1 Introduction
In financial econometrics, the last two decades have witnessed an increasing interest in the development of dynamic models incorporating information on realized volatility measures. The reason is that it is believed these models can provide more accurate forecasts of financial volatility than the standard volatility models based on daily squared returns, e.g. the GARCH(1,1).
Engle and Russell [14] originally proposed the Autoregressive Conditional Duration (ACD) model as a tool for modelling irregularly spaced transaction data observed at high frequency. This model has been later generalized in the class of Multiplicative Error Model (MEM) by [10] for modelling and forecasting positive-valued random variables that are decomposed into the product of their conditional mean and a positive-valued i.i.d. error term with unit mean. Discussions and extensions on the properties of this model class can be found in [4–8, 18, 19], among others.
One of the most prominent fields of application of MEMs is related to the modelling and forecasting of realized volatility measures. It is well known that these variables have very rich serial dependence structures sharing the features of clustering and high persistence. The recurrent feature of long-range dependence is conventionally modelled as an Autoregressive Fractionally Integrated Moving Average (ARFIMA) process as in [3], or using regression models mixing information at different frequencies such as the Heterogeneous AR (HAR) model of [9]. The HAR model, inspired by the heterogeneous market hypothesis of [20], is based on additive cascade of volatility components over different horizons. This particular structure, despite the simplicity of the model, has been found to satisfactorily reproduce the empirical regularities of realized volatility series, including their highly persistent autocorrelation structure.
In this field, component models are an appealing alternative to conventional models since they offer a tractable and parsimonious approach to modelling the persistent dependence structure of realized volatility measures. Models of this type have first been proposed in the GARCH framework and are usually characterized by the mixing of two or more components moving at different frequencies. Starting from the Spline GARCH of [13], where volatility is specified to be the product of a slow-moving component, represented by an exponential spline, and a short-run component which follows a unit mean GARCH process, several contributions have extended and refined this idea. [12] introduced a new class of models called GARCH-MIDAS, where the long-run component is modelled as a MIDAS (Mixed-Data Sampling, [16]) polynomial filter which applies to monthly, quarterly or biannual financial or macroeconomic variables. [2] decomposed the variance into a conditional and an unconditional component such that the latter evolves smoothly over time through a linear combination of logistic transition functions taking time as the transition variable.
Moving to the analysis of intra-daily data, [15] developed the multiplicative component GARCH, decomposing the volatility of high-frequency asset returns into the product of three components, namely, the conditional variance is a product of daily, diurnal and stochastic intra-daily components. Recently [1] have provided a survey on univariate and multivariate GARCH-type models featuring a multiplicative decomposition of the variance into short- and long-run components.
This paper proposes a novel multiplicative dynamic component model which is able to reproduce the main stylized facts arising from the empirical analysis of time series of realized volatility. Compared to other specifications falling into the class of component MEMs, the main innovation of the proposed model can be found in the structure of the long-run component. Namely, as in [21], this is modelled as an additive cascade of MIDAS filters moving at different frequencies. This choice is motivated by the empirical regularities arising from the analysis of realized volatility measures that are typically characterized by two prominent and related features: a slowly moving long-run level and a highly persistent autocorrelation structure. For ease of reference, we will denote the parametric specification adopted for the long-run component as a Heterogeneous MIDAS (H-MIDAS) filter. Residual short-term autocorrelation is then explained by a short-run component that follows a mean reverting unit GARCH-type model. The overall model will be referred to as a H-MIDAS Component MEM model (H-MIDAS-CMEM). It is worth noting that, specifying the long-run component as an additive cascade of volatility filters as in [9], we implicitly associate this component to long-run persistent movements of the realized volatility process.
The model that is here proposed differs from that discussed in [21] under two main respects. First, in this paper, we model realized volatilities on a daily scale rather than high-frequency intra-daily trading volumes. Second, the structure of the MIDAS filters in the long-run component is based on a pure rolling window rather than on a block rolling window scheme.
The estimation of model parameters can be easily performed by maximizing a likelihood function based on the assumption of Generalized F distributed errors. The motivation behind the use of this distribution is twofold. First, nesting different distributions, the Generalized F results very flexible in modelling the distributional properties of the observed variable. Second, it can be easily extended to control the presence of zero outcomes [17].
