Kapitel 10
Persistenter Speicher
IN DIESEM KAPITEL
- lernen Sie grundlegende Abstraktionen und Begriffe im Zusammenhang mit dem Massenspeicher kennen,
- erhalten Sie eine Einführung in die Systemprogrammierung des persistenten Speichers,
- diskutieren wir einige Implementationsprinzipien für Dateisysteme,
- widmen wir uns der Planung von Massenspeicheraufträgen, dem so genannten I/O-Scheduling.
Eine wichtige Aufgabe von Betriebssystemen besteht in der Verwaltung des sogenannten Massenspeichers. Darunter verstehen wir Geräte, die Daten dauerhaft, also persistent abspeichern können. Davon gibt es mittlerweile eine ganze Menge! Im Wesentlichen kommen drei verschiedene Technologien zum Einsatz:
- magnetische Datenträger: Festplatten, Disketten (Floppy-Disks),
- Medien auf der Basis elektrisch beschreibbaren Speichers (Flash Memory): Solid-State Drives (SSDs), Flashdisks, aber auch die gesamte Vielfalt der Speicherkärtchen für elektronische Geräte, wie SD-Karten oder CompactFlash-Medien,
- optische Datenträger: CDs, DVDs, BluRay-Medien, egal, ob einmal oder mehrfach beschreibbar.
Diese Heterogenität der Medien bildet eine große Herausforderung für die Konstruktion der entsprechenden Betriebssystemfunktionalität. Es gibt aber noch mehr:
Persistenter Speicher bietet potenziell ein riesiges Speichervolumen. Große Festplatten bieten gegenwärtig eine Kapazität von 18 Terabyte. Ausgeschrieben sind das immerhin 18 000 000 000 000 Bytes. Setzt man das Datenaufkommen einer durchschnittlichen Buchseite mit 40 Zeilen á 50 Zeichen an (2000 Byte = 2 kB), kann man auf der 18-TB-Festplatte das Äquivalent von 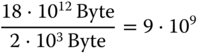 , also neun Milliarden Textseiten ablegen. Der entsprechende Papierstapel ist übrigens 135 Kilometer hoch, wenn man eine Papierdicke von 0.15 mm annimmt.
, also neun Milliarden Textseiten ablegen. Der entsprechende Papierstapel ist übrigens 135 Kilometer hoch, wenn man eine Papierdicke von 0.15 mm annimmt.
 Schummeln Festplattenhersteller?
Schummeln Festplattenhersteller?
Größenangaben von physikalischen Einheiten erfolgen gemäß dem internationalen Einheitensystem mit Hilfe von Zehnerpotenzen. So wird ein Faktor von 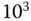 mit dem Präfix Kilo-,
mit dem Präfix Kilo-, 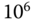 mit Mega- und
mit Mega- und 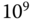 mit Giga- gekennzeichnet. Traditionell verstand man in der Informatik unter der Größe eines Kilobyte jedoch
mit Giga- gekennzeichnet. Traditionell verstand man in der Informatik unter der Größe eines Kilobyte jedoch 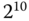 = 1024 Byte (und nicht 1000 Byte), da es in der Informatik allgemein üblich ist, mit Zweierpotenzen zu hantieren und die »Abweichung« zur entsprechenden Zehnerpotenz nur 24 Byte beträgt. Analog umfasste ein Megabyte nicht 1 000 000, sondern
= 1024 Byte (und nicht 1000 Byte), da es in der Informatik allgemein üblich ist, mit Zweierpotenzen zu hantieren und die »Abweichung« zur entsprechenden Zehnerpotenz nur 24 Byte beträgt. Analog umfasste ein Megabyte nicht 1 000 000, sondern 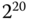 , also genau 1 048 576 Byte. Mit wachsenden Speicherkapazitäten wächst auch die Differenz zwischen der entsprechenden Zehnerpotenz und der gemeinten Zweierpotenz.
, also genau 1 048 576 Byte. Mit wachsenden Speicherkapazitäten wächst auch die Differenz zwischen der entsprechenden Zehnerpotenz und der gemeinten Zweierpotenz.
Massenspeicherhersteller machten sich dieses Begriffswirrwarr sofort zunutze. Erwerben Sie beispielsweise ein Medium, auf dem die Größenangabe »8 TB« prangt, dann erwarten Sie eigentlich eine Kapazität von 8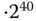 = 8 796 093 022 208 Byte. Tatsächlich nutzen die Hersteller von Festplatten für Kapazitätsangaben stillschweigend den kleineren, auf Zehnerpotenzen beruhenden Wert.Sie erhalten daher leider nur 8
= 8 796 093 022 208 Byte. Tatsächlich nutzen die Hersteller von Festplatten für Kapazitätsangaben stillschweigend den kleineren, auf Zehnerpotenzen beruhenden Wert.Sie erhalten daher leider nur 8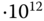 = 8 000 000 000 000 Bytes; das sind fast 10% weniger!
= 8 000 000 000 000 Bytes; das sind fast 10% weniger!
Um diese Mehrdeutigkeit zu bekämpfen, entschloss man sich, ein zweites Präfixsystem basierend auf Zweierpotenzen zu etablieren. Die Tabelle führt die wichtigsten Werte und die zugehörigen Bezeichnungen auf.
Bytes |
exakter Wert |
Bezeichnung |
|---|---|---|
|
1024 |
KibiByte (KiB) |
|
1 048 576 |
MebiByte (MiB) |
|
1 073 741 824 |
GibiByte (GiB) |
|
1 099 511 627 776 |
TebiByte (TiB) |
|
1 125 899 906 842 624 |
PebiByte (PiB) |
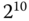
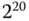
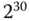
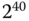
Eine weitere Schwierigkeit bildet die verhältnismäßig geringe Zugriffsgeschwindigkeit bei Massenspeichermedien. Während sich die Kapazität in unvorstellbare Regionen entwickelt hat, bietet die Geschwindigkeit prinzipbedingt weit weniger Evolutionspotenzial. Festplatten wie optische Datenträger rotieren, und es ist aus physikalischen Gründen unmöglich, diese Geschwindigkeit um Zehnerpotenzen zu steigern. Flash-Medien bilden hier eine Ausnahme, doch auch ihre Zugriffsoperationen sind weitaus langsamer als diejenigen des Hauptspeichers.
Die durchschnittliche Latenz (das ist die Zeit zwischen dem Aussenden des entsprechenden Kommandos an und dem Beginn der Datenübertragung durch die Festplatte) wird durch den Hersteller in einem Datenblatt beispielsweise mit vier Millisekunden angegeben (später werden wir lernen, dass diese Angabe unsinnig ist). Ein Prozessor mit einer Taktfrequenz von 3 GHz kann in dieser Zeit mindestens 120 Millionen Instruktionen ausführen. Auch diese Rechnung ist ein wenig fragwürdig, denn ihr liegt die vereinfachende Annahme zugrunde, dass die CPU etwa eine Instruktion pro Taktzyklus ausführt. Zur Illustration der Notwendigkeit, Zugriffe auf die Festplatte so gut wie möglich zu optimieren, taugt die Abschätzung aber allemal.
Grundlegende Abstraktionen
Die grundlegenden Abstraktionen eines Dateisystems (Datei und Verzeichnis, Sie erinnern sich?) haben Sie bereits im zweiten Kapitel kennengelernt. Es gibt jedoch noch einige Dateien betreffende Aspekte, die zunächst vorgestellt werden sollen. Des Weiteren bieten moderne Dateisysteme eine weitere wichtige Abstraktion, die Verknüpfung, die Sie ebenfalls in diesem Abschnitt kennenlernen. Danach widmen wir uns den Möglichkeiten, Beschränkungen des Zugriffs auf Daten in UNIX vorzunehmen, und wir werfen einen kurzen Blick auf die »Innereien« einer Festplatte.
Dateien revisited
Im Folgenden lernen Sie, was man unter Dateiattributen versteht und wie man die unterschiedlichen Inhalte von Dateien verwalten kann.
Dateiattribute
Dateien enthalten jedoch nicht nur die reinen Nutzdaten. Damit der Nutzer die in Dateien abgelegten Daten später wiederfindet, werden in den Dateien zusätzlich sogenannte Metadaten abgelegt, also Daten, die die Nutzdaten näher beschreiben.
Das wichtigste Metadatum stellt der Dateiname dar. Ohne Dateinamen würde es uns kaum gelingen, in einer Sammlung von wenigen Dutzend oder Hunderten Dateien die abgelegten Daten wiederzufinden, insbesondere nach längerer Zeit! Der Name ist ein wichtiges Hilfsmittel zum Strukturieren und somit zum Wiederauffinden der Daten und sollte daher so deskriptiv wie möglich gewählt werden. Dabei muss der Nutzer sich an die Namensregeln des Dateisystems halten.
Im MS-DOS bestand der Name einer Datei aus bis zu acht Zeichen, einem obligatorischen Punkt sowie einer sogenannten Dateinamenserweiterung aus bis zu drei Zeichen, die den Dateityp angab. Erlaubte Zeichen waren Buchstaben, Ziffern sowie einige Sonderzeichen, wobei Groß- und Kleinschreibung nicht unterschieden wurde. Die Erstellung einigermaßen deskriptiver Dateinamen war damit alles andere als einfach. Moderne Dateisysteme wie das Fourth Extended File System (ext4) von Linux bieten eine maximale Länge für den Dateinamen von 255 Zeichen und schränken die Auswahl benutzbarer Zeichen kaum ein. (Hier: Der Name darf kein / und kein Nullbyte enthalten, alles andere ist erlaubt.)
Weitere Metainformationen, die für eine Datei abgelegt werden können, sind:
- Zeitstempel (Zeitpunkt der Erzeugung, des letzten Zugriffs, der letzten Modifikation)
- Zugriffsrechte (Wer darf was mit der Datei tun?)
Die konkrete Ausprägung der unterstützten Dateiattribute hängt vom Betriebssystem, genauer vom Dateisystem, ab. Moderne Dateisysteme gestatten es dem Nutzer, eigene Attribute zu definieren und zu nutzen.
Dateitypen
Je nach Inhalt unterscheidet man verschiedene Typen von Dateien. So muss das System beispielsweise erkennen, ob eine Datei ausführbaren Code enthält oder nicht. Aber nicht nur das Betriebssystem, sondern auch die Applikationsprogramme müssen die von ihnen zu verarbeitenden von »fremden« Dateien unterscheiden können.
Im Laufe der Zeit wurde eine große Anzahl verschiedener Dateitypen definiert und entwickelt, die sich teilweise auch noch in Versionen unterscheiden. Vom beliebten Portable Document Format PDF gibt es gegenwärtig beispielsweise zwölf verschiedene Versionen!
Die Unterscheidung der einzelnen Dateitypen kann man verschieden realisieren. Zum einen kann dies mittels des Dateinamens erfolgen: Eine Datei, deren Name document.pdf lautet, gilt somit als ein PDF-Dokument. Problematisch sind dabei Dateien, die einen falschen Namen tragen. Diese sind gegebenenfalls kaum mehr dem richtigen Inhaltstyp zuzuordnen. Der Nutzer müsste alle in Frage kommenden Applikationsprogramme mit der fraglichen Datei aufrufen, um deren Inhaltstyp zu ermitteln.
Aus diesem Grund nutzt man eine andere Technik, die sogenannten Magic Words. Das sind kurze, charakteristische Bytesequenzen im Kopf einer Datei, die deren Typ angeben. Dateien, die beispielsweise ausführbaren Programmcode (im sogenannten Executable and Linkable Format [ELF]) für Linux enthalten, beginnen mit der Bytesequenz 7F 45 4C 46, während das Pendant unter Windows (hier Portable Executable, PE, genannt) mit den Bytes 4D 5A startet. Meist sind in diesen Sequenzen einfache Buchstabenfolgen enthalten, die man sofort erkennt. Problematisch bei allen Versuchen, Typen von Dateien zu unterscheiden, ist die mangelhafte Standardisierung dieser Information. Es existiert kein Gremium, das die Vergabe dieser Bytesequenzen verbindlich und übergreifend organisiert.
Verknüpfungen (Links)
Häufig ist es nützlich, Dateien unter mehr als einem Namen ansprechen zu können. Im UNIX-Dateisystem gibt es dafür sogar zwei verschiedene Mechanismen, die sogenannte harte Verknüpfung (hard link) und die symbolische Verknüpfung (symbolic oder soft link). Beide Konzepte haben den gleichen Zweck, unterscheiden sich jedoch subtil.
Harte Verknüpfung
Unter UNIX ist der Name nicht fest mit einer Datei verknüpft, und sie kann unter mehreren verschiedenen Namen im Dateisystem erscheinen.
