Kapitel 3
C
IN DIESEM KAPITEL
- erlernen Sie die Grundzüge der Programmiersprache C (jedoch nicht alle Feinheiten).
Damit Sie in den späteren Kapiteln die Programmierschnittstelle von Linux nicht nur erlernen, sondern praktisch ausprobieren können, benötigen Sie Grundkenntnisse in einer Programmiersprache. Und da Linux zum allergrößten Teil selbst in C implementiert wurde, bietet sich C dafür geradezu an. Auf geht's!
Warum C?
Die gute Nachricht gleich zu Anfang: C besitzt einen kleinen Sprachumfang. Sie müssen also nur sehr wenige Schlüsselwörter lernen. Diese sind in Abbildung 3.1 aufgeführt.

Abbildung 3.1: Die Schlüsselwörter von C
Betriebssysteme wurden und werden in C programmiert, unter ihnen UNIX (und Linux). C gibt es (wahrscheinlich) für jede Plattform. C gilt als sehr effiziente Hochsprache. Das bedeutet, dass Code, der in C geschrieben ist, schneller abgearbeitet werden kann als Code in den allermeisten anderen Hochsprachen, vorausgesetzt, beide werden auf ein und derselben Maschine abgearbeitet und die implementierten Algorithmen sind identisch.
C ist eine außerordentlich populäre Programmiersprache. Im »TIOBE Programming Community Index« rangiert sie im Februar 2022 hinter Python auf Platz zwei, und im »Popularity of Programming Language Index« (PYPL) belegt sie zum gleichen Zeitpunkt Platz fünf.
Warum nicht C?
Es gibt auch einige Gründe, die gegen den Einsatz von C sprechen, diese sollen nicht verschwiegen werden.
C ist ausgesprochen elementar. Der kleine Sprachumfang bedingt, dass Sie vergleichsweise viele Anweisungen benötigen, um komplexe Funktionalität in C zu implementieren. Es gibt zwar sehr viele Bibliotheken (das sind Sammlungen von Funktionen, in denen Routineaufgaben bereits als Funktionen »gebrauchsfertig« programmiert sind), jedoch muss man diese als Programmierer zunächst wieder erlernen. Wenn Sie vorhaben, sehr komplexe Anwendersoftware zu implementieren, bei der es zusätzlich nicht allzu sehr auf die Laufzeit ankommt, dann ist C möglicherweise nicht die erste Wahl.
C erlaubt subtile Programmierfehler, die schwer zu entdecken sind. C ist alt. Es gibt modernere Sprachen, die teilweise die in C möglichen Fehler verhindern. C gestattet es, sehr schwer verständliche Programme wie das in Listing 3.1 abgebildete zu schreiben.

Listing 3.1: Ein korrektes, wenn auch sehr unverständliches C-Programm
Es handelt sich dabei um einen Gewinnerbeitrag beim »International Obfuscated C Code Contest«, also dem Internationalen Wettbewerb im Schreiben unverständlicher C-Programme (ja, das gibt es wirklich). Falls Sie obiges Programm verstehen, können Sie das Kapitel getrost überspringen.
Geschichtlicher Abriss
C ist eine verhältnismäßig alte Sprache. Sie wurde Anfang der 1970er-Jahre von Brian Kernighan und Dennis Ritchie entwickelt. C hat sich ursprünglich vor allem mit dem Betriebssystem UNIX verbreitet. Mehr als 90 Prozent des UNIX-Systems wurde in C implementiert (für den Rest benötigte man Assembler).
C erlaubt sowohl eine wohlstrukturierte und portable als auch eine hardwarenahe Programmierung (man hat beispielsweise direkten Zugriff auf Hauptspeicheradressen).
Viele Mechanismen, die in anderen Sprachen zu diesen selbst gehören, wie die Ein- und Ausgabe, Dateiarbeit und Speicherallokation, werden nicht innerhalb der Sprache C definiert, sondern stattdessen durch Bibliotheksfunktionen realisiert, beispielsweise in der C-Standardbibliothek.
C ist durch mehrere Gremien standardisiert. Gegenwärtig maßgebend ist C11 der International Organization for Standardization (ISO).
Der Name »C« leitet sich aus dem Namen einer Vorgängersprache ab, die (Sie dürfen nur einmal raten) »B« genannt wurde. Vielleicht waren Kernighan und Ritchie auch einfach nicht kreativ genug, denken sie an Programmiersprachennamen wie »Rust«, »Java« oder »Brainfuck«.
Vom Werkzeugkasten
Was benötigt man nun zur C-Programmierung? Eigentlich gar nicht so viel. Zum einen benötigen Sie einen Editor, mit dem Sie den Quelltext bearbeiten. Prinzipiell kann man für diese Aufgabe die Textverarbeitung einsetzen, aber es gibt eine Menge an Editoren, die dafür besser geeignet sind. Bereits im vorangegangenen Kapitel haben Sie den Editor vi kennengelernt – eine gute Gelegenheit, die hoffentlich erworbenen Kenntnisse zu reaktivieren. Dazu geben Sie vielleicht gleich einmal das Listing 3.2 ein und speichern es unter dem Namen hello.c in einem geeigneten Verzeichnis ab. Achten Sie darauf, keine Tippfehler einzubauen!

Listing 3.2: Das erste C-Programm
 Es gehört zur Folklore der Programmiersprache C, dass das erste Programm, das der Schüler schreibt und übersetzt, die Zeichenkette »
Es gehört zur Folklore der Programmiersprache C, dass das erste Programm, das der Schüler schreibt und übersetzt, die Zeichenkette »Hello, world!« auf der Konsole ausgibt, weshalb es stets hello.c genannt wird.
Außer dem Editor benötigen Sie noch ein Werkzeug, mit dem Sie den Quellcode in ein ausführbares Programm verwandeln, den C-Compiler. In diesem Buch nutzen Sie den weitverbreiteten und freien Compiler gcc der sogenannten »Gnu Compiler Collection«. Dieser ist in den meisten Distributionen standardmäßig installiert.
Um herauszufinden, ob dies bei Ihnen auch der Fall ist, rufen Sie ihn einfach einmal auf:

Entweder Sie erhalten eine längere Meldung über die installierte Version und darüber, dass es sich um freie Software handelt, oder es erscheint eine Fehlermeldung, die ungefähr so aussieht:

In diesem Fall muss das zugehörige Paket nachinstalliert werden. Unter Debian Linux und seinen Verwandten geschieht das mittels
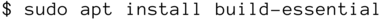
Unter Arch Linux hingegen ist

notwendig. Natürlich dürfen Sie auch ein grafisches Frontend für die Paketverwaltung einsetzen.
Jetzt wird es ernst! Sie sollen Ihr erstes C-Programm übersetzen. Dazu starten Sie ein Terminalprogramm und führen im Verzeichnis, in dem Sie zuvor hello.c abgelegt haben, das Kommando
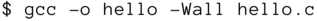
aus. Sie rufen den Compiler auf und sagen ihm mit der Option -o, wie die Datei mit dem generierten Programmcode heißen soll, nämlich hello. Probieren Sie ruhig einmal aus, was geschieht, wenn Sie diese Option »vergessen«. Die Option -Wall weist den Compiler an, Ihren Quellcode besonders kritisch zu analysieren und auf alle verdächtigen Stellen im Quelltext hinzuweisen. Das letzte Argument ist der Name der Quelltextdatei, die übersetzt werden soll.
Syntaktische Fehler wird der Compiler mit einer oder mehreren Fehlermeldungen kommentieren, wie im folgenden Beispiel:

Am Anfang ist es nicht immer ganz einfach, aus den kryptischen Fehlermeldungen des Compilers auf den konkreten Fehler im Quelltext zu schließen. Nützlich ist die Angabe der Nummer der Zeile, in der der Fehler erkannt wurde: Im Beispiel hat ein schusseliger Programmierer in Zeile 5 primtf anstelle printf geschrieben. Die Stelle im Quellcode wird durch die Wellenlinie extra hervorgehoben. Die restlichen Ausschriften beziehen sich ebenso auf diesen im Grunde genommen klitzekleinen Fehler.
Solange der Compiler syntaktische Fehler findet, wird kein Programmcode generiert. Sie müssen zunächst diese Fehler korrigieren, daher empfiehlt es sich, stets den Editor mit dem Quelltext in einem extra Fenster parat zu haben. Vergessen Sie nicht, nach Korrekturen am Quelltext den Compiler erneut aufzurufen!
Wenn Sie den Quellcode fehlerfrei abgetippt haben, dann kehrt der Compileraufruf stillschweigend zurück, und das ist unter UNIX fast immer ein gutes Zeichen. Es gilt nämlich die Regel, dass Kommandos nur im Fehlerfalle Meldungen ausgeben sollen. Die Abwesenheit derselben bedeutet also, dass das Kommando fehlerfrei das getan hat, was es soll. Im vorliegenden Fall hat es aus dem C-Quelltext eine ausführungsfähige Datei mit dem Programmcode erzeugt.
Sie können nun das frisch übersetzte Programm aufrufen. Dies geschieht, indem Sie vor den Programmnamen eine Pfadangabe setzen. Die kürzestmögliche Pfadangabe ist ./, also das aktuelle Verzeichnis.