In order to assess the relative merits of the proposed approach we present the results of an application to the realized volatility time series of the S&P 500 index in which the predictive performance of the proposed model is compared to that of the standard MEM by means of an out-of-sample rolling window forecasting experiment. The volatility forecasting performance has been assessed using three different loss functions, the Mean Squared Error (MSE), the Mean Absolute Error (MAE) and the QLIKE. The Diebold-Mariano test is then used to evaluate the significance of differences in the predictive performances of the models under analysis. Our findings suggest that the H-MIDAS-CMEM significantly outperforms the benchmark in terms of forecasting accuracy.
The remainder of the paper is structured as follows. In Sect. 2, we present the proposed H-MIDAS-CMEM model, while the estimation procedure is described in Sect. 3. The results of the empirical application are presented and discussed in Sect. 4. Finally, Sect. 5 concludes.
2 Model Specification
 be a time series of daily realized volatility (RV) measures observed on day i in period t, such as in a month or a quarter. The general H-MIDAS-CMEM model can be formulated as
be a time series of daily realized volatility (RV) measures observed on day i in period t, such as in a month or a quarter. The general H-MIDAS-CMEM model can be formulated as
 is the sigma-field generated by the available intra-daily information until day
is the sigma-field generated by the available intra-daily information until day  of period t. The conditional expectation of
of period t. The conditional expectation of  , given
, given  , is the product of two components characterized by different dynamic specifications. In particular,
, is the product of two components characterized by different dynamic specifications. In particular,  represents a daily dynamic component that reproduces autocorrelated movements around the current long-run level, while
represents a daily dynamic component that reproduces autocorrelated movements around the current long-run level, while  is a smoothly varying component given by the sum of MIDAS filters moving at different frequencies. This component is designed to track the dynamics of the long-run level of realized volatility.1 In order to make the model identifiable, as in
[12], the short-run component is constrained to follow a mean reverting unit GARCH-type process. Namely,
is a smoothly varying component given by the sum of MIDAS filters moving at different frequencies. This component is designed to track the dynamics of the long-run level of realized volatility.1 In order to make the model identifiable, as in
[12], the short-run component is constrained to follow a mean reverting unit GARCH-type process. Namely,  is specified as
is specified as
 , it is necessary to set appropriate constraints on
, it is necessary to set appropriate constraints on  by means of a targeting procedure. In particular, taking the expectation of both sides of
by means of a targeting procedure. In particular, taking the expectation of both sides of  , it is easy to show that
, it is easy to show that
 is then ensured by setting the following standard constraints:
is then ensured by setting the following standard constraints:  ,
,  for
for  , and
, and  for
for  .2
.2

 and
and  denote the RV aggregated over a rolling window of length equal to
denote the RV aggregated over a rolling window of length equal to  and
and  , respectively, with
, respectively, with  , while K is the number of MIDAS lags and
, while K is the number of MIDAS lags and  . In particular,
. In particular,

 implying a biannual rolling window RV and
implying a biannual rolling window RV and  , meaning that the RV is rolled back monthly. Furthermore, the long-run component is considered in terms of logarithmic specification since it does not require parameter constraints to ensure the positivity of
, meaning that the RV is rolled back monthly. Furthermore, the long-run component is considered in terms of logarithmic specification since it does not require parameter constraints to ensure the positivity of  .
. is computed according to the Beta weighting scheme which is generally defined as
is computed according to the Beta weighting scheme which is generally defined as
This multiple frequency specification appears to be preferable to the single-frequency MIDAS filter for at least two different reasons. First, the modeller is not constrained to choose a specific frequency for trend estimation, but can determine the optimal blend of low- and high-frequency information in a fully data-driven fashion. Second, as pointed out in
[9], an additive cascade of linear filters, applied to the same variable aggregated over different time intervals, can allow to reproduce very persistent dynamics such as those typically observed for realized volatilities. We have also investigated the profitability of adding more components to the specification of  . However, this did not lead to any noticeable improvement in terms of fit and forecasting accuracy.
. However, this did not lead to any noticeable improvement in terms of fit and forecasting accuracy.
3 Estimation
The model parameters can be estimated in one step by Maximum Likelihood (ML), assuming that the innovation term follows a Generalized F (GF) distribution. Alternatively, estimation could be performed by maximizing a quasi-likelihood function based on the assumption that the errors  are conditionally distributed as a unit Exponential distribution that can be seen as the counterpart of the standard normal distribution for positive-valued random variables
[10, 11]. To save space, here we focus on ML estimation based on the assumption of GF errors.
are conditionally distributed as a unit Exponential distribution that can be seen as the counterpart of the standard normal distribution for positive-valued random variables
[10, 11]. To save space, here we focus on ML estimation based on the assumption of GF errors.
