3
Graph Rewriting and Transformation of Syntactic Annotations in a Corpus
One elementary application of graph rewriting is pattern matching in a syntactically annotated corpus. The objective of this process may be to detect annotation errors or to study linguistic phenomena in the corpus. This application involves the use of isolated rules, and only the pattern aspect of each rule is required. If we want to go beyond error detection, for example correcting recurring mistakes, then we use the command element of the rules.
A more sophisticated application, involving full rule systems, consists of transforming the annotation of a corpus. Graph rewriting can be applied to transform corpus annotations in two ways:
- – to move from one linguistic level to the next;
- – to change annotation format, retaining the same linguistic level.
In this chapter, we shall only consider applications to syntax. For this reason, the first approach will be illustrated using the passage from surface syntax to deep syntax. The surface and deep SEQUOIA annotation formats were presented in Chapter 2; these will be distinguished using the term SSQ for the former and DSQ for the latter. We shall present a system of rewriting rules SSQ_to_DSQ to transform surface annotation using SSQ into deep annotation using DSQ.
In Chapter 2, we also considered another surface syntax format, UD, which also has a deep syntax equivalent, denoted as AUD. The rule system for rewriting UD_to_AUD, transforming surface annotation in UD format into deep annotation in AUD, is very similar to SSQ_to_DSQ; for this reason, only the latter will be discussed here.
The other form of corpus transformation is to change the format, while staying on the same linguistic level. This transformation will be illustrated using the SSQ_to_UD and UD_to_SSQ systems, used to move from SSQ format to UD format and vice-versa.
3.1. Pattern matching in syntactically annotated corpora
Chapter 1 featured simple examples of pattern matching searches in linguistic structures. In this chapter, we shall consider the way in which pattern matching can be used for corpus management.
Specifically, we shall consider corpus correction and searches for linguistic examples in a corpus of annotated sentences. In both cases, these methods were applied to corpora of sentences with surface syntax annotation; a variety of resources exist, or are being developed, for this type of usage. Clearly, a similar approach may also be applied to other types of resources, including graph banks.
In what follows, these searches will be carried out in either the SEQUOIA corpus or the French section of the Universal Dependencies corpus. A description of pattern syntax may be found in Chapter 2 (see section 1.5.1).
3.1.1. Corpus correction
Corpus creation is a tedious and time-consuming task. Many cases are hard to judge, as linguistic phenomena often take the form of a continuum. Furthermore, different annotators do not always perceive phenomena in the same way, reducing the overall consistency of a corpus; moreover, when annotation guides are not sufficiently precise, there is an increased likelihood of discrepancies and inconsistencies in annotation. Finally, conventions may change over the course of an annotation campaign, for example to take account of a forgotten element or to add precision to an aspect of annotation choices. As a general rule, a postprocessing phase is therefore useful to correct and/or verify the final corpus.
Many research projects have resulted in the production of annotated data, often using linguistic choices that are specific to the project in question; these corpora are therefore not directly compatible, even in cases where they aim to describe the same level of linguistic analysis. A frequent solution is to automatically convert corpora from one representation to another. However, these automatic conversions may also result in new errors or inconsistencies in the converted data.
3.1.1.1. Example: error searching for the subject relation
The set of annotations used in a corpus depends on a set of linguistic choices that are, in principle, set out in an annotation guide. In the documentation for the nsubj relation in UD version 11, for example, we find:
This nominal may be headed by a noun, or it may be a pronoun or relative pronoun, or in ellipsis contexts, other things such as an adjective.
This rule may be translated by a pattern, and we may look for occurrences that do not respect this description. In this case, we search for nsubj relations of which the dependents are neither nouns nor pronouns (whether relative or personal), i.e.:
pattern { G -[nsubj]-> D }
without { D [cat=NOUN|PROPN] }
without { D [cat=PRON] }
In UD_FRENCH-2.0, we find 108 occurrences of this pattern. For D, these are split into the following categories: NUM for cardinal numbers, SYM for symbols, X for indeterminate categories and ADJ for adjectives. The occurrences are distributed as follows: 31 NUM (11 of which are annotation errors), 37 SYM (two errors), 22 X (several of these are debatable: ONU, DGSE, …), 12 ADJ (translations of categories, as in Ce dernier aurait dû recevoir […]) (the latter should have received…). There are then six remaining cases: two multi-word expressions (tout le monde, everybody), two titles used as subjects, one other type of translation and one erroneous text.
One further example is not stipulated in the guide, but is clearly visible in the syntax model: the same node should not be the governor of two subject relations. Thus, the following pattern appears 107 times in UD_FRENCH-1.4; these errors are corrected in version 2.0.
pattern {
G -[nsubj|nsubj:pass|csubj|csubj:pass]-> D1;
G -[nsubj|nsubj:pass|csubj|csubj:pass]-> D2;
D1 << D2;
}
After searching for subjects which may include errors, we can then search for missing subjects: a verb should have a subject. The following pattern eliminates legitimate reasons for absence (infinitives, copulas, etc.).
% Search for verbs without subjects.
% a verb with feature constraints…
match {V [cat=“VERB”, VerbForm <> Ger|Inf|Part, Mood <> Imp]}
% …which is not the governor of a subject relation…
without { V -[nsubj|csubj|nsubj:pass]-> S}
% …and which is not dependent of "cop", "aux", …
without { N -[cop|aux|aux:pass|conj]-> V}
% …and is not part of a multi-word expression.
without { * -[fixed]-> V }
This pattern is found 82 times in UD_FRENCH-2.0. In 29 of these cases, the annotation is correct (four cases of multi-word expressions, seven cases annotated with expl for impersonal subjects, and 18 cases of ungrammatical sentences). This leaves 53 cases with annotation errors (14 cases of incorrect verb features, 13 cases where the post-verbal subject is considered as an object, and 26 miscellaneous cases). These 53 errors have been corrected in version 2.1, due for release in November 2017.
