Clinical phonetics is a field concerned with speech sound description and analysis applied to people with communication disorders (Crystal, 1980, 1981, 1984; Powell and Ball, 2010; Shriberg et al., 2013). Analyses of recent publication patterns show that clinical phonetic research constitutes a major portion of clinical linguistics, the parent field (Perkins et al., 2011; Crystal, 2013). However, despite the growing popularity of clinical phonetics, the history of phonetics does not reflect a longstanding priority to describe speech and language disorders. The creators of the International Phonetic Alphabet (IPA) (e.g., Passy, 1884; Sweet, 1902; Jones, 1928) were chiefly concerned with language teaching, pronunciation, and translation. As a result, the IPA has primarily evolved to describe sound details pertaining to world language differences, and not variability typical of pathology (see discussion by Howard and Heselwood, 2002). In this sense, the field resembles sociophonetics, which has traditionally also had impoverished tools for describing language variation (see chapter by Thomas, this volume). For years phoneticians have noted this shortcoming, as illustrated by Trim’s (1953) comment that the IPA “is still inadequately furnished with tools for the use of speech therapists” (p. 24).
Nonetheless, certain key founders of phonetics did express an interest in the physiology of speech perception and production, for both healthy and disordered individuals. Perhaps the strongest early advocates for this viewpoint were those Ohala (2004) described as taking a “scientific” (or “positivist,” more physically based) phonetic approach, as opposed to a “taxonomic” approach (chiefly concerned with naming, classifying, and transcribing speech sounds). Examples may be observed in 17th-century attempts to get the deaf to speak, such as Amman (1694, 1700), van Helmont (1667), Holder (1669), and Wallis (1969). Other historians offer John Thelwall (1794–1834) as an important bridge figure in the later 19th-century period. This British elocutionist formed the first school for pupils with “impediments of speech,” incorporating therapies based on prosody and articulatory phonetics (Rockey, 1977; Thelwall, 1981; Duchan, 2006). Additional prominent examples include Alexander Melville Bell (1867) and Alexander Graham Bell (1872) working to promote visible speech for the deaf.
Both scientific and taxonomic approaches remain crucial to the current field of clinical phonetics. These approaches are ultimately interrelated, since taxonomy cannot exist without an underlying theoretical framework, and scientific advancement requires precise nomenclature.1 As the writings of Jespersen (1910) and Jakobson (1968) indicate, some linguists who made prominent taxonomic contributions were inspired to address the speech and language of healthy and disordered individuals.
From 1940s to 1960s, many important breakthroughs in linguistics served as fertile ground for the eventual genesis of clinical phonetics as a field. This included the Fundamentals of Language (Jakobson and Halle, 1956) and the concepts of distinctive features, markedness, and language universals. In addition, new generative paradigms in linguistics and their potential cognitive implications also had the effect of broadening perspectives from individual case studies and/or treatment plans to more extensive theoretical issues.
The field of clinical linguistics began to emerge into a recognized specialty area around 1976 and continued into the early 1980s, at least in the USA and Britain (Powell and Ball, 2010). A pivotal development was the 1981 publication of the book Clinical Linguistics by David Crystal, who defined clinical linguistics as “the application of linguistic science to the study of communication disability, as encountered in clinical situations” (p. 1). Crystal and colleagues provided initial frameworks for the analysis of healthy and disordered segmental phonology, syntax, morphology, and semantics. Subsequently Crystal (1984, p. 31) and several other researchers (e.g., Code and Ball, 1984) stressed the importance of phonetics to the field.
As Muller and Ball (2013) note, clinical linguistics research can be uni- or bi-directional with respect to the relation between clinical populations and linguistic/neurological theory. That is, some researchers emphasize applying linguistic theory for the benefit of patients (a clinical approach), others use data from clinical populations to gain insight into linguistic or neurological theory (a neurolinguistic approach),2 while many now assume a bi-directional flow of information between clinical data and theory. As an example of the clinical approach, Dinnsen et al. (2014) employed Optimality Theory (OT; Prince and Smolensky, 1993) to better understand the sound system of a child with a phonological delay and to propose some clinical recommendations. In contrast, a classic neurolinguistic approach is found in Jakobson’s consideration of child language and the language of individuals with aphasia in order to elaborate phonetic feature theory (Jakobson, 1968).
As clinical phonetics has progressed, numerous studies have addressed the shortcomings of IPA description with respect to clinical populations (see e.g., Howard and Heselwood, 2002; Muller and Ball, 2013, for detailed reviews). For instance, Shriberg and Kent (1982) provided important examples of procedures useful for examining clinical populations, including perceptual analyses and suggestions for transcription. Shriberg and colleagues also worked on improving transcription by investigating consensus methodologies (Shriberg et al., 1984) and comparing reliability across different techniques (Shriberg and Lof, 1991). Other researchers developed transcription methods specifically for disordered output (e.g., Ball et al., 2009; Rutter et al., 2010), including cleft palate speech (Trost, 1981) and prosodic changes in the speech of hearing impaired (e.g., Ball et al., 1994) and cochlear-implanted (Teoh and Chin, 2009) patients.
A systematic effort to develop symbol sets designed for use with individuals having speech and language disorders began when a King’s Fund working party developed the Phonetic Representation of Disordered Speech (PRDS, 1983). These symbols were considered at the 1989 IPA meeting (Kiel), resulting in a recommended set of Extensions to the International Phonetic Alphabet (ExtIPA), designed for clinical use (Duckworth et al., 1990). The ExtIPA has since been updated (2008) to encompass description of the airstream mechanism, phonation, nasalization, articulatory strength, articulatory timing, and prosodic features of disordered speech (see Appendix 1).
For the most part, the ExtIPA consists of letters and diacritics not used for healthy speech. For example, “nareal fricative” (as found in a nasal lisp) would not occur in healthy adult speech. In contrast, some articulatory descriptions, such as the diacritics for “alveolar” and “linguolabial”, use IPA symbols that can also be applied to healthy speech. For disordered prosody, musical notation is borrowed to describe phenomena such as abnormally loud [f] or fast speech [allegro], as may be found in disorders such as cluttering or “press for speech” associated with mania.
The Voice Quality Symbols (VoQS) were developed by Ball et al. (1995; updated 2015) to provide a systematic means of transcribing unusual or disordered voice quality by specifying airstream types and phonation types, larynx height, and supralaryngeal settings (see Appendix 2). Similar to the ExtIPA, some symbols pertain to disordered conditions (e.g., trachea-oesophageal speech, [{Ю}], or spasmodic dysphonia, [{ꟿ}]), while many symbols can also represent the voice of a healthy talker during unusual speaking conditions, e.g., whisper, [{W}], faucalized (“yawning”) voice, [{Vᵸ}], or open-jaw voice, [{J̞}]. Overall, the ExtIPA and VoQs add symbolic capacity to the IPA for describing the features and voice quality of healthy talkers (Heselwood, 2013, p. 122; Esling, 2010, p. 694).
As this short history suggests, the field of clinical phonetics has evolved in response to both scientific and clinical needs. It is common for researchers in the brain and cognitive sciences to question how speech and language processing is involved when modeling or measuring behavior. Thus, clinical phonetics is frequently at the center of cutting-edge investigations in the behavioral and brain sciences. Clinical phonetics’ ongoing priority of developing symbol sets and descriptors for disordered speech provides practical benefits for clinicians. In a related sense, situations arguably arise in which traditional phonetic transcription may have significant limitations, e.g., for describing “covert contrasts,” where sound distinctions may be perceptually unreliable but acoustically and/or kinematically distinct (Hewlett, 1988). The field has therefore seen an increasing use of acoustic and kinematic measures to help describe healthy and disordered speech.
The next section briefly reviews multisensory information in speech processing; a topic that has long been ignored within the broader framework of clinical phonetics but that I believe should be emphasized for at least three reasons: First, a growing literature indicates that multisensory speech processing in healthy adults and children is crucial for everyday language function. Thus, in order to understand the phonetics of disordered language acquisition and breakdown, a multisensory approach may be essential. Second, audiovisual (face-to-face) speech communication is increasingly facilitated via new electronic systems (e.g., cell phones, videoconferencing, telemedicine) and this may well have clinical import for populations with speech and language disorders. Third, technological advances in measuring speech kinematics have permitted researchers to more easily describe and model the movement of speech articulators than was previously possible. Here, I emphasize recent studies of AV speech properties, including motion of the head, face, lips, jaw and tongue, in order to further our understanding of the speech of individuals presenting with speech and language problems.3
It is common to portray speech as necessarily involving the auditory modality, comprising the link between talker and listener (e.g., Denes and Pinson, 1993; Raphael et al., 2007). Nonetheless, researchers widely recognize that speech communication involves multisensory processing, noted for instance in a recent, explicit addition of multisensory streams to the “speech chain” (Gick et al., 2012, p. 272). What follows is a brief overview of this issue.
“Multisensory” commonly refers to audiovisual (AV) processing, such as when facing others in conversation (or watching TV or movies). Although the multisensory processing of speech includes proprioceptive and somatosensory (e.g., haptic, and aero-tactile) information (discussed later), we shall begin with AV processing, as study of this topic began at least as early as Alexander Melville Bell (Visible Speech, 1867). Seminal work by Sumby and Pollack (1954) contrasted listeners’ perception of English spondees in auditory and audiovisual conditions, across different size word sets, and at different levels of noise masking. A key finding is that the relative contribution of vision to AV perception is constant across a wide range of signal-to-noise ratios. This suggests that the AV processing of speech is a natural mode of attention and is relatively indifferent to purely auditory phonetic processes (Remez, 2012). Research by Summerfield and colleagues (e.g., Summerfield, 1979, 1983, 1992; Brooke and Summerfield, 1983) has provided valuable information concerning the AV processing involved in lip-reading, including the permissible amounts of AV asynchrony, which cognitive skills are recruited for this ability, and which regions of synthetic faces and lips (including teeth) are required for heightened intelligibility. These issues are further described in the next section of this chapter.
Other critical information on AV perception has derived from research into the McGurk effect (McGurk and MacDonald, 1976), in which a visual stimulus (e.g., /ɡa/) alters the perception of an auditory stimulus (e.g., /ba/) that is perfectly audible on its own (Alsius et al., 2017). Listeners commonly report hearing a fusion of both modalities (e.g., /da/). This effect has been noted for different types of stimuli (e.g., Walker et al., 1995; Quinto et al. 2010), across different perceiver ages (e.g., Rosenblum et al., 1997; Burnham and Dodd, 2004; Sekiyama et al., 2014) and languages (Sekiyama and Tohkura, 1991; Burnham and Dodd, 1996), and under different temporal constraints (Munhall et al., 1996) and attentional demands (e.g., Alsius et al., 2005). Several questions and controversies remain concerning the large degree of inter-subject variability observed (e.g., Mallick et al., 2015) and the exact mechanisms involved (see e.g., Tiippana, 2014; Alsius et al., 2017) in the McGurk effect. Despite these controversies, there is consensus that the effect is quite robust, occurs whether one has knowledge of it or not, and likely has theoretical and clinical relevance for people with communication disorders. For instance, reduced McGurk effects have been reported for individuals with dyslexia (Bastien-Toniazzo et al., 2010), children with specific language impairment (Norrix et al., 2007; Kaganovich et al., 2015), autism spectrum disorders (Williams et al., 2004; Mongillo et al., 2008; Taylor et al., 2010), and language learning disabilities (Norrix et al., 2006), and for adults with Alzheimer’s disease (Delbeuck et al. 2007) and aphasia (Youse et al., 2004; Hessler et al., 2012).
In addition to using noise masking and incongruent stimuli (McGurk) paradigms to assay AV integration (as described previously), new versions of the “phonemic restoration” paradigm have provided some intriguing results and may hold promise for studying clinical populations. Jerger et al. (2014) examined children aged 4–14 years old in an experiment in which congruent audio and visual speech syllables were presented, and in which for some conditions the auditory token (/ba/) had weakened acoustic cues (here, flattened formant frequency transitions for the /b/, such that only “a” is heard). When this weakened acoustic stimulus was paired with a visual whole syllable /ba/, the weakened auditory cue was effectively restored. The authors concluded that the children use visual speech to compensate for non-intact auditory speech. Other researchers are developing this paradigm to study AV perception in healthy individuals and in clinical populations (e.g., Irwin et al., 2014; Irwin and DiBlasi, 2017).
Proprioception refers to sensing of the body position in space, while somatosensory refers to sensations such as pressure, pain or temperature, superficial or deep to the organism. Sensing one’s position in space enables orienting the head toward a sound, which in turn assists localization and identification by vision of the sound source (e.g., Lewald and Ehrenstein, 1998; Lewald et al., 2000). Anecdotal evidence supporting the importance of proprioception in speech comes from the testimony of astronauts experiencing “earth sickness” after returning to gravity after weightlessness. For instance, Canadian astronaut Chris Hadfield, of International Space Station Expedition 35, stated, “Right after I landed, I could feel the weight of my lips and tongue and I had to change how I was talking. I didn’t realize I had learned to talk with a weightless tongue” (Hadfield, 2013). Experimental support may be found in dual-processing tasks, such as requiring subjects to speak while walking. Plummer D-Amato et al. (2011) tested a series of cognitively demanding tasks on gait in a dual-task interference paradigm and found that speech produced the greatest interference of all tasks tested. These results suggest that speech and body positioning (i.e., involving proprioception) use common regulatory mechanisms. Speaking tasks can particularly affect the posture and gait of certain populations, including slow walkers, the elderly, and individuals recovering from stroke.
Evidence of a role for proprioception in speech also comes from study of individuals with focal damage to the nervous system, including the cerebellum and basal ganglia. Kronenbuerger et al. (2009) studied individuals with essential tremor (ET), including those with and without cerebellar involvement. They observed syllable production, gait, and posture. Results indicated increased postural instability and increased syllable duration, particularly for individuals with ET resulting from cerebellar disorders. The results suggest that deficits in balance and dysarthria arise with an impairment to the cerebellum. Similarly, Cantiniaux et al. (2010) observed rhythmic problems in the speech and gait of individuals with Parkinson’s disease (PD), suggesting a linked pathophysiological process for these individuals having cerebellar/basal ganglia disorders. In summary, studies of gait, posture, and focally disordered speech processing support proprioceptive links to speech by means of shared neural bases, including the cerebellum.
To investigate speech-related somatosensory information, Nasir and Ostry (2006) conducted a series of speaking experiments in which participants were required to talk with unexpected loads applied to the lower lip and jaw. The results indicated that precise somatosensory specification was required for speech production, in addition to presumed auditory targets. A subsequent study by Ito et al. (2009) used a robotic device to create patterns of skin deformation that would normally be involved in speech production. Listeners heard computer-generated productions of CVC stimuli ranging from “head” to “had.” Listeners’ skin-stretched (perturbed) responses varied systematically from their non-perturbed responses, suggesting a role of the somatosensory system in speech perception.
Early studies of haptic speech (e.g., gestures felt from manual tactile contact with the speaker’s face) were conducted to develop effective communication methods for deaf-blind individuals, the Tadoma method (Alcorn, 1932; Norton, 1977). More recently, investigations have established that auditory information can influence haptic sensation (“the parchment skin illusion”; Jousmaki and Hari, 1998) and that haptic information can benefit speech perception in healthy individuals. These (latter) studies include cross-modal perception and production tasks (Fowler and Dekle, 1991), cross-modal perception with degraded acoustic information (Sato et al., 2010), tests of speech intelligibility in noise (Gick et al., 2008), and neural processing (evoked potentials) in live dyadic interactions (Treille et al., 2014). Considered together with the somatosensory perturbation experiments described earlier (Nasir and Ostry, 2006; Ito et al., 2009), this literature suggests that listeners integrate auditory and haptic information, perhaps occurring relatively early during the speech perception process (Treille et al., 2014, p. 75).
A more specific form of the tactile modality, aero-tactile stimulation, is under active investigation. Gick and Derrick (2009) gave listeners a slight, inaudible puff of air to the hand or neck while they heard noise-masked CV syllables differing in initial-consonant voicing (“pa”/“ba,” “ta”/“da”). Syllables heard with simultaneous air puffs were more likely to be perceived as voiceless, suggesting that tactile information (timed to correspond with articulatory aspiration events) is integrated with auditory information during speech perception. Subsequent work showed that such aero-tactile effects also improve listeners’ ability to differentiate stop-fricative pairs (“fa”/“ba” and “da”/“sha”) in a forced-choice task (Derrick et al., 2014).
In summary, ample evidence indicates that the multisensory processing of speech is a vital part of the everyday language experience for healthy individuals. We may therefore reason that the field of clinical phonetics can benefit by considering the multisensory nature of speech in developing theories, clinical applications, and phonetic description. For instance, as will be described further in later sections of this chapter, researchers using visual feedback of articulatory motion report success for treating speech errors in individuals with apraxia of speech (see McNeil et al., 2010 for review), and dysarthria (Vick et al., 2014, 2017), raising questions about the nature of speech representation and the locus of breakdown with different types of brain damage. The next section describes AV information processing for speech, including data for healthy adults and children, as well as individuals having speech and language disorders. Co-verbal motion of the head is considered first, followed by orofacial motion.
Healthy talkers accompany their everyday speech with head motion. However, determining exactly which types of linguistic and paralinguistic information are relayed by head motion, how this behavior develops, and how it is interpreted by perceivers has posed a challenge to researchers. This section briefly reviews studies of head motion in speech production and perception by adults, the development of co-verbal head motion in infants and children, and how head AV processing may be impacted by disease processes.
Early investigations of adult head movement during conversation provide information indicating a role in signaling phrasing (juncture) and contrastive stress (e.g., Hadar et al., 1983). These studies also provide evidence for the semantic or narrative discourse functions of head gestures (McNeill, 1985; McClave, 2000). For example, McClave (2000) describes side-to-side head shakes (rotation) correlating with expressions of inclusivity and intensification, head nods (flexion/extension) serving as backchannel requests, and lateral movements correlating with uncertain statements and lexical repairs.
At a phonetic level, Yehia et al. (2002) examined the relation between head motion (kinematics) and fundamental frequency (f0) during speech production. An LED-tracking system measured face and rigid head motion while Japanese- and English-speaking talkers produced short sentences. Correlation analysis showed that with rising f0, talkers’ heads tilt upward and away from the chest, while the head tips downward (towards the chest) with falling f0. The authors suggest this is a primarily functional linkage, as most talkers can volitionally override these effects, such as by placing the chin low while making a higher pitch (Yehia et al., 2002, p. 568). A similar functional linkage between the amplitude of the speech signal and head motion was noted by Yehia et al. (2002). Other evidence of head movement affecting speech can be found from cases in which individuals speak while temporarily placed in head restraints, such as subjects in early speech experiments or singers/actors during certain types of stage training (Vatikiotis-Bateson and Kuratate, 2012; Roon et al., 2016). In such cases, people tend to talk much more quietly than usual and report feeling unnatural.
