Kapitel 11
Betriebssystem-Sicherheit
IN DIESEM KAPITEL
- lernen Sie, welche verschiedenen Arten von Schadcode es gibt,
- erfahren Sie, wie ein Stack-Overflow-Angriff funktioniert und was man dagegen tun kann,
- geht es im letzten Abschnitt um die Nutzerauthentifizierung, also um Mechanismen zur Unterscheidung zwischen berechtigten und unberechtigten Nutzern.
Eine Diskussion jeglicher Aspekte, die die Sicherheit von Betriebssystemen betreffen, liegt weit außerhalb dieses Buches. Andererseits kann man den Aspekt »Betriebssystem-Sicherheit« in einem einführenden Text nicht komplett außer Acht lassen. Aus diesem Grunde beschränken wir uns auf einige grundlegende Aspekte.
Grundbegriffe
Bevor Sie sich konkreten Aspekten von Schadcode und den dafür notwendigen Schwachstellen widmen, ist es nützlich, sich über die Notwendigkeit der Implementierung von Mechanismen zur Gefahrenabwehr in Betriebssystemen und die dabei verfolgten Ziele klar zu werden.
Ziele der Systemsicherheit
Zunächst muss der Begriff der Sicherheit ein wenig präzisiert werden. Es gibt nämlich drei verschiedene Schutzziele, von denen manchmal nur ein oder zwei, meist aber alle drei verfolgt werden. Konkret unterscheidet man in der Systemsicherheit drei sogenannte »Säulen«:
- Vertraulichkeit (confidentiality) – bestimmte Daten sind nur für einen ausgewählten Personenkreis (häufig nur für eine einzige Person) bestimmt.
- Integrität (integrity) – es muss verhindert werden, dass unautorisierte Schreibzugriffe Daten verfälschen.
- Verfügbarkeit (availability) – Angreifer versuchen, Dienste, Funktionen oder ganze Rechner so zu beeinträchtigen, dass sie nicht mehr für die Nutzer zur Verfügung stehen. Angriffe auf die Verfügbarkeit werden gern »Denial of Service« (DoS), also gewissermaßen »Dienstverhinderung«, genannt.
Angreifer versuchen also, die Vertraulichkeit, die Integrität und/oder die Verfügbarkeit bestimmter Daten oder Funktionen zu unterminieren. Die Motivation hierfür ist vielfältig, sie reicht von Selbstbestätigung über persönliche Rachemotive bis hin zu schnöder Gewinnerzielungsabsicht und der Durchsetzung wirtschaftlicher sowie politischer Interessen.
Ist Betriebssystem-Sicherheit überhaupt notwendig?
Ein einfaches Mittel, die Vertraulichkeit und die Integrität der Daten zu gewährleisten, sind die Rechte-Mechanismen von Mehrnutzerbetriebssystemen. Jeder Nutzer muss sich zuallererst authentifizieren, egal, ob er direkt vor dem System sitzt (also lokal arbeitet) oder sich per Netzwerk mit dem System verbindet. Er besitzt ein Nutzerkennzeichen sowie ein nur ihm bekanntes Passwort. Ist die Authentifizierung erfolgreich, stimmt also das eingegebene mit dem für diesen Nutzer registrierten Passwort überein, dann erhält er Zugang und kann anschließend mit dem System arbeiten. Er hat dabei jedoch im Allgemeinen nur Zugriff auf Ressourcen, die ihm zugeordnet sind, wie »sein« Homeverzeichnis sowie die darin befindlichen Dateien. Nach getaner Arbeit darf er nicht vergessen, sich abzumelden, weil ansonsten ein anderer Nutzer in seiner Rolle arbeiten könnte und Zugriff auf seine Daten hätte.
Prozesse verschiedener Nutzer sind über den virtuellen Speicher voreinander geschützt. Außer über wohldefinierte Schnittstellen wie die IPC-Mechanismen ist es für einen Prozess unmöglich, auf den Adressraum eines anderen Prozesses zuzugreifen.
Moderne Betriebssysteme bringen also »von Haus aus« eine ganze Menge Mechanismen zur Gewährleistung der Systemsicherheit mit. Ein Blick in einschlägige Medien wird Sie jedoch davon überzeugen, dass das nicht ausreicht. In diesem Kapitel erlernen Sie, welche sicherheitsbezogenen Dienste und Mechanismen (außer den bereits diskutierten) Betriebssysteme bieten, um ein möglichst hohes Maß an Sicherheit zu erreichen.
Insider versus Outsider
In der Sicherheitsforschung unterscheidet man zwei Kategorien von Bedrohungen: Die Mehrzahl der Angriffe werden typischerweise durch externe Personen, Systeme oder Organisationen ausgeführt (externe Bedrohung). Sie besitzen zunächst keine tiefergehenden Kenntnisse über die angegriffenen Systeme, sind aber in der Lage, sich diese unter Zuhilfenahme von bestimmten Werkzeugen und Techniken zu verschaffen.
Beim Insider-Angriff (interne Bedrohung) befindet sich der Feind gewissermaßen in den eigenen Reihen: Er ist beispielsweise ein Mitarbeiter des Unternehmens, der viele Kenntnisse, die der externe Angreifer zunächst mühselig erwerben muss, bereits besitzt. Er hat möglicherweise Zugang zu den den angegriffenen Systemen und muss »nur noch« die Mechanismen zur direkten Zugriffsbeschränkung umgehen. Eine effektive Verteidigung gegen Insider ist in der Regel viel schwieriger als eine gegen externe Angriffe.
Schadcode
In diesem Abschnitt sollen Sie einige Formen »bösartiger« Software (malicious software, kurz Malware) kennenlernen. Eine vollständige Übersicht oder eine saubere orthogonale Klassifizierung ist dabei unmöglich, da die Komplexität von Schadcode stetig zunimmt und historische Funktionalität gleich mit integriert. Beispielsweise installieren aktuelle Würmer häufig Rootkits und verwirklichen Hintertüren für späteren unautorisierten Zugang zum System.
Logische Bomben
Die einfachste und wahrscheinlich älteste Form bösartiger Software sind sogenannte Logische Bomben. Die einfache Idee besteht darin, eine Form destruktiver Software in einer Applikation oder im System zu verankern und deren Abarbeitung mit einer Bedingung zu verknüpfen. Dies kann das Erreichen eines bestimmten Datums oder das Verstreichen einer gewissen Frist sein oder ein speziell präpariertes von außen empfangenes Datenpaket. Logische Bomben sind typische Insider-Angriffe, gegen die sich Betriebssysteme kaum systematisch verteidigen können.
 David Tinley arbeitete als externer Programmierer für die Siemens-Niederlassung in Monroeville, Pennsylvania. Unter anderem entwickelte er Skripte für Tabellenkalkulationen, die für die Automatisierung der Bestands- und Auftragsverwaltung genutzt wurden. Diese funktionierten zunächst mehrere Jahre lang, produzierten dann aber ab 2014 sporadisch Fehler. Siemens wandte sich jedes Mal an Tinley, der den »Fehler« kostenpflichtig behob.
David Tinley arbeitete als externer Programmierer für die Siemens-Niederlassung in Monroeville, Pennsylvania. Unter anderem entwickelte er Skripte für Tabellenkalkulationen, die für die Automatisierung der Bestands- und Auftragsverwaltung genutzt wurden. Diese funktionierten zunächst mehrere Jahre lang, produzierten dann aber ab 2014 sporadisch Fehler. Siemens wandte sich jedes Mal an Tinley, der den »Fehler« kostenpflichtig behob.
Dies funktionierte etwa zwei Jahre lang. Siemens-Mitarbeiter kamen ihm auf die Schliche, als Tinley während einer längeren Abwesenheit das Superuser-Passwort des Systems einem Kollegen mitteilte, der prompt die Logische Bombe in Tinleys Skripten entdeckte, die den Fehler triggerte.
Tinley wurde zu immerhin sechs Monaten Gefängnis und einer Geldstrafe verurteilt.
Computerviren
Computerviren waren die wichtigste Schadcode-Kategorie in den 1980er- und 1990er-Jahren. Mittlerweile hat sich Ihre Bedeutung deutlich reduziert.
Ähnlich wie biologische Viren einen Organismus zum Überleben benötigen, ist für die Existenz eines Computervirus eine Wirtsdatei (Host, gewissermaßen der »Gastgeber der Virenparty«) notwendig, die zunächst »infiziert« werden muss. Viren sind also an die Existenz eines Dateisystems gekoppelt. Sie verstecken sich häufig in ausführbaren Dateien, die Programmcode enthalten, oder in bestimmten Regionen des Massenspeichers. Davon zu unterscheiden sind sogenannte Makroviren, die Dokumente der gängigen Office-Programme als Wirt nutzen.
Führt der Nutzer eine infizierte Datei aus, dann führt er nicht nur das eigentliche Binary aus, sondern zusätzlich (unwissentlich) den Code des Virus. Dieser besitzt die folgende Funktionalität:
- Replikation – das Virus muss sich verbreiten: neue Dateien aufsuchen und sich in ihnen »einnisten«.
- Tarnung – das Virus versucht, sich vor dem Nutzer und dessen System zu verbergen.
- Der eigentliche Schadcode – manchmal nur eine harmlose Animation oder ein Sound, manchmal bösartige Zerstörung von Daten auf dem Massenspeicher.
Bei der Replikation besteht für den Virus das Problem, infizierte von nicht infizierten Dateien zu unterscheiden, um Mehrfachinfektion ein und derselben Datei zu verhindern. Wird dies nicht getan, dann würden infizierte Dateien schnell an Größe gewinnen, was wiederum die Wahrscheinlichkeit der Entdeckung steigern würde. Dieser »Infektionsindikator« kann wiederum durch Anti-Viren-Software genutzt werden, um infizierte Dateien aufzuspüren.
Häufig wird zwecks Tarnung eine zeitliche Entkopplung von Infektionsvorgang und Ausführung der Schadroutine vorgenommen und der Infektionsvorgang künstlich verlangsamt. Aus mehreren Gründen sind Viren meist sehr klein (typisch sind wenige Hundert Bytes): Zum einen bieten die typischen Versteckmöglichkeiten wie Binärdateien und der Bootsektor der Festplatte nur sehr wenig Platz, zum anderen gilt die Regel »je kleiner, umso unauffälliger«.
Zur Zeit von MS-DOS und der ersten Windows-Versionen besaßen Computerviren die größte Bedeutung. Die Verbreitung erfolgte über den Tausch von Wechseldatenträgern wie Disketten, die infizierte Dateien enthielten. Wie bereits erwähnt wurde, ist MS-DOS ein Einnutzerbetriebssystem. Zudem besaß es keine Mechanismen zum Schutz des Systems vor dem Nutzer; entsprechend konnte die Schadfunktion häufig verheerenden Schaden anrichten. Dies war unter Windows eigentlich unmöglich, jedoch hatte sich alsbald die Unsitte eingebürgert, jegliche Arbeiten mit Administratorrechten auszuführen. Dabei versehentlich gestarteter Schadcode konnte somit wiederum prima seine Arbeit tun.
UNIX-Betriebssysteme (und mittlerweile auch moderne Varianten von Windows) blieben von Viren traditionell zum größten Teil verschont, da hier stets eine strikte Trennung der einzelnen Nutzer und der Systemdateien durchgesetzt wird. Viren können somit eigentlich nur die persönlichen Dateien des Nutzers angreifen, und mit Hilfe eines ordentlichen Backups sollten diese problemlos restaurierbar sein.
Häufig wird zur Installation spezieller Anti-Virus-Software geraten, es gibt jedoch eine Reihe von Gründen, die dies zumindest debattierbar machen:
Anti-Virus-Software kann nur Viren erkennen, die beim Hersteller bereits bekannt sind; sie hilft natürlich nicht gegen neue Viren. Aus diesem Grunde ist es zwingend erforderlich, die Signaturdatenbank, in der die charakteristischen Erkennungsmerkmale aller Viren abgelegt sind, permanent zu aktualisieren. Insbesondere ist der Hersteller dazu verpflichtet. Veraltete Signaturen sind wahrscheinlich schlechter als gar keine Anti-Viren-Software, denn sie gaukeln Sicherheit vor, die nicht besteht.
Darüber hinaus spricht man davon, dass Anti-Viren-Software die »Angriffsoberfläche« erhöht. Was bedeutet das? Wenn der Virenscanner nicht korrekt programmiert ist, dann kann das Virus versuchen, in ihm selbst einen Fehler zu provozieren und diesen auszunutzen. Dies klingt zunächst unwahrscheinlich, aber der Hersteller ClamAV musste beispielsweise im Jahre 2018 einräumen, dass infolge eines Programmierfehlers veraltete Versionen seines Scanners Denial of Service und sogar unautorisierte Codeausführung erlaubte.
Zu guter Letzt bedingt der Einsatz von Anti-Viren-Software gelegentlich Fehlalarme (sogenannte false positives). Das bedeutet, dass Dateien fälschlich als infiziert gemeldet werden. Der Virenscanner sucht typischerweise in Binärdateien nach charakteristischen Merkmalen von Viren. Treten diese zufällig in einer nicht infizierten Datei auf, dann wird diese natürlich trotzdem als »vermutlich infiziert« gemeldet. Der Nutzer muss nun manuell entscheiden, was zu tun ist. Diese manuelle Interaktion ist lästig und führt sehr schnell zum »Abstumpfen«: Der Virenalarm wird nicht mehr ernst genommen.
Die gegenüber früher deutlich verbesserten Sicherheitseigenschaften von Betriebssystemen sowie die kaum mögliche wirtschaftliche Verwertbarkeit einer Infektion mit Computerviren hat zu einer abnehmenden Bedrohung durch diese geführt. An ihre Stelle sind »Computerwürmer« getreten, die sich selbstständig über das Netzwerk von Rechner zu Rechner bewegen können.
Hintertüren
Eine weitere Kategorie Schadcode, die in Zusammenhang mit Betriebssystemen zu sehen ist, sind die sogenannten Hintertüren oder Backdoors. Darunter versteht man den Einbau nicht dokumentierter Schnittstellen in Software (hier also ins Betriebssystem) zwecks späteren (unautorisierten) Zugriffs auf das System. Die Zugriffssteuerung (Authentifizierung) wird damit umgangen.
Dies geschieht nicht immer mit bösartiger Intention. Entwickler komplexer Systeme bauen solche Schnittstellen manchmal ein, um sich zu Wartungs- und Diagnosezwecken ohne großen Aufwand mit dem System zu verbinden. Normalerweise werden diese Schnittstellen nach Fertigstellung entfernt, aber hin und wieder werden sie auch »vergessen«, sei es aus Nachlässigkeit oder aus Bequemlichkeit: Manchmal müssen auch nach Auslieferung eines Systems Änderungen und Aktualisierungen durch den Hersteller vorgenommen werden.
Gelingt es einem Hacker oder einer Schadsoftware, sich unautorisierten Zugang zu einem System zu verschaffen, dann installieren beide gern ebenfalls eine Hintertür, um den Zugriff auf das kompromittierte System zu vereinfachen und gegebenenfalls sogar zu automatisieren.
Ein berüchtigtes Beispiel für den Versuch, in die Linux-Kernelquellen eine Hintertür einzubauen, ist der Code in Listing 11.1. Er stammt aus dem Jahr 2003. Jemand hatte die beiden Zeilen in die Implementierung des Systemrufs wait4() eingeschmuggelt und zu diesem Zweck den Server, auf dem das Versionsverwaltungssystem für die Kernelentwickler lief, unter seine Kontrolle gebracht.