3.1.1.2. Other examples and corpus searching tips
In French, nouns and determiners must agree in both number and gender. In the SEQUOIA corpus, the following pattern highlights annotations which appear not to follow the gender agreement rule:
pattern {
N [cat=N];
D [cat=D];
N -[det]-> D;
N.g <> D.g;
}
This pattern is found 12 times in SEQUOIA version 7.0. One of these occurrences corresponds to a specific construction, le plus d’informations possibles (as much information as possible); the 11 other instances are errors, which have since been corrected.
The case of agreement in number between a verb and its subject is more complex. The following example illustrates an approach that is often used in error checking: a general pattern is used to find a superset of the element we wish to observe, then this set is reduced iteratively by adding negative conditions to eliminate examples corresponding to correctly-annotated exceptions.
First, take the following pattern:
pattern {
V [cat=V]; V -[suj]-> S;
S.n <> V.n;
}
This pattern is found 174 times. Many of these cases are correct annotations. The first example is …plusieurs automobilistes ont quitté la chaussée…, several drivers left the highway; the word automobilistes (drivers) is plural, while the past participle quitté (left) is singular. A negative condition is added to the pattern to take account of this exception:
without {
V[m=part, t=past];
A[cat=V, lemma=avoir];
V -[aux.tps]-> A;
}
With this addition, the set is reduced to 45 instances. These include further correct annotations in which the subject is a coordination (Denise et son époux René faisaient aussi partie…, Denise and her husband René were also among them) and others featuring lexical exceptions (…une douzaine d’hommes étaient mobilisés…, a dozen men were mobilized, where douzaine is considered to be the subject of mobilisés). These exceptions are accounted for using the following negative conditions:
without {
S[n=s]; V[n=p]; S -[coord]-> *;
}
without {
S [cat=N,
lemma=“minorité”|“majorité”|“ensemble”|“nombre”|“dizaine”
|“douzaine”|“quinzaine”|“vingtaine”|“trentaine”|
“quarantaine”;
]
}
The 14 instances identified using this new pattern can then be treated on a case-by-case basis. They correspond to errors in the original sentences, or specific cases, such as the construction ce sont […].
Patterns may also express constraints concerning the order of words in a sentence, either using a clause N1 << N2, which only selects cases in which N1 precedes N2 in the linear order of the sentence, or using N1 < N2, that only selects cases in which N1 immediately precedes N2. Note that the first type of clause was used earlier in searching for two subjects (see 3.1.1.1): without the line D1 « D2, each instance would have been found twice, exchanging the nodes associated with D1 and D2.
Immediate precedence enables us to control the annotation of n-grams. The following pattern is used to identify the way in which instances of en plus de are annotated in a corpus.
pattern {
N1 [lemma=“en”]; N2 [lemma=“plus”]; N3 [lemma=“de”];
N1 < N2; N2 < N3
}
23 instances are found in UD_FRENCH-2.0, highlighting a number of inconsistencies, including seven errors requiring correction.
3.1.2. Searching for linguistic examples in a corpus
Pattern matching can also be used for the purposes of corpus linguistics, taking an approach similar to that illustrated through the examples above. We can see whether a particular construction is present in a corpus, discover its frequency and, where applicable, find examples.
For instance, say that we want to find verbs with a given subcategorization framework. The following pattern identifies verbs with both an argument introduced by à and an argument introduced by de (or a clitic playing this role).
pattern {
V [cat=V];
V -[a_obj]-> A;
V -[de_obj]-> DE;
}
There are six instances of this type in SEQUOIA 7.0 (laisser le soin, leave sth. to; répondre, respond; faire part, notify, x2; parler, speak; and donner l’occasion, offer the opportunity).
As in the case of error searches, successive refinements may be used to target more precise constructions or to create sub-sets in our results. Say that we want to know how many of our six occurrences feature a verb with (or without) a direct object. In this case, we may use the following pattern:
pattern {
V [cat=V];
V -[a_obj]-> A;
V -[de_obj]-> DE;
} without {
V -[obj]-> O;
}
This gives us two cases without a direct object, and we may simply comment out the fifth line “} without {” (using the character % at the start of the line) to find the other four cases.
Now, let us consider a search for a specific verbal construction: in this example, we wish to find a nominal object without a determiner, as in the case of prendre conscience (to gain awareness) or avoir peur (to be afraid).
pattern {
V[cat=V];
OBJ[cat=N, s=c];
V -[obj]-> OBJ
}
without {
OBJ -[det]-> D
}
This occurs 170 times, and the verbs in question are easy to identify (39 cases of avoir, 29 faire, 11 prendre, etc.).
Evidently, any number of other examples may be found, but we shall limit ourselves to one further case here, that of coordination of unlikes, in which conjuncts do not belong to the same category. The way in which ellipsis coordination is treated in SEQUOIA makes it difficult to search for disparate coordinations, as the dep.coord relation is used as a default relation to describe non-standard dependencies. In UD, coordination is treated differently, making this search easier to carry out using the following pattern:
pattern {
N1 -[conj]-> N2;
N1.cat <> N2.cat;
}
There are 84 matches for this pattern in UD_FRENCH-PARTUT-2.0. By creating further patterns, we discover 21 cases of “Noun/Verb” coordination, 20 of “Proper noun/Common noun”, 17 of “Verb/Adjective”, nine of “Noun/Adjective”, eight of “Noun/Pronoun”, and nine remaining miscellaneous cases (notably featuring annotation errors).
