Theories of speech perception attempt to explain how human listeners decode an acoustic waveform into those linguistic units they believe were intended by the speaker. Such theories attempt to answer two questions:
Because spoken communication consists of at least two participants – a speaker and a listener1 – there are two domains that have to be considered by any theory of speech perception: One is the articulatory or gestural domain which is tied directly to the physiology of the speech mechanism any speaker uses to produce speech sounds, including both the vocal tract and the neural structures that regulate it. The second is the auditory domain where the acoustic signal is transduced to an auditory representation that ultimately maps to the linguistic message that is ideally a close match to what the speaker intended. Although the term speech perception refers to a process that takes place in the listener, we cannot overlook the speaker’s role: The speaker must first encode linguistic units to an acoustic waveform that a listener can decode.
Many theories of speech perception suggest that these two processes – encoding and decoding – are strongly related in some way; linguistic units have to be mapped both to and from an acoustic waveform. Some of these theories suggest that one of these pathways is much simpler and more direct than the other and that linguistic units are mapped to either auditory representations or articulatory gestures without any direct reference to the other.
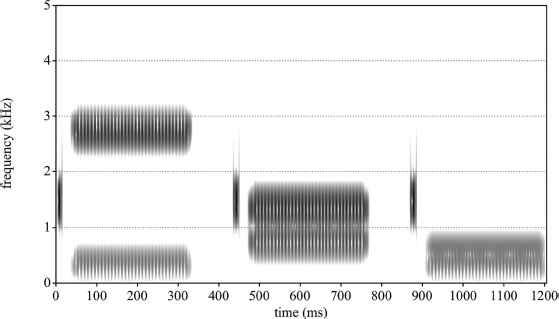
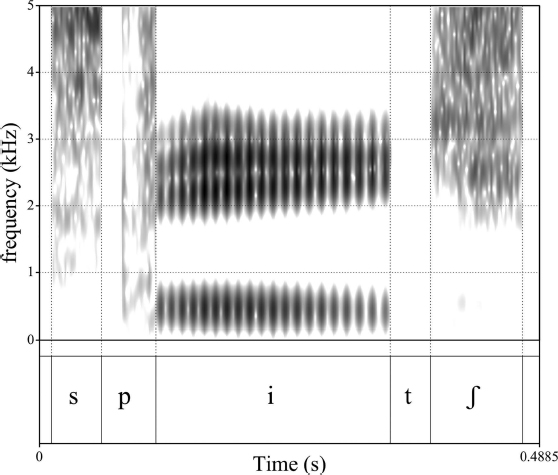
The spectrogram in Figure 11.1 is a visual representation of the word “speech.” A spectrogram is a spectrotemporal representation of a recorded sound that shows acoustic energy as a function of time along the x-axis, frequency along the y-axis, and amplitude as the grayscale intensity with darker patches representing relatively greater energy. The process by which a spectrogram is generated is not unlike how the auditory system delivers sound to the brain: Sound energy is analyzed by overlapping bandpass filters and the fluctuations in energy within these bands are mapped to intensity levels as a function of both time and frequency. In the case of the auditory system, the bandpass-filter analysis is performed by the cochlea in which frequency-selective regions of the basilar membrane vibrate in response to incoming signals (Winn & Stilp, this volume). However, intensity level is mapped by the cochlea to neural impulses while, in the spectrogram, intensity is proportional to relative darkness of patches within the image.
Several pieces of information can be gleaned from the representation in Figure 11.1: The word-initial /s/ sound as well as the /ʃ/ at the end consist of largely high-frequency energy; the /p/ and /t/ sounds consist of a silent gap corresponding to closure at the lips or alveolar ridge, respectively. In the case of /p/, there is also a very brief noise burst and a period of noisy aspiration following closure. The vowel /i/ consists of mostly horizontal bands of relatively greater energy that correspond to formants or vocal-tract resonances – three such bands are visible: one below 500 Hz, and another two that appear almost merged above 2 kHz. The temporal extent of the speech sounds /s/, /p/, /i/, /t/, and /ʃ/ are not difficult to determine and their boundaries are also illustrated in the figure.
The prevailing view among many researchers is that the primary goal of speech perception is the correct identification of these individual speech sounds (although this view may, in itself, be too simplistic; Kluender & Kiefte, 2006; Kluender, Stilp & Kiefte, 2013). In addition, it is widely believed that the formants that extend throughout the duration of, e.g., /i/ in Figure 11.1 are also important in speech perception – not just for vowels but also for the adjacent consonants as well (see Kiefte, Nearey & Assmann, 2012, for a review). Throughout this chapter, we expand on these views.
How are these acoustic properties used by listeners to decode the acoustic waveform into something meaningful like the word “speech”? Can individual linguistic units be identified by matching the acoustic properties of the incoming sound directly to some internal representation? How does this internal representation relate to the physical properties of the speech sounds themselves? For example, is this internal representation defined by acoustics or the output of peripheral auditory structures? Or does the perceptual system first map the acoustic waveform systematically to articulatory patterns of a (real or virtual) vocal tract resembling those used by the speaker, which are, in turn, translated to an estimate of the intended speech sounds? Another possibility is that this internal representation is a compromise between auditory/acoustic and articulatory properties and that the direct relationships between these two domains can serve as important perceptual correlates. Since it is assumed that both speakers and listeners are in possession of a vocal tract capable of speech production through basic physiologic processes, it may seem reasonable that the first stage of speech perception is to map the acoustics onto the articulations that were used to generate them and then to identify individual speech sounds on the basis of those articulations. However, this analysis by synthesis is by no means straightforward. Conversely, if speech sounds are more directly represented by acoustics, then the speaker must determine the sequence of articulations that most closely produces the desired waveform which may also be a highly complex process.
Each of these positions suggests a tradeoff in the complexity of perception and production. If speech sounds are mapped directly to acoustic waveforms then it is the job of the speaker to navigate the complex relationship between articulation and acoustics. On the other hand, if speech perception is somehow mediated by articulation, then the listener must refer to a model of either the human vocal tract or neurological motor commands in order to map acoustics to the articulations intended by the speaker. The distinction between these two ideas lies primarily in how speech is represented in the mind of the listener. However, a third possibility is that the relationships or mappings between acoustics, perception and articulation are all relatively straightforward and that it is the job of speech researchers to discover these relationships. Intermediate positions also exist: It is also possible that all of these are true under certain circumstances and that listeners can make use of several types of information when decoding the speech signal.
An additional issue is whether there is perhaps a “special” phonetic mode of processing in either the articulatory or perceptual domain or whether the perceptual processes involved in human speech perception are based on fundamental psychoacoustic phenomena that are exploited in other domains. If it is the case that speech perception makes use of fundamental psychoacoustic processes that are well documented in other areas of perception, then there may be no need to suggest that there is something special or unique about speech perception that makes it fundamentally different from other types of auditory perception.
In this chapter, we give a broad overview of the theories that attempt to explain how the acoustic signal is converted into a linguistic message by the perceptual system of the listener. We will also provide a review of some of the perceptual phenomena that have influenced the development of these theories and which have been taken as key evidence for one or another.
In the following sections, we first describe evidence that the fundamental units of perception are basic speech sounds or phonemes which are a small finite set of building blocks from which all words or morphemes can be assembled. Then we explore some of the speech-related phenomena that theories of speech perception must address with respect to these building blocks – namely, context sensitivity, lack of invariance, and segmentability, which are all closely related. We will see that the acoustic and articulatory consequences of these basic linguistic units are widely overlapping in time: A given speech sound changes depending on the context in which it occurs, and acoustic correlates to individual speech categories can be shared between multiple speech sounds. Finally, we explore several theories of speech perception that attempt to explain how human listeners convert an acoustic signal into something potentially meaningful in spoken communication. Our discussion builds toward a discussion of both articulatory/gestural and acoustic/auditory perspectives and ends by advocating a “double-weak” approach wherein speech is viewed as being shaped by a kind of compromise between constraints on gestural and auditory complexity.
A common view among researchers is that the goal of human speech perception is to correctly identify some basic units of speech that are combined to make utterances. We referred to these units as “speech sounds,” but what exactly are these basic units that are being transmitted from speaker to listener? Are they whole phrases, words, speech sounds or phonemes, or something even smaller, such as some fundamental acoustic or phonetic features?
In written language, a simplistic view is that the basic units or symbols of writing are letters or graphemes that can be assembled into arbitrarily long words or sentences. For example, in English, there are 26 small combinational units that can be rearranged to form novel, never-before-seen messages that can be reliably interpreted and repeated by a reader. In speech, we can understand novel phrases and sentences that violate basic grammatical rules such as cat the dog bark jumped which suggests that longer utterances can be composed from discrete words that can be rearranged at will and still be reliably repeated by a listener (even if they do not make sense). Likewise, we can hear and repeat well-formed nonsense words that have never been heard before, constructed by joining basic speech sounds or phonemes. We can invent novel words, such as plim /plɪm/, that listeners can reliably transcribe, either orthographically or phonetically. This can only be possible if we assume that basic speech sounds that correspond to, for example, /p/ or /l/, can be recombined to form words or syllables. However, due to coarticulation and lack of acoustic invariance as discussed in the following, the acoustic signal cannot be disassembled and rearranged as easily as can letters on a page (Harris, 1953; Cooper, Gaitenby, Mattingly & Umeda, 1969).
