Source code versioning is a very important part of development. If the code is not versioned, then it might as well not exist. There are many tools available for source code versioning, but these days, Git and Apache Subversion are the most popular ones. It is always good to have one repository for each application and then create multiple branches for development. With respect to Git, when we create a repository, there is already a master branch. The master holds the golden copy of the code, which is usually used as a benchmark and can also be used as a production copy. We can also create many other branches for the feature, release, and development versions of the code for efficient development and deployment.
So the best practices concerning the source code management is to commit often and also make sure that you raise the pull request every time you start your day. This allows us to avoid wasting time on merging the code and also prevents us from breaking the build. Usually, we have a huge team of developers in various parts of the globe building different modules for the application. If we forgot to commit one day, then the next morning we would have to waste lots of time merging our code before we actually started development. We should also make sure that we always inspect before we commit, because otherwise we might commit a whole bunch of junk, unwanted libraries, or JAR or debug files into the repository, which will clog the repository, as well as make our function bigger, eventually degrading the performance.
We should also make sure that we add the commit message while we commit the code. The comment should explain why we committed the code because this will help us to easily trace whether something failed, and also makes it easier for us to roll back if we committed buggy code, or if some functionality changes. When we add the commit message, we should make sure that it is not too generic or lacking in information. We should also ensure that it is fixed, that it works, and that it has no typos, because this won't help us to trace it back if we have introduced a bug or an issue. In addition, it is not good practice to have the same commit message appear after a previous commit, as we usually commit because something has changed in the code compared to the previous commit.
We should avoid committing a build artifact or compiled dependencies like .dll or .jar into the source control as this could well irritate your coworkers, as they will have to check out a huge list of files or have his on local environment corrupted by downloading these dependencies. Another way to avoid commit issues would be to write precommit hooks, which can mitigate most of the commit issues.
We have talked about versioning, but we should also talk about the version database component. Like the UI, application, and testing code, the database component should be versioned for stable deployment and application. If we don't version the database, then we might run the application with old data or an old configuration. It is also easier to track what DDL and DML statement were used in a particular release version.
So, in short, we should always remember to commit regularly, know what are we committing, add a valid commit message, and ensure that sure we do it ourselves.
AWS also supports the versioning of the functions. The Lambda function is versioned through publishing. One of the AWS Lambda consoles is specifically dedicated to publishing the new version of the Lambda function, and we can create multiple versions of the same function. Each Lambda function version is provided with a unique ARN, and becomes immutable postpublishing. Lambda also allows us to create aliases (as shown in the following screenshot), which are pointers to specific Lambda function versions. Each alias will have a unique ARN and can only point to one function version, and not to another alias:
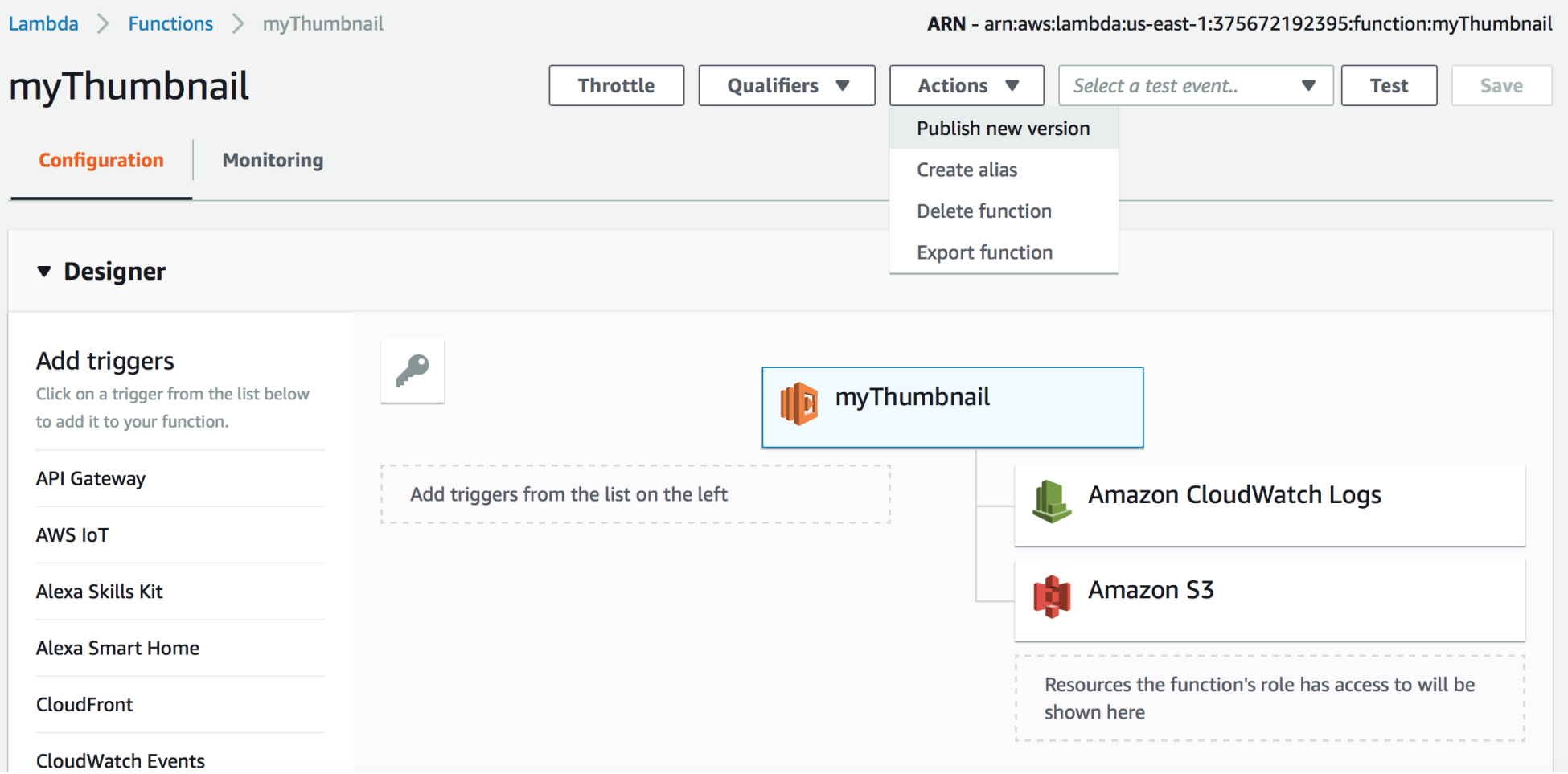
Let's look at an example of AWS Lambda versioning. Say that we have an AWS S3 bucket that is an event source for a Lambda function, so whenever any new item is added to the bucket, the Lambda function is triggered and executed. The event source mapping information is stored in the bucket notification configuration, and in that configuration, we can identify the Lambda function ARN that S3 can invoke. But the newly published version is not automatically updated, so we have to make sure that this is updated every time a new version of the function is created.
If we are using the Serverless Framework, the new version is created through the deployment. There is also the provision to roll back to a previous version through the following command line:
$ serverless rollback function -f my-function -v 23