To facilitate this process, an online pattern matching interface is available at http://match.grew.fr. This interface makes it possible to create patterns and carry out searches in a set of corpora in different languages, forming part of the UD project, and in different versions of SEQUOIA with or without deep syntax.
EXERCISE 3.1.– Suppose that we have a syntactically annotated corpus in SEQUOIA format, in which verbs are marked with the category V and adverbs with ADV. Write patterns using GREW syntax to find the following constructions:
- 1) verbs immediately preceded by the adverb ne and immediately followed by the adverb que in such a way that they govern ne but not que;
- 2) verbs with a single direct object (
objrelation) placed before them; - 3) verbs with an inverted subject (
sujrelation) and a direct object (objrelation); - 4) verbs with a modifier on the right (
modrelation) where there are no other elements between the modifier and the verb.
3.2. From surface syntax to deep syntax
The deep syntax level was defined in very general terms in section 2.3. Deep syntax highlights the arguments of lexical words present in a sentence in a canonical form, neutralizing the different diatheses through which the arguments are presented.
As we are working with two different surface syntax formats, SSQ and UD, a corresponding deep syntax format is required for each. The deep syntax format corresponding to SSQ is DSQ, a well-established and well-documented format2.
Work on designing a deep syntax level for UD is more recent in date, and a consensus has yet to be reached. [SCH 16] proposes an enrichment of UD surface syntax toward deep syntax: this is the Enhanced Universal Dependencies (EUD) format. [CAN 17] proposes an addition to the EUD scheme, taking account of all aspects generally considered as part of deep syntax. This is known as Alt-enhanced Universal Dependencies (AUD) format. Our UD_to_AUD system transforms annotations in UD format to annotations in AUD. It also has the capacity to produce an annotation in EUD format as an intermediary step.
In this section, we shall give a detailed presentation of the SSQ_to_DSQ system, highlighting the universal elements of this system that may be reused in other systems for transformations from surface to deep syntax, whatever the input and output formats in question. For this reason, our presentation of the UD_to_AUD system will be much shorter.
3.2.1. Main steps in the SSQ_to_DSQ transformation
The SSQ_to_DSQ system takes a corpus annotated in SSQ format as its input and produces an annotation in DSQ format. In reality, the output annotation retains a trace of the input annotation; this mixed format is known as SSQ-DSQ. From this format, we can then obtain either surface annotation in SSQ format or deep annotation in DSQ format by simple projection. The transformation from SSQ to SSQ-DSQ involves a series of four main steps:
- 1) add the deep arguments of adjectives, adverbs and verbs;
- 2) show the deep dependencies relating to certain specific constructions: relative propositions, dislocations; superlatives, comparatives, parenthetical clauses, etc.;
- 3) neutralize passive, passive pronomial, impersonal and causative diatheses;
- 4) eliminate semantically empty words and the associated dependencies.
Coordinations affect most other phenomena, and they are thus treated differently, on multiple occasions at opportune moments in the transformation process.
These different steps are illustrated in the example below, using the following sentence, taken from example [annodis.er_00342] in the SEQUOIA corpus.
(3.1) Il devrait indiquer s’ il plaide coupable des faits
He should indicate whether he pleads guilty to the facts
qui lui sont reprochés
which him are alleged
’He should indicate whether he pleads guilty to the facts alleged against him’
The figure below shows the initial annotation of the sentence in SSQ format.

The deep subjects of the infinitive indiquer and the adjective coupable are added in step 1. These deep subjects are determined using lexicons. Thus, a lexicon indicates that the verb devoir has a direct object which is an infinitive, and the deep subject of the infinitive is the subject of devoir. Similarly, a lexicon indicates that the verb plaider has a direct object that is an adjective, and the deep subject of the adjective is the subject of plaider.

Step 2 reveals deep dependencies for specific constructions. In our example, the suj dependency targeting the relative pronoun is transferred to its antecedent, faits.

The various diatheses are neutralized in step 3. The only case in our example is the passive sont reprochés. Its final subjects, qui and faits, become its canonical objects. This is shown in the figure by a change in the dependency label. The final function is replaced by the (final function: canonical function) pair. In this case, this means that the label suj is replaced by suj:obj. For functions that may be affected by a diathesis change, in cases where this does not happen, the final function is repeated as the canonical function. This is the reason for the suj:suj label for the dependency from devrait to Il.

The final step, 4, consists of eliminating semantically empty words and their associated dependencies. As we have seen, a trace of these deleted elements is retained; these are shown in red in the figure3. Prepositions or conjunctions are effectively short-circuited rather than being eliminated. For example, the conjunction s’ should be deleted. It is the target of an obj:obj dependency originating from indiquer and the source of an obj.cpl dependency toward plaide. These two dependencies are replaced by a single obj:obj dependency from indiquer to plaide.
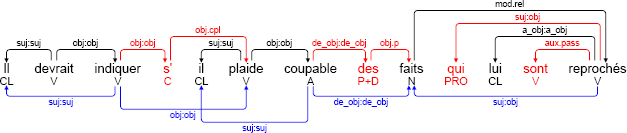
The interest of the mixed SSQ-DSQ format lies in the possibility of recreating SSQ annotation, on the one hand, and of creating DSQ, on the other hand, by simple projection. Graphically, as we see from the example above, SSQ surface annotation includes of all of the words and dependencies shown above the sentence; for double labels, only the left hand side, indicating a final function, is retained. This gives us the SSQ annotation shown below.