At a more fundamental level of linguistic description, listeners cannot, in general, understand new phonemes formed by altering or rearranging more basic acoustic properties. Studies have shown that adult listeners are not well suited for discriminating speech sounds that they have never heard before and which do not form part of their native phonology. For example, teaching new phonemic contrasts to second-language learners often poses challenges as the speech sounds of their native language interfere with both perception and production in the new language. Past the critical period of speech development, our perceptual systems are largely locked into a phonemic system specific to a native language (Flege, 1995; Best, 1995; Chang, this volume).
One theory of speech perception does, however, suggest that the fundamental units of speech are indeed very small and very general and that infants are tuned to these properties during the so-called critical period of language development (e.g., Stevens, 1989; Stevens & Keyser, 1989; Stevens & Blumstein, 1981). This small set of units, or distinctive features, are posited to be universal across all languages and are associated with well-defined psychoacoustic properties. On the opposite extreme of the theoretical spectrum, it has been suggested that speech perception is mediated by memory traces of previously heard utterances stored in an episodic lexicon which may consist of units as large as words or short phrases and that novel utterances are identified with reference to this broad store of acoustic experience (e.g., Goldinger, 1997; Johnson, 1997; Pisoni, 1997).
An intermediate view is that basic units of speech perception correspond to simple speech sounds such as /p/ or /u/. Although these symbolic units may have a fairly complex relationship to more fundamental acoustic elements, they are otherwise more general than the stored acoustic waves in an episodic lexicon (Nearey, 1990, 1992, 1997a, 1997b). Although speakers can rearrange these phonemes to form novel words or syllables, it is not the case that the acoustic waveforms corresponding to those phonemes can be arranged and rearranged by simply splicing them together.2 It is well known that the acoustic properties associated with phonemes are widely overlapping in time (see the following). However, if we accept a theory of speech perception that posits phonemes as the fundamental symbolic units of speech, then we must also believe that there is a way for the auditory system to extract acoustic properties associated with different phonemes from widely overlapping acoustic segments.
There is good evidence that phonemes are the fundamental units of speech perception. It is known from early work in telecommunications that the correct identification of nonsense syllables over a noisy telephone channel can be predicted directly from the correct identification of the individual phonemes that make up the syllables themselves (see Allen, 1994; Fletcher, 1995). These syllables consisted of all possible combinations of consonant-vowel-consonant (CVC) sequences. It was found that the likelihood that a CVC syllable was correctly identified by a listener was the product of the likelihoods of the individual phonemes being correctly identified. This entails that the perception of individual phonemes is statistically independent, indicating that listeners identify syllables on the basis of their individual phonemes.
Although this observation holds true for nonsense syllables, it does not hold for real words and sentences. If listeners are presented with a mix of real and nonsense words in an open-set situation (e.g., “Write whatever you hear”), high-frequency real words are identified better than low-frequency ones, and those are better identified than nonsense words (Boothroyd & Nitrouer, 1988). However, the advantage of high-frequency real words can be eliminated altogether if listeners are presented with a closed-set choice, even with a very large number of possible items (Pollack, Rubenstein & Decker, 1959). A possible explanation for this range of behavior is that frequency effects and phonotactic patterns provide a kind of a priori bias toward certain words, even in the absence of any reliable sensory information. However, these biases are relatively labile and are not deeply wired into the representations themselves (for more discussion, see Bronkhorst, Bosman & Smoorenburg, 1993; Nearey, 2001; Luce & Pisoni, 1998; Broadbent, 1967).
Although Figure 11.1 seems to indicate that the temporal extent of individual phonemes is well defined, the waveforms associated with these speech sounds cannot be rearranged arbitrarily in a manner akin to an acoustic typewriter. For example, Mermelstein (1978) conducted an experiment with synthetic /bVC/ syllables, where the vowel ranged from /æ/ to /ɛ/ in the peak frequency of the first formant (F1), while the consonant ranged from /t/ to /d/ in the duration of the vowel. Thus, the acoustic properties within the temporal extent of the vowel determined the identification of both the vowel itself as well as the following consonant. Indeed, when listeners identified these stimuli as one of bad, bed, bat, or bet, it was found that both F1 and vowel duration influenced the identification of both the vowel and the consonant.
On the surface, the fact that the acoustic properties of the vowel determined the perception of both the vowel and the consonant appears to contradict the results of Fletcher (1995), who found that the perception of individual phonemes is statistically independent. Nonetheless, Nearey (1990, 1997b) found that stimulus properties produced statistically independent changes in the identification of consonants and vowels. Although there were response biases favoring bat and bed, these biases may be attributed to lexical or phonotactic frequency (inter alia, Nearey, 2004). When these bias effects are accounted for, listeners’ identification of the vowel and consonant were still independent.
However, although the identification of individual phonemes is statistically independent, the acoustic information associated with each speech sound is still overlapping in time. Speech sounds are not “beads on a string” that can be rearranged in a manner similar to acoustic anagrams (e.g., Stetson, 1945). In the preceding example, exchanging vowels between words will also affect the perception of the final consonant. This overlap in acoustic information is seen as a problem of segmentation – i.e., speech sounds cannot be segmented from the waveform without potentially losing or distorting information.
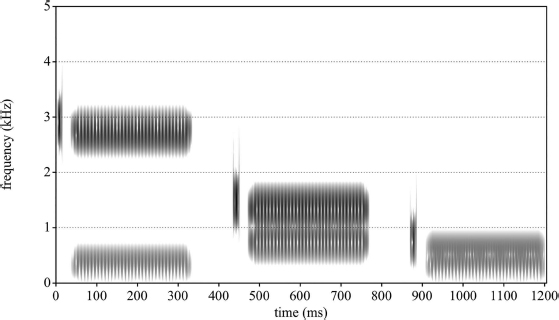
The fact that the acoustic counterparts of phonemes change depending on their context indicates that phonemes are not invariant. As one of the most influential publications in speech-perception research, a classic example of this was given by Liberman, Delattre and Cooper (1952) in their report on the identification of synthetic, voiceless stops in CV syllables. These syllables were generated by the Pattern Playback, which was capable of converting spectrograms – either photographic copies or hand-painted patterns – into sound (Cooper, 1950; Cooper, Delattre, Liberman, Borst & Gerstman, 1952). Liberman, Delattre & Cooper examined the perceptual effects of the initial stop bursts associated with the voiceless plosive consonants /p/, /t/, and /k/ by parametrically manipulating their spectral properties. A spectrogram of synthetic sounds similar to those used in the original study is given in Figure 11.2. When played, the stimuli approximate the sounds /pi ka pu/, despite the fact that the burst for all three syllables is completely identical. Specifically, the same burst is heard as /k/ before /a/, but as /p/ before /i/ and /u/.
In order to hear /k/ before either /i/ or /u/, instead of /p/, Liberman, Delattre and Cooper (1952) found that the center frequency of the burst had to be just higher than the frequency of F2 of the following vowel, as illustrated in Figure 11.3.
This context dependence, or lack of invariance – i.e., the fact that the same acoustic waveform is identified as different speech sounds or that the same speech sound has very different acoustic properties depending on its surrounding context – has often been presented as a demonstration of the highly complex relationship between acoustics and perception of the speech signal: e.g., not only does place perception depend on the center frequency of the burst but also on the vowel context in which the burst occurs.
Two distinct acoustic properties in possibly non-overlapping time frames that correlate with the perception of the same phonetic contrast are said to share a trading relation. For example, the voicing distinction between, e.g., /b/ and /p/ correlates with voice onset time (VOT),3 frequency of F1 onset and frequency of voicing (f0) for syllable-initial stops. For syllable-final stops, it also includes duration of the preceding vowel, while for intervocalic stops, it includes silence duration and the presence or absence of voicing during the closure interval (Repp, 1982). Changes in any one of these acoustic properties can result in a change in phonemic category. Additionally, changes in one of these properties can compensate for changes in another: For example, a longer closure duration is required to perceive a consonant as voiceless when voicing is present during closure than when it is not (Parker, Diehl & Kluender, 1986).
These complex patterns of context dependence encouraged models of speech perception that proposed “decoding” of the speech signal via speech production mechanisms (Liberman, Cooper, Shankweiler & Studdert-Kennedy, 1967). Other models of speech perception are able to capture some complex context dependency as well without reference to articulation (Nearey, 1990). While the data reported by Liberman, Delattre & Cooper might appear to be difficult to model using simple statistical methods, the original experiment (by Liberman, Delattre & Cooper, 1952) was replicated by Kiefte and Kluender (2005a) who found that, although there was clear context dependence for the perception of the initial consonant, it was not nearly as complex as originally found, and listeners’ perception could be modeled adequately in terms of the acoustic properties alone.
