1 Introduction
Functional Data Analysis is the statistical analysis of data sets composed of functions of a continuous variable (time, space, ...), observed in a given domain (see Ramsay and Silverman [8]). In this work, we focus on the inference for functional data, a particularly challenging problem since functional data are objects embedded in infinite-dimensional spaces, and the traditional inferential tools cannot be used in this case. The challenge of deriving inference for functional data is currently tackled by literature from two different perspectives: global inference involves testing a (typically simple) null hypothesis against an alternative extending over the whole (remaining) domain of the parameter space (see e.g. Benko et al. [1], Cuevas et al. [2], Hall and Keilegom [4], Horváth et al. [5], Horváth and Kokoszka [5]); local inference instead addresses the problem of selecting the areas of the domain responsible for the rejection of the null hypothesis, assigning a p-value to each point of the domain (see e.g. Pini and Vantini [6, 7]).
Here, we take the second line of research as a starting point. More precisely, Pini and Vantini [6] suggest performing inference on the coefficients of a B-spline basis expansion, while in extension of the previous work, the same authors propose the interval-wise testing procedure (IWT) which performs inference directly on the functional data (without requiring a basis expansion) [7]. Both methods propose to adjust local p-values in order to control the interval-wise error rate, that is, the probability of wrongly rejecting the null hypothesis in any interval.
In this paper, we extend the IWT to functional data defined in two-dimensional domains. Indeed, all current works addressing local inference deal with one-dimensional domains. Their extension to two (or more) dimensions is not trivial since it would require to define a proper notion of ‘interval’ in two dimensions. We start from a brief overview of the IWT and its properties (Sect. 2, then we discuss how to extend this approach to two-dimensional domains (Sect. 3). Finally, we report in Sect. 4 on a simulation study investigating the properties of this new method, and draw some conclusions (Sect. 5).
2 Previous Works: The IWT for Functional Data Defined on One-Dimensional Domains
We give here a brief overview of the IWT. For a thorough treatment of the method, see Pini and Vantini
[6, 7]. The setting in which the IWT can be used is this: assume that for each unit of analysis (a subject, mechanical object, etc.) we have observed a function  ,
,  ,
, ![$$t \in D = [a,b]$$](../images/461444_1_En_28_Chapter/461444_1_En_28_Chapter_TeX_IEq3.png) , with
, with  . For ease of notation, we assume here that functional data are continuous. However, this assumption can be relaxed (see Pini and Vantini
[7]).
. For ease of notation, we assume here that functional data are continuous. However, this assumption can be relaxed (see Pini and Vantini
[7]).
 against an alternative
against an alternative  . For example, assume that the sample is divided into a different groups. We indicate our functional data as
. For example, assume that the sample is divided into a different groups. We indicate our functional data as  , where
, where  denotes the group, and
denotes the group, and  denotes the units in group j. We could be interested in testing mean differences between the groups:
denotes the units in group j. We could be interested in testing mean differences between the groups:
![$$\mu _j{(t)} = \mathbb E [x_{ij}(t)]$$](../images/461444_1_En_28_Chapter/461444_1_En_28_Chapter_TeX_IEq10.png) . Testing each hypothesis (1) is straightforward since it involves univariate data. The challenge is to adjust the results in order to take the multiplicity of tests into account. The IWT executes this as follows: First, we test each hypothesis (1) separately, and denote the corresponding p-value as p(t). This is an unadjusted p-value function defined for all
. Testing each hypothesis (1) is straightforward since it involves univariate data. The challenge is to adjust the results in order to take the multiplicity of tests into account. The IWT executes this as follows: First, we test each hypothesis (1) separately, and denote the corresponding p-value as p(t). This is an unadjusted p-value function defined for all  . Next, we test the null and alternative hypotheses over each interval
. Next, we test the null and alternative hypotheses over each interval ![$$\mathscr {I} = [t_1,t_2] \subseteq D$$](../images/461444_1_En_28_Chapter/461444_1_En_28_Chapter_TeX_IEq12.png) and the complementary set of each interval
and the complementary set of each interval  :
:

 and
and  , respectively.
, respectively. , we now define an adjusted p-value for interval-wise testing as the maximum p-value of all tests including the point t:
, we now define an adjusted p-value for interval-wise testing as the maximum p-value of all tests including the point t:

 is computed applying formula (4) on the performed tests. For details, see Pini and Vantini
[7].
is computed applying formula (4) on the performed tests. For details, see Pini and Vantini
[7].3 Methods
The primary task in extending the IWT to functional data defined on two-dimensional domains is to find a suitable neighbourhood over which the tests are performed (corresponding to the intervals in the one-dimensional case). If one has decided on a neighbourhood, the very same principle of p-value adjustment as in the one-dimensional case applies. Instead of interval-wise control, we then get control for every neighbourhood of the specified type. What constitutes a good neighbourhood can depend on the specific data one wants to analyse. If there is reason to believe that the two-dimensional subset of the domain in which there is a significant difference between groups takes on a certain shape, then it is reasonable to take this kind of shape as the neighbourhood. The choice of neighbourhood might also depend on the shape of the domain of the functional data. In this contribution, we will try to stay as general as possible and make no assumptions about the area in which significant differences may be found. We do however have to make an assumption about the shape of the two-dimensional domain. We will assume that the data have been recorded on a rectangular grid. This shape makes the use of rectangles or squares as neighbourhoods plausible.
Before we continue, we would like to make one important remark: When using intervals as neighbourhoods in the one-dimensional case, the complement of an interval can be seen as an interval that wraps around. When using rectangles or squares in the two-dimensional scenario, this is not the case. A rectangle that leaves the domain on the right or top and comes in on the left or bottom can not necessarily be described as the complementary set of a rectangle fully contained in the domain. For ease of computation, we decided to test for all possible squares and the complements thereof and to not test squares that wrap around.
Here, we describe the extension of IWT to the two-dimensional domain D, starting from a general definition of neighbourhood. In the following subsection, we discuss instead different possible choices of neighbourhoods.
3.1 The Extension of the IWT to Functional Data Defined on Two-Dimensional Domains
Assume to observe functional data  , with
, with ![$$t\in D=[a_1,b_1]\times [a_2,b_2]$$](../images/461444_1_En_28_Chapter/461444_1_En_28_Chapter_TeX_IEq19.png) , and
, and  . Assume that the functions
. Assume that the functions  are continuous on D. Also, in this case, we aim at locally testing a null hypothesis against an alternative, and selecting the points of the domain where the null hypothesis is rejected. For instance, assume again that units belong to a groups, and that we aim at testing mean equality between the groups (1).
are continuous on D. Also, in this case, we aim at locally testing a null hypothesis against an alternative, and selecting the points of the domain where the null hypothesis is rejected. For instance, assume again that units belong to a groups, and that we aim at testing mean equality between the groups (1).
 a generic neighbourhood. Then, the two-dimensional IWT requires testing the null and alternative hypotheses on every possible neighbourhood, and on every complement of it, i.e. performing the tests
a generic neighbourhood. Then, the two-dimensional IWT requires testing the null and alternative hypotheses on every possible neighbourhood, and on every complement of it, i.e. performing the tests

 . Let us denote with
. Let us denote with  the p-value of such test. Then, the adjusted p-value at point
the p-value of such test. Then, the adjusted p-value at point  can be computed as
can be computed as