DSQ deep annotation is made up of the words shown in black, the dependencies shown in black above the sentence that are applicable on both the surface and deep levels, and the dependencies in blue below the sentence, which only apply to the deep level. For double labels, only the right hand side, indicating a canonical function, has been retained. This gives us the DSQ annotation below.

The SSQ_to_DSQ system includes 50 packages of 260 rules, including 61 lexical rules. The main steps we have presented for the translation from surface to deep syntax can be found in any rewriting system designed for this purpose, whatever the input and output formats or the language in question.
3.2.2. Lessons in good practice
In constructing the SSQ_to_DSQ system, we were able to identify a number of keys for good practice, presented below.
3.2.2.1. Managing the limits of an automatic system
Even with the addition of lexical information, an automatic rule system cannot take account of all aspects of a transformation, for example the identification of the deep arguments of all infinitives and participles. In the example below, syntax is not sufficient to identify the subject of the infinitives être and apporter: bénévoles.
(3.2) [annodis.er_00255]
… rappelle la vocation des bénévoles de
… recall the vocation of the volunteers
l’association: être un soutien pour la
of the association: to be a support for
paroisse, apporter une petite contribution financière
the parish, to make a small contribution
aux travaux grâce aux manifestations et
financial to the work through demonstrations
aux dons, …
and donations, …
’… recall the vocation of the volunteers of the association: to be a support for the parish, to make a small financial contribution to the work through demonstrations and donations, …’
Automatic transformation therefore needs to be supplemented by manual annotation. Cases such as those highlighted in the example above are rare and can be localized automatically, for example by searching for infinitives and participles without subjects in the converted corpus. The problem lies in the fact that the rule system responsible for transformations is designed to evolve, and it would be inefficient to carry out manual annotation from scratch for each new version of the system. It is thus important to memorize this manual annotation.
3.2.2.2. Refer to other linguistic levels to remove ambiguities
Ambiguity is only rarely encountered when transforming SSQ annotations into DSQ format, as the computation is generally deterministic: a single SSQ annotation is transformed into a single DSQ annotations. When they do occur, ambiguities may be of a lexical nature. For example, in the sentence il fait monter le secrétaire (which has two main possible translations in English: he got the secretary to come up/he had the writing desk brought up), the SSQ annotation includes an obj dependency from monter to secrétaire. However, this does not tell us whether secrétaire is the subject or the object of monter in deep syntax. This ambiguity can only be resolved using semantic information: we need to know whether the "secrétaire" is a person (secretary) or an item of furniture (a writing desk).
For certain ambiguities, the phonological level may come into play. This is the case, for example, in managing dependencies originating at the first conjunct in a coordination. Let us consider the example below.
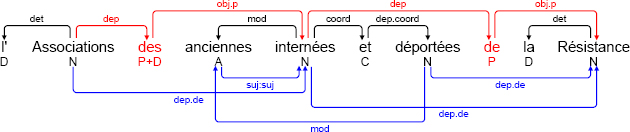
(3.3) [annodis.er_00294]
l’ Associations des anciennes internées et déportées de
The Associations of the former interned and deported of
la Résistance
the Resistance
’The Associations of former internees and deportees of the Resistance’
The surface annotation of this sentence does not tell us whether the constituent de la Résistance is linked to the whole coordination internées et déportées, or simply to the first element internées. A decision can only be reached by looking at the word order. As the constituent de la Résistance is situated after the second conjunct déportées, it must necessarily be linked to the whole coordination.
Unfortunately, ambiguities cannot always be resolved. Thus, the surface annotation of the sentence above does not tell us if the adjective anciennes applies solely to internées, or to the whole coordination internées et déportées. In both cases the mod dependency targeting anciennes originates from internées. Looking at the deep annotation, we see that the mod dependency is distributed to déportées, indicating that a decision has been made to apply the adjective to the full coordination. In this case, results of this type can only be obtained through manual annotation.
EXERCISE 3.2.– In the graphs, let us consider patterns of the form:
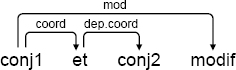
Write a rule which adds a mod dependency from conj2 to modif only when the latter is situated after conj2.
3.2.2.3. Iterating strategies
All rules are systematically iterated, i.e. applied to a corpus for as long as this is possible. Certain recursive phenomena require not only iterative application of rules, but also complex strategy. This often occurs for strategies that are sequential compositions S1, S2 such that S2 creates the conditions for further applications of S1. In these cases, we need to execute Iter(Seq (S1, S2)).
The SSQ_to_DSQ system features an example of complex iteration of this type. A package S1 defines the deep arguments of infinitives, participles and adjectives, then a package S2 distributes the dependencies originating in a coordination across the conjuncts. However, S2 introduces new dependencies that permit further applications of S1, as we see from the example below.

(3.4) [annodis.er_00487]
L’ automobile a perdu [sa roue gauche], et a décollé
The car lost [its wheel left], and
pour se retourner et terminer [sa course sur
took off to turn over and finish [its running
le toit].
on the roof]
’The car lost [its left wheel], and went on to turn over and finish [running on the roof]’
The initial annotation is shown above the sentence.
A first execution of S_1 does not produce any new dependencies. Next, an execution of S2 produces the subject dependency from décollé to automobile. A further execution of S1 then allows us to determine the subject of retourner, and repetition of S2 serves the same purpose for terminer.