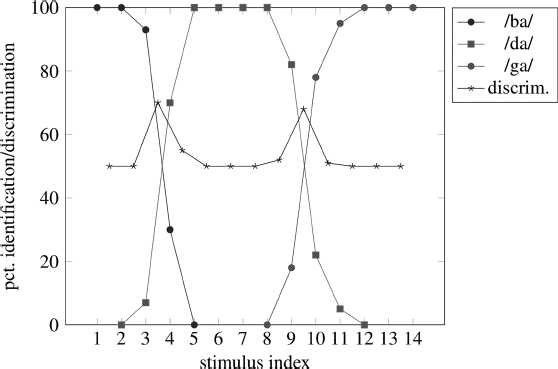
Problems of segmentability and lack of acoustic invariance are addressed to varying degrees by theories of speech perception. Another phenomenon that has been addressed by such theories is categorical perception, whereby listeners’ ability to discriminate similar stimuli that differ in a single dimension along an acoustic continuum is determined largely by whether they label those stimuli as different categories. To demonstrate this phenomenon, two experiments are conducted: identification and discrimination. In the identification experiment, listeners are simply asked to identify each stimulus as one of a small number of categories: e.g., /ba/, /da/, or /ɡa/. In the discrimination experiment, listeners hear pairs of stimuli that are adjacent or nearly adjacent along the acoustic continuum and indicate whether they are same or different.4
Liberman, Harris, Hoffman and Griffith (1957) reported that when people listen to speech-like sounds that vary along a continuum of onset-F2 transitions from /ba/ through /da/ to /ɡa/, they were much less able to hear differences between similar stimuli in those cases where they labeled both stimuli as belonging to the same category (e.g., both /ba/). However, if listeners tended to label them as different categories – e.g., one as /da/ and the other /ɡa/ – they could easily distinguish them. Another way to explain this phenomena is to imagine a boundary between each pair of adjacent categories /ba/–/da/ and /da/–/ɡa/: on one side of a boundary, listeners in the identification experiment are more likely to label the stimulus as, e.g., /ba/ and on the other side of the boundary, listeners identify the stimulus as /da/. If two stimuli fall on the same side of the boundary, however, listeners have greater difficulty distinguishing them even if the absolute differences in the stimulus property between each pair are the same. The consequences of this are that listeners’ sensitivity to acoustic properties is nonlinear – i.e., equivalent changes in acoustic parameters are not heard as equivalent intervals by listeners.
Liberman et al. (1957) and Eimas (1963) found that listeners’ ability to discriminate stimulus continua was just slightly better than could be predicted on the basis of identification responses alone – i.e., discrimination was much better across phoneme boundaries than within a single speech category. Eimas showed that this phenomenon was not found with non-speech stimuli and was therefore peculiar to speech perception. Similarly, McGovern and Strange (1977) found that a /ra/–/la/ continuum in which F3 was varied was perceived categorically. However, if all but the third formant was removed from the stimuli, not only were the resulting sounds not heard as speech, but the stimuli were discriminated continuously instead of categorically. We return to these issues below.
In general, non-speech stimuli are perceived continuously in that listeners’ sensitivity to small acoustic differences does not vary non-linearly across a continuum. Two conclusions were drawn from this (Liberman & Mattingly 1985). First, because this phenomenon only occurred with speech-like stimuli, it was thought that categorical perception could not be explained by general auditory processes. Second, it was thought that nonlinear discriminability in speech sounds reflected vocal-tract discontinuities between, e.g., different places of articulation, and it was therefore presumed that perception reflected these discontinuities. Because the presentation of speech stimuli resulted in discrimination behavior that was strikingly different from that found with non-speech tokens, many researchers were led to believe that a distinct neural structure existed for the sole purpose of decoding speech into phonetic units and that these structures were entirely separate from other forms of auditory perception. It was therefore suggested that categorical perception was unique to speech, and this fact was used as evidence in favor of the Motor Theory of Speech Perception, which posits that speech perception was somehow mediated by articulation.
According to the Motor Theory of Speech Perception, the reason listeners are more sensitive to differences between stimuli that represent different speech categories, such as /ba/ and /da/, or /da/ and /ɡa/, is that their perception of speech sounds is mediated directly by articulation. Although the stimuli may appear to vary continuously and linearly in the acoustic domain, the range of articulations required to produce those sounds is highly nonlinear. For example, the differences between /ba/ and /da/ are thought to be very large in terms of production, while differences between different articulations of /ba/ are relatively small.
Some researchers thought that categorical perception was a learned phenomenon – in the process of experimenting with their own vocal tracts through babbling, infants would learn the simple mapping between articulation and speech sounds. Although infants cannot label speech sounds directly, there are several techniques to determine if they can discriminate speech stimuli. For example, when a long series of stimuli are presented and which suddenly change by some small acoustic parameter, an infant who detects the difference might show an increase in sucking rate on an electronic pacifier – a technique known as the high-amplitude sucking (HAS) paradigm. Using this technique, Eimas, Siqueland, Jusczyk and Vigorito (1971) demonstrated that infants showed discrimination abilities that mirrored those of adults – i.e., they showed more sensitive discrimination for speech sounds that were in different categories. The fact that infants as young as one month exhibited this pattern of discrimination further suggested that, rather than being learned from experience with one’s own vocal tract, speech perception resided in some special speech processing mechanism that was innate and special to humans (Liberman & Mattingly, 1985). This also resolved the problem of how nonverbal listeners could understand speech without the advantage of using their own speech in order to learn the mapping between articulation and speech sounds. However, we note in the following section that animals can also be trained to respond to speech stimuli in a manner similar to categorical perception, which suggests that this phenomenon does not, in fact, reflect any innate abilities in humans.
If, as suggested previously, the goal of speech perception is the correct identification of phonemes or simple speech sounds, then the next important question that must be answered by any theory of speech perception is how the acoustic signal relates to these fundamental symbolic units of speech (here, and in the next few sections, we adopt the overall taxonomy of Nearey, 1997b).
Three important observations led to what is now referred to as the Motor Theory of Speech Perception (Liberman, Cooper, Shankweiler & Studdert-Kennedy, 1967). First, the same sound can lead to the perception of different phonemes, depending on the context in which it occurs (e.g., Figure 11.2). Second, different sounds can lead to the perception of the same phoneme, again depending on the context in which it occurs (e.g., Figure 11.3). Finally, sensitivity to stimulus differences in speech sounds is highly nonlinear and is largely determined by listeners’ ability to label phonemic categories that differ substantially in articulation.
Early attempts to find invariant acoustic counterparts to speech categories met with failure, and it was ultimately concluded that the relationship between perception and articulation may be simpler and more direct than that between perception and acoustics (e.g., Cooper, Delattre, Liberman, Borst & Gerstman, 1952). This was largely inspired by the complex mapping of relevant acoustic cues to particular phonetic distinctions that could only be understood with reference to their articulatory source (e.g., Liberman & Mattingly, 1985; Repp, 1982). The proposed simple relationship between perception and articulation was partly inspired by the context sensitivity of observed acoustic properties and the assumed context-invariance of articulation. It was therefore suggested that basic symbolic units or phonemes corresponded more closely to the articulatory or gestural domain.
Further examples of the segmentability problem and the lack of acoustic invariance are found in the voicing distinction in English CV syllables consisting of a plosive followed by a vowel: If the VOT is negative or zero, listeners generally perceive the plosive as voiced. However, listeners will also hear the plosive as voiced if the first formant or fundamental frequency has a low-frequency onset. Proponents of the Motor Theory have interpreted this relationship as the byproduct of relatively simple glottal gestures and, if the listener maps the acoustic signal to these relatively simple gestures, then the identification data can more easily be explained (see Kingston & Diehl, 1994, for a review).
As another example, the action of pressure release by the tongue dorsum at the velum or soft palate is generally heard as /ɡ/ or /k/, regardless of the vowel that follows it. This simple relationship was clearly not evident between acoustics and perception (see Figures 11.2 and 11.3). Experiments showed that there was often a many-to-one or a one-to-many mapping between a perceived consonant and its associated acoustic stimulus parameters. For example, it was observed that the same burst centered at 1400 Hz was heard as /p/ before /i/ and /u/, but as /k/ before /a/ (Liberman, Delattre & Cooper, 1952; Schatz, 1954). Conversely, different bursts for /k/ were required before different vowels to generate a velar percept (Liberman, Delattre & Cooper, 1952). Although it has been suggested that the movement of the oral articulators can be perceived directly [e.g., Fowler’s (1986) direct realist approach to speech perception], Liberman, Cooper, Shankweiler and Studdert-Kennedy (1967) instead claimed that the invariant component of speech was somehow encoded into the acoustic signal in a relatively complex manner.
Several observations were used to further illustrate the complexity of the acoustic signal relative to the articulations that produce it. First, a stream of “building blocks,” in which discrete acoustic segments represented unique units of speech, would be very difficult to understand at the rates needed for the perception of continuous speech (cf. Liberman, 1984); communication by such means would be no more efficient than Morse code. In addition, basic acoustic properties typically associated with individual phonemes are in fact widely overlapping in natural speech. For example, we find acoustic properties relevant to the place of articulation of prevocalic stop consonants in the burst, formant transitions, and vowel formants, while vowel information can be found in the formant transitions and vowel formants. This lack of phoneme segmentability was seen as a consequence of the relative efficiency with which speech could be transmitted acoustically – i.e., several speech units could be conveyed simultaneously at any given moment.
The second observation that illustrated the complexity of the acoustic signal relative to its articulatory source and its perceptual representation was the nonlinear mapping between articulation and acoustics on the one hand, and the nonlinear mapping between acoustics and perception on the other. As has already been shown, very different stimuli are heard as the same speech unit. Although formant transitions for – e.g., /di/ and /du/ – are quite different (onset F2 rising and falling respectively), they are nevertheless perceived as the same consonant.