Die Datenstruktur, die alle relevanten Informationen (außer dem Dateinamen) enthält, nennt man Indexknoten oder verkürzt Inode. Sie enthält eine eindeutige Nummer, die als Identifikator fungiert, die Attribute der Datei sowie Informationen, wo auf dem Datenträger die zugehörigen Nutzdaten zu finden sind. Des Weiteren enthält der Inode einen sogenannten Referenzzähler, der angibt, wie viele Namen (Referenzen) auf eine Datei verweisen. Der Dateiname wiederum enthält einen Verweis auf den Inode. Möchte ein Nutzer mit einer bestimmten Datei arbeiten, dann gibt er den betreffenden Dateinamen an, der zugehörige Verzeichniseintrag verweist auf den Inode, und über diesen findet das System die betreffenden Attribut- und Nutzdaten (Abbildung 10.1). Weitere Namen, die sich an beliebiger Stelle im Dateisystem befinden können, legt der Nutzer mit dem Kommando ln an. Die Anzahl der auf die Datei verweisenden Namen wird stets im Referenzzähler festgehalten (Abbildung 10.2). Die Namen sind völlig gleichwertig, und es kann auch nicht unterschieden werden, welcher Name zuerst vergeben wurde. Wird der erste Name gelöscht, so existiert die Datei selbst weiter unter dem zweiten Namen. Erst wenn kein Name auf die Datei mehr verweist (der letzte auf sie verweisende Name wird gelöscht), werden auch der Inode sowie die Datenblöcke, die den Dateiinhalt konstituieren, freigegeben. Dies geschieht immer dann, wenn der Referenzzähler auf null gesunken ist. Die Verknüpfung eines Namens mit einem Inode nennt man im UNIX-Jargon harte Verknüpfung oder Hard Link.
Harte Verknüpfungen sind nur innerhalb ein und desselben (UNIX-)Dateisystems möglich. Das Anlegen einer Verknüpfung zu einer Datei außerhalb des UNIX-Dateisystems (zum Beispiel auf einem USB-Stick mit ExFAT-Dateisystem) ist unmöglich, weil das ExFAT gar keine Inodes kennt; es ist völlig anders aufgebaut. Mit symbolischen Verknüpfungen gelingt jedoch auch dies!
Symbolische Verknüpfung
Symbolische Verknüpfungen haben den gleichen Zweck wie harte Verknüpfungen: Dateien unter mehr als einem Namen ansprechen zu können. Ihr innerer Aufbau ist jedoch anders: Ein symbolischer Link ist eine Datei, die als einzige Nutzdaten einen Pfad enthält, nämlich den Pfad zur Zieldatei.

Abbildung 10.1: Beziehung zwischen Verzeichniseintrag, Inode und Nutzdaten
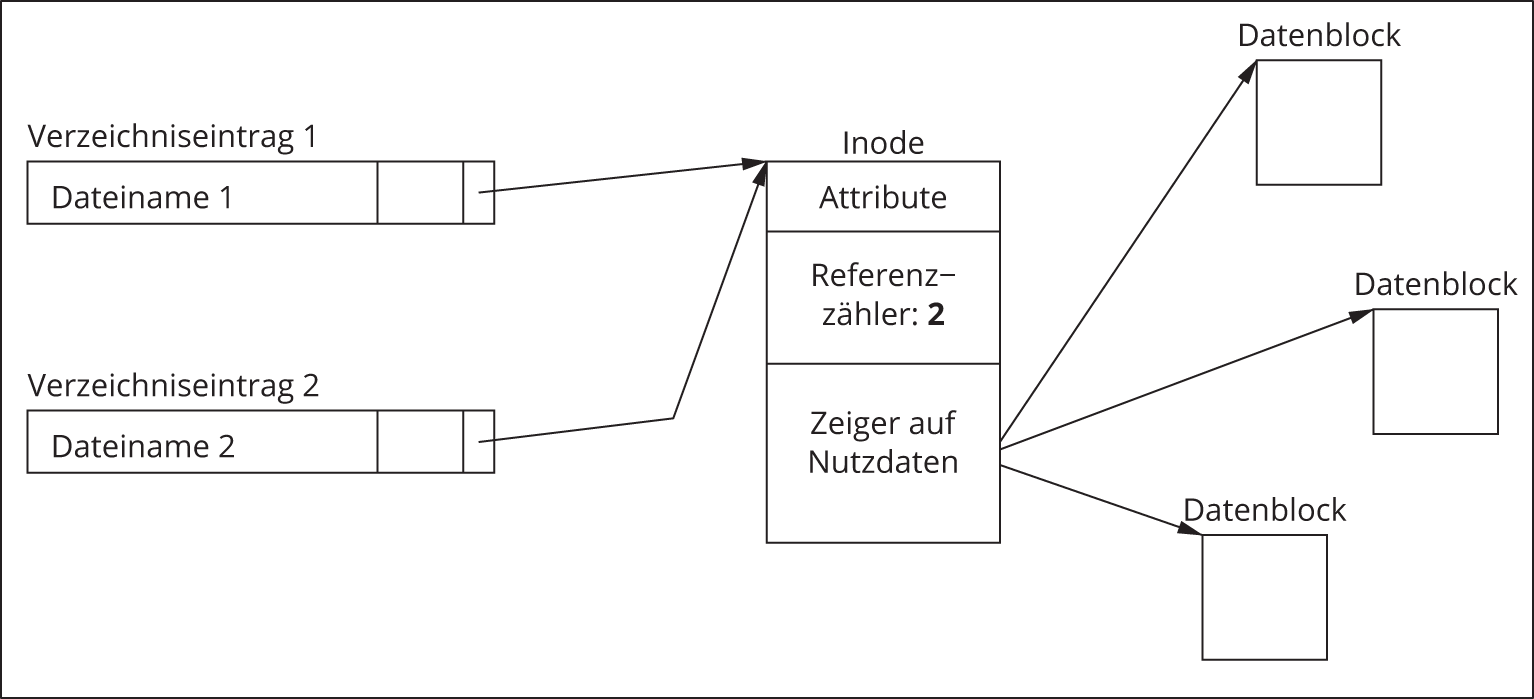
Abbildung 10.2: Zwei Verzeichniseinträge für ein und dieselbe Datei
Wenn Sie einen symbolischen Link öffnen, dann erkennt das System, dass es sich nicht um eine gewöhnliche Datei handelt. Entsprechend liest es die Nutzdaten und sucht danach im zweiten Schritt die Datei auf, auf die der Pfad verweist, den der symbolische Link enthält. Diese Datei (oder dieses Verzeichnis) wird zuletzt geöffnet und zurückgeliefert (Abbildung 10.3). Wenn Sie also eine Datei mittels einer symbolischen Verknüpfung ansprechen, dann werden zwei Pfade ausgewertet:
- der Pfad zur symbolischen Verknüpfung,
- der Pfad, der sich in den Nutzdaten der symbolischen Verknüpfung befindet.

Abbildung 10.3: Prinzip einer Symbolischen Verknüpfung
Dieser doppelte Aufwand wird durch die Tatsache aufgewogen, dass symbolische Verknüpfungen auch über Dateisystemgrenzen hinweg möglich sind, da das Ziel einer symbolischen Verknüpfung innerhalb des gesamten Verzeichnisbaumes liegen kann, der ja gegebenenfalls aus vielen verschiedenen Dateisystemen zusammengesetzt sein kann. Die Verknüpfung selbst muss natürlich von einem Dateisystem ausgehen, das diesen Mechanismus unterstützt.
Nachteilig bei symbolischen Links ist, dass sie auch auf nicht existierende Dateien verweisen können (»dangling link«).
Zugriffsbeschränkungen
Im einführenden Abschnitt dieses Kapitels haben Sie bereits erfahren, dass moderne Dateisysteme Mechanismen zur Steuerung oder Beschränkung des Zugriffs benötigen. Wie kann dies nun erfolgen?
Naiv könnten Sie eine systemweite Tabelle anlegen, in der pro Nutzer jeweils eine Zeile reserviert ist. Die Spalten dieser Tabelle sind den Dateien (oder besser gesagt allen Objekten, für die Sie Zugriffssteuerung realisieren wollen) vorbehalten. Die Felder der Tabelle enthalten diejenigen Operationen, die für den betreffenden Nutzer mit der betreffenden Datei erlaubt sind. Ist das Feld leer, dann darf der Nutzer mit dieser Datei nichts tun. Tabelle 10.1 illustriert das Prinzip, wobei die Buchstaben r, w und x für das Recht, eine Datei zu lesen (read), zu schreiben (write), sowie das Recht zur Ausführung dieser Datei (execute) stehen). Mit Hilfe einer solchen Zugriffsmatrix kann das System jederzeit entscheiden, ob eine Operation eines Nutzers durchgeführt oder unterbunden werden muss. Es selektiert das Matrixelement, das sich am Schnittpunkt zwischen der Spalte des zugreifenden Nutzers und der Zeile des referenzierten Objektes befindet. Enthält das Element die durch den Nutzer gewünschte Operation, dann wird diese ausgeführt, ansonsten verweigert.
datei1 |
datei2 |
datei3 |
datei4 |
… |
|
arno |
rwx |
rw |
rw |
||
beate |
x |
r |
|||
cyrus |
x |
r |
|||
dave |
r |
rw |
r |
rwx |
|
⋮ |
Tabelle 10.1: Beispiel einer Zugriffsmatrix
Permissions im AFS
Die drei Operationen read, write und execute orientieren sich am klassischen UNIX-Dateisystem. Andere Dateisysteme besitzen differierende Typen von Operationen. Das so genannte Andrew File System (AFS), ein etwas exotisches Netzwerk-Dateisystem, bietet beispielsweise die in der Tabelle 10.2 aufgeführten vier Rechte für Operationen mit Verzeichnissen sowie drei Rechte für Dateien.
Recht |
Bedeutung |
|
|---|---|---|
lookup |
l |
Anzeige des Verzeichnisinhalts |
insert |
i |
Anlegen neuer Dateien (Verzeichniseinträge) |
delete |
d |
Löschen von Verzeichniseinträgen |
administer |
a |
Verändern der Rechte des Verzeichnisses |
read |
r |
Dateiinhalt lesen |
write |
w |
Dateiinhalt schreiben |
lock |
k |
Datei für andere Nutzer sperren |
Tabelle 10.2: Permissions im AFS
Im Regelfall hat ein Nutzer nur Zugriff auf seine eigenen Dateien. Dies bedeutet, dass sehr viele Einträge in der Matrix leer sind. Stellen Sie sich folgende Situation vor: Es gibt in einem System zehn verschiedene Nutzer, von denen jeder in seinem Homeverzeichnis 1000 Dateien besitzt (es gibt somit insgesamt im System 10 000 Dateien). Von diesen 1000 Dateien sollen jeweils 10 %, also 100 Dateien, allen Nutzern zum Zugriff zur Verfügung stehen.
Jeder Nutzer hat also Zugriffsrechte auf 1900 Dateien: seine eigenen 1000 Dateien sowie die 10% aller anderen neun Nutzer. 8100 Dateien sind für jeden Nutzer somit nicht zugreifbar. Von den insgesamt 100 000 Einträgen der Matrix sind 81 000 leer, das sind immerhin 81 %! Man kann mit Fug und Recht von einer spärlich besetzten Matrix sprechen.
Das Gedankenexperiment verdeutlicht, dass es hinsichtlich des Speichers ineffizient ist, Zugriffsrechte in Form einer Matrix zu realisieren, da ein großer Anteil der Matrixelemente leer ist. Stattdessen dekomponiert man die zweidimensionale Datenstruktur in eine Liste: Entweder man legt eine Liste aller Objekte an und vermerkt, welche Nutzer Rechte an diesen haben, oder man geht umgekehrt vor, legt eine Liste aller Nutzer an und vermerkt für jeden Nutzer, für welche Dateien er Rechte besitzt. Erstere Variante nennt man Access Control List (ACL), letztere Capability List. Die in Betriebssystemen meist gewählte Variante ist die ACL.
Vorteilhaft an der Listenstruktur ist, dass leere Elemente nicht mit abgespeichert werden. Kommt ein bestimmter Nutzer in der ACL einer Datei nicht vor, dann darf dieser Nutzer einfach nicht auf die Datei zugreifen. Nachteilig ist hingegen prinzipbedingt die Notwendigkeit, die Liste entweder zu durchsuchen oder diese sortiert zu halten.
 Im klassischen UNIX entschied man sich aus Aufwandsgründen für eine reduzierte Form der Access Control List. Es gibt grundsätzlich drei Rechte: ein Leserecht (read), ein Schreibrecht (write) und ein Recht zum Ausführen des Objektes (execute). Diese drei Rechte werden zumeist mit rwx abgekürzt. Das Recht zum Ausführen ergibt natürlich nur bei ausführbaren Dateien wie Shellskripten oder Programmcode einen Sinn. Im Kontext eines Verzeichnisses repräsentiert es das Recht, in selbiges hineinzuwechseln, also das Verzeichnis zum aktuellen Verzeichnis zu machen.
Im klassischen UNIX entschied man sich aus Aufwandsgründen für eine reduzierte Form der Access Control List. Es gibt grundsätzlich drei Rechte: ein Leserecht (read), ein Schreibrecht (write) und ein Recht zum Ausführen des Objektes (execute). Diese drei Rechte werden zumeist mit rwx abgekürzt. Das Recht zum Ausführen ergibt natürlich nur bei ausführbaren Dateien wie Shellskripten oder Programmcode einen Sinn. Im Kontext eines Verzeichnisses repräsentiert es das Recht, in selbiges hineinzuwechseln, also das Verzeichnis zum aktuellen Verzeichnis zu machen.
Jedes Objekt im Dateisystem besitzt eine Access Control List mit genau drei Einträgen. Es wäre aber ungünstig, wenn auf jede Datei nur von genau drei Nutzern zugegriffen werden könnte. Daher gibt es wiederum drei Kategorien von Nutzern:
- Das erste Rechtetripel
rwxist dem Eigentümer der Datei vorbehalten.- Jede Datei ist genau einer Gruppe von Nutzern zugeordnet. Den Mitgliedern dieser Gruppe ist das zweite Rechtetripel vorbehalten.