![$$\begin{aligned} f(x;\underline{\zeta })=\frac{ax^{ab-1}[c+(x/\eta )^a]^{(-c-b)}\,c^c}{\eta ^{ab}\,\mathscr {B}(b,c)}, \end{aligned}$$](../images/461444_1_En_35_Chapter/461444_1_En_35_Chapter_TeX_Equ7.png)
 ,
,  ,
,  ,
,  and
and  , with
, with  the Beta function such that
the Beta function such that ![$$\mathscr {B}(b,c)=[ \Gamma (b)\Gamma (c) ] / \Gamma (b+c)$$](../images/461444_1_En_35_Chapter/461444_1_En_35_Chapter_TeX_IEq39.png) . The GF distribution is based on a scale parameter
. The GF distribution is based on a scale parameter  and three shape parameters a, b and c, and thus it is very flexible, nesting different error distributions, such as the Weibull for
and three shape parameters a, b and c, and thus it is very flexible, nesting different error distributions, such as the Weibull for  and
and  , the generalized Gamma for
, the generalized Gamma for  and the log-logistic for
and the log-logistic for  and
and  . The Exponential distribution is also asymptotically nested in the GF for
. The Exponential distribution is also asymptotically nested in the GF for  and
and  .
.Note that in the presence of zero outcomes the Zero-Augmented Generalized F (ZAF) distribution [17] can be used.
 is fulfilled, we need to set
is fulfilled, we need to set  , where
, where![$$\begin{aligned} \xi =c^{1/a}\left[ \Gamma (b+1/a)\Gamma (c-1/a)\right] \left[ \Gamma (b)\Gamma (c)\right] ^{-1}. \end{aligned}$$](../images/461444_1_En_35_Chapter/461444_1_En_35_Chapter_TeX_Equ10.png)
![$$\begin{aligned} \begin{aligned} \mathscr {L}(\underline{v};\underline{\vartheta }) =&\sum _{t,i} \left\{ log \, a + (ab-1) \, log \left( \varepsilon _{t,i} \right) + c \, log \, c -(c+b) \, log \left[ c + \left( \xi \varepsilon _{t,i}\right) ^a \right] + \right. \\&\left. -log ( \tau _{t,i} \, g_{t,i} ) - log \, \mathscr {B}(b,c) + ab\,log( \xi ) \right\} , \end{aligned} \end{aligned}$$](../images/461444_1_En_35_Chapter/461444_1_En_35_Chapter_TeX_Equ8.png)
 and
and  is the parameter vector to be estimated.
is the parameter vector to be estimated.4 Empirical Application
To assess the performance of the proposed model, in this section, we present and discuss the results of an empirical application to the S&P 500 realized volatility series.3 The 5-min intra-daily returns have been used to compute the daily RV series covering the period between 03 January 2000 and 27 December 2018 for a total of 4766 observations. The analysis has been performed using the software R [23].
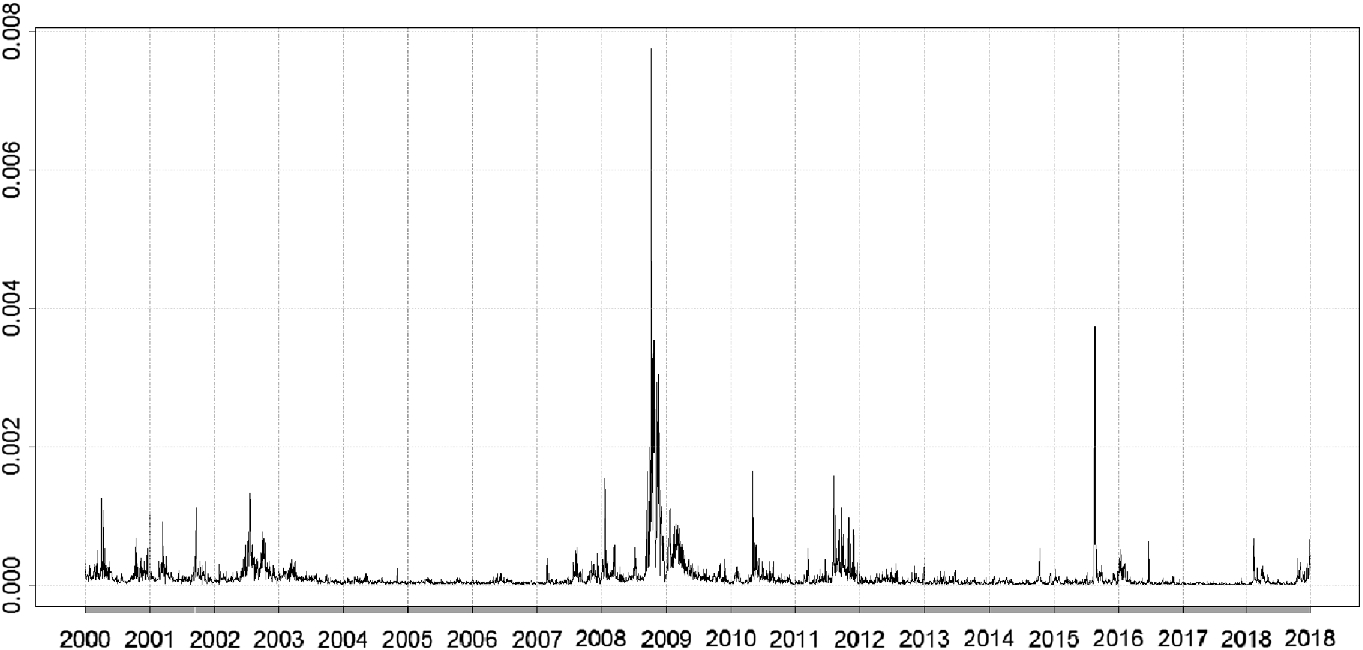
S&P 500 Realized Volatility
In sample parameter estimates for the Generalized F distribution
 |
Regarding the H-MIDAS-CMEM, the short-run component follows a mean reverting unit GARCH(1,1) process, while the long-term component is specified as a combination of two MIDAS filters moving at a semiannual ( ) and a monthly (