Several other pieces of evidence were presented in support of the Motor Theory: Liberman, Isenberg and Rakerd (1981) demonstrated that when a speech stimulus was split into two parts and presented to different ears over headphones, the listeners hear one speech sound resulting from the integration across both ears as well as a non-speech sound. For example, if a single formant transition from a CV syllable is presented separately to one ear while the remaining stimulus, without that formant, is presented to the other, listeners hear both the original, integrated syllable and a chirp-like sound resulting from the isolated formant transition. Proponents of the Motor Theory took this as evidence that a special speech processor in the brain fuses speech-like stimuli, while a non-speech auditory module also processes the formant transition heard as a chirp.
Evidence for a special speech module in perception was also seen in what is now referred to as the McGurk effect: When the sound /ba/ is dubbed over a video of someone saying /ɡa/, the combined audiovisual stimulus produces the percept /da/. The fact that listeners perceive neither /ɡa/ nor /ba/ suggests that the audiovisual experience is processed in a special speech module and that listeners are attempting to determine speech gestures from the conflicting stimuli (McGurk & MacDonald, 1976). Thus, perception is neither completely auditory nor visual, but rather what is perceived is the (distorted) articulation itself.
However, the relationship between gestures and acoustics as suggested by the Motor Theory is not so straightforward; for example, the articulatory targets for the same vowel are quite varied across speakers (Ladefoged, DeClerk, Lindau & Papçun, 1972; Nearey, 1980; Johnson, Ladefoged & Lindau, 1993). Perkell, Matthies, Svirsky and Jordan (1993) have also shown that wide variation in tongue and lip position in the production of the vowel /u/ seems motivated by the production of a consistent acoustic output instead of a stable articulatory target. Some speakers appear to use varying articulatory means to achieve a relatively constant acoustic end in different phonetic contexts. Therefore, many have argued that, at least for some classes of sounds, the acoustic output produced by those gestures is much more invariant than the gestures themselves and that linguistically relevant properties are acoustic rather than gestural. If we assume that the auditory processing of acoustic events is relatively straightforward, then listeners may rely on the acoustic relationships to phonemes instead.
One of the early assumptions of the Motor Theory was that, even if acoustic properties are not invariant, articulations or gestures are. However, the lack of structural independence between articulators and coarticulation effects complicated the notion of articulatory invariance, which was only relatively obvious for bilabials such as /p/, /b/, and /m/. Liberman, Cooper, Shankweiler and Studdert-Kennedy (1967) therefore proposed that the neuromotor rules – or the neural signals that were used in production – held this simple one-to-one relationship with perception. This was viewed as advantageous since the listener could use the same neural mechanisms designed for speech production to decode the acoustic signal in perception, and it was suggested that perception was mediated in some way by these neuromotor correlates to articulatory gestures. The neural commands were assumed to be invariant across all contexts, despite the observed context dependencies found in acoustics and articulation. As more evidence was obtained regarding the exact nature of the neural mechanisms used in speech, the specification of invariance was weakened to merely the gestures intended by the speaker. For example, it was known that even a simple articulatory movement, such as the raising of the tongue dorsum to make contact with the velum, was the result of several complex neural commands. Such complexities were eventually accommodated by a form of Motor Theory that also strengthened the idea that speech processing was innate rather than learned and that speech perception was performed by a specialized speech module (Liberman & Mattingly, 1985). Motor Theory still maintained that perception and production are intimately linked.
In the last two decades, some results from neurophysiology have been interpreted by some as supporting a version of Motor Theory. It was discovered that neurons in the ventral premotor cortex of monkeys are active both when the monkey grasps an object as well as when it observes someone doing so (Rizzolatti & Arbib, 1998; Rizzolatti & Craighero, 2004). These neurons are referred to as mirror neurons; although they are primarily responsible for the regulation of motor commands, they also respond to the perception of those same actions and it was suggested that similar mirror neurons may play a role in speech perception, particularly within the framework of Motor Theory (Rizzolatti & Arbib, 1998; Lotto, Hickok & Holt, 2009). A similar result was later observed when the sound of an action resulted in an activation of the motor neurons associated with performing the action that produced the sound (Kohler, Keysers, Umilta, Fogassi, Gallese & Rizzolatti, 2002). Therefore, these mirror neurons may represent the “missing link” between perception and production postulated earlier by Liberman and Mattingly (1985).
Although proponents of the Motor Theory maintained that the objects of perception were the intended gestures of the speaker, the issue of exactly how the perceptual system recovers these gestures from the waveforms has never been resolved (Kluender & Kiefte, 2006; Galantucci, Fowler & Turvey, 2006; Massaro & Chen, 2008). Therefore, much of the simplicity and elegance of the Motor Theory lies in the fact that the precise mechanism whereby listeners identify the symbolic units of speech is largely abstracted or completely ignored.5
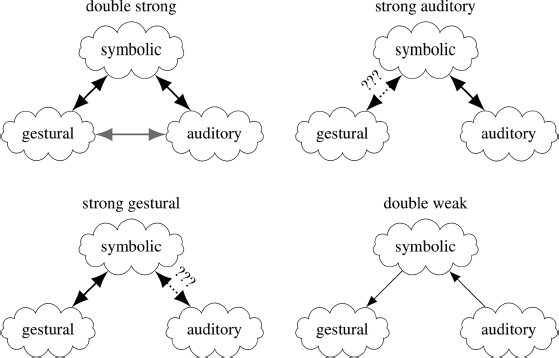
Nearey (1992) refers to Motor Theory as a strong gestural position because of the strong links that are postulated between perception and articulation (see Figure 11.5). However, other theories regarding the relationship between articulation, auditory processing, and the symbolic units of language have been proposed as well. The next section presents strong auditory accounts which instead postulate a strong relationship between the auditory domain and perception.
Although Motor Theory claims that there is a direct relationship between speech sounds and the intended gestures of the speaker, Kingston and Diehl (1994, 1995) have argued that a number of properties claimed to be the natural fallout of the biophysical interaction of gestures instead result from deliberate, controlled actions (see also Diehl & Kluender, 1989). Specifically, they argue that many properties that may seem at first to simply covary automatically in production are, in fact, actively managed to produce an enhancement of the resultant auditory-perceptual properties. This perspective is described further in the following section.
In auditory theories, it is assumed that there is a much stronger relationship between phonemes and basic auditory properties and that the identification of these linguistic units can be understood in terms of basic psychoacoustic processes that can be attested in other areas of auditory perception. Much of the evidence presented supporting Motor Theory was focused on the lack of acoustic invariance for coarticulated speech sounds such as CV syllables.
However, based on the Acoustic Theory of speech production, Fant (1970) suggested that a syllable-initial consonant could be identified from the release burst and the first few milliseconds thereafter, irrespective of coarticulatory effects. Several authors have taken this view and have subsequently proposed a set of cues based on grossly defined spectral properties. They also presuppose a direct and simple relationship between articulation and acoustics as well as between acoustics and perception. Expanding on these ideas, Stevens and Blumstein (1978) suggested that simple spectral properties drawn from brief frames of the waveform can contain context-invariant information regarding, e.g., stop-consonant-identity information (Stevens & Blumstein, 1978; Blumstein & Stevens, 1979). For example, they suggested that the stop burst and a very brief segment of vocalic formant transitions form a single integrated acoustic property that is essentially invariant within places of articulation: Bilabial releases were characterized by low-frequency formant energy resulting in a downward tilt in spectral shape; alveolar articulations were characterized by higher-frequency energy which resulted in a rising spectral tilt; and for velars, there should be a relatively pronounced peak of energy in the mid-frequency range, whereas bilabial and alveolar spectra were more diffuse. Hence it was thought that place of articulation could be discriminated entirely on the basis of very simple spectral parameters or templates without any need to refer directly to articulatory gestures. Blumstein and Stevens (1980) further suggested that even the deletion of release bursts which may occur for voiced stops or in rapid speech still does not substantially change these invariant global spectral properties.
Moreover, Stevens and Blumstein (1978) claimed that these templates reflected the articulatory configuration of the stop consonants at the moment of release. They proposed that not only do these acoustic properties have a direct one-to-one relationship with phonemes, but that they also have a simple one-to-one relationship with articulations. Nearey (1992) refers to this class of hypotheses as double strong theories because of the assumed direct links between all three domains: gestural, auditory, and phonemic (see Figure 11.5).
However, this model completely ignores contextual variability that is present in speech (e.g., Suomi, 1985). In particular, formant transitions between the release burst and the following vowel are determined by the identity of both the consonant and the vowel (e.g., see Sussman, Fruchter & Cable, 1995, for a review of locus equations which describe the correlation between formant frequencies at voicing onset and those of the following vowel). The position taken by Stevens and Blumstein (1978) was that these transitions serve no direct role in speech perception beyond what was abstracted into spectral templates and, similar to Cole and Scott (1974), they went on to suggest that the primary role of these formant transitions was to provide information regarding the temporal order of phonetic segments and to smooth out acoustic discontinuities between phonemes.
Similar to Stevens and Blumstein (1978) and Blumstein and Stevens (1979), Kewley-Port (1983) and Kewley-Port and Luce (1984) characterized stop consonants in terms of the global spectral tilt and compactness at stimulus onset. However, they also included time-varying relational acoustic features that spanned 20–40 ms beyond closure release which also included information regarding voicing as well as formant transitions. Based on the measurement of natural stimuli, as well as the results of synthesis experiments, Lahiri, Gewirth and Blumstein (1984) similarly concluded that it was not the absolute global spectral shape of the first few tens of milliseconds, but rather the relative change of this property over time that was best able to discriminate places of articulation. For example, it was hypothesized that there was a smaller change in high-frequency energy between the burst onset and the onset of voicing for alveolars than for bilabials.