Das Programm funktioniert! Nun müssen Sie aber verstehen, was Sie eingegeben haben! Sehen Sie sich dazu bitte das Listing 3.2 erneut an. In Zeile 1 finden Sie ein sogenanntes Präprozessorstatement. Es sorgt dafür, dass Sie innerhalb des Programms auf die Funktionen der Standardbibliothek zugreifen können, indem es den Code der zugehörigen sogenannten Header-Datei (hier: stdio.h) an dieser Stelle in den Quelltext einfügt. Diese Standardbibliothek benötigt man fast immer; sie bietet häufig verwendete Funktionen beispielsweise zur Ein- und Ausgabe auf der Textkonsole und zur Arbeit mit Dateien.
Zeile 3 enthält einen Kommentar. Dieser ist für den Ablauf des Programms irrelevant und hat nur den Sinn, dem Leser des Codes Hinweise zu geben, wie das Programm funktioniert. Alles, was zwischen den Symbolen /* und */ steht, wird durch den Compiler ignoriert. Sie ahnen es bestimmt schon: Diese Kommentare sind sowohl für Fremde als auch für den Autor selbst ein wichtiges Hilfsmittel, um Übersicht im Code zu behalten.
In Zeile 4 wird die sogenannte main-Funktion definiert. C-Programme bestehen nämlich im Wesentlichen aus Funktionen, und die main-Funktion muss in jedem Programm vorkommen. Hier beginnt stets die Abarbeitung.
Den Funktionskopf überspringen wir ausnahmsweise und schauen uns gleich an, was innerhalb von main() im Funktionskörper geschieht. Dieser wird durch geschweifte Klammern { } eingeschlossen.
In Zeile 6 sehen wir die erste »richtige« Anweisung: printf("Hello, world\n"). Es handelt sich hierbei um einen Aufruf der Bibliotheksfunktion printf(), die dafür genutzt wird, ihre Argumente auf dem Bildschirm auszugeben. Das Argument von printf() ist eine in Anführungszeichen eingeschlossene Zeichenkette, die mit einem ∖n-Symbol endet. Es repräsentiert einen Zeilenvorschub (newline), der die auszugebende Zeile abschließt. Die Anweisung gibt also »Hello, world!« auf einer Zeile aus. Jede Anweisung, so auch der printf()-Aufruf wird durch ein Semikolon beendet.
Die letzte Anweisung unseres kleinen Programms ist return 0 in Zeile 7. Diese Anweisung verlässt sofort die aktuell ausgeführte Funktion und liefert den Resultatwert, der hinter return steht (also 0), an die rufende Umgebung zurück. Da wir uns noch in der Hauptfunktion befinden, wird diese verlassen, und die Abarbeitung des Programms endet somit.
 Warum keine integrierte Entwicklungsumgebung?
Warum keine integrierte Entwicklungsumgebung?
Wenn Sie schon über etwas Programmiererfahrung verfügen, dann stellen Sie sich vielleicht die Frage, wieso wir in diesem Buch keine integrierte Entwicklungsumgebung (auch Integrated Development Environment, IDE, genannt) wie »Visual Studio« oder »Eclipse« einsetzen? Diese umfasst im Allgemeinen mehrere Werkzeuge wie Editor, Debugger und Codeverwaltung und präsentiert alle in einer einheitlichen grafischen Oberfläche.
Nun, zum einen sind die im Rahmen dieses Buches entwickelten Quelltexte eher kurz und benötigen die umfangreiche Funktionalität dieser Werkzeuge kaum. Zum anderen ist es nach Erfahrung des Autors ungünstig, dass IDEs viele der notwendigen Operationen auf dem Weg zum korrekten Programmcode verbergen. Der Entwickler drückt auf einen Knopf, und dann werden Compiler und Linker nacheinander aufgerufen, ein Terminal wird geöffnet und das übersetzte Programm sofort ausgeführt. Etwaige Warnungen des Compilers scrollen in einem verhältnismäßig kleinen Fenster durch und entgehen dadurch der Aufmerksamkeit des Programmierers. Zumindest für die ersten Gehversuche sollte daher auf die elementaren Kommandozeilenwerkzeuge zurückgegriffen werden, wenn diese auch auf den ersten Blick archaisch wirken.
Aller Anfang ist schwer
Nun ist es Zeit, sich mit den syntaktischen Elementen von C auseinanderzusetzen. Sie sollen auf den nächsten Seiten in die Lage versetzt werden, C-Programme zu lesen (also zu verstehen), diese zu modifizieren und danach selbst Experimente mit (verhältnismäßig kleinen) C-Programmen durchzuführen. Sie werden nach der Lektüre noch kein C-Experte sein, der sich selbstständig durch den Linux-Kernel wühlt, aber den ersten Schritt auf diesem Weg haben Sie mit Sicherheit bewältigt.
Daten
Programme arbeiten mit Daten, das sind allgemein Informationen in einer digitalen Repräsentation. Zur Aufbewahrung von Daten innerhalb eines Programms stellen Programmiersprachen verschiedene Abstraktionen wie Datentypen, Konstanten und Variablen zur Verfügung. Beginnen wir zunächst mit den wichtigsten Datentypen.
Grunddatentypen
Zunächst muss man die Grunddatentypen von den sogenannten zusammengesetzten Datentypen unterscheiden. Die Grunddatentypen dienen dem effektiven Zugriff auf einzelne Speicherstellen und bilden Zeichen, ganze und reelle Zahlen ab. Tabelle 3.1 führt die wichtigsten auf.
Typ |
Semantik |
Größe |
Beispiel |
|---|---|---|---|
|
Zeichen |
8 Bit |
|
|
Ganzzahl |
64 Bit |
−6495 |
|
Gleitkommazahl |
32 Bit |
4.669201 |
Tabelle 3.1: Die wichtigsten Grunddatentypen in C
Der Typ char ist eigentlich auch ein Integer, wird aber fast immer zur Repräsentation eines Zeichens (»character«) eingesetzt. Er umfasst stets ein Byte. Der Speicherbedarf eines Integer-Wertes (int), also einer ganzen Zahl, hängt vom Prozessor ab. Seine Größe ist die effektive Verarbeitungsbreite des Prozessors; in den heute gängigen PC-Architekturen sind das 64 Bit, in den 1990er-Jahren waren es 32 Bit. Der Typ float repräsentiert eine einfach genaue Gleitkommazahl gemäß Standard IEEE 754. Sie werden ihn in diesem Buch kaum verwenden.
Den Typen char und int können die Modifikatoren signed und unsigned vorangestellt werden. Ist nichts angegeben, dann gilt signed, also eine Interpretation als vorzeichenbehaftete Zahl. Zusätzlich kann der Typ int mit den Schlüsselwörtern short und long im Speicherbedarf (und Wertebereich) verkürzt respektive verlängert werden. Des Weiteren gibt es den Typ double, der eine Gleitkommazahl (Sie ahnen es) doppelter Genauigkeit repräsentiert.
Da die Grunddatentypen eine fixe Größe aufweisen, können sie auch nur einen endlichen Wertebereich abbilden. Variablen vom Typ unsigned char können beispielsweise nur Werte zwischen null und 255 annehmen, was bei einem Speicherbedarf von acht Bit einigermaßen einleuchten sollte. Analog reicht der Wertebereich eines signed char (und damit auch eines char) von -128 bis 127.
Die Grunddatentypen mit ihren Modifikationen und Wertebereichen sind ein bisschen schwierig zu verstehen. In der Praxis benötigt man vor allem char, int und long int. Letzteren darf man zu long abkürzen, was fast immer auch gemacht wird. Wertebereichsüberschreitungen muss man immer dort in Betracht ziehen, wo mit großen Mengen an Informationen gearbeitet wird. Bei Betriebssystemen sind das beispielsweise die Verwaltung des Haupt- und insbesondere des Massenspeichers, also das Dateisystem.
C ist übrigens eine streng getypte Sprache. Das bedeutet, dass Sie jeglichen Variablen vor ihrer Benutzung einen expliziten Typ zuweisen müssen. Es ist unmöglich, dass der Compiler aus der Zuweisung eines Wertes an eine Variable den Typ dieser gewissermaßen »errät«.
Zahlensysteme
Sie wissen sicherlich, dass man ganzzahlige Werte durch Zahlensysteme mit unterschiedlichen Basen darstellen kann. Im normalen Leben hat sich weitestgehend das Dezimalsystem durchgesetzt, während die Babylonier aus unerfindlichen Gründen im Sexagesimalsystem (zur Basis 60) arbeiteten, was einige Schwierigkeiten beim Rechnen nach sich zog. Informatiker benutzen außer dem Dezimalsystem auch gern das Oktalsystem (Basis 8) und das Hexadezimalsystem (Basis 16).
In C werden Oktalzahlen durch eine vorangestellte 0 und Hexadezimalzahlen durch das Präfix 0x gekennzeichnet. Die (oktale) Zahl 0640 hat dezimal also den Wert 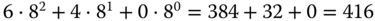 , und die hexadezimale Zahl
, und die hexadezimale Zahl 0xAFFE steht für einen dezimalen Wert von
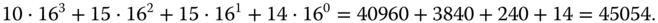
Hexadezimalzahlen nutzt man sehr gern für Adressen im Hauptspeicher.
Warum können amerikanische Programmierer Weihnachten nicht von Halloween unterscheiden? Weil bei ihnen »Dec 25 = Oct 31« gilt. Die Zahl 25 im Dezimalsystem (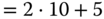 ) ergibt im Oktalsystem 31 (
) ergibt im Oktalsystem 31 (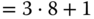 ). Der Witz zündet im Deutschen nicht so richtig, weil wir bereits am 24. Dezember Weihnachten feiern und nur wenige wissen, wann Halloween gefeiert wird.
). Der Witz zündet im Deutschen nicht so richtig, weil wir bereits am 24. Dezember Weihnachten feiern und nur wenige wissen, wann Halloween gefeiert wird.
Eine explizite Darstellung für Werte im Binärsystem gibt es übrigens in C nicht, zumindest nicht im Sprachstandard. Viele Compiler ignorieren dies aber; zum Beispiel können Sie im gcc binäre Konstanten durch das Präfix 0b vereinbaren. Das ist aber fragwürdig, weil man damit die Portabilität des Codes, also die potenzielle Übertragbarkeit auf andere Plattformen, aufgibt.
Variablen
Variablen sind im Grunde genommen nichts weiter als benannte Speicherplätze, deren Inhalt auf eine bestimmte Art und Weise interpretiert wird. Der Typ der Variablen bestimmt die Interpretation. Die Grunddatentypen kennen Sie bereits, die zusammengesetzten Typen erlernen Sie etwas später. Außer dem Typ besitzt jede Variable noch eine Speicherklasse und einen Bezeichner, den Variablennamen.
Diese unterliegen den folgenden Regeln:
- Nur Buchstaben, Ziffern und der Unterstrich
_sind erlaubt. - Das erste Zeichen muss ein Buchstabe oder
_sein. - Groß- und Kleinbuchstaben werden unterschieden.
befAktundbefaktsind zwei verschiedene Bezeichner. - Die Länge eines Bezeichners ist beliebig.
- C-Schlüsselworte sind unzulässig (sie können aber Bestandteil eines längeren Namens sein).
Somit sind var1, naechsterKunde und automat gültige Variablenbezeichner, während 1neVariable und auto-mat nicht erlaubt sind.
Der Programmierer kann die Namen unter Beachtung dieser Regeln frei festlegen, diese sollten aber stets deskriptiv, das heißt den Zweck beschreibend, gewählt werden. Gute Variablennamen sind nextElem oder InputFD, schlechte Beispiele sind var1 oder x2.
Die sogenannte Speicherklasse legt die Lebensdauer und Sichtbarkeit der Variablen fest; sie kann die Werte auto, register, static und extern annehmen. Verzichtet man auf die explizite Angabe der Speicherklasse, dann wird auto angenommen: Die Variable wird (automatisch) angelegt, wenn die betreffende Funktion betreten wird, und zerstört, sobald die Funktion wieder verlassen wird. Die anderen Speicherklassen sparen wir zunächst aus.
Variablen werden im Kopf der Funktion definiert und gegebenenfalls gleich mit einem Wert belegt, indem ihnen mit dem Zuweisungsoperator = ein initialer Wert zugewiesen wird. Formal kann man eine Variablendefinition mittels der sogenannten Backus-Naur-Form folgendermaßen ausdrücken:
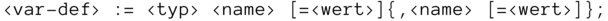
Backus-Naur-Form
Diese formale Notation finden Sie in diesem Kapitel noch häufiger. Es handelt sich um eine vereinfachte Form der sogenannten Backus-Naur-Notation. Sie dient zur Definition von Kategorien innerhalb syntaktischer Regelsysteme. Etwas weniger hochtrabend formuliert: Damit beschreiben wir die Regeln einer formalen Sprache, wie im vorliegenden Fall der Programmiersprache C. Die Backus-Naur-Form ist also eine Sprache zur Beschreibung von Sprachen, was der Informatiker Metasprache nennt.
Für diese Metasprache gelten wiederum Regeln, und zwar die folgenden:
- Ausdrücke in
< >sind Metasymbole und müssen an anderer Stelle definiert werden. - der Zuweisungsoperator
:=trennt das (links stehende) zu definierende Metasymbol von dessen (rechts stehender) Definition - Ausdrücke in
[ ]können genau einmal stehen oder fortgelassen werden. - Ausdrücke in
{ }können beliebig häufig stehen (also auch fortgelassen werden). - Alle Zeichen, die keine Metasymbole sind, stehen für sich selbst.
- Von Ausdrücken, die durch
|getrennt stehen, darf genau einer stehen.
Ein ganz einfaches Regelsystem wäre
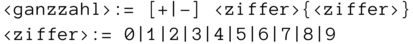
zur syntaktischen Beschreibung einer Ganzzahl, also eines Datums vom Typ int oder long.
Man kann das gesamte Regelwerk einer Programmiersprache mittels Backus-Naur-Form beschreiben. Wir nutzen sie ausschließlich in diesem Kapitel und nur, um die wichtigsten programmiersprachlichen Konstrukte zu definieren.
Zunächst wird der Variablentyp angegeben, dann ihr Name. Danach kann (muss aber nicht) der Zuweisungsoperator und ein dem Typ entsprechender Wert stehen. Mehrere Variablen gleichen Typs können durch Komma getrennt in einer Zeile definiert werden.
Einige Beispiele für korrekte Initialisierungen sind:

Die Initialisierung kann auch getrennt von der Definition später erfolgen, sie darf jedoch nicht vergessen werden!
Werden Variablen innerhalb einer Funktion definiert, so sind diese nur in dieser Funktion benutzbar. Jedes Mal, wenn die Funktion ausgeführt wird, werden diese Variablen angelegt, und sie werden zerstört, wenn die Funktion wieder verlassen wird. Man spricht von lokalen Variablen.
Im Unterschied dazu gibt es die globalen Variablen, die außerhalb jeder Funktion definiert werden und im ganzen Programm und innerhalb jeder Funktion sichtbar sind. Sie werden beim Programmstart mit einem Wert belegt und niemals zerstört.
Eine dritte Form, die dynamischen Variablen, erzeugt und zerstört der Programmierer zu selbst gewählten Zeitpunkten. Um diese zu verstehen, muss zuvor das Konzept der Zeiger behandelt werden.
Konstanten
Konstanten sind in gewissem Sinne als Antipoden zu Variablen zu verstehen. Technisch gesehen handelt es sich um Variablen, da sie ebenfalls Speicherplatz repräsentieren, aber ihr Wert darf sich nicht ändern. Das Schlüsselwort const qualifiziert die Variable zur Konstanten.
Man unterscheidet ganzzahlige Konstanten, Gleitkomma-Konstanten und Zeichenkonstanten. Ganzzahlige Konstanten kann man dezimal, oktal und hexadezimal vereinbaren, wie im Abschnitt »Zahlensysteme« diskutiert. Für Gleitkomma-Konstanten sind ebenfalls verschiedene Schreibweisen möglich, die wir geflissentlich ignorieren.
Zeichenkonstanten repräsentieren ein einzelnes Zeichen und werden in Apostrophe ('’) eingeschlossen. Sie haben somit den typischen Wertebereich der ASCII-Kodierung zwischen null und 255 und werden meist in Zusammenhang mit dem Typ char genutzt. Als Zeichenkonstanten kann man auch einige spezielle Zeichen repräsentieren, wie Tabelle 3.2 zeigt.
Einige Beispiele für korrekte Konstantenvereinbarungen zeigt das folgende Listing:

Die letzte Variable, message, ist kein Grunddatentyp, sondern ein Feld (Array), das schon ein Beispiel für einen zusammengesetzten Typ ist. Diesen werden Sie im nächsten Abschnitt näher kennenlernen.
Zeichen |
Bedeutung |
|---|---|
|
Ziffer null |
|
Buchstabe x |
|
Anführungszeichen |
|
Nullbyte |
|
Newline-Zeichen (Zeilenvorschub) |
|
Tabulator-Zeichen |
|
Apostroph |
|
Backslash |
|
Bitmuster als Oktalzahl (3 Ziffern) |
Tabelle 3.2: Beispiele einiger wichtiger Zeichenkonstanten
Zusammengesetzte Typen
Häufig ist es nützlich, mehrere Grunddatentypen zu einem zusammengesetzten Typ zu aggregieren. Es können dabei mehrere Variablen identischen Typs (dann erhält man ein Feld oder Array) oder Variablen verschiedenen Typs (dann bekommt man eine Struktur oder struct) zusammengefügt werden. Auch die Verwendung zusammengesetzter Typen zur Konstruktion komplexerer zusammengesetzter Typen ist selbstverständlich möglich.
Darüber hinaus bietet C die Vereinigung (union) und Aufzählungstypen (enum) an.
Felder
Der wichtigste zusammengesetzte Datentyp in C ist zweifelsohne das Feld oder Array. Ein Feld ist nichts weiter als eine feste Anzahl von Elementen eines beliebigen Typs. Bei der Definition eines Feldes wird dessen Elementanzahl nach dem Namen in [ ] angegeben. Beispiel:

vereinbart ein Feld von 100 Ganzzahlen namens fib. Um auf ein bestimmtes Element des Feldes zuzugreifen, wird dessen Index wiederum in eckigen Klammern angegeben. Dabei wird in C (wie allgemein in der Informatik üblich) stets von null beginnend gezählt. Beispiele zum Zugriff auf die Feldelemente sind:
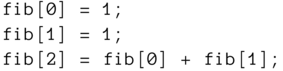
Ein Zugriff auf fib[100] würde einen Fehler verursachen, denn das Feld wurde nur mit 100 Elementen vereinbart, die mit den Indizes 0…99 referenziert werden können. Diese sogenannten Off-by-One Errors – im Deutschen vielleicht »Fehler infolge Abweichung um 1« – sind in C häufig zu beobachten, weil zur Laufzeit keine Prüfung der Gültigkeit von Feldindizes erfolgt.
Wenn Sie genau aufgepasst haben, dann ist Ihnen im vorangegangenen Abschnitt über Konstanten sicher das letzte Initialisierungsbeispiel (mit dem Feld message) aufgefallen. Die fehlende Angabe der Feldgröße ist keine Nachlässigkeit des Autors, sondern es handelt sich um eine implizite Größenangabe. Die für die Initialisierung angegebene Zeichenkette determiniert die Größe des Feldes, ohne dass diese explizit irgendwo im Code verankert ist. Sie beträgt im Beispiel 31. Der reine Text umfasst 29 Zeichen, dazu kommt der am Ende stehende Zeilenumbruch '\n' (1 Byte) und das die Zeichenkette terminierende Nullbyte, das Sie im nächsten Abschnitt »Zeichenketten« kennenlernen werden.
Es gibt in C auch mehrdimensionale Felder, diese benötigen Sie für die Lektüre dieses Buches jedoch nicht.
Zeichenketten
Ein schwerer »Geburtsfehler« der Programmiersprache C ist das Fehlen eines Datentyps für Zeichenketten. Kernighan und Ritchie sahen wohl eher Anwendungen mathematisch-naturwissenschaftlicher Aufgabenstellungen. Man nutzt stattdessen Felder des Typs char. Eine typische Definition inklusive Initialisierung sieht so aus:

Die Repräsentation als Feld von Ganzzahlen im Speicher zeigt Abbildung 3.2, wobei jedes Kästchen ein Byte enthält. Die Zeichen werden gemäß ASCII kodiert; somit hat das Leerzeichen den Wert (dezimal) 32 und das Ausrufezeichen den Wert 33.

Abbildung 3.2: Die Zeichenkette msg im Speicher
Am Ende der Zeichenkette befindet sich ein Zeilenvorschub (Newline), der durch das Symbol \n dargestellt wird (Tabelle 3.2, Sie erinnern sich?). Wenn die Zeichenkette ausgegeben würde, dann würde an dieser Stelle die Ausgabe in der aktuellen Zeile unterbrochen und an Position 0 der folgenden Zeile fortgesetzt werden, was sich allerdings erst auf nachfolgende Ausgaben auswirken würde.
Zeichenketten werden in C stets durch ein Nullbyte abgeschlossen. Dieses wird automatisch bei obiger Wertzuweisung mitgeschrieben, denn jede Folge von Zeichen in Anführungszeichen steht für eine nullterminierte Zeichenkette. Es ist eminent wichtig, dieses Nullbyte immer mit einzuplanen und insbesondere dafür auch Speicherplatz vorzusehen.
Die abgelegte Zeichenkette ist übrigens kürzer als der Speicher für msg, die restlichen Bytes daher haben einen undefinierten Wert.
Strukturen
Strukturen (structs) sind Zusammenfassungen von Elementen verschiedenen Typs in einem Objekt. Die Elemente selbst können elementare Typen oder wiederum structs sein. Wenn man mit Strukturen arbeiten möchte, muss man in zwei Schritten vorgehen:
- Die Struktur muss definiert werden. Dies geschieht folgendermaßen:

Sehen Sie sich das Beispiel eines
structan, das ein Datum repräsentieren soll:
Es besteht aus drei Ganzzahlvariablen, die das Jahr, den Monat und den Tag des zu bezeichnenden Datums aufnehmen. Zusätzlich gibt es eine Komponente
weekday, in der ein gängiges Kürzel des entsprechenden Wochentags, alsoMo,Di, …Soaufbewahrt wird. Dies wird durch ein dreielementiges Feld von Zeichen realisiert. (Warum reichen nicht zwei Elemente?) - Instanzen, also typischerweise Variablen der Struktur müssen angelegt werden, nämlich so:

Das Schlüsselwort
struct, gefolgt vom Namen der Struktur, wird gefolgt von einem oder mehreren Variablennamen. Beispielsweise legt die folgende Anweisung zwei Variablen vomstruct datean, das zuvor definiert wurde: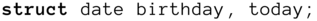
- Die angelegten Instanzen müssen mit Werten belegt werden. Um auf die Elemente eines
structzuzugreifen, schreibt man den Namen desstruct, dann einen Punkt (».«), gefolgt vom Namen der Komponente. Listing 3 zeigt ein Beispiel.
Beachten Sie, dass es keine Zuweisungsoperation für Zeichenketten gibt. Stattdessen muss man auf eine Funktion (hier:
strcpy()für »string copy«) zurückgreifen. Die genutzte Funktionstrcpykopiert die als zweites Argument übergebene Zeichenkette an die als erstes Argument übergebene Adresse.Es gibt noch eine zweite Variante, um auf Elemente eines
structzuzugreifen, nämlich mit dem Operator »->«. Dazu müssen Sie aber zunächst verstehen, was Zeiger in C sind.
Auf die zusammengesetzten Typen »Vereinigung« (union) und »Aufzählungstyp« (enum) wird an dieser Stelle verzichtet.
Typumwandlung
Nun haben Sie alle für das Buch relevanten Datentypen kennengelernt, es fehlt aber noch eine relevante Operation. Manchmal muss man Werte verschiedenen Type miteinander kombinieren, und dazu ist eine Umwandlung aus einem Typ in einen anderen Typ notwendig. Diese Typumwandlung (im englischen typecast genannte Operation sieht syntaktisch folgendermaßen aus:

Der gewünschte Typ, den das Datum in <ausdruck> annehmen soll, wird also in Klammern dem Ausdruck einfach vorangestellt. Dabei muss natürlich eine Umwandelbarkeit vorliegen. Probieren Sie doch spaßeshalber aus, was passiert, wenn Sie eine Zeichenkette in eine Integerzahl umwandeln. (Der Compiler warnt in diesem Falle vor der Operation, generiert aber trotzdem Code.)
Zum Zweiten muss man beim Umwandeln die Wertebereiche beachten. Umwandlungen in einen größeren Wertebereich sind problemlos, aber Umwandlungen in einen kleineren Wertebereich (beispielsweise von long in int) sind problematisch. Sie sind als Programmierer dafür verantwortlich, dass der Wert des Datums nicht den Wertebereich des Zieldatentyps verlässt, andernfalls sind Laufzeitfehler unausweichlich. Dies ist insbesondere beim Umwandeln zwischen vorzeichenbehafteten (signed) und vorzeichenlosen (unsigned) Varianten ein und desselben Grunddatentyps zu beachten.
Sie sollten sich also beim Definieren von Variablen stets gut überlegen, welche Werte diese annehmen können.
Damit haben Sie den Komplex »Datentypen, Variablen, Konstanten in C« bewältigt. Aus diesen Bausteinen konstruieren Sie im nächsten Abschnitt mit Hilfe von Operatoren Ausdrücke.
Ausdrücke und Operatoren
Während der Lektüre des Kapitels ist Ihnen bereits mehrfach der Begriff »Zuweisungsoperator« begegnet, ohne dass dieser explizit erläutert wurde. Es gibt aber noch viele weitere Operatoren und dazu auch noch Operanden. Beide Kategorien (und ihr Verhältnis zueinander) erlernen Sie in diesem Abschnitt.
Ein wichtiger Bestandteil jeder Programmiersprache sind Ausdrücke. Diese verknüpfen Operanden mit Operatoren. Operanden sind entweder Variablen, Konstanten oder ihrerseits Ausdrücke, sind Ihnen also aus der bisherigen Lektüre vertraut.
Einfache Operatoren
Es fehlen noch die Operatoren; in der Mathematik würde man von »Operationssymbolen« sprechen. Werfen Sie zunächst bitte einen Blick auf die arithmetischen und die Vergleichsoperatoren in Tabelle 3.3.
Operator |
Bedeutung |
Operator |
Bedeutung |
|---|---|---|---|
|
unäres Vorzeichen |
|
größer als |
|
Subtraktion, Addition |
|
größer oder gleich |
|
Multiplikation, Division |
|
kleiner als |
|
Rest bei ganzzahliger Division |
|
kleiner oder gleich |
|
gleich |
||
|
ungleich |
Tabelle 3.3: Arithmetische (links) und Vergleichsoperatoren (rechts)
C bildet also im Großen und Ganzen die Grundrechenarten (allerdings mit unterschiedlichen Datentypen) und alle möglichen Vergleichsoperatoren ab. Bitte beachten Sie, dass Gleichheit mittels == und nicht mit = (das ist nämlich der Zuweisungsoperator!) geprüft wird. Die Verwechslung beider ist einer der beliebtesten Programmierfehler!
Wertzuweisung
Nun kommen wir endlich zur bereits mehrfach verwendeten und angekündigten Wertzuweisung. Diese Operation wird immer dann benötigt, wenn Sie den Inhalt eines Speicherplatzes modifizieren wollen, also schreibend auf den Speicher zugreifen. Formal sieht die Wertzuweisung so aus:
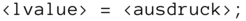
Unter der Bezeichnung lvalue versteht man einen modifizierbaren Hauptspeicherbereich, also beispielsweise eine Variable. Einige Beispiele für Wertzuweisungen sind die folgenden.