- Das dritte Rechtetripel bestimmt, welche Operationen durch alle anderen Nutzer des Systems über der Datei ausgeführt werden dürfen.
Die drei Kategorien werden im Englischen user, group und other, kurz ugo, genannt. Möchte man die Bits aller drei Kategorien identisch ändern, gibt es zusätzlich all.
Der ls-Befehl in der Langform (ls -l) zeigt für jede Datei die Rechte als Teil der Dateiattribute folgendermaßen an:

Jede Zeile beschreibt eine Datei. Das erste Zeichen gibt den Dateityp an (hier: - für eine reguläre Datei), und die folgenden neun Zeichen determinieren die 3 x 3 Rechte der Datei für Eigentümer, Gruppenmitglieder und alle anderen Nutzer. Steht ein Kleinbuchstabe  , so ist das Recht gewährt, steht hingegen ein ‘-’, dann ist das Recht verweigert.
, so ist das Recht gewährt, steht hingegen ein ‘-’, dann ist das Recht verweigert.
Im Beispiel darf der Eigentümer (Nutzer robert) der Datei foo diese also lesen, schreiben und ausführen, und sowohl die Mitglieder der Gruppe (inf) als auch alle anderen Nutzer dürfen die Datei lesen und ausführen. Der Eigentümer der Datei bar, der Nutzer kerstin, darf diese lesen und beschreiben, alle anderen Nutzer haben keinen Zugriff.
Dieses Rechteschema hat sich in der Praxis bewährt und benötigt nur wenig Speicherplatz, nämlich 9 Bit pro Verzeichniseintrag. Allerdings sind bestimmte Rechteverteilungen damit nicht zu realisieren. Beispielsweise ist es unmöglich, drei unterschiedlichen Nutzern verschiedene Rechte zu verleihen und allen anderen Nutzern den Zugriff zu verwehren.
Wie funktioniert eine Festplatte?
Bevor Sie tiefer in die Struktur von Dateisystemen hinabsteigen, ist es nützlich, sich einen kurzen Überblick über die Funktionsweise von Festplatten zu verschaffen. Insbesondere geht es dabei um die Frage, welche Faktoren welchen Einfluss auf die Dauer eines Festplattenzugriffs haben.
Aufbau
Eine Festplatte besteht aus einer oder mehreren rotierenden Magnetplatten. Die Rotationsgeschwindigkeit ist, vom Ein- und Ausschaltvorgang abgesehen, konstant (Constant Angular Velocity, CAV) und liegt typabhängig zwischen 5400 und 15 000 min−1 – im Gegensatz zu optischen Datenträgern, deren Rotationsgeschwindigkeit variiert, was man deutlich am Betriebsgeräusch hören kann. Die Daten befinden sich auf jeder Plattenoberfläche in Form konzentrischer Spuren. Die Spuren sind in Kreissegmente unterteilt, diese werden physische Blöcke genannt (in älterer Literatur: Sektoren). Die Größe der physischen Blöcke beträgt 512 Byte; seit einigen Jahren gibt es jedoch auch Festplatten mit einer Blockgröße von 4 KiB. Zum Zugriff auf die Daten gibt es einen Schreib-/Lesekopf pro Plattenoberfläche; alle Köpfe sind miteinander starr verbunden und können somit nur gemeinsam bewegt werden. Die Kopfbewegung erfolgt radial zur Platte. Der physische Block ist die kleinste Einheit, auf die zugegriffen werden kann. Abbildung 10.4 zeigt eine Festplatte in vereinfachter Draufsicht.
Die physischen Blöcke sind einfach durchnummeriert und erhalten somit eine physische Blocknummer (Physical Block Number, PBN). Diese physischen Blocknummern sind nur für die Festplatte selbst sichtbar. Für die Kommunikation nach »außen« übersetzt die Festplatte die internen physischen Blocknummern in sogenannte logische Blocknummern (Logical Block Numbers, LBN). Die Übersetzung LBN  PBN erledigt die Firmware der Festplatte.
PBN erledigt die Firmware der Festplatte.
Mit diesem Mechanismus ist es beispielsweise möglich, den Ausfall einzelner Blöcke für den Nutzer zu maskieren. Für diesen Fall besitzt die Festplatte Reserveblöcke, die eine PBN, aber zunächst keine LBN erhalten. Stellt die Firmware fest, dass ein Block defekt ist, so wird versucht, dessen Inhalt in einen Reserveblock zu kopieren. Dieser Reserveblock erhält anschließend die logische Blocknummer des defekten Blockes, der somit aus dem Verkehr gezogen ist. Das Ganze funktioniert natürlich nur, solange Reserveblöcke zur Verfügung stehen.

Abbildung 10.4: Festplatte in Draufsicht (vereinfacht)
 Die logischen Blocknummern der Festplatte dürfen nicht mit den logischen Blöcken des Dateisystems verwechselt werden. Aus Effizienzgründen fassen Dateisysteme mehrere physische Festplattenblöcke (die über logische Blocknummern adressiert werden), zu größeren logischen Blöcken des Dateisystems zusammen. Diese sind wiederum nummeriert, und diese Nummern sind wiederum nur innerhalb des Dateisystems von Bedeutung; die Festplatte kann mit diesen nichts anfangen. Das UNIX-Dateisystem arbeitet beispielsweise traditionell mit einer logischen Blockgröße von 4 KiB, also jeweils acht physischen Festplattenblöcken, während das Dateisystem von MS-DOS die logische Blockgröße zwischen 512 Byte und 32 KiB (abhängig von der Größe des Datenträgers) auswählt. In Microsoft-Terminologie werden die logischen Blöcke des Dateisystems als Cluster beziehungsweise Zuordnungseinheiten bezeichnet.
Die logischen Blocknummern der Festplatte dürfen nicht mit den logischen Blöcken des Dateisystems verwechselt werden. Aus Effizienzgründen fassen Dateisysteme mehrere physische Festplattenblöcke (die über logische Blocknummern adressiert werden), zu größeren logischen Blöcken des Dateisystems zusammen. Diese sind wiederum nummeriert, und diese Nummern sind wiederum nur innerhalb des Dateisystems von Bedeutung; die Festplatte kann mit diesen nichts anfangen. Das UNIX-Dateisystem arbeitet beispielsweise traditionell mit einer logischen Blockgröße von 4 KiB, also jeweils acht physischen Festplattenblöcken, während das Dateisystem von MS-DOS die logische Blockgröße zwischen 512 Byte und 32 KiB (abhängig von der Größe des Datenträgers) auswählt. In Microsoft-Terminologie werden die logischen Blöcke des Dateisystems als Cluster beziehungsweise Zuordnungseinheiten bezeichnet.
Abbildung 10.5 zeigt ein Beispiel. Ursprünglich verbargen sich hinter den Festplattenblöcken mit den LBN 1…8 die physischen Blöcke 4…11. Ein Defekt führte irgendwann zur Ausmusterung des physischen Blocks 5. Seine Aufgabe (den Inhalt des logischen Blockes 2 aufzunehmen) übernahm Reserveblock 412. Ein logischer Block des Dateisystems umfasst vier Festplattenblöcke, ist somit 2048 Bytes lang. Die im Dateisystem angelegte Datei besteht aus den logischen Blöcken 0 und 1, die jeweils ihrerseits aus den logischen Festplattenblöcken 1…4 beziehungsweise 5…8 bestehen.
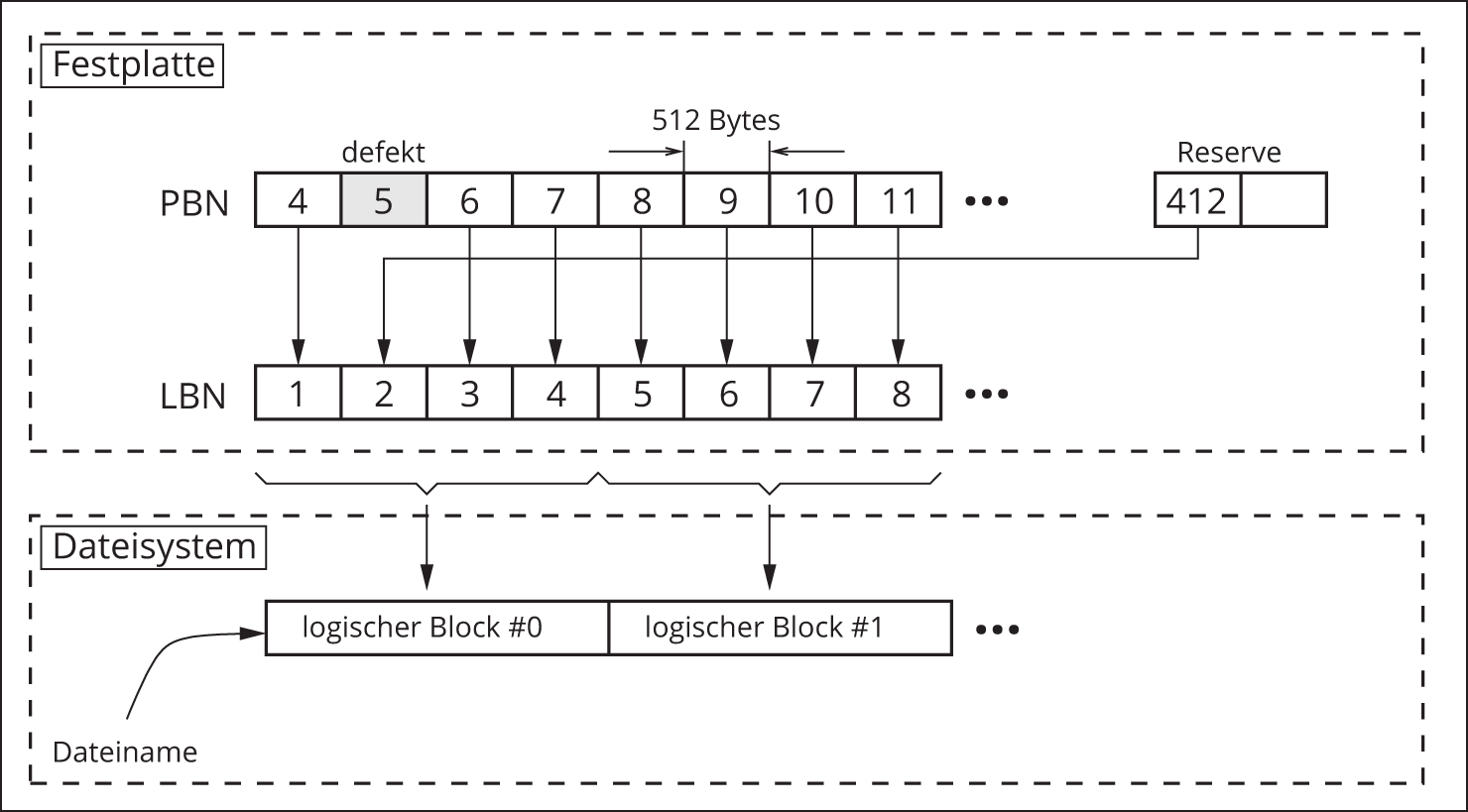
Abbildung 10.5: Physische und logische Blocknummern des Massenspeichers und ihre Abbildung auf logische Blöcke des Dateisystems
Ablauf einer Zugriffsoperation
Der Zugriff auf die Daten eines Blockes erfolgt in mehreren Etappen. Das Verständnis dieses Mechanismus ist essenziell für die Diskussion des I/O-Schedulings später in diesem Kapitel!
Die folgenden Schritte geschehen, wenn das Betriebssystem einen logischen Block lesen möchte. Je nach genutztem Peripheriebus (ATA, SCSI) gibt es dafür unterschiedliche Kommandos, von denen abstrahiert werden soll.
- Die Festplatte empfängt das Lese- oder Schreibkommando, das die logische Blocknummer enthält sowie gegebenenfalls die zu schreibenden Daten.
- Die Festplatte ermittelt zur gewünschten LBN die entsprechende PBN. Damit weiß sie, wo sich der gewünschte Block befindet (welche Plattenoberfläche, welche Spur, welcher Sektor innerhalb der Spur).
-
Der Schreib-/Lesekopf muss nun gegebenenfalls zur richtigen Spur bewegt werden. Diese Operation wird Seek genannt.
Im besten Fall, nämlich wenn der Kopf schon auf der dieser Spur steht, ist dies natürlich unnötig. Im schlimmsten Fall (aktuelle Kopfposition ganz innen, Zielspur ganz außen oder genau andersherum) muss einmal über den gesamten Radius der Platte gefahren werden (Full Stroke). Typische Zeiten für die Seek-Operation liegen je nach Distanz zwischen ein bis zehn Millisekunden.
- Befindet sich der gewünschte Block nicht auf der Plattenoberfläche des vorangegangenen Zugriffs, muss zum »zuständigen« Schreib-/Lese-Kopf umgeschaltet werden.
- Nun muss gegebenenfalls noch gewartet werden, bis der Beginn des Blocks sich genau unter dem Kopf befindet. Diese Dauer wird Rotationslatenz genannt. Sie hängt von der Drehzahl der Festplatte ab. Im günstigsten Fall ist die Rotationslatenz null, nämlich wenn genau zum Ende des Seeks der Block den Schreib-/Lesekopf erreicht. Im ungünstigsten Fall ist er ein klitzekleines bisschen eher da, dann muss eine ganze Umdrehung der Platte abgewartet werden. Bei einer Drehzahl von 7200 min−1 wären das beispielsweise 8.3 ms.