3.2.2.4. Package decomposition
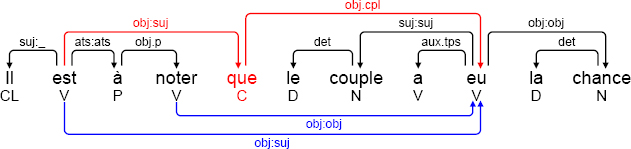
When creating a rule system, we often start by grouping rules related to a specific task into large packages. This was carried out, for example, for the deletion of certain grammatical words (prepositions, subordination conjunctions and relative pronouns). To delete a given conjunction C, which is the target of a dependency X -[e]-> C and the source of a dependency C -[obj.cpl]-> Y, we considered, at the outset, that it would be enough to delete node C and replace the two dependencies by a single dependency X -[e]-> Y. We designed a packet to carry out this, and similar, transformations for prepositions and relative pronouns. However, this approach fails to take account of the fact that a conjunction may be the target of several dependencies, as we see in the example below.
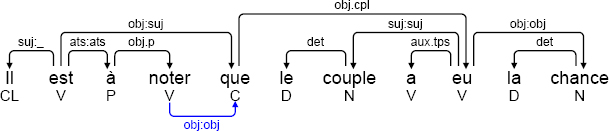
(3.5) [annodis.er_00107]
Il est à noter que le couple a eu la chance …
It should be noted that the couple had the chance …
’It should be noted that the couple had the chance …’
The figure above shows the annotation of a sentence prior to deletion of semantically empty nodes and their associated dependencies. Let us consider the conjunction que, due to be deleted. This conjunction is the target of two dependencies: an obj:suj surface dependency and an obj:obj deep dependency. If we apply the package in its original form, only one of the two dependencies will be transformed correctly. For this reason, we decomposed the package into a sequential composition P1;P2 with two sub-packages: P1 transfers all dependencies that target the word to be deleted toward its object, in the case of a preposition or a conjunction, or its antecedent, in the case of a relative pronoun; P2 effectively deletes the grammatical word and the dependency originating from it.
In our example, P1 transfers each of the dependencies, obj:suj and obj:obj, from the conjunction que to the participle eu. The conjunction and the obj.cpl dependency originating from it can only be deleted by package P2 once all transfers have been carried out. We thus obtain the annotation shown below4.
Decomposition of a package into ordered subpackages is one way of defining the order in which rules should be applied, but this is not the only possible approach. Negative constraints may also be inserted into rules to fulfill this purpose. This notion will be explored in the following exercise.
EXERCISE 3.3.– In the graphs, let us consider patterns of the form:

Write a rule that replaces the obj dependency from verb1 to conj with an obj dependency from verb1 to verb2, where conj is the subordination conjunction que or si. Write a second rule to delete the conj node and the dependency stemming from it if, and only if, there is no dependency targeting conj (this is an alternative to the package decomposition approach proposed above).
3.2.2.5. Generating non-local dependencies
Graph rewriting is, by its very nature, essentially a local process: a rule can only be applied to graph nodes that are connected by a fixed number of edges. In natural language processing, however, we sometimes need to generate non-local dependencies between linguistic units, as a result of the fact that they may be produced from an unlimited number of dependencies. This may occur, for example, in relations between relative pronouns and their antecedents, as a relative pronoun may be an argument for a word more or less deeply embedded in the relative proposition.
Consider the example below, which shows the annotation of an expression by the SSQ_to_DSQ system prior to determination of the antecedents of the relative pronouns.
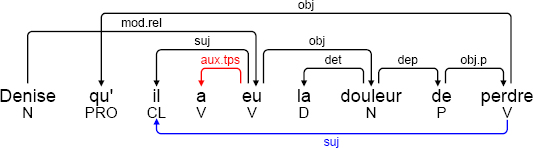
(3.6) [annodis.er_00079]
Denise[, son épouse,] qu’il a eu la douleur de perdre
Denise [, his wife,] he had the pain of losing
[il y a quinze jours]
[a fortnight ago]
’He had the misfortune to lose Denise [, his wife,] [a fortnight ago]’
In this example, to find the antecedent of the relative pronoun qu’, i.e. the name Denise, we need to travel back up a dependency chain from the pronoun qu’ until we reach the antecedent. Here, the chain is obj ← obj.p ← dep ← obj ← mod.rel. To do this, we use three rules. The first is an initialization rule, which marks the start of the chain by an ant.tmp dependency, from the relative pronoun to one of its governors. A propagation rule is then used to move the target of this dependency one step further up the chain. Following a series of successive steps, when the mod.rel dependency is reached, the final rule ends the search process by replacing the ant.tmp dependency with an ant.rel dependency from the relative pronoun to its antecedent. In practice, slightly more sophisticated rules are needed to take account of the fact that nodes in the chain may have two governors. In this case, one governor needs to be selected in order to continue.
EXERCISE 3.4.– Write rules to carry out the three tasks described above (initialization, propagation, termination), enabling us to find the antecedent of a relative pronoun. We shall presume that there are no forks in the chain for the ant.tmp dependency, i.e. that there is a single chain from the relative pronoun to its antecedent.
3.2.3. The UD_to_AUD transformation system
As we have seen, a consensus has yet to be reached regarding the deep syntax level for UD. For SEQUOIA, the passage from surface syntax to deep syntax is carried out by adding dependencies, but also by replacement and deletion. In all existing proposals for UD, the transformation process essentially involves the addition of dependencies.