Die erste Anweisung (in Zeile 2; zuvor müssen die benutzten Variablen definiert werden) prüft keine Gleichheit des Wertes von x mit 23, sondern schreibt den Wert 23 in die Variable x. Man kann die Anweisung lesen als »x ergibt sich aus 23«. Die dritte Anweisung ist ein Funktionsaufruf, den Sie etwas später kennenlernen.
Inkrement- und Dekrementoperator
Zwei sehr gern in C genutzte Operatoren sind der Inkrementoperator ++ und der Dekrementoperator --. Im einfachsten Falle wendet man sie auf Variablen an, und dann inkrementieren oder dekrementieren sie diese einfach.

ist identisch mit
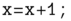
Beide Operatoren besitzen jedoch einen Nebeneffekt, der nicht unerwähnt bleiben darf. Sie können beide Operatoren entweder in Präfixnotation

oder in Postfixnotation

einsetzen. Im ersten Falle wird zuerst die Variable (der <lvalue>) modifiziert und dann der Rest des Ausdrucks, in dem sich der Operator befindet, ausgewertet. Im zweiten Fall ist es genau andersherum: Es wird zunächst der Gesamtausdruck ausgewertet und als Letztes die betreffende Variable modifiziert. Das wird an einem Beispiel schnell klar:

Sie haben es in Zeile 2 mit der Postfix-Variante des Inkrements zu tun. Die Teiloperationen werden in der folgenden Reihenfolge ausgeführt:
- Der Gesamtausdruck wird ausgewertet (damit erhält
yden Wert42). - Danach wird
xinkrementiert (also enthältxnun43).
Stünde anstelle von x++ jedoch --x, dann hätten x und y den Wert 41! Alles klar?
Vorsicht vor Seiteneffekten!
Richtig hässlich wird es übrigens, wenn diese Operatoren mehrfach in ein und demselben Ausdruck vorkommen, vielleicht wie in diesem kurzen Programm:

Das erste Inkrement x++ soll nach Evaluation des Gesamtausdrucks ausgeführt werden, das zweite vor der Evaluation. Wenn jedoch initial x erhöht wird, wirkt sich dies dann auf den ersten Operand auch aus oder nicht? Erhält y also den Wert 2*3 zugewiesen oder 3*3? Und bezieht sich der Postfix-Operator auf den ursprünglichen Wert von x oder auf den bereits inkrementierten?
Probieren Sie es am besten aus. Wenn Sie alle Warnungen einschalten, weist Sie der Compiler auf das fragwürdige Konstrukt hin (dies tut er interessanterweise nicht, wenn Sie den Schalter -Wall weglassen). Das System des Autors ermittelt im konkreten Fall für y den Wert 8 (er rechnet also 2*4) und für x den Wert 4.
Auf Ausdrücke, die mehrere Prä- oder Postinkrementoperationen enthalten, sollten Sie somit unbedingt verzichten.
Logische und Bitoperatoren
Zwei weitere Typen von Operatoren müssen noch erlernt werden. Zum einen ist es häufig notwendig, logische Werte, wie durch die bereits erlernten Vergleichsoperatoren geliefert, miteinander zu verknüpfen. Dies geschieht mit den in Tabelle 3.4 aufgeführten logischen Operatoren.
Operand |
Semantik |
|---|---|
|
logisches UND |
|
logisches ODER |
|
logische Negation |
Tabelle 3.4: Logische Verknüpfungen in C
Diese Operatoren benötigen Sie beispielsweise für Schleifen und die if-Anweisung. Drei kurze Beispiele illustrieren die Benutzung (x und y sollen vom Typ int sein):

Der erste Ausdruck wird wahr, wenn x Werte zwischen 23 und 42 (inklusive) annimmt, ansonsten ist er falsch. Der zweite Ausdruck wird wahr, wenn x entweder den Wert 23 oder den Wert 42 annimmt oder wenn y gleich 0 ist (der Wert von x ist in diesem Falle egal).
Der dritte Ausdruck ist syntaktisch korrekt, aber ein Musterbeispiel für schlechte Lesbarkeit. Er wird wahr, wenn x entweder 'a' oder 'b' enthält. Im Interesse besserer Lesbarkeit sollte er unmittelbar vereinfacht werden zu
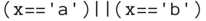
Auch der allererste Ausdruck ist übrigens verbesserbar, was Ihnen zur Übung überlassen sei.
Zum Zweiten gibt es zum Zwecke der Manipulation einzelner Bits die in Tabelle 3.5 aufgeführten Bitoperatoren. Diese dürfen nicht mit den gerade behandelten logischen Operatoren verwechselt werden, was infolge der Ähnlichkeit leider sehr häufig geschieht.
Operand |
Semantik |
|---|---|
|
(bitweises) UND |
|
(bitweises) ODER |
|
(bitweises) XOR |
|
Einerkomplement |
|
(bitweises) Schieben nach links |
|
(bitweises) Schieben nach rechts |
Tabelle 3.5: Bitoperatoren in C
Im Gegensatz zu den unmittelbar zuvor erlernten logischen Operatoren, die nur die Wahrheitswerte wahr und falsch kennen, müssen hier die Operanden integrale Typen (char, int, short, long) sein, die Bit für Bit miteinander verknüpft werden.
Bei den Schiebeoperatoren muss die Anzahl an Bits angegeben werden, um die verschoben werden soll. Diese muss kleiner sein als die Länge des Operanden in Bit. Man kann also keine 8-Bit-Zahl um 12 Bit verschieben.
Ein kleines Programm soll die Arbeitsweise der Bitoperatoren illustrieren (Listing 3.3). Die Arbeitsweise der mehrfach genutzten Funktion printf() erlernen Sie im nächsten Abschnitt.

Listing 3.3: Beispiel zur Illustration der Bitoperationen
Überzeugen Sie sich bitte auch, dass das Linksschieben eines Operanden einer Multiplikation mit einer Zweierpotenz entspricht, während die Schiebeoperation nach rechts einer (ganzzahligen) Division durch eine Zweierpotenz entspricht.
Präzedenz: Die Vorfahrtregeln von C
Aus dem Mathematikunterricht kennen Sie sicherlich die Regel: »Punktrechnung geht vor Strichrechnung.« Wenn Sie also beispielsweise programmieren
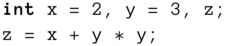
dann bewirkt die eben genannte Regel, dass in z der Wert 11 abgelegt wird, da die Multiplikation vor der Addition erledigt wird. C besitzt nun weitaus mehr Operatoren als die vier Grundrechenarten, und für diese gibt es ganz ähnliche Regeln in Form der sogenannten Operatorpräzedenz. Tabelle 3.6 führt die »Priorität« der wichtigsten Operatoren auf. Lassen Sie sich bitte nicht von einigen neuen Symbolen (->, (<Typ>)) irritieren, diese erlernen Sie später noch. Wie Sie sehen, hat auch in C die »Punktrechnung« (also die Multiplikation und Division) Vorrang vor der »Strichrechnung« (Addition und Subtraktion).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
 höchste
höchste niedrigste
niedrigsteTabelle 3.6: Präzedenz der wichtigsten Operatoren in C
Man kann die Präzedenz außer Kraft setzen, in dem man die Ausdrücke, die zuerst ausgewertet werden sollen, klammert. Formuliert man also beispielsweise die Berechnung aus dem vorigen Beispiel so:

dann erhält man als Ergebnis für y den Wert 15. Falls man Tabelle 3.6 nicht vollständig im Kopf hat oder sich generell unsicher ist, ist es ratsam, die intendierte Berechnungsreihenfolge mit Klammern abzusichern.
Wenn Sie die Tabelle genau studieren, dann finden Sie einige Operatoren, die bislang überhaupt noch nicht angesprochen wurden. Dazu zählen alle neben dem Zuweisungsoperator (=) in der niedrigsten Präzedenzstufe, also +=, -= …>>=. Es handelt sich um die sogenannten Zuweisungsoperatoren, denn sie bestehen aus einer arithmetischen Operation und einer Zuweisung. Ziel der Zuweisung und der erste Operand der arithmetischen Operation ist ein und dieselbe Variable. Die Anweisung x+=y entspricht also x=x+y, und step«2 entspricht step=step«2 (was wiederum step=step*4 entspricht).
Ebenfalls noch nicht angesprochen wurde der sizeof-Operator. Er sieht aus wie eine Funktion und ermittelt den Speicherbedarf in Bytes für den übergebenen Typ oder das übergebene Datum, beispielsweise so: y=sizeof(long).
Hinein und wieder hinaus: Ein-/Ausgabe
Mit dem bisher erarbeiteten Wissen können Sie nun Daten definieren und diese auf vielfältige Weise miteinander verknüpfen. Sie benötigen jedoch Wege, um Ihrem Programm Eingabedaten zur Verfügung zu stellen und die Ergebnisse Ihrer Berechnungen auszugeben. Man spricht kurz von Mechanismen zur »Ein-/Ausgabe« oder im Englischen von »Input/Output«, was gewöhnlich weiter zu »I/O« abgekürzt wird.
Formatierte Ausgabe mittels printf()
C selbst bietet keine Anweisung für die Ein- und Ausgabe; stattdessen greift man auf Funktionen zurück, die in sogenannten Bibliotheken organisiert sind. Für die Ausgabe von Daten nutzt man sehr häufig die Funktion printf(). Bereits im allerersten »Hello, world«-Beispiel (Listing 3.2, Sie erinnern sich?) haben Sie printf() benutzt. Die Funktion dient der formatierten Ausgabe von Informationen und hat die folgende allgemeine Form:

Der formatstring wird auf der Konsole ausgegeben. Jedoch enthält er bestimmte Platzhalter, die vor der Ausgabe durch den Wert der dem Formatstring folgenden Argumente ersetzt werden. Die Platzhalter steuern das Ausgabeformat: ob beispielsweise eine Zahl dezimal oder hexadezimal ausgegeben wird, ob führende Nullen hinzugefügt werden und vieles mehr. Tabelle 3.7 führt einige Platzhalter mit ihrer Bedeutung auf.
Platzhalter |
Funktion |
|---|---|
|
Integer-Zahl, dezimale Ausgabe |
|
Integer-Zahl ( |
|
vorzeichenlose Integer-Zahl, ( |
|
Integer-Zahl, hexadezimale Ausgabe (Kleinbuchstaben) |
|
Integer-Zahl, hexadezimale Ausgabe (Großbuchstaben) |
|
Ausgabe einer Zeichenkette |
|
Integer-Zahl, Ausgabe als ASCII-Zeichen |
Tabelle 3.7: Platzhalter im formatstring von printf()
Wichtig ist, dass es genauso viele Platzhalter im formatstring gibt wie Argumente folgen (deren Anzahl übrigens beliebig sein kann).
Wiederum soll ein kleines Programm zur Veranschaulichung dienen (Listing 3.4). Beachten Sie das Erzwingen von führenden Nullen sowie die explizite Angabe der Ausgabelänge (4) in Zeile 8.

