


1 Introduction
 with
with  and
and  , this consists in finding the estimator
, this consists in finding the estimator  that solves an equation usually of the form:
that solves an equation usually of the form:
 is a kind of ‘budget’: acting as a weight, it limits the norm of
is a kind of ‘budget’: acting as a weight, it limits the norm of  . Ridge regression and Lasso are special cases where
. Ridge regression and Lasso are special cases where  and
and  , respectively, and their solutions can be calculated even when
, respectively, and their solutions can be calculated even when  is not of full rank.
is not of full rank.Ideally, one would perform  regularisation, i.e. penalising the sum of squared residuals by the number of nonzero variables, but this is a combinatorial problem, and therefore intractable from the computational point of view. On the other hand, Lasso
[8] and other
regularisation, i.e. penalising the sum of squared residuals by the number of nonzero variables, but this is a combinatorial problem, and therefore intractable from the computational point of view. On the other hand, Lasso
[8] and other  -type regularisations (penalisation by the sum of the absolute values of the selected variables) offer a quadratic programming alternative whose solution is still a proper variable selection, as it contains many zeros.
-type regularisations (penalisation by the sum of the absolute values of the selected variables) offer a quadratic programming alternative whose solution is still a proper variable selection, as it contains many zeros.
Lasso has many advantages. First, it applies shrinkage on the variables which can lead to better predictions than simple least squares due to Stein’s phenomenon
[7]. Second, the convexity of its penalty means Lasso can be solved numerically. Third,  regularisation is variable selection consistent under certain conditions, provided that the coefficients of the true model are large enough compared to the regularisation parameter
[6, 10, 14]. Fourth, Lasso can take into account structures; simple modifications of its penalisation term result in structured variable selection. Such variations among others are the fused lasso
[9], the graphical lasso
[3] and the composite absolute penalties
[13] including the group-lasso
[12]. Fifth, for a fixed regularisation parameter,
regularisation is variable selection consistent under certain conditions, provided that the coefficients of the true model are large enough compared to the regularisation parameter
[6, 10, 14]. Fourth, Lasso can take into account structures; simple modifications of its penalisation term result in structured variable selection. Such variations among others are the fused lasso
[9], the graphical lasso
[3] and the composite absolute penalties
[13] including the group-lasso
[12]. Fifth, for a fixed regularisation parameter,  regularisation has nearly the same sparsity as
regularisation has nearly the same sparsity as  regularisation
[2]. However, this does not hold anymore when the regularisation parameter is optimised in a data-dependent way, using an information criterion such as AIC
[1] or Mallows’s Cp
[5].
regularisation
[2]. However, this does not hold anymore when the regularisation parameter is optimised in a data-dependent way, using an information criterion such as AIC
[1] or Mallows’s Cp
[5].
Mallows’s Cp, like many other information criteria, takes the form of a penalised—likelihood or—sum of squared residuals whose penalty depends on the number of selected variables. Therefore, among all models of equal size, the selection is based on the sum of squared residuals. Because of sparsity, it is easy to find a well-chosen combination of falsely significant variables that reduces the sum of squared residuals, by fitting the observational errors. The effects of these false positives can be tempered by applying shrinkage. The optimisation of the information criterion then overestimates the number of variables needed, including too many false positives in the model. In order to avoid this scenario, one idea could be to combine both  and
and  regularisation: the former to select the nonzeros and the latter to estimate their value. The optimal balance between the sum of squared residuals and the
regularisation: the former to select the nonzeros and the latter to estimate their value. The optimal balance between the sum of squared residuals and the  regularisation should shift towards smaller models. Of course, this change must be taken into account and the expression of the information criterion consequently adapted. The correction for the difference between
regularisation should shift towards smaller models. Of course, this change must be taken into account and the expression of the information criterion consequently adapted. The correction for the difference between  and
and  regularisation has been described as a ‘mirror’ effect
[4].
regularisation has been described as a ‘mirror’ effect
[4].
In Sect. 2, we explain more the mirror effect. The main contribution of this paper follows and concerns the impact of a structure among the variables and how it affects the selection. More precisely, the behaviour of the mirror effect for unstructured and structured signal-plus-noise models is investigated in Sect. 3. A simulation is presented in Sect. 4 to support the previous sections.