[SCH 16] proposes a first enrichment, the EUD format. This enrichment involves five aspects5:
- 1) adding the subjects of infinitives which are dependent on controlled or raised verbs;
- 2) propagating dependencies relating to a coordination to all conjuncts;
- 3) attaching relative pronouns to their antecedents;
- 4) for complements introduced by a preposition, refining the dependency label with the name of the preposition;
- 5) adding empty nodes to represent elided predicates.
In order to obtain a full deep syntax representation as defined in Chapter 2, two additions to the EUD format are required: first, all subjects and indirect complements of infinitives and participles in the sentence need to be added, and second, the different diatheses must be neutralized. Working in collaboration with Candito and Seddah [CAN 17], we have proposed a new format, AUD, which has been tested in French. AUD may be seen as an enrichment of the EUD format, with a few subtle differences. Notably, it does not take account of the 4 and 5 aspects of EUD. The modifications made by AUD in relation to the 4 element cannot truly be considered as an enrichment; this information is simply redundant due to the use of the case and mark dependencies. With regardss to 5, empty nodes are intended to represent elided words in certain expressions, and their introduction is difficult to annotate (even manually); there are no clear guidelines in the current UD documentation, and for this reason, they were left out of the AUD format.
The UD_to_AUD system is intended to transform annotations in UD format into AUD format. It may produce an annotation in EUD format, without empty nodes, as an intermediate stage in the process. It is composed of 191 rules, including 27 lexical rules, grouped into 26 packages.
3.2.4. Evaluation of the SSQ _to_ DSQ and UD _to_ AUD systems
The SEQUOIA corpus, annotated using the SSQ-DSQ schema, has been validated manually and may thus be used as a point of reference in evaluating the SSQ_to_DSQ transformation system.
Evaluating the transformation from SSQ format to SSQ-DSQ we obtain an F-measure of 0.9849. However, this figure takes account of the surface relations provided as input, which are simple to predict. To obtain a better evaluation of the transformation itself, we may choose to consider the score for new edges alone (i.e. edges shown in blue in the figures above); in this case, the transformation obtains an F-measure of 0.9598. These positive results confirm that rewriting offers a satisfactory means of carrying out this transformation, and the need for manual annotation is relatively low.
There is no available reference corpus annotated in UD or AUD format. The only form of evaluation that can be carried out in a reasonable time frame involves the use of a reduced sample from a corpus annotated in both UD and AUD validated manually. The UD_to_AUD system is applied to the sample annotated in UD and the results are compared to the reference sample annotated in AUD. An evaluation of this type is presented in [CAN 17]. One hundred sentences were chosen at random from the SEQUOIA corpus (transformed into UD format) and 100 other sentences were taken from the UD_FRENCH corpus. These 200 sentences were validated in both the UD surface format and in their converted AUD forms.
Evaluation of the UD_to_AUD transformation using this data gave an F-measure of 0.9949 for all relations. However, as in the previous case, an evaluation of the subset of new relations alone gives a lower F-measure of 0.9386.
3.3. Conversion between surface syntax formats
In this section, we shall describe two conversion systems, operating between the same formats in opposite directions: the SSQ_to_UD system and the UD_to_SSQ system. The two systems differ in their levels of complexity and precision, as SSQ format is finer than UD format, so the transformation from the former to the latter results in a loss of information. In the SSQ to UD transformation, conversion rules tend to delete information; in the other direction, some of the information required is not found in the annotation and must be obtained from other sources, notably lexicons. In order to gain a clear understanding of the issues involved, we shall begin by presenting the main differences between the SSQ and UD annotation schemes.
3.3.1. Differences between the SSQ and UD annotation schemes
Generally speaking, the UD annotation scheme for surface syntax takes more account of semantics than the SSQ scheme. The reason for this is that UD is intended to be a universal format, i.e. applicable to all languages, and as such must be able to leave aside the syntactic specificities of each individual language. This is seen notably in the choice of lexical words rather than grammatical words as the heads of syntagms. We shall now consider the main differences between the two schemes in greater detail.
3.3.1.1. The copula – subject predicative complement relationship
In French, the verb être is considered to be a copula when it is used with a subject predicative complement. In SSQ, this construction is modeled by an ats dependency from the copula to the head of the subject predicative complement; in UD a cop dependency is used in the opposite direction. Each modeling presents a number of advantages and drawbacks, as we shall see from the two examples below.
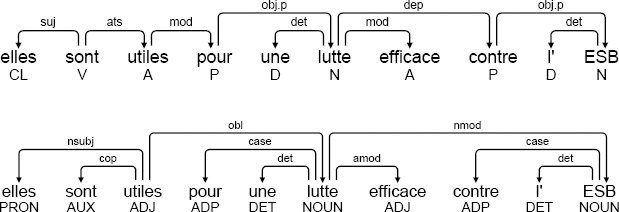
(3.7) elles sont utiles pour une lutte efficace contre l’ESB
they are useful for a struggle effective against ESB
’they are useful for an effective struggle against ESB’
For the example above, derived from sentence [Europar.550_00450] in the SEQUOIA corpus6, the annotation at the top is in SSQ format, while the annotation shown below is in UD format. In all of the examples below featuring annotations in both SSQ and UD, the SSQ annotation will be shown first. Here, in both cases, the constituent pour une lutte efficace is linked to the adjective utile as it is a complement to this adjective, independently of the function of the adjective in the sentence, head or otherwise.
In the second example below, however, the constituent malgré mon attachement is a sentential complement and needs to be linked to the head of the sentence. In SSQ format, the head is the copula, while in UD format, the head is the subject predicative complement.