Listing 3.4: Beispiele zur formatierten Ausgabe mittels printf()
Es gibt noch einige weitere Platzhalter. (Finden Sie doch einmal heraus, was der Formatstring “%03.2lf” bedeutet oder wozu “%n” genutzt wird; die man-Page von printf enthält alle Informationen.) Es ist übrigens unbedingt notwendig, Formatstrings korrekt zu formulieren (beispielsweise für jeden Platzhalter auch wirklich ein Argument zu übergeben), andernfalls kann es passieren, dass Angreifer eine sogenannte »Formatstring-Attacke« auf Ihren Code loslassen.
Die Funktion printf() besitzt noch nahe Verwandte, die statt auf die Konsole in einen Hauptspeicherbereich (sprintf()) oder direkt in eine Datei (fprintf()) ausgeben.
Formatierte Eingabe von der Konsole (scanf())
Gewissermaßen spiegelbildlich funktioniert die Eingabe über die Konsole mittels scanf().

Die Funktion stoppt die Abarbeitung, und der Nutzer ist aufgefordert, einen oder mehrere Werte mittels der Konsole einzugeben. Die Argumente argument1, argument2 werden mit den eingegebenen Werten belegt.
Im Unterschied zu printf() enthält der formatstring keinen Ausgabetext, sondern nur Platzhalter, die den Typ und das Format der einzugebenden Daten festlegen, ganz ähnlich wie bei printf(). Wiederum müssen so viele Variablen angegeben werden, wie Platzhalter im formatstring stehen, und so viele Werte müssen bei der Ausführung auch eingegeben werden (meist ist es nur ein einziger). Im Unterschied zu printf() müssen nun aber Referenzen (das sind die Hauptspeicheradressen, an denen sich die Variablen befinden) angegeben werden, weil die Werte der übergebenen Variablen geändert werden sollen. Was Referenzen genau sind, erlernen Sie im Abschnitt »Zeiger«, hier ist es erst einmal nur wichtig, dass Sie ein &-Zeichen vor den Variablennamen setzen.
Die Eingabe muss syntaktisch korrekt erfolgen; Sie dürfen also beispielsweise keine Buchstaben eingeben, wenn eine Integer-Zahl eingelesen werden soll. Der Resultatwert von scanf() ist die Anzahl korrekt eingelesener Werte.
Um Zeichenketten einzulesen, nutzt man meist die Funktion fgets() anstelle von scanf().

Sie benötigt die Adresse eines Puffers (s), dessen Länge (size) und stdin als drittes Argument, sofern sie von der Konsole (und nicht aus einer Datei) lesen wollen.
Das Testprogramm in Listing 3.5 demonstriert die beiden Funktionen zur Eingabe.

Listing 3.5: Beispiel zur Ein-/Ausgabe mittels scanf(), fgets() und printf()
Ein Testlauf könnte beispielsweise die folgende Ausgabe produzieren:

Erst ersetzen, dann übersetzen: Der Präprozessor
Eine wesentliche Komponente der Programmiersprache C wurde bislang unterschlagen. Bevor der Compiler das in C formulierte Hochsprachenprogramm in Maschinencode übersetzt, bearbeitet der sogenannte Präprozessor den Quellcode. Seine Funktionalität ist auf reine Textersetzung beschränkt und wird durch Anweisungen gesteuert, die mit dem Zeichen '#' beginnen. Schon im »Hello, world«-Programm (Listing 3.2, Sie erinnern sich?) gab es die Präprozessoranweisung #include <stdio.h>. Sie dient dazu, sogenannte Header-Dateien bei der Übersetzung an dieser Stelle in den Quelltext einzufügen. Das ist notwendig, damit die Bibliotheksfunktionen definiert sind, bevor man diese benutzt.
Die Präprozessoranweisungen sind ziemlich mächtig; auf ihre Erörterung soll trotzdem weitgehend verzichtet werden. Zum einen sind sie für das Verständnis dieses Büchleins irrelevant, zum anderen kann man mit ihnen verhältnismäßig »wilde«, das heißt unverständliche und manchmal auch fehleranfällige Operationen am Quelltext vornehmen.
Eine Anweisung verwenden wir allerdings häufig. Mittels

kann man beliebige symbolische konstante Ausdrücke erzeugen, die die Lesbarkeit des Quelltextes im Allgemeinen erhöhen. Beispiele aus den im Buch enthaltenen Quelltexten sind
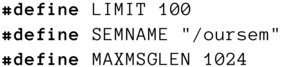
Bitte beachten Sie, dass diese symbolischen Konstanten keinen Speicherplatz reservieren, also keine Variablen oder Konstanten repräsentieren. Es sind reine Substitutionsoperationen; der Präprozessor ersetzt im Quelltext jedes Vorkommen von <Symbol> durch Zeichenkette.
Wenn Sie wissen wollen, wie Ihr Quelltext nach Behandlung durch den Präprozessor aussieht, dann rufen Sie
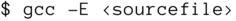
auf (aber erschrecken Sie nicht; insbesondere die #includes fügen große Mengen Code ein).
Konstrukte zur Steuerung der Abarbeitung
Mit den bisher erarbeiteten Mitteln sind Sie bereits in der Lage, vollständige einfache Programme zu entwickeln. Es fehlen nun noch Hilfsmittel, um den Abarbeitungsfluss zu steuern und zu strukturieren. In diesem Abschnitt lernen Sie daher Anweisungen kennen, die Verzweigungen und Schleifen verwirklichen, und im darauffolgenden Abschnitt lernen Sie Funktionen kennen.
Alternative
Ein für den Programmierer sehr nützliches Konstrukt ist die Alternative. Mit ihrer Hilfe ist es möglich, in Abhängigkeit von einer Bedingung unterschiedliche Codeblöcke auszuführen.
In C wird die Alternative durch die if-else-Anweisung realisiert. Sie hat die folgende allgemeine Form:

Nach dem Schlüsselwort if folgt ein in Klammern stehender Ausdruck. Ergibt dieser den Wahrheitswert »wahr« (oder allgemein einen numerischen Wert ungleich 0), dann wird der in geschweiften Klammern stehende Anweisungsblock (hier: <anweisungen1>) ausgeführt. Ist er »falsch« (oder hat den numerischen Wert 0), dann wird entweder nach der if-Anweisung fortgesetzt oder im Falle, dass ein else-Zweig angegeben wurde, der auf das Schlüsselwort else folgende Codeblock (hier: <anweisungen2>) ausgeführt.
Listing 3.6 zeigt ein konkretes Beispiel, das Sie gleich ausprobieren können. Die Bibliotheksfunktion scanf() in Zeile 8 liest einen Integer-Wert von der Konsole ein und legt diesen in der Variablen x ab. Dann soll in Abhängigkeit davon, ob x eine gerade oder ungerade Zahl ist, eine entsprechende Meldung ausgegeben werden. Genau dafür benötigen Sie die if-Anweisung.

Listing 3.6: Beispiel für if-else-Anweisung (gerade-ungerade.c)
Für die Bedingung ist ein Ausdruck notwendig, der 0 im geraden und ungleich 0 im ungeraden Fall liefert (umgekehrt funktioniert es natürlich auch); dies entspricht exakt dem Rest bei Division der zu betrachtenden Zahl durch 2. Ist dieser 0, dann ist die Zahl offenbar gerade, beträgt er 1, dann ist die Zahl ungerade. C bringt alles Nötige in Form der sogenannten modulo-Operation mit. Das Operationssymbol für »modulo« ist das '%'. Somit ermittelt x%2 den Rest, den man bei Division von x durch 2 erhält.
Schleifen
Die zweite wichtige Kategorie von Konstrukten, die Sie zur Programmierung benötigen, sind die Schleifen. Darunter versteht man Codeblöcke, die in Abhängigkeit von einer Bedingung mehrfach abgearbeitet werden. In C gibt es dazu zum einen die for-Anweisung, zum anderen die while- sowie die do-while-Schleife.
for-Schleife
Wenn man im Vorhinein weiß, wie viele Male die Schleife abzuarbeiten ist, dann nutzt man meist die for-Anweisung. Sie hat die in Listing 3 dargestellte allgemeine Form:

Die Anweisung besteht aus drei Teilen: dem Schlüsselwort for, dem in Klammern stehenden Schleifenkopf, der die Ausführung der Schleife steuert, und dem in geschweiften Klammern befindlichen Schleifenkörper.
Der Schleifenkopf seinerseits besteht aus drei durch Semikola getrennten Teilen. Der erste Teil anweisung1 wird vor Beginn der Schleife einmalig ausgeführt. Hier wird gern eine Laufvariable initialisiert, die die Anzahl bereits absolvierter Iterationen enthält. Der zweite Teil <ausdruck> enthält die Schleifenbedingung. Ist diese erfüllt (logisch wahr), dann wird der gesamte Schleifenkörper (<anweisungen>) einmal ausgeführt. Danach wird einmalig der dritte Teil des Schleifenkopfes (anweisung2) ausgeführt. Nun wird erneut die Schleifenbedingung geprüft, bei Erfüllung der Körper ein weiteres Mal ausgeführt, und danach ist wiederum anweisung2 an der Reihe. Dies geschieht so lange, bis die Schleifenbedingung in <ausdruck> logisch falsch ergibt. Ist das der Fall, dann wird nach der schließenden geschweiften Klammer fortgesetzt.
Listing 3.7 zeigt ein einfaches Beispiel. Der Code ermittelt die Summe aller Zahlen von 1 bis zum Wert, der in der Variablen limit steht.

Listing 3.7: Ein einfaches Beispiel zur for-Schleife
Die Schleifenvariable c wird eingangs mit dem Wert 1 initialisiert und nimmt nacheinander alle Werte von 2 bis einschließlich 100 (der Wert von limit) an und wird bei jeder Iteration auf die (bisherige) Summe (Variable sum) aufaddiert. Nach Beendigung der Schleife wird der Wert von sum ausgegeben.
Die for-Schleife wird im Allgemeinen eingesetzt, wenn man im Vorhinein weiß, wie viele Iterationen (Schleifendurchläufe) absolviert werden müssen.
Das Programm ist natürlich sehr ineffizient, denn wie Sie sicherlich wissen, kann man die Summe der natürlichen Zahlen von 1 bis zu einem beliebigen 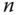 mittels
mittels 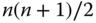 ermitteln. Carl Friedrich Gauß, von einem Lehrer mit der Summierung einer großen Menge natürlicher Zahlen zwecks Überbrückung der Arbeitszeit der »normalen« Kinder beauftragt, erkannte diese Gesetzmäßigkeit im Alter von neun Jahren. Anstelle der
ermitteln. Carl Friedrich Gauß, von einem Lehrer mit der Summierung einer großen Menge natürlicher Zahlen zwecks Überbrückung der Arbeitszeit der »normalen« Kinder beauftragt, erkannte diese Gesetzmäßigkeit im Alter von neun Jahren. Anstelle der for-Schleife würde man also besser programmieren:
printf("Summe: %u\n", limit*(limit+1)/2;)
while- und do-while-Schleifen
Noch einfacher ist die while-Schleife zu verwenden. Sie hat die in Listing 3 abgebildete allgemeine Struktur.

Zu Beginn der Abarbeitung wird <ausdruck> ermittelt. Ergibt dieser logisch wahr, dann wird der Schleifenkörper (<anweisungen>) einmal ausgeführt. Danach erfolgt eine weitere Auswertung von <ausdruck>, der bei wahrem Ergebnis die nächste Schleifeniteration folgt. Ergibt <ausdruck> hingegen falsch (genauer gesagt den Wert 0), dann wird die Abarbeitung nach der schließenden Klammer fortgesetzt. Um die Schleife zu beenden, muss also im Schleifenkörper Bezug auf <ausdruck> genommen werden, damit dieser den Wert »falsch« ergibt.
Das Beispiel aus dem vorangegangenen Abschnitt kann man mittels while also wie in Listing 3.8 dargestellt realisieren.