Listing 11.1: Versuchte Backdoor im Linux-Kernel
Auf den ersten Blick sieht der Code aus wie eine typische Parameterprüfung: Wenn bestimmte Optionen gesetzt sind und der Nutzer UID 0 besitzt, also root ist, dann wird der Fehlercode »EINVAL« (das steht für »Invalid Value«, also einen ungültigen Wert) zurückgeliefert. So weit, so gut. Wenn man ein bisschen in den Implementierungen der Systemrufe stöbert, findet man jede Menge ähnlicher Codezeilen.
Schaut man aber ganz genau hin, dann sieht man, dass der zweite Vergleich gar keiner ist, sondern eine Zuweisung! Es steht current->uid = 0 und nicht current->uid == 0! Man erwartet innerhalb des if-Statements keine Zuweisung, sondern einen Vergleich, darum überliest man einen solchen Fehler schnell.
Was tut der Code also tatsächlich? Wenn die Variable options einen der bezeichneten Werte hat, dann bekommt der rufende Nutzer die UID 0, er wird root. Danach schlägt der Systemruf fehl, indem er EINVAL zurückliefert. Zusammengefasst: Wenn man den (sehr selten verwendeten) Systemruf wait4() auf eine bestimmte, illegale Weise aufruft, dann schlägt dieser Ruf fehl, und der Rufer wird root! Damit hat er automatisch alle Rechte, er kann die Systemsicherheit beliebig kompromittieren. Eine klassische Hintertür! Das Prinzip wird manchmal »Cloaked Code« genannt, es ist gewissermaßen getarnter Code, der auf den ersten Blick anders aussieht, als er tatsächlich funktioniert.
Glücklicherweise sind einem aufmerksamen Code Reviewer diese beiden Zeilen aufgefallen, bevor sie in das Repository aufgenommen wurden. Das Beispiel illustriert den immensen Wert von Code Reviews, also dem kontrollierenden Lesen neu entwickelter Software. Der Urheber dieses Angriffs konnte leider nie entdeckt werden.
Eine andere Form der Hintertür sind Debugging-Schnittstellen, die bei der Entwicklung eingebetteter Systeme genutzt werden, um einen unkomplizierten Zugang zum System zu ermöglichen, der aus Bequemlichkeitsgründen häufig sogar die Authentifizierung umgeht. Diese Schnittstellen werden manchmal vergessen und manchmal »vergessen«, also bewusst im System belassen, um auch nach dessen Inbetriebnahme unkomplizierten Zugang für eventuelle Servicearbeiten wie das Update der Firmware zu gewährleisten.
Im Jahr 2016 fanden Sicherheitsanalytiker heraus, dass viele Internetkameras der Firma Sony über undokumentierte Nutzeraccounts verfügten. Damit war es möglich, von außen bestimmte Funktionen auszulösen und beispielsweise einen Telnet-Server zu starten. Des Weiteren existierte ein undokumentierter root-Zugang, mit dessen Hilfe die Kamera hätte komplett übernommen und einem Botnet hinzugefügt werden können.
Würmer
Würmer ähneln Computerviren in gewisser Weise, denn sie replizieren sich ebenfalls. Im Gegensatz zu Letzteren sind sie in der Lage, sich von Rechner zu Rechner über das Netzwerk zu verbreiten. Da dazu erheblich mehr Funktionalität erforderlich ist, sind Würmer nicht in der Lage, sich in Programmen oder Dateien zu verbergen. Würmer machen heutzutage den Großteil der Schadsoftware aus.
Würmer nutzen vielfältige Verbreitungswege. Wechseldatenträger gehören dazu, oder es werden gängige E-Mail-Programme wie Outlook genutzt, und der Wurm verschickt sich selbst an alle Einträge im Adressbuch des Nutzers.
Zur Funktionalität eines Wurms können die folgenden Komponenten gehören:
Aufklärung potenzieller Angriffsziele. Hat man erfolgreich einen Rechner eines Firmennetzwerkes angegriffen, dann kann man beispielsweise versuchen, den entsprechenden IP-Adressbereich durchzuprobieren, indem man an jede mögliche IP-Adresse ein ICMP-Datagramm schickt. Antwortet der Rechner, dann hat man ein weiteres Angriffsziel gefunden. Nun gilt es herauszufinden, welches Betriebssystem auf diesem läuft und welche Dienste in welcher Version. Dieser Vorgang wird OS-Fingerprinting genannt. Im Wesentlichen werden dabei spezielle Datenpakete an das Ziel geschickt und aus den Antworten Schlussfolgerungen bezüglich der auf dem Ziel laufenden Software gezogen.
Angriffscode. Wenn ein verwundbares Ziel entdeckt wurde, muss es kompromittiert und übernommen werden. Dazu benötigt man Code in Form sogenannter Exploits, die programmiertechnische Schwachstellen und Fehler in identifizierten Komponenten des Zielsystems ausnutzen. Wie dies genau geschieht, erlernen Sie etwas später in diesem Kapitel. Meist ist das Ziel, eine Shell zu starten, die über das Netzwerk mit dem Angreifer kommuniziert.
Etablierung verdeckter Kommunikationskanäle. Das erfolgreich angegriffene Ziel muss nun dauerhaft unter der Kontrolle des Angreifers bleiben. Im Gegensatz zum Virus erfolgt der Angriff nicht zum Selbstzweck, sondern man versucht, wirtschaftlichen Gewinn zu erzielen. Eine Form der »Verwertung« gekaperter Rechner besteht in der Vermietung als sogenanntes Botnet, das seinerseits wieder für illegale Aktivitäten wie dem Versenden von Spam-Mails oder zur Ausführung verteilter Denial-of-Service-Attacken genutzt werden kann. Damit der gekaperte Rechner ferngesteuert werden kann, müssen Kommunikationskanäle geschaffen werden, die dem rechtmäßigen Eigentümer verborgen bleiben. Dies erreicht man beispielsweise, indem man die Binärabbilder relevanter Systemkommandos wie ps oder netstat durch modifizierte Versionen ersetzt, die die an der verdeckten Kommunikation beteiligten Prozesse und Datenstrukturen nicht anzeigen.
Kommandoschnittstelle. Zur effizienten Kommunikation zwischen dem kompromittierten Rechner und dem Angreifer wird eine Schnittstelle geschaffen, die das Ausführen typischer Aufgaben erleichtert. So finden sich beispielsweise Funktionen für den Up- und Download von Dateien, für das Versenden von ICMP-Datagrammen und HTTP-Requests.
Zur Infrastruktur von Computerwürmern zählen noch weitere Komponenten, die nicht im Code des Wurms lokalisiert sind. Dazu zählt beispielsweise die Verwaltung der erfolgreich angegriffenen Rechner. Da Botnetze viele Millionen Systeme umfassen können, ist diese Aufgabe keineswegs trivial. Da wir damit langsam, aber sicher den Bereich der Betriebssystem-Sicherheit verlassen, soll an dieser Stelle nicht weiter darauf eingegangen werden.
 Der Morris-Wurm
Der Morris-Wurm
Computerwürmer existieren schon seit geraumer Zeit. Einer der ersten bekannten war der nach seinem Programmierer benannte Morris-Wurm, den dieser 1988 nach eigenen Angaben versehentlich freisetzte. Durch einen Implementationsfehler replizierte er sich viel schneller als ursprünglich intendiert. Er nutzte verschiedene Sicherheitslücken aus, versuchte auch, Nutzerpassworte zu ermitteln, und infizierte nach Schätzungen etwa 10 % der das Internet konstituierenden Hosts [2]. Obwohl er über keine expliziten Schadroutinen verfügte und somit möglicherweise nur als Informatikexperiment angesehen werden kann, über das der Autor die Kontrolle verlor, verursachte seine Bekämpfung, Eliminierung und Analyse einen horrenden wirtschaftlichen Schaden. Folgerichtig wurde Robert T. Morris zu einer Bewährungs- und Geldstrafe verurteilt; Schadenersatz blieb ihm immerhin erspart. Das Dasein als »Straftäter« hat ihm übrigens nicht nachhaltig geschadet: Er hat seit 2006 eine Professur am renommierten Massachusetts Institute of Technology (MIT) inne.
Einige der bekannteren Würmer sind der Morris-Wurm (siehe Kasten), Conficker [12] und Stuxnet, der sehr wahrscheinlich zur Sabotage iranischer Nuklearzentrifugen eingesetzt wurde.
Trojaner
Eine weitere Kategorie Schadsoftware wird umgangssprachlich »Trojaner« genannt. Dabei handelt es sich um Code, den der angegriffene Nutzer versehentlich ausführt und mit dem er dem Angreifer sprichwörtlich die Tür öffnet, indem er Sicherheitsmechanismen unwissentlich deaktiviert, einen Nutzer mit bekanntem Passwort anlegt und dergleichen mehr.
Der Begriff »Trojaner« ist eigentlich irreführend; gemeint ist eigentlich das Trojanische Pferd, in dessen Bauch sich Griechen versteckten, um des Nachts die Stadttore Trojas den griechischen Truppen zu öffnen. Die armen Trojaner würden sich ob der falschen Verwendung Ihrer Ethnie sicherlich beim zuständigen UN-Gremium beschweren, wenn es sie denn noch gäbe.