2 The Mirror Effect

 is a n-vector of independent and identically distributed errors with
is a n-vector of independent and identically distributed errors with  and
and  for
for  . The design matrix
. The design matrix  has size
has size  with n possibly smaller than m. We assume
with n possibly smaller than m. We assume  is sparse in the sense that the unknown number of nonzeros
is sparse in the sense that the unknown number of nonzeros  in
in  is smaller than n. For a given k, let
is smaller than n. For a given k, let  be a binary m-vector with
be a binary m-vector with  zeros, provided by a procedure
zeros, provided by a procedure  which can be unstructured best k selection or any structured procedure. An example of such a procedure could be an implementation of Lasso with the regularisation parameter fine-tuned to obtain the appropriate model size. Also, define
which can be unstructured best k selection or any structured procedure. An example of such a procedure could be an implementation of Lasso with the regularisation parameter fine-tuned to obtain the appropriate model size. Also, define  as the selection found by an oracle knowing
as the selection found by an oracle knowing  without noise, using the same procedure as for
without noise, using the same procedure as for  , i.e.
, i.e.  . The notations
. The notations  and
and  are used for the
are used for the  submatrices of
submatrices of  containing the k columns corresponding to the 1s in
containing the k columns corresponding to the 1s in  and
and  , respectively.
, respectively. , is measured by the prediction error
, is measured by the prediction error  which can be, in turn, estimated unbiasedly by
which can be, in turn, estimated unbiasedly by  , where, for a generic selection
, where, for a generic selection  ,
,
 is a non-studentised version of Mallows’s Cp
is a non-studentised version of Mallows’s Cp
 , however, depends on
, however, depends on  . Hence, for the corresponding least squares projection
. Hence, for the corresponding least squares projection  , the expectation of
, the expectation of  will not be equal to
will not be equal to  .
.Among all selections of size k for k large enough so that the important variables are in the model, the procedure consisting of minimising (2), i.e.  , adds seemingly nonzero variables—that should, in fact, be zeros—in order to fit the observational errors by minimising further the distance between
, adds seemingly nonzero variables—that should, in fact, be zeros—in order to fit the observational errors by minimising further the distance between  and
and  . The consequence is a better-than-average appearance of
. The consequence is a better-than-average appearance of  contrasting with the worse-than-average true prediction error: indeed the false positives perform worse in staying close to the signal without the errors than variables selected in a purely arbitrary way. This two-sided effect of appearance versus reality is described as a mirror effect
[4].
contrasting with the worse-than-average true prediction error: indeed the false positives perform worse in staying close to the signal without the errors than variables selected in a purely arbitrary way. This two-sided effect of appearance versus reality is described as a mirror effect
[4].
 affects the statistics of the selected variables. Because the selection
affects the statistics of the selected variables. Because the selection  does not depend on
does not depend on  , leaving the statistics of the selected variables unchanged, the oracle curve
, leaving the statistics of the selected variables unchanged, the oracle curve  acts as a mirror reflecting
acts as a mirror reflecting  onto
onto  :
:
 and
and  in dashed and dotted lines, respectively, as functions of the model size k. Also, the mirror curve
in dashed and dotted lines, respectively, as functions of the model size k. Also, the mirror curve  is represented as the solid curve. Details of the calculations can be found in Sect. 4.