Listing 3.8: Beispiel zur while-Schleife
Wenn Sie for mit while vergleichen, dann stellen Sie fest dass das Management der Laufvariable c bei der for-Schleife sauber vom Schleifenkörper getrennt ist, während es bei while vor (zur Initialisierung in Zeile 3) und in die Schleife (zur Aktualisierung; Zeile 6) wandert. Gerade die explizit notwendige Initialisierung wird bei while gern vergessen.
Streng genommen sind Schleifen zur Programmierung nicht notwendig. Sie können auch durch die Alternative und die sogenannte goto-Anweisung implementiert werden. Letztere springt im Programmfluss zu einer definierten Stelle, einem sogenannten Label.
Die Schleife zur Summierung der Zahlen von 1 bis 100 kann in C damit auch folgendermaßen formuliert werden.

Das Label loop befindet sich in Zeile 4. Solange die if-Bedingung in Zeile 7 wahr ist, wird immer wieder zu loop zurückgesprungen.
Die Nutzung von goto ist allerdings schwer verpönt, da sie in der Regel zu sehr unübersichtlichem und schwer verständlichem Programmcode (sogenanntem »Spaghetticode«) führt, was Sie im Codebeispiel recht gut erkennen können. In heute mehr oder minder ungebräuchlichen Programmiersprachen wie BASIC spielte das goto-Statement eine wichtige Rolle.
Die durch den Compiler erzeugte und auf der CPU abgearbeitete Maschinensprache benutzt diese Form von Sprüngen, da auf der Maschinenebene häufig keine strukturierten Schleifenkonstrukte existieren.
Manchmal ist es nötig, zuerst eine Iteration des Schleifenkörpers auszuführen und danach die Fortsetzungsbedingung zu prüfen. Dazu gibt es in C die do-while-Schleife mit der folgenden allgemeinen Form:

Es wird zunächst einmal <anweisungen> ausgeführt und danach der <ausdruck> berechnet. Ergibt dieser logisch wahr, dann wird die nächste Iteration des Schleifenkörpers (einmal <anweisungen>) ausgeführt und danach erneut <ausdruck> geprüft. Dies geschieht so lange, bis <ausdruck> logisch falsch ergibt. In diesem Falle wird die Ausführung nach der Schleife fortgesetzt.
Diese Schleifenform wird verhältnismäßig selten genutzt; und sie ist auch nicht zwingend notwendig. Können Sie den Beispielcode zur Summierung mit Hilfe der do-while-Schleife implementieren?
Modifikation des Schleifenverhaltens mittels break und continue
Zwei Schlüsselworte sind im Zusammenhang mit Schleifen sehr nützlich. Zum einen ist es manchmal erforderlich, mitten im Schleifenkörper sofort die gesamte Schleife zu verlassen und die Ausführung nach der Schleife fortzusetzen. Dies geschieht mit der Anweisung break. Meist wird es mit einer zusätzlichen Abbruchbedingung genutzt. Listing 3.9 zeigt ein einfaches Beispiel.

Listing 3.9: Vorzeitiges Verlassen einer Schleife mittels break
Mit Hilfe der Schleife soll der Nutzer zehn natürliche Zahlen eingeben, deren Summe ermittelt und nach der Schleife ausgegeben wird. Nach jeder Eingabe wird in Zeile 10 getestet, ob auch wirklich eine natürliche Zahl (der Wert muss 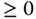 sein) eingegeben wurde. Ist dies nicht der Fall, dann erfolgt eine Meldung, und die Schleife wird vorzeitig mittels
sein) eingegeben wurde. Ist dies nicht der Fall, dann erfolgt eine Meldung, und die Schleife wird vorzeitig mittels break verlassen. Im »regulären« Fall wird die eingegebene Zahl auf die bisherige Summe aufaddiert, und es wird zur nächsten Schleifeniteration übergegangen.
Die Anweisung continue innerhalb des Schleifenkörpers bewirkt, dass sofort zur nächsten Schleifeniteration übergegangen wird, es wird also unmittelbar an den Anfang der Schleife gesprungen. Auch dazu ist ein illustrierendes Beispiel nützlich. Stellen Sie sich vor, sie haben ein Feld von 100 Integerzahlen int a[100], das entsprechende ganzzahlige Werte enthält. Nun sollen die Werte aller Elemente um zehn erhöht werden, die nicht null sind. Das könnten Sie folgendermaßen lösen:

Die beiden Anweisungen break und continue sind nicht unbedingt notwendig, beispielsweise könnten Sie das continue im letzten Beispiel mit Hilfe einer else-Klausel im if eliminieren. Gerade break ist aber äußerst nützlich und wird daher entsprechend häufig eingesetzt.
Komplexeres Beispiel
Nun sollten Sie das bislang gelernte in einem etwas komplexeren Beispiel vertiefen. Werfen Sie dazu bitte einen Blick auf Listing 3.10.

Listing 3.10: Ein etwas komplexeres Beispiel (collatz.c)
Die ersten beiden Zeilen enthalten jeweils eine #include-Präprozessoranweisung. Da im Code Bibliotheksfunktionen genutzt werden, müssen diese zuvor dem Compiler bekannt gemacht werden, was durch #include der entsprechenden sogenannten Headerdateien geschieht. Die I/O-Funktionen printf() und scanf() befinden sich in der Datei stdio.h, und die Funktion exit() wird in stdlib.h definiert. Letztere dient dazu, das Programm mit einem sogenannten Rückgabewert ordnungsgemäß abzuschließen, wie dies in Zeile 20 geschieht.
Der Nutzer soll also offenbar eine (positive, weil vorzeichenlose) Zahl eingeben. Nun wird in Zeile 11 eine while-Schleife betreten, die so lange ausgeführt wird, bis der Wert von n 1 beträgt. Es ist somit keine gute Idee, initial den Wert 1 einzugeben, denn dann ist der Spaß bereits vorbei. Die Anweisung in Zeile 12 kennen Sie ebenfalls: Es wird ermittelt, ob n gerade ist. Ist dies der Fall, dann wird n durch 2 dividiert (halbiert). Ist n hingegen ungerade, dann erhält n den Wert 3n+1. Der neu ermittelte Wert von n wird auf der Konsole ausgegeben, und eine neue Schleifeniteration beginnt.
Warum endet die Schleife ausgerechnet beim Wert 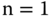 ? Dazu lassen wir die Schleife einfach einmal weiterlaufen: 1 ist ungerade, also erhält
? Dazu lassen wir die Schleife einfach einmal weiterlaufen: 1 ist ungerade, also erhält n im nächsten Durchgang den Wert 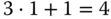 . Das ist wiederum gerade, also folgt darauf der Wert
. Das ist wiederum gerade, also folgt darauf der Wert 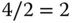 . Auch 2 ist gerade, also wird noch einmal dividiert, und wir stehen wieder beim Wert 1. Das Ganze bildet den Zyklus
. Auch 2 ist gerade, also wird noch einmal dividiert, und wir stehen wieder beim Wert 1. Das Ganze bildet den Zyklus 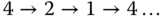 .
.
Wozu ist das Programm nun eigentlich gut? Es gestattet Ihnen, für verschiedene Startwerte auszuprobieren, wohin die eben beschriebene Iterationsvorschrift führt. Die sogenannte Collatz-Vermutung besagt, dass die Iteration völlig unabhängig vom Startwert letztendlich immer zum Wert 1 führt. Sie ist nach dem Mathematiker Lothar Collatz benannt, der sie im Jahre 1937 formulierte. Falls Ihnen ein Beweis dieser Vermutung gelingt, sollten Sie die Lektüre dieses Buches unterbrechen und ihn publizieren, immerhin ist ein nicht unerhebliches Preisgeld von 120 Millionen Yen ausgelobt. Es handelt sich um ein bislang ungelöstes Problem der Zahlentheorie.
Funktionen
Eingangs des Kapitels haben Sie bereits gelernt, dass C-Programme aus Funktionen bestehen. Die Aufgabe, die das Programm lösen soll, lässt sich normalerweise in Teilaufgaben zergliedern, und häufig ist es sinnvoll, diese Teilaufgaben durch Funktionen zu bearbeiten. Oft müssen auch bestimmte Dinge im Programm mehrfach erledigt werden, eine Berechnung beispielsweise, die mit unterschiedlichen Eingangswerten vorgenommen wird. Auch in diesem Falle bietet es sich an, diese Berechnung in eine Funktion auszulagern. Das Abbilden von Teilaufgaben auf Funktionen ist gar nicht so einfach; man lernt es am besten durch Üben!
Funktionen kapseln Codeblöcke, übernehmen Parameter und liefern ein Ergebnis, den Funktionswert, zurück. Im Codeblock einer Funktion können wiederum Funktionen gerufen werden. Es ist sogar möglich, dass eine Funktion sich direkt oder indirekt selbst aufruft, man spricht in diesem Fall von Rekursion.
Funktionsdefinition
Funktionen müssen definiert werden, idealerweise vor ihrer Benutzung. Eine Definition hat die folgende abstrakte Form:

Funktionen sollten, ganz genauso wie mathematische Funktionen, ein Resultat zurückliefern. Dieses Resultat muss einen wohldefinierten Typ besitzen, der als Erstes im Funktionskopf angegeben wird. Als Resultattyp sind alle arithmetischen Typen, Strukturen, unions sowie Zeiger (dazu kommen wir im nächsten Abschnitt) erlaubt. Falls die Funktion ausnahmsweise kein Resultat liefert, weil sie vielleicht nur etwas auf den Bildschirm druckt, dann steht an dieser Stelle das Schlüsselwort void.
Durch Leerzeichen getrennt folgt nun der Name der Funktion, der den Regeln zur Konstruktion von Bezeichnern unterliegt (nur Buchstaben, Zahlen und der Unterstrich sind als Zeichen erlaubt). Sie sollten sich von Anfang an angewöhnen, deskriptive Funktionsnamen zu vergeben, damit man bereits aus dem Namen der Funktion schlussfolgern kann, was diese tut. Die Liste formaler Parameter behandeln wir ein bisschen später.
Im Funktionskörper, der durch geschweifte Klammern eingeschlossen ist, definieren Sie zunächst lokale Variablen. Diese sind nur in der Funktion sichtbar und existieren auch nur so lange, wie das Programm in der Funktion arbeitet. Beim Verlassen der Funktion werden alle lokalen Variablen zerstört.
Apropos: Wie verlässt man denn überhaupt eine Funktion? Das geschieht mit dem Schlüsselwort return. Ihm muss ein Ausdruck folgen, der vom <Resultattyp> ist. Eine Ausnahme bildet der Resultattyp void: Hier wird die Funktion entweder mit return (ohne folgendes Resultat) oder beim Erreichen der schließenden geschweiften Klammer verlassen. Mehrere return-Anweisungen, die natürlich an verschiedenen Stellen der Funktion stehen sollen, sind zulässig.
Damit ist geklärt, wie man aus einer Funktion herauskommt. Wie kommt man aber hinein? Dazu ist der Funktionsaufruf gedacht. Dies geschieht durch den Namen der Funktion und die Liste aktueller Parameter in Klammern. Wenn die Funktion ein Resultat zurückliefert, so wird dieses häufig einer Variablen zugewiesen oder als Teil eines Ausdrucks verwendet. Der Resultatwert kann auch ignoriert werden. Einige Beispiele für syntaktisch korrekte Funktionsaufrufe sind:

Das printf() in der dritten Zeile kennen Sie schon. Das Beispiel demonstriert, dass überall dort, wo ein Ausdruck stehen darf, ein Funktionsaufruf stehen kann. Innerhalb der Parameterliste von printf() ist es der Aufruf der Funktion ggT(), die ihrerseits zwei Parameter übernimmt.
Zu jeder Definition einer Funktion außer () gehört ein sogenannter Funktionsprototyp oder kurz Prototyp. Darunter versteht man den Funktionskopf der Funktion mit einem angehängten Semikolon, also formal:

Die Namen der Parameter können dabei weggelassen werden. Die Prototypen aller definierten Funktionen werden normalerweise nach den Präprozessoranweisungen weit vorn im Quelltext platziert. Wenn ein Prototyp existiert, dann ist es egal, ob Sie die Funktion vor oder nach ihrer Benutzung im Quelltext definieren. Rufen Sie die Funktion vor ihrer Definition auf, dann ist ein Prototyp notwendig.
Parameterübergabe an Funktionen
Nun muss noch genauer erläutert werden, wie Parameter in die Funktion hineinkommen. Die Liste formaler Parameter aus der Funktionsdefinition des vorangegangenen Abschnittes muss dazu noch präzisiert werden. Sie hat folgende abstrakte Form:

Die Parameterliste enthält Paare von Typen und Namen der formalen Parameter, die durch Kommas voneinander getrennt sind. Ihre Anzahl ist prinzipiell beliebig, jedoch bevorzugt man aus Gründen der Übersichtlichkeit meist wenige Parameter. Als Parameter sind in C die gleichen Typen zulässig wie für das Funktionsergebnis.
Die eigentliche Übergabe der Parameter an die Funktion erfolgt in C mittels des Prinzips »Call-by-Value«. Das bedeutet, dass die Werte der aktuellen Parameter beim Aufruf der Funktion berechnet und an die formalen Parameter der Funktion gebunden werden. Die formalen Parameter können innerhalb der Funktion wie lokale Variablen genutzt werden. Änderungen ihrer Werte wirken sich nicht auf den rufenden Block aus.
Eine alternative Form der Parameterübergabe ist »Call-by-Reference«. Hier wird der gerufenen Funktion eine sogenannte Referenz auf eine Variable des rufenden Blockes übergeben. Wertemodifikationen in der Funktion wirken sich hier auf den rufenden Block aus. C bietet diesen Mechanismus nicht an.
Das Schlüsselwort void zeigt an, dass keine Parameter übernommen werden. Es sind sogar Funktionen mit einer variablen Anzahl an Parametern möglich (die sogenannte »Ellipse«), die printf()-Funktion ist ein Beispiel.
Ein vollständiges Beispiel
Listing 3.11 zeigt ein komplettes Beispiel eines Programms, das zwei Funktionen definiert, das stets erforderliche main() und die Funktion factorial(), was auf Deutsch »Fakultät« bedeutet.

Listing 3.11: Ein Programm zur Berechnung der Fakultät (factorial.c)
Der (einzige) Parameter x ist vom Typ unsigned int, genauso wie das Resultat. Die Fakultät einer positiven Zahl 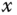 ist das Produkt dieser Zahl mit allen positiven Zahlen kleiner
ist das Produkt dieser Zahl mit allen positiven Zahlen kleiner 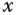 und wird als »
und wird als »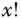 « notiert. Es gilt also:
« notiert. Es gilt also:
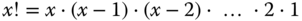
Genau diesen Ausdruck berechnet die Funktion in einer Schleife. Die Variable a nimmt nacheinander die einzelnen Faktoren auf, und in der Variablen fak erscheint nach und nach das Produkt. Sobald a den Wert 1 erreicht hat, endet die Schleife, und der in fak gespeicherte Wert bildet das Resultat. Beachten Sie, dass auf die letzte Multiplikation mit dem Wert 1 verzichtet wird, weil sich ohnehin am Ergebnis nichts ändert.
Die Zahl, deren Fakultät durch das Programm ermittelt werden soll, wird als Argument auf der Kommandozeile übergeben. Ein Aufruf sieht beispielsweise so aus:

Nachgerechnet »per Hand« ergibt sich: 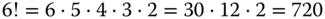 . Es handelt sich zwar um keinen Korrektheitsbeweis, ist aber zumindest ein Indikator, dass das Programm richtig arbeitet.
. Es handelt sich zwar um keinen Korrektheitsbeweis, ist aber zumindest ein Indikator, dass das Programm richtig arbeitet.
Analysieren wir auch noch das Hauptprogramm. Es überprüft zunächst, ob ein Parameter übergeben wurde. Dies geschieht mittels der vordefinierten Variable argc, die stets der erste Parameter von main() ist. Sie enthält die Anzahl übergebener Kommandozeilenparameter + 1. Hat sie also einen Wert von 1, dann wurde kein Parameter übergeben. Dies wird in den Zeilen 20–23 überprüft, und gegebenenfalls wird das Programm mit einem kurzen Hinweis auf den Fehler beendet.
Sie fragen sich vielleicht, wieso argc nicht einfach die Anzahl der Parameter enthält, sondern genau einen mehr. Das ist ein bisschen kompliziert. Der zweite Parameter von main(), argv[], ist ein Feld von Zeigern auf Zeichenketten. Das allererste Element argv[0] zeigt dabei auf den Namen des Programms, unter dem es aufgerufen wurde. Die folgenden Elemente argv[1], argv[2] … enthalten Zeiger auf Zeichenketten, die die einzelnen Parameter des Programms enthalten. Das Feld argv enthält also die gesamte Kommandozeile hübsch in ihre Bestandteile zerlegt, und argc gibt die Elementanzahl von argv[] an.
Da Kommandozeilenparameter stets als Zeichenketten abgelegt sind (deren Anfangsadressen im Feld argv[] abgelegt sind), muss das übergebene Argument in einen Festkommatyp (hier: unsigned int) gewandelt werden. Dies übernimmt die Bibliotheksfunktion atoi() in Zeile 24. Eigentlich müsste an dieser Stelle eine ziemlich komplexe Fehlerbehandlung erfolgen, denn die Umwandlung einer Zeichenkette in eine Zahl kann erstaunlich viele Probleme verursachen. (Versuchen Sie doch spaßeshalber, die Argumente »Hallo« oder »23hebauf« zu übergeben.) Aus Gründen der Übersichtlichkeit soll jedoch ausnahmsweise darauf verzichtet werden.
Der Aufruf der Funktion factorial() erfolgt erst kurz vor Ende des Programms in Zeile 25. Das Argument wird zu Kontrollzwecken auch mit ausgegeben.
Das Beispiel soll jedoch noch etwas anderes illustrieren. Durch die fortgesetzte Multiplikation entstehen schnell sehr große Ergebnisse. Wie groß können diese denn werden? Dazu rufen wir die Funktion mit allen Argumenten von 1 bis 25 in einem kleinen Shellskript auf:

Während 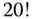 wahrscheinlich korrekt ist, erscheint der Wert für
wahrscheinlich korrekt ist, erscheint der Wert für 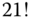 verdächtig. Wo sind die Nullen an den niederwertigsten Dezimalstellen hin? Wir haben es mit einem klassischen Überlauf oder Overflow zu tun. Dieser erfolgt, wenn das Operationsergebnis nicht in das Register oder den Speicherbereich der Variable »hineinpasst«.
verdächtig. Wo sind die Nullen an den niederwertigsten Dezimalstellen hin? Wir haben es mit einem klassischen Überlauf oder Overflow zu tun. Dieser erfolgt, wenn das Operationsergebnis nicht in das Register oder den Speicherbereich der Variable »hineinpasst«.
Im konkreten Beispiel hat die Variable 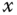 (vom Typ
(vom Typ unsigned int) eine Größe von 8 Byte, also 64 Bit. Damit kann sie Werte aufnehmen, die der folgenden Ungleichung genügen:
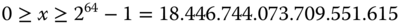
Dieser Wertebereich wird bei Multiplikation von 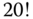 mit 21 offenbar überschritten. Alle Folgewerte sind natürlich ebenso unsinnig. Weil C eine so effiziente Programmiersprache ist, sind gegen diese Fehlerbedingung keine Tests eingebaut. Der Programmierer ist schlicht dafür zuständig, dass die Operanden und Resultate niemals den definierten Wertebereich verlassen.
mit 21 offenbar überschritten. Alle Folgewerte sind natürlich ebenso unsinnig. Weil C eine so effiziente Programmiersprache ist, sind gegen diese Fehlerbedingung keine Tests eingebaut. Der Programmierer ist schlicht dafür zuständig, dass die Operanden und Resultate niemals den definierten Wertebereich verlassen.
 Der Wertebereich der integralen Datentypen von C ist eine vertrackte Angelegenheit. Er hängt nämlich von der Verarbeitungsbreite der CPU-Register und allgemein von der Maschinenarchitektur des Systems ab. Der C-Standard fordert für
Der Wertebereich der integralen Datentypen von C ist eine vertrackte Angelegenheit. Er hängt nämlich von der Verarbeitungsbreite der CPU-Register und allgemein von der Maschinenarchitektur des Systems ab. Der C-Standard fordert für unsigned int nur eine minimale Größe von 16 Bit. Damit Sie als Programmierer nicht erst mühselig die Größe der Datentypen herausfinden müssen, sind in der Headerdatei limits.h symbolische Konstanten definiert, die Auskunft über den kleinst- und den größtmöglichen Wert jedes Integer-Typs für das System geben. Für das gerade betrachtete Beispiel würde UINT_MAX den maximalen Wert angeben, den ein Datum vom Typ unsigned int annehmen kann. (Eine Konstante, die den kleinstmöglichen Wert enthält, gibt es hingegen nicht. Wissen Sie, warum?)
Im normalen Leben ist der Wertebereich der Basisdatentypen von C vollkommen ausreichend. Wer benötigt schon Zahlen, die größer als 18 Trillionen sind?
Wenn – wie im vorliegenden Beispiel – eine höhere Stellenanzahl erforderlich ist, muss man entweder eine Langzahlarithmetik, wie sie beispielsweise die libgmp-Bibliothek mitbringt, einsetzen, oder gleich auf eine Programmiersprache umsteigen, die Datentypen beliebiger Größe unterstützt, beispielsweise Python:

Das sieht eher nach dem korrekten Ergebnis aus. Langzahlarithmetik ist aber mit erheblichen Geschwindigkeitseinbußen verbunden, und deshalb ist sie in C nicht von Haus aus unterstützt.
Zeiger
Bislang haben wir nur Elementardatentypen an Funktionen übermittelt und als Resultat zurückerhalten. Wie verhält es sich aber mit zusammengesetzten Typen? Dazu müssen Sie sich in diesem Abschnitt zunächst durch das Konzept von Zeigern und Referenzen kämpfen.
Konzept
Nun werden Sie noch einen etwas komplexeren Aspekt der Programmiersprache C kennenlernen, das sogenannte Zeigerkonzept.
Ein Zeiger (auch: Pointer) ist eine Variable, die eine Adresse einer anderen Variablen erhält. Ein Zeiger wird formal so definiert:

Die Variable name wird zu einem Zeiger, der auf eine Variable vom Typ typ zeigt. Beispielsweise definiert int *pt; die Zeigervariable pt, die die Adresse einer Integer-Variable enthält.
Um einer Zeigervariable Werte zuzuweisen, wird der unäre Adressoperator & benötigt. Er bedeutet »Adresse von« und wird folgendermaßen verwendet:

Die Variable pt erhält die Adresse der Integervariable a zugewiesen. Bitte verwechseln Sie nicht den Adressoperator & mit dem Operator für das bitweise UND &. Es ist ungünstig, dass die Autoren von C für beide das gleiche Symbol festlegten, normalerweise macht aber der Kontext klar, welche Semantik gemeint ist.
Man kann Zeigervariablen wiederum nutzen, um auf die Werte der Variablen zuzugreifen, auf die die Zeiger verweisen. Dazu wird der unäre Dereferenz-Operator eingesetzt, für den unglücklicherweise das Zeichen * genutzt wird; es steht jedoch an anderer Stelle, nämlich vor der betreffenden Zeigervariable. Die Anweisung *pt=23; bewirkt, dass die Speicherstelle, auf die pt verweist, den Wert 23 zugewiesen erhält. Dieser Vorgang wird Dereferenzierung genannt. Falls wie in oben stehendem Beispiel pt auf die Variable a verweist, ist *pt=23; völlig äquivalent zu a=23;.
Vergisst man den Dereferenzoperator und schreibt pt=23, dann erhält der Zeiger pt den Wert 23 zugewiesen. Das bedeutet, dass er ab sofort auf die Speicherstelle mit der Adresse 23 verweist, bei der man aber im Normalfall gar nicht weiß, welche Variable sich dahinter verbirgt, geschweige denn, ob man auf diese Adresse überhaupt zugreifen darf.
Ein dereferenzierter Zeiger darf überall dort stehen, wo eine Variable des Typs, auf den gezeigt wird, stehen darf. In Fortsetzung des Beispiels ist also Folgendes erlaubt:
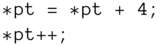
Zeigervariablen gleichen Typs dürfen direkt einander zugewiesen werden, während für Zeigervariablen unterschiedlichen Typs eine explizite Typumwandlung erforderlich ist. Der Typ void* steht für einen Zeiger beliebigen Typs, er muss jedoch vor Benutzung in einen konkreten Typ umgewandelt werden.
Eine spezielle symbolische Konstante ist der sogenannte Nullzeiger NULL (die Zeigervariable enthält die Adresse 0). Er zeigt eine allgemeine Ungültigkeit des betreffenden Zeigers an und darf keinesfalls dereferenziert werden.
Zeiger als Funktionsparameter
Zeiger können genauso wie arithmetische Grunddatentypen an Funktionen übergeben werden. Dies ist notwendig, wenn eine Funktion Werte oder Variablen der rufenden Instanz ändern möchte. Da es in C unmöglich ist, Variablen direkt der rufenden Instanz zwecks Modifikation in der Funktion zu übergeben, übergibt man stattdessen Referenzen, also Adressen, an die Funktion. Innerhalb der Funktion greift man mittels dieser Adressen auf die zu manipulierenden Variablen zu.
Zur Illustration soll die folgende Funktion dienen, die die Werte zweier Integer-Variablen miteinander vertauschen soll.
Naiv würde man wie in Listing 3.12 dargestellt vorgehen:

Listing 3.12: Eine Funktion, die ihre Argumente nicht vertauscht
Beim Aufruf von swap() erhalten die Parameter x und y jedoch nur Wertekopien! Diese Kopien werden innerhalb der Funktion mit der Hilfsvariable tmp vertauscht und gehen nach dem Verlassen der Funktion verloren, da sowohl die Parameterkopien als auch die lokale Variable auf dem Stack angelegt werden. Eine korrekte Implementierung der Vertauschung muss sich der Adressen der zu tauschenden Variablen, also Referenzen, bedienen (Listing 3.13).

Listing 3.13: Eine Funktion, die ihre Argumente per Referenz auf diese vertauscht
Hier werden an swap() nicht mehr die Werte, sondern die Adressen der beiden zu vertauschenden Variablen übermittelt. Der Aufruf der Funktion erfolgt nun nicht mehr mit den Variablennamen, sondern mit deren Referenzen mittels des Adressoperators:
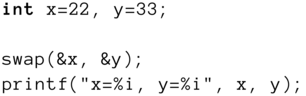
Probieren Sie es am besten selbst aus!
Felder und andere komplexe Datentypen werden stets als Referenz an Funktionen übergeben. Funktionen, die mit Zeichenketten arbeiten, sind also für die Arbeit mit Zeigern prädestiniert.
Schauen Sie sich dazu einmal den Prototypen der Funktion strcpy() an:

Sie dient dazu, eine Zeichenkette src in die Zeichenkette dest zu kopieren. Beide Parameter werden als Zeiger übergeben. Das Resultat von strcpy() ist ein Zeiger auf die kopierte Zeichenkette, er ist also identisch mit dest.
Dynamische Speicherverwaltung
Bislang sind wir stets davon ausgegangen, dass die Anzahl, der Typ und die Größe aller Variablen und Datenstrukturen eines Programms feststehen. Man spricht davon, dass sie zur Übersetzungszeit bekannt sind.
Was geschieht aber, wenn dies nicht der Fall ist und Anzahl und Größe von Datenstrukturen zur Laufzeit geändert werden müssen? Dafür benötigt das Programm einen Mechanismus, um während seiner Abarbeitung Variablen anzulegen und wieder zu zerstören. Genau dies leisten die Funktionen zur sogenannten dynamischen Speicherverwaltung.
Im Speicherabbild jedes Prozesses ist dafür ein extra Speicherbereich reserviert, der sogenannte Heap. »Heap« bedeutet »Haufen« oder »Halde«. Dies deutet an, dass es sich dabei um einen unstrukturierten Speicherbereich handelt, der bei Bedarf auch vergrößert werden kann – eben ein »Haufen« Bytes.
Die grundlegende API besteht aus den Funktionen malloc() und free(), die beide in der Headerdatei stdlib.h definiert sind und im Folgenden kurz erläutert werden.
Allokation und Rückgabe von Blöcken
Mittels malloc() kann der Nutzer sich einen Block beliebiger Größe vom Heap holen. Dieser Vorgang wird Allokation genannt.

Die Größe (in Bytes) wird im Parameter size angegeben, und die Funktion liefert entweder einen Zeiger auf den von der Laufzeitumgebung zurückgelieferten Speicherblock oder den Wert NULL, wenn der Heap erschöpft ist. Eine Prüfung des Resultats ist daher stets als erste Aktion nach dem malloc()-Aufruf zwingend erforderlich. Der Resultatwert ist ein void-Zeiger; dieser muss somit vor Verwendung in einen getypten Zeiger umgewandelt werden.
Der Inhalt des Speicherblockes ist nicht initialisiert; er kann also beliebige Werte enthalten. Der Zugriff auf den Speicherblock und auch dessen Rückgabe erfolgen stets über den zurückgelieferten Zeiger. Dieser darf also nicht überschrieben werden.
Sobald der Speicherblock durch den Prozess nicht mehr benötigt wird, sollte er wieder freigegeben werden, denn die Größe des Heaps ist nicht unerschöpflich. Dies erfolgt mittels free():

Der Parameter ist der bei malloc() gelieferte Zeiger. Diese Funktion hat keinen Resultatwert. Nach Aufruf von free() darf der betreffende Speicherblock nicht mehr referenziert werden, weil das Betriebssystem ihn unter Umständen bereits an einen anderen Prozess ausgereicht hat.
Um die Speichergröße eines komplexeren Datums (die Größe der Elementardatentypen ist standardisiert) zu bestimmen, nutzt man gern den sizeof-Operator. Sein Einsatz wird im folgenden Beispiel deutlich.
Beispielprogramm
Bitte sehen Sie sich nun Listing 3.14 an. (Oder besser: Tippen Sie es mit dem Editor ein, und übersetzen Sie es.)
In den Zeilen 5–9 wird ein struct definiert, das offensichtlich eine Datumsangabe aufnehmen soll. Der Monat soll dabei als dreibuchstabige Zeichenkette (»Jan«, »Feb«, …»Dec«) abgelegt werden, während Tag und Jahr durch normale Ganzzahlen repräsentiert werden.

Listing 3.14: Verwendung von Funktionen der dynamischen Speicherverwaltung
Innerhalb von main() wird zunächst in Zeile 13 eine Zeigervariable p1 definiert, die auf eine dynamische Instanz des gerade definierten structs verweisen soll. Danach fasst das Programm in Zeile 15 einen Speicherblock für eine Instanz von struct date mittels malloc() aus, wobei die exakte Größe mit sizeof() bestimmt wird. Unmittelbar anschließend (Zeilen 16–19) erfolgt der Test, ob die Allokation erfolgreich war.
Die einzelnen Felder des structs werden in den Zeilen 21–23 mit Werten belegt. Dabei kommt der bislang noch nicht behandelte Operator -> zum Einsatz. Der vor dem Operator stehende Zeiger wird dereferenziert, und das nach dem Operator stehende Feld des structs wird selektiert – hier jeweils für eine Wertzuweisung. Der Operator -> ähnelt in gewisser Weise dem .-Operator, nur dass Ersterer mittels eines Zeigers auf ein struct arbeitet, während letzterer den Namen einer struct-Variable erfordert. Da es keine Zuweisung für Zeichenketten gibt, muss in Zeile 22 stattdessen “Sep” per Bibliotheksfunktion strcpy() in das entsprechende Feld kopiert werden.
In Zeile 25 werden die einzelnen Bestandteile des structs mittels printf() auf der Konsole ausgegeben, wobei wiederum der ->-Operator zum Einsatz kommt. Das Programm endet mit der Freigabe des zuvor allozierten Speichers (Zeile 27).
Häufige Programmierfehler
Die Funktionen zur dynamischen Speicherverwaltung sind eine der »beliebtesten« Fehlerquellen in C-Programmen. Insbesondere, wenn man komplexe Datenstrukturen wie Bäume oder mehrfach verkettete Listen mit vielen Elementen erzeugt, kann es sehr schnell zu den folgenden Fehlern kommen:
- Die Anzahl der Allokationen stimmt nicht mit denen der Rückgaben überein (»memory leak«).
- Die Blöcke werden uninitialisiert benutzt.
- Blöcke werden nach Rückgabe noch verwendet (»use-after-free«).
- Blöcke werden mehrfach zurückgegeben (»double free«).
- Vergessene Prüfung des Zeigers auf
NULL.
In den meisten Fällen resultiert eine nicht korrigierbare Korruption des Heaps, und der Prozess wird abgebrochen.
Was fehlt jetzt noch zum C-Profi?
Damit sind die für das Verständnis des restlichen Buches notwendigen Grundlagen der Programmiersprache C abgehandelt. Trotz des verhältnismäßig kleinen Sprachumfangs fehlen noch einige Aspekte, die aber im Interesse einer kompakten Darstellung weggelassen werden, schließlich lesen Sie nicht »C für Dummies«. Trotzdem ist es günstig zu wissen, was noch fehlt. Dazu zählen insbesondere
- Funktionen mit variabler Parameterliste (Ellipse)
- Speicherklassen von Variablen:
auto,extern,static - Das Definieren eigener Datentypen mittels
typedef - Der Aufzählungstyp
enumund die Vereinigung (union) - Das komplexe
switch-case-Statement, das man aber durch eine Folge vonif-Klauseln ersetzen kann - Der Entscheidungsoperator (
?:) sowie der Kommaoperator - Ein Überblick über die wichtigsten Funktionen der Standardbibliothek
- Die Strukturierung größerer Projekte in mehrere Quell- und Headerdateien
- Weitere Präprozessoranweisungen, beispielsweise zur bedingten Übersetzung
Lesevorschläge
Zur Programmierung in C gibt es eine Fülle an empfehlenswerter Literatur. Aus dieser seien nur drei kurz erwähnt:
- Brian Kernighan, Dennis Ritchie: Programming in C. Das originale Lehrbuch der Autoren von C ist auch heute noch empfehlenswert, wenn Sie die Sprache von der Pike auf erlernen wollen.
- Samuel Harbison, Guy Steele: C. A Reference Manual. Dieses Buch ist vor allem dann von Interesse, wenn Sie bereits C beherrschen, es aber Unstimmigkeiten bezüglich eines Aspektes gibt. Es stellt den offiziellen Sprachstandard in leicht fasslicher Form dar.
- Peter van der Linden: Expert C Programming. Deep C Secrets. Wenn Sie C bereits recht gut beherrschen, aber wirklich jeden Aspekt verstehen wollen, dann kommen Sie um dieses Buch nicht herum.
Übungsaufgaben
- Erweitern Sie
collatz.cderart, dass Sie automatisiert die ersten zehn Millionen Startwerte durchprobieren. Bestimmen Sie auch den Startwert mit der längsten Sequenz sowie deren Länge.