Listing 11.2: Ein simpler Trojaner in Bash
Listing 11.2 zeigt ein (sehr) simples Beispiel für ein »trojanisches Shellskript«. Stellen Sie sich vor, es gelingt einem Angreifer, dieses Skript unter dem Namen ls im System so zu verankern, dass es anstelle des regulären ls-Kommandos ausgeführt wird. Nun ruft ein argloser Nutzer dieses Skript irrtümlich auf. Was geschieht?
Zunächst kopiert es den Programmcode der Standard-Shell, die stets installiert ist, ins Verzeichnis /tmp, auf das jeder Nutzer Zugriff hat. Es erhält den Dateinamen .xxsh, der beim normalen ls-Kommando nicht angezeigt wird, es wird zumindest ein bisschen versteckt. Das chmod-Kommando setzt zum einen mit dem Argument u+s das sogenannte SetUID-Bit der Datei, das Sie bislang noch nicht kennen (zumindest kam es in diesem Buch noch nicht vor). Es bewirkt, dass der resultierende Prozess nicht mit der ID (und den Rechten) desjenigen, der das Programm gestartet hat, ausgeführt wird, sondern mit den Rechten des Eigentümers der Datei. Wie Sie sich leicht überzeugen können, gehört /bin/sh genauso wie jede Kopie davon root, also würde der zugehörige Prozess mit den Rechten von root (also mit allen Rechten; man spricht von einer sogenannten root-Shell) gestartet. Zum Zweiten erhält durch das Argument o+x jeder Nutzer des Systems das Recht, die Datei auszuführen. Das bedeutet nichts weniger, als dass jeder Nutzer nun plötzlich als root arbeiten kann, vorausgesetzt, er weiß, wo sich diese Shell befindet.
Der Rest des Skriptes dient dazu, die Spuren des Angriffs so gut wie möglich zu verwischen. Das rm-Kommando löscht das verräterische Skript, also die Kopie von /bin/ls. Zu guter Letzt wird noch das »richtige« ls-Kommando ausgeführt, damit der Nutzer keinen Verdacht schöpft.
Der Trojaner legt also eine root-Shell unter verstecktem Namen in das Verzeichnis /tmp und löscht sich nach getaner Arbeit. Der Angreifer kann mit dieser Shell das System somit komplett übernehmen.
Das Beispiel ist wiederum vereinfacht. Zum einen werden für den chmod-Befehl selbst die Rechte von root benötigt, so dass der Trojaner nur beim Administrator selbst überhaupt funktioniert. Zum anderen ist das Ablegen des Trojaners unter falschem Namen eine schwierige Aufgabe, die ihrerseits ebenfalls root-Rechte erfordert. Zum Dritten besitzt die Shell einen eingebauten ls-Befehl, der normalerweise stets Präzedenz über das ebenfalls vorhandene externe ls-Kommando besitzt.
Das Beispiel dient nur der Veranschaulichung der prinzipiellen Funktionsweise eines Trojaners. Richtige Trojaner arbeiten viel, viel sophistischer. Ihre Diskussion würde jedoch den Rahmen dieses Buches sprengen.
Ransomware
Eine besonders perfide Form von Computerwürmern ist die in den letzten Jahren stark in Mode gekommene Ransomware. Sie wird sowohl per Trojaner als auch per Wurm verbreitet. Die Schadfunktion besteht darin, das Dateisystem des angegriffenen Systems kryptografisch sicher zu verschlüsseln und dann dem Eigentümer zu erpressen. Bezahlt er einen gewissen Geldbetrag, dann erhält er den Schlüssel zur Entschlüsselung der Daten. Lehnt er die Zahlung ab, dann bleibt der Datenträger verschlüsselt. Eine Wiederherstellung der Daten ist bei korrekter Implementierung im Allgemeinen unmöglich.
Ein beliebtes Ziel von Ransomware-Angriffen sind Einrichtungen des Gesundheitswesens, da die dort lagernden Daten ungeheuer wichtig sind.
Die Existenz elektronischer Währungen wie Bitcoin und Ethereum hat wesentlich zu Verbreitung dieser Form von Schadsoftware beigetragen. Eine wichtige Gegenmaßnahme besteht in der Einrichtung von Backup-Mechanismen für alle relevanten Daten. Petya, WannaCry und Locky sind konkrete Beispiele aus den letzten Jahren.
Stack Overflow
Einer der ersten und beliebtesten Eintrittsvektoren für Schadsoftware ist ein überlaufender Stack. Um diese Schwachstelle zu verstehen, ist zunächst eine knappe Zusammenfassung des Funktionsprinzips vonnöten, bevor Sie erlernen, wie dieser überlaufen kann und was von Seiten des Betriebssystems dagegen getan werden kann.
Der Stack
In diesem Abschnitt lernen Sie Aufbau und Funktionsweise des Stack (auch: Stapelspeicher) kennen.
Grundprinzip
Um zu verstehen, wie Schadcode in ein System eingeschleust werden kann, müssen Sie gegebenenfalls noch einmal einen Blick auf das Speicherlayout eines Prozesses werfen, das Sie im Kapitel 9 »Hauptspeicher (RAM)« kennengelernt haben. Sie können sich hoffentlich noch an dessen drei wesentliche Bestandteile erinnern:
- das Codesegment, das, wie der Name bereits verrät, den Programmcode enthält,
- das Datensegment, das die initialisierten sowie die nicht initialisierten globalen Daten des Prozesses sowie den Heap aufnimmt,
- und das Stacksegment, das für die Ablage von Daten begrenzter Lebensdauer gedacht ist.
Während Code- und Datensegment einigermaßen statisch organisiert sind, ändert sich am Stack laufend irgendetwas. Gleichzeitig ist das Stacksegment potenzieller Eintrittspunkt für Angriffe mittels eines sogenannten Stacküberlaufs (Stack Overflow), einer der häufigsten Angriffsformen. Diese sollen Sie durch die folgenden Abschnitte erlernen, um danach verstehen zu können, wie moderne Betriebssysteme sich dagegen zur Wehr setzen.
Das Funktionsprinzip eines Stacks ist eigentlich ziemlich simpel, die Bezeichnung »Stack« deutet schon darauf hin. »Stack« heißt im Deutschen »Stapel«, und so funktioniert er auch: Man kann stets nur das oberste Element entfernen oder auf dieses ein weiteres Element drauflegen. Möchte man »weiter unten« liegende Elemente referenzieren, so müssen zunächst die darüber liegenden entfernt werden. In der Informatik wird dieses Prinzip »LIFO« genannt, Last In First Out; was man zuletzt hinein getan hat, kommt als Erstes wieder raus.
Der wichtigste Unterschied zu realen Stapeln besteht darin, dass der Stack im Rechner in Richtung kleinerer Adressen wächst, also gewissermaßen nach unten. Mit physischen Stapeln ist dies infolge der Gravitationswirkung ziemlich schwierig.
Um das oberste Element zu referenzieren, nutzt man ein eigens dafür reserviertes Register, den sogenannten Stack Pointer (SP). Dieser zeigt stets auf die oberste Stackadresse (»Top of Stack«, TOS), also die kleinste Adresse, die zum Stack gehört.
Push- und Pop-Operation
Für den Zugriff auf den Stack existieren normalerweise zwei Operationen: Mittels »Push« wird ein Operand auf dem Stack abgelegt (der Stapel wächst also um ein Element), und mittels »Pop« wird das zuoberst befindliche Element zurückgeliefert.
Der Befehlssatz der CPU umfasst stets eine Push-Operation, die zunächst den Stack Pointer dekrementiert und danach den übergebenen Operanden auf die durch den Stack Pointer referenzierte Adresse schreibt.
Jedes Mal, wenn eine Funktion oder eine Prozedur betreten wird, wird auf dem Stack ein gewisser Platz reserviert: Es wird ein sogenannter Stack Frame für diese Funktion ausgefasst. Wird die Funktion verlassen, dann wird der für sie reservierte Stack Frame wieder freigegeben.
Abbildung 11.1 soll diesen Vorgang verdeutlichen. Sobald die main()-Funktion eines Programms aufgerufen wird (also bei dessen Start), wird der zugehörige Stack Frame auf dem Stack angelegt. Im Wesentlichen enthält er Platz für die Rücksprungadresse und die lokalen Variablen der Funktion. Wenn nun innerhalb von main() eine andere Funktion gerufen wird, wie im Beispiel die Funktion foo(), dann wird der nächste Stack Frame (in Abbildung 11.1 der mittlere) auf dem Stack ausgefasst. Dies geschieht bei jedem Aufruf einer Funktion, auch wenn wie im Beispiel die Funktion sich selbst aufruft, denn jede Instanz besitzt ihren eigenen Stack Frame. Jeder Frame enthält die Werte aller lokalen Variablen, die der Funktionsinstanz zugeordnet sind. Der oberste Stack Frame (der mit der niedrigsten Adresse) ist der gegenwärtig abgearbeiteten Funktion zugeordnet; die darunter abgelegten Frames sind inaktiv.

Abbildung 11.1: Stack Frames für jeden Funktionsaufruf
Der Stack Frame einer Funktion existiert also, solange diese Funktion noch nicht komplettiert und damit verlassen wurde. Es verwundert nicht weiter, dass alle Daten, die irgendwie mit dieser Funktion zu tun haben, gespeichert werden. Dies sind oder können sein (Rechnerarchitekturen unterscheiden sich häufig in diesem Aspekt):
- Argumente, die der Funktion übergeben werden,
- alle lokalen Variablen der Funktion,
- die Rückkehradresse.
Während es unmittelbar vernünftig erscheint, Argumente und lokale Variablen auf dem Stack abzulegen, ist dies bei der Rückkehradresse nicht unbedingt der Fall. Was soll man sich überhaupt darunter vorstellen? Das erlernen Sie im folgenden Abschnitt.
Der Call-Return-Mechanismus
Wenn im Programmtext eine Funktion aufgerufen wird, dann bedeutet das für den Programmfluss zunächst einen Sprung, nämlich zum Code der Funktion. Für eine gewisse Weile verbleibt die Ausführung innerhalb der Funktion. Irgendwann jedoch wird die Funktion wieder verlassen (ansonsten würde es keinen Sinn ergeben, überhaupt eine Funktion zu nutzen). In C geschieht dies, wenn entweder ein return-Statement oder die schließende Klammer des Funktionsblocks erreicht wird.
Wo soll nun weitergearbeitet werden? Na klar, an der auf den Funktionsaufruf folgenden Anweisung. Damit das reibungslos funktioniert, hebt man sich deren Adresse unmittelbar vor dem Sprung auf, und zwar auf dem Stack: Es handelt sich um die bereits im vorangegangenen Abschnitt erwähnte Rückkehr- oder Rücksprungadresse.
Wahrscheinlich jede Maschinenarchitektur stellt zu diesem Zweck den sogenannten Call-Return-Mechanismus in Form zweier Maschineninstruktionen zur Verfügung. In der Intel-Architektur sind es die Instruktionen call und ret.
Wenn die CPU auf eine Instruktion call <adr> trifft (als Operand wird die Adresse der anzuspringenden Funktion angegeben), dann passiert Folgendes:
- Der Stack Pointer wird dekrementiert.
- Der Inhalt des Registers Instruction Pointer, das ist die Adresse der auf den
callfolgenden Instruktion, wird auf die Adresse geschrieben, auf die der Stack Pointer nun verweist. - Die Abarbeitung setzt an Adresse
<adr>fort (also am Funktionskörper).
Nun werden die einzelnen Instruktionen innerhalb des Funktionskörpers abgearbeitet, und es ist natürlich ebenso möglich, dass innerhalb der Funktion eine weitere Funktion mittels call gerufen wird. Irgendwann wird aber einmal ein ret erreicht. Nun geschieht gewissermaßen das Gegenteil des obigen Ablaufs:
- Das oberste Element des Stacks (das ist die Speicherzelle, auf die der Stack Pointer momentan zeigt) wird in den Instruction Pointer übernommen; das ist die oben abgelegte Rücksprungadresse.
- Der Stack Pointer wird inkrementiert.
- Die Abarbeitung wird an der im Instruction Pointer abgelegten Adresse fortgesetzt, das ist die auf den
callfolgende Instruktion.
Dieser Ablauf geschieht bei jedem Funktionsaufruf. Es ist unmittelbar einsichtig, dass die Rückkehradresse nicht verändert werden darf, sonst springt man nicht an den Ausgangspunkt zurück, sondern an einen ganz anderen Ort. Genau dies ist das Ziel des Angreifers!
Stack Overflow
Wie erfolgt nun die (bösartige) Manipulation der Rücksprungadresse? Schauen Sie bitte dazu Listing 11.3 an.

Listing 11.3: Ein verwundbares Programm
Wie funktioniert dieses Programm? Wenn mindestens ein Kommandozeilenparameter übergeben wurde, dann wird die Funktion vuln() aufgerufen, und der erste Parameter, der an der Kommandozeile übergeben wurde, wird an diese Funktion gewissermaßen weitergereicht. Wurde kein Parameter an main() übergeben, endet das Programm sofort.
In der Funktion vuln() gibt es zwei lokale Variablen: ein Feld passwort, das aus genau 10 Bytes besteht (und mit einer der beliebtesten Passphrasen initialisiert ist), sowie ein nicht initialisiertes Feld buf der Länge 128 Byte.
Die Funktion kopiert nun mittels strcpy() die als Argument übergebene Zeichenkette in buf und gibt danach den Inhalt von buf und passwort auf der Konsole aus. Die Funktion endet, springt in main() zurück, und das gesamte Programm endet.
Übersetzen Sie bitte das Programm, und probieren Sie es aus, etwa so:
robge@sorpen:∼/os4dummies/master/prg$ gcc -Wall -o bo bo.crobge@sorpen:∼/os4dummies/master/prg$./bo “Kilroy was here.”Puffer: Kilroy was here.Passwort: 12345678
Scheint zu funktionieren! Das Kommandozeilenargument wird in buf übertragen; die Ausgabe beider Variablen ist korrekt. Wo sollte hier also das Problem sein?
Dazu stellen Sie sich vor, die Programmabarbeitung hielte in vuln() nach dem strcpy()-Aufruf. Abbildung 11.2 zeigt ein schematisches Abbild des Stacks genau zu diesem Zeitpunkt.