- Nun kann der entsprechende Sektor eingelesen oder beschrieben werden, was wiederum eine gewisse Dauer benötigt. Im Vergleich zu Seek-Zeit und Rotationslatenz kann sie vernachlässigt werden.
- Bei einer Leseoperation müssen die Daten noch in den Hauptspeicher transportiert werden.
In Datenblättern zu Festplatten ist gern neben der maximalen Übertragungsrate eine »mittlere Seek-Zeit« (average seek time) angegeben. In Ermangelung standardisierter Testverfahren oder wenigstens einer nachvollziehbaren Beschreibung der Ermittlung des Parameters ist diese Angabe genauso unsinnig wie der durchschnittliche Kraftstoffverbrauch eines Pkws mit Verbrennungsmotor.
Die Dauer eines Festplattenzugriffs wird im Wesentlichen durch die Zeit für die Kopfbewegung (Seek) und die Wartezeit, bis der gewünschte Block unter dem Schreib-/Lesekopf steht (Rotationslatenz), bestimmt. Erstere hängt von der gegenwärtigen Position des Kopfes, Letztere von der Rotationsgeschwindigkeit der Platte ab.
Systemrufe fürs Dateisystem
In diesem Abschnitt werden Sie einige typische Dienste kennenlernen, die ein Betriebssystem zur Arbeit mit dem persistenten Speicher bereitstellt.
Grundsätzlich unterscheidet man den sogenannten sequenziellen Zugriff (sequential access) vom wahlfreien Zugriff (random access). Im ersten Fall werden die Blöcke hintereinanderweg gelesen oder geschrieben. Dies erfolgt zum Beispiel, wenn Sie einen Film ansehen oder wenn der Programmcode eines auszuführenden Programms in den Speicher geladen wird. Beim wahlfreien Zugriff ist die Reihenfolge der Daten, auf die zugegriffen wird, beliebig (zum Beispiel das Lesen von Datensätzen aus einer Datenbank nach Abfrage). Er erfordert häufig Seek-Operationen zwischen den einzelnen Lese- oder Schreiboperationen, die bei rein sequenziellem Zugriff nicht notwendig sind.
Nun sollen aber die wichtigsten Dienste eines Betriebssystems zum Zugriff auf das Dateisystem kurz eingeführt und demonstriert werden.
Einfaches Lesen und Schreiben von Dateien
Um mit dem Inhalt einer Datei arbeiten zu können, muss diese teilweise oder komplett in den Hauptspeicher übertragen werden. Dort kann der Inhalt manipuliert werden, und anschließend muss das Ergebnis wieder auf den Massenspeicher zurückgeschrieben werden, sofern es dauerhaft abgelegt werden soll.
Um auf Dateien zugreifen zu können, bietet jedes System eine Reihe von Systemrufen an, die meist eine ähnliche Semantik haben. Dateien müssen normalerweise eröffnet werden, bevor auf ihren Inhalt zugegriffen werden kann (Funktion open()). Zum Lesen von Bytes dient der Dienst read(), das Schreiben erledigt write(). Am Ende der Bearbeitung einer Datei wird diese mittels des Dienstes close() geschlossen. In vielen Betriebssystemen arbeiten diese Zugriffsoperationen rein sequenziell. Wenn also eine Datei eröffnet wird, so beginnt read() am Anfang der Datei zu lesen. Verantwortlich hierfür ist der sogenannte Dateipositionszeiger, der nach einem open() standardmäßig auf den Anfang der Datei zeigt. Alle Lese- und Schreiboperationen greifen nämlich stets auf das Byte zu, auf das der Dateipositionszeiger verweist, und sie setzen den Dateipositionszeiger entsprechend weiter. Damit erhält man gewissermaßen automatisch sequenziellen Zugriff.
Listing 10.1 zeigt ein UNIX-Programm zum Kopieren einer Datei. Dies erfolgt diesmal nicht wie im vorigen Kapitel mittels mmap() (blättern Sie ruhig noch einmal zurück; es ist Listing 9.1), sondern gewissermaßen auf die »althergebrachte« Art und Weise, das bedeutet mittels der Systemrufe read() und write().


Listing 10.1: Programm zum Kopieren einer Datei
Die Pfadangaben von Quell- und Zieldatei sollen als Argumente auf der Kommandozeile übergeben werden. Zunächst wird die tatsächliche Argumentanzahl geprüft. Danach erfolgt das Öffnen der Quell- und Zieldatei (Zeilen 22, 27). Beide open()-Aufrufe liefern einen sogenannten Dateideskriptor zurück, der fürderhin zur Identifikation der geöffneten Datei dient. Nun wird der erste Block mittels read() in den Pufferspeicher buf gelesen (Zeile 33) und danach die Schleife betreten.
Innerhalb dieser erfolgen nun im Wechsel das Schreiben des zuvor eingelesenen Blockes in die Zieldatei mittels write() (Zeile 39) und das Lesen des nächsten Blockes (Zeile 44). Dabei können sowohl die Schreib- als auch die Leseoperation fehlschlagen, also wird in beiden Fällen eine Fehlerbehandlung benötigt (Zeilen 35–38 sowie 40–43).
Wie kommen wir nun aus der Schleife wieder heraus? Wir haben bereits gesehen, dass das zweite Argument von read() die Anzahl der Bytes ist, die gelesen werden soll. Der Ruf liefert als Resultat die Anzahl an Bytes zurück, die tatsächlich gelesen wurde, denn diese kann kleiner sein als die verlangte Anzahl. Ein Resultatwert von 0 zeigt an, dass man das Ende der Datei (»End of File«, EOF) erreicht hat. Ein Fehler liegt vor, wenn -1 zurückgeliefert wird. Die Abbruchbedingung für die Schleife ist also der Test, ob das Ende der Quelldatei gelesen wurde. Außerdem wird die Schleife außerplanmäßig verlassen, wenn das Schreiben eines Blockes einen Fehler erzeugt (dies ist unwahrscheinlich, aber nicht unmöglich; beispielsweise könnte die Kapazität des Datenträgers erschöpft sein).
Zu guter Letzt werden beide eröffnete Dateien geschlossen (Zeilen 46, 47), und je nach Fehlerstatus wird ein entsprechender Rückgabewert an die rufende Umgebung zurückgeliefert (Zeilen 50 und 53).
Ein weiterer wichtiger Systemruf ist lseek(). Er dient dazu, den Dateipositionszeiger explizit zu versetzen, ohne dass eine Lese- oder Schreiboperation ausgeführt wird. Dies ist insbesondere bei der Verwirklichung von wahlfreien Zugriffen notwendig.
Arbeit mit Verzeichnissen
Wir wollen exemplarisch noch eine zweite Gruppe von Diensten näher betrachten, nämlich die Schnittstelle zur Arbeit mit Verzeichnissen.
Verzeichnisse werden in UNIX ähnlich wie Dateien behandelt. Sie müssen eröffnet werden (opendir()), danach kann man die einzelnen Einträge sequenziell mittels readdir() lesen, und schließlich muss das Verzeichnis mittels closedir() wieder geschlossen werden. Listing 10.2 zeigt ein Beispiel für die Verwendung dieser Rufe. Als Argument erhält das Programm den Pfad eines Verzeichnisses, und es sollen nun die Namen und Größen aller enthaltenen Dateien angezeigt werden.
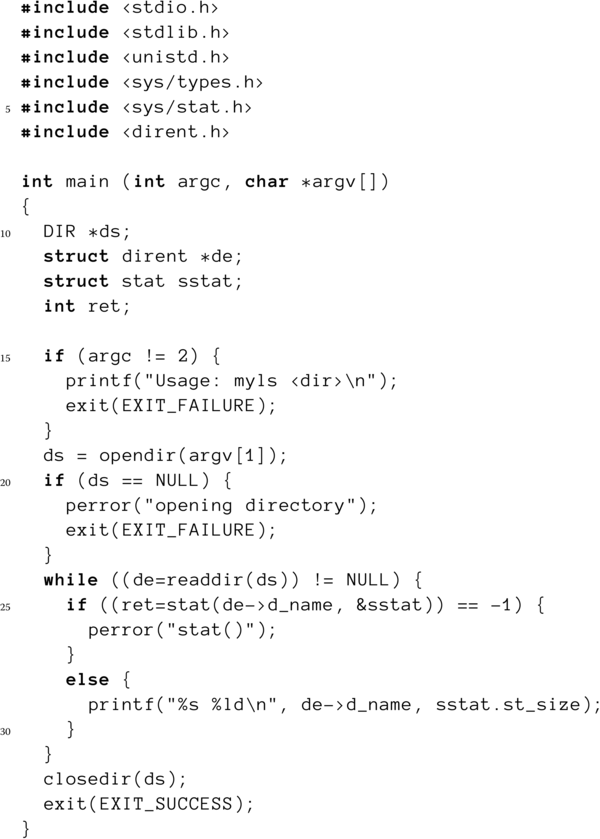
Listing 10.2: Programm zur Anzeige eines Verzeichnisinhaltes
Nach der Existenzprüfung des Argumentes wird das Verzeichnis eröffnet (Zeile 19). Genauso wie das Öffnen einer Datei kann dies fehlschlagen, beispielsweise wenn der aufrufende Prozess nicht die erforderlichen Leserechte für dieses Verzeichnis besitzt. Aus diesem Grunde ist wiederum eine potenzielle Fehlerbehandlung notwendig (Zeilen 20–23).
Nun kann man mittels readdir() die einzelnen Verzeichniseinträge auslesen (Zeile 24). Diese sind vom Typ struct dirent, der die in Listing 10 aufgeführte Definition besitzt.

Sie können erkennen, dass weder die Größe der Datei noch andere Attribute – mit Ausnahme des Namens – im Verzeichniseintrag enthalten sind. Wie Sie später noch sehen werden, hat das durchaus seinen Sinn, damit sind nämlich mehrere Namen für ein und die selbe Datei möglich. Der Verzeichniseintrag enthält aber die Nummer des Inodes, den Sie bereits im Abschnitt über Verknüpfungen kennengelernt haben.
Wenn man den Namen des Verzeichniseintrages kennt, dann kann man mit Hilfe eines weiteren Systemrufes, stat(), dem man ein sogenanntes struct stat übergibt, alle zugehörigen Attribute und damit auch die Größe der Datei ermitteln (Zeile 25). Diese wird zusammen mit dem Dateinamen in Zeile 29 ausgegeben, und danach startet eine neue Schleifeniteration, bis alle Einträge im Verzeichnis bearbeitet sind und readdir() den Wert NULL zurückliefert (Zeile 24).
Das Programm ist in vielen Aspekten verbesserungsbedürftig, beispielsweise zeigt es auch die Größe von Verzeichnissen und Pseudodateien an, und die Ausgabe sieht auch nicht allzu schön aus. Eine Überarbeitung des Codes wäre eine prima Übung für den interessierten Leser! Sehen Sie sich auch bitte die Übungsaufgaben am Ende des Kapitels an.
Es existieren viele weitere nützliche Systemrufe, beispielsweise das ziemlich komplexe scandir(), das eine effiziente Dateisuche nach beliebigen Kriterien inklusive Sortierung implementiert. Die Diskussion würde den Rahmen dieses Buches jedoch sprengen. Einen kleinen Einblick in die dateisystembezogene Programmierung haben Sie aber auf alle Fälle absolviert.
Implementation von Dateisystemen
Wir wollen im Folgenden einige Aspekte der Implementation von Dateisystemen diskutieren. Von einem trivialen Ansatz ausgehend werden wir dabei schrittweise dessen Nachteile eliminieren und bestimmte Aspekte verfeinern.
Blöcke
Ein Massenspeicher stellt seine Kapazität aus Effizienzgründen blockweise zur Verfügung. Bei Festplatten beträgt die Größe eines Blockes entweder 512 Byte oder (seit einigen Jahren) 4096 Byte. Die Adressierung ist denkbar einfach: Die Blöcke des Datenträgers werden beginnend ab null durchnummeriert (das sind die bereits erwähnten logischen Blocknummern, LBN), und aus dem Produkt aus Blockanzahl und Blockgröße erhalten wir die Gesamtkapazität des Datenträgers.
Dateisysteme wiederum gruppieren in der Regel mehrere Massenspeicherblöcke zu (größeren) Blöcken des Dateisystems, die logische Blöcke genannt werden. Beispielsweise nutzt das ext4-Dateisystem von Linux traditionell eine logische Blockgröße von 4 KiB, während die Blockgröße des FAT-Dateisystems zwischen 512 Byte und 32 KiB liegt und von der Größe des Datenträgers abhängt.
Die Wahl der Blockgröße bedingt einen Kompromiss: Je größer die Blöcke gewählt werden, desto effizienter geschieht im Allgemeinen der Datentransfer, da pro Transferoperation weniger Verwaltungsaufwand nötig ist. Gleichzeitig steigt aber der Verlust von Speicherplatz durch »Verschnitt«, denn selbst eine Datei von 1 Byte Größe belegt stets einen kompletten logischen Block.