Stevens (2002) proposed a model of speech perception in which words were specified by sequences of discrete symbols (phonemes) and that these speech categories were themselves described by relatively simple elements that were specified directly, both in terms of simple acoustic templates and gestures. Stevens (1989) had already suggested that vocal-tract gestures could be subdivided into discrete configurations and that small articulatory maneuvers can result in large changes in the acoustic output. He also added that there were broad regions of acoustic stability in vocal-tract configurations that speakers could exploit in speech production and that these regions corresponded to relatively invariant acoustic outputs. Further, because this acoustic model of speech perception relied on spectral templates that were so broadly defined that they could abstract away context sensitivity resulting in a highly schematized invariance, Stevens (2002) suggested that speech sounds could be aligned to acoustic landmarks such as abrupt onsets of energy or sudden changes in spectral composition.
This model was also heavily influenced by the notion of binary distinctive features in phonology (Halle & Stevens, 1991), which are a small set of universal properties that are sufficient to define all speech sounds of any human language. This notion of universal distinctive features suggests that phonemes are not arbitrarily different from one another, but vary along a small set of dimensions with the additional constraint that each of these dimensions can only have one of two values: present or absent. Although these features are often described in terms of articulation (e.g., coronal, voiced), it has been shown that perceptual errors most commonly occur along those dimensions as well (e.g., Miller & Nicely, 1955).
Although all of the observations described in the previous section showed some promise for invariant cues to speech categories in the acoustic waveform, none of the discussion so far has dealt with how these stimuli are processed by the auditory system. As mentioned previously, while the process of making a spectrogram is roughly similar to perceptual processing by the auditory periphery, its output is only a crude approximation of very first stages of neural encoding.
Several researchers have studied auditory-nerve responses to speech-like sounds (e.g., Young & Sachs, 1979; Sachs & Young, 1979; Recio, Rhode, Kiefte & Kluender, 2002). Much like the perception of speech by human listeners, Delgutte and Kiang (1984) found that these auditory-nerve responses are also context sensitive. For example, they found that the auditory-nerve responses to a recording of /da/ vary depending on the preceding context. The neurophysiological explanation for this phenomenon was short-term peripheral adaptation in which the response pattern of individual nerve fibers decays gradually over 100–150 ms – roughly the duration of a vowel. The effect of this adaptation is that spectral differences between adjacent segments of speech are enhanced by the auditory periphery. Delgutte, Hammond, Kalluri, Litvak and Cariani (1996) argued that these data demonstrate how adaptation serves to increase perceived spectral contrast between successive speech signals and that this effect enhances phonetically relevant spectral information.
Kluender, Coady and Kiefte (2003) and Kluender and Kiefte (2006) have suggested that the only information available to the auditory system is acoustic contrast. In support of this, they cite several studies demonstrating spectral-contrast effects between adjacent coarticulated consonants and vowels (e.g., Lotto & Kluender, 1998). For example, listeners are more likely to hear /dʌd/ than /dɛd/ when vowel-formant information (here, F2) is ambiguous. However, when the consonants are replaced with /b/, listeners are more likely to hear /bɛb/ than /bʌb/, even for exactly the same vowel, demonstrating a lack of acoustic invariance for these vowels. When consonants are replaced by sine-wave analogs that are not heard as speech sounds but which contain similar spectral information, the same vowel-identification bias occurs. Lotto and Kluender argue that spectral contrast between successive acoustic segments largely determines perception, irrespective of whether elements of the acoustic context are heard as speech. For example, the differences between the second formant of the consonant and the F2 of the vowel are perceptually exaggerated, resulting in more responses to /dʌd/ than /bɛb/, even when the second formant of the consonant is represented instead by a sinewave. Similarly, Stilp, Kiefte, Alexander, and Kluender (2010) demonstrated that a model of auditory contrast predicts changes in speech perception under several forms of acoustic distortion. Conversely, Darwin, McKeown and Kirby (1989), Watkins (1991), Watkins and Makin (1994), and Kiefte and Kluender (2008) demonstrated that listeners will ignore acoustic properties that do not change in a given acoustic context, even when those properties have been shown to be important for identification of speech sounds presented in isolation.
Kluender, Stilp, and Kiefte (2013) argue that examples that demonstrate a lack of acoustic invariance in speech result from the fact that the primary source of information in the speech signal is acoustic change and not absolute spectral properties. They further suggest that peripheral adaptation is one of the mechanisms by which the acoustic consequences of context sensitivity are decoded in auditory processing. For example, coarticulation increases acoustic similarity between neighboring speech sounds. However, peripheral adaptation emphasizes the remaining acoustic contrast such that perceived differences are magnified, thereby reversing the effects of coarticulation.
Kiefte and Kluender (2005b) further showed that listeners identify vowels primarily on the basis of changing acoustic properties and will ignore constant spectral characteristics (see Kiefte, Nearey & Assmann, 2012, for a review). This supports the view that changes in formant frequency are important in vowel perception. For example, Andruski and Nearey (1992), Nearey and Assmann (1986), and Hillenbrand, Getty, Clark and Wheeler (1995) showed that lax vowels, such as /ɪ/ and /ɛ/, may be characterized by the same magnitude of spectral change as observed for acknowledged diphthongs, such as /eɪ/. Later studies have shown that this vowel-inherent spectral change (VISC) is critical to vowel perception (e.g., Assmann & Katz, 2000).
If the lack of acoustic invariance for speech sounds is at least partly compensated for by relatively peripheral auditory structures, then these effects may not be specific to speech or even to human listeners. For example, Kuhl and Miller (1975) showed that when chinchillas6 are trained to identify naturally produced tokens of /ta/ and /da/, they learn to categorize the voicing distinction between /t/ and /d/ in a manner very similar to that of human listeners. Further, Kuhl and Padden (1982) found that Japanese macaques, a small terrestrial monkey, showed a pattern of discrimination of VOT in prevocalic stops that was very similar to what is found in human listeners in experiments of categorical perception. In this case, the perceptual boundary for VOT between voiced and voiceless stops is different for each of the three places of articulation, /ba/–/pa/, /da/–/ta/, and /ɡa/–/ka/ (see Watson & Kewley-Port, 1988, for a discussion of the controversy over importance of “auditory proclivities” versus learned patterns in human VOT perception for stop consonants). Without any innate capacity for human speech, the macaques showed increased sensitivity to small changes in voice onset time at each of those boundaries observed in human listeners. Although we cannot call this “categorical perception” as the monkeys did not actually label any stimuli, the fact that they showed increased sensitivity at boundaries between human phonemes suggests a biological predisposition to distinguishing speech sounds at those locations in the stimulus continuum and that these differences across consonant contexts must be due to neural processing shared between primates. Similar results were also shown for distinctions between /b/, /d/, and /ɡ/ by macaques along changes in onset frequency of F2 (Kuhl & Padden, 1983). Although no one has proposed a specific auditory mechanism that explains these patterns of classification, the fact that they occur across species suggests that it is not specific to speech processing by human listeners.
Kluender, Diehl, and Killeen (1987) showed that Japanese quail learn context variability similar to that illustrated in Figures 11.2 and 11.3. The birds were first trained to discriminate /b/, /d/, and /ɡ/ followed by one set of vowels and then tested on the same consonants when followed by a different set of vowels. Kluender, Diehl, and Killeen found that Japanese quail were able to generalize to the new vowel contexts despite context dependencies between consonants and vowels in CV syllables and even though the second set had never been heard before. In later experiments, Lotto, Kluender, and Holt (1997) found that quail compensated for coarticulation in /ar/ and /al/ before /ɡa/ and /da/ after being trained on /da/ and /ɡa/ in isolation. The authors concluded that there must be some very basic mechanism shared by the auditory systems of both birds and mammals that could account for this cross-contextual generalization.
So how are nonhuman animals able to unravel context sensitivity found in the speech signal? In direct opposition to the proposals laid out by proponents of the Motor Theory (Liberman & Mattingly 1985), Diehl and Kluender (1989) argue that the phonemic representation of the speech signal is primarily acoustic and that human listeners do not need to make reference to articulations or gestures to decode the speech signal.
Further, they claim that speakers, either directly or indirectly, enhance some of these auditory contrasts when speaking (Liljencrants & Lindblom, 1972). They note that in the vowel inventories of languages, vowels are maximally separated in formant frequencies to limit acoustic overlap. For example, in languages with only three vowels, vowel systems tend to consist of /i/, /a/, and /u/, which are the furthest apart that the human vocal tract will allow in terms of F1 and F2 frequency. For languages with five vowels, the additional vowels tend to be /e/ and /o/ which are acoustically intermediate. Further, the back vowels /u/ and /o/ are most frequently associated with lip rounding which lowers formant frequencies thereby increasing acoustic separation from the front vowels /i/, /e/, and /a/. In consonants, they also point out that differences in voice onset-time boundary between places of articulation serve only to maximize acoustic distinctiveness making it easier for both human – and nonhuman (e.g., Kuhl & Padden, 1982) – listeners to learn.
