CHAPTER 7
From Testers to Quality Engineers
Good testers are people who look both ways before crossing a one-way street.
—Common testing saying
In the last chapter, I talked about the organizational structure of your IT transformation, and my “burger chart” of an appropriate organizational structure (Figure 6.1) had aspects of testing included. Why do I spend another separate chapter on testing? In my experience, the organizational change associated with testing is by far the most significant and the one that organizations struggle with the most. The change journey for people in testing roles is even greater—a role that used to be focused on execution of test scripts but has evolved into either a very technical test engineer role or into business experts who evaluate risks and then design a test strategy around them. Every day, I see clients who still prefer separate test organizations focusing on traditional manual testing (which is often highly dysfunctional and optimized for cost instead of speed or risk) and would like us to help build these. More often than not, I see failed or suboptimal test automation initiatives by clients who are driven by those test organizations and test managers. The change from traditional testing to quality engineering will require a mind-set shift in the people who work in testing. Not everyone will be able to make that transition. While this chapter focuses on the organizational dimension, I will expand on technical topics as required to illustrate the point.
The Quality Organization
Quality is such an important aspect that is reflected in all parts of the organization. At the top of Figure 6.1, in the governance layer, the standards and principles are defined that play a large role to ensure quality. You will also need to look at the day-to-day quality as shown in the actual software you deliver, which should be part of your governance. This means your measures of quality and the outputs from retrospectives and reviews need to be discussed to identify where the overall quality process can be improved and where standards need to be adjusted.
Initially, the test automation team is required to set up the test automation framework and to work with the platform team to build the right integrations that allow for targeted automation runs (e.g., just functionality that was impacted). This team’s primary job is to enable all the test engineers to leverage the test automation framework successfully; hence, a lot of coaching and pair programming is required to help make the quality engineers familiar with the framework. The team also needs to provide guardrails so that the overall test automation is not failing in the long run. Those guardrails ensure that test execution does not take too long or require too many resources, for example—both common problems of test automation frameworks that grow over time. Guardrails can be coding standards, common libraries, regular peer reviews, or other technical documentation and governance processes. In the early days, this will be pretty intense, especially as the test automation framework evolves to support all the data flows. Later on, this team can reduce in size when the test engineers become familiar with the framework and don’t require as much support. While my clients tend to make the test automation team a permanent fixture, I can imagine this function disappearing completely as a separate team and just being picked up by the more experienced test engineers.