3.2 The Problem of Dimensionality in the Choice of the Neighbourhood
In the one-dimensional case, we have two parameters that fully characterise an interval: the starting point of the interval and its length. There are p different starting points and p different lengths. There is, however, only one interval of length p, giving us a total of  possible intervals for which p-values need to be computed. Thus, the computational cost is of order
possible intervals for which p-values need to be computed. Thus, the computational cost is of order  . If we want to use rectangles as neighbourhoods in the two-dimensional case, we can first freely chose the lower left corner of the rectangle, giving us
. If we want to use rectangles as neighbourhoods in the two-dimensional case, we can first freely chose the lower left corner of the rectangle, giving us  possibilities, where
possibilities, where  is the number of grid points on the x-axis and
is the number of grid points on the x-axis and  is the number of grid points on the y-axis. Once the lower left corner is chosen, the rectangle can then be fully characterised by its length in the x-direction and its length in the y-direction. These can however not be chosen freely since the rectangle has to remain inside the domain. Overall, this puts us as
is the number of grid points on the y-axis. Once the lower left corner is chosen, the rectangle can then be fully characterised by its length in the x-direction and its length in the y-direction. These can however not be chosen freely since the rectangle has to remain inside the domain. Overall, this puts us as  possible neighbourhoods, setting the computational cost to the order of
possible neighbourhoods, setting the computational cost to the order of  .
.
If we are content with only using squares, assuming for now that the domain D is observed on a square grid discretised in  points, we only need to test for
points, we only need to test for  neighbourhoods. The computational cost is thus of the order
neighbourhoods. The computational cost is thus of the order  , an order lower than the one of the rectangle case.
, an order lower than the one of the rectangle case.
What if we want to have the benefit of lower computational cost but our domain is a rectangular grid? In this case, we can simply rescale the grid: assume we start from a  grid and assume
grid and assume  . We fix
. We fix  . Let, w.l.o.g,
. Let, w.l.o.g,  . We then rescale the axis with the
. We then rescale the axis with the  observations by using new points with coordinates
observations by using new points with coordinates  ,
,  . If
. If  is not an integer, then the functions were not observed at the resulting new grid points. We can however use a simple nearest neighbour imputation, using only the nearest neighbour. Note that when we speak of squares and rectangles, we mean in terms of the grid, not in terms of the physical units of the observations. Accordingly, by the nearest neighbour, we mean the nearest observation, assuming that the distance between two adjacent grid points is the same for the two dimensions. Our squares thus can be thought of as rectangles whose sides have the same ratio as the sides of the original domain.
is not an integer, then the functions were not observed at the resulting new grid points. We can however use a simple nearest neighbour imputation, using only the nearest neighbour. Note that when we speak of squares and rectangles, we mean in terms of the grid, not in terms of the physical units of the observations. Accordingly, by the nearest neighbour, we mean the nearest observation, assuming that the distance between two adjacent grid points is the same for the two dimensions. Our squares thus can be thought of as rectangles whose sides have the same ratio as the sides of the original domain.
4 Simulation Study
(S0) The grid is quadratic and the null hypothesis is true everywhere. In this case, we should see that we have weak control of the error rate.
(S1) The grid is quadratic and the null hypothesis is violated on a square region. In this case, we should have our square-wise control of the error rate.
(S2) The grid is quadratic and the null hypothesis is violated on a region that is not a square but a rectangle with unequal sides. Thus, we have no control of the FWER in this scenario.
(S3) The grid is rectangular and the null hypothesis is violated on a rectangular region, the ratio of the sides of which is the same as the ratio of the sides of the grid. If our rescaling works as is should, we should see the same results as in (S1).
4.1 Simulation Settings


![$$[0,1] \times [0,1]$$](../images/461444_1_En_28_Chapter/461444_1_En_28_Chapter_TeX_IEq44.png) . In (S3), the domain was
. In (S3), the domain was ![$$[0,2] \times [0,1]$$](../images/461444_1_En_28_Chapter/461444_1_En_28_Chapter_TeX_IEq45.png) . The first mean function was always a constant zero. The second mean function was as follows:
. The first mean function was always a constant zero. The second mean function was as follows:(S0) The second mean function was also a constant zero.
- (S1) The second mean function was defined asThis is a quadratic pyramid of height 1 and with base

![$$[0.25,0.75] \times [0.25,0.75]$$](../images/461444_1_En_28_Chapter/461444_1_En_28_Chapter_TeX_IEq46.png) .
. - (S2) The second mean function was defined asThis is a triangular prism of height 1 and with base

![$$[0,1] \times [0.25,0.75]$$](../images/461444_1_En_28_Chapter/461444_1_En_28_Chapter_TeX_IEq47.png) .
. - (S3) The second mean function was defined asThis is a pyramid of height 1 with base