Studies of adults’ perception of co-verbal head motion have provided a wealth of information over the past few decades, and the findings raise many intriguing new questions (Vatikiotis-Bateson and Munhall, 2015). Initial research suggested that listeners are able to decipher head and eyebrow movements to detect differences in emphatic stress (e.g., Thompson, 1934; Risberg and Lubker, 1978; Bernstein et al. 1989) and in sentence-level intonation (Fisher, 1969; Bernstein et al., 1989; Nicholson et al., 2002). Other research has found that the timing of head motion is consistent with prosodic structure, suggesting that head motion may be valuable for segmenting spoken content (Graf et al., 2002). The notion that head motion plays a role in “visual prosody” was promoted in a study by Munhall et al. (2004) in which Japanese subjects viewed a talking-head animation during a speech-in-noise task. The participants correctly identified more syllables with natural head motion than without it, suggesting that head motion helps people synchronize their perception to speech rhythm, and thereby retrieve phonetic information.
Head motion also conveys paralinguistic information in speech, including emotional prosody. For instance, Busso et al. (2007) derived statistical measures from an AV database and found that head motion patterns of activation, range, and velocity provide discriminating information about sadness, happiness, anger, and neutral emotional states. The researchers then used these statistically derived features to drive facial animations, which raters perceived as more natural than the original head motion sequences. Critically, head motion played a major role enhancing the emotional content of the animations. Similar results were observed in a study of vocalists singing and speaking semantically neutral statements produced with different emotional intentions (Livingstone and Palmer, 2016). Observers could identify the intended emotions of these vocalists well above chance levels solely by their head movements, at similar levels of accuracy for both speech and song.
Indeed, viewing rigid motion of only part of the head can still assist listeners with speech perception. Davis and Kim (2006) found that showing listeners a talker’s moving upper head produced a small but reliable improvement in speech intelligibility for expressive sentences made with major head movements. Cvejic et al. (2010) conducted a cross-modal AV priming task under a variety of conditions including video conditions with outlines only (rigid motion). They found that top of the head movements produced by the speakers were sufficient to convey information about the prosodic nature of an utterance.
To summarize, adult head motion is correlated with voice pitch (and to a lesser degree, amplitude), both of which are used for linguistic and paralinguistic purposes during speech. Study of the timing and coordination of co-verbal head movement suggests a complex relationship with speech. More research, including work with annotative systems originally designed for the analysis and synthesis of speech and gesture (e.g., Kong et al., 2015; Johnston, 2017), may help clarify these issues. It would also be important to investigate the strength of any language- and culture-specific factors in these effects, in order to establish the extent to which this behavior is universal or language-particular.
Head shakes and nods, like hand pointing gestures, are early emerging forms of preverbal communication. Fenson et al. (1994) found that a large sample of American children produce head shakes (12 mos.) and nods (14 mos.) approximately three to five months earlier than their corresponding verbal forms, “no” and “yes.” Studies suggest that young children quickly recruit these early head gestures for purposes of communicative competence. Examples include using head nods to clarify the intent of vocalizations (e.g., Yont et al., 2001) and employing head gestures to facilitate turn-taking exchanges (Fusaro, 2012). Overall, these data imply that head motion plays a role in developing discourse-relevant skills as children’s speech and language skills map in.
With respect to speech perception, researchers have asked whether infants are able to extract suprasegmental phonetic information from head movement during infant-directed (ID) exchanges. To address this question, researchers must consider the many factors known to be involved in contingent mother-infant interactions. Thus, cross-modal and cross-talker factors, as well as linguistic and social goals all come into play during the mother-child dyad (see Leclere et al., 2014; Viaux-Savelon, 2016). Kitamura et al. (2014, experiment 2) had 8-month-old infants hear a short sentence while watching two silent, line-joined, point-light displays: One depicted rigid (head only) verbal motion and the other non-rigid (face only) verbal motion. The researchers were interested in determining whether the infants were sensitive to the match between audio and visual correlates of ID speech prosody. Results indicate that infants look longer to a visual match in the rigid condition than to a visual mismatch in the non-rigid condition. The researchers concluded that 8-month-old infants can extract information about speech prosody from head movement and from voice (i.e., are sensitive to their match), and were less sensitive to lip movement and voice information. They speculate that head signals are prioritized in order to track the slower rate of global prosody (e.g., as would be found in sentence-level intonation) over local rhythm (e.g., as found in lexical stress). To determine whether mothers produce special head motion during ID speech, Smith and Strader (2014) conducted an eye-tracking study contrasting mothers talking under ID and AD (adult directed) conditions. The results suggest that mothers exaggerate their head movement as a form of visual prosody, in a manner analogous to the acoustical exaggerations in their speech (e.g., Fernald, 1989).
Taken together, studies of children’s production and perception of head motion, as well as head motion produced in ID speech, suggest that an association of head movement with speech is a fundamental attribute of children’s speech and language development. Future studies should consider studying languages other than English, as this would help substantiate some recent claims advanced, such as whether head motion signals “universals in discourse and communicative function” (Smith and Strader, 2014) or whether head motion indicates “global prosody over local prosody” (Kitamura et al., 2014). In addition, dyadic studies that track synchronized (contingent) aspects of AV co-verbal head motion during mother-infant interactions would be very useful.
Limitations or exaggerations in head movement occurring from a variety of medical causes (e.g., inherited genetic factors, injury, stroke, or neurological disorders) can affect speech production. Such problems may be direct or indirect. The patient’s speech production may be directly affected, particularly in the case of an erratically moving head (e.g., in cerebral palsy or Huntington’s disease) by interfering with rigid head movement cues normally associated with speech. That is, assuming a conversation partner is used to attending to a healthy talker’s moving head, viewing an erratically moving head (or an abnormally still head, as in the case of paralysis) may degrade perception by interfering with rigid motion cues. Head movement problems during speaking may also produce indirect effects by reducing visible facial cues otherwise available for prosody and discourse information. Simply put, if the talker’s head is turned away during conversation, his/her face cannot be easily viewed. Unfortunately, these issues have not been systematically addressed in the literature.
Individuals with neurological disorders that result in speech dysarthria (e.g., cerebral palsy, Huntington’s disease, amyotrophic lateral sclerosis, Parkinson’s disease) also present with postural and motor control deficits (including tremor), issues that in themselves can potentially affect speech production. To illustrate how such motor control disorders can affect head positioning and ultimately impair speech processing, it will be useful to consider cerebral palsy (CP), a mixed group of early-onset, non-progressive, neuromotor disorders that affect the developing nervous system (Rosenbaum et al., 2007). CP results in changes in movement, posture, and muscle tone. The speech characteristics of this population may include respiratory anomalies, strained-strangled voice, pitch/loudness fluctuations, imprecise articulation, rate and timing problems, and hypernasality (Scholderle et al., 2014). Notably, head stability issues are common in children with even with mild-to-moderate CP (Saavedra et al., 2010). Research using head-mounted inertial sensors suggests that these stability deficits are predominantly due to “negative motor signs,” including postural problems resulting from insufficient muscle activity and/or neural motor control (Velasco et al., 2016).
Although there appears to be a link between the severities of gross motor impairment and speech disorders in CP (Himmelmann and Uvebrant, 2011; Nordberg et al., 2013) scant data exist concerning the specific role of head movement in the communication difficulties experienced by individuals with CP. Research in this area might also examine whether the family and caretakers of individuals with CP learn to adapt (compensate) for reduced head motion by attending to other information (secondary cues) present in the auditory or visual streams.
Orofacial movement for speech involves ensembles of articulatory movements, including non-rigid movement of the lips and face (via the combined action of the facial and perioral muscles), rigid jaw movement, and effects due to regulation of intraoral air pressure (Vatikiotis-Bateson, 1998). Extensive research on the kinematics of the oral region has focused on lip movement (e.g., opening/closing gestures), lip shape (e.g., protrusion, inversion, spread), and the oral aperture during speech (e.g., Linker, 1982; Ramsay et al., 1996). Overall, the lips have a comparatively small movement range but can reach relatively high speeds, while the jaw has a larger range but slower speeds. Considering displacement, the lips’ range of motion is approximately 6 mm for the upper lip and 12 mm for the lower lip (Sussman et al., 1973; Smith, 1992). Jaw motion for speech mainly involves midsagittal movements of up to 10 mm of translation and 10–15 degrees of rotation (Vatikiotis-Bateson, 1998). In terms of velocity, early reports of lip movement fundamental frequencies were <10 Hz (Muller and MacLeod, 1982), whereas more recent reports describe speeds ranging up to ~20 Hz, varying as a function of the gesture/consonant produced (Gracco, 1994; Lofqvist and Gracco, 1997) and voicing quality (Higashikawa et al., 2003). Jaw movement velocities during oral reading are reported to have a fundamental frequency of ~4 Hz (Ohala, 1975) and show averaged rates falling roughly in the same range (e.g., Ostry and Flanagan, 1989).
Orofacial movements have been linked to vocal tract and acoustic regularities. Based on a series of experiments evaluating English and Japanese sentence production using flesh-point tracking systems and acoustic analysis, Vatikiotis-Bateson and Munhall (2015) describe a “tight, causal coupling between kinematic (vocal tract and face) and acoustic data” (p. 179). Using multivariate correlations, over 80% of facial motion was estimated from vocal tract articulations. In addition, 65% of the speech acoustics examined were estimated from the vocal tract articulation. Lastly, approximately 95% of the 3D facial motion could be predicted from the acoustic signal if small movements of the cheeks (corresponding to structured changes of intraoral air pressure) were considered. (p. 180). The researchers suggest that perceivers could in principle take advantage of these kinematic/acoustic linkages, although they also advise caution in such an interpretation as many questions remain to be answered (see next section, “Viewing the tongue during speech”).
Speech perception studies emphasize that the mouth is the most important visible region of the face for extracting visual features pertaining to speech (e.g., Hassanat, 2014). For instance, seeing only the mouth area is sufficient for speech reading and for eliciting McGurk effects (Hietanen et al., 2001; Rosenblum et al., 2000; Thomas and Jordan 2004). However, studies have shown that oral kinematic patterns are highly correlated with movements produced in the outer regions of the face, including the side of the jaw and cheeks (Vatikiotis-Bateson and Munhall, 2015). The fact that oral movements are linked to those of the jaw and cheeks suggests that such extra-oral information is available to perceivers, such as when simple occlusions block vision of the mouth of a talker (Jordan and Thomas, 2011).
Advances in understanding co-verbal facial perception have also come from the fields of face perception and face recognition. Face perception is known to depend on attending to features (e.g., mouth, eyes, and nose) and, more importantly, on featural configuration (e.g., the fact that the eyes are above the nose, and that Joe’s eyes may be wider apart than Jim’s) (Valentine, 1988; Farah et al., 1998). Analysis of the well-known “Thatcher illusion” (Thompson, 1980) shows that configuration information is less effective when the face is presented upside down (Bartlett and Searcy, 1993; Carbon et al., 2005; Bruce and Young, 2012). The Thatcher illusion occurs when viewers note that a face with inverted eyes and mouth looks grotesque when a face is upright, but not inverted. A “Thatcherized” face can greatly reduce the strength of the McGurk illusion (described previously), but only when the face is upright (Rosenblum et al., 2000; Rosenblum, 2001). Thus, a head with an inverted mouth producing “va” heard synchronously with auditory /ba/ is usually perceived as “ba” when the face is upright (no McGurk effect), but shifts to “va” when the face is inverted. However, this effect does not rely solely on inversion of the mouth segment, as it does not occur when the mouth segment is shown in isolation. These findings, named the “McThatcher” effect (Rosenblum, 2001) suggest that configuration information is important for visual and AV speech perception. Subsequent work has also related the McThatcher effect to a physiological index of brain processing, the McGurk mismatch negativity (Eskelund et al., 2015).
In summary, adults produce facial movement correlated with speech sufficient for perceivers to boost intelligibility in situations such as speech reading or speech intelligibility in noise. Facial movement also contributes to perceptual illusions (e.g., McGurk and McThatcher) suggesting features and configuration information are processed to derive co-verbal facial cues. While these facts support the general importance of facial AV information in speech processing, many aspects of AV facial processing remain poorly understood. For example, AV gating studies using phoneme identification tasks indicate that the salience and time course of audio and visual information streams differ for various sounds tested (Jesse and Massaro, 2010; Sánchez-García et al., 2018). That is, some sounds cannot be neatly classified in terms of their time course or modality. Thus, in hearing an upcoming /f/ in a VC syllable presented under AV conditions, perceivers show earlier identification in visual and audiovisual presentation (compared to audio), suggesting a visual-dominated phoneme (Sánchez-García et al., 2018). Conversely, in cases of an upcoming /ɡ/ sound under AV conditions, perceivers show no earlier identification when compared with a purely auditory presentation, implying an auditory-dominated phoneme. Finally, some phonemes (e.g., /s/) appear to have more complex time-courses and AV contributions that are not clearly classifiable as “auditory” or “visual” dominant (Sánchez-García et al., 2018). These considerations potentially complicate current models of AV processing.
In addition, some co-verbal facial patterns are quantifiable during production but not discernible to perceivers. For example, the labial stops (/p/, /b/, /m/) are not visually distinguishable by people (Fisher, 1968), but can be classified using optic flow techniques and machine recognition systems using visual features (Abel et al., 2011). While good news for machine recognition systems, these data suggest some AV contrasts are not relevant for clinical linguistic purposes.
Babies pay exquisite attention to the faces of their caretakers, and data suggest infants have early sensitivity to AV speech. Kuhl and Meltzoff (1984) conducted a preferential looking paradigm and found that 4-month-old infants favor looking at faces that match heard vowels (/ɑ/ and /i/). Infants also use multimodal information when imitating speech sounds (Legerstee, 1990) and this use of AV information extends to influences from their own lip positions (spread or puckered) during vowel perception (Yeung and Werker, 2013). As infants enter the canonical babbling phase at about seven months of age, they deploy selective attention to the mouth of a talking face when learning speech (e.g., Haith et al., 1977; Lewkowicz and Hansen-Tift, 2012). Other studies have proposed more precise timelines for this process, in consideration of infants’ exposure to AV synchronization issues and linguistic experience. For example, Hillairet de Boisferon et al. (2017) tested infants (aged 4-, 6-, 8-, 10-, and 12-mo.) in an eye-gaze study with synchronized and desynchronized speech presented in their native and non-native languages. They found that, regardless of language, desynchronization interrupted the usual pattern of relatively more attention to mouth than eyes found in synchronized speech for the 10 month olds, but not at any other age. The authors concluded that prior to the emergence of language, temporal asynchrony mediates attentional responsiveness to a talker’s mouth, after which attention to temporal synchrony declines in importance. As this research continues, we may expect a better understanding of the AV speech acquisition process.
Infants show multimodal effects for discordant AV stimuli in the McGurk paradigm (Rosenblum et al., 1997; Burnham and Dodd, 2004). Although some inconsistencies have been pointed out in these studies due to results being dependent on testing and stimulus conditions (Desjardins and Werker, 2004), the data nonetheless suggest that infants obtain important information from facial cues in learning the phonological structure of language. In summary, a varied literature suggests that young infants pay attention to face (mouth and eyes) during the first year of speech perception.
In contrast to the general importance of visual facial information in speech perception by adults and infants, these influences appear to have less effect on the speech processing of young children (Massaro, 1984; Massaro et al., 1986; Hockley and Polka, 1994; Desjardins et al., 1997; Sekiyama and Burnham, 2004; Dupont et al., 2005; Wightman et al., 2006). Rather, many studies support the overall concept that young children show an auditory input bias (Sloutsky and Napolitano, 2003).
As children mature, visual speech processing improves, although the reasons for this improvement remain poorly understood. Possibilities include gaining speech production experience, shifts in perceptual weighting and emphasis (developmental cue-trading), and age-related changes in speech reading and/or language resulting from formal education (Desjardins et al., 1997; Green, 1998; Massaro et al., 1986; Sekiyama and Burnham, 2004). Jerger et al. (2009) report a “U shaped” pattern, with a significant influence of visual speech in 4-year-olds and in 10- to 14-year-olds, but not in 5- to 9-year-olds, perhaps indicating reorganization of phonology in response to formal literacy instruction. Many factors potentially complicate children’s progression from less to more visually perceived speech. One complication is that observed effects may not reflect actual age-related effects but may instead result from different task demands imposed by the tests used at different ages (see Jerger et al., 2009, for discussion). Another issue is that children’s information processing ability changes with age. For younger children, visual speech may act as an “alerting” or “motivational” signal (Arnold and Hill, 2001; Campbell, 2006), boosting attention, and thus broadly affecting information processing. Also, children may have particular issues processing faces, due to gaze aversion, in which individuals reduce environmental stimulation in an attempt to reduce cognitive load and enhance processing (Glenberg et al., 1998). Indeed, children’s face-to-face communication is relatively poor on certain types of tasks (Doherty-Sneddon et al., 2000; Doherty-Sneddon et al., 2001). In summary, while it is generally agreed that children improve visual speech processing with maturation, studies that carefully control for task demands and age-dependent cognitive capabilities are needed to make further progress on this complex issue.
As researchers compile databases to study children’s speech development (e.g., Beckman et al., 2017), it would be useful to consider measures of AV speech in order to improve our knowledge of how these speech capabilities mature. While a growing literature is addressing the development of speech motor control in children (see e.g., reviews by Goffman et al., 2010; Smith, 2010; Green and Nip, 2010), most studies focus on the auditory modality, and the development of AV speech motor control is less described. That is, there are relatively few data addressing how young children’s facial movements contribute to their AV speech quality. Additionally, with respect to children’s speech perception, little is known about how children interpret orofacial movements for speech, how these capabilities develop over time, or how children’s co-verbal orofacial movements are perceived by others during face-to-face conversation.
One promising direction in this research addresses children’s audio-temporal binding, which refers to the determination that stimuli presented in close spatial and temporal correspondence are more likely to be “bound” into a single perceptual entity. Recent findings suggest that these capabilities coalesce slowly by early childhood (e.g., age four) and continue to refine through adolescence (Hillock-Dunn and Wallace, 2012; Lewkowicz and Flom, 2014). These data imply that children have a perceptual basis for adult-like AV speech perception at a young age and refine these skills with maturation. Extensions of this type of research to examine children of younger ages and to encompass speech and language disorders would seem promising.
Orofacial movement disorders can result from many causes, including neurological conditions (e.g., dystonias, apraxias, ataxias, and tremor), facial nerve disease and/or damage, primary muscle disorders, and medication side effects. Parkinson’s disease (PD) is a prime example, a progressive neurological disorder affecting approximately 2% of the world population over 65 years old. Individuals with PD present with gait difficulties, tremor, rigidity, balance, slowed movement (bradykinesia), and speech and swallowing problems (see Sveinbjornsdottir, 2016, for review). Approximately 70–75% of individuals with PD present with hypokinetic dysarthria, including reduced amplitude and irregularly timed speech (Hartelius and Svensson, 1994; Tjaden, 2008). Individuals with PD also commonly have a condition called “masked facies” (or hypomimia), in which there is a marked loss of facial expressiveness. Studies using facial rating scales have shown that individuals with PD produce less frequent facial expressions (Katsikitis and Pilowsky, 1988, 1991), recruit fewer muscles when reacting to certain stimuli (Simons et al., 2003), and generate lower-amplitude facial movements compared to healthy controls (Bologna et al., 2012).