Dateiverwaltung
Eine wesentliche Aufgabe des Dateisystems besteht darin, sich für jede Datei zu merken, aus welchen Blöcken sie besteht. Dies soll so geschehen, dass der Zugriff effizient erfolgt, wenig Speicherplatz verschwendet wird und willkürliche Beschränkungen der Dateigröße ausgeschlossen sind. In diesem Abschnitt werden Sie Techniken dafür kennenlernen.
Kontinuierliche Allokation
Betrachten wir zunächst den Massenspeicher als lineares Medium, welches initial leer ist. Eine zu schreibende Datei wird einfach hintereinanderweg auf dem Medium abgelegt, eine zweite Datei wird direkt dahinter abgelegt und so weiter.

Abbildung 10.6: Kontinuierliche Allokation von Blöcken
Abbildung 10.6 zeigt ein Beispiel: Datei A belegt die Festplattenblöcke 12 bis 15, Datei B die Blöcke 16 und 17 und ab Block 18 ist Datei C abgelegt.
Dieses Verfahren bietet einige Vorteile: Zu jeder Datei müssen nur die Position des ersten Blocks und die Anzahl der zugehörigen Blöcke (also die Länge der Datei) gespeichert werden. Darüber hinaus ist nicht nur der sequentielle, sondern auch der wahlfreie Zugriff sehr schnell: Die Position des Bytes 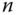 einer Datei ergibt sich aus der Position des ersten Bytes der Datei +
einer Datei ergibt sich aus der Position des ersten Bytes der Datei + 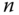 . Wir werden später sehen, dass dies keineswegs immer der Fall ist.
. Wir werden später sehen, dass dies keineswegs immer der Fall ist.
Solange alle Dateien eine konstante Länge haben, ist die kontinuierliche Allokation das Mittel der Wahl. Dies ist bei optischen Datenträgern der Fall, da diese nur gelesen werden. Für ein beschreibbares Dateisystem ist diese Einschränkung jedoch nicht durchsetzbar. Wie sollte man beispielsweise vorgehen, wenn man nachträglich Datei A um einige Blöcke verlängern möchte (append-Operation)? Ein vorausschauendes Reservieren von freien Blöcken am Ende einer Datei kommt sicherlich nicht in Frage, denn wie groß sollte diese Reserve gewählt werden? Ein gangbarer Weg ist das Löschen von A an der ursprünglichen Position und das Neuschreiben des vergrößerten A auf freie Blöcke (Umkopieren). Die dabei entstehenden Löcher könnten durch zyklische »Aufräumvorgänge« (Garbage Collection) eliminiert werden. Es liegt jedoch auf der Hand, dass der dafür notwendige Aufwand beträchtlich ist. Beispielsweise würde das Anhängen eines einzigen Bytes an eine sehr große Datei zu einem Umkopieren der gesamten Datei führen.
Wenn aber von vornherein Schreiboperationen im Dateisystem ausgeschlossen sind (denken Sie an CD-ROMs und verwandte optische Datenträger), dann ist die kontinuierliche Allokation durchaus ein Mittel der Wahl. Das Dateisystem ISO 9660 nutzt beispielsweise diese Technik.
Verkettete Liste
Ein probates Mittel zur Realisierung von Datenstrukturen mit variabler Länge ist die verkettete lineare Liste. Versuchen wir, das Prinzip zur Speicherung der Folge der eine Datei konstituierenden Blöcke einzusetzen.
Ein Listenelement besteht aus einem Nutzdatenfeld sowie einem Zeiger auf das nachfolgende Element. Im der Datei zugeordneten Verzeichniseintrag muss dann nur der Zeiger auf das erste Listenelement (der »Anker«) abgelegt werden (Abbildung 10.7).

Abbildung 10.7: Datenblöcke einer Datei als Liste
Beim sequenziellen wie beim wahlfreien Zugriff müssen Sie sich ausgehend vom Anker durch die Liste bewegen, wobei dies durch die einfache Verkettung ausschließlich vorwärts möglich ist.
Programmtechnisch am einfachsten wäre es, den Zeiger in die letzten Bytes eines Festplattenblockes zu schreiben und den verbleibenden Rest des Blockes zur Aufnahme der eigentlichen »Datei-Daten« zu verwenden. Abbildung 10.8 verdeutlicht das Prinzip.
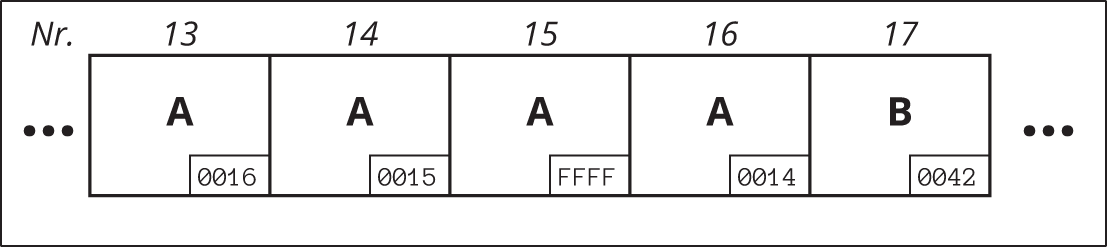
Abbildung 10.8: Datei als verkettete Liste
Die Datei A belegt (in der Reihenfolge) die Blöcke 13, 16, 14 und 15. Der Wert FFFF ist die Endemarkierung. Dies bedeutet übrigens auch, dass im Beispiel maximal die Blocknummern von 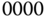 bis
bis 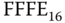 , also insgesamt
, also insgesamt 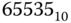 verschiedene Blöcke, innerhalb des Dateisystems angesprochen werden können.
verschiedene Blöcke, innerhalb des Dateisystems angesprochen werden können.
Um auf eine Datei zuzugreifen, müssen wir uns nur noch den ersten Block der Datei merken; selbst die Längenangabe ist nicht zwingend nötig, denn das letzte Element einer Liste ist ja durch einen besonders vereinbarten Wert im Zeigerfeld gekennzeichnet.
Damit ist es nun sehr leicht möglich, Dateien zu verlängern oder zu verkürzen. Bei einer Verlängerung holen wir uns einfach einen bisher unbenutzten Block, belegen ihn mit Daten und ketten ihn ans Ende der bisherigen Liste. Selbst komplexe Operationen wie das Löschen und Einfügen von Daten irgendwo in der Mitte der Datei sind ohne Umkopieren möglich. Ziel erreicht? Leider nein, denn den unbestreitbaren Vorteil erkämpfen wir mit einem gravierenden Nachteil: Der wahlfreie Zugriff wird sehr aufwendig:
Nehmen wir an, unsere Datei bestünde aus 70 000 Blöcken á 512 Byte ( 36 MiB) und wir wollen die letzten 200 Byte lesen. Dazu müssen wir auf den letzten Block zugreifen. Wie erhalten wir dessen Position? Sie ist im vorletzten Block (und nur dort!) vermerkt, also müssen wir diesen lesen. Wie erhalten wir die Position des vorletzten Blockes? – Durch Lesen des drittletzten Blockes und so weiter. Wir müssen uns mühsam Schritt für Schritt, beginnend am ersten Block (der im zugehörigen Verzeichniseintrag vermerkt ist), durch die Datei hangeln und alle 70 000 Blöcke lesen, nur um auf die letzten 200 Byte Zugriff zu erlangen. Wenn jeder Lesevorgang zehn Millisekunden dauert, so benötigen wir für das Finden des Dateiendes über elf Minuten, ein völlig inakzeptabler Wert.
36 MiB) und wir wollen die letzten 200 Byte lesen. Dazu müssen wir auf den letzten Block zugreifen. Wie erhalten wir dessen Position? Sie ist im vorletzten Block (und nur dort!) vermerkt, also müssen wir diesen lesen. Wie erhalten wir die Position des vorletzten Blockes? – Durch Lesen des drittletzten Blockes und so weiter. Wir müssen uns mühsam Schritt für Schritt, beginnend am ersten Block (der im zugehörigen Verzeichniseintrag vermerkt ist), durch die Datei hangeln und alle 70 000 Blöcke lesen, nur um auf die letzten 200 Byte Zugriff zu erlangen. Wenn jeder Lesevorgang zehn Millisekunden dauert, so benötigen wir für das Finden des Dateiendes über elf Minuten, ein völlig inakzeptabler Wert.
Auch eine mehrfache Verkettung der Listenelemente ändert daran nichts, wir gewinnen damit nur die Möglichkeit, uns rückwärts von Block zu Block zu bewegen, was in der Praxis kaum auftritt. Halten wir fest: Der wahlfreie Zugriff auf Dateien wird durch die lineare Liste stark verlangsamt.
Ein zweiter Nachteil ist die geringe Fehlertoleranz des Konzeptes. Wird die Liste an irgendeiner Stelle unterbrochen (zum Beispiel durch einen fehlerhaften Schreibvorgang), so gibt es bei einer einfachen Verkettung keine Möglichkeit mehr, die nachfolgenden Blöcke wiederzufinden. Inkonsistenzen im Dateisystem sind die Folge.
Es gibt noch einen dritten, nicht so offensichtlichen Nachteil bei dieser Realisierungsvariante: Der Nutzdatenteil jedes Blockes ist kein ganzzahliges Vielfaches der Sektorgröße mehr. Nutzen wir beispielsweise 48-Bit-Zahlen als Blocknummern und 512 Byte große Blöcke, so benötigt der Zeiger auf den Nachfolgeblock 6 Byte. Das Nutzdatenfeld ist damit 506 Byte lang. Der Hauptspeicher, in den die Daten geladen werden, wird jedoch in Vielfachen von Zweierpotenzen zugeteilt. Der Transfer der Daten wird damit entweder komplex, oder die (Nutz-)Daten werden im Hauptspeicher nicht mehr kontinuierlich abgelegt. Für das Schreiben der Daten aus dem Hauptspeicher in die Datei gilt sinngemäß das Gleiche.
Liste mit Zuordnungstabelle
Der eben erwähnte dritte Nachteil kann behoben werden, wenn die Zeiger auf den Nachfolgeblock nicht mehr im Block selbst, sondern in einer separaten Tabelle abgelegt werden. Die Nutzdatenblöcke sind damit wieder Vielfache der Sektorgröße. Die Verwaltungsinformationen werden von den Nutzdaten nun räumlich getrennt. Für jeden Block des Dateisystems gibt es in der Tabelle genau einen Eintrag. Dieser Eintrag verweist auf den (in der Datei) folgenden Block oder hat einen besonders ausgezeichneten Wert (beispielsweise FFFF), der das Ende der Datei kennzeichnet. Abbildung 10.9 zeigt die Zuordnungstabelle für die Datei aus Abbildung 10.8.

Abbildung 10.9: Datei als verkettete Liste mit Zuordnungstabelle
Wesentlich ist, dass es sich hierbei immer noch um eine verkettete Liste handelt; die verkettenden Zeiger werden nur separat abgelegt.
Die Fehlertoleranz des Verfahrens ist ebenfalls besser als in der vorangegangenen Variante. Es können leicht Kopien der Tabelle an physisch getrennten Orten auf dem Massenspeicher angelegt werden, sodass im Falle einer fehlerhaften Zuordnungstabelle (hervorgerufen beispielsweise durch Programmabsturz während eines Schreibzugriffes) einfach auf die Kopie(n) zurückgegriffen werden kann.
Die Geschwindigkeit sequenzieller Zugriffe ist etwas geringer als in der einfachen verketteten Liste, denn es muss zuerst die Zuordnungstabelle gelesen werden, bevor der Folgeblock eines Blockes selbst gelesen werden kann. Da die Blöcke einer Datei über die gesamte Zuordnungstabelle »verstreut« liegen können, erfordert dies unter Umständen Mehraufwand. Dafür werden wahlfreie Zugriffe im Vergleich beschleunigt, denn die kompakte Speicherung erleichtert das Durchsuchen der Tabelle.
Nachteilig ist die Abhängigkeit zwischen Länge der Zuordnungstabelle und der Anzahl logischer Blöcke. Je länger die Zuordnungstabelle ist, desto geringer ist die Wahrscheinlichkeit, sie vollständig im Hauptspeicher platzieren zu können (und damit Suchoperationen beträchtlich zu beschleunigen).
Die Firma Microsoft stattete insbesondere ältere Betriebssysteme (MS-DOS, Windows 95, Windows ME) mit Dateisystemen aus, die diese Form der Blockverwaltung verwenden. Die Tabelle wird in Microsoft-Terminologie »Dateizuordnungstabelle« oder englisch File Allocation Table (FAT) genannt, woraus sich der Name dieser Dateisysteme ableitet. Es gibt zahlreiche Varianten, von denen einige bei flashbasierten Speichermedien bis heute genutzt werden (VFAT, ExFAT).
Indizierte Speicherung
Eine andere Idee zur Realisierung eines Dateisystems besteht im indizierten Zugriff auf die Blöcke einer Datei. Hierbei werden die zu einer Datei gehörigen Blocknummern in sogenannten Indexblöcken abgelegt. Die Nummern der Blöcke, aus denen eine Datei besteht, werden einfach hintereinanderweg in die Indexblöcke geschrieben. Für jede Datei müssen die Adresse des ersten Eintrags im jeweiligen Indexblock sowie die Anzahl der Folgeeinträge gespeichert werden.