![$$[0.5,1.5] \times [0.25,0.75]$$](../images/461444_1_En_28_Chapter/461444_1_En_28_Chapter_TeX_IEq48.png) .
.
 grid points in scenarios (S0), (S1) and (S2), and
grid points in scenarios (S0), (S1) and (S2), and  grid points in scenario (S3). The mean functions for the second group for the scenarios (S1), (S2) and (S3) are illustrated in Figure 1
grid points in scenario (S3). The mean functions for the second group for the scenarios (S1), (S2) and (S3) are illustrated in Figure 1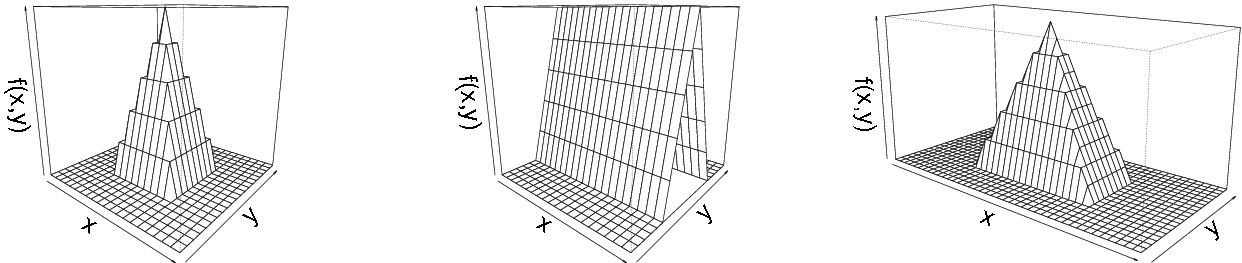
Perspective plots of the mean functions used in scenarios (S1), (S2) and (S3) (from left to right)
4.2 Results of Simulation Study
 . The estimated FWER is reported in Table 1, and the probability of rejection in Fig. 2. Since the estimated probability of rejection was zero in all points in (S0), we decided to show in the figure only the results of (S1), (S2) and (S3). Looking at the FWER, the simulations confirmed what was expected from the theory. When the null hypothesis was true over the whole domain (S0) when it was violated on a square (S1), and when it was violated on a rectangle with the same aspect ratio as the domain (S3), the FWER was controlled, and in fact, the procedure was conservative (the actual FWER was significantly lower than its nominal value in all three cases). However, when the null hypothesis was violated on a region that was different from a square (S2), the FWER was not controlled. Indeed, in this scenario, it was slightly higher than its nominal level.
. The estimated FWER is reported in Table 1, and the probability of rejection in Fig. 2. Since the estimated probability of rejection was zero in all points in (S0), we decided to show in the figure only the results of (S1), (S2) and (S3). Looking at the FWER, the simulations confirmed what was expected from the theory. When the null hypothesis was true over the whole domain (S0) when it was violated on a square (S1), and when it was violated on a rectangle with the same aspect ratio as the domain (S3), the FWER was controlled, and in fact, the procedure was conservative (the actual FWER was significantly lower than its nominal value in all three cases). However, when the null hypothesis was violated on a region that was different from a square (S2), the FWER was not controlled. Indeed, in this scenario, it was slightly higher than its nominal level.FWER estimated over 1000 runs in scenarios (S0), (S1), (S2) and (S3)
Scenario 0 | Scenario 1 | Scenario 2 | Scenario 3 | |
|---|---|---|---|---|
FWER | 0.014 | 0.021 | 0.21 | 0.032 |
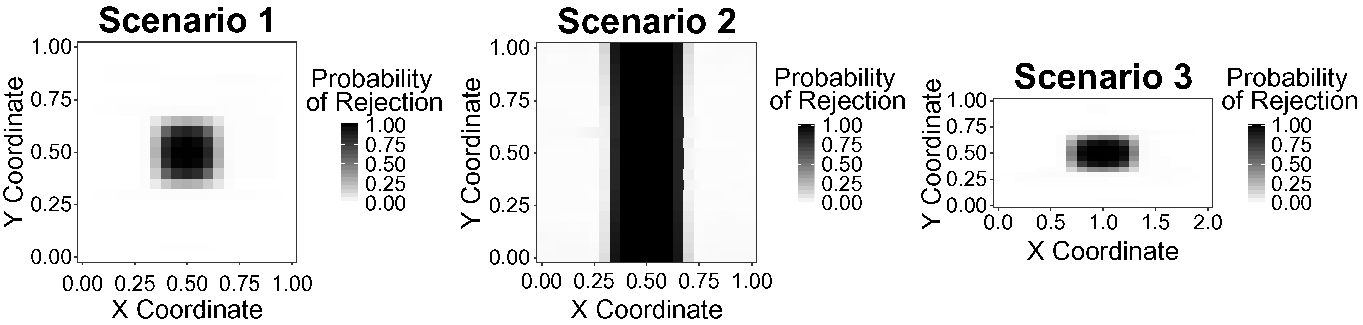
Probability of rejection of each grid point estimated over 1000 runs in scenarios (S1), (S2) and (S3) (from left to right)
5 Discussion
In this paper, we extended the IWT by Pini and Vantini [7] to two-dimensional functional data defined on a rectangular domain. We performed a simulation study to assess the performance of the method when using squares and/or rectangles with the same ratio of sides as the domain and the complement of such shapes as neighbourhoods. The results of the simulation study show that the FWER is controlled when the null hypothesis is true in such neighbourhoods, but not necessarily when it is true on neighbourhoods of a different shape. The simulation also shows that the method can be quite conservative in some instances. Future work will target further improving the respective performance of the method in these situations while keeping the computational complexity manageable.
The presented research was funded by the Austrian Science Fund (FWF): KLI657-B31 and I 2697-N31 and by PMU-FFF: A-18/01/029-HÖL.