Impaired orofacial movements affect how well talkers with PD are able to portray emotions (Borod et al., 1990; Tickle-Degnen and Lyons, 2004), including emotions in spoken language. For example, acoustic analyses suggest there is diminished emotional prosody in the productions of individuals with PD (Borod et al., 1990; Buck and Duffy, 1980; Hertrich and Ackermann, 1993), and perceptual analyses propose this reduced information corresponds with less successful detection of emotional qualities on the part of listeners (Pell et al., 2006). Data also indicate that individuals with PD have a deficit in the perception of emotions (e.g., Paulmann and Pell, 2010), including both the voice and the face (Gray and Tickle-Degnen, 2010), and this perceptual deficit may contribute to their inability to portray emotion in their expressions (see also Pell and Monetta, 2008; Ricciardi et al., 2015). In summary, it is likely that orofacial movement restrictions of talkers with PD contribute to their reduced capacity for expressing emotion, but the strength of this contribution has not been systematically tested.
Although studies have examined global aspects of speech prosody in PD in order to gauge speech intelligibility (e.g., Logemann et al., 1978; Klopfenstein, 2009; Ma et al., 2015), little is known about the extent to which PD orofacial impairments (e.g., hypomimia) affect their AV speech processes. One interesting approach to studying this issue may come from comparing individuals with PD to patients having Moebius Syndrome, a rare congenital disease that commonly causes facial paralysis. Nelson and Hodge (2000) conducted acoustic (F2 locus equations) and perceptual analyses (identification in V and AV modes) of /bV/ and /dV/ syllables produced by a 7 year, 11 month old girl with Moebius Syndrome. Her productions were compared with those of an age-matched healthy talker. The main results indicate the girl with facial paralysis produced conflicting cues for stop place for the /bV/ syllables and this influenced listeners’ perceptions, especially in the AV mode. Thus, the more visible phoneme showed greater perceptual deficits. It may be fruitful to investigate these issues in talkers with PD, as similar patterns would be predicted for individuals with masked facies. For such research, using an expanded inventory of speech sounds (e.g., requiring lip shape, oral aperture, and jaw position changes) would be helpful.
Orofacial movement problems may also be involved in communication difficulties affecting the mother-child dyad (see previous section on Development). Maternal depression has been consistently associated with a variety of adverse childhood developmental outcomes, including poor cognitive functioning, insecure attachment, and difficulties in behavioral and emotional adjustment (see reviews by Rutter, 1997; Murray and Cooper, 2003; Murray et al., 2015). Exposure to maternal depressive symptoms, whether during the prenatal period, postpartum period, or chronically, increases children’s risk for later cognitive and language difficulties (Sohr-Preston and Scaramella, 2006). For severely depressed mothers, reduced facial expressiveness is part of the problem: their infants are less responsive to faces and voices, as early as the neonatal period (Field et al., 2009). Newborns of mothers with high-adversity depressive symptoms are less expressive (Lundy et al., 1996) and these children show high rates of distress and avoidance of social interaction with their mothers (Murray et al., 2015, p. 140). Thus, among other problems, infants of depressed mothers may not receive normal AV (facial) cues for speech, either at the segmental or suprasegmental (prosodic) level. Further study of these topics can provide evidence about the role of AV information in infant development and potentially contribute to improved speech and language outcomes for at-risk children.
By localizing sensory feedback signals of speech motor response so that the S has a clear and immediate sensory indication of his movements, tracking tasks can be utilized as part of a rehabilitative program for those with sensorimotor impairments of the articulation apparatus. In addition to providing a simplified task that children could easily perform, auxiliary feedback channels can be used, such as visual feedback, to take the place of malfunctioning or missing feedback modes. Such an approach represents a fruitful area of study on both normal and abnormal populations to help ascertain the cortical control functions underlying speech and language.
– Harvey M. Sussman (1970, pp. 318–319)
As Sussman notes in the preceding quote from an article on tongue movement control, there is a healthy tradition of studying the tongue4 in experimental phonetics. This tradition is seen in early kymograms (Rousselot, 1897), palatograms, and linguograms (e.g., Jones, 1922; Firth, 1948; Abercrombie, 1957; Ladefoged, 1957), x-ray cinematography films (Moll, 1960; Munhall et al., 1995), and x-ray microbeam images (Kiritani et al., 1975; Westbury et al., 1990). Current imaging techniques (including MRI, Ultrasound, EPG, and EMA) are described in Chapter 2 of this volume and in reviews by Scott et al. (2014), Whalen and McDonough (2015), Cleland et al. (2016), Sorensen et al. (2016), Wang et al. (2016), Gibbon and Lee (2017), and Preston et al. (2017a). Using these imaging techniques, the speech-related motion of the tongue can be studied and related to acoustic and perceptual data. Another means of understanding the tongue is to model its biomechanics in order to better understand muscle forces and activation patterns (e.g., Perkell, 1974; Gerard et al., 2006; Stavness et al., 2012; Woo et al. 2016; Anderson et al., 2017; Hermant et al., 2017; Yu et al., 2017; Tang et al., 2017). Taking a rather different approach, this section focuses on the tongue’s visual properties, one of its lesser-studied aspects, in order to further understand AV speech processing and to introduce techniques that appear useful in training pronunciation in healthy individuals as well as persons with speech and language disorders.
Some important data addressing visual aspects of tongue movement have come from the speech technology literature, including the fields of automated speech recognition (ASR) and visual animated speech (VAS). In the development of early ASR systems, researchers working with acoustic-based speech processing systems found that results could be made more robust by adding visual information concerning articulatory movement (Potamianos et al., 2004). Critical to this effort is the notion of a viseme, the basic unit of mouth movements (Fisher, 1968; Chen and Rao, 1998). Visemes chiefly involve lip movement and mouth opening, and share a many-to-one mapping with phonemes. Visemes are classified by systems that are roughly articulatory (e.g., /p/, /b/, and /m/ belonging to one viseme group involving “bilabial” closure). However, the resulting visual under-specification can result in notorious lip-reading equivalents, such as the phrases “I love you” and “Elephant juice” involving similar visemes. In the rapidly developing field of ASR, approaches have changed dramatically since their inception in the 1960s/70s (see Huang et al., 2014; Singh et al., 2017 for review), and deep neural net (DNN) systems currently surpass performance of previous systems in both audio and AV speech recognition (e.g., Son Chung, 2017). Critically, as research has proceeded on audiovisual automatic speech recognition (AVASR) systems, data have shown that large performance gains result from the addition of visual information, both for noisy audio conditions and for clean speech (Potamianos et al., 2003; Mroueh et al., 2015; Potamianos et al., 2017).
Study of visual animated speech (VAS), such as lip synch models or text-to-AV-speech systems, also point to the usefulness of visually displayed tongue information. Facial animation, a branch of computer-generated imagery (CGI), has become increasingly sophisticated in the approaches used to simulate talking faces and heads (e.g., Theobald, 2007; Mattheyses and Verhelst, 2015). From the early development of these systems, researchers have noted that depicting the anterior part of the tongue (e.g., for such sounds as /a/ and /l/) increases speech animation quality, both in terms of subjective ratings of naturalness and improved intelligibility (e.g., Beskow, 1995; King and Parent, 2001, 2005). Work in this area continues to model tongue movement in order to increase accuracy and naturalness (e.g., Rathinavelu et al., 2006; Musti et al., 2014; Yu, 2017).
A related issue concerns the extent to which individuals can benefit from viewing the tongue’s internal motion, motion that is ordinarily inaccessible in face-to-face conversation and can only be viewed using speech instrumentation. Researchers are investigating this topic to develop applications for L2 pronunciation training and speech correction in clinical populations. As will be described in the next section, the data potentially bear on a number of questions relevant to clinical phonetics, including (a) the role of audio and visual streams in speech processing, (b) feedback and feedforward mechanisms in speech and their breakdown in disease, and (c) the relation between speech and non-speech oral motor processing.
Animated images of tongue movement have been included in computer-assisted pronunciation training (CAPT) systems, such as “Baldi” (Massaro and Cohen, 1998; Massaro, 2003; Massaro et al., 2006), “ARTUR” (Engwall et al., 2004; Engwall and Bälter, 2007; Engwall, 2008), “ATH” (Badin et al., 2008), “Vivian” (Fagel and Madany, 2008), and “Speech Tutor” (Kröger et al., 2010). These systems employ animated talking heads, most of which optionally display transparent vocal tracts showing (training) tongue movement. “Tongue reading” studies based on these systems have shown small but consistent perceptual improvement when tongue movement information is added to the visual display. Such effects are noted in word retrieval for acoustically degraded sentences (Wik and Engwall, 2008) and in a forced-choice consonant identification task (Badin et al., 2010).
Whereas the visual effects of these CAPT systems on speech perception are fairly well established, the effects on speech production are less well understood. Massaro and Light (2003) investigated the effectiveness of Baldi in teaching non-native phonetic contrasts (/r/-/l/) to Japanese learners of English. Both external and internal views (i.e., showing images of the speech articulators) of Baldi were found to be effective, with no added benefit noted for the internal articulatory view. A subsequent, rather preliminary report on English-speaking students learning Chinese and Arabic phonetic contrasts reported similar negative results for the addition of visual, articulatory information (Massaro et al., 2008). In this study, training with the Baldi avatar showing face (Mandarin) or internal articulatory processes (Arabic) provided no significant improvement in a small group of students’ productions, as rated by native listeners. In contrast, Liu et al. (2007) observed potentially positive effects of visual feedback on speech production for 101 English-speaking students learning Mandarin. This investigation contrasted three feedback conditions: Audio only, human AV, and a Baldi avatar showing visible articulators. A key finding was that for the training of Chinese final rimes, the stimuli that most involved viewing tongue motion, both the human AV and Baldi condition scores were higher than audio-only, with the Baldi condition significantly higher than the audio condition. This pattern is compatible with the view that information concerning the internal articulators assists in L2 production.
Researchers have further addressed these issues by adapting speech instrumentation systems in order to provide real-time visual feedback of tongue motion. An electropalatography (EPG) system was used to provide visual feedback for accent reduction in the training of two Japanese students learning English /r/ and /l/ distinctions (Gibbon et al., 1991). Positive findings for EPG feedback were also noted for three Thai-speaking subjects learning English/r/-/l/, /s/-/ʃ/, and /t/-/θ/ distinctions (Schmidt and Beamer, 1998). According to these authors, “EPG makes possible exploration of the details of sound production by L2 speakers, as well as possible effects on L1 sound production related to the learning of new or modified articulations” (p. 402).
More recently, Hacking et al. (2017) used EPG to train palatalized consonant productions to native American English learners of Russian. Acoustic analysis (second formant of the pre-consonantal vowel, and final consonant release “noise”) suggested significant improvement with this phonological contrast. However, perceptual tests with three native Russian listeners showed only a modest increase in identification accuracy. The authors concluded that such short-term EPG training may nevertheless be effective for adult L2 learners.
Studies conducted in our laboratory have used electromagnetic articulography (EMA) as a means of investigating visual feedback in training non-native consonants and vowels for healthy talkers. Levitt and Katz (2008) trained two groups of American English speakers to produce Japanese /r/ (apico-postalveolar flap). One group received traditional L2 instruction alone and the other group received traditional L2 instruction plus visual feedback for tongue movement provided by a 2D EMA system (Carstens AG100). Acoustic (consonant duration) and perceptual (on/off target judgments by Japanese native listeners) results indicated improved acquisition and maintenance by the participants who received traditional instruction plus EMA training. These findings suggest that visual information regarding consonant place of articulation can assist L2 learners with accent modification.
Recent studies from our lab have utilized real-time software designed to interface with 3D EMA-based input (Opti-Speech, Katz et al., 2014). This system is designed to provide talkers with online visual feedback of their tongue and jaw movement, with virtual articulatory targets that can be set by the operator during speaking practice (Figure 19.1). In an initial study, four monolingual English speakers produced stop CV syllables that alternated in initial consonant place of articulation (e.g., /pɑ/-/kɑ/-/tɑ/-/jɑ/). One talker was given articulatory visual feedback of his tongue movement and requested to “hit the target” during production. The target region was a 1 cm virtual sphere (placed at the alveolar ridge), that changed color when the tongue tip sensor entered. Results showed that subjects in the no-feedback condition performed less accurately than the subject given visual feedback. These findings suggest that real-time tongue tracking may be useful for phonetic training purposes, including L2 learning applications concerning consonantal place of articulation (Katz et al., 2014).
Katz and Mehta (2015) used the Opti-Speech system to investigate the accuracy with which American English talkers can produce a novel, non-English speech sound (a voiced, coronal, palatal stop) and whether learning can benefit from short-term training with visual feedback. Five talkers’ productions were evaluated based on kinematic (EMA/tongue-tip spatial positioning) and acoustic (burst spectra) measures. The kinematic results indicated a rapid gain in accuracy associated with visual feedback training for all talkers, which corresponded with acoustic shifts in the predicted direction for three of the five talkers. In summary, although the data from these small-scale studies remain preliminary, the findings suggest that augmented visual information concerning one’s own tongue movement can assist skill acquisition when learning consonant place of articulation.
Studies are investigating vowel production under real-time tongue visual feedback conditions. Suemitsu et al. (2015) provided real-time EMA-based articulatory feedback to facilitate production of an unfamiliar English vowel (/æ/) by five native speakers of Japanese. Learner-specific vowel target positions were computed for each participant (using a model estimated from American English vowels) and feedback was provided in the form of a multiple-sensor, mid-sagittal display. Acoustic analysis of subjects’ productions indicated that acoustic and articulatory training resulted in significantly improved /æ/ productions.
A related approach to tongue-based visual feedback is to devise speech training games that incorporate consonant and vowel targets. Tilsen et al. (2015) describe preliminary findings with an EMA real-time feedback system that uses input from a WAVE magnetometer system for a series of articulatory training games. Tasks included hitting a target line positioned along the palate with the tongue tip while saying “ta,” bilabial closure and release (“QuickLips”), and a rapid tongue targeting task (“QuickTongue”). Overall, it was suggested that articulatory biofeedback systems can provide useful methods for investigating speech motor control, conducting therapy, and improving phonetic performance by increasing motivation.
Ultrasound offers portability and cost advantages over other speech imaging systems and its use in visual feedback applications is being actively pursued. For instance, Gick et al. (2008) describe the use of ultrasound to train English /l/ and /r/ for three Japanese students with persistent difficulties producing these sounds in certain phonetic environments. After an initial assessment, the participants were shown ultrasound video-recordings of their “best and most troublesome productions” in a brief training session. Post-training assessment indicated that all participants showed improvement, including stimulus generalization to other lexical items. The authors suggested that ultrasound visual feedback has important potential in L2 pronunciation instruction. Positive training results for ultrasound in L2 applications have also been reported for Japanese students learning the vowels /y/ and /u/ in French (Pillot-Loiseau et al., 2013), and for Italian talkers learning the American English /ɑ/-/ʌ/ distinction (Sisinni et al., 2016). These data suggest that, at least for certain consonants and vowels, ultrasound visual feedback of tongue motion is beneficial for L2 learning applications.
In summary, studies based on instructional avatars and on real-time imaging systems (EPG, EMA and ultrasound) suggest that visual real-time articulatory feedback is helpful for improving L2 learning of consonant and vowel contrasts in healthy children and adults. More research is needed to expand our knowledge of the motor principles involved in this type of training and the types of sounds amenable to training by different methodologies.
Of the many recent speech imaging technologies, EPG has perhaps seen the widest use in providing visual feedback for various clinical populations. This includes assessment and treatment of children with speech sound disorders (e.g., Morgan Barry and Hardcastle, 1987; Hickey, 1992; Dagenais, 1995; Gibbon et al., 1999; Gibbon and Wood, 2010), cleft palate (e.g., Abe et al., 1977; Dent et al., 1992; Gibbon et al., 2007; Scobbie et al., 2004; Lohmander et al., 2010; Maine and Serry, 2011), Down’s syndrome (e.g., Wrench et al., 2002; Cleland et al., 2009), hearing impairment (e.g., Fletcher and Hasagawa, 1983; Dagenais, 1992; Crawford, 1995; Martin et al., 2007; Pratt, 2007; Bacsfalvi et al., 2007; Bacsfalvi and Bernhardt, 2011), and acquired neurological disorders (e.g., Morgan Barry, 1995; Gibbon and Wood, 2003; Lundeborg and McAllister, 2007; Morgan et al., 2007; Nordberg et al., 2011).
A recent study illustrates some of the strengths of EPG therapy in working with children, while also showing the complexity of working with different sound classes. Hitchcock et al. (2017) provided EPG feedback therapy for five English-speaking, school-aged children who misarticulated /r/ in words. The results indicated that 4/5 participants were able to accurately produce /r/ during treatment (as judged perceptually and acoustically), while two participants generalized these patterns to non-treated targets (as judged by blinded listeners). It was concluded that EPG therapy can help some children with rhotic errors, but its utility appears to vary across individuals (perhaps because /r/ can be realized in so many more ways than were illustrated by the EPG targets in this experiment).
EPG feedback studies of adult clinical populations have investigated glossectomy (Suzuki, 1989; Wakumoto, 1996) and neurological disorders (Hartelius et al., 2001; Howard and Varley, 1995; McAuliffe and Ward, 2006; Mauszycki et al., 2016). Overall, this literature overwhelmingly suggests that providing child and adult patients with visual information concerning tongue-palate contact improves the accuracy of consonant production. Nevertheless, a recent study by Mauszycki and colleagues (2016) illustrate some of the potential complexities with this type of translational research and highlight some important directions for future research. These investigators treated five individuals with Broca’s aphasia and apraxia of speech (AOS) on a series of target sounds (treated and untreated) in two-word phrases. Participants received articulatory-kinematic treatment in combination with EPG visual feedback. Results indicated improved accuracy for the majority of treated sounds, with generalization for most trained sounds (including better long-term maintenance of treated sounds in trained and untrained stimuli for two of the participants). The authors concluded that EPG may be a potential treatment tool for individuals with AOS, pending several considerations: Many treatment steps were taken in the study (and in other recent visual feedback studies) that could lead to participant improvement, including pairing visual feedback with verbal feedback, progressing from simple to more complex speech tasks, gradually reducing clinician feedback, and using a large number of treatment trials within a session. Thus, teasing out the exact effects of visual feedback in these studies is important to determine whether providing such therapy for clinical populations offers advantages over more traditional types of therapy.