) and a monthly ( ) frequency, with K corresponding to two MIDAS lag years. It is worth noting that, although the Beta lag structure in (6) includes two parameters, following a common practice in the literature on MIDAS models, in our empirical applications,
) frequency, with K corresponding to two MIDAS lag years. It is worth noting that, although the Beta lag structure in (6) includes two parameters, following a common practice in the literature on MIDAS models, in our empirical applications,  and
and  have been set equal to 1 in order to have monotonically decreasing weights over the lags.
have been set equal to 1 in order to have monotonically decreasing weights over the lags.
The panel of the short-term component in Table 1 shows that the intercept  is slightly higher for the H-MIDAS-CMEM than the standard MEM. Furthermore, standard errors for
is slightly higher for the H-MIDAS-CMEM than the standard MEM. Furthermore, standard errors for  are missing since it is estimated through the expectation targeting procedure. The parameter
are missing since it is estimated through the expectation targeting procedure. The parameter  takes values much larger than those typically obtained fitting GARCH models to log-returns, while the opposite holds for
takes values much larger than those typically obtained fitting GARCH models to log-returns, while the opposite holds for  . The analysis of the long-run component reveals that all the involved parameters in
. The analysis of the long-run component reveals that all the involved parameters in  are statistically significant. In particular, the slope coefficient
are statistically significant. In particular, the slope coefficient  of the biannual filter is negative, while
of the biannual filter is negative, while  associated to the monthly filter is positive. Moreover, the coefficients
associated to the monthly filter is positive. Moreover, the coefficients  and
and  defining the features of the Beta weighting function take on values such that the weights slowly decline to zero over the lags. Finally, the panel referring to the error distribution parameters indicates that the GF coefficients are similar between MEM and H-MIDAS-CMEM.
defining the features of the Beta weighting function take on values such that the weights slowly decline to zero over the lags. Finally, the panel referring to the error distribution parameters indicates that the GF coefficients are similar between MEM and H-MIDAS-CMEM.
From a comparison of the log-likelihoods, it clearly emerges that the value recorded for the H-MIDAS-CMEM is much larger than that of the competing model. In addition, the BIC reveals that there is a big improvement coming from the inclusion of the heterogeneous component in the MIDAS trend which allows to better capture the changes in the dynamics of the average volatility level.