(3.8) [annodis.er_00474]
J’ étais prêt à partir, malgré mon attachement …
I was ready to go, despite my attachment …
’I was ready to go, despite my attachment …’
These two examples show that, in SSQ, the dependencies of the head of the sentence, which are governed by the copula, are differentiated from those that are specific to the subject predicative complement; this distinction cannot be made in UD. This is a drawback if we consider this distinction to be important or an advantage if we consider it to be insignificant.
3.3.1.2. Heads of prepositional phrases and subordinate clauses
In SSQ, the head of a prepositional phrase is the preposition, which governs its object via a obj.p dependency. The reverse is true in UD: the object of the preposition is the head of the constituent. If this object forms a noun phrase, it governs the preposition via a case dependency or, if it is an infinitive or a participle, via a mark dependency.
Similarly, in SSQ, the head of a subordinate introduced by a conjunction is the conjunction and the conjunction governs its object via an obj.cpl dependency. In UD, the head of the subordinate is the object of the conjunction (generally the principal verb of the subordinate), and governs the subordination conjunction via a mark dependency. As in the case of copulas, the choice made in UD results in an ambiguity which is not present in SSQ. This difference between SSQ and UD is illustrated in the two examples below.
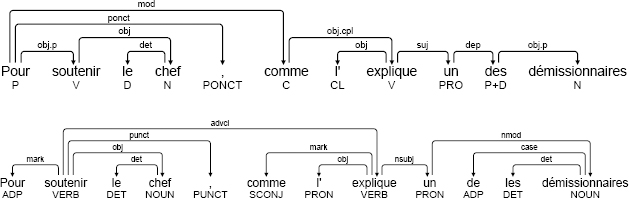
(3.9) [annodis.er_00474]
Pour soutenir "le chef", comme l’explique un des
To support "the leader", as explains one of the
démissionnaires …
resigners …
’To support "the leader", as one of the resigners explains …’
In the example above, the subordinate clause comme l’explique un des démissionnaires is linked to the head of the prepositional phrase Pour soutenir le chef. In SSQ annotation, the head of the prepositional phrase is the preposition Pour. This means that the clause modifies the whole prepositional phrase, not only the infinitive. In UD annotation, it is impossible to make this distinction, as the head of the prepositional phrase is the infinitive soutenir.
In the second example below, the fixed espression dans son ensemble is linked to conférence. In SSQ annotation, this means that dans son ensemble only modifies the nominal syntagm la conférence rather than the whole prepositional syntagm sur la conférence; in UD annotation, this is ambiguous.


(3.10) [Europar.550_00337]
Voici mon opinion sur la conférence dans son ensemble
Here is my opinion on the conference as a whole
’Here is my opinion on the conference as a whole’
3.3.1.3. Controlled complements and modifiers
SSQ makes a distinction between the prepositional complements of verbs, adjectives, or adverbs which are controlled by their governor and those which are modifiers. The former are expressed using a_obj, de_obj, p_obj.o or p_obj.agt dependencies. The latter are expressed using the mod dependency.
In UD format, a distinction is only made in cases where these complements are clauses. Clauses which are modifiers are associated with advcl dependencies, while those controlled by their governor are associated with xcomp or ccomp dependencies, depending on whether or not the subject of the complement clauses is controlled by the governor. Nominal complements, whether or not they are controlled or modifiers, are always expressed through obl dependencies. The example below illustrates the difference in representation between SSQ and UD.
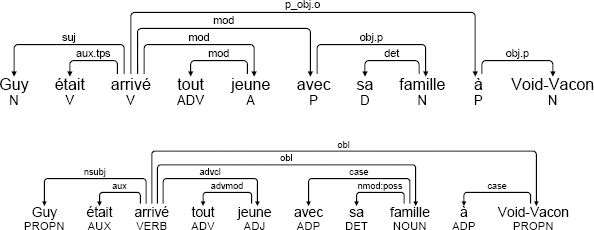
(3.11) [annodis.er_00072]
Guy était arrivé tout jeune avec sa famille à Void-Vacon
Guy arrived very young with his family at Void-Vacon
’Guy arrived with his family at Void-Vacon at a very young age’
In this example, the verb arrivé has three complements. The complement à Void-Vacon is controlled by the verb and this is marked by a p_obj.o dependency in SSQ annotation. The complement avec sa famille is a modifier and this difference from the previous complement is marked by the use of the mod dependency. In UD annotation, no distinction is made between the two complements and both are linked using the obl dependency.
The complement tout jeune, however, is an adjectival phrase. As in the case of clausal complements, UD format makes a distinction between modifiers, expressed using an advcl dependency, and required complements, expressed using xcomp or ccomp. In the example, tout jeune is considered to be a modifier.
3.3.1.4. Dissociation or non-dissociation of amalgams
The French prepositions (au, du, des, etc.) and amalgamated relative pronouns (auquel, desquels, etc.) are left as-is in SSQ format; in UD format, however, they are dissociated. The transformation from one format to the other does not raise any particular difficulties in this case, but the issue becomes complex when a multiword expression is also involved. This can be seen in the following example.
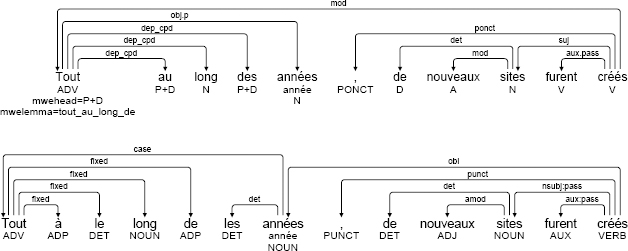
(3.12) [annodis.er_00072]
Tout au long des années, de nouveaux sites furent créés
Throughout the years, new sites were created
’Throughout the years, new sites were created’
This example features the prepositional locution tout au long de. Its structure is the same in SSQ and UD format: the word on the left, in this case the adverb Tout, is treated as the head, and all other components are linked to the head using the dep_cpd dependency in SSQ and the fixed dependency in UD.