Electromagnetic articulography (EMA) has been increasingly used to investigate clinical populations, as current systems offer the ability to record both consonant and vowel articulation in 3D. Because EMA systems require the attachment of sensors to the speech articulators, it is somewhat more invasive than EPG and therefore study populations have tended to involve adults rather than children (cf. Katz and Bharadwaj, 2001). However, as researchers devise better methods of sensor placement, more EMA studies involving children are being reported (e.g., Vick et al., 2014, 2017). Feedback studies of adult clinical populations have included individuals with Broca’s aphasia and apraxia of speech (Katz et al., 1999, 2002, 2007, 2010; McNeil et al., 2007, 2010), dysarthria (Watkins, 2015) and hearing impairment (Bock, 2009). Across a series of studies completed in our laboratory using midsagittal EMA displays, we found that lingual visual feedback generally helped individuals with AOS improve the accuracy of consonant place of articulation (see Katz and McNeil, 2010, for review). All the same, as described in the previous discussion of EPG training studies, more work must be done to better understand the exact contribution that visual training provides over associated intervention procedures. The variable strength of effects noted for different sounds and for different participants remains a challenge to our current understanding.
Other new challenges and opportunities are noted for real-time EMA feedback experimentation. For instance, our early work was limited to showing patients midsagittal images of their articulatory trajectories, together with spatial “targets” representing regions that the EMA sensors must hit in order to receive real-time augmented visual feedback. Using newer systems (e.g., Carstens AG500, Carstens Medezinelektronik, GmbH), one can present high-resolution, spherical targets and consider a greater range of articulatory motion, including diagonal and loop-like patterns that may be more typical of speech. One can also devise pursuit tracking experiments to determine the precision with which the tongue can follow oscillating targets at different speeds and at either predictable or unpredictable frequencies (e.g., Fazel and Katz, 2016). These experimental capabilities permit study of issues such as whether there are shared (or disparate) motor bases for speech and non-speech motor control (e.g., by making targets more speech-like or less speech-like) and the extent to which participants recruit feedforward and feedback processes in voluntary oral motor control.
Other researchers have suggested ways to make 3D EMA feedback systems more user-friendly and affordable for clinical and teaching settings (Shtern et al., 2012; Haworth et al., 2014; Tilsen et al., 2015). For instance, Shtern and colleagues (2012) describe a game system based on an interactive EMA system (WAVE, Northern Digital Inc, Waterloo, Canada) that represents participant tongue position as either a simulated wooden plank that can be maneuvered up and down, or as a honeybee that can be guided to a target flower. Further data are needed to determine whether different types of interactive displays are better suited for particular clinical populations, whether particular views are preferred, and whether certain types of game training scenarios (e.g., competitive versus cooperative) are optimal. These parameters will likely interact with the type of speech sounds being trained.
With developments in ultrasound technology, visual feedback research has greatly accelerated, particularly for children with speech and language disorders. Ultrasound intervention studies have been conducted for children with developmental speech sound disorders (e.g., Shawker and Sonies, 1985; Adler-Bock et al., 2007; Byun et al., 2014; Cleland et al., 2015; Bressmann et al., 2016; Preston et al., 2017b), hearing impairment (Bernhardt et al., 2003, 2005; Bacsfalvi et al., 2007; Bacsfalvi, 2010; Bacsfalvi and Bernhardt, 2011), cleft lip and palate (Roxburgh et al., 2016), and childhood apraxia of speech, or CAS (Preston et al., 2016, 2017c). For adults, Down’s syndrome (Fawcett et al., 2008), glossectomy (Blyth et al., 2016), AOS (Preston and Leaman, 2014), and nonfluent aphasia (Haldin et al., 2017) have recently been investigated.
Similar to EPG visual feedback, a preponderance of ultrasound studies suggest positive results for intervention paradigms conducted with clinical populations. A potential difference from EPG is that ultrasound can be used to provide an image of the tongue (“ultrasound tongue imaging”) which is arguably less abstract and more intuitive than the palate-contact image displayed by EPG. In addition, researchers can use ultrasound to image the tongue shape of vowels in an accurate and relatively non-invasive manner. Nonetheless, this research is also in an early stage and many challenges remain. For example, a recent study compared the ability of adults to interpret slow motion EPG and ultrasound (silent) movies and reported some surprising results (Cleland et al., 2013). As predicted, participants scored above chance for consonants using both techniques, suggesting that most participants can “tongue-read” these sounds. However, EPG was preferred by subjects and showed higher overall accuracy rates for both consonants and vowels, while participants performed at chance level for vowels shown in the ultrasound condition. These latter findings suggest that feedback quality may play a role: Many participants described the ultrasound images being “unclear” or “fuzzy,” while those preferring ultrasound described benefit from an “actual tongue” (p. 308). The authors further suggest that the success of using ultrasound in therapy is likely not only due to tongue-reading, but also the training and support of a clinician (p. 309).
To summarize, studies using real-time visual feedback (based on EPG, EMA, or ultrasound) suggest that viewing normally invisible movement of the tongue can assist in pronunciation training for individuals with speech/language disorders. However, most of these studies have examined small subject groups and more data are needed. Future investigations should continue to examine how articulatory training draws on principles of motor learning, including the type, frequency, and scheduling of feedback (Ballard et al., 2012). In addition, studies should further address the functional and neural underpinnings of the visual feedback gains shown by participants.
An intriguing question concerns whether special processing routes may be involved when accessing (normally) invisible articulators during the use of feedback systems (e.g., with Opti-Speech or Vizart3D, Hueber et al., 2012). This issue may be relevant when interpreting other data, such as the results of a discordant, cross-modal feedback paradigm (e.g., McGurk effect). Real-time visual feedback of the articulators may plausibly engage slightly different behavioral mechanisms and cortical pathways than those pathways involved in more traditional learning (e.g., “watch me, memorize, repeat”).
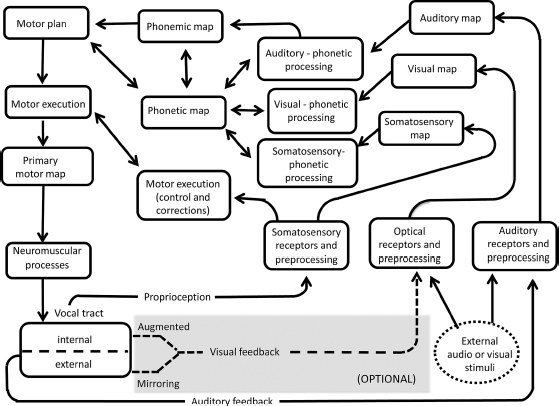
One way to address this issue is to consider recent visual feedback findings in light of current neurocomputational models of speech production (e.g., “Directions Into Velocities of Articulators” (DIVA) (Guenther and Perkell, 2004; Guenther, 2006; Guenther et al., 2006; Guenther and Vladusich, 2012) and “ACTion” (ACT) (Kröger et al., 2009). These models seek to provide an integrated explanation for speech processing, incorporated in testable artificial neural networks. Both DIVA and ACT assume as input an abstract speech sound unit (a phoneme, syllable, or word), and generate as output both articulatory and auditory representations of speech. The systems operate by computing neural layers (or “maps”) as distributed activation patterns. Producing an utterance involves fine-tuning between speech sound maps, sensory maps, and motor maps, guided by feedforward (predictive) processes and concurrent feedback from the periphery. Learning in these models critically relies on forward and inverse processes, with the internal speech model iteratively strengthened by the interaction of feedback information. This feedback may include simple mirroring of the lips and jaw, or instrumentally augmented visualizations of the tongue (via EMA, ultrasound, MRI, or articulatory inversion systems that convert sound signals to visual images of the articulators; e.g., Hueber et al., 2012). The remaining audio and visual preprocessing and mapping stages are similar between this internal route and the external (modeled) pathways.
Findings of L2 learning under conditions of visual (self) feedback training supports this internal route and the role of body sensing and motor familiarity (shaded region at bottom of Figure 19.2). This internal route also accounts for the fact that talkers can discern between natural and unnatural tongue movements displayed by an avatar (Engwall and Wik, 2009), and that training systems based on a talkers’ own speech may be especially beneficial for L2 learners (see Felps et al., 2009 for discussion).
The neural processing of visual feedback for speech learning is an interesting topic for future research. Data on this topic are few. A recent ultrasound training study examined individuals with Broca’s type aphasia and included fMRI imaging before and after tongue-image “sensory motor feedback” in order to investigate potential neural correlates of training (Haldin et al., 2017). For both rhyme detection and syllable repetition tasks, the post-training results indicated cerebral activation for brain regions related to articulatory, auditory and somatosensory processes. These included changes in left superior-medial frontal and left precentral gyrus, right frontal middle and superior and superior temporal gyri, and right cerebellum for rhyme detection. The authors interpreted these cerebral changes as evidence of strengthened production and perception networks, while the cerebellar data changes were considered possible sources of improved attention, memory, or internal model factors associated with speech gains. For syllable repetition, feedback training corresponded with increased activation of the left inferior frontal gyrus and left insula. Activation in these regions were claimed to relate to improved sensorimotor interaction and articulatory coordination.
In addition to brain systems associated with articulatory, auditory, and somatosensory processes, visual feedback tasks require a participant to sense one’s own body in motion. As described in Daprati et al. (2010), this involves both corporeal identity (the feeling of one’s own body) and sense of agency (experiencing oneself as the cause of an action). Substantial data implicate parietal and insular cortex supporting these processes awareness (e.g., Farrer et al., 2003, 2008; Berlucchi and Aglioti, 2010), including specialized roles of the two parietal lobes to generate and supervise the internal model (left parietal) while the right parietal maintains spatial (egocentric) reference. Based on these findings, one might predict contributions from parietal and insular circuitry to support visual articulatory feedback. With respect to the specific task of visual feedback and speech learning, Berthier and Moreno-Torres (2016) discuss two specific structures that may be expected to participate: anterior insular cortex and anterior cingulate cortex. These structures are noted to be part of larger systems that can be voluntarily self-controlled (Ninaus et al. 2013), process multimodal information (Moreno-Torres et al., 2013), and relate to speech initiation (Goldberg, 1985). Additional brain structures that may play a role are those associated with reward dependence during behavioral performance, including lateral prefrontal cortex and the striatum (Pochon et al., 2002; Ullsperger and von Cramon, 2003; Liu et al., 2011; Dayan et al., 2014; Widmer et al., 2016).
Katz and Mehta (2015) speculate that speech visual feedback for normally invisible articulators (such as the tongue) rely in part on oral self-touch mechanism (particularly for consonant production) by visually guiding participants to the correct place of articulation, at which point somatosensory processes take over. This mechanism may prove particularly important for consonants, which are produced with more articulatory contact than vowels (see also Ladefoged, 2005). As data accrue with respect to both external (mirroring) and internal (“tongue reading”) visual speech feedback, it will be important to continue study of the relevant neural control structures, in order to develop more complete models of speech production. Future studies should focus on extending the range of speech sounds, features, and articulatory structures trained with real-time feedback, with a focus on vowels as well as consonants. It will also be important to examine the extent and nature of individual variation across talkers.
This chapter has briefly reviewed the history of clinical phonetics, emphasizing its prominence within the larger field of clinical linguistics and noting rapid developments in light of innovations in medicine, linguistics, and speech science. Two important goals of clinical phonetics are to (1) develop scientific and clinical knowledge based on two-way information flow between clinical practice and linguistic/cognitive theory, and (2) perfect symbol systems useful in describing healthy and disordered speech. These goals are considered in light of recent evidence concerning the audiovisual (AV) nature of speech processing. Evidence is reviewed from speech produced and perceived by adults, children, and individuals with speech/language disorders. We find that because healthy speech production and perception is strongly audiovisual in nature, our understanding of speech- and language-disordered populations should include a similar emphasis. This will entail scrutiny of speech-related head and orofacial motion when considering the speech and language difficulties of individuals with communication disorders, as well as their families. Such research may also involve new ways of thinking about the articulators most commonly associated with speech (lips, jaw, tongue and velum); for instance, by considering the role played by normally invisible articulators, such as the tongue, when made visible by means of real-time instrumentation.
In the course of this chapter, many examples of AV properties related to speech and language have been described, including instances of impairment resulting from the misprocessing of such information. We may draw examples for the first current goal of clinical phonetics, namely two-way information flow between theory and practice. Researchers have used neurocomputational frameworks to gain important insights about speech and language disorders, including apraxia of speech (AOS) in adults (Kröger et al., 2011; Hickok et al., 2014; Maas et al., 2015), childhood apraxia of speech (Terband et al., 2009; Terband and Maassen, 2010), developmental speech sound disorders (Terband et al., 2014), and stuttering (Max et al., 2004; Civier et al., 2010). For example, DIVA and ACT simulations have been used to test the claim that apraxic disorders result from relatively preserved feedback (and impaired feedforward) speech motor processes (Civier et al., 2010; Maas et al., 2015) or from defective neural motor speech mappings leading to types of AOS of varying severity (Kröger et al., 2011). These neurocomputational modeling-based findings correspond with largely positive results from visual augmented feedback intervention studies for individuals with AOS (see Katz and McNeil, 2010 for review; also, Preston and Leaman, 2014). Overall, recent intervention findings have suggested that visual augmented feedback of tongue movement can help remediate speech errors in individuals with AOS, presumably by strengthening the internal model. Other clinical studies have reported that visual feedback can positively influence the speech of individuals with a variety of speech and language problems in children and adults, including articulation/phonological disorders, residual sound errors, and dysarthria. This research has included training with electropalatography (EPG), ultrasound, and strain gauge transducer systems (Shirahige et al., 2012; Yano et al., 2015).
The findings concerning AV processing also potentially relate to the second goal of clinical phonetics, perfecting symbol systems. Over the years, some researchers have mentioned the concept of “optical phonetics,” either in relation to the visual perception of prosody (e.g., Scarborough et al., 2009) or for lip-reading (e.g., Jiang et al., 2007; Bernstein and Jiang, 2009). Understandably, these considerations have not affected the International Phonetic Alphabet, which is based on features that express either articulatory or acoustic characteristics. However, assuming our understanding of AV speech processing continues to support the importance of AV speech processing (and deficits with impairment), I would think it reasonable that phonetic features such as “decreased head motion,” “excessive head motion,” and “masked facies” (problems of AV speech noted in clinical populations) should be considered for the ExtIPA. Here, I leave this as a friendly suggestion for future consideration.
The author gratefully acknowledges support from the University of Texas at Dallas Office of Sponsored Projects, the UTD Callier Center Excellence in Education Fund, and a grant awarded by NIH/NIDCD (R43 DC013467) for portions of this work. I greatly appreciate Carstens Medezinelektronik GmbH for material support towards this research. I would also like to thank Peter F. Assmann, Martin J. Ball, Susan Behrens, Bryan Gick, Lisa Goffman, Sonya Mehta, and Patrick Reidy for helpful comments on previous versions of this manuscript. All remaining errors are mine alone.
Abe, M., Fukusako, Y. and Sawashima, M., 1977. Results of articulation training on 60 cleft palate patients. The Japan Journal of Logopedics and Phoniatrics, 18(2), pp. 67–73.
Abel, J., Barbosa, A.V., Black, A., Mayer, C. and Vatikiotis-Bateson, E., 2011. The labial viseme reconsidered: Evidence from production and perception. The Journal of the Acoustical Society of America, 129(4), p. 2456.
Abercrombie, D., 1957. Direct palatography. STUF-Language Typology and Universals, 10(1–4), pp. 21–25.
Adler-Bock, M., Bernhardt, B.M., Gick, B. and Bacsfalvi, P., 2007. The use of ultrasound in remediation of North American English /r/ in 2 adolescents. American Journal of Speech-Language Pathology, 16(2), pp. 128–139.
Alcorn, S., 1932. The Tadoma method. Volta Review, 34, pp. 195–198.
Alsius, A., Navarra, J., Campbell, R. and Soto-Faraco, S., 2005. Audiovisual integration of speech falters under high attention demands. Current Biology, 15(9), pp. 839–843.
Alsius, A., Paré, M. and Munhall, K.G., 2017. Forty years after Hearing lips and seeing voices: The McGurk effect revisited. Multisensory Research, 31(1–2), pp. 111–144.
Amman, J.C., 1700. Dissertatio de loquela, qua non solum vox humana, et loquendi artificium ex originibus suis eruuntur: Sed et traduntur media, quibus ii, qui ab incunabulis surdi et muti fuerunt, loquelam adipisci … possint (Vol. 1). Amsterdam: Apud Joannem Wolters.
Amman, J.C., 1694. The Talking Deaf Man: Or, a Method Proposed Whereby He Who Is Born Deaf May Learn to Speak. London: Tho. Howkins
Anderson, P., Fels, S., Harandi, N.M., Ho, A., Moisik, S., Sánchez, C.A., Stavness, I. and Tang, K., 2017. FRANK: A hybrid 3D biomechanical model of the head and neck. Biomechanics of Living Organs, pp. 413–447.
Anderson, S.R., Keating, P.A., Huffman, M.K. and Krakow, R.A., 2014. Nasals, Nasalization, and the Velum (Vol. 5). Amsterdam: Elsevier.
Arnold, P. and Hill, F., 2001. Bisensory augmentation: A speechreading advantage when speech is clearly audible and intact. British Journal of Psychology, 92(2), pp. 339–355.
Bacsfalvi, P., 2010. Attaining the lingual components of /r/ with ultrasound for three adolescents with cochlear implants. Canadian Journal of Speech-Language Pathology & Audiology, 34(3).
Bacsfalvi, P. and Bernhardt, B.M., 2011. Long-term outcomes of speech therapy for seven adolescents with visual feedback technologies: Ultrasound and electropalatography. Clinical Linguistics & Phonetics, 25(11–12), pp. 1034–1043.
Bacsfalvi, P., Bernhardt, B.M. and Gick, B., 2007. Electropalatography and ultrasound in vowel remediation for adolescents with hearing impairment. Advances in Speech Language Pathology, 9(1), pp. 36–45.
Badin, P., Elisei, F., Bailly, G. and Tarabalka, Y., 2008, July. An audiovisual talking head for augmented speech generation: Models and animations based on a real speaker’s articulatory data. In International Conference on Articulated Motion and Deformable Objects (pp. 132–143). Springer, Berlin, Heidelberg.
Badin, P., Tarabalka, Y., Elisei, F. and Bailly, G., 2010. Can you ‘read’ tongue movements? Evaluation of the contribution of tongue display to speech understanding. Speech Communication, 52(6), pp. 493–503.
Ball, M.J., Code, C., Rahilly, J. and Hazlett, D., 1994. Non-segmental aspects of disordered speech: Developments in transcription. Clinical linguistics & phonetics, 8(1), pp. 67–83.
Ball, M.J., Esling, J. and Dickson, C., 1995. The VoQS system for the transcription of voice quality. Journal of the International Phonetic Association, 25(2), pp. 71–80.