Vorteilhaft ist der nun recht einfache wahlfreie wie sequenzielle Zugriff auf die Blöcke der Datei. Im Gegensatz zur vorangegangenen Idee ist es ausgeschlossen, dass große Teile der Zuordnungstabelle durchsucht werden, um die einzelnen Dateiblöcke zu lokalisieren. Die Daten, die die Blockabfolge einer Datei beschreiben, sind streng sequenziell angeordnet und damit leichter zu verarbeiten.
Wie gestaltet man nun die Einträge in die Indexblöcke? Da die Dateien bekanntlich eine variable Länge aufweisen, wäre es offenbar günstig, die Indexblock-Einträge zur Beschreibung der Dateien ebenfalls variabel lang zu gestalten. Abbildung 10.10 zeigt ein Beispiel. Innerhalb eines Indexblocks ist der Eintrag für die Datei A vier Blocknummern lang, der für die Datei B zwei Einträge lang, ihm schließt sich unmittelbar der Eintrag für die Datei C an. Zwischen den Einträgen gibt es keine Lücken, sodass diese Lösung genauso speicherplatzeffizient ist wie die Dateizuordnungstabelle. Die Indizierungstabelle ist genauso lang wie die Dateizuordnungstabelle, es gibt jedoch nun pro Datei einen Eintrag, der variabel lang ist.

Abbildung 10.10: Speicherung mit variablen Indexblöcken
Leider handeln wir uns ein gar nicht so neues Problem ein: Was geschieht, wenn eine Datei verlängert oder verkürzt wird? Wir müssen nachfolgende Einträge gegebenenfalls umsortieren oder auch Lücken zulassen. Der Hauptnachteil der kontinuierlichen Allokation ist wieder da! Nun sind aber nicht die Datenblöcke betroffen, sondern die Indexblöcke, also die Daten, die die (Nutz-)Daten beschreiben. Für Letztere hat sich der Begriff Metadaten eingebürgert.
Was tun? Offensichtlich ist für die Indexeinträge ein Format variabler Länge doch nicht das Mittel der Wahl. Versuchen wir es also mit einem festen Format: Jedem Eintrag in der Indextabelle (also jeder Datei) ist eine feste Anzahl Blocknummern zugeordnet. Die Blocknummern haben entweder den Wert 0, was einen freien Block kennzeichnet, oder verweisen auf die Nummer der anzusprechenden Datenblöcke. Doch wie groß sollte die Anzahl Blocknummern gewählt werden? Setzen wir sie recht groß an, so laufen wir Gefahr, eine große Menge unbenutzter Blocknummern zu erhalten, die Indextabelle wird sehr speicherineffizient. Wählen wir sie knapp, dann beschränken wir die maximale Dateilänge in inakzeptabler Weise.
Beispiel: Das UNIX-Dateisystem
Wie man die im vorangegangenen Abschnitt aufgeworfenen Probleme bei indizierter Speicherung pragmatisch lösen kann, zeigt das klassische UNIX-Dateisystem, dessen Grundideen Sie im Folgenden kennenlernen werden.
Die zentrale Datenstruktur zur Verwaltung ist der sogenannte Inode, was sich von »Index-Knoten« ableitet. Zu jeder Datei gibt es genau einen Inode, in ihm sind alle Attribute bis auf den Dateinamen gespeichert sowie die Information, wo sich die zugehörigen Datenblöcke befinden.
Abbildung 10.11 zeigt die beteiligten Datenstrukturen beim Zugriff auf eine Datei. Der Inode befindet sich links oben. Er enthält zunächst die Attribute der Datei. Es folgt eine Anzahl (12 im ext2fs) Adressen von Datenblöcken, diese werden direkte Verweise genannt. Die verbleibenden drei Einträge im Inode haben folgende Funktion:
Der drittletzte Eintrag verweist auf einen kompletten Indexblock, dessen Einträge ihrerseits auf Datenblöcke verweisen. Es handelt sich somit um einen einfach indirekten Verweis im Inode. Der vorletzte Eintrag verweist ebenfalls auf einen kompletten Indexblock. Dessen Einträge verweisen jetzt aber nicht mehr auf Datenblöcke, sondern wiederum auf Indexblöcke, deren Einträge aber dann auf Datenblöcke verweisen. Dieser Eintrag im Inode wird doppelt indirekter Verweis genannt; er zeigt auf einen doppelt indirekten Block.

Abbildung 10.11: Eine Datei im UNIX-Dateisystem
Damit ist das Spiel aber noch nicht zu Ende, denn es gibt noch den letzten Verweis im Inode. Sie ahnen es bereits: Dieser wird dreifach indirekter Verweis genannt, denn er zeigt auf einen dreifach indirekten Block, dessen Einträge auf Indexblöcke verweisen, deren Einträge auf Indexblöcke verweisen, deren Einträge auf Datenblöcke verweisen. Alles klar?
Die Größenverhältnisse zwischen Inode, Index- und Datenblöcken sind aus Gründen der Darstellbarkeit in Abbildung 10.11 übrigens falsch dargestellt. Index- und Datenblöcke haben normalerweise eine identische Größe, und der Inode ist viel kleiner (beispielsweise 128 Byte im ext2-Dateisystem), sodass mehrere Inodes in Inode-Blöcken abgelegt werden, die dann wieder die allgemeine Blockgröße besitzen.
Um die etwas abenteuerliche Verwaltungsstruktur besser zu verstehen, versuchen wir, zunächst zu ermitteln, welche maximale Dateigröße möglich ist. Wir gehen von einer Blockgröße von 4 KiB und einer Anzahl von zwölf direkten Verweisen aus. Blocknummern sollen 32 Bit lang sein. Versuchen Sie es zunächst selbst, bevor Sie weiterlesen!
Mit den zwölf direkten Verweisen kann man genau zwölf Datenblöcke adressieren. Ein Indexblock kann insgesamt 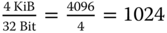 Blocknummern (Verweise) aufnehmen. Der einfach indirekte Verweis adressiert somit 1024 Datenblöcke, der doppelt indirekte zeigt auf
Blocknummern (Verweise) aufnehmen. Der einfach indirekte Verweis adressiert somit 1024 Datenblöcke, der doppelt indirekte zeigt auf 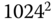 Datenblöcke, und der dreifach indirekte schließlich kann
Datenblöcke, und der dreifach indirekte schließlich kann 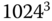 Blöcke adressieren. Insgesamt kann eine Datei also aus
Blöcke adressieren. Insgesamt kann eine Datei also aus
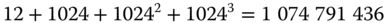
Datenblöcken zu je 4 KiB bestehen. Grob gerechnet ist also eine maximale Dateigröße von 4100 GiB möglich.
Man könnte nun auf die Idee kommen, die zwölf direkten Verweise im Inode einzusparen. Sie ermöglichen ja nur Dateigrößen bis zu 48 KiB, angesichts der gerade abgeschätzten maximalen Dateigröße ist das ein Witz. Sie haben aber eine wichtige Funktion. Stellen Sie sich vor, Sie wollen ein beliebiges Byte einer Datei lesen. Welcher Ablauf ist notwendig unter der Voraussetzung, dass der Inode sich im Hauptspeicher befindet?
Es kommt auf die Position des Bytes innerhalb der Datei an. Befindet sich diese innerhalb der ersten 48 KiB, dann kann man direkt den entsprechenden Datenblock lesen. Es ist also genau ein Zugriff nötig (man muss nur die Nummer des entsprechenden direkten Verweises ermitteln, also Position dividiert durch Blockgröße). Wenn das Byte irgendwo im Bereich des durch den einfach indirekten Verweis »abgedeckten« Bereiches liegt, dann sind zwei Blockzugriffe nötig: Erst muss der einfach indirekte Block gelesen werden, um die Nummer des Datenblocks herauszufinden, und dann muss auch noch der entsprechende Datenblock gelesen werden.
Liegt das gesuchte Byte noch weiter hinten, dann sind drei Zugriffe notwendig, und im Worst Case, nämlich wenn der dreifach indirekte Verweis ins Spiel kommt, dann sind sogar vier Blockzugriffe erforderlich, bis das Byte gelesen oder geschrieben wird. Wenn man nun die direkten Verweise und vielleicht auch noch den einfach indirekten einsparen würde, dann wären für jede Dateioperation drei oder vier Blockzugriffe nötig! Andersherum betrachtet sind durch die realisierte Struktur Zugriffe auf Dateien mit einer Größe von bis zu 48 KiB sehr schnell, und für Dateien zwischen 48 KiB und 4 MiB ist die Zugriffsgeschwindigkeit (zwei Zugriffe) immer noch recht akzeptabel.
Zusammengefasst bewirkt die Struktur des klassischen UNIX-Dateisystems
- schnellen Zugriff auf kleine Dateien,
- die Möglichkeit, sehr große Dateien anzulegen (mit größerer Dauer des Zugriffs).
Bereits vor langer Zeit hat man nämlich ermittelt, dass die allermeisten Dateien in einem typischen UNIX-Dateisystem ziemlich klein sind.
Fortgeschrittene Konzepte
Bedingt durch sich wandelnde Anforderungen, aber auch durch die kontinuierliche Weiterentwicklung der Speichermedien unterliegen auch Dateisysteme einer Fortentwicklung. In diesem Abschnitt lernen Sie einige Ideen und Aspekte von Dateisystemen kennen, die dabei eine Rolle spielen.
Extents
In den bis hierhin vorgestellten Dateisystemen wurden die Datenblöcke stets einzeln referenziert. Für sehr große Dateien zieht das erheblichen Speicherbedarf für die Metainformationen nach sich, wie folgendes Beispiel illustrieren soll.
Eine Datei umfasse 512 MiB. Bei einer typischen Blockgröße von 4 KiB sind das 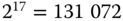 Blöcke. Wenn eine Blocknummer 48 Bit umfasst, dann benötigen die Indexinformationen für die Datei
Blöcke. Wenn eine Blocknummer 48 Bit umfasst, dann benötigen die Indexinformationen für die Datei 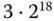 Byte, das sind 192 Blöcke. Beträchtlich, nicht wahr?
Byte, das sind 192 Blöcke. Beträchtlich, nicht wahr?
Wenn es Ihnen gelingt, die Datei in wenigen Regionen kontinuierlich aufeinanderfolgender Blocknummern abzulegen, dann können Sie die Indexinformationen auch viel kompakter ablegen.
Obige Datei solle in zwei gleich großen kontinuierlichen Blockregionen abgelegt werden, wie in Abbildung 10.12 dargestellt.

Abbildung 10.12: Beispiel für die Speicherung einer Datei mittels zweier Extents
Jede Region umfasst 65 536 Blöcke, eine startet bei Blocknummer 20, die andere bei Blocknummer 80 000. Zur kompletten Beschreibung der Datei benötigt man für jede Region deren Position innerhalb der Datei, die Nummer ihres Startblockes und ihre Länge (in Blöcken). Zusätzlich muss noch vermerkt werden, aus welchen Regionen die Datei besteht. Für diese Regionen hat sich in der Dateisystemtechnik der Begriff Extent etabliert.
Das Prinzip wird beispielsweise beim NTFS von Windows, wo der Extent Cluster Run genannt wird, und beim Linux-Dateisystem ext4 genutzt. Damit es effizient funktioniert, muss eine Fragmentierung der Dateiinhalte in viele kleine Extents unbedingt vermieden werden.
Log-strukturierte Dateisysteme
Um die Metadaten des Dateisystems schnell aufzufinden, werden diese bei konventionellen Dateisystemen stets an der gleichen Stelle auf dem Datenträger abgelegt. Dies gilt für die File Allocation Table bei FAT-basierten Dateisystemen genauso wie die Inode-Tabellen (die Datenstrukturen, die die Inodes enthalten) beim UNIX-Dateisystem.
Diese festen Adressen führen zu einer Vielzahl Seek-Operationen, da die Datenstrukturen sehr häufig konsultiert werden müssen (im Prinzip bei jeder Dateioperation). Aus Sicht des Nutzers sind diese Seek-Operationen unerfreulich, denn während der Schreib-/Lese-Kopf der Festplatte bewegt wird, können keine Daten übertragen werden, was sich negativ auf die Performance von Lese- und Schreiboperationen auswirkt.
Die Anzahl der Leseoperationen kann man durch extensives Caching einschränken. Wie könnte man aber vorgehen, um die Seeks, die durch Schreiboperationen verursacht werden, zu reduzieren? John Ousterhout und Mendel Rosenblum haben dazu 1991 eine radikale Idee formuliert: das sogenannte Log-strukturierte Dateisystem [22].
Die Grundidee ist ziemlich simpel: Schreiboperationen auf dem Datenträger sind strikt sequenziell. Das bedeutet, es wird stets dort weitergeschrieben, wo zuletzt geschrieben wurde, ganz im Stile eines Logbuchs. Sowohl die Nutzdaten (also die Dateien) als auch die Metadaten (beispielsweise die Inodes) werden auf diese Weise geschrieben. Wenn eine neue Datei geschrieben wird, landet diese im Log. Wird eine Datei modifiziert, dann werden die veränderten Blöcke ins Log geschrieben – stets an die Position, an der zuletzt geschrieben wird. Das Gleiche gilt für die Metadaten. Wird eine Datei verändert, dann müssen der Zeitstempel und die Größe im Inode angepasst werden. In einem konventionellen Dateisystem stehen die Inodes an festen Positionen, die beim Anlegen des Dateisystems vereinbart werden. Beim Log-strukturierten Dateisystem werden Inodes genauso in das Log geschrieben, wie normale Daten.