is represented as the solid curve. Details of the calculations can be found in Sect. 4.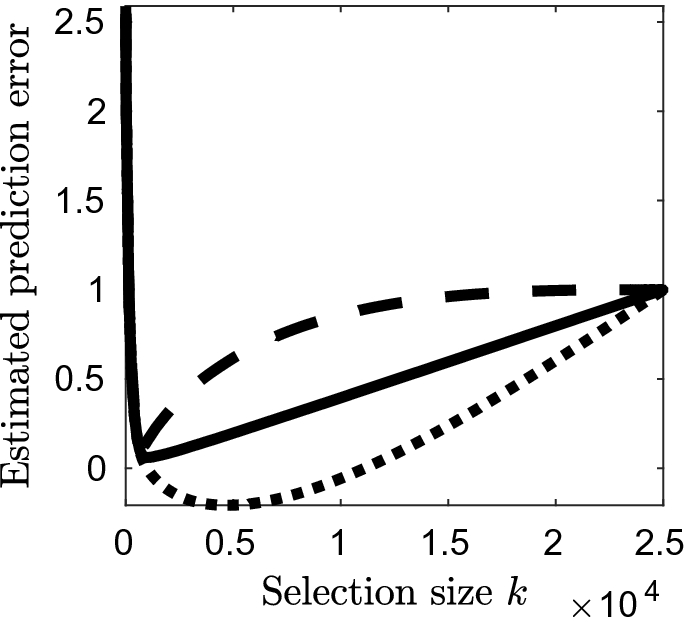
Illustration of the mirror effect. The mirror curve is plotted in solid line as a function of the model size and reflects the prediction error and Mallows’s Cp, represented as dashed and dotted curves, respectively
 , the generalised degrees of freedom are given by
, the generalised degrees of freedom are given by![$$\begin{aligned} \nu _k = \frac{1}{\sigma ^2} E[\mathbf {\varepsilon }^T(\mathbf {\varepsilon }-\mathbf {e}_k)] = \frac{1}{n} E(\mathbf {\varepsilon }^T \mathbf {X}_{\mathbf {S}^k}\widehat{\mathbf {\beta }}_{\mathbf {S}^k}) \end{aligned}$$](../images/461444_1_En_32_Chapter/461444_1_En_32_Chapter_TeX_Equ4.png)
 is then an unbiased estimator of
is then an unbiased estimator of  for any choice of the selection
for any choice of the selection  . Under sparsity assumptions
[4], we have
. Under sparsity assumptions
[4], we have![$$\begin{aligned} \nu _k = E[\Vert \mathbf {P}_{\mathbf {S}_k}\mathbf {\varepsilon }\Vert ^2_2]\sigma ^{-2} + o[\mathrm {PE}(\widehat{\mathbf {\beta }}_{\mathbf {S}^k})] \mathrm {~as~} n \rightarrow \infty \end{aligned}$$](../images/461444_1_En_32_Chapter/461444_1_En_32_Chapter_TeX_Equ5.png)
 . Given such a projection, the mirror correction
. Given such a projection, the mirror correction  is found to be
is found to be![$$\begin{aligned} m_k = \frac{1}{n} E[\Vert \mathbf {P}_{\mathbf {S}^k}\mathbf {\varepsilon }\Vert ^2_2; \mathbf {\beta }]-\frac{k}{n}\sigma ^2, \end{aligned}$$](../images/461444_1_En_32_Chapter/461444_1_En_32_Chapter_TeX_Equ6.png)
![$$m_k = (\nu _k-k)\sigma ^2/n+o[\mathrm {PE}(\widehat{\mathbf {\beta }}_{\mathbf {S}^k})]$$](../images/461444_1_En_32_Chapter/461444_1_En_32_Chapter_TeX_IEq74.png) . This expression explicitly writes the parametric dependence on
. This expression explicitly writes the parametric dependence on  . An unbiased estimator is given by
. An unbiased estimator is given by![$$\begin{aligned} \widehat{m}_k = \frac{1}{n} E[\Vert \mathbf {P}_{\mathbf {S}^k}\mathbf {\varepsilon }\Vert ^2_2| \mathbf {S}^k; \mathbf {\beta }]-\frac{k}{n}\sigma ^2. \end{aligned}$$](../images/461444_1_En_32_Chapter/461444_1_En_32_Chapter_TeX_Equ7.png)
3 Qualitative Description of the Mirror
 , an estimator of the mirror effect
, an estimator of the mirror effect  can be written as
can be written as
 . The behaviour of this estimator is described in the two following subsections.
. The behaviour of this estimator is described in the two following subsections.3.1 Unstructured Signal-Plus-Noise Models
- Small selection sizes:
especially if
 (the true number of nonzeros in
(the true number of nonzeros in  ), only nonzero variables should be selected. The errors associated with these variables have an expected variance equal to
), only nonzero variables should be selected. The errors associated with these variables have an expected variance equal to  since they are randomly distributed among these variables. Hence,
since they are randomly distributed among these variables. Hence,  is close to zero.
is close to zero.- Intermediate selection sizes:
the large errors are selected accordingly to their absolute value. Their expected variance is obviously greater than
 , meaning that
, meaning that  is increasing. Its growth is high at first and decreases to zero as smaller errors are added to the selection, leading to the last stage.
is increasing. Its growth is high at first and decreases to zero as smaller errors are added to the selection, leading to the last stage.- Large selection sizes:
finally, only the remaining small errors are selected. This has the effect of diminishing the (previously abnormally high) variance to its original expected value;
 drops to zero which is achieved for the full model.
drops to zero which is achieved for the full model.