Ball, M., Müller, N., Klopfenstein, M. and Rutter, B., 2009. The importance of narrow phonetic transcription for highly unintelligible speech: Some examples. Logopedics Phoniatrics Vocology, 34(2), pp. 84–90.
Ballard, K.J., Smith, H.D., Paramatmuni, D., McCabe, P., Theodoros, D.G. and Murdoch, B.E., 2012. Amount of kinematic feedback affects learning of speech motor skills. Motor Control, 16, pp. 106–119.
Bartlett, J.C. and Searcy, J., 1993. Inversion and configuration of faces. Cognitive Psychology, 25(3), pp. 281–316.
Bastien-Toniazzo, M., Stroumza, A. and Cavé, C., 2010. Audio-visual perception and integration in developmental dyslexia: An exploratory study using the McGurk effect. Current Psychology Letters. Behaviour, Brain & Cognition, 25(3, 2009).
Beckman, M.E., Plummer, A.R., Munson, B. and Reidy, P.F., 2017. Methods for eliciting, annotating, and analyzing databases for child speech development. Computer Speech & Language, 45, pp. 278–299.
Bell, A.G., 1872. Establishment for the Study of Vocal Physiology: For the Correction of Stammering, and Other Defects of Utterance: And for Practical Instruction in “Visible Speech.” [Boston: AG Bell], 1872 (Boston: Rand, Avery).
Bell, Alexander Melville (Visible Speech, 1867).
Berlucchi, G. and Aglioti, S.M., 2010. The body in the brain revisited. Experimental Brain Research, 200(1), p. 25.
Bernhardt, B., Gick, B., Bacsfalvi, P. and Adler-Bock, M., 2005. Ultrasound in speech therapy with adolescents and adults. Clinical Linguistics & Phonetics, 19(6–7), pp. 605–617.
Bernhardt, B., Gick, B., Bacsfalvi, P. and Ashdown, J., 2003. Speech habilitation of hard of hearing adolescents using electropalatography and ultrasound as evaluated by trained listeners. Clinical Linguistics & Phonetics, 17(3), pp. 199–216.
Bernstein, L.E., Eberhardt, S.P. and Demorest, M.E., 1989. Single-channel vibrotactile supplements to visual perception of intonation and stress. The Journal of the Acoustical Society of America, 85(1), pp. 397–405.
Bernstein, L.E. and Jiang, J., 2009. Visual Speech Perception, Optical Phonetics, and Synthetic Speech. In Visual Speech Recognition: Lip Segmentation and Mapping (pp. 439–461).IGI Global, Hershey, PA.
Berthier, M.L. and Moreno-Torres, I., 2016. Commentary: Visual feedback of tongue movement for novel speech sound learning. Frontiers in Human Neuroscience, 10, p. 662.
Beskow, J., 1995. Rule-based visual speech synthesis. In EUROSPEECH ’95. 4th European Conference on Speech Communication and Technology (pp. 299–302).
Blyth, K.M., Mccabe, P., Madill, C. and Ballard, K.J., 2016. Ultrasound visual feedback in articulation therapy following partial glossectomy. Journal of Communication Disorders, 61, pp. 1–15.
Bock, R., 2009. Effectiveness of visual feedback provided by an electromagnetic articulograph (EMA) system: training vowel production in individuals with hearing impairment. Independent Studies and Capstones. Paper 206. Program in Audiology and Communication Sciences, Washington University School of Medicine.
Bologna, M., Fabbrini, G., Marsili, L., Defazio, G., Thompson, P.D. and Berardelli, A., 2012. Facial bradykinesia. Journal of Neurology, Neurosurgery, and Psychiatry, pp. 1–5.
Borod, J.C., Welkowitz, J., Alpert, M., Brozgold, A.Z., Martin, C., Peselow, E. and Diller, L., 1990. Parameters of emotional processing in neuropsychiatric disorders: Conceptual issues and a battery of tests. Journal of Communication Disorders, 23(4–5), pp. 247–271.
Bressmann, T., Harper, S., Zhylich, I. and Kulkarni, G.V., 2016. Perceptual, durational and tongue displacement measures following articulation therapy for rhotic sound errors. Clinical Linguistics & Phonetics, 30(3–5), pp. 345–362.
Brooke, N.M. and Summerfield, Q., 1983. Analysis, synthesis, and perception of visible articulatory movements. Journal of Phonetics, 11(1), pp. 63–76.
Bruce, V. and Young, A.W., 2012. Face Perception. New York, NY: Psychology Press.
Buck, R. and Duffy, R.J., 1980. Nonverbal communication of affect in brain-damaged patients. Cortex, 16(3), pp. 351–362.
Burnham, D. and Dodd, B., 1996. Auditory-visual speech perception as a direct process: The McGurk effect in infants and across languages. In Speechreading by Humans and Machines (pp. 103–114). Berlin, Heidelberg: Springer.
Burnham, D. and Dodd, B., 2004. Auditory-visual speech integration by pre-linguistic infants: Perception of an emergent consonant in the McGurk effect. Developmental Psychobiology, 44, pp. 209–220.
Busso, C., Deng, Z., Grimm, M., Neumann, U. and Narayanan, S., 2007. Rigid head motion in expressive speech animation: Analysis and synthesis. IEEE Transactions on Audio, Speech, and Language Processing, 15(3), pp. 1075–1086.
Byun, T.M., Hitchcock, E.R. and Swartz, M.T., 2014. Retroflex versus bunched in treatment for rhotic misarticulation: Evidence from ultrasound biofeedback intervention. Journal of Speech, Language, and Hearing Research, 57(6), pp. 2116–2130.
Campbell, R., 2006. Audio-visual speech processing. The Encyclopedia of Language and Linguistics, pp. 562–569.
Cantiniaux, S., Vaugoyeau, M., Robert, D., Horrelou-Pitek, C., Mancini, J., Witjas, T. and Azulay, J.P., 2010. Comparative analysis of gait and speech in Parkinson’s disease: Hypokinetic or dysrhythmic disorders? Journal of Neurology, Neurosurgery & Psychiatry, 81(2), pp. 177–184.
Carbon, C.C., Grüter, T., Weber, J.E. and Lueschow, A., 2007. Faces as objects of non-expertise: Processing of thatcherised faces in congenital prosopagnosia. Perception, 36(11), pp. 1635–1645.
Carbon, C.C., Schweinberger, S.R., Kaufmann, J.M. and Leder, H., 2005. The Thatcher illusion seen by the brain: An event-related brain potentials study. Cognitive Brain Research, 24(3), pp. 544–555.
Chen, T. and Rao, R., 1998. Audio-visual integration in multimodal communication. Proceedings of the IEEE, 86(5), pp. 837–852.
Son Chung, J., Senior, A., Vinyals, O. and Zisserman, A., 2017. Lip reading sentences in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 6447–6456).
Civier, O., Tasko, S.M. and Guenther, F.H., 2010. Overreliance on auditory feedback may lead to sound/syllable repetitions: Simulations of stuttering and fluency-inducing conditions with a neural model of speech production. Journal of Fluency Disorders, 35(3), pp. 246–279.
Cleland, J., McCron, C. and Scobbie, J.M., 2013. Tongue reading: Comparing the interpretation of visual information from inside the mouth, from electropalatographic and ultrasound displays of speech sounds. Clinical Linguistics & Phonetics, 27(4), pp. 299–311.
Cleland, J., Scobbie, J.M. and Wrench, A.A., 2015. Using ultrasound visual biofeedback to treat persistent primary speech sound disorders. Clinical Linguistics & Phonetics, 29(8–10), pp. 575–597.
Cleland, J., Scobbie, J.M. and Zharkova, N., 2016. Insights from ultrasound: Enhancing our understanding of clinical phonetics. Clinical Linguistics and Phonetics, 30, pp. 171–173.
Cleland, J., Timmins, C., Wood, S.E., Hardcastle, W.J. and Wishart, J.G., 2009. Electropalatographic therapy for children and young people with Down’s syndrome. Clinical Linguistics & Phonetics, 23, pp. 926–939.
Code, C. and Ball, M.J., 1984. Experimental Clinical Phonetics: Investigatory Techniques in Speech Pathology and Therapeutics. Worcester: Billing & Sons Limited.
Coleman, J., 2011. A history maker. Journal of Linguistics, 47, pp. 201–217.
Crawford, R., 1995. Teaching voiced velar stops to profoundly deaf children using EPG, two case studies. Clinical Linguistics and Phonetics, 9, pp. 255–270.
Crystal, D., 1980. An Introduction to Language Pathology. London: Edward Arnold.
Crystal, D., 1981. Clinical Linguistics: Disorders of Human Communication vol. 3. Wien: Sprinter.
Crystal, D., 1984. Linguistic Encounters with Language Handicap. Oxford: Wiley-Blackwell.
Crystal, D., 2002. Clinical linguistics and phonetics’ first 15 years: An introductory comment. Clinical Linguistics & Phonetics, 16(7), pp. 487–489.
Crystal, D., 2013. Clinical linguistics: Conversational reflections. Clinical Linguistics Phonetics, 27(4), pp. 236–243.
Cvejic, E., Kim, J. and Davis, C., 2010. Prosody off the top of the head: Prosodic contrasts can be discriminated by head motion. Speech Communication, 52(6), pp. 555–564.
Dagenais, P.A., 1992. Speech training with glossometry and palatometry for profoundly hearing-impaired children. Volta Review, 94, pp. 261–282.
Dagenais, P.A., 1995. Electropalatography in the treatment of articulation/phonological disorders. Journal of Communication Disorders, 28, pp. 303–329.
Daprati, E., Sirigu, A. and Nico, D., 2010. Body and movement: Consciousness in the parietal lobes. Neuropsychologia, 48(3), pp. 756–762.
Davis, C. and Kim, J., 2006. Audio-visual speech perception off the top of the head. Cognition, 100(3), pp. B21–B31.
Dayan, E., Hamann, J.M., Averbeck, B.B. and Cohen, L.G., 2014. Brain structural substrates of reward dependence during behavioral performance. Journal of Neuroscience, 34, 16433–16441.
Delbeuck, X., Collette, F. and Van der Linden, M., 2007. Is Alzheimer’s disease a disconnection syndrome? Evidence from a crossmodal audio-visual illusory experiment. Neuropsychologia, 45(14), pp. 3315–3323.
Denes, P.B. and Pinson, E., 1993. The Speech Chain. London: Macmillan.
Dent, H., Gibbon, F. and Hardcastle, W., 1992. Inhibiting an abnormal lingual pattern in a cleft palate child using electropalatography. In M.M. Leahy and J.L. Kallen (Eds.) Interdisciplinary Perspectives in Speech and Language Pathology (pp. 211–221). Dublin: School of Clinical Speech and Language Studies.
Derrick, D., O’Beirne, G.A., Rybel, T.D. and Hay, J., 2014. Aero-tactile integration in fricatives: Converting audio to air flow information for speech perception enhancement. In Fifteenth Annual Conference of the International Speech Communication Association (pp. 2580–2284). International Speech Communication Association, Baixas.
Desjardins, R.N., Rogers, J. and Werker, J.F., 1997. An exploration of why preschoolers perform differently than do adults in audiovisual speech perception tasks. Journal of Experimental Child Psychology, 66(1), pp. 85–110.
Desjardins, R.N. and Werker, J.F., 2004. Is the integration of heard and seen speech mandatory for infants? Developmental Psychobiology, 45(4), pp. 187–203.
Dinnsen, D.A., Gierut, J.A., Morrisette, M.L. and Rose, D.E., 2014. Unraveling phonological conspiracies: A case study. Clinical Linguistics & Phonetics, 28(7–8), pp. 463–476.
Doherty-Sneddon, G., Bonner, L. and Bruce, V., 2001. Cognitive demands of face monitoring: Evidence for visuospatial overload. Memory & Cognition, 29(7), pp. 909–919.
Doherty-Sneddon, G., McAuley, S., Bruce, V., Langton, S., Blokland, A. and Anderson, A.H., 2000. Visual signals and children’s communication: Negative effects on task outcome. British Journal of Developmental Psychology, 18(4), pp. 595–608.
Duchan, J.F., 2006. How conceptual frameworks influence clinical practice: Evidence from the writings of John Thelwall, a 19th-century speech therapist. International Journal of Language & Communication Disorders, 41(6), pp. 735–744.
Duckworth, M., Allen, G., Hardcastle, W. and Ball, M., 1990. Extensions to the International Phonetic Alphabet for the transcription of atypical speech. Clinical Linguistics & Phonetics, 4(4), pp. 273–280.
Dupont, S., Aubin, J. and Ménard, L., 2005. A Study of the McGurk Effect in 4 and 5-Year-Old French Canadian Children. Leibniz Center for General Linguistics (ZAS) Papers in Linguistics, 40, pp. 1–17.
Engwall, O., 2008. Can audio-visual instructions help learners improve their articulation?-An ultrasound study of short term changes. Interspeech, pp. 2631–2634.
Engwall, O. and Bälter, O., 2007. Pronunciation feedback from real and virtual language teachers. Computer Assisted Language Learning, 20(3), pp. 235–262.
Engwall, O. and Wik, P., 2009. Can you tell if tongue movements are real or synthesized? AVSP, pp. 96–101.
Engwall, O., Wik, P., Beskow, J., Granstrom, G., 2004. Design strategies for a virtual language tutor. Proceedings of International Conference on Spoken Language Processing, 3, pp. 1693–1696.
Eskelund, K., MacDonald, E.N. and Andersen, T.S., 2015. Face configuration affects speech perception: Evidence from a McGurk mismatch negativity study. Neuropsychologia, 66, pp. 48–54.
Esling, J.H., 2010. Phonetic notation. In The Handbook of Phonetic Sciences, Second Edition (pp. 678–702). Oxford: Wiley–Blackwell.
Fagel, S. and Madany, K., 2008. A 3-D virtual head as a tool for speech therapy for children. Proceedings of Interspeech 2008 (pp. 2643–2646). ISCA, Brisbane, Australia.
Fant, G., 1971. Acoustic Theory of Speech Production: With Calculations Based on X-Ray Studies of Russian Articulations (Vol. 2). Berlin: Walter de Gruyter.
Farah, M.J., Wilson, K.D., Drain, M. and Tanaka, J.N., 1998. What is “special” about face perception? Psychological Review, 105(3), p. 482.
Farrer, C., Franck, N., Georgieff, N., Frith, C.D., Decety, J. and Jeannerod, M., 2003. Modulating the experience of agency: A positron emission tomography study. Neuroimage, 18(2), pp. 324–333.
Farrer, C., Frey, S.H., Van Horn, J.D., Tunik, E., Turk, D., Inati, S. and Grafton, S.T., 2008. The angular gyrus computes action awareness representations. Cerebral Cortex, 18(2), pp. 254–261.
Fawcett, S., Bacsfalvi, P. and Bernhardt, B.M., 2008. Ultrasound as visual feedback in speech therapy for /r /with adults with Down Syndrome. Down Syndrome Quarterly, 10(1), pp. 4–12.
Fazel, V. and Katz, W., 2016. Visuomotor pursuit tracking accuracy for intraoral tongue movement. The Journal of the Acoustical Society of America, 140(4), pp. 3224–3224.
Felps, D., Bortfeld, H. and Gutierrez-Osuna, R., 2009. Foreign accent conversion in computer assisted pronunciation training. Speechan Communication, 51(10), pp. 920–932.
Fenson, L., Dale, P.S., Reznick, J.S., Bates, E., Thal, D.J., Pethick, S.J., Tomasello, M., Mervis, C.B. and Stiles, J., 1994. Variability in early communicative development. Monographs of the Society for Research in Child Development, pp. 1–185.
Fernald, A., 1989. Intonation and communicative intent in mothers’ speech to infants: Is the melody the message? Child Development, pp. 1497–1510.
Field, T., Diego, M. and Hernandez-Reif, M., 2009. Depressed mothers’ infants are less responsive to faces and voices. Infant Behavior and Development, 32(3), pp. 239–244.
Firth, J.E., 1948. Word-palatograms and articulation. Bulletin of the School of Oriental and African Studies, 12(3–4), pp. 857–864.
Fisher, C.G., 1968. Confusions among visually perceived consonants. Journal of Speech, Language, and Hearing Research, 11(4), pp. 796–804.
Fisher, C.G., 1969. The visibility of terminal pitch contour. Journal of Speech, Language, and Hearing Research, 12(2), pp. 379–382.
Fletcher, S. and Hasagawa, A., 1983. Speech modification by a deaf child through dynamic orometric modelling and feedback. Journal of Speech and Hearing Disorders, 48, pp. 178–185.
Fowler, C.A. and Dekle, D.J., 1991. Listening with eye and hand: Cross-modal contributions to speech perception. Journal of Experimental Psychology: Human Perception and Performance, 17(3), p. 816.
Fusaro, M., Harris, P.L. and Pan, B.A., 2012. Head nodding and head shaking gestures in children’s early communication. First Language, 32(4), pp. 439–458.
Gerard, J.M., Perrier, P. and Payan, Y., 2006. 3D Biomechanical Tongue Modeling to Study Speech Production. New York: Psychology Press.
Gibbon, F., Hardcastle, B. and Suzuki, H., 1991. An electropalatographic study of the /r/, /l/ distinction for Japanese learners of English. Computer Assisted Language Learning, 4(3), pp. 153–171.
Gibbon, F., Law, J. and Lee, A., 2007. Electropalatography for articulation disorders associated with cleft palate (protocol). In Cochrane Collaboration, The Cochrane Library I. Hoboken, NJ: Wiley.
Gibbon, F.E. and Lee, A., 2017. Electropalatographic (EPG) evidence of covert contrasts in disordered speech. Clinical Linguistics & Phonetics, 31(1), pp. 4–20.
Gibbon, F., Stewart, F., Hardcastle, W.J. and Crampin, L., 1999. Widening access to electropalatography for children with persistent sound system disorders. American Journal of Speech-Language Pathology, 8, pp. 319–334.
Gibbon, F.E. and Wood, S.E., 2003. Using electropalatography (EPG) to diagnose and treat articulation disorders associated with mild cerebral palsy: A case study. Clinical Linguistics & Phonetics, 17(4–5), pp. 365–374.
Gibbon, F. and Wood, S.E., 2010. Visual feedback therapy with electropalatography (EPG) for speech sound disorders in children. In L. Williams, S. McLeod and R. McCauley (Eds.) Interventions in Speech Sound Disorders (pp. 509–536). Baltimore: Brookes.
Gick, B., Bernhardt, B., Bacsfalvi, P., Wilson, I. and Zampini, M.L., 2008. Ultrasound imaging applications in second language acquisition. Phonology and Second Language Acquisition, 36, pp. 315–328.
Gick, B. and Derrick, D., 2009. Aero-tactile integration in speech perception. Nature, 462(7272), pp. 502–504.
Gick, B., Wilson, I. and Derrick, D., 2012. Articulatory Phonetics (p. 272). Hoboken, NJ: John Wiley & Sons.