Abbildung 11.2: Stack-Layout während der Ausführung von bo
Die beiden Register Frame Pointer FP und Stack Pointer SP begrenzen den Stack Frame der Funktion vuln(). In Richtung wachsender Adressen gelesen befinden sich in ihm die beiden Felder buf und passwort, die Inhalte der potenziell durch die Funktion genutzten Register sowie der gesicherte Frame Pointer (SFP) der übergeordneten Funktion main(). Unmittelbar dahinter ist die Rückkehradresse abgelegt, zu der gesprungen wird, wenn vuln() verlassen wird.
Es spricht allerdings nichts dagegen, an der Kommandozeile ein Argument zu übergeben, das länger als die reservierten 128 Byte ist. Versuchen Sie dies einmal:
robge@sorpen:∼/src/os4d$./bo 'perl -e 'print "a"x134,''Passwort!Puffer: aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaPasswort!Passwort: Passwort!
Nun, dies ist in mehrerlei Hinsicht erklärungsbedürftig. Dem Programm wird als Argument eine 143 Zeichen lange Zeichenkette übergeben, die aus 134 Exemplaren des Buchstabens 'a' und der unmittelbar angehängten Phrase »Passwort!« besteht. Um Schreibaufwand zu sparen, werden die 134 Buchstaben 'a' durch einen perl-Einzeiler generiert. Dieser wird durch den Eval-Operator der Bash zuerst ausgeführt, und danach wird ./bo mit dem Ergebnis aufgerufen.
Nun läuft also bo mit einem potenziell zu großen Argument (es passt nicht mehr in den Zielpuffer buf), und es gibt in C auch keinen Mechanismus, der die Größe einer Datenstruktur prüft. Was geschieht? Die Funktion strcpy() kopiert brav Byte für Byte von der Adresse, auf die in zeigt (das ist der Puffer, der das Kommandozeilenargument enthält), in den lokalen Puffer buf. Wenn dieser gefüllt ist, arbeitet strcpy() einfach weiter, denn der Kopiervorgang ist noch nicht abgeschlossen. Damit wird nun die oberhalb liegende lokale Variable passwort in Mitleidenschaft gezogen und ihr Wert mit »Passwort!« überschrieben. Es resultiert die in Abbildung 11.3 gezeigte Situation.
In der gezeigten Konfiguration ist es also möglich, in Richtung höherer Adressen benachbarte Variablen eines Puffers zu manipulieren. Der Grund dafür ist, dass die Funktion strcpy() das ihr übergebene Argument auf die Zieladresse kopiert, egal, ob dort genügend Platz ist oder nicht. Das Problem ist sogar noch schlimmer, denn es kann alles, was in Richtung höherer Adressen liegt, manipuliert werden, vorausgesetzt, die für den Überlauf genutzten Daten sind ausreichend lang. Zum einen ist es möglich, die beim Eintritt in die Funktion angelegten Sicherheitskopien der Registerinhalte zu verfälschen. Zum anderen könnte man den gesicherten Frame Pointer der übergeordneten Instanz (hier: die Funktion main()) verbiegen, aber am allerinteressantesten ist natürlich die unmittelbar darüber abgelegte Rückkehradresse!
Beim Verlassen der Funktion bewirkt der Call-Return-Mechanismus, dass die auf dem Stack abgelegte Rückkehradresse in den Instruction Pointer übertragen wird und die Abarbeitung an dieser Adresse fortgesetzt wird. Durch den Pufferüberlauf ist ein Angreifer nun in der Lage, anstelle der ursprünglichen Rückkehradresse eine völlig andere Adresse abzulegen und diese entsprechend anzuspringen. Er kann somit direkt den Kontrollfluss des Programms verändern.

Abbildung 11.3: Stack-Layout nach Kopieroperation mit zu langem Argument
In realen Systemen sind solche potenziellen Pufferüberläufe natürlich nicht so offensichtlich. Es gibt außer strcpy() noch weitere C-Funktionen, die keine Längenprüfung ihrer Argumente vornehmen, beispielsweise strcat(), gets() und getpw(). Erstmals beschrieben wurde diese Form eines Angriffes im klassischen Aufsatz Smashing the Stack for Fun and Profit [1].
Gegenmaßnahmen
Gegen diese und andere Angriffe wurden eine ganze Menge Maßnahmen entwickelt, die unterschiedliche Wirksamkeit aufweisen. Einige sollen in den folgenden Abschnitten beschrieben werden.
Verzicht auf unsichere Funktionen
Eine naheliegende Möglichkeit besteht darin, auf die Nutzung unsicherer Funktionen generell zu verzichten. Beispielsweise könnte man anstelle des unsicheren strcpy() die Funktion strncpy() einsetzen. Diese übernimmt einen zusätzlichen Parameter 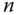 , der die maximale Länge der zu kopierenden Zeichenkette enthält. Wenn die Länge der Quellzeichenkette diese Maximallänge
, der die maximale Länge der zu kopierenden Zeichenkette enthält. Wenn die Länge der Quellzeichenkette diese Maximallänge 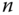 überschreitet, dann bricht der Kopiervorgang nach
überschreitet, dann bricht der Kopiervorgang nach 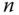 Zeichen ab. Somit ist ein Pufferüberlauf wirksam unterbunden, vorausgesetzt,
Zeichen ab. Somit ist ein Pufferüberlauf wirksam unterbunden, vorausgesetzt, 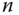 übersteigt nicht die Länge der Zielzeichenkette. Zu allen unsicheren Funktionen gibt es jeweils eine sichere »Ersatz«funktion; die wichtigsten führt Tabelle 11.1 auf.
übersteigt nicht die Länge der Zielzeichenkette. Zu allen unsicheren Funktionen gibt es jeweils eine sichere »Ersatz«funktion; die wichtigsten führt Tabelle 11.1 auf.
unsicher |
sicher |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Tabelle 11.1: Unsichere C-Funktionen und ihre sicheren Pendants
Allerdings hat die Nutzung von strncpy() auch wieder einen Pferdefuß. Bedingt durch diesen »Abbruchmechanismus« kann es nun nämlich passieren, dass die Zielzeichenkette nicht mehr nullterminiert ist, und zwar genau dann, wenn die Quellzeichenkette mindestens 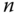 Zeichen lang ist. Man muss also nach dem Aufruf von
Zeichen lang ist. Man muss also nach dem Aufruf von strncpy() prüfen, ob der Kopiervorgang bis zum terminierenden Nullbyte ausgeführt oder vorzeitig abgebrochen wurde, und im letzteren Fall die Zielzeichenkette nachträglich nullterminieren. Dies ist mindestens mühselig und kann natürlich auch zu weiteren Fehlern führen, wenn es vergessen wird. Häufig werden als Gegenargument auch vermeintliche oder tatsächliche Performance-Nachteile der sicheren Funktionen ins Felde geführt. Nicht zuletzt ist es auch in bereits entwickeltem Quellcode (»Legacy Code«) häufig sehr schwierig, die genutzten (unsicheren) Funktionen zu ersetzen. Aus diesen Gründen entscheiden sich Entwickler nach wie vor gern für die Nutzung von strcpy() und Co.
Stack Guard
Im vorangegangenen Abschnitt wurde deutlich, dass ein mechanischer Austausch unsicherer Funktionen durch ihre Pendants mit Längenbegrenzung nicht immer möglich und auch häufig nicht gewollt ist. Komfortabler wäre, wenn Funktionen automatisch gegen Pufferüberläufe geschützt würden.
Eine einfache Idee besteht darin, die Rücksprungadresse vor Manipulation zu schützen. Dies geschieht, indem auf dem Stack unmittelbar vor der Rücksprungadresse ein wohldefinierter Wert, das sogenannte Canary Word, abgelegt wird. Dies geschieht beim Betreten der Funktion im sogenannten Funktionsprolog. Abbildung 11.4 zeigt das Canary Word (hier: 0x000a0dff) für den Stack aus dem vorangegangenen Beispiel.