In sample parameter estimates for the Exponential distribution
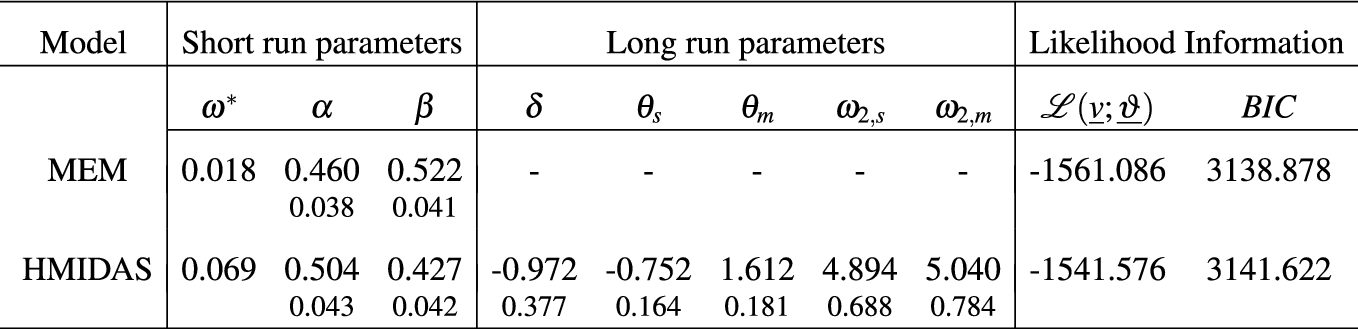 |
The out-of-sample predictive ability of the models, for the S&P 500 RV time series, has been assessed via a rolling window forecasting exercise leaving the last 500 observations as out-of-sample forecasting period, that is, 30 December 2016–27 December 2018.

S&P 500 out-of-sample loss functions comparison
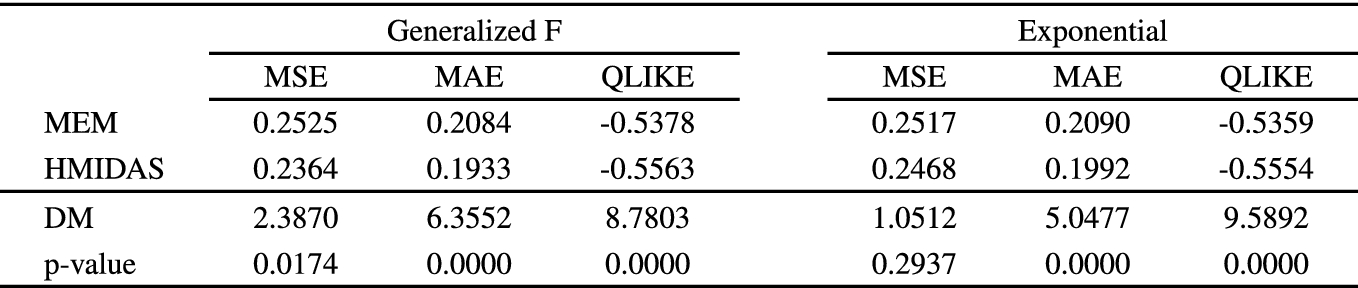 |
The out-of-sample performance of the fitted models is summarized in Table 3, reporting the average values of the considered loss functions (top panel) and the Diebold-Mariano (DM) test statistics, together with the associated p-values (bottom panel). The empirical results suggest that the H-MIDAS-CMEM always returns average losses that are significantly lower than those recorded for the benchmark MEM. The only exception occurs for the MSE when models are fitted by Exponential QML. In this case, the H-MIDAS-CMEM still returns a lower average loss, but the null of equal predictive ability cannot be rejected. Finally, comparing forecasts based on models fitted by MLE and QMLE, respectively, we find that there are no striking differences between these two sets of forecasts, with the former returning slightly lower average losses.
5 Concluding Remarks
This paper investigates the usefulness of the application of the Heterogeneous MIDAS Component MEM (H-MIDAS-CMEM) for fitting and forecasting realized volatility measures. The introduction of the heterogeneous MIDAS component, specified as an additive cascade of linear filters which take on different frequencies, allows to better capture the main empirical properties of the realized volatility, such as clustering and memory persistence. The empirical analysis of the realized volatility series of the S&P 500 index points out that the H-MIDAS-CMEM outperforms the standard MEM model in fitting the S&P 500 volatility. At the same time, the out-of-sample comparison shows that, for all the loss functions considered, the H-MIDAS-CMEM significantly outperforms the benchmark in terms of predictive accuracy. These findings appear to be robust to the choice of the error distribution. Accordingly, gains in predictive ability are mainly determined by the dynamic structure of the H-MIDAS-CMEM, rather than from the estimation method (MLE versus QMLE).
Finally, although the model discussed in this paper is motivated by the empirical properties of realized volatility measures, our approach can be easily extended to the analysis of other financial variables sharing the same features, such as trading volumes, bid-ask spreads and durations.