Glenberg, A.M., Schroeder, J.L. and Robertson, D.A., 1998. Averting the gaze disengages the environment and facilitates remembering. Memory & Cognition, 26(4), pp. 651–658.
Goffman, L., Maassen, B. and Van Lieshout, P.H., 2010. Dynamic interaction of motor and language factors in normal and disordered development. Speech Motor Control: New Developments in Basic and Applied Research, pp. 137–152.
Goldberg, G., 1985. Supplementary motor area structure and function: Review and hypothesis. Behavioral and Brain Sciences, 8, pp. 567–615.
Gracco, V.L., 1994. Some organizational characteristics of speech movement control. Journal of Speech, Language, and Hearing Research, 37(1), pp. 4–27.
Graf, H.P., Cosatto, E., Strom, V. and Huang, F.J., 2002, May. Visual prosody: Facial movements accompanying speech. In Automatic Face and Gesture Recognition, 2002. Proceedings: Fifth IEEE International Conference (pp. 396–401).
Gray, H.M. and Tickle-Degnen, L., 2010. A meta-analysis of performance on emotion recognition tasks in Parkinson’s disease. Neuropsychology, 24(2), pp. 176–191.
Green, J.R. and Nip, I.S., 2010. Some organization principles in early speech development. In Speech Motor Control: New Developments in Basic and Applied Research, pp. 171–188.
Green, K.P., 1998. The use of auditory and visual information during phonetic processing: Implications for theories of speech perception. Hearing by Eye II: Advances in the Psychology of Speechreading and Auditory-Visual Speech, 2, p. 3.
Guenther, F.H., 2006. Cortical interactions underlying the production of speech sounds. Journal of Communication Disorders, 39(5), pp. 350–365.
Guenther, F.H., Ghosh, S.S. and Tourville, J.A., 2006. Neural modeling and imaging of the cortical interactions underlying syllable production. Brain and Language, 96(3), pp. 280–301.
Guenther, F.H. and Perkell, J.S., 2004. A neural model of speech production and supporting experiments. In From Sound to Sense Conference: Fifty+ Years of Discoveries in Speech Communication (pp. 98–106). Cambridge, MA.
Guenther, F.H. and Vladusich, T., 2012. A neural theory of speech acquisition and production. Journal of Neurolinguistics, 25(5), pp. 408–422.
Hacking, J.F., Smith, B.L. and Johnson, E.M., 2017. Utilizing electropalatography to train palatalized versus unpalatalized consonant productions by native speakers of American English learning Russian. Journal of Second Language Pronunciation, 3(1), pp. 9–33.
Hadar, U., Steiner, T.J., Grant, E.C. and Clifford Rose, F., 1983. Head movement correlates of juncture and stress at sentence level. Language and Speech, 26(2), pp. 117–129.
Hadfield, C. (2013). Astronaut Chris Hadfield savors fresh air of Earth. www.cbc.ca/news/technology/astronaut-chris-hadfield-savours-fresh-air-of-earth-1.1304791, Posted May 16th 2013.
Haith, M.M., Bergman, T. and Moore, M.J., 1977. Eye contact and face scanning in early infancy. Science, 198(4319), pp. 853–855.
Haldin, C., Acher, A., Kauffmann, L., Hueber, T., Cousin, E., Badin, P., Perrier, P., Fabre, D., Pérennou, D., Detante, O. and Jaillard, A., 2017. Speech recovery and language plasticity can be facilitated by sensori-motor fusion training in chronic non-fluent aphasia. A case report study. Clinical Linguistics & Phonetics, pp. 1–27.
Hartelius, L.L., Mcauliffe, M., Murdoch, B.E. and Theodoros, D.G., 2001, January. The use of electropalatography in the treatment of disordered articulation in traumatic brain injury: A case study. In 4th International Speech Motor Conference (pp. 192–195).Uitgeverij Vantilt, Nijmegen.
Hartelius, L.L. and Svensson, P., 1994. Speech and swallowing symptoms associated with Parkinson’s disease and multiple sclerosis: A survey. Folia Phoniatrica et Logopaedica, 46(1), pp. 9–17.
Hassanat, A., 2014. Visual speech recognition. Eprint Arxiv, 32(3), pp. 2420–2424.
Haworth, B., Kearney, E., Baljko, M., Faloutsos, P. and Yunusova, Y. 2014. Electromagnetic articulography in the development of ‘serious games’ for speech rehabilitation. Paper presented at the Second International Workshop on BioMechanical and Parametric Modelling of Human Anatomy, Vancouver, Canada.
Hermant, N., Perrier, P. and Payan, Y., 2017. Human tongue biomechanical modeling. Biomechanics of Living Organs, pp. 395–411.
Hertrich, I. and Ackermann, H., 1993. Acoustic analysis of speech prosody in Huntington’s and Parkinson’s disease: A preliminary report. Clinical Linguistics & Phonetics, 7(4), pp. 285–297.
Heselwood, B., 2013. Phonetic Transcription in Theory and Practice. Edinburgh: Edinburgh University Press.
Hessler, D., Jonkers, R. and Bastiaanse, R., 2012. Processing of audiovisual stimuli in aphasic and non-brain-damaged listeners. Aphasiology, 26(1), pp. 83–102.
Hewlett, N., 1988. Acoustic properties of /k/ and /t/ in normal and phonologically disordered speech. Clinical Linguistics & Phonetics, 2(1), pp. 29–45.
Hickey, J., 1992. The treatment of lateral fricatives and affricates using electropalatography: A case study of a 10 year old girl. Journal of Clinical Speech and Language Studies, 1, pp. 80–87.
Hickok, G., Rogalsky, C., Chen, R., Herskovits, E.H., Townsley, S. and Hillis, A.E., 2014. Partially overlapping sensorimotor networks underlie speech praxis and verbal short-term memory: Evidence from apraxia of speech following acute stroke. Frontiers in Human Neuroscience, 8, p. 649.
Hietanen, J.K., Manninen, P., Sams, M. and Surakka, V., 2001. Does audiovisual speech perception use information about facial configuration? European Journal of Cognitive Psychology, 13(3), pp. 395–407.
Higashikawa, M., Green, J.R., Moore, C.A. and Minifie, F.D., 2003. Lip kinematics for /p/ and /b/ production during whispered and voiced speech. Folia Phoniatrica et Logopaedica, 55(1), pp. 17–27.
Hiiemae, K.M. and Palmer, J.B., 2003. Tongue movements in feeding and speech. Critical Reviews in Oral Biology & Medicine, 14(6), pp. 413–429.
Hillairet de Boisferon, A., Tift, A.H., Minar, N.J. and Lewkowicz, D.J., 2017. Selective attention to a talker’s mouth in infancy: Role of audiovisual temporal synchrony and linguistic experience. Developmental Science, 20(3).
Hillock-Dunn, A. and Wallace, M.T., 2012. Developmental changes in the multisensory temporal binding window persist into adolescence. Developmental Science, 15(5), pp. 688–696.
Himmelmann, K. and Uvebrant, P., 2011. Function and neuroimaging in cerebral palsy: A population-based study. Developmental Medicine & Child Neurology, 53(6), pp. 516–521.
Hitchcock, E.R., Byun, T.M., Swartz, M. and Lazarus, R., 2017. Efficacy of Electropalatography for Treating Misarticulation of /r/. American Journal of Speech-Language Pathology, 26(4), pp. 1141–1158.
Hockley, N.S. and Polka, L., 1994. A developmental study of audiovisual speech perception using the McGurk paradigm. The Journal of the Acoustical Society of America, 96(5), pp. 3309–3309.
Holder, W., 1669. Elements of Speech: An Essay of Inquiry into the Natural Production of Letters: With an Appendix Concerning Persons Deaf & Dumb. London: John Martyn.
Howard, S.J. and Heselwood, B.C., 2002. Learning and teaching phonetic transcription for clinical purposes. Clinical Linguistics & Phonetics, 16(5), pp. 371–401.
Howard, S. and Varley, R., 1995. III: EPG in therapy using electropalatography to treat severe acquired apraxia of speech. European Journal of Disorders of Communication, 30(2), pp. 246–255.
Huang, X., Baker, J. and Reddy, R., 2014. A historical perspective of speech recognition. Communications of the ACM, 57(1), pp. 94–103.
Hueber, T., Ben-Youssef, A., Badin, P., Bailly, G. and Eliséi, F., 2012. Vizart3D: Retour Articulatoire Visuel pour l’Aide à la Prononciation (Vizart3D: Visual Articulatory Feedack for Computer-Assisted Pronunciation Training) [in French]. In Proceedings of the Joint Conference JEP-TALN-RECITAL 2012, Volume 5: Software Demonstrations (pp. 17–18). Grenoble, France.
Irwin, J. and DiBlasi, L., 2017. Audiovisual speech perception: A new approach and implications for clinical populations. Language and Linguistics Compass, 11(3), pp. 77–91.
Irwin, J., Preston, J., Brancazio, L., D’angelo, M. and Turcios, J., 2014. Development of an audiovisual speech perception app for children with autism spectrum disorders. Clinical Linguistics & Phonetics, 29(1), pp. 76–83.
Ito, T., Tiede, M. and Ostry, D.J., 2009. Somatosensory function in speech perception. Proceedings of the National Academy of Sciences, 106(4), pp. 1245–1248.
Jakobson, R., 1968. Child Language, Aphasia and Phonological Universals (Vol. 72). The Hague: de Gruyter Mouton.
Jakobson, R. and Halle, M., 1956. Fundamentals of Language. The Hague: Mouton & Co.
Jerger, S., Damian, M.F., Spence, M.J., Tye-Murray, N. and Abdi, H., 2009. Developmental shifts in children’s sensitivity to visual speech: A new multimodal picture – word task. Journal of Experimental Child Psychology, 102(1), pp. 40–59.
Jerger, S., Damian, M.F., Tye-Murray, N. and Abdi, H., 2014. Children use visual speech to compensate for non-intact auditory speech. Journal of Experimental Child Psychology, 126, pp. 295–312.
Jespersen, O., 1910. What is the use of phonetics? Educational Review.
Jesse, A. and Massaro, D.W., 2010. The temporal distribution of information in audiovisual spoken-word identification. Attention, Perception, & Psychophysics, 72(1), pp. 209–225.
Jiang, J., Auer, E.T., Alwan, A., Keating, P.A. and Bernstein, L.E., 2007. Similarity structure in visual speech perception and optical phonetic signals. Perception & Psychophysics, 69(7), pp. 1070–1083.
Johnston, M., 2017. Extensible multimodal annotation for intelligent interactive systems. In Multimodal Interaction with W3C Standards (pp. 37–64). Cham: Springer.
Jones, D., 1922. An Outline of English Phonetics. Berlin: BG Teubner.
Jones, D., 1928. Das System der Association Phonétique Internationale (Weltlautschriftverein). In Heepe, Martin (Ed.) Lautzeichen und ihre Anwendung in verschiedenen Sprachgebieten (pp. 18–27). Berlin: Reichsdruckerei. Reprinted in Le Maître Phonétique 23, July–September 1928. Reprinted in Collins, Beverly and Inger M. Mees, eds., 2003. Daniel Jones: Selected Works, Volume VII: Selected Papers. London: Routledge.
Jordan, T.R. and Thomas, S.M., 2011. When half a face is as good as a whole: Effects of simple substantial occlusion on visual and audiovisual speech perception. Attention, Perception, & Psychophysics, 73(7), p. 2270.
Jousmäki, V. and Hari, R., 1998. Parchment-skin illusion: Sound-biased touch. Current Biology, 8(6), pp. R190–R191.
Kaganovich, N., Schumaker, J., Macias, D. and Gustafson, D., 2015. Processing of audiovisually congruent and incongruent speech in school-age children with a history of specific language impairment: A behavioral and event-related potentials study. Developmental Science, 18(5), pp. 751–770.
Katsikitis, M. and Pilowsky, I., 1991. A controlled quantitative study of facial expression in Parkinson’s disease and depression. Journal of Nervous and Mental Disease, 79(11), pp. 683–688.
Katsikitis, M. and Pilowsky, I., 1988. A study of facial expression in Parkinson’s disease using a novel microcomputer-based method. Journal of Neurology, Neurosurgery & Psychiatry, 51(3), pp. 362–366.
Katz, W.F. and Bharadwaj, S., 2001. Coarticulation in fricative-vowel syllables produced by children and adults: A preliminary report. Clinical Linguistics & Phonetics, 15(1–2), pp. 139–143.
Katz, W.F., Bharadwaj, S.V. and Carstens, B., 1999. Electromagnetic articulography treatment for an adult with Broca’s aphasia and apraxia of speech. Journal of Speech, Language, and Hearing Research, 42(6), pp. 1355–1366.
Katz, W.F., Bharadwaj, S.V., Gabbert, G. and Stetler, M., 2002, October. Visual augmented knowledge of performance: Treating place-of-articulation errors in apraxia of speech using EMA. Brain and Language, 83(1), pp. 187–189.
Katz, W., Campbell, T.F., Wang, J., Farrar, E., Eubanks, J.C., Balasubramanian, A., Prabhakaran, B. and Rennaker, R., 2014. Opti-speech: A real-time, 3D visual feedback system for speech training. Proceedings of Interspeech (pp. 1174–1178).
Katz, W.F., Garst, D.M., Carter, G.S., McNeil, M.R., Fossett, T.R., Doyle, P.J. and Szuminsky, N.J., 2007. Treatment of an individual with aphasia and apraxia of speech using EMA visually-augmented feedback. Brain and Language, 103(1–2), pp. 213–214.
Katz, W.F. and McNeil, M.R., 2010. Studies of articulatory feedback treatment for apraxia of speech based on electromagnetic articulography. Perspectives on Neurophysiology and Neurogenic Speech and Language Disorders, 20(3), pp. 73–80.
Katz, W.F., McNeil, M.R. and Garst, D.M., 2010. Treating apraxia of speech (AOS) with EMA-supplied visual augmented feedback. Aphasiology, 24(6–8), pp. 826–837.
Katz, W.F. and Mehta, S., 2015. Visual feedback of tongue movement for novel speech sound learning. Frontiers in Human Neuroscience, 9, p. 612.
King, S.A. and Parent, R.E., 2001. A 3d parametric tongue model for animated speech. Computer Animation and Virtual Worlds, 12(3), pp. 107–115.
King, S.A. and Parent, R.E., 2005. Creating speech-synchronized animation. IEEE Transactions on Visualization and Computer Graphics, 11(3), pp. 341–352.
Kiritani, S., Itoh, K. and Fujimura, O., 1975. Tongue-pellet tracking by a computer-controlled x-ray microbeam system. The Journal of the Acoustical Society of America, 57(6), pp. 1516–1520.
Kitamura, C., Guellaï, B. and Kim, J., 2014. Motherese by eye and ear: Infants perceive visual prosody in point-line displays of talking heads. PLoS One, 9(10), p. e111467.
Klopfenstein, M., 2009. Interaction between prosody and intelligibility. International Journal of Speech-Language Pathology, 11(4), pp. 326–331.
Kong, A.P.H., Law, S.P., Kwan, C.C.Y., Lai, C. and Lam, V., 2015. A coding system with independent annotations of gesture forms and functions during verbal communication: Development of a database of speech and gesture (DoSaGE). Journal of Nonverbal Behavior, 39(1), pp. 93–111.
Kröger, B.J., Birkholz, P., Hoffmann, R. and Meng, H., 2010. Audiovisual tools for phonetic and articulatory visualization in computer-aided pronunciation training. In Development of Multimodal Interfaces: Active Listening and Synchrony (pp. 337–345). Berlin, Heidelberg: Springer.
Kröger, B.J., Kannampuzha, J. and Neuschaefer-Rube, C., 2009. Towards a neurocomputational model of speech production and perception. Speech Communication, 51(9), pp. 793–809.
Kröger, B.J., Miller, N., Lowit, A. and Neuschaefer-Rube, C., 2011. Defective neural motor speech mappings as a source for apraxia of speech: Evidence from a quantitative neural model of speech processing. In A. Lowit and R. Kent (Eds.) Assessment of Motor Speech Disorders (pp. 325–346). San Diego, CA: Plural Publishing.
Kronenbuerger, M., Konczak, J., Ziegler, W., Buderath, P., Frank, B., Coenen, V.A., Kiening, K., Reinacher, P., Noth, J. and Timmann, D., 2009. Balance and motor speech impairment in essential tremor. The Cerebellum, 8(3), pp. 389–398.
Kuhl, P.K. and Meltzoff, A.N., 1984. The intermodal representation of speech in infants. Infant Behavior and Development, 7(3), pp. 361–381.
Ladefoged, P., 1957. Use of palatography. Journal of Speech and Hearing Disorders, 22(5), pp. 764–774.
Ladefoged, P., 2005. Speculations on the control of speech. In W.J. Hardcastle and J.M. Beck (Eds.) A Figure of Speech: A Festschrift for John Laver (pp. 3–21). Macwah, NJ: Lawrence Erlbaum.
Leclère, C., Viaux, S., Avril, M., Achard, C., Chetouani, M., Missonnier, S. and Cohen, D., 2014. Why synchrony matters during mother-child interactions: A systematic review. PLoS One, 9(12), p. e113571.
Legerstee, M., 1990. Infants use multimodal information to imitate speech sounds. Infant Behavior and Development, 13(3), pp. 343–354.
Lesser, R., 1989. Linguistic Investigations of Aphasia. London: Whurr Publishers.
Levitt, J.S. and Katz, W.F., 2008. Augmented visual feedback in second language learning: Training Japanese post-alveolar flaps to American English speakers. Proceedings of Meetings on Acoustics 154ASA, 2(1), p. 060002. ASA.
Lewald, J., Dörrscheidt, G.J. and Ehrenstein, W.H., 2000. Sound localization with eccentric head position. Behavioural Brain Research, 108(2), pp. 105–125.
Lewald, J. and Ehrenstein, W.H., 1998. Influence of head-to-trunk position on sound lateralization. Experimental Brain Research, 121(3), pp. 230–238.
Lewkowicz, D.J. and Flom, R., 2014. The audiovisual temporal binding window narrows in early childhood. Child Development, 85(2), pp. 685–694.
Lewkowicz, D.J. and Hansen-Tift, A.M., 2012. Infants deploy selective attention to the mouth of a talking face when learning speech. Proceedings of the National Academy of Sciences, 109(5), pp. 1431–1436.
Linker, W.J., 1982. Articulatory and Acoustic Correlates of Labial Activity: A Cross-Linguistic Study. Ph.D. dissertation, UCLA.
Liu, X., Hairston, J., Schrier, M. and Fan, J., 2011. Common and distinct networks underlying reward valence and processing stages: A meta-analysis of functional neuroimaging studies. Neuroscience and Biobehavioral Review, 35, 1219–1236.
Liu, Y., Massaro, D.W., Chen, T.H., Chan, D. and Perfetti, C., 2007. Using visual speech for training Chinese pronunciation: An in-vivo experiment. In Proceedings of the International Speech Communication (ISCA) (pp. 29–32). ITRW SLaTE, Farmington, PA.