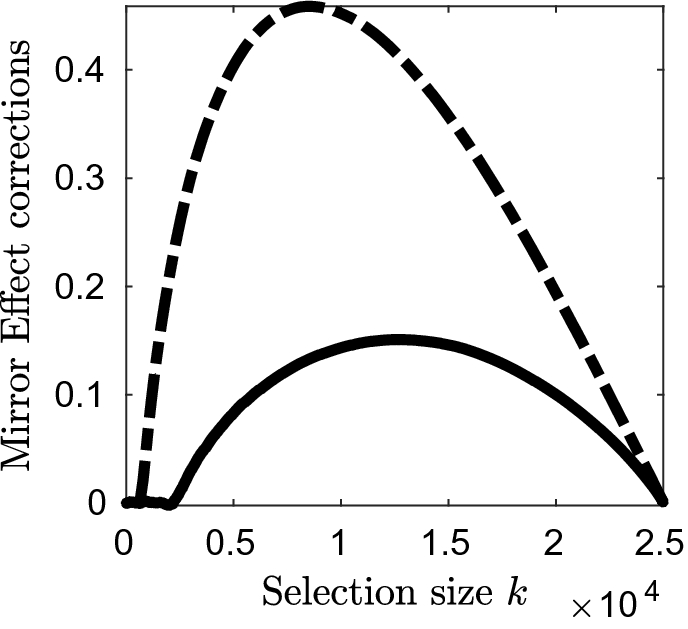
Illustration of the mirror correction behaviour for unstructured (dot-dashed line) and group selections (solid) as functions of the model size
3.2 Structured Models: Grouped Variables
 . See Sect. 4 for a more complete definition of
. See Sect. 4 for a more complete definition of  .
. - Small selection sizes:
groups of nonzero variables are selected first as they have major effects on the linear regression. As before, the associated errors are randomly distributed, so their expected variance equals
 and
and  is roughly zero.
is roughly zero.- Intermediate selection sizes:
the groups containing only errors are selected accordingly to their norms. These groups typically contain high value errors and some low value errors. Hence, their expected variance is greater than
 but smaller than in the case of unstructured selection as the latter just selects the largest errors. The consequence on
but smaller than in the case of unstructured selection as the latter just selects the largest errors. The consequence on  is that it increases but its growth, although high at first, is smaller than for the unstructured case.
is that it increases but its growth, although high at first, is smaller than for the unstructured case.- Large selection size:
groups of small errors are selected (although they can still contain some large errors), meaning that their expected variance decreases to
 which is achieved for the full model.
which is achieved for the full model.
The explanations above hold for any type of structure, so we can deduce that the unstructured mirror has the largest amplitude in signal-plus-noise models. Indeed, as there is no constraint on the variables, once the nonzeros are selected, the errors are included in the model given their absolute value and more correction is needed in order to temper their effects.
This description is represented in Fig. 2 where the mirror corrections for group and unstructured selections can be visually compared as they are plotted in dot-dashed and solid lines, respectively. The three stages of group selection can be seen in the intervals [0, 2500], [2500, 125000] and [12500, 25000]. Details of the calculations can be found in Sect. 4.
4 Simulation
In this simulation,  groups containing
groups containing  coefficients
coefficients  are generated so that
are generated so that  is a n-dimensional vector with
is a n-dimensional vector with  . Within group j, the
. Within group j, the  coefficients have the same probability
coefficients have the same probability  of being nonzero and, for each group j, a different value
of being nonzero and, for each group j, a different value  is randomly drawn from the set
is randomly drawn from the set  with the respective probability
with the respective probability  . The expected proportion of nonzeros is
. The expected proportion of nonzeros is  for the whole vector
for the whole vector  . The nonzeros from
. The nonzeros from  are distributed according to the zero inflated Laplace model
are distributed according to the zero inflated Laplace model  where
where  . The observations then are computed as the vector of groups
. The observations then are computed as the vector of groups  , where
, where  is an n-vector of independent, standard normal errors.
is an n-vector of independent, standard normal errors.