Abbildung 11.4: Schutz der Rücksprungadresse durch Canary Word
Wenn die Funktion verlassen wird, prüft diese im sogenannten Funktionsepilog, ob das Canary Word noch an der entsprechenden Position steht. Ist dies nicht der Fall, dann hat mit hoher Wahrscheinlichkeit ein Pufferüberlauf stattgefunden, der das Canary Word und die Rücksprungadresse überschrieben hat. Die weitere Ausführung des Programms wird daher unterbunden und der Prozess abgebrochen. Dieses Verfahren wird häufig Stack Guard oder Stack Protector genannt.
Bergmänner nutzen Kanarienvögel seit alters her als Indikatoren für eine hohe Kohlenmonoxid-Konzentration im Schacht. Das hochgiftige, jedoch leider geruchlose und unsichtbare Gas sammelt sich infolge seiner im Vergleich zur Atemluft höheren Dichte zunächst in Bodennähe. Da die Käfige auf dem Boden abgestellt wurden, war das Verenden eines Vogels ein sicheres Anzeichen für eine gefährliche Konzentration an Kohlenmonoxid. Dies bedeutete unmittelbare Erstickungsgefahr für die Bergleute, die sich unverzüglich in Sicherheit bringen mussten.
Das »Kanarienwort« funktioniert ganz ähnlich: Ist es »tot«, also durch einen anderen Wert überschrieben, dann droht unmittelbare Gefahr, denn höchstwahrscheinlich ist auch die dahinter abgelegte Rückkehradresse manipuliert. Die angegriffene Funktion darf also unter keinen Umständen verlassen werden. Der Prozess muss sofort abgebrochen werden, um tiefergehenden Schaden für das Gesamtsystem zu verhindern.
Was hat es nun mit dem konkreten Wert 0x000a0dff des Canary Words auf sich? Dieser ist nicht zufällig gewählt, sondern die einzelnen Bytes beenden potenziell unsichere Funktionen. Ein cleverer Angreifer könnte ja die zum Überlauf genutzte Quellzeichenkette so modifizieren, dass beim Überlauf das Canary Word exakt mit dem Canary Word »über«schrieben wird. Sobald aber strcpy() in der Quellzeichenkette eine 0 findet, wird diese noch in das Ziel übertragen, und dann endet der Kopiervorgang. Der Angreifer kann zwar das Canary Word noch schreiben, aber er kommt nicht mehr an die dahinter stehende Rücksprungadresse heran! Ganz ähnlich würde ein auf gets() basierender Angriff enden, sobald ein Zeilenvorschub (0x0a) oder EOF (-1, also 0xff) gelesen würde. Das Schreiben des Canary Words beendet also den Überlauf vorzeitig; die Rückkehradresse bleibt intakt.
Den Code für das Schreiben (im Prolog) und die Integritätsprüfung des Canary Words (im Epilog) muss der Compiler bei der Übersetzung einfügen. Es resultiert ein gewisser Zusatzaufwand (Overhead), der sowohl die Größe des Programmcodes als auch dessen Abarbeitungszeit betrifft. Dieser ist in den meisten Fällen zu vertreten. Schwerer wiegt der Nachteil, dass ausschließlich die Integrität der Rückkehradresse gesichert wird. Manipulation der lokalen Variablen und des Saved Frame Pointer (SFP) sind weiterhin möglich und bleiben gegebenenfalls unentdeckt.
Ausführungsverbot beschreibbarer Seiten
Warum ist es nun eigentlich so schlimm, wenn die Rückkehradresse einer Funktion durch einen Angreifer manipuliert werden kann? Oder anders formuliert: Wohin sollte denn gesprungen werden, um beispielsweise den Rechner zu übernehmen?
Nun, statt einen Puffer mit sinnlosen Zeichen wie 134 Exemplaren 'a' zu überfluten, könnte man ein Schadprogramm auf den Adressen des Puffers ablegen, denn dem ausgenutzten strcpy() ist die Art der kopierten Daten egal (solange kein Nullbyte enthalten ist). Danach überschreibt man die originale Rücksprungadresse mit der Anfangsadresse des überfluteten Puffers und somit wird beim Verlassen der Funktion nun nicht mehr zur rufenden Funktion gesprungen, sondern zum Schadcode, der im Puffer steht. Abbildung 11.5 verdeutlicht diesen Ablauf.
Der bei dieser Angriffsvariante ausgeführte Code befindet sich nicht im Codesegment, sondern auf dem Stack. Wenn das Betriebssystem virtuellen Speicher verwirklicht, dann kann es selbstverständlich unterscheiden, ob eine Instruktion aus dem Codesegment oder aus einem anderen Segment (Daten, Stack) stammt. Eine naheliegende Schutzstrategie besteht daher darin, nur Instruktionen auszuführen, die sich im »richtigen« Segment, dem Codesegment, befinden.
Alle modernen Betriebssysteme verwirklichen diesen Mechanismus und gestatten die Ausführung von Code ausschließlich aus dem Codesegment. Zusätzlich sind Schreiboperationen in das Codesegment nach dem Laden des Programmcodes verboten. Damit sind für die drei Segmente eines Prozesses die in Tabelle 11.2 aufgeführten Operationen erlaubt. Daten- und Stacksegment werden also gleich behandelt; beide enthalten Daten, und diese müssen gelesen und geschrieben werden. Niemals darf Code aus diesen beiden Segmenten ausgeführt werden. Sie haben in den vorangegangenen Abschnitten gelernt, warum.
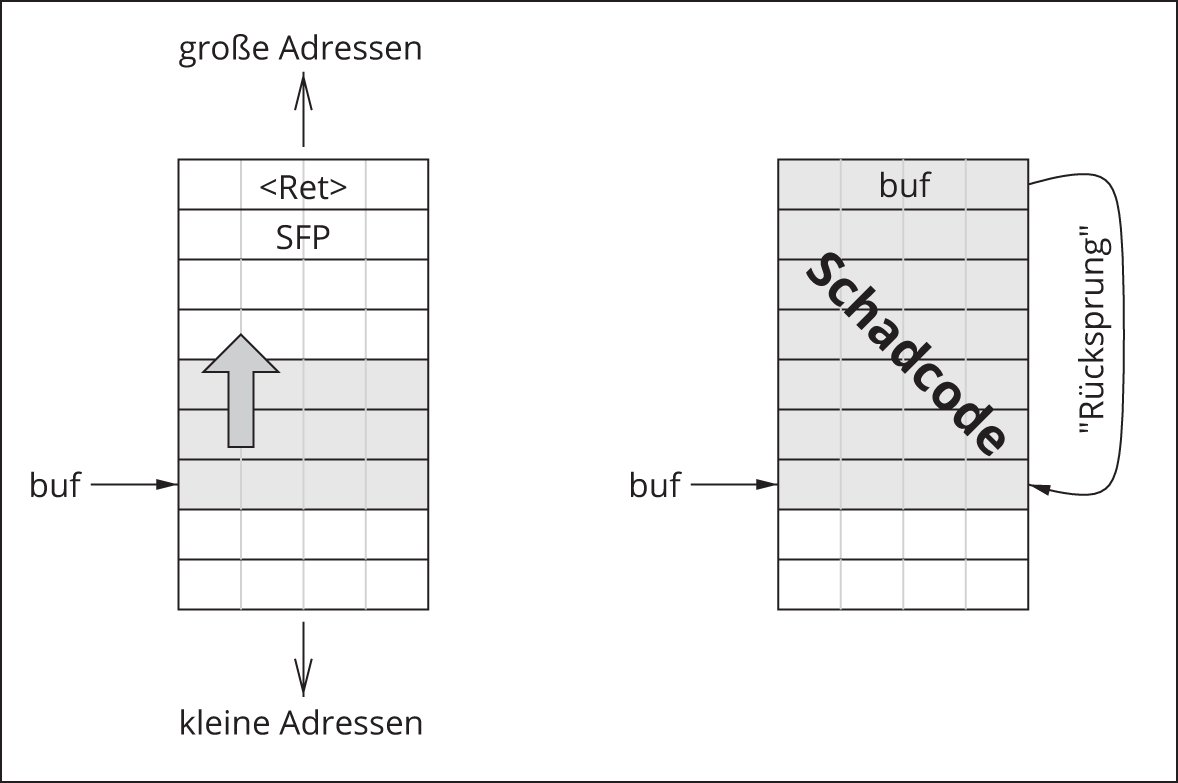
Abbildung 11.5: Überschreiben der Rücksprungadresse mittels Stack Overflow
Segment |
erlaubt |
verboten |
|---|---|---|
Daten |
Read, Write |
Execute |
Stack |
Read, Write |
Execute |
Code |
Read, Execute |
Write |
Tabelle 11.2: Erlaubte Operationen für Prozesssegmente
Das Codesegment erlaubt die Operationen Lesen und Ausführen; es darf jedoch nicht beschrieben werden. Der Speicherbereich eines Prozesses, in dem sich der Code befindet, darf also nachträglich nicht verändert werden! Damit ist sogenannter selbstmodifizierender Code ausgeschlossen, also Code, der sich während seiner Ausführung verändert. Für diesen gibt es ohnehin zumindest heutzutage kaum sinnvolle Anwendungsmöglichkeiten, jedoch einige aus dem Bereich bösartiger Software. Die sogenannten polymorphen Computerviren fallen in diese Kategorie. Sie modifizieren sich selbst fortwährend, um einer Detektion durch Anti-Viren-Software zu entgehen. Das Ausführungsverbot beschreibbarer Seiten erschwert somit nebenbei die Verbreitung von Computerviren.
Linux hat diesen Mechanismus ab der Kernelversion 2.6.8 eingebaut; im Windows gehört er ab einer späten Version von Windows XP zum Standardinventar. Dies wirft möglicherweise die Frage auf, warum Betriebssysteme nicht schon von Beginn an (ab der Entwicklung des virtuellen Speichers) entsprechend konstruiert wurden. Die Antwort ist mehrgestaltig. Zum einen gab es anfangs keinen Bedarf für Schutzmechanismen: Schadcode entstand erst mit zunehmender Verbreitung von Rechensystemen Anfang der 1980er-Jahre. Die erste ausgefeilte Angriffstechnik — der Stack Overflow — erschien Mitte der 1990er-Jahre. Zum anderen mag eine weitere Ursache darin liegen, dass die in den 1980er-Jahren marktbeherrschenden Prozessoren der Intel-80386-Architektur im Seitentabelleneintrag kein Execute-Bit vorsahen, sondern nur Rechte zum Lesen und Schreiben verwirklichten. Zum Dritten mag auch die Schwierigkeit, funktionsfähige, sich selbst modifizierende Software zu entwickeln, eine Rolle gespielt haben.
Der Mechanismus wurde mit einer Reihe mehr oder minder blumiger Begriffe versehen. Microsoft kreierte beispielsweise »Data Execution Prevention« (DEP), was sogar in »Datenausführungsverhinderung« eingedeutscht wurde. Die Firma AMD benannte das Feature »Enhanced Virus Protection«; das durch AMD neu eingeführte Bit im Seitentabelleneintrag wurde »NX«-Bit (No eXecute) getauft. Die Bezeichnungen »W^X« und »W X« spielen darauf an, dass für jede virtuelle Seite entweder das Write- oder das Execute-Bit gesetzt sein darf, niemals aber beide den gleichen Wert haben dürfen, was der logischen EXOR-Funktion entspricht.
X« spielen darauf an, dass für jede virtuelle Seite entweder das Write- oder das Execute-Bit gesetzt sein darf, niemals aber beide den gleichen Wert haben dürfen, was der logischen EXOR-Funktion entspricht.
Das Ausführungsverbot beschreibbarer Seiten macht es unmöglich, per Pufferüberlauf auf dem Stack abgelegten Schadcode auszuführen. Der Pufferüberlauf selbst wird nicht verhindert, somit kann die Integrität der über dem Puffer liegenden Variablen und abgelegten Daten (SFP, gesicherte Register) nicht garantiert werden. Des Weiteren besteht nur Schutz für Anwenderprozesse im User Mode; die Sicherheit des Betriebssystems wird nicht verbessert.
Mehr geschüttelt als gerührt: ASLR
Eine weitere, auf den ersten Blick recht primitive Technik hat sich in der Praxis als verhältnismäßig wirksam gegen Angriffe wie den Stack Overflow erwiesen.
Betrachten Sie dazu bitte noch einmal den durch einen Überlauf angegriffenen Stack in Abbildung 11.2. Versuchen Sie einmal zu formulieren, wie in dieser Situation die für einen Puffer-Überlauf notwendigen Daten aussehen müssten: Es müssen genau 152 Bytes mit Schadcode gefüllt werden (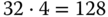 Byte in
Byte in buf, 10 Byte in passwort, zwei Füllbytes, 8 Byte für die gesicherten Register und 4 Byte für den gesicherten Frame Pointer SFP), und danach muss die Adresse von buf folgen, die die Rückkehradresse <Ret> überschreibt. Vertut man sich nur um ein einzelnes Byte, dann klappt der Angriff nicht mehr.
Woher weiß der Angreifer, dass er für den Schadcode genau 152 Bytes zur Verfügung hat, und woher kennt er die Adresse von buf? Nun, bis zur Einführung von Address Space Layout Randomization (ASLR) waren die Ladeadressen der Speichersegmente für jeden Aufruf ein und desselben Prozesses stets identisch. Ein Angreifer konnte sich das anzugreifende Programm besorgen, auf seinem Rechner starten und dann mit Hilfe eines Debuggers die relevanten Adressen und Daten in aller Ruhe ermitteln und einen maßgeschneiderten »Exploit«, also eine Software, die die Sicherheitslücke ausnutzt, konstruieren. Er konnte sich darauf verlassen, dass auf dem »richtigen« Zielsystem der Prozess an genau die gleichen virtuellen Adressen geladen wurde.
Heutige Systeme sind aus Hackerperspektive nicht mehr so komfortabel, sie nutzen ASLR, das bedeutet eine zufällige Wahl der Ladeadressen der Segmente eines Prozesses und der genutzten Shared Libraries. Die Ermittlung der Adresse von buf beispielsweise nützt dem Angreifer somit nichts mehr, weil sich diese bei jedem Programmstart ändert. Damit ASLR realisiert werden kann, muss der Compiler sogenannten positionsunabhängigen Code (position-independent executable, PIE) erzeugen, also Programmcode, der an jede beliebige Stelle geladen werden kann und keine absoluten Adressen enthält.
 Probieren Sie es aus: Das Programm in Listing 11.4 gibt jeweils eine Adresse aus dem Daten- (
Probieren Sie es aus: Das Programm in Listing 11.4 gibt jeweils eine Adresse aus dem Daten- (&bar), dem Code- (&main()) und dem Stacksegment (&foo) aus. Wenn Sie es übersetzen und mehrfach ausführen, erhalten Sie für jeden Lauf andere Adressen.
robge@sorpen:∼/txt/nebenjob/os4dummies/master/prg$./addressmain(): 55aa7fedb135, foo(): 7ffc4ac55170, bar(): 55aa7fede060robge@sorpen:∼/txt/nebenjob/os4dummies/master/prg$./addressmain(): 55d00e3db135, foo(): 7ffc68488370, bar(): 55d00e3de060robge@sorpen:∼/txt/nebenjob/os4dummies/master/prg$./addressmain(): 55684642e135, foo(): 7ffe6a239ad0, bar(): 556846431060
Starten Sie nun mittels
robge@sorpen:∼/os4dummies/master/prg$ setarch 'arch' -R /bin/bash
eine Sub-Shell, in der ASLR ausgeschaltet ist. Diese Einstellung gilt auch für alle Kindprozesse dieser Shell, also alle Kommandos, die man in ihr startet. Wenn Sie erneut address ausführen, bleiben die Adressen konstant.
Vergessen Sie nicht, die Subshell mittels exit wieder zu beenden, sonst nutzt am Ende noch ein Angreifer diese kleine Lücke aus!