We spoke about the platform team before. Just to recap, this team will integrate the scripts so that the overall pipeline enforces good behavior and makes the results visible. The platform team also works with the test engineers to agree on standards that will make sure the scripts work on the platform (e.g., for environment variables).
And then, of course, the test engineers in the delivery teams have ownership of the test automation scripts and make sure all functional areas are covered. They work with all other teams, as they are end-to-end accountable for the quality of the service.
The Quality Engineering Process
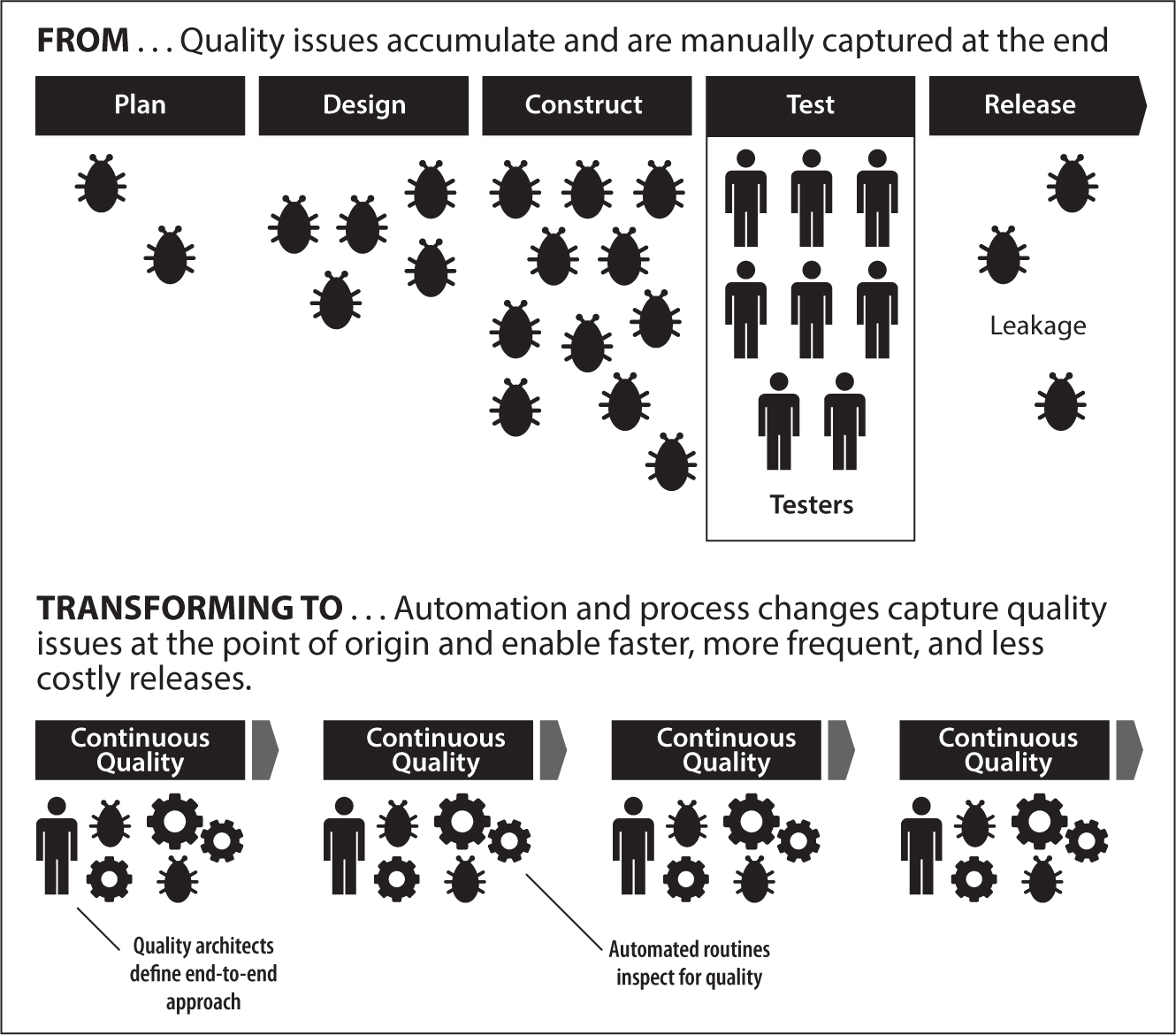
Let’s look at a common misconception: test automation is just the automation of tests you would otherwise run manually. This is not true. This is probably the number-one reason why test automation initiatives fail: they try to automate the kind of testing that they have traditionally done manually. In rare cases this might work, but more often, this approach will fail. I like the term “quality engineering” a lot more than test automation because it avoids the term “test,” which many associate with the last-ditch effort to find all the bugs at the end of the SDLC. Quality engineering speaks to the end-to-end aspect of automation to ensure a quality product at the end. This means that the person or team responsible for quality engineering needs to look at the full life cycle and not just the testing phase—a shift that is quite challenging. Test automation (e.g., the automated execution of test scripts) is an activity within quality engineering.
The traditional testing center of excellence was set up as an antagonist to the delivery team, who controls the quality of delivery by mass inspection. This created dysfunction, as a lot of opportunities for quality improvements were missed, and often, the teams would argue about who was accountable for the product’s lack of quality (the testers for not finding the problems or the developers for creating them). It’s quite easy to put yourself in the shoes of the developers and say, “It’s okay if there is a problem; it’s the testers’ job to find them.” On the flip side, a tester could say, “I should be able to take it easy, as a good developer would not create defects in the first place.” You want to break this dynamic by making quality a common goal. Deming said that “quality comes not from inspection but from improvement of the production process.”1 This means that testers who take this to heart will start playing a more involved role in the delivery process, not as antagonist but, rather, as a member of the team.
Another thing that has gone wrong is the way we measure quality—many organizations use defects or defect density as a measure. Measuring increased quality through the number of defects does not give any good indication of overall quality.* You agree, I hope, that we need better ways to improve quality, so let’s discuss what can be done meaningfully and how we will measure this.