If the primary correlate to phoneme identity is auditory, it is then the task of the speaker to produce an appropriate acoustic signal that can be decoded by the auditory system of the listener. Diehl and Kluender (1989) point out that a number of examples of coarticulation are, in fact, deliberately controlled for the purpose of enhancing auditory contrast. In the last decade, researchers in neurophysiology have weighed in on the gestural versus auditory controversy from a new perspective (see Hickok, Houde & Rong, 2011, for discussion and extensive references to many aspects of the debate between proponents of these views of the primary “objects” of speech perception).
These auditory theories are contrasted with gestural theories in that they propose a strong relationship between the fundamental symbols of speech – i.e., phonemes – and basic acoustic properties whereas Motor Theory proposes a strong relationship between phonemes and the intended gestures of the speaker (see Figure 11.5).
All of these accounts, whether motivated by gestural or auditory processes, attempt to find invariant correlates to speech sounds in some domain of communication in the face of enormous context variability. In the case of Motor Theory, the invariants are to be found in the intended gestures of the speaker which must, somehow, be recovered by the listener. In auditory theories, the invariants are to be found in the outputs of fundamental auditory processes that are enhanced by this context variability, and it is the task of the speaker to produce these acoustic contrasts. Another position is that absolute invariants do not exist and that the trading relations or characteristic correlations between acoustic properties that are observed as part of these context effects are used directly in speech-sound identification (e.g., Lindblom, 1996).
In early experiments with the Pattern Playback, Cooper, Delattre, Liberman, Borst, and Gerstman (1952) and Liberman, Delattre, Cooper, and Gerstman (1954) found that listeners could identify /b/, /d/, and /ɡ/ from second-formant transitions from the onset of the syllable to the vowel. However, they found that the direction and extent of these formant transitions also depended on the vowel context: while a rising F2 was generally heard as /b/, a falling F2 was identified as either alveolar or velar depending on the following vowel. To complicate matters further, Öhman (1966) found that formant transitions following intervocalic stops depended not only on the following vowel, but also on the preceding one. Because it was known that formant transitions reflected changes in the size and shape of the vocal tract and that these changes resulted primarily from the movement of the oral articulators, it was suggested at the time that these transitions merely gave the listener insight into the approximate configuration of the speaker’s vocal tract (Delattre, Liberman & Cooper, 1955).
However, in apparent contradiction to his colleagues, Delattre (1969) suggested that these context-dependent but characteristic transitions for each place of articulation were defined in terms of perception and not production, in that phoneme identity was arrived at by perceptual means. Sussman, Fruchter, Hilbert, and Sirosh (1998) presented a summary of evidence that second formant transitions might serve as a partly invariant cue to the perception of stop consonants. It was originally found by Lindblom (1963) that the onset frequency of F2 was strongly correlated with the F2 of the following vowel and that the slope and y-intercept of the regression fit was specific to the consonant itself (see also Nearey & Shammass, 1987; Sussman, McCaffrey & Matthews, 1991; Sussman 1991). These correlations and their regression fits have been referred to as locus equations.
Not only did they suggest that perception of stop place was defined in purely acoustic terms, they even proposed a neurological mechanism whereby the human auditory system could take advantage of the observed correlations. They did so by drawing parallels between this language-specific ability and perceptual mechanisms that have been studied in specific mammalian and avian species. They also showed that this acoustic patterning was not merely a byproduct of human articulatory physiology, but that speakers actually exploited this acoustic correlation by specifically targeting the locus equation relations in articulation. It has also been shown that they provide good correlates to perception in synthetic speech (Fruchter & Sussman, 1997).
While Stevens and Blumstein (1978) propose strong relationships between all three domains of speech – gestural, auditory, and symbolic – Nearey (1997b) proposes a significant compromise between these positions in which the relationship between phonemes and both acoustics and gestures is relatively weaker than that proposed elsewhere, but in which a relationship does indeed exist between all three of these domains, if only indirectly. It is clear that perception plays a role in speech production and that speakers monitor their own speech to correct for errors (Levelt, 1983). Similarly, if auditory feedback is distorted artificially in some manner, speakers will compensate articulatorily (e.g., Purcell & Munhall, 2006). Conversely, it has been suggested that mirror neurons in cortical regions of the brain associated with speech production have, at least, a limited role in speech perception (Hickok, Houde & Rong, 2011).
Nearey (1990, 1997b) proposes a double-weak approach to the study of speech perception. Nearey arrives at this position as by the force of the argument among opposing camps and he states: “I am genuinely impressed by the quality of the research by both the auditorists and the gesturalists that is critical of the other position. Each has convinced me that the others are wrong.” In a talk to the Acoustical Society of America in 2016, he proposed the double-weak position as more of a framework than a true theory – one that postpones rumination on the deeper principles but rather adopts minimal assumptions about the relation among symbols, sounds and gestures. The framework might serve as a rationale for immediately pursuing empirical generalizations or primitive “laws.” The hope is that some such generalizations will serve the role of Kepler’s laws of planetary motion or eighteenth century “gas laws” which may also serve as grist for later, more deeply explanatory theories. A schematic depiction of the double-weak approach and its relation to other views is shown in Figure 11.5. In this figure, heavy, double-headed arrows indicate relatively strong and direct links. Thinner single-sided arrows indicate weaker (complex but otherwise tractable) links in the indicated direction. Dotted connections indicate a relationship the theory assumes but does not characterize, and which may be arbitrarily complex.
Advocates of the double-strong (both strong-auditory and strong-gestural) theory in the upper left claim that there are strong, direct ties between symbolic objects (e.g., distinctive features or phonemes) and auditory patterns on the one hand, but also a direct link from symbols to articulatory patterns (e.g., Stevens & Blumstein, 1978; Stevens & Blumstein, 1981). This seems to imply that there are also relatively strong, direct ties between auditory patterns and gestures, indicated by the gray double arrow. Strong gestural theory (e.g., that of Liberman & Mattingly, 1985), on the lower left, suggests that only the links between symbols and gestures are strong and relatively simple. Relations between symbols and acoustics in this theory are not direct, but must somehow infer gestual patterns from the auditory input and rely on the complex relationship between articulation and acoustics which are somehow mapped in the brain of the listener, at which point the symbols can be easily read off. However, Liberman and Mattingly make no attempt to characterize this latter relationship. Strong auditory theory (e.g., that of Kingston & Diehl, 1994), on the upper right, takes a diametrically opposed position and suggests that only the links between symbols and auditory patterns are strong and simple. Relations between symbols and articulation are not direct in this theory, but rather involve speakers finding ways to make sure that the gestures they choose will have the desired auditory effects and hence trigger the recognition of the correct symbols by the listener.
Double-weak theory gives up on the notion of any relation being strong or transparent. Rather, it contends the only things necessary for a successful speech communication system are:
This implies (or at least readily allows) that gestural and auditory patterns are only indirectly linked by virtue of their relationship to acoustics. Neither requires a direct or fully transparent link to symbols: Rather,
[The relations] … are assumed only to be tractably systematic, to lie within the range of the feasible for the (possibly speech-specialized) auditory and motor control systems. Longer-term and secular trends effectively impose a communicative natural selection, ensuring that the phonology of a language remains within easy reach of the vast majority of speakers and listeners.
(Nearey, 1997b, p. 3243)
Although the double-weak approach is, in principle, about both production and perception, research in the framework has been limited to perception. Specifically, efforts have been directed at trying to explicitly characterize non-trivial, but relatively simple functions that can map cue patterns into listeners’ choice behavior in categorization experiments (see Nearey, 1990, 1997b, for more details).
It is by no means clear to us what an analogously constrained double-weak approach to production would look like. However, we suspect it would involve organizing gestural patterns in some systematic way that produced appropriate acoustic reflexes, rather than patterns that were organized on the basis of motor or articulatory configurations and movements alone.
Allen, J. B. (1994), ‘How do humans process and recognize speech?’, IEEE Transactions on Speech and Audio Processing 2, 567–577.
Andruski, J. E. & Nearey, T. M. (1992), ‘On the sufficiency of compound target specification of isolated vowels and vowels in /bVb/ syllables’, The Journal of the Acoustical Society of America 91, 390–410.
Assmann, P. F. & Katz, W. F. (2000), ‘Time-varying spectral change in the vowels of children and adults’, The Journal of the Acoustical Society of America 108, 1856–1866.
Best, C. T. (1995), A direct realist view of cross-language speech perception, in W. Strange, ed., ‘Speech Perception and Linguistic Experience: Issues in Cross-Language Research’, York Press, Baltimore, MD, pp. 171–204.
Blumstein, S. E. & Stevens, K. N. (1979), ‘Acoustic invariance in speech production: Evidence from measurements of the spectral characteristics of stop consonants’, The Journal of the Acoustical Society of America 66, 1001–1017.
Blumstein, S. E. & Stevens, K. N. (1980), ‘Perceptual invariance and onset spectra for stop consonants in different vowel environments’, The Journal of the Acoustical Society of America 67, 648–662.
Boersma, P. & Weenink, D. (2018), ‘Praat: Doing phonetics by computer’, Computer Program. Version 6.0.37, Retrieved 3 February 2018 from www.praat.org
Boothroyd, A. & Nitrouer, S. (1988), ‘Mathematical treatment of context effects in phoneme and word recognition’, The Journal of the Acoustical Society of America 84, 101–114.
Broadbent, D. E. (1967), ‘Word-frequency effect and response bias’, Psychological Review 74, 1–15.