Livingstone, S.R. and Palmer, C., 2016. Head movements encode emotions during speech and song. Emotion, 16(3), p. 365.
Lofqvist, A. and Gracco, V.L., 1997. Lip and jaw kinematics in bilabial stop consonant production. Journal of Speech, Language, and Hearing Research, 40(4), pp. 877–893.
Logemann, J.A., Fisher, H.B., Boshes, B. and Blonsky, E.R., 1978. Frequency and cooccurrence of vocal tract dysfunctions in the speech of a large sample of Parkinson patients. Journal of Speech and Hearing Disorders, 43(1), pp. 47–57.
Lohmander, A., Henriksson, C. and Havstam, C., 2010. Electropalatography in home training of retracted articulation in a Swedish child with cleft palate: Effect on articulation pattern and speech. International Journal of Speech-Language Pathology, 12(6), pp. 483–496.
Lundeborg, I. and McAllister, A., 2007. Treatment with a combination of intra-oral sensory stimulation and electropalatography in a child with severe developmental dyspraxia. Logopedics Phoniatrics Vocology, 32(2), pp. 71–79.
Lundy, B., Field, T. and Pickens, J., 1996. Newborns of mothers with depressive symptoms are less expressive. Infant Behavior and Development, 19(4), pp. 419–424.
Ma, J.K.Y., Schneider, C.B., Hoffmann, R. and Storch, A., 2015. Speech prosody across stimulus types for individuals with Parkinson’s Disease. Journal of Parkinson’s Disease, 5(2), pp. 291–299.
Maas, E., Mailend, M.L. and Guenther, F.H., 2015. Feedforward and feedback control in apraxia of speech: Effects of noise masking on vowel production. Journal of Speech, Language, and Hearing Research, 58(2), pp. 185–200.
Maine, S. and Serry, T., 2011. Treatment of articulation disorders in children with cleft palate. Journal of Clinical Practice in Speech-Language Pathology, 13(1), p. 136.Mallick, D.B., Magnotti, J.F. and Beauchamp, M.S., 2015. Variability and stability in the McGurk effect: Contributions of participants, stimuli, time, and response type. Psychonomic Bulletin & Review, 22(5), pp. 1299–1307.
Martin, K.L., Hirson, A., Herman, R., Thomas, J. and Pring, T., 2007. The efficacy of speech intervention using electropalatography with an 18-year-old deaf client: A single case study. Advances in Speech Language Pathology, 9(1), pp. 46–56.
Massaro, D.W., 1984. Children’s perception of visual and auditory speech. Child Development, pp. 1777–1788.
Massaro, D.W., 2003, November. A computer-animated tutor for spoken and written language learning. In Proceedings of the 5th International Conference on Multimodal Interfaces (pp. 172–175). ACM, New York.
Massaro, D.W., Bigler, S., Chen, T., Perlman, M. and Ouni, S., 2008. Pronunciation training: The role of eye and ear. In Interspeech 2008 (pp. 2623–2626). Brisbane, Australia.
Massaro, D.W. and Cohen, M.M., 1998. Visible speech and its potential value for speech training for hearing-impaired perceivers. In Proceedings of the Speech Technology in Language Learning (STiLL’98) (pp. 171–174). Marholmen, Sweden.
Massaro, D.W. and Light, J., 2003. Read my tongue movements: Bimodal learning to perceive and produce non-native speech /r/ and /l. In Eurospeech 2003 (pp. 2249–2252). Geneva, Switzerland.
Massaro, D.W., Liu, Y., Chen, T.H. and Perfetti, C., 2006. A multilingual embodied conversational agent for tutoring speech and language learning. In Proceedings of the 9th International Conference on Spoken Language Processing (Interspeech 2006 – ICSLP) (pp. 825–828). Pittsburgh, PA.
Massaro, D.W., Thompson, L.A., Barron, B. and Laren, E., 1986. Developmental changes in visual and auditory contributions to speech perception. Journal of Experimental Child Psychology, 41(1), pp. 93–113.
Mattheyses, W. and Verhelst, W., 2015. Audiovisual speech synthesis: An overview of the state-of-the-art. Speech Communication, 66, pp. 182–217.
Mauszycki, S.C., Wright, S., Dingus, N. and Wambaugh, J.L., 2016. The use of electropalatography in the treatment of acquired apraxia of speech. American Journal of Speech-Language Pathology, 25(4S), pp. S697–S715.
Max, L., Guenther, F.H., Gracco, V.L., Ghosh, S.S. and Wallace, M.E., 2004. Unstable or insufficiently activated internal models and feedback-biased motor control as sources of dysfluency: A theoretical model of stuttering. Contemporary Issues in Communication Science and Disorders, 31(31), pp. 105–122.
McAuliffe, M.J. and Ward, E.C., 2006. The use of electropalatography in the assessment and treatment of acquired motor speech disorders in adults: Current knowledge and future directions. NeuroRehabilitation, 21(3), pp. 189–203.
McClave, E.Z., 2000. Linguistic functions of head movements in the context of speech. Journal of Pragmatics, 32(7), pp. 855–878.
McGurk, H. and MacDonald, J., 1976. Hearing lips and seeing voices. Nature, 264(5588), p. 746.
McNeil, M.R., Fossett, T.R., Katz, W.F., Garst, D., Carter, G., Szuminsky, N. and Doyle, P.J., 2007. Effects of on-line kinematic feedback treatment for apraxia of speech. Brain and Language, 1(103), pp. 223–225.
McNeil, M.R., Katz, W.F., Fossett, T.R.D., Garst, D.M., Szuminsky, N.J., Carter, G. and Lim, K.Y., 2010. Effects of online augmented kinematic and perceptual feedback on treatment of speech movements in apraxia of speech. Folia Phoniatrica et Logopaedica, 62(3), pp. 127–133.
McNeill, D., 1985. So you think gestures are nonverbal?. Psychological Review, 92(3), p. 350.
Moll, K.L., 1960. Cinefluorographic techniques in speech research. Journal of Speech, Language, and Hearing Research, 3(3), pp. 227–241.
Mongillo, E.A., Irwin, J.R., Whalen, D.H., Klaiman, C., Carter, A.S. and Schultz, R.T., 2008. Audiovisual processing in children with and without autism spectrum disorders. Journal of Autism and Developmental Disorders, 38(7), pp. 1349–1358.
Moreno-Torres, I., Berthier, M.L., del Mar Cid, M., Green, C., Gutiérrez, A., García-Casares, N., Walsh, S.F., Nabrozidis, A., Sidorova, J., Dávila, G. and Carnero-Pardo, C., 2013. Foreign accent syndrome: A multimodal evaluation in the search of neuroscience-driven treatments. Neuropsychologia, 51(3), pp. 520–537.
Morgan, A.T., Liegeois, F. and Occomore, L., 2007. Electropalatography treatment for articulation impairment in children with dysarthria post-traumatic brain injury. Brain Injury, 21(11), pp. 1183–1193.
Morgan Barry, R.A., 1995. EPG treatment of a child with the Worster-Drought syndrome. International Journal of Language & Communication Disorders, 30(2), pp. 256–263.
Morgan Barry, R.A. and Hardcastle, W.J., 1987. Some observations on the use of electropalatography as a clinical tool in the diagnosis and treatment of articulation disorders in children. In Proceedings of the First International Symposium on Specific Speech and Language Disorders in Children (pp. 208–222). AFASIC, Reading.
Mroueh, Y., Marcheret, E. and Goel, V., 2015, April. Deep multimodal learning for audio-visual speech recognition. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2130–2134). IEEE, Brisbane, Australia.
Müller, E. and MacLeod, G., 1982. Perioral biomechanics and its relation to labial motor control. The Journal of the Acoustical Society of America, 71(S1), pp. S33–S33.
Müller, N. and Ball, M.J., 2013. 1 Linguistics, phonetics, and speech-language Pathology: Clinical linguistics and phonetics. In Research Methods in Clinical Linguistics and Phonetics: A Practical Guide. Oxford: Wiley-Blackwell.
Munhall, K.G., Gribble, P., Sacco, L. and Ward, M., 1996. Temporal constraints on the McGurk effect. Perception & Psychophysics, 58(3), pp. 351–362.
Munhall, K.G., Jones, J.A., Callan, D.E., Kuratate, T. and Vatikiotis-Bateson, E., 2004. Visual prosody and speech intelligibility: Head movement improves auditory speech perception. Psychological Science, 15(2), pp. 133–137.
Munhall, K.G., Vatikiotis-Bateson, E. and Tohkura, Y.I., 1995. X-ray film database for speech research. The Journal of the Acoustical Society of America, 98(2), pp. 1222–1224.
Murray, E.S.H., Mendoza, J.O., Gill, S.V., Perkell, J.S. and Stepp, C.E., 2016. Effects of biofeedback on control and generalization of nasalization in typical speakers. Journal of Speech, Language, and Hearing Research, 59(5), pp. 1025–1034.
Murray, L. and Cooper, P., 2003. Unipolar Depression: A Lifespan Perspective. New York: Oxford Univesity Press.
Murray, L., Fearon, P. and Cooper, P., 2015. Postnatal depression, mother – infant interactions, and child development. In Identifying Perinatal Depression and Anxiety: Evidence-Based Practice in Screening, Psychosocial Assessment, and Management (pp. 139–164). Chichester: John Wiley & Sons Ltd.
Musti, U., Ouni, S., Zhou, Z. and Pietikäinen, M., 2014, December. 3D Visual speech animation from image sequences. In Proceedings of the 2014 Indian Conference on Computer Vision Graphics and Image Processing (p. 47).
Nasir, S.M. and Ostry, D.J., 2006. Somatosensory precision in speech production. Current Biology, 16(19), pp. 1918–1923.
Nelson, M.A. and Hodge, M.M., 2000. Effects of facial paralysis and audiovisual information on stop place identification. Journal of Speech, Language, and Hearing Research, 43(1), pp. 158–171.
Nicholson, K.G., Baum, S., Cuddy, L.L. and Munhall, K.G., 2002. A case of impaired auditory and visual speech prosody perception after right hemisphere damage. Neurocase, 8(4), pp. 314–322.
Ninaus, M., Kober, S.E., Witte, M., Koschutnig, K., Stangl, M., Neuper, C. and Wood, G., 2013. Neural substrates of cognitive control under the belief of getting neurofeedback training. Frontiers in Human Neuroscience, 7, p. 914.
Nordberg, A., Carlsson, G. and Lohmander, A., 2011. Electropalatography in the description and treatment of speech disorders in five children with cerebral palsy. Clinical Linguistics & Phonetics, 25(10), pp. 831–852.
Nordberg, A., Miniscalco, C., Lohmander, A. and Himmelmann, K., 2013. Speech problems affect more than one in two children with cerebral palsy: Swedish population-based study. Acta Paediatrica, 102(2), pp. 161–166.
Norrix, L.W., Plante, E. and Vance, R., 2006. Auditory – visual speech integration by adults with and without language-learning disabilities. Journal of Communication Disorders, 39(1), pp. 22–36.
Norrix, L.W., Plante, E., Vance, R. and Boliek, C.A., 2007. Auditory-visual integration for speech by children with and without specific language impairment. Journal of Speech, Language, and Hearing Research, 50(6), pp. 1639–1651.
Norton, S.J., 1977. Analytic study of the Tadoma method: Background and preliminary results. Journal of Speech & Hearing Research, 20, pp. 625–637.
Ohala, J.J., 1975. The temporal regulation of speech. Auditory Analysis and Perception of Speech, pp. 431–453.
Ohala, J.J., 2004. Phonetics and phonology: Then, and then, and now. LOT Occasional Series, 2, pp. 133–140.
Ostry, D.J. and Flanagan, J.R., 1989. Human jaw movement in mastication and speech. Archives of Oral Biology, 34(9), pp. 685–693.
Passy, P., 1884. Premier livre de lecture. Paris: Firmin-Didot.
Paulmann, S. and Pell, M.D., 2010. Dynamic emotion processing in Parkinson’s disease as a function of channel availability. Journal of Clinical and Experimental Neuropsychology, 32(8), pp. 822–835.
Pell, M.D., Cheang, H.S. and Leonard, C.L., 2006. The impact of Parkinson’s disease on vocal-prosodic communication from the perspective of listeners. Brain and Language, 97(2), pp. 123–134.
Pell, M.D. and Monetta, L., 2008. How Parkinson’s disease affects non-verbal communication and language processing. Language and Linguistics Compass, 2(5), pp. 739–759.
Perkell, J.S., 1974. A physiologically-oriented model of tongue activity in speech production (Doctoral dissertation. Massachusetts Institute of Technology).
Perkins, M.R., 2011. Clinical linguistics: Its past, present and future. Clinical Linguistics & Phonetics, 25(11–12), pp. 922–927.
Perkins, M.R., Howard, S. and Simpson, J., 2011. Clinical linguistics. The Routledge Handbook of Applied Linguistics, pp. 112–124.
Phonetic Representation of Disordered Speech Working Party, 1983. The Phonetic Representation of Disordered Speech: Final Report of the PRDS Project Working Party. London: King’s Fund.
Pillot-Loiseau, C., Antolík, T.K. and Kamiyama, T., 2013, August. Contribution of ultrasound visualisation to improving the production of the French /y/-/u/ contrast by four Japanese learners. In Proceedings of the PPLC13: Phonetics, Phonology, Languages in Contact Contact: Varieties, Multilingualism, Second Language Learning (pp. 86–89).
Plummer-D’Amato, P., Altmann, L.J. and Reilly, K., 2011. Dual-task effects of spontaneous speech and executive function on gait in aging: Exaggerated effects in slow walkers. Gait & Posture, 33(2), pp. 233–237.
Pochon, J.B., Levy, R., Fossati, P., Lehericy, S., Poline, J.B., Pillon, B., Le Bihan, D. and Dubois, B., 2002. The neural system that bridges reward and cognition in humans: An fMRI study. Proceedings of the National Academy of Sciences, 99(8), pp. 5669–5674.
Potamianos, G., Neti, C., Gravier, G., Garg, A. and Senior, A.W., 2003. Recent advances in the automatic recognition of audiovisual speech. Proceedings of the IEEE, 91(9), pp. 1306–1326.
Potamianos, G., Neti, C., Luettin, J. and Matthews, I., 2004. Audio-visual automatic speech recognition: An overview. Issues in Visual and Audio-Visual Speech Processing, 22, p. 23.
Potamianos, G., Marcheret, E., Mroueh, Y., Goel, V., Koumbaroulis, A., Vartholomaios, A. and Thermos, S., 2017, April. Audio and visual modality combination in speech processing applications. In The Handbook of Multimodal-Multisensor Interfaces (pp. 489–543). Association for Computing Machinery and Morgan & Claypool.
Powell, T.W.P. and Ball, M.J.B. eds., 2010. Clinical Linguistics: Critical Concepts in Linguistics: Applications of Clinical Linguistics and Phonetics. London: Routledge.
Pratt, S.R., 2007. Using electropalatographic feedback to treat the speech of a child with severe-to-profound hearing loss. The Journal of Speech and Language Pathology – Applied Behavior Analysis, 2(2), p. 213.
Preston, J.L., Byun, T.M., Boyce, S.E., Hamilton, S., Tiede, M., Phillips, E., Rivera-Campos, A. and Whalen, D.H., 2017a. Ultrasound Images of the Tongue: A Tutorial for Assessment and Remediation of Speech Sound Errors. Journal of Visualized Experiments: JoVE, 119.
Preston, J.L. and Leaman, M., 2014. Ultrasound visual feedback for acquired apraxia of speech: A case report. Aphasiology, 28(3), pp. 278–295.
Preston, J.L., Leece, M.C. and Maas, E., 2017b. Motor-based treatment with and without ultrasound feedback for residual speech-sound errors. International Journal of Language & Communication Disorders, 52(1), pp. 80–94.
Preston, J.L., Leece, M.C., McNamara, K. and Maas, E., 2017c. Variable practice to enhance speech learning in ultrasound biofeedback treatment for childhood apraxia of speech: A single case experimental study. American Journal of Speech-Language Pathology, 26(3), pp. 840–852.
Preston, J.L., Maas, E., Whittle, J., Leece, M.C. and McCabe, P., 2016. Limited acquisition and generalisation of rhotics with ultrasound visual feedback in childhood apraxia. Clinical Linguistics & Phonetics, 30(3–5), pp. 363–381.
Prince, A., and Smolensky, P. 1993/2004. Optimality Theory: Constraint interaction in generative grammar. Malden, MA:Blackwell..
Quinto, L., Thompson, W.F., Russo, F.A. and Trehub, S.E., 2010. A comparison of the McGurk effect for spoken and sung syllables. Attention, Perception, & Psychophysics, 72(6), pp. 1450–1454.
Ramsay, J.O., Munhall, K.G., Gracco, V.L. and Ostry, D.J., 1996. Functional data analyses of lip motion. The Journal of the Acoustical Society of America, 99(6), pp. 3718–3727.
Raphael, L.J., Borden, G.J. and Harris, K.S., 2007. Speech Science Primer: Physiology, Acoustics, and Perception of Speech. Philadelphia, PA: Lippincott Williams & Wilkins.
Rathinavelu, A., Thiagarajan, H. and Savithri, S.R., 2006. Evaluation of a computer aided 3D lip sync instructional model using virtual reality objects. In International Conference on Disability, Virtual Reality & Associated Technologies (pp. 67–73). Esbjerg, Denmark.
Remez, R., 2012. Three puzzles of multimodal speech perception. In G. Bailly, P. Perrier and E. Vatikiotis-Bateson (Eds.) Audiovisual Speech Processing (pp. 4–20). Cambridge: Cambridge University Press.
Ricciardi, L., Bologna, M., Morgante, F., Ricciardi, D., Morabito, B., Volpe, D., Martino, D., Tessitore, A., Pomponi, M., Bentivoglio, A.R. and Bernabei, R., 2015. Reduced facial expressiveness in Parkinson’s disease: A pure motor disorder? Journal of the Neurological Sciences, 358(1), pp. 125–130.
Risberg, A. and Lubker, J., 1978. Prosody and speechreading. Speech Transmission Laboratory Quarterly Progress Report and Status Report, 4, pp. 1–16.
Rockey, D., 1977. The logopaedic thought of John Thelwall, 1764–1834: First British speech therapist. International Journal of Language & Communication Disorders, 12(2), pp. 83–95.
Roon, K.D., Dawson, K.M., Tiede, M.K. and Whalen, D.H., 2016. Indexing head movement during speech production using optical markers. The Journal of the Acoustical Society of America, 139(5), pp. EL167–EL171.
Rosenbaum, P.L., Paneth, N., Leviton, A., Goldstein, M., Bax, M., Damiano, D., Dan, B. and Jacobsson, B., 2007. A report: The definition and classification of cerebral palsy April 2006. Developmental Medicine & Child Neurology, 109 (Suppl 109), pp. 8–14.