Listing 11.4: Näherungsweise Ausgabe der Adressen von Stack-, Daten- und Codesegment (address.c)
Das Beispiel ist unterkomplex; in Wirklichkeit sind die einzelnen Segmente eines Prozesses viel zerklüfteter und unübersichtlicher. Sie können aber mit Hilfe des /proc-Dateisystems tiefer vordringen. Beispielsweise enthält die (Pseudo-)Datei /proc/PID/maps Informationen über alle Speicherbereiche des Prozesses mit der entsprechenden PID.
ASLR erschwert also alle Angriffe, die eine sorgfältige Ermittlung von Adressen von Objekten im virtuellen Adressraum eines Prozesses erfordern, unabhängig von der konkreten Angriffstechnik. Es ist besonders bei großen Adressräumen wirkungsvoll, während bei 32-Bit-Adressen der Raum für den Zufall begrenzt ist.
Andere Angriffe
Es gibt eine ganze Reihe weiterer Techniken, um verwundbare C-Programme anzugreifen und die bislang beschriebenen Gegenmaßnahmen zu umgehen. In diesem Abschnitt lernen Sie einige überblicksmäßig kennen.
Return-into-libc
Wenn man mittels Stack Overflow die Rücksprungadresse einer Funktion manipuliert, muss man nicht zwangsläufig zu Schadcode, der sich auf dem Stack befindet, springen. Es ist beispielsweise auch möglich, eine oder mehrere Funktionen innerhalb von sogenannten Shared Libraries aufzurufen.
Was versteht man darunter? Programme nutzen sehr viele Funktionen von Bibliotheken. Sie haben beispielsweise gleich am Anfang dieses Buches printf() kennengelernt, das zur C-Standardbibliothek gehört. Da so gut wie jedes C-Programm diese Funktion benutzt, wäre es unsinnig, wenn die Implementierung dieser Funktion in jedes einzelne Binary eingefügt würde. Wenn im System 90 Prozesse aktiv sind, die alle printf() nutzen, wäre 90-mal der Code von printf() (irgendwo) im Hauptspeicher abgelegt – eine ziemliche Speicherplatzverschwendung! Stattdessen wird der printf()-Code genau einmal in den Hauptspeicher geladen, und jedes Programm, das printf() nutzt, blendet die entsprechende Seite in seinen virtuellen Adressraum ein. Dieses Prinzip wird dynamisches Linken genannt (das Gegenteil, den Code aller genutzten Bibliotheksfunktionen dem Binary hinzuzufügen, heißt statisches Linken).
Ein Angreifer, der mittels eines Stack Overflow die Rückkehradresse einer Funktion manipuliert, kann nun versuchen, in eine solche Bibliotheksfunktion zu springen, indem er ihre Anfangsadresse an die Stelle der Rückkehradresse der angegriffenen Funktion schreibt. Dies macht das Ausführungsverbot beschreibbarer Seiten wirkungslos, denn es muss natürlich erlaubt sein, den Code der Shared Libraries auszuführen. Das System kann nicht zwischen einem »rechtmäßigen« Aufruf der Funktion innerhalb eines Prozesses und einem »illegalen« Sprung durch die Manipulation einer Rückkehradresse unterscheiden.
Dieser Angriffstyp wird Return-into-libc-Angriff genannt, denn libc ist der Kurzbegriff für die C-Standardbibliothek. Sehr häufig wird dabei versucht, die Funktion system() anzuspringen und mit ihrer Hilfe eine Shell zu starten. Es sind hierbei auch noch einige technische Probleme zu überwinden, denn man muss der Bibliotheksfunktion Argumente übergeben. An dieser Stelle soll auf deren Diskussion jedoch verzichtet werden.
Auch Zahlen können überlaufen
Eine weitere Klasse von subtilen Programmierfehlern, die in C möglich sind, sind die sogenannten Integer Overflows (Ganzzahlüberläufe). Sie geschehen üblicherweise, wenn vorzeichenbehaftete Daten mit vorzeichenlosen Daten »vermischt« werden.
Listing 11.5 zeigt ein sehr einfaches Beispiel:

Listing 11.5: Programm, das für einen Integer Overflow anfällig ist
Es soll zwei Parameter an der Kommandozeile übernehmen, nämlich eine Zeichenkette, die im Programm in das Feld buf kopiert werden soll, und die explizite Länge dieser Zeichenkette. Letztere wird in Zeile 15 mit Hilfe der Funktion atoi() in einen Integer gewandelt. Das Programm prüft, ob die Länge der Zeichenkette die Länge des Puffers übersteigt, und bricht in diesem Falle die Abarbeitung mit einer Fehlermeldung ab (Zeilen 18–20). Danach kopiert das Programm mittels der (sicheren) Funktion memcopy() die Zeichenkette in buf und terminiert diese mit einem Nullbyte. Zuletzt wird der Inhalt von buf zur Kontrolle ausgegeben. Ein Aufruf des Programms könnte so aussehen:

Auf den ersten Blick ist ein Überlauf durch die Angabe einer zu langen Zeichenkette nicht möglich. Jedoch ist die Variable s vom Typ unsigned short, der 2 Byte umfasst und dessen Wertebereich somit von 0 bis 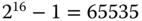 reicht. Wenn Sie als Länge 65536 oder mehr angeben, dann ist es nicht möglich, diesen Wert in
reicht. Wenn Sie als Länge 65536 oder mehr angeben, dann ist es nicht möglich, diesen Wert in s korrekt abzulegen; s »läuft über«. Dies äußert sich so, dass in s nur die beiden niederwertigsten Bytes des Wertes von i abgelegt werden. Damit ist s wieder im »erlaubten« Bereich, und die Längenprüfung in den Zeilen 18–20 schlägt nicht fehl.
Die Kopierfunktion memcopy() arbeitet jedoch mit der Variablen i, die den kompletten Längenwert enthält, und somit werden (viel) mehr als 80 Byte kopiert, der Stack läuft über, was zum Programmabbruch führt.
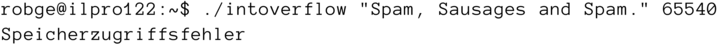
Der Fehler ist also in Zeile 16 versteckt. Der Integer i wird dem unsigned short-Wert s zugewiesen. Da der Wertebereich von i größer ist als der von s, kann es, wie im Beispiel demonstriert, zu einem Überlauf kommen. Ein Angreifer kann das Programm durch geeignete Wahl der Parameter zum Absturz bringen.
Nun könnte man argumentieren, dass ein Programmabbruch nicht so gravierend sei wie die direkte Ausführung von Schadcode. Trotzdem sollten Angreifer keinesfalls in der Lage sein, willkürlich Prozesse zu beenden, da damit zum einen Denial-of-Service-Attacken möglich werden (das System kann seinen Einsatzzweck vielleicht nur teilweise oder gar nicht mehr erfüllen – denken Sie an E-Mail- oder Nameserver!), zum anderen bestimmte Prozesse der Verteidigung dienen, wie etwa Paketfilter und Einbruchserkennungssoftware (Intrusion Detection Systems, IDS).
Es gibt noch viele weitere Möglichkeiten, Fehler in C-Programmen auszunutzen. Wenigstens genannt seien der Heap Overflow, der dem Stack Overflow ähnelt, aber keine Modifikation des Kontrollflusses gestattet, die Formatstring-Attacke, die versucht, Programmierfehler bei printf() auszunutzen, und das sogenannte Return-oriented programming (ROP), das die Grundidee des Return-into-libc-Angriffs verfeinert.
Gegen all diese Techniken gibt es wiederum Gegenmaßnahmen auf verschiedenen Ebenen des Systems. Ihre Diskussion bleibt aber, genauso wie die genaue Vorstellung der Angriffstechniken, Spezialliteratur vorbehalten.
Authentifizierung
Ein weiterer wichtiger Dienst, den moderne Betriebssysteme zwecks Erhöhung der Systemsicherheit anbieten, ist die Authentifizierung. Darunter versteht man das erzwungene Anmelden eines Nutzers am System, bevor dieser Zugriff auf dessen Daten erhält. Sehr häufig spricht man vom »Einloggen« bei Anmeldung und »Ausloggen« nach getaner Arbeit. Die Anmeldung kann lokal erfolgen, das bedeutet, der Nutzer hat direkten physischen Zugang zum System oder entfernt. Im letzteren Fall nutzt er einen anderen Computer als Zugangspunkt und kommuniziert über ein (Authentifizierungs-)Protokoll mit dem entfernten Rechner.
Der Vorgang der Authentifizierung ist vielen Angriffen ausgesetzt, aus diesem Grunde wurden und werden immer noch viele verschiedene Mechanismen vorgeschlagen und implementiert. Im Rahmen dieses Buches werfen wir nur einen Blick auf eine besonders einfache, grundlegende Form: die lokale, passwortbasierte Authentifizierung. Die heute gern genutzte Authentifizierung mittels biometrischer Merkmale (Fingerabdruck, Retina-Scan, Stimmerkennung) sei genauso Spezialliteratur vorbehalten wie komplexe kryptografische Protokolle (beispielsweise Kerberos).
Nicht jedes Betriebssystem unterstützt Authentifizierung. Historische Single-User-Betriebssysteme (MS-DOS, CP/M) und viele Betriebssysteme für eingebettete Systeme verzichten auf diese Funktionalität.
Passwortbasierte Authentifizierung
Überlegen Sie zunächst, wie der grundlegende Ablauf eines Anmeldevorgangs aussieht.
- Sie geben Ihren Namen oder ein Nutzerkennzeichen (im Englischen Login genannt) zur Identifikation ein. Dies ist notwendig, um Sie als Person von anderen Nutzern, die ebenfalls potenziell mit dem System arbeiten dürfen, zu unterscheiden. Woher kommt dieses Login? Sie erhalten dieses üblicherweise von einer administrativen Stelle (IT-Abteilung Ihres Unternehmens, Rechenzentrum der Hochschule) zugeteilt.
- Sie geben ein nur Ihnen bekanntes (und gut gehütetes) geheimes Passwort in die entsprechende Eingabemaske ein. Dabei achten Sie darauf, dass Ihnen niemand über die Schulter schaut oder den Vorgang filmt.
- Der Rechner vergleicht das eingegebene Passwort mit dem ihm vorliegenden Passwort (das Sie bei der Zuteilung des Nutzerkennzeichens für sich festlegten und das auf irgendeine Art und Weise im System hinterlegt werden muss) und gewährt bei Gleichheit Zugang zum System. Differieren eingegebene und hinterlegte Passphrase, so wird der Zugang verweigert.
Wie könnte man diesen Vorgang nun im Betriebssystem implementieren?
Wie man Passworte nicht aufbewahrt
Die geheimen Passworte müssen auch nach einem Reboot des Systems zur Verfügung stehen, daher muss diese Information auf irgendeine Weise persistent abgelegt werden. Man könnte beispielsweise die geheimen Passworte und die zugehörigen Nutzerkennzeichen in einer Datei ablegen, die durch die Mechanismen des Betriebssystems vor unbefugtem Zugriff gesichert ist.
Der Nutzer gibt Login und Passwort ein, das Betriebssystem sucht mit Hilfe des Logins das passende Passwort aus der Passwortdatei heraus und vergleicht dieses mit der eingegebenen Phrase (Abbildung 11.6).
Diese Vorgehensweise birgt einen entscheidenden Nachteil: Durch die Ablage des Passwortes als Klartext kann sich ein Angreifer, der die Zugriffsbeschränkung der Passwortdatei überwindet, über die Passworte aller Nutzer informieren (und sich fortan als eine dieser Personen ausgeben). Er könnte beispielsweise die Festplatte aus dem Rechner ausbauen und deren Daten unter einem anderen System ohne Zugriffsbeschränkung auslesen.

