currently scheduled jobs
6 Conclusion and Future Work
HDFS is a large and complex infrastructure with a web of different configuration files, logs and systems that can be analysed to gain information on the actions occurring within. The purpose of this paper was to forensically explore the HDFS environment and uncover forensic artefacts that could aid in a forensic investigation. During this investigation, each key HDFS command was executed and monitored to understand which artefacts were produced following the execution of each command. The Linux file systems, volatile system memory and network files were all analysed at each interval of action.
The inbuilt HDFS commands for both the Offline Image Viewer and Offline Edits Viewer proved invaluable in forensic data retrieval during the investigation. Each tool provided the examiners with a range of information featured in each FSimage and edited log, which could be extrapolated to other areas of the investigation. The granularity of each of the tool outputs allowed for a comprehensive insight into the activities of the cluster during each action. Subsequently, it is our recommendation that effective forensic analysis of the HDFS environment can occur, checkpointing of the Master NameNode on the secondary NameNode must occur at a high frequency to effectively track the activities of HDFS.
In addition to the FSimages and edit logs provided by checkpointing, the comprehensive nature of the Hadoop log files themselves provided a plethora of information on any actions made with Hadoop. It is due to this and the collation of the previously mentioned FSimages that more information could be found. The generic hadoop-criminal-namenode-masternamenode.log file logged almost every action within the HDFS cluster, showing that this file has great importance to forensic investigators, and interpreting the output of this log file (and others) is vital when forensically analysing the Hadoop environment.
One of the key objectives of this investigation was to assess all aspects of the HDFS including processes within volatile memory. Unfortunately, the findings surrounding this area of the investigation did not reap any forensically significant information as the processes associated with HDFS is run as abstract processes of Java, these processes were associated with the malicious user, but this information alone does not offer any insight into the actions being taken.
Clarification was also sought regarding the communication occurring between the Nodes and whether network traffic produced forensic artefacts that could prove useful in determining activity. Although some information was gained from the network traffic that corresponded with other findings, the traffic offered only a small amount of information that could be used to validate communications between the NameNode and DataNodes. It should also be noted that in some HDFS installations, communication between each of the nodes is often encrypted as a means of security and would, therefore, offer less information.
Assumptions were made with some of the actions that seemed logical, the removal of data being once instance in which one would assume some notation of deletion to occur, however, this produced results that did not coincide with the assumptions made. It is because of assumptions like this that forensically analysing environments like that of HDFS and other distributed file systems are required so that the forensically community can build a repertoire of knowledge with regards to these systems.
As this investigation focused predominately on HDFS, more works needs to be done to understand the entirety of the Hadoop ecosystem with special attention being paid to the types of artefacts that are generated as a result of MapReduce. The exploration of the Eclipse IDE with the MapReduce plugin may also prove valuable in gathering forensic insight into HDFS forensics. Additional research may be needed in HDFS environments that utilise Kerberos for authentication, as more forensic artefacts may be attributed to a Kerberos base cluster. Moreover, forensics investigation of evidence generated in HDFS through connecting it to emerging IoT and IIoT environments is another interesting future research [47, 48]. Analysing malicious programs are specifically written to infect HDFS platforms to exfiltrate data or steal private information within cyber-attack campaigns is another future work of this study [15]. Finally, as machine learning based forensics investigation techniques are proving their value in supporting forensics investigators and malware analyst activities it is important to build AI-based techniques to collect, preserve and analyse potential evidence from distributed file system platforms [49–51].
Acknowledgement
We would like to thank the editor and anonymous reviewers for their constructive comments. The views and opinions expressed in this article are those of the authors and not the organisation with whom the authors are or have been associated with or supported by.