Bronkhorst, A. W., Bosman, A. J. & Smoorenburg, G. F. (1993), ‘A model for context effects in speech recognition’, The Journal of the Acoustical Society of America 93, 499–509.
Cole, R. A. & Scott, B. (1974), ‘The phantom in the phoneme: Invariant cues for stop consonants’, Perception & Psychophysics 15, 101–107.
Cooper, F. S. (1950), ‘Spectrum analysis’, The Journal of the Acoustical Society of America 22, 761–762.
Cooper, F. S., Delattre, P. C., Liberman, A. M., Borst, J. M. & Gerstman, L. J. (1952), ‘Some experiments on the perception of synthetic speech sounds’, The Journal of the Acoustical Society of America 24, 597–606.
Cooper, F. S., Gaitenby, J. H., Mattingly, I. G. & Umeda, N. (1969), ‘Reading aids for the blind: A special case of machine-to-man communication’, IEEE Transactions on Audio and Electronics AU-17, 266–270.
Darwin, C. J., McKeown, J. D. & Kirby, D. (1989), ‘Perceptual compensation for transmission channel and speaker effects on vowel quality’, Speech Communication 8, 221–234.
Delattre, P. C. (1969), ‘Coarticulation and the locus theory’, Studia Linguistica 23, 1–26.
Delattre, P. C., Liberman, A. M. & Cooper, F. S. (1955), ‘Acoustic loci and transitional cues for consonants’, The Journal of the Acoustical Society of America 27, 769–773.
Delgutte, B., Hammond, B. M., Kalluri, S., Litvak, L. M. & Cariani, P. A. (1996), Neural encoding of temporal envelope and temporal interactions in speech, in W. Ainsworth & S. Greenberg, eds., ‘Auditory Basis of Speech Perception’, European Speech Communication Association, pp. 1–9.
Delgutte, B. & Kiang, N. Y. S. (1984), ‘Speech coding in the auditory nerve: IV. Sounds with consonant-like dynamic characteristics’, The Journal of the Acoustical Society of America 74, 897–907.
Diehl, R. L. & Kluender, K. R. (1989), ‘On the objects of speech perception’, Ecological Psychology 1, 121–144.
Dutoit, T. (1997), An Introduction to Text-to-Speech Synthesis, Kluwer, Dordrecht.
Eimas, P. D. (1963), ‘The relation between identification and discrimination along speech and non-speech continua’, Language and Speech 6, 206–217.
Eimas, P. D., Siqueland, E. R., Jusczyk, P. & Vigorito, J. (1971), ‘Speech perception by infants’, Science 171, 303–306.
Fant, G. (1970), Acoustic Theory of Speech Production: With Calculations Based on X-Ray Studies of Russian Articulations, second edn, Mouton, The Hague, the Netherlands.
Flege, J. E. (1995), Second language speech learning: Theory, findings, and problems, in W. Strange, ed., ‘Speech Perception and Linguistic Experience: Issues in Cross-Language Research’, York Press, Timonium, MD.
Fletcher, H. (1995), Speech and Hearing in Communication, American Institute of Physics, Woodbury, NY.
Fowler, C. A. (1986), ‘An event approach to the study of speech perception from a direct-realist perspective’, Journal of Phonetics 14, 3–28.
Fowler, C. A. (1989), ‘Real objects of speech perception: A commentary on Diehl and Kluender’, Ecological Psychology 1, 145–160.
Fruchter, D. & Sussman, H. M. (1997), ‘The perceptual relevance of locus equations’, The Journal of the Acoustical Society of America 102, 2997–3008.
Galantucci, B., Fowler, C. A. & Turvey, M. T. (2006), ‘The motor theory of speech perception reviewed’, Psychonomic Bulletin & Review 13, 361–377.
Goldinger, S. D. (1997), Words and voices: Perception and production in an episodic lexicon, in K. Johnson & J. W. Mullennix, eds., ‘Talker Variability in Speech Processing’, Morgan Kaufmann, San Francisco, CA, pp. 33–66.
Halle, M. & Stevens, K. N. (1991), Knowledge of language and the sounds of speech, in J. Sundberg, L. Nord & R. Carlson, eds., ‘Music, Language, Speech and Brain’, Springer, Berlin, pp. 1–19.
Harris, C. M. (1953), ‘A study of the building blocks in speech’, The Journal of the Acoustical Society of America 25, 962–969.
Hickok, G., Houde, J. & Rong, F. (2011), ‘Sensorimotor integration in speech processing: Computational basis and neural organization’, Neuron 69, 407–422.
Hillenbrand, J., Getty, L. A., Clark, M. J. & Wheeler, K. (1995), ‘Acoustic characteristics of American English vowels’, The Journal of the Acoustical Society of America 97, 3099–3111.
Johnson, K. (1997), Speech perception without speaker normalization, in K. Johnson & J. W. Mullennix, eds., ‘Talker Variability in Speech Processing’, Morgan Kaufmann, San Francisco, CA, pp. 145–165.
Johnson, K., Ladefoged, P. & Lindau, M. (1993), ‘Individual differences in vowel production’, The Journal of the Acoustical Society of America 94, 701–714.
Kewley-Port, D. (1983), ‘Time-varying features as correlates of place of articulation in stop consonants’, The Journal of the Acoustical Society of America 73, 322–335.
Kewley-Port, D. & Luce, P. A. (1984), ‘Time-varying features of initial stop consonants in auditory running spectra: A first report’, Perception & Psychophysics 35, 353–360.
Kiefte, M. & Kluender, K. R. (2005a), ‘Pattern Playback revisited: Unvoiced stop consonant perception’, The Journal of the Acoustical Society of America 118, 2599–2606.
Kiefte, M. & Kluender, K. R. (2005b), ‘The relative importance of spectral tilt in monophthongs and diphthongs’, The Journal of the Acoustical Society of America 117, 1395–1404.
Kiefte, M. & Kluender, K. R. (2008), ‘Absorption of reliable spectral characteristics in auditory perception’, The Journal of the Acoustical Society of America 123, 366–376.
Kiefte, M., Nearey, T. M. & Assmann, P. F. (2012), Vowel perception in normal speakers, in M. J. Ball & F. Gibbon, eds., ‘Handbook of Vowels and Vowel Disorders’, Psychology Press, New York, pp. 160–185.
Kingston, J. & Diehl, R. L. (1994), ‘Phonetic knowledge’, Language 70, 419–454.
Kingston, J. & Diehl, R. L. (1995), ‘Intermediate properties in the perception of distinctive feature values’, Papers in Laboratory Phonology 4, 7–27.
Kluender, K. R., Coady, J. A. & Kiefte, M. (2003), ‘Perceptual sensitivity to change in perception of speech’, Speech Communication 41, 59–69.
Kluender, K. R., Diehl, R. L. & Killeen, P. R. (1987), ‘Japanese quail can learn phonetic categories’, Science 237, 1195–1197.
Kluender, K. R. & Kiefte, M. (2006), Speech perception within a biologically realistic information-theoretic framework, in M. A. Gernsbacher & M. Traxler, eds., ‘Handbook of Psycholinguistics’, second edn, Elsevier, London, pp. 153–199.
Kluender, K. R., Stilp, C. E. & Kiefte, M. (2013), Perception of vowel sounds within a biologically realistic model of efficient coding, in G. Morrison & P. F. Assmann, eds., ‘Vowel Inherent Spectral Change’, Springer, Berlin, pp. 117–151.
Kohler, E., Keysers, C., Umilta, M. A., Fogassi, L., Gallese, V. & Rizzolatti, G. (2002), ‘Hearing sounds, understanding actions: Action representation in mirror neurons’, Science 297, 846–848.
Kuhl, P. K. & Miller, J. D. (1975), ‘Speech perception by chinchilla: Voiced-voiceless distinction in alveolar plosive consonants’, Science 190, 69–72.
Kuhl, P. K. & Padden, D. M. (1982), ‘Enhanced discriminability at the phonetic boundaries for the voicing feature in macaques’, Perception & Psychophysics 32, 542–550.
Kuhl, P. K. & Padden, D. M. (1983), ‘Enhanced discriminability at the phonetic boundaries for the place feature in macaques’, The Journal of the Acoustical Society of America 73, 1003–1010.
Ladefoged, P., DeClerk, J., Lindau, M. & Papçun, G. (1972), ‘An auditory-motor theory of speech production’, UCLA Working Papers in Phonetics 22, 48–76.
Lahiri, A., Gewirth, L. & Blumstein, S. E. (1984), ‘A reconsideration of acoustic invariance for place of articulation in diffuse stop consonants: Evidence from a cross-language study’, The Journal of the Acoustical Society of America 76, 391–404.
Levelt, W. J. (1983), ‘Monitoring and self-repair in speech’, Cognition 14, 41–104.
Liberman, A. M. (1984), On finding that speech is special, in ‘Handbook of Cognitive Neuroscience’, Springer, Boston, MA, pp. 169–197.
Liberman, A. M., Cooper, F. S., Shankweiler, D. P. & Studdert-Kennedy, M. (1967), ‘Perception of the speech code’, Psychological Review 74, 431–461.
Liberman, A. M., Delattre, P. & Cooper, F. S. (1952), ‘The rôle of selected stimulus-variables in the perception of the unvoiced stop consonants’, The American Journal of Psychology LXV, 497–516.