Estimates  are calculated considering two configurations: groups of size
are calculated considering two configurations: groups of size  (initial setting) and groups of size 1 (unstructured selection). In the latter scenario,
(initial setting) and groups of size 1 (unstructured selection). In the latter scenario,  where
where  is the binary n-vector selecting the k largest absolute values. The 10-group estimator is
is the binary n-vector selecting the k largest absolute values. The 10-group estimator is  where
where  is the binary r-vector selecting the l groups whose
is the binary r-vector selecting the l groups whose  norms are the largest. Using Lasso and group-lasso, respectively, would provide us with the same selections
norms are the largest. Using Lasso and group-lasso, respectively, would provide us with the same selections  and
and  , because of the signal-plus-noise model. Mirror corrections for both configurations are found using (8).
, because of the signal-plus-noise model. Mirror corrections for both configurations are found using (8).
A comparison of the false discovery rates (FDR) of nonzero variables for unstructured and group selections is presented in Fig. 3: because we allow groups to contain zeros and nonzeros in this simulation, at first the recovery rate of the nonzeros in the group setting is below the recovery rate of the unstructured nonzeros. However, the two rates quickly cross and we find the recovery of the nonzeros in the group setting to be better afterwards: particularly, this is the case for the selection that minimises the group-mirror-corrected Cp (marked with the vertical line in Fig. 3).
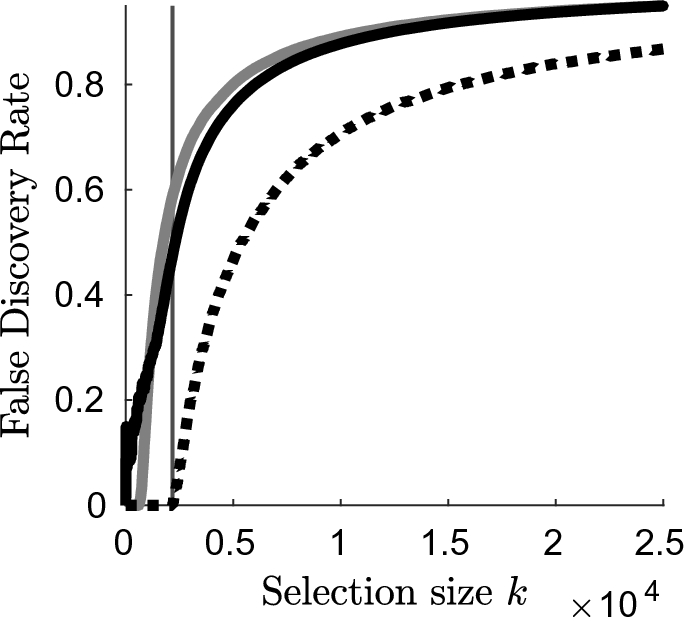
Illustration of the false discovery rate (FDR) of nonzero variables for unstructured (grey solid curve) and group selections (black solid curve) as functions of the model size. The vertical line represents the selection size of the best model found with the group-mirror-corrected Cp and the black dotted curve is the FDR of nonzero groups
5 Conclusion
During the optimisation of an information criterion over the model size, using both  and
and  -regularisation for the selection and estimation of variables allows us to take advantage of quadratic programming for the former and least squares projection for the latter. This technique avoids an overestimation of the number of selected variables; however, it requires a corrected expression for the information criterion: the difference between
-regularisation for the selection and estimation of variables allows us to take advantage of quadratic programming for the former and least squares projection for the latter. This technique avoids an overestimation of the number of selected variables; however, it requires a corrected expression for the information criterion: the difference between  and
and  regularisation is compensated using the mirror effect.
regularisation is compensated using the mirror effect.
In this paper, we described the behaviour of the mirror effect in signal-plus-noise models, observing three stages depending on the model size. This way we can distinguish the selection of nonzero variables, of large false positives and of small false positives for which the mirror is, respectively, close to zero, then increasing and finally decreasing to zero again. In the special case of structured selection, we note a similar behaviour for the mirror although its amplitude is smaller, meaning that the information criterion needs less correction.