Damit das sequenzielle Schreiben auch effizient funktioniert, müssen sehr viele Schreiboperationen in einem Rutsch durchgeführt werden. Zu diesem Zweck dient das sogenannte »Write Buffering«. Die Schreibzugriffe werden zunächst im RAM in einem sogenannten Segment gesammelt und, sobald die Größe des Segmentes eine bestimmte Schwelle (einige Megabyte) überschreitet, hintereinanderweg in das Log auf dem Massenspeicher geschrieben.
Das fortlaufende Schreiben des Logs wirft noch ein zweites Problem auf: Was tut man, wenn man am Ende des Datenträgers angekommen ist? Es ist klar, dass innerhalb des Logs jede Menge veraltete Versionen der Daten existieren. Diese kann man entweder verwerfen, dann ist eine Art Garbage Collection nötig. Darunter versteht man eine Aktivität, die aktuelle von veralteten Daten unterscheiden kann, Letztere löscht und Erstere kompaktifiziert wieder ablegt. Oder man macht aus dem Problem ein Feature und bietet dem Nutzer Zugriff auf frühere Versionen der Dateien, wie dies Versionsverwaltungssoftware tut.
Die gebräuchlichen Dateisysteme unter Windows und unter Linux sind bislang nicht Log-strukturiert. Sie haben jedoch Anwendung bei Speichermedien gefunden, die auf Flash-Speicher basieren. Physikalisch bedingt kann jede Speicherzelle nur eine feste Anzahl an Schreiboperationen ausführen, danach ist sie defekt. Aus diesem Grunde müssen die Medien oder das Dateisystem sogenanntes Wear Leveling ausführen. Darunter versteht man Mechanismen, um Schreibzugriffe möglichst gleichmäßig auf alle Zellen des Mediums zu verteilen. Log-strukturierte Dateisysteme sind dafür ein idealer Ausgangspunkt, weil das fortlaufende Schreiben des Logs genau verhindert, dass manche Zellen viel und manche weniger häufig beschrieben werden.
Journaling
Ein wenig verwandt mit den Log-strukturierten Dateisystemen ist der Mechanismus des Journalings, den Sie in diesem Abschnitt kennenlernen. Um ihn zu verstehen, betrachten wir das Löschen einer Datei in einem Dateisystem. Zum Löschen sind mehrere Suboperationen notwendig:
- Die Datenblöcke der Datei müssen freigegeben werden.
- Der zugehörige Verzeichniseintrag muss gelöscht werden.
In Wahrheit sind noch mehr Operationen nötig: Denken Sie nur an den Inode, der ebenfalls gelöscht werden muss, oder an die notwendigen Manipulationen in der FAT.
Stellen Sie sich nun bitte vor, dass zwischen diesen beiden Suboperationen der Rechner versehentlich ausgeschaltet ist. Je nachdem, in welcher Reihenfolge diese ausgeführt werden, gibt es nun einen Verzeichniseintrag, der ins Nichts verweist, weil die zugehörigen Datenblöcke gelöscht wurden, oder es gibt belegte Datenblöcke, auf die kein einziger Verzeichniseintrag verweist. In beiden Fällen ist das Dateisystem inkonsistent geworden.
Diese Inkonsistenz wurde vor der Erfindung des Journalings durch Reparaturtools wie fsck (»file system check«) repariert. Dieses führt verschiedene strukturelle Tests über den Metadaten des Dateisystems aus. Da es aber keine Informationen über die zuletzt ausgeführten Operationen hat, muss das gesamte Dateisystem überprüft werden, was durch das kontinuierliche Kapazitätswachstum der Datenträger irgendwann zu inakzeptabel langen Wartezeiten führt (die Strukturprüfung und »Reparatur« des Dateisystems kann nicht während des normalen Betriebs vorgenommen werden).
Beim Journaling wird zunächst an einem definierten Platz auf der Festplatte (dem Journal) vermerkt, welche Modifikationen am Dateisystem vorgenommen werden. Dabei ist wichtig, dass der Eintrag im Journal mit einem Marker TA »Transaktion Anfang« beginnt und mit einem Marker TE »Transaktion Ende« abschließt. Abbildung 10.13 versucht, den Vorgang zu verdeutlichen.
Bis dahin wurde noch keine Änderung am Dateisystem vorgenommen! Dies geschieht nun im Schritt 2, dem sogenannten Checkpointing. Dabei werden die im Journal verankerten Operationen im Dateisystem durchgeführt. Nach Abschluss der Operation wird die Komplettierung der Operation im Journal vermerkt, und der Eintrag kann aus dem Journal gelöscht werden.
Was geschieht nun bei einem Systemcrash oder Stromausfall? Wenn dieser geschieht, solange der Eintrag ins Journal geschrieben wird, dann ist das Dateisystem ja noch in einem konsistenten Zustand, da keine Änderungen an ihm vorgenommen wurden. Der nicht komplettierte Eintrag im Journal wird gelöscht, und die Operation muss neu gestartet werden. Wenn hingegen der Ausfall während des Checkpointings geschieht, dann muss die entsprechende (komplette) Operation noch einmal durchgeführt werden, was problemlos möglich ist, denn sie steht ja noch im Journal. Im Beispiel müssen also noch einmal die Datenblöcke freigegeben werden, und der Verzeichniseintrag muss noch einmal gelöscht werden. Schließlich kann der Crash passieren, nachdem die Operation bereits komplettiert wurde, aber bevor die Komplettierung im Journal vermerkt wurde. In diesem Fall wird sie erneut ausgeführt, was aber nicht schlimm ist, es wird das Gleiche nur noch einmal geschrieben. Dies ist aber angesichts der Tatsache, dass Crashes (hoffentlich) ein sehr seltenes Ereignis sind, vertretbar.

Abbildung 10.13: Ein einfaches Beispiel zum Journaling
Journaling wird auch »Write-Ahead Logging« genannt und kommt in sehr vielen modernen Dateisystemen zum Einsatz. Dabei unterscheidet man, ob nur Operationen, die die Struktur des Dateisystems verändern, im Journal verankert werden oder auch Nutzdaten. Im letzteren Fall wird effektiv jeder einzelne Datenblock doppelt geschrieben (zuerst ins Journal und danach in die eigentliche Datei), was sich natürlich negativ auf die Performance auswirkt, aber nicht nur gegen strukturelle Fehler im Dateisystem schützt, sondern auch gegen Datenverlust.
Optimierung von Massenspeicherzugriffen
Sie wissen bereits, dass Massenspeichermedien im Vergleich zum Hauptspeicher um einige Größenordnungen langsamer arbeiten. Insbesondere bei Festplatten dauert es sehr lange, bis das Medium die angeforderten Daten zur Verfügung stellt (bei einer Leseoperation) oder bis die Daten auf dem Massenspeicher geschrieben wurden (bei einer Schreiboperation).
Es könnte also lohnend sein, Massenspeicherzugriffe zu optimieren. Dabei unterscheidet man wenigstens zwei verschiedene Herangehensweisen:
-
Man könnte das Layout der Daten auf dem Massenspeicher beeinflussen. Ein Beispiel wäre ein Storage-Server, der Videoströme enthält. Sinnvoll wäre hier, die einzelnen Blöcke eines Videos so anzuordnen, dass sie genau mit der Abspielgeschwindigkeit vom Massenspeicher gelesen werden, sodass kaum oder kein Pufferspeicher nötig ist.
Dieser Ansatz ist allerdings mit aktuellen Festplatten kaum zu realisieren, da es schwierig ist, die Platzierung der zu schreibenden Daten zu beeinflussen. Die Festplatte verbirgt viele der dafür notwendigen Informationen.
- Man könnte die einzelnen Aufträge an den Massenspeicher in geeigneter Weise umsortieren, um ein bestimmtes Optimierungsziel (beispielsweise die Maximierung des Durchsatzes, also der gelesenen oder geschriebenen Daten pro Zeit) zu erreichen. Dies hat sich in modernen Betriebssystemen unter dem Schlagwort I/O-Scheduling oder (etwas sperriger) Planen von Massenspeicherzugriffen etabliert.
I/O-Scheduling auf der Basis der Seek-Zeit
Es gibt nun eine ganze Reihe Verfahren zum Planen von Festplattenaufträgen, von denen Sie in den beiden folgenden Abschnitten die wichtigsten kennenlernen. Dabei ist unbedingt zu beachten, dass I/O-Scheduling in typischen Desktop- und Notebooksystemen, die interaktiv genutzt werden, einen sehr geringen Nutzen hat, da in diesen Systemen zu jedem beliebigen Zeitpunkt nur sehr wenige Massenspeicheraufträge existieren (wenn überhaupt), es damit also kaum etwas zu sortieren gibt.
Anders sieht es bei Servern aus, also Rechnern, deren vorrangiges Einsatzziel die Bereitstellung von großen Datenmengen ist, egal, ob in Form von Webseiten, Datenbanken oder Videos. Hier gibt es in der Regel stets eine Warteschlange mit potenziell vielen auszuführenden Festplattenoperationen, die wir nun nach Herzenslust umsortieren wollen.
Voraussetzung ist, dass kleine LBN auf kleine PBN abgebildet werden und große LBN auf große PBN. Das bedeutet, dass die Differenz zwischen zwei logischen Blocknummern einen ähnlichen Wert ergeben muss wie die Differenz der zugehörigen physischen Blocknummern. Dies ist im Allgemeinen der Fall. Gälte dies nicht, wäre eine Unterscheidung der »Entfernung« verschiedener Aufträge und damit eine gezielte Umsortierung unmöglich.
Historisch gesehen wurden zunächst nur die Seek-Zeiten für das I/O-Scheduling genutzt. Man ignorierte also die eigentlich ebenso wichtige Rotationslatenz komplett, weil diese sich permanent ändert: Während der Scheduler noch überlegt, diesen oder jenen Auftrag als Nächstes auszuführen, rotiert die Platte beständig weiter, und die Rotationslatenz aller betrachteten Jobs nimmt kontinuierlich ab – bis einer genau unter der Kopfposition hindurchzieht, in diesem Moment erhöht sich die Rotationslatenz dieses Auftrags um die Dauer einer Umdrehung.
Eingangsdaten, die sich permanent und dazu noch nicht linear ändern, sind ungünstig, somit entschied man sich, das Planen nur auf der Basis der Seek-Distanz auszuführen.
First Come First Serve (FCFS)
Im einfachsten (oder eher akademischen) Fall ordnet man alle Aufträge an die Festplatte in der Reihenfolge ihres Eintreffens und führt sie in dieser Reihenfolge aus. Dies hat den offensichtlichen Vorteil, dass jeder Auftrag garantiert ausgeführt wird. Sie werden bald sehen, dass dies keine Selbstverständlichkeit ist! Auch der Implementierungsaufwand ist sehr gering, es muss ja nichts implementiert werden.
Da kein Scheduling im engeren Sinne erfolgt, ist die Leistung dieses Verfahrens ansonsten bescheiden. Es existiert vor allem als Referenz, um den Leistungsgewinn der »richtigen« Verfahren zu bestimmen.
Shortest Seek Time First (SSTF)
Nomen est omen: SSTF wählt stets den Auftrag zur Bearbeitung aus, der, bezogen auf die Seek-Zeit, am nächsten an der aktuellen Kopfposition liegt. Dies sind natürlich Aufträge, die auf der gleichen Spur wie der vorangegangene Auftrag liegen oder auf dazu benachbarten Spuren. Nahe Aufträge werden vor entfernteren Aufträgen abgearbeitet.
Es hat sich gezeigt, dass dieses Verfahren zu einer starken Verbesserung des Durchsatzes (also der gelesenen/geschriebenen Datenmenge pro Zeit) im Vergleich zu FCFS führt. Wo viel Licht ist, ist allerdings auch viel Schatten. Bei SSTF ist es möglich, dass Aufträge niemals ausgeführt werden, sie verhungern, nämlich dann, wenn kontinuierlich neue Aufträge eintreffen, die relativ nahe an der aktuellen Kopfposition liegen und sich somit vor einen weit entfernten Auftrag »vordrängen« und diesen damit blockieren. Je weiter am »Rand« ein Auftrag liegt, desto größer ist diese Gefahr.
Elevator oder SCAN-Verfahren
Das Verhungern kann man verhindern, indem man sich an der Operation eines Personenaufzugs orientiert. Ausgehend von der aktuellen Kopfposition werden zunächst nur Aufträge bearbeitet, die in Richtung größerer Spurnummern liegen, wobei ebenfalls zunächst die nächstliegenden dran sind. Treffen neue Aufträge ein, die diesem Kriterium genügen, dann werden diese gleich mit erledigt. Irgendwann gibt es nur noch Aufträge mit kleinerer als der aktuellen Spurnummer, spätestens wenn der äußere Rand erreicht ist. Nun wird die allgemeine Bewegungsrichtung des Kopfes umgekehrt, es werden also nur noch Aufträge bedient, die kleinere Spurnummern besitzen, bis nur noch Aufträge mit größeren Spurnummern existieren. Danach beginnt das Spiel von Neuem. Bei diesem Muster wandert der Kopf langsam von innen nach außen und wieder zurück. Er scannt gewissermaßen die Oberfläche der Platte vollständig, daher der Name.