Liberman, A. M., Delattre, P. C., Cooper, F. S. & Gerstman, L. J. (1954), ‘The role of consonant-vowel transitions in the perception of the stop and nasal consonants’, Psychological Monographs: General and Applied 68(8), 1–13.
Liberman, A. M., Harris, K. S., Hoffman, H. S. & Griffith, B. C. (1957), ‘The discrimination of speech sounds within and across phoneme boundaries’, Journal of Experimental Psychology 54, 358–368.
Liberman, A. M., Isenberg, D. & Rakerd, B. (1981), ‘Duplex perception of cues for stop consonants: Evidence for a phonetic mode’, Perception & Psychophysics 30, 133–143.
Liberman, A. M. & Mattingly, I. G. (1985), ‘The motor theory of speech perception revisited’, Cognition 21, 1–36.
Liljencrants, J. & Lindblom, B. (1972), ‘Numerical simulation of vowel quality systems: The role of perceptual contrast’, Language 48, 839–862.
Lindblom, B. (1963), ‘On vowel reduction’, Technical Report 29, Speech Transmission Laboratory, Royal Institute of Technology, Stockholm, Sweden.
Lindblom, B. (1996), ‘Role of articulation in speech perception: Clues from production’, The Journal of the Acoustical Society of America 99, 1683–1692.
Lotto, A. J., Hickok, G. S. & Holt, L. L. (2009), ‘Reflections on mirror neurons and speech perception’, Trends in Cognitive Sciences 13, 110–114.
Lotto, A. J. & Kluender, K. R. (1998), ‘General contrast effects in speech perception: Effect of preceding liquid on stop consonant identification’, Perception & Psychophysics 60, 602–619.
Lotto, A. J., Kluender, K. R. & Holt, L. L. (1997), ‘Perceptual compensation for coarticulation by Japanese quail (Coturnix coturnix japonica)’, The Journal of the Acoustical Society of America 102, 1134–1140.
Luce, P. A. & Pisoni, D. B. (1998), ‘Recognizing spoken words: The neighborhood activation model’, Ear and Hearing 19, 1–36.
Massaro, D. W. & Chen, T. H. (2008), ‘The motor theory of speech perception revisited’, Psychonomic Bulletin & Review 15, 453–457.
McGovern, K. & Strange, W. (1977), ‘The perception of /r/ and /l/ in syllable-initial and syllable-final position’, Perception & Psychophysics, 162–170.
McGurk, H. & MacDonald, J. (1976), ‘Hearing lips and seeing voices’, Nature 264, 746–748.
Mermelstein, P. (1978), ‘On the relationship between vowel and consonant identification when cued by the same acoustic information’, Perception & Psychophysics 23, 331–336.
Miller, G. A. & Nicely, P. E. (1955), ‘An analysis of perceptual confusions among some English consonants’, The Journal of the Acoustical Society of America 27, 338–352.
Nearey, T. M. (1980), ‘On the physical interpretation of vowel quality: Cinefluorographic and acoustic evidence’, Journal of Phonetics 8, 213–241.
Nearey, T. M. (1990), ‘The segment as a unit of speech perception’, Journal of Phonetics 18, 347–373.
Nearey, T. M. (1992), ‘Context effects in a double-weak theory of speech perception’, Language and Speech 35, 153–171.
Nearey, T. M. (1997a), Modularity and tractability in speech perception, in K. Singer, R. Eggert & G. Anderson, eds., ‘CLS 33: The Panels’, Chicago Linguistic Society, Chicago, IL, pp. 399–413.
Nearey, T. M. (1997b), ‘Speech perception as pattern recognition’, The Journal of the Acoustical Society of America 101, 3241–3254.
Nearey, T. M. (2001), ‘Phoneme-like units and speech perception’, Language and Cognitive Processes 16, 673–681.
Nearey, T. M. (2004), ‘On the factorability of phonological units in speech perception’, Laboratory Phonology 6, 197–221.
Nearey, T. M. & Assmann, P. F. (1986), ‘Modeling the role of inherent spectral change in vowel identification’, The Journal of the Acoustical Society of America 80, 1297–1308.
Nearey, T. M. & Shammass, S. E. (1987), ‘Formant transitions as partly distinctive invariant properties in the identification of voiced stops’, Canadian Acoustics 15, 17–24.
Öhman, S. E. G. (1966), ‘Coarticulation in VCV utterances: Spectrographic measurements’, The Journal of the Acoustical Society of America 39, 151–168.
Parker, E. M., Diehl, R. L. & Kluender, K. R. (1986), ‘Trading relations in speech and nonspeech’, Perception & Psychophysics 39, 129–142.
Perkell, J. S., Matthies, M. L., Svirsky, M. A. & Jordan, M. I. (1993), ‘Trading relations between tongue-body raising and lip rounding in production of the vowel /u/: A pilot “motor equivalence” study’, The Journal of the Acoustical Society of America 93, 2948–2961.
Pisoni, D. B. (1997), Some thoughts on “normalization” in speech perception, in K. Johnson & J. W. Mullennix, eds., ‘Talker Variability in Speech Processing’, Morgan Kaufmann, San Francisco, CA, pp. 9–32.
Pollack, I., Rubenstein, H. & Decker, L. (1959), ‘Intelligibility of known and unknown message sets’, The Journal of the Acoustical Society of America 31, 273–279.
Purcell, D. W. & Munhall, K. G. (2006), ‘Compensation following real-time manipulation of formants in isolated vowels’, The Journal of the Acoustical Society of America 119, 2288–2297.
Recio, A., Rhode, W. S., Kiefte, M. & Kluender, K. R. (2002), ‘Responses to cochlear normalized speech stimuli in the auditory nerve of cat’, The Journal of the Acoustical Society of America 111, 2213–2218.
Repp, B. H. (1982), ‘Phonetic trading relations and context effects: New experimental evidence for a speech mode of perception’, Psychological Bulletin 92, 81–110.
Rizzolatti, G. & Arbib, M. A. (1998), ‘Language within our grasp’, Trends in Neurosciences 21, 188–194.
Rizzolatti, G. & Craighero, L. (2004), ‘The mirror-neuron system’, Annual Review of Neuroscience 27, 169–192.
Sachs, M. B. & Young, E. D. (1979), ‘Encoding of steady-state vowels in the auditory nerve: Representation in terms of discharge rate’, The Journal of the Acoustical Society of America 66, 470–479.
Schatz, C. D. (1954), ‘The role of context in the perception of stops’, Language 30, 47–56.
Stetson, R. H. (1945), Bases of Phonology, Oberlin College, Oberlin.
Stevens, K. N. (1989), ‘On the quantal nature of speech’, Journal of Phonetics 17, 3–45.
Stevens, K. N. (2002), ‘Toward a model for lexical access based on acoustic landmarks and distinctive features’, The Journal of the Acoustical Society of America 111, 1872–1891.
Stevens, K. N. & Blumstein, S. E. (1978), ‘Invariant cues for place of articulation in stop consonants’, The Journal of the Acoustical Society of America 64, 1358–1368.
Stevens, K. N. & Blumstein, S. E. (1981), The search for invariant acoustic correlates of phonetic features, in P. D. Eimas & J. L. Miller, eds., ‘Perspectives on the Study of Speech’, Lawrence Erlbaum, Hillsdale, NJ, pp. 1–38.
Stevens, K. N. & Keyser, J. J. (1989), ‘Primary features and their enhancement in consonants’, Language 65, 81–106.
Stilp, C. E., Kiefte, M., Alexander, J. M. & Kluender, K. R. (2010), ‘Cochlea-scaled spectral entropy predicts rate-invariant intelligibility of temporally distorted sentences’, The Journal of the Acoustical Society of America 128, 2112–2126.
Suomi, K. (1985), ‘The vowel-dependence of gross spectral cues to place of articulation of stop consonants in CV syllables’, Journal of Phonetics 13, 267–285.
Sussman, H. M. (1991), ‘The representation of stop consonants in three-dimensional acoustic space’, Phonetica 48, 18–31.
Sussman, H. M., Fruchter, D. & Cable, A. (1995), ‘Locus equations derived from compensatory articulation’, The Journal of the Acoustical Society of America 97, 3112–3124.
Sussman, H. M., Fruchter, D., Hilbert, J. & Sirosh, J. (1998), ‘Linear correlates in the speech signal: The orderly output constraint’, Behavioral and Brain Sciences 21, 241–299.
Sussman, H. M., McCaffrey, H. A. & Matthews, S. A. (1991), ‘An investigation of locus equations as a source of relational invariance for stop place categorization’, The Journal of the Acoustical Society of America 90, 1309–1325.
Watkins, A. J. (1991), ‘Central, auditory mechanisms of perceptual compensation for spectral-envelope distortion’, The Journal of the Acoustical Society of America 90, 2942–2955.
Watkins, A. J. & Makin, S. J. (1994), ‘Perceptual compensation for speaker differences and for spectral-envelope distortion’, The Journal of the Acoustical Society of America 96, 1263–1284.
Watson, C. & Kewley-Port, D. (1988), ‘Some remarks on Pastore (1988)’, The Journal of the Acoustical Society of America 84, 2266–2270.
Young, E. D. & Sachs, M. B. (1979), ‘Representation of steady-state vowels in the temporal aspects of the discharge patterns of populations of auditory-nerve fibers’, The Journal of the Acoustical Society of America 66, 1381–1403.