Abbildung 11.6: Naive Implementierung der Authentifizierung
 Passworte und andere Authentifizierungsinformationen sollten niemals im Klartext persistent abgelegt werden.
Passworte und andere Authentifizierungsinformationen sollten niemals im Klartext persistent abgelegt werden.
Nun wäre möglicherweise ein Ausweg, die Passwortdatei zu verschlüsseln. Doch dazu benötigt man einen Schlüssel, der wiederum irgendwo im System aufbewahrt oder durch den Nutzer zusätzlich eingegeben werden muss. All das verkompliziert die Anmeldung auf alle Fälle ungemein.
Aber der Blick über den Tellerrand zum Fach der Kryptografie ist schon angebracht. Das Hilfsmittel der Wahl sind kryptografische Hashfunktionen.
Hash mich, ich bin der Mörder!
An dieser Stelle ist ein kurzer Ausflug in die Kryptografie nötig. Dabei verzichten wir auf jeglichen mathematischen Ballast und nähern uns dem Begriff »kryptografische Hashfunktion« aus Anwendersicht.
Eine kryptografische Hashfunktion bildet Eingangsdaten beliebiger Länge auf ein kurzes Datum (typisch sind 128–512 Bit), den Hash, ab. Dabei gibt es keinerlei Korrespondenz zwischen Eingangs- und Ausgangsdaten; ganz ähnliche Eingangsdaten erzeugen völlig unterschiedliche Hashes. Des Weiteren sind kryptografische Hashfunktionen Einwegfunktionen, das bedeutet, dass es verhältnismäßig einfach ist, für ein gegebenes Datum den Hash zu ermitteln, jedoch unmöglich, aus einem gegebenen Hash das entsprechende Eingangsdatum zu ermitteln. Es gibt keine Umkehrfunktion.
Zum Dritten sind kryptografische Hashfunktionen so konstruiert, dass für jedes Eingangsdatum ein anderer Hash erzeugt werden soll. Es soll gewissermaßen keine zwei verschiedenen Eingangsdaten geben, die den gleichen Hash erzeugen. Gleiche Hashes für unterschiedliche Eingangsdaten nennt man »Kollisionen«, und die soll es nicht geben.
Wenn man ein bisschen darüber nachdenkt, dann kommt man zu dem Schluss, dass Kollisionsfreiheit unmöglich zu erfüllen ist. Warum ist das so?
Nehmen wir einmal ein populäres Verfahren namens »SHA256«. Das Akronym steht für Secure Hash Algorithm, und die 256 ist die Länge des Hashes in Bit. Die Anzahl  verschiedener Hashes, die dieses Verfahren erzeugen kann, beträgt
verschiedener Hashes, die dieses Verfahren erzeugen kann, beträgt 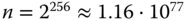 . Das ist zwar eine ganze Menge, aber es sind endlich viele.
. Das ist zwar eine ganze Menge, aber es sind endlich viele.
Wie viele verschiedene Eingangsdaten kann es geben? Das hängt von deren Länge in Bit ab. Beschränken wir diese willkürlich auf ein KiB. Dann gibt es offenbar 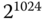 verschiedene Eingangsdaten (das sind
verschiedene Eingangsdaten (das sind 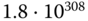 , eine unfassbar große Zahl), und diese müssen auf die viel kleinere Anzahl Hashes abgebildet werden, denn jedes Eingangsdatum benötigt ja einen Hash. Somit gibt es jede Menge Kollisionen! Trotzdem ist bislang keine einzige Kollision für SHA256 bekannt geworden. Es liegt einfach an der cleveren Konstruktion der Hashfunktion und den sehr, sehr großen Zahlen.
, eine unfassbar große Zahl), und diese müssen auf die viel kleinere Anzahl Hashes abgebildet werden, denn jedes Eingangsdatum benötigt ja einen Hash. Somit gibt es jede Menge Kollisionen! Trotzdem ist bislang keine einzige Kollision für SHA256 bekannt geworden. Es liegt einfach an der cleveren Konstruktion der Hashfunktion und den sehr, sehr großen Zahlen.
Bevor Sie jetzt schnell ein Programm schreiben, das Kollisionen in SHA256 sucht, ermitteln Sie zunächst den Zeitbedarf, um alle möglichen Hashes zu errechnen. Selbst wenn Sie für die Ermittlung eines Hashes optimistischerweise nur eine Nanosekunde veranschlagen, brauchen Sie 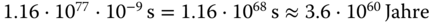 . Angesichts des Alters unseres Universums von 13 Milliarden Jahren haben Sie da ganz schön was vor!
. Angesichts des Alters unseres Universums von 13 Milliarden Jahren haben Sie da ganz schön was vor!
Tabelle 11.3 führt einige populäre Hashverfahren auf. MD5 und SHA-1 gelten als als unbrauchbar, da für sie mittlerweile Wege bekannt sind, Kollisionen herbeizuführen. Aus diesem Grunde werden auch immer wieder neue Verfahren publiziert. Die wichtigsten Hashalgorithmen stehen in typischen Linux-Installationen in Form der Kommandos md5sum, sha1sum, sha512sum zur Verfügung.
Verfahren |
Jahr |
Länge [Bit] |
gebrochen? |
|---|---|---|---|
MD5 |
1991 |
128 |
|
SHA-1 |
1995 |
160 |
|
SHA-256 |
2004 |
256 |
- |
SHA-512 |
2004 |
512 |
- |
SHA-3 |
2012 |
224-512 |
- |


Tabelle 11.3: Einige gebräuchliche Hashverfahren
Die Konstruktion von Hashfunktionen ist etwas für Spezialisten. Mehr dazu erfahren Sie in der einschlägigen Spezialliteratur [8].
Wir hashen Passworte
Anstelle von Klartextpassworten legt man also Hashes der Passworte in einer Datei ab. Wenn sich der Nutzer authentifiziert, gibt er wiederum Login und Passwort ein, das System ermittelt zum Passwort den Hash und vergleicht diesen mit dem abgespeicherten Hash (Abbildung 11.7).
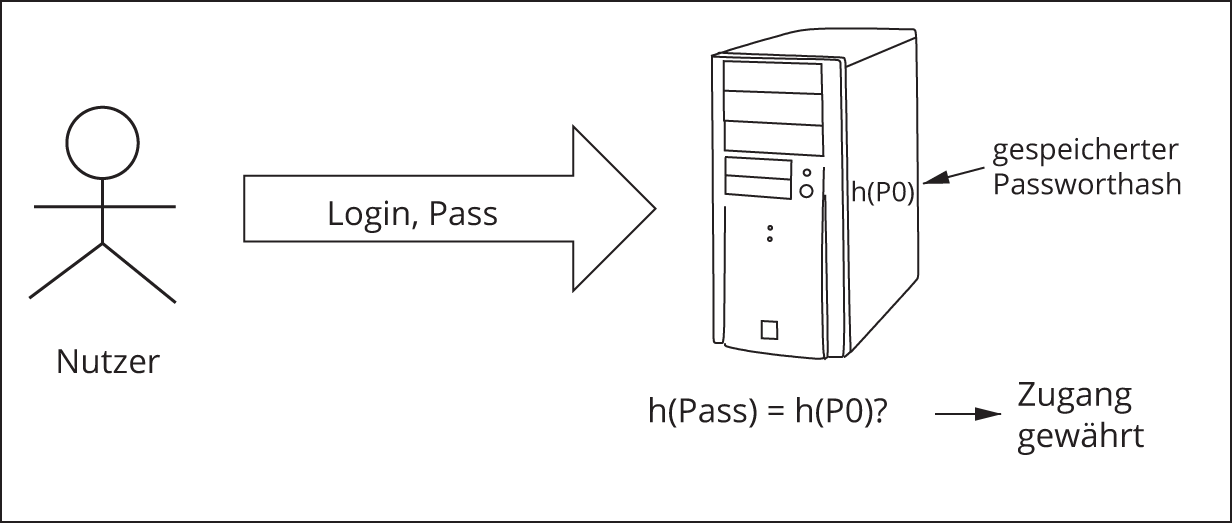
Abbildung 11.7: Authentifizierung mittels Passworthash
Ein Angreifer kann sich nun zwar die Datei mit den Hashes besorgen, aus den Hashes kann er jedoch das Passwort nicht ermitteln, da es keine Umkehrfunktion zur Hashfunktion gibt. Er kann jedoch populäre Passworte »durchprobieren«, in dem er Hashes für alle möglichen Passworte generiert und diese mit den Hashes in der Passwortdatei vergleicht. Findet er eine Übereinstimmung, dann ist das probierte Passwort das des entsprechenden Nutzers. Ein solcher Angriff wird Wörterbuchangriff genannt, weil man systematisch alle Wörter, die in einem Wörterbuch vorkommen, durchprobiert. Des Weiteren kann der Angreifer alle potenziellen Zeichenketten durchprobieren (also nicht nur bedeutungstragende Wörter), was natürlich noch viel länger dauert. Diese Form des Angriffs nennt man Brute-Force-Angriff.
Einschlägige »Hacker«-Werkzeuge wie John the Ripper und Hashcat wurden genau dafür entwickelt.
Challenge-Response-Authentifizierung
Für die lokale Anmeldung am System ist die Nutzung von Hashes sicher genug. Anders sieht es aus, wenn man sich an einem entfernten Rechner anmelden möchte, das lokale System also nur als Eingabeterminal genutzt wird. Da der Hash nun vom Anmelde- zum Zielrechner übertragen werden müsste, könnte ihn ein Angreifer, der physischen Zugang zum Netz hat, abfangen und mit einschlägigen Werkzeugen versuchen, die zugehörige Passphrase zu ermitteln.
Aus diesem Grunde nutzt man ein etwas komplexeres Protokoll: Der Zielrechner, an dem sich der Nutzer anmelden möchte, stellt gewissermaßen ein Rätsel, eine »Challenge«. Der Nutzer muss das Rätsel lösen und die hoffentlich korrekte Antwort zurückschicken (»Response«). Daher nennt man das Verfahren gern Challenge-Response-Authentifizierung.
Abbildung 11.8 illustriert die einzelnen Schritte. Zunächst gibt der Nutzer sein Login und sein Passwort am Anmelderechner ein. Zum Passwort wird wie gehabt der kryptografische Hash berechnet. Danach wird im zweiten Schritt (nur) das Login an den Zielrechner übermittelt. Wenn der Zielrechner dieses kennt, generiert er als Nächstes eine Zufallszahl, die nur ein einziges Mal verwendet werden darf (diese wird Nonce genannt, das bedeutet »number to be used once«), und schickt diese an den Anmelderechner zurück. Die Nonce repräsentiert offenbar die Challenge; sie wird im nächsten Schritt mit dem Passworthash verschlüsselt. Anschließend wird die verschlüsselte Nonce als Response an den Zielrechner gesandt. Dieser verschlüsselt die generierte Nonce mit dem Passworthash des Nutzers, den er ebenfalls besitzt, und vergleicht empfangene und selbst verschlüsselte Nonce. Bei Gleichheit wird Zugang gewährt. In der Abbildung wird die Verschlüsselung durch den Buchstaben E (wie Encryption) symbolisiert.
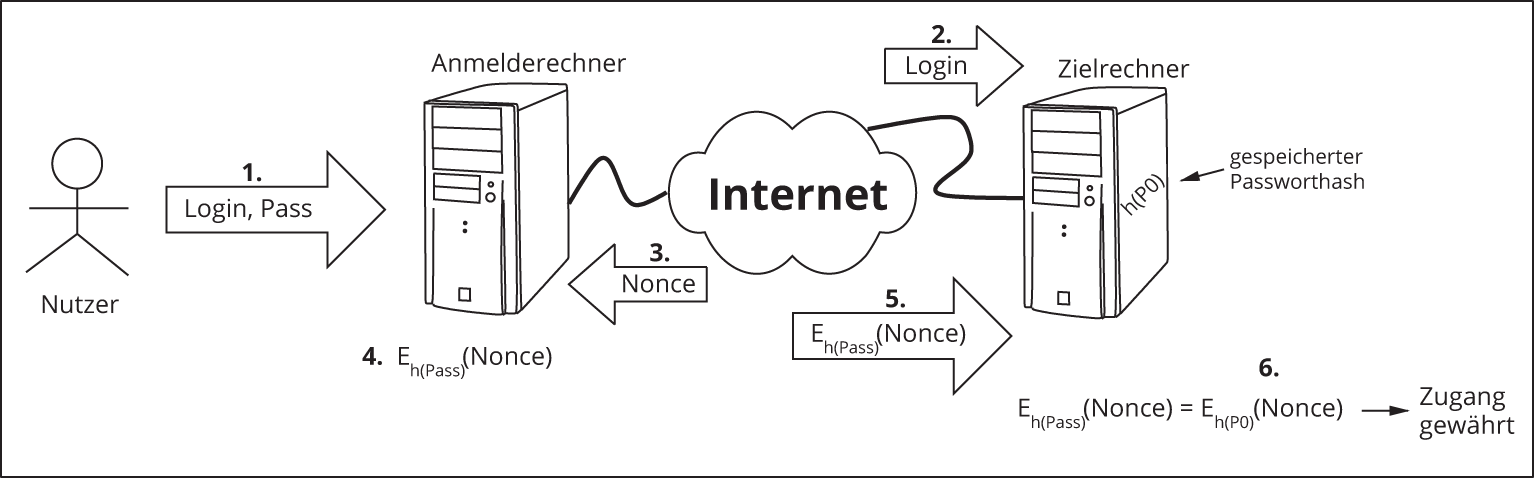
Abbildung 11.8: Authentifizierung mittels Challenge-Response
Das Protokoll gewährleistet, dass nur irrelevante oder verschlüsselte relevante Daten übertragen werden. Der Angreifer kann zwar das Login oder die Nonce mitlesen, aber dieses Wissen nützt ihm nichts.
Er könnte ebenfalls den gesamten Datenverkehr aufzeichnen und das Nutzerkennzeichen sowie die verschlüsselte Nonce später dem Zielrechner erneut vorspielen, um sich unautorisiert einzuloggen (dies nennt man eine »Replay-Attacke«). Da aber der Zielrechner jede Nonce nur ein einziges Mal benutzt und somit bei jedem Anmeldeversuch ein neues Rätsel stellt, passt die aufgezeichnete verschlüsselte Nonce nicht zum Rätsel, und der Zielrechner verwehrt den Zugang.
Microsoft Windows nutzt dieses Verfahren zur Authentifizierung beispielsweise im Active Directory und im veralteten NTLM-Protokoll.
2-Faktor-Authentifizierung
Die bisher behandelten Formen der Authentifizierung leiden alle unter einem Nachteil: Wenn ein Angreifer in den Besitz des Passwortes kommt, dann kann er sich am System anmelden und getarnt als der entsprechende Nutzer agieren. Besser wäre es, wenn durch eine Kompromittierung des Passwortes noch kein direkter Zugang zum System möglich wäre.
Genau diesem Zweck dient die sogenannte 2-Faktor-Authentifizierung: Der Nutzer muss auf zwei voneinander unabhängigen Kanälen seine Identität nachweisen. Beim Zugriff auf das Girokonto (durch Besitz der EC-Karte und Kenntnis der PIN) und seit deutlich kürzerer Zeit allgemein beim Online-Banking (durch die sogenannte PSD2-Richtlinie erzwungen) ist dies etablierter Stand der Technik.
Selbstverständlich kann man auch Betriebssysteme für die 2-Faktor-Authentifizierung konfigurieren. Der zweite Kanal wird dabei entweder über ein Handy realisiert oder mittels eines Security-Tokens, das per USB mit dem Zielsystem verbunden wird. Man muss allerdings aufpassen, dass man sich dabei nicht versehentlich dauerhaft vom System ausschließt, beispielsweise durch den Verlust des Security-Tokens.
Beispiel: Lokale Authentifizierung in Linux
Am Beispiel von Linux soll in diesem Abschnitt eine einfache Authentifizierung mit den Mitteln des Betriebssystems implementiert werden. Dazu sind zunächst einige implementationstechnische Details zu klären.
Das Einlesen der Passphrase
Beim Anlegen des Nutzeraccounts und später bei der eigentlichen Authentifizierung muss eine geheime Passphrase eingelesen werden. Die typischen Eingabefunktionen von C wie fgets() oder scanf() haben dabei den Nachteil, dass sie die eingegebene Phrase auf dem Bildschirm darstellen, sodass Personen, die einen Blick auf den Bildschirm werfen, diese unautorisiert mitlesen können. Dieses »Echo« muss also unterdrückt werden, der Nutzer muss blind schreiben.
Viele grafische Eingabemasken geben bei jedem Tastendruck ein neutrales Zeichen, wie » « aus, um dem Nutzer eine Rückmeldung über etwaige Tastenbetätigung zu geben. Das ist gefährlich, denn ein Shoulder Surfer kann damit auf einen Blick die Länge des Passwortes erkennen und somit den Suchraum für einen Brute-Force-Angriff erheblich verkleinern!
« aus, um dem Nutzer eine Rückmeldung über etwaige Tastenbetätigung zu geben. Das ist gefährlich, denn ein Shoulder Surfer kann damit auf einen Blick die Länge des Passwortes erkennen und somit den Suchraum für einen Brute-Force-Angriff erheblich verkleinern!
UNIX stellt dafür die Funktion getpass() zur Verfügung.