The difference lies in the way in which amalgams are treated. The expression features two amalgamated prepositions: aux and des. Part of the second, which is broken down into de les, is therefore included in the prepositional locution; in SSQ, the whole amalgam is integrated into the expression. Another difference that adds complexity to the conversion process lies in the fact that, unlike UD, SSQ takes account of two features relating to the whole expression: MWEHEAD, which represents the part of discourse of the expression, and MWELEMMA, representing its lemma.
3.3.2. The SSQ to UD format conversion system
The SSQ_to_UD system is relatively simple and precise, insofar as it essentially consists of presenting existing information in a different manner, or of ignoring certain differences. The aim is to carry out the following tasks in a precise sequence:
- 1) words are reorganized within certain expressions, either with the aim of coming closer to UD format (proper nouns, productive prefixes), or to facilitate processing at a later stage (superlatives);
- 2) amalgamated prepositions and relative pronouns are dissociated;
- 3) grammatical categories and other features are translated from SSQ into UD format;
- 4) the category of multiword expressions, linked to their head as a MWEHEAD feature, is propagated as a CAT feature of the head; this then allows multiword expressions to be treated as individual words;
- 5) coordinations and enumerations are translated from SSQ into UD format; coordinations with ellipses require a specific treatment;
- 6) the mode of composed verbs, indicated by the VERBFORM feature in UD, is propagated from the auxiliary to the principal verb, allowing mode-dependent syntactic dependencies to be treated in a uniform manner for both simple and composed verbs; the initial form of a composed verb is expressed via a INITVERBFORM feature;
- 7) the labels of dependencies between verbs and auxiliaries and between verbs and affixes are translated into UD format;
- 8) the heads of certain syntactic constructions are changed: this applies to prepositional phrases, subordinate clauses introduced by a conjunction, expressions of the form (quantity adverb + preposition de + common noun) and expressions in foreign languages;
- 9) the labels of dependencies are translated from SSQ to UD format without changing their source or target;
- 10) in copula – subject predicative complement couples, the copula is adopted as the head;
- 11) finally, certain phonological forms (euphonisms, grammatical expressions, etc.) must be modified in order to comply with UD format, and certain intermediary features that were only relevant for the conversion process need to be deleted.
This series of 11 tasks is applied in the same way as a sequential composition of 11 strategies. These strategies themselves are a sequential composition of packages. The system includes 28 packages, used without repetition in composing strategies. They include 226 rules, only 20 of which are lexical rules. These rules are all essentially focused on solving the substantive differences between the two formats, as described in the previous section. In most cases, the execution is deterministic; this is unsurprising, as the conversion involves "forgetting" a certain amount of information. Any structural changes are entirely deterministic.
3.3.3. The UD to SSQ format conversion system
The UD_to_SSQ system is less precise than its opposite counterpart, as certain information not provided in the input annotation must be obtained from lexicons. In this process, both ambiguity and the limited scope of lexicons can prove problematic, meaning that conversion in this direction is less precise. The system carries out the following tasks:
- 1) categories and other word features are translated from UD to SSQ format;
- 2) the part of speech of each multiword expression is computed using the type of dependency targeting the head, and is stored in the MWEHEAD feature; in parallel, as the expression is considered as a single unit in later transformations, the category and part of speech of the head word are replaced by the category and part of speech of the expression as a whole, although they are retained in the INITCAT and INITPOS features;
- 3) in copula – subject predicative complement couples, the copula is adopted as the head, and dependencies in which the subject predicative complement features are transferred on a case-by-case basis to the copula, raising all of the difficulties mentioned above;
- 4) the mode of composed verbs is transferred from the auxiliary to the principal verb, which then makes it possible to process syntactic dependencies involving complex verbs. The mode features in the same way as for simple verbs. The initial mode of the principal verb is retained using an INITM feature;
- 5) for prepositional phrases and subordinate clauses introduced by a conjunction, the preposition and the conjunction respectively are adopted as the head, implying the transfer of certain associated dependencies;
- 6) coordinations are translated from UD to SSQ format, then those which prove to be enumerations are translated into SSQ enumerations;
- 7) UD dependency labels are replaced by SSQ labels; as we have seen, for verb complements and adjectives, lexicons must be used to determine which label is required;
- 8) constructions of the form (quantity adverb + preposition de + common noun) are translated from UD to SSQ format;
- 9) preposition and pronoun amalgams are created;
- 10) the lemmas of multiword expressions are computed and saved in the form of a MWELEMMA feature;
- 11) finally, all intermediary features that were only relevant for the conversion process are deleted.
The UD_to_SSQ system uses 226 rules to carry out these 11 tasks: exactly the same number found in the SSQ_to_UD system. However, 55 of these rules make use of a lexicon, compared to 20 in the case of the former system. These 226 rules are grouped into 22 packages. This sequence of 11 tasks is applied as a sequential composition of 11 strategies, each of which is a sequential composition of packages, with no repetition.
Compared to the SSQ_to_UD conversion system, this system offers more freedom in terms of the order in which the 11 tasks are applied, due to a certain level of redundancy in the annotation. In many cases, the category of the source and target of a dependency can be deduced from the dependency label. This does not mean that an order should not be established in advance: first, the form of the rules is dependent on their order, and second, in certain cases, some orders may be better than others.