Ein Fahrstuhl arbeitet ähnlich, jedoch kennt er zwei verschiedene Typen von Aufträgen: »hinauf« und »hinunter«.
Durch die monotone Bewegungsrichtung des Kopfes wird die Lokalität von Aufträgen bei SCAN etwas schlechter ausgenutzt, somit resultiert häufig ein etwas geringerer Durchsatz als bei SSTF. Ein Verhungern von Aufträgen ist hingegen ausgeschlossen.
Jedoch ist auch SCAN nicht fair. Betrachten Sie einen kompletten Zyklus, der ganz außen beginnt. Zunächst werden alle Aufträge, die auf der ganz äußeren Spur liegen, abgearbeitet, dann diejenigen auf der zweitäußersten Spur und so weiter. Irgendwann werden die Aufträge auf den mittleren Spuren erreicht und abgearbeitet, danach diejenigen die auf den inneren Spuren liegen, und zuletzt die Aufträge auf der innersten Spur (sofern es Aufträge gibt). Legt man eine zufällige Verteilung aller Aufträge auf der Plattenoberfläche zugrunde (was eigentlich nicht realistisch ist), dann kann man von einer ungefähr gleichmäßigen Bewegung des Kopfes über die Spuren von außen nach innen und wieder zurück ausgehen. Für die Spuren in der Mitte der Plattenoberfläche kommt dabei der Kopf in regelmäßigen Abständen vorbei. Je weiter zum Rand eine Spur liegt, umso ungleichmäßiger werden die Bedienabstände: Im obigen Beispiel vergeht zunächst viel Zeit, bis eine relativ weit innen liegende Spur bedient wird, dann läuft der Kopf noch bis zur innersten Spur, kehrt die Richtung um und bedient die betrachtete Spur gleich noch einmal, und in dieser kurzen Zeitspanne liegt vielleicht gar kein neuer Auftrag für diese Spur vor! Danach dauert es wieder ewig, bis der Kopf wieder vorbeikommt. Man kann konstatieren, dass die Spuren desto ungleichmäßiger bedient werden, je weiter sie in Richtung Rand liegen.
Diesem Übel kann man mit einer Modifikation von SCAN abhelfen: Bezogen auf das oben stehende Beispiel erfolgt initial die Abarbeitung aller Aufträge von außen nach innen. Wenn der Schreib-/Lesekopf die innerste Spur, die noch einen Auftrag enthält, erreicht hat, wird der Kopf über alle Spuren wieder ganz nach außen gefahren, ohne Aufträge zu bedienen. Anschließend werden wiederum von außen nach innen Aufträge bedient. Dieses Verfahren wird CSCAN genannt. Es hat bedingt durch die »Leerfahrt« einen etwas schlechteren Durchsatz als SCAN, dafür ist es aus Sicht der Aufträge fair. Die Wartezeiten der Aufträge variieren weitaus geringer.
I/O-Scheduling unter zusätzlicher Einbeziehung der Rotationslatenz
Alle bisher betrachteten Verfahren haben gemeinsam, dass Sie nur die Seek-Zeit als Optimierungsparameter nutzen. Der Grund dafür ist, dass die Seek-Zeit eines Jobs konstant ist, da sie nur von der Spurnummer, auf der sich der gewünschte Zielsektor befindet, abhängt.
In Abschnitt »Ablauf einer Zugriffsoperation« haben Sie aber gelernt, dass es zwei Einflussfaktoren sind, die die Zeit für eine Festplattenoperation determinieren, die Seek-Zeit und die Rotationslatenz. Ein entsprechendes Verfahren lernen Sie im nächsten Abschnitt kennen.
Shortest Access Time First (SATF)
Als Zugriffszeit eines Auftrags sollen nun die Zeit für die Seek-Operation und die notwendige Rotationslatenz zugrunde gelegt werden. Dabei sind zwei Schwierigkeiten zu beachten:
- Während der Kopfbewegung rotiert die Platte weiter. Man kann also nicht einfach die Zeit für den Seek und die Zeit, bis der Sektor unter dem Kopf ankommt, addieren.
- Die Platte rotiert kontinuierlich, damit ändern sich die Rotationslatenzen aller Jobs kontinuierlich.
Die Ermittlung der Zugriffszeit ist nicht ganz trivial und soll an dieser Stelle nicht erläutert werden. Interessierte finden in [18] die notwendigen Informationen.
Ganz analog zu SSTF wird nun jeweils der Auftrag ausgeführt, dessen gegenwärtige Zugriffszeit am kleinsten ist. Da nun beide relevanten Parameter berücksichtigt werden, führt SATF in der Regel zu noch besserem Durchsatz als SSTF. Gleichzeitig ist die Gefahr für »weitab« liegende Aufträge (die eine verhältnismäßig große Zugriffszeit aufweisen), zu verhungern, noch einmal größer.
Optimum Access Time (OAT)
Haben wir nun das bestmögliche Verfahren gefunden? Mitnichten, denn es wurde beharrlich ein Fakt ignoriert. Wenn in einem System 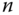 Festplattenaufträge vorliegen, dann wird der größte Durchsatz erzielt, wenn die Summe aller n Zugriffszeiten minimal wird. SATF als bislang bestes Verfahren führt jedoch immer nur den Auftrag mit der geringsten Zugriffszeit aus.
Festplattenaufträge vorliegen, dann wird der größte Durchsatz erzielt, wenn die Summe aller n Zugriffszeiten minimal wird. SATF als bislang bestes Verfahren führt jedoch immer nur den Auftrag mit der geringsten Zugriffszeit aus.
Warum löst man das Problem dann nicht exakt ein für alle Mal? Diejenigen Leser mit einschlägigem theoretischem Wissen haben wahrscheinlich längst erkannt, dass es sich beim I/O-Scheduling um eine Abwandlung des Problems des Handlungsreisenden (Traveling Salesman Problem) handelt. Dies bedeutet, dass eine exakte Lösung für eine größere Anzahl an Festplattenaufträgen einen sehr hohen Rechenaufwand erfordert, da es kein Verfahren gibt, das das Problem in polynomieller Laufzeit löst; es ist NP-schwer. Dazu kommt, dass sich die Eingangsparameter durch die kontinuierliche Rotation der Festplatte permanent ändern. Somit ist eine optimale Lösung für den allgemeinen Fall unmöglich. Zum Vergleich mit realen Verfahren wird es für kleine Probleme (wenig Aufträge) in der Literatur unter dem Namen Optimum Access Time (OAT) herangezogen.
Um NP-schwere Probleme in der Praxis zu lösen, nutzt man Heuristiken, das sind auf Erfahrungswerten basierende Näherungsverfahren. Diese finden keine optimale, sondern im Regelfall eine gute Lösung, und zwar in vertretbarer Zeit. SATF gehört dazu, es nutzt als Heuristik das sogenannte Nearest-Neighbour-Verfahren.
I/O-Scheduling in Linux
Zum Abschluss des Abschnittes soll wiederum der Blick in ein konkretes Betriebssystem, nämlich Linux, gewagt werden. Linux besitzt gleich mehrere I/O-Scheduler, die zur Laufzeit des Systems gewechselt werden können. Das ist eigentlich auch kein Wunder, sieht man die Vielzahl verschiedener Einsatzszenarien.
Der erste I/O-Scheduler im Linux-Kernel wurde – nomen est omen – Linus Elevator genannt und realisierte im Wesentlichen den SCAN-Algorithmus über allen Aufträgen.
Im praktischen Einsatz bemerkte man sehr bald, dass unter hoher Last manchmal Aufträge eine sehr große Wartezeit erleiden. Des Weiteren geschah es, dass Leseaufträge durch näher befindliche Schreibaufträge blockiert wurden; dieses Phänomen wurde »write-starving-reads« genannt. Es resultiert aus der Tatsache, dass Leseoperationen fast immer synchron erfolgen (der Prozess wartet mit seiner Arbeit, bis die Daten von der Festplatte gelesen wurden), während Schreibaufträge im Allgemeinen asynchron ausgeführt werden (der Prozess arbeitet sofort wieder, egal, wann die Daten geschrieben werden).
Ein I/O-Scheduler, der »write-starving-reads« zu verhindern versucht, wird deadline genannt. Er arbeitet prinzipiell wie das Elevator-Verfahren, vermerkt jedoch zusätzlich, wie lange jeder Auftrag auf Abarbeitung wartet. Überschreitet diese Wartezeit eine bestimmte Schwelle (»deadline«), dann werden diese Aufträge direkt abgearbeitet. Die Schwelle beträgt 500 ms für Lese- und 5 s für Schreibprozesse. Dieses Verfahren priorisiert somit Leseaufträge und verhindert für alle Aufträge sehr große Wartezeiten; der Durchsatz wird in diesem Falle jedoch verringert.
Ein weiteres wichtiges Verfahren wird cfq genannt. Das Kürzel cfq steht für Completely Fair Queueing. Die Grundidee besteht darin, allen Prozessen ein und derselben Priorität identische Zeit für die Durchführung von I/O-Operationen zuzugestehen. Fairness steht somit im Vordergrund. Dieses Verfahren ist in den meisten Distributionen für Festplatten voreingestellt.
Schließlich gibt es noop (»no operation«), das das FCFS-Verfahren realisiert.
I/O-Scheduling und SSDs
Wieso wurde die ganze Zeit nur von Festplatten, niemals jedoch von Solid State Disks (SSD) gesprochen? Nun, das liegt in deren Aufbau begründet. Die Dauer von Zugriffsoperationen auf SSDs hängt nicht von der Position des Zugriffs ab. Somit ist es sinnlos, auf Basis der Blocknummer eine Umsortierung von Aufträgen auszuführen.
Das heißt übrigens nicht, dass alle Zugriffsoperationen bei SSDs identisch schnell erfolgen. Technisch bedingt kann jede Speicherzelle eines Flash-Speichers nur endlich oft beschrieben werden (etwa 10 000- bis 100 000-mal), bevor sie ihre Funktionsfähigkeit verliert.
Deshalb ist es im Interesse einer langen Betriebszeit wichtig, dass das Medium alle Speicherzellen gleichmäßig nutzt. SSDs haben dafür sogenannte Wear-Leveling-Verfahren eingebaut, die verhindern, dass beim wiederholten Beschreiben ein und derselben Blocknummer stets derselbe physische Block beschrieben wird. Diese und andere in der Firmware des Mediums verborgenen Interna resultieren in einer Varianz der Dauer von Zugriffsoperationen, die für den Nutzer unvorhersehbar sind und damit nicht Grundlage für I/O-Scheduling sein können.
Für SSDs wird daher im Betriebssystem im Allgemeinen der FCFS-Scheduler eingesetzt.
Lesevorschläge
- Chris Ruemmler und John Wilkes. An introduction to disk drive modeling. In: IEEE Computer 27.3 (1994), S. 17–29. Wenn Sie mehr über den Aufbau und die Funktionsweise von Festplatten erfahren wollen, ist dieses leicht verständliche Paper das richtige für Sie.
- Ohad Rodeh, Josef Bacik und Chris Mason. BTRFS: The Linux B-Tree Filesystem. In: ACM Computing Surveys 9.3 (Aug. 2013), 9:1–9:32. DOI:
10. 1145 / 2501620.2501623. Der Artikel beschreibt ein ziemlich modernes Dateisystem, das mittlerweile viel unter Linux genutzt wird, jedoch auch nicht ganz unumstritten ist. Vorsicht, die Lektüre ist schwere Kost!
Übungsaufgaben
- Gegeben ist eine Datei, die aus
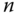 einfach verketteten Blöcken besteht. Wie viele Zugriffsoperationen (Lesen eines Blockes von Platte) werden benötigt, um die Datei vollständig
einfach verketteten Blöcken besteht. Wie viele Zugriffsoperationen (Lesen eines Blockes von Platte) werden benötigt, um die Datei vollständig- byteweise von vorn beginnend sequenziell zu lesen,
- byteweise von hinten beginnend umgekehrt sequenziell zu lesen?
-
- Wie groß muss jeder Eintrag in der Indextabelle mindestens sein, damit bei einer Blockgröße von 4 KiB Dateigrößen bis 128 MiB möglich sind?
- Wenn jede Blocknummer in 32 Bit abgelegt wird, welche maximale Größe des Dateisystems ist damit verwaltbar?
- Wie viel Speicherplatz wird in der Indextabelle mindestens verschwendet, wenn 90 % aller Dateien kleiner als 4 KiB sind und 10 000 Dateien angelegt wurden (Blocknummern umfassen 32 Bit)?
- Wie groß ist die Indextabelle?
- Erweitern Sie das Programm aus Listing 10.2, sodass es Unterverzeichnisse automatisch mit berücksichtigt.
-
Im Abschnitt »Ablauf einer Zugriffsoperation« haben Sie gelernt, dass man die Zeit zum Einlesen eines Blocks bei der Bestimmung der Dauer des Zugriffs vernachlässigen kann. Überprüfen Sie diese Behauptung für die folgende (reale) Festplatte, indem Sie die Zeit für das Einlesen eines Blockes auf der innersten und auf der äußersten Spur berechnen. Ermitteln Sie auch die rohe Leserate ohne Positionierzeiten.
Technische Daten: Rotationsgeschwindigkeit 7200 min−1, Anzahl Blöcke auf der äußersten Spur: 500, Anzahl Blöcke auf der innersten Spur: 229, Blockgröße: 4096 Byte.