Die als Argument übergebene Zeichenkette wird als Prompt gleich wieder ausgegeben, und getpass() liest ohne Echo nach stdout eine Zeichenkette ein. Diese wird in einem internen Puffer abgelegt, dessen Startadresse als Resultatwert zurückgeliefert wird. Ein Überlauf des Puffers ist unmöglich, es werden maximal PASS_MAX Zeichen eingelesen.
Genau genommen darf man diese Funktion nicht (mehr) einsetzen, denn sie ist im Single-Unix-Standard als legacy, also als (stark) veraltet oder »früher einmal wichtig«, gekennzeichnet. Der Standard empfiehlt, stattdessen manuell das Echo des Terminals auszuschalten, die Passphrase einzulesen und das Echo wieder einzuschalten. Aus Gründen der Übersichtlichkeit verzichten wir an dieser Stelle darauf, und Sie merken sich bitte, getpass() nur zum Zwecke der Lektüre dieses Buches einzusetzen!
Hashen der Passphrase
Das nächste zu lösende Problem betrifft das Hashing. Welches Verfahren sollte eingesetzt werden, und wie sollte dieses implementiert werden?
In erster Näherung könnte man ein bewährtes Verfahren auswählen, sagen wir SHA-1, und dieses from scratch implementieren. Die meisten Hashalgorithmen (so auch SHA-1) sind frei und wohldokumentiert. Eine Eigenimplementierung birgt aber stets das Risiko, dass man dabei etwas falsch macht, und Implementationsfehler bei der Authentifizierung könnten die Sicherheit der betreffenden Systeme gravierend unterminieren. Aus diesem Grunde wird im Allgemeinen davon abgeraten, kryptografische Funktionalität ohne Entwicklungserfahrung selbst zu implementieren (was natürlich die berechtigte Frage aufwirft, woher man diese Entwicklungserfahrung dann bekommen soll), sondern stattdessen auf bewährte Implementierungen zurückzugreifen. Mit der sogenannten OpenSSL-Bibliothek steht eine freie, professionell entwickelte und fehlerarme Bibliothek zur Verfügung.
Es geht aber noch einfacher: Sie benötigen gar keine externe Bibliothek, denn UNIX bringt Ihnen in Gestalt der crypt()-Funktion alles mit, was man zur Authentifizierung benötigt.

Als Parameter phrase übergeben Sie die Klartext-Passphrase. crypt() ermittelt den zugehörigen Hash in einem weiteren internen Puffer und liefert dessen Anfangsadresse als Resultat zurück.
Der zweite Parameter setting ist einigermaßen kompliziert, daher soll an dieser Stelle auf die Erörterung aller Details verzichtet werden. Zum einen definiert er das zu verwendende konkrete Verfahren, zum anderen übergibt man damit noch einen weiteren Eingabeparameter, das sogenannte Salz.
Gesalzene Passworte
Das Salz ist eine Zufallszahl, die vor dem Hashen mit der Passphrase konkateniert, also verkettet, wird. Es ist nicht geheim, sondern wird in der Passwortdatei unverschlüsselt mit abgelegt. Es erscheint auf den ersten Blick widersinnig, einen Teil der zu hashenden Daten unverschlüsselt abzulegen, denn ein Angreifer, der Zugang zur Passwortdatei hat, kennt damit auch das Salz.
Das Salz wird aber für jeden Nutzer individuell festgelegt. Es erschwert den Wörterbuchangriff, der im Folgenden etwas genauer betrachtet wird. Er besteht prinzipiell aus zwei Phasen (Abbildung 11.9):
- Zunächst wird der Angriff vorbereitet. Der Angreifer berechnet für alle möglichen (und unmöglichen) Passphrasen den zugehörigen Hash. Dies kann lange Zeit in Anspruch nehmen, je nach Art und Umfang des zugrunde liegenden Wörterbuchs. Als Resultat erhält der Angreifer eine (sehr große) zweispaltige Tabelle, in der jeweils paarweise das Passwort und der zugehörige Hash abgelegt sind.
- Im zweiten Schritt sucht der Angreifer Übereinstimmungen zwischen den berechneten Hashes aus der Tabelle und den in einer gestohlenen Passwortdatei abgelegten Hashes. Gibt es Übereinstimmung, dann ist das zugehörige Passwort aus der Tabelle dasjenige des Nutzers: Der Account ist damit »geknackt«.

Abbildung 11.9: Prinzip des Wörterbuchangriffs
Die Nutzung von Salz verhindert somit effektiv das Vorberechnen der Hashes, denn der Angreifer müsste das Salz ja ebenfalls mit der Klartext-Passphrase kombinieren. Dieses ist aber eine variable Zufallszahl, daher müsste der Angreifer alle möglichen Salz-Werte mit allen durchzuprobierenden Passphrasen kombinieren, was den Aufwand gewaltig steigen lässt!
Ein vollständiges Beispiel
Zum Abschluss zeige ich Ihnen, wie eine einfache Authentifizierung unter Linux implementiert werden kann.
Das Programm soll das als Parameter übergebene Kommando ausführen, zuvor soll sich der Nutzer jedoch authentifizieren. Die Passwortdatei enthält Login und Salz sowie Hash der Passphrase eines Nutzers jeweils in einer Zeile. Das Login ist von den restlichen Daten durch einen Doppelpunkt getrennt. Diese Dateistruktur ähnelt der »richtigen« (lokalen) Passwortdatei /etc/shadow von UNIX.


Listing 11.6: Authentifizierung vor Ausführung eines Kommandos
Listing 11.6 zeigt das Programm. Nach der Prüfung des Kommandozeilenarguments wird die Passwortdatei zum Lesen (Zeile 28) geöffnet. Danach wird zunächst das Login des Nutzers abgefragt (Zeile 34–36). Da dieses nicht geheim ist, kann dafür wie im Listing fgets() genutzt werden. Zeile für Zeile wird nun die Passwortdatei nach diesem Login durchsucht (Zeilen 38–45). Ein falsches Login wird entsprechend abgewiesen (48–51). Andernfalls wird das zugehörige Salz aus der Zeile entnommen und in salt abgelegt. Der nun folgende Aufruf von my_getpass() liest die Passphrase ohne Echo auf dem Bildschirm in die Variable plainpw ein und liefert deren Länge in nchars zurück. Die Implementierung dieser Funktion ist verhältnismäßig komplex und wird daher an dieser Stelle ausgelassen.
Nun muss die Passphrase mittels crypt() gehasht (Zeile 62) und der Hash mit dem in der Passwortdatei abgelegten Hash verglichen werden (Zeile 66). Bei Gleichheit ist der Nutzer authentifiziert, und das eingangs übergebene Kommando wird mittels execvp() ausgeführt (Zeile 70). Stimmen abgelegter und berechneter Hash nicht überein, dann wird die Ausführung verweigert.
Wichtig ist noch, dass das im Klartext im Hauptspeicher stehende Passwort sofort überschrieben wird, sobald es nicht mehr benötigt wird (Zeile 63)!
Um das Beispiel praktisch auszuprobieren, benötigen Sie noch die Implementierung der Funktion my_getpass() sowie ein Werkzeug, um die Passwortdatei anzulegen. Schauen Sie sich bitte dazu die beiden letzten Aufgaben an.
Zusammenfassung
Sie haben (hoffentlich ohne Mühe) das Ende dieses etwas anspruchsvolleren Kapitels erreicht. Das Gebiet der Betriebssystemsicherheit ist mittlerweile wahrscheinlich das wichtigste Teilgebiet der Betriebssysteme, denn für alle im Buch angesprochenen Probleme der Betriebssystemkonstruktion gibt es effiziente Algorithmen, Verfahren und Lösungen. Jedoch vergeht kaum ein Tag, an dem wir nicht von (Computer-)Einbrüchen, Cyberkriminalität und Sicherheitslöchern in Computern erfahren. Nicht alle gehen auf das Konto unsicherer Betriebssysteme, jedoch ist es nach wie vor ein schwieriges Problem, Betriebssysteme in ausreichendem Maße abzusichern.
Lesevorschläge
- »Aleph One«. »Smashing The Stack For Fun And Profit«. In: Phrack 7.49 (November 1996). http://www.phrack.org/phrack/49/P49-14. Das ist der Artikel, der erstmals einen Stack Overflow beschrieb.
- »Bulba« und »Kil3r«. »Bypassing Stackguard and Stackshield«. In: Phrack 10.56 (Januar 2000). http://www.phrack.org/issues/56/5.html#article. Hier ist beschrieben, wie man den Schutz mittels Canary Word neutralisiert.
- Mark Ludwig. The Little Black Book of Computer Viruses. American Eagle Publications, Inc., 1991. Wenn Sie ein bisschen mehr darüber erfahren wollen, wie Computerviren funktionieren, dann sollten Sie einmal dieses Büchlein konsultieren. Es dürfte heutzutage nur noch von historischem Interesse sein.
Übungsaufgaben
- Schützen Sie die angreifbare Funktion im Programm 11.3 durch ein Canary Word. Dazu müssen Sie den Quelltext mit dem Schalter
-fstack-protectordesgccübersetzen. Was geschieht nun beim Überlauf? - Schreiben Sie ein Programm, das die Adresse von
main(), die Adresse einer globalen Variable (die somit im Datensegment liegt) und die Adresse einer auf dem Stack befindlichen lokalen Variable nachstdoutschreibt. Als Ausgangspunkt können Sie Listing 11.4 nutzen. Nach der Ausgabe soll ein Sohn erzeugt werden, der sein Programmabbild mittelsexecl()mit dem eigenen Code überlagert, während der Vater endet. Was stellen Sie fest? -
Vervollständigen Sie das Programm
auth.cmit der folgenden Implementierung vonmy_getpass():
Listing 11.7: Funktion zum Einlesen einer Passphrase
Zusätzlich benötigen Sie noch die Headerdatei
mycrypt.h, die Sie in Listing 11.8 finden.
Listing 11.8: Gemeinsame Headerdatei (mycrypt.h)
- Implementieren Sie ein Werkzeug, um die Passwortdatei für
auth.canzulegen. Das Löschen eines Nutzers muss nicht explizit programmiert werden, man kann ja einfach die entsprechende Zeile aus der Passwortdatei löschen.