Rosenblum, L.D., 2001. Reading upside-down lips. www.faculty.ucr.edu/~rosenblu/VSinvertedspeech.html
Rosenblum, L.D., Schmuckler, M.A. and Johnson, J.A., 1997. The McGurk effect in infants. Perception & Psychophysics, 59(3), pp. 347–357.
Rosenblum, L.D., Yakel, D.A. and Green, K.P., 2000. Face and mouth inversion effects on visual and audiovisual speech perception. Journal of Experimental Psychology: Human Perception and Performance, 26(2), p. 806.
Rousselot, J-P., 1897. Principes de Phonétique Expérimentale (Vols. 1 and 2). Paris, Didier.
Roxburgh, Z., Cleland, J. and Scobbie, J.M., 2016. Multiple phonetically trained-listener comparisons of speech before and after articulatory intervention in two children with repaired submucous cleft palate. Clinical Linguistics & Phonetics, 30(3–5), pp. 398–415.
Rutter, B., Klopfenstein, M., Ball, M.J. and Müller, N., 2010. My client is using non-English sounds! A tutorial in advanced phonetic transcription. Part II: Prosody and unattested sounds. Contemporary Issues in Communication Science and Disorders, 37, pp. 111–122.
Rutter, M., 1997. Maternal depression and infant development: Cause and consequence; sensitivity and specificity. Postpartum Depression and Child Development, pp. 295–315.
Saavedra, S., Woollacott, M. and Van Donkelaar, P., 2010. Head stability during quiet sitting in children with cerebral palsy: Effect of vision and trunk support. Experimental Brain Research, 201(1), pp. 13–23.
Sánchez-García, C., Kandel, S., Savariaux, C. and Soto-Faraco, S., 2018. The time course of audio-visual phoneme identification: A high temporal resolution study. Multisensory Research, 31(1–2), pp. 57–78.
Sato, M., Buccino, G., Gentilucci, M. and Cattaneo, L., 2010. On the tip of the tongue: Modulation of the primary motor cortex during audiovisual speech perception. Speech Communication, 52(6), pp. 533–541.
Scarborough, R., Keating, P., Mattys, S.L., Cho, T. and Alwan, A., 2009. Optical phonetics and visual perception of lexical and phrasal stress in English. Language and Speech, 52(2–3), pp. 135–175.
Schmidt, A.M. and Beamer, J., 1998. Electropalatography treatment for training Thai speakers of English. Clinical Linguistics & Phonetics, 12(5), pp. 389–403.
Schölderle, T., Staiger, A., Lampe, R., Strecker, K. and Ziegler, W., 2014. Dysarthria in Adults with Cerebral Palsy: Clinical Presentation, Communication, and Classification. Neuropediatrics, 45(S 01), p. fp012.
Scobbie, J.M., Wood, S.E. and Wrench, A.A., 2004. Advances in EPG for treatment and research: An illustrative case study. Clinical Linguistics & Phonetics, 18(6–8), pp. 373–389.
Scott, A.D., Wylezinska, M., Birch, M.J. and Miquel, M.E., 2014. Speech MRI: Morphology and function. Physica Medica: European Journal of Medical Physics, 30(6), pp. 604–618.
Sekiyama, K. and Burnham, D., 2004. Issues in the development of auditory-visual speech perception: Adults, infants, and children. In S.H. Kim and D.H. Yuon (Eds.) Proceedings of the Eighth International Conference on Spoken Language Processing (pp. 1137–1140). Sunjin Printing, Seoul, Korea.
Sekiyama, K., Soshi, T. and Sakamoto, S., 2014. Enhanced audiovisual integration with aging in speech perception: A heightened McGurk effect in older adults. Frontiers in Psychology, 5, p. 323.
Sekiyama, K. and Tohkura, Y.I., 1991. McGurk effect in non-English listeners: Few visual effects for Japanese subjects hearing Japanese syllables of high auditory intelligibility. The Journal of the Acoustical Society of America, 90(4), pp. 1797–1805.
Shawker, T.H. and Sonies, B.C., 1985. Ultrasound biofeedback for speech training. Instrumentation and preliminary results. Investigative Radiology, 20(1), pp. 90–93.
Shirahige, C., Oki, K., Morimoto, Y., Oisaka, N. and Minagi, S., 2012. Dynamics of posterior tongue during pronunciation and voluntary tongue lift movement in young adults. Journal of Oral Rehabilitation, 39(5), pp. 370–376.
Shriberg, L.D. and Kent, R.D., 1982. Clinical Phonetics. New York: John Wiley and Sons.
Shriberg, L.D., Kwiatkowski, J. and Hoffmann, K., 1984. A procedure for phonetic transcription by consensus. Journal of Speech, Language, and Hearing Research, 27(3), pp. 456–465.
Shriberg, L.D. and Lof, G.L., 1991. Reliability studies in broad and narrow phonetic transcription. Clinical Linguistics & Phonetics, 5(3), pp. 225–279.
Shtern, M., Haworth, M.B., Yunusova, Y., Baljko, M. and Faloutsos, P., 2012, November. A game system for speech rehabilitation. In International Conference on Motion in Games (pp. 43–54). Springer, Berlin, Heidelberg.
Simons, G., Ellgring, H. and Smith Pasqualini, M., 2003. Disturbance of spontaneous and posed facial expressions in Parkinson’s disease. Cognition & Emotion, 17(5), pp. 759–778.
Singh, N., Agrawal, A. and Khan, R.A., 2017. Automatic speaker recognition: Current approaches and progress in last six decades. Global Journal of Enterprise Information System, 9(3), pp. 45–52.
Sisinni, B., d’Apolito, S., Fivela, B.G. and Grimaldi, M., 2016. Ultrasound articulatory training for teaching pronunciation of L2 vowels. In Conference Proceedings. ICT for Language Learning (p. 265). libreriauniversitaria. it Edizioni, Limena, Italy.
Sloutsky, V.M. and Napolitano, A.C., 2003. Is a picture worth a thousand words? Preference for auditory modality in young children. Child Development, 74(3), pp. 822–833.
Smith, A., 1992. The control of orofacial movements in speech. Critical Reviews in Oral Biology & Medicine, 3(3), pp. 233–267.
Smith, A., 2010. Development of neural control of orofacial movements for speech. In The Handbook of Phonetic Sciences, Second Edition (pp. 251–296). Oxford: Wiley–Blackwell.
Smith, N.A. and Strader, H.L., 2014. Infant-directed visual prosody: Mothers’ head movements and speech acoustics. Interaction Studies, 15(1), pp. 38–54.
Sohr-Preston, S.L. and Scaramella, L.V., 2006. Implications of timing of maternal depressive symptoms for early cognitive and language development. Clinical Child and Family Psychology Review, 9(1), pp. 65–83.
Sorensen, T., Toutios, A., Goldstein, L. and Narayanan, S.S., 2016. Characterizing vocal tract dynamics across speakers using real-time MRI. Interspeech, pp. 465–469.
Stavness, I., Lloyd, J.E. and Fels, S., 2012. Automatic prediction of tongue muscle activations using a finite element model. Journal of Biomechanics, 45(16), pp. 2841–2848.
Suemitsu, A., Dang, J., Ito, T. and Tiede, M., 2015. A real-time articulatory visual feedback approach with target presentation for second language pronunciation learning. The Journal of the Acoustical Society of America, 138(4), pp. EL382–EL387.
Sumby, W.H. and Pollack, I., 1954. Visual contribution to speech intelligibility in noise. The Journal of the Acoustical Society of America, 26(24), pp. 212–215.
Summerfield, Q., 1979. Use of visual information for phonetic perception. Phonetica, 36(4–5), pp. 314–331.
Summerfield, Q., 1983. Audio-visual speech perception, lipreading and artificial stimulation. Hearing Science and Hearing Disorders, pp. 131–182.
Summerfield, Q., 1992. Lipreading and audio-visual speech perception. Philosophical Transactions of the Royal Society B: Biological Sciences, 335(1273), pp. 71–78.
Sussman, H.M., 1970. The role of sensory feedback in tongue movement control. Journal of Auditory Research, 10(4), pp. 296–321.
Sussman, H.M., MacNeilage, P.F. and Hanson, R.J., 1973. Labial and mandibular dynamics during the production of bilabial consonants: Preliminary observations. Journal of Speech, Language, and Hearing Research, 16(3), pp. 397–420.
Suzuki, N., 1989. Clinical applications of EPG to Japanese cleft palate and glossectomy patients. Clinical Linguistics & Phonetics, 3(1), pp. 127–136.
Sveinbjornsdottir, S., 2016. The clinical symptoms of Parkinson’s disease. Journal of Neurochemistry, 139, pp. 318–324.
Sweet, H., 1902. A Primer of Phonetics (2nd ed.). Oxford: Oxford University Press.
Tang, K., Harandi, N.M., Woo, J., El Fakhri, G., Stone, M. and Fels, S., 2017. Speaker-specific biomechanical model-based investigation of a simple speech task based on tagged-MRI. Proceedings Interspeech, pp. 2282–2286.
Taylor, N., Isaac, C. and Milne, E., 2010. A comparison of the development of audiovisual integration in children with autism spectrum disorders and typically developing children. Journal of Autism and Developmental Disorders, 40(11), pp. 1403–1411.
Teoh, A.P. and Chin, S.B., 2009. Transcribing the speech of children with cochlear implants: Clinical application of narrow phonetic transcriptions. American Journal of Speech-Language Pathology, 18(4), pp. 388–401.
Terband, H. and Maassen, B., 2010. Speech motor development in childhood apraxia of speech: Generating testable hypotheses by neurocomputational modeling. Folia Phoniatrica et Logopaedica, 62(3), pp. 134–142.
Terband, H., Maassen, B., Guenther, F.H. and Brumberg, J., 2009. Computational neural modeling of speech motor control in childhood apraxia of speech (CAS). Journal of Speech, Language, and Hearing Research, 52(6), pp. 1595–1609.
Terband, H., Maassen, B., Guenther, F.H. and Brumberg, J., 2014. Auditory – motor interactions in pediatric motor speech disorders: Neurocomputational modeling of disordered development. Journal of Communication Disorders, 47, pp. 17–33.
Thelwall, R., 1981. The phonetic theory of John Thelwall (1764–1834). Towards a History of Phonetics, pp. 186–203.
Theobald, B., 2007, August. Audiovisual speech synthesis. International Congress on Phonetic Sciences, pp. 285–290.
Thomas, S.M. and Jordan, T.R., 2004. Contributions of oral and extraoral facial movement to visual and audiovisual speech perception. Journal of Experimental Psychology: Human Perception and Performance, 30(5), p. 873.
Thompson, D.M., 1934. On the detection of emphasis in spoken sentences by means of visual, tactual, and visual-tactual cues. The Journal of General Psychology, 11(1), pp. 160–172.
Thompson, P., 1980. Margaret Thatcher: A new illusion. Perception, 9, pp. 483–484.
Tickle-Degnen, L. and Lyons, K.D., 2004. Practitioners’ impressions of patients with Parkinson’s disease: The social ecology of the expressive mask. Social Science & Medicine, 58(3), pp. 603–614.
Tiippana, K., 2014. What is the McGurk effect?. Frontiers in Psychology, 5, p. 725.
Tilsen, S., Das, D. and McKee, B., 2015. Real-time articulatory biofeedback with electromagnetic articulography. Linguistics Vanguard, 1(1), pp. 39–55.
Tjaden, K., 2008. Speech and swallowing in Parkinson’s disease. Topics in Geriatric Rehabilitation, 24(2), p. 115.
Toutios, A., Byrd, D., Goldstein, L. and Narayanan, S.S., 2017. Articulatory compensation strategies employed by an aglossic speaker. The Journal of the Acoustical Society of America, 142(4), pp. 2639–2639.
Treille, A., Cordeboeuf, C., Vilain, C. and Sato, M., 2014. Haptic and visual information speed up the neural processing of auditory speech in live dyadic interactions. Neuropsychologia, 57, pp. 71–77.
Trim, J., 1953. Some suggestions for the phonetic notation of sounds in defective speech. Speech, 17, pp. 21–24.
Trost, J.E., 1981. Articulatory additions to the classical description of the speech of persons with cleft palate. The Cleft Palate Journal, 18(3), pp. 193–203.
Ullsperger, M. and Von Cramon, D.Y., 2003. Error monitoring using external feedback: Specific roles of the habenular complex, the reward system, and the cingulate motor area revealed by functional magnetic resonance imaging. Journal of Neuroscience, 23(10), pp. 4308–4314.
Valentine, T., 1988. Upside-down faces: A review of the effect of inversion upon face recognition. British Journal of Psychology, 79(4), pp. 471–491.
van Helmont, F.M., 1667. Alphabeti Vere Naturalis Hebraici Brevissima Delineatio. Sulzbach: A. Lichtenthaler.
Vatikiotis-Bateson, E., 1998. The moving face during speech communication. Hearing by Eye II: Advances in the Psychology of Speechreading and Auditory-Visual Speech, 2, p. 123.
Vatikiotis-Bateson, E. and Kuratate, T., 2012. Overview of audiovisual speech processing. Acoustical Science and Technology, 33(3), pp. 135–141.
Vatikiotis-Bateson, E. and Munhall, K.G., 2015. Auditory-visual speech processing. In The Handbook of Speech Production, (pp. 178–199). John Wiley & Sons, 2015.
Velasco, M.A., Raya, R., Ceres, R., Clemotte, A., Bedia, A.R., Franco, T.G. and Rocon, E., 2016. Positive and negative motor signs of head motion in cerebral palsy: Assessment of impairment and task performance. IEEE Systems Journal, 10(3), pp. 967–973.
Viaux-Savelon, S., 2016. Establishing parent – infant interactions. In Joint Care of Parents and Infants in Perinatal Psychiatry (pp. 25–43). Cham: Springer.
Vick, J., Foye, M., Schreiber, N., Lee, G. and Mental, R., 2014. Tongue motion characteristics during vowel production in older children and adults. The Journal of the Acoustical Society of America, 136(4), pp. 2143–2143.
Vick, J., Mental, R., Carey, H. and Lee, G.S., 2017. Seeing is treating: 3D electromagnetic midsagittal articulography (EMA) visual biofeedback for the remediation of residual speech errors. The Journal of the Acoustical Society of America, 141(5), pp. 3647–3647.
Wakumoto, M., Ohno, K., Imai, S., Yamashita, Y., Akizuki, H. and MICHI, K.I., 1996. Analysis of the articulation after glossectomy. Journal of Oral Rehabilitation, 23(11), pp. 764–770.
Walker, S., Bruce, V. and O’Malley, C., 1995. Facial identity and facial speech processing: Familiar faces and voices in the McGurk effect. Perception & Psychophysics, 57(8), pp. 1124–1133.
Wallis, J., 1969. Grammatica Linguae Anglicanae 1653. Menston: Scolar Press.
Wang, J., Samal, A., Rong, P. and Green, J.R., 2016. An optimal set of flesh points on tongue and lips for speech-movement classification. Journal of Speech, Language, and Hearing Research, 59(1), pp. 15–26.
Watkins, C.H., 2015. Sensor driven realtime animation for feedback during physical therapy. MS thesis. The University of Texas at Dallas.
Westbury, J., Milenkovic, P., Weismer, G. and Kent, R., 1990. X-ray microbeam speech production database. The Journal of the Acoustical Society of America, 88(S1), pp. S56–S56.
Whalen, D.H. and McDonough, J., 2015. Taking the laboratory into the field. Annual Review Of Linguistics, 1(1), pp. 395–415.
Widmer, M., Ziegler, N., Held, J., Luft, A. and Lutz, K., 2016. Rewarding feedback promotes motor skill consolidation via striatal activity. In Progress in Brain Research (Vol. 229, pp. 303–323). Amsterdam: Elsevier.
Wightman, F., Kistler, D. and Brungart, D., 2006. Informational masking of speech in children: Auditory-visual integration. The Journal of the Acoustical Society of America, 119(6), pp. 3940–3949.
Wik, P. and Engwall, O., 2008, June. Looking at tongues – can it help in speech perception?. Proceedings FONETIK, pp. 57–61.
Williams, J.H., Massaro, D.W., Peel, N.J., Bosseler, A. and Suddendorf, T., 2004. Visual – auditory integration during speech imitation in autism. Research in Developmental Disabilities, 25(6), pp. 559–575.
Witzel, M.A., Tobe, J. and Salyer, K., 1988. The use of nasopharyngoscopy biofeedback therapy in the correction of inconsistent velopharyngeal closure. International Journal of Pediatric Otorhinolaryngology, 15(2), pp. 137–142.
Woo, J., Xing, F., Lee, J., Stone, M. and Prince, J.L., 2016. A spatio-temporal atlas and statistical model of the tongue during speech from cine-MRI. Computer Methods in Biomechanics and Biomedical Engineering: Imaging & Visualization, pp. 1–12.
Wrench, A., Gibbon, F., McNeill, A.M. and Wood, S., 2002. An EPG therapy protocol for remediation and assessment of articulation disorders. In Seventh International Conference on Spoken Language Processing (ICSLP2002) – INTERSPEECH 2002. Denver, Colorado, USA, September 16–20, 2002.
Yano, J., Shirahige, C., Oki, K., Oisaka, N., Kumakura, I., Tsubahara, A. and Minagi, S., 2015. Effect of visual biofeedback of posterior tongue movement on articulation rehabilitation in dysarthria patients. Journal of Oral Rehabilitation, 42(8), pp. 571–579.
Yehia, H.C., Kuratate, T. and Vatikiotis-Bateson, E., 2002. Linking facial animation, head motion and speech acoustics. Journal of Phonetics, 30(3), pp. 555–568.
Yeung, H.H. and Werker, J.F., 2013. Lip movements affect infants’ audiovisual speech perception. Psychological Science, 24(5), pp. 603–612.
Yont, K.M., Snow, C.E. and Vernon-Feagans, L., 2001. Early communicative intents expressed by 12-month-old children with and without chronic otitis media. First Language, 21(63), pp. 265–287.
Youse, K.M., Cienkowski, K.M. and Coelho, C.A., 2004. Auditory-visual speech perception in an adult with aphasia. Brain Injury, 18(8), pp. 825–834.
Ysunza, A., Pamplona, M., Femat, T., Mayer, I. and García-Velasco, M., 1997. Videonasopharyngoscopy as an instrument for visual biofeedback during speech in cleft palate patients. International Journal of Pediatric Otorhinolaryngology, 41(3), pp. 291–298.
Yu, J., 2017, January. Speech synchronized tongue animation by combining physiology modeling and X-ray image fitting. In International Conference on Multimedia Modeling (pp. 726–737). Cham, Switzerland: Springer.
Yu, J., Jiang, C. and Wang, Z., 2017. Creating and simulating a realistic physiological tongue model for speech production. Multimedia Tools and Applications, 76(13), pp. 14673–14689.