Figure 7.1: Quality engineering process: Quality engineering shifts the focus to the whole delivery lifecycle
Quality engineering is leveraging the idea that you should build quality in whatever you do and look for ways to do more testing without additional cost (in both money and time). Frameworks like SAFe and disciplined Agile delivery (DAD) have made this one of their principles. What does this mean in practice, though? Let’s break down the process into five phases:
Requirements, Design, and Architecture
Quality starts at the beginning, so we should have a quality approach for the early phases of the project or in Agile projects for the ongoing elaboration of scope. There are a few obvious things we can do here. Many projects suffer from poorly written requirements / user stories and short-term architectures. But this can be mitigated. There are obviously certain aspects here that are business specific and that require experts to be involved, but other things can be supported by a good tooling platform.
Accenture uses a tool that analyzes requirements and user stories, and identifies unclear language. Sentences that are ambiguous get highlighted: for example, “The response time should be fast,” “The screen needs to be easy to navigate,” or “We need to support several different payment types.” You can see how you can quite easily create a tool for yourself or look for some open source solutions that let your tooling platform learn what unclear language is. With the introduction of more and more artificial intelligence into the IT life cycle, you might soon see products that go beyond key-word recognition.
On the architecture side, there is a qualitative aspect that your architects need to be involved with. They should make sure that each initiative is leaving your architecture in a better place than it was found. Decoupling of systems and modules needs to be one of the core aspects they encourage. As discussed before, there is no end-state architecture anymore that architects need to define and try to enforce; they just need to help make the architecture fluid and flexible for the future so that continuous evolution is possible and gets easier over time, not harder.
Traditional approaches accrued technical debt in the architecture, and changes became increasingly expensive. Hence, the performance of your architects should be evaluated on how flexible the architecture is becoming. For example, how do the architects make sure your architecture is future proof? There are some aspects of architecture that you can measure, and I encourage you to find these measures so that you have something to help drive the right behavior: number of database access requests, data volume transferred over interfaces, stateless calls versus stateful calls, number of calls to external systems, response and CPU times. As trends over time, these give you interesting and useful information about the maturity of your architecture.
An important part of architecture governance is having a set of clearly defined architecture principles. Everyone in your organization should know what architecture means in your context. You don’t have to go as far as Amazon (where an anecdote says that Jeff Bezos made it a mandate to use service orientation at the threat of being fired otherwise),2 but having an opinionated view for your organization is important to align all the moving parts. As you can see, we are trying to create collaboration and accountability across the whole life cycle of delivery; we are breaking the functional silos, not by restructuring but by overlapping accountabilities.
Coding
The quality aspects of coding are usually undervalued. I have talked to many organizations, and very few know or care about what quality measures are taken in the coding phase, instead relying on the testing phase. When working with system integrators, there is often disagreement on the quality measures during coding. But there are a few things that should be mandatory: static code analysis, automated unit-testing, and peer reviews. You should have an automated unit-testing framework that is being used to test modules directly by the developer in an automated fashion. They are available for many technologies, like jUnit for Java or nUnit for .NET—there is really no excuse for not using this and letting your developers get away with some level of manual testing. Additionally, static code analysis is quite easy to implement, even for technologies like COTS packages. Your coding standards can, to a large degree, be codified and enforced through this.
The manual peer review of code that many organizations use (although often in a terribly inefficient way) should only happen after the automated static code analysis and unit tests have been run. You don’t want to waste expensive and time-consuming manual effort on things that automation can address for you. Peer reviews should focus on architectural and conceptual aspects of the code, as well as fit-for-purpose (e.g., does this piece of code solve the problem?).
I have been in organizations that have, over time, added to their peer-review checklist new items whenever a problem was found. This meant the checklist had over 150 items at some stage. Guess what? No one was actually following that checklist anymore because it was too long, and too much was irrelevant on a day-by-day basis. Create a simple and short checklist as a guide, and teach people what to look for by pairing them up with experienced developers during the peer-review process.
You can also get a group of developers together on a regular basis to peer review some selected changes as a group, so that they can learn from each other and align on the coding style in the team. And make code review easy by supporting it with proper tooling that shows the actual changed lines of code and reason for the change. Don’t make the peer-review process cumbersome by asking the reviewer to find the changes in the code herself and fill in Excel sheets for feedback. That does not help anyone. Get her to provide feedback directly, in context of the user story and in the same work management system that everyone uses.
Agile Testing
It does not matter whether you formally use an Agile method or not; the best way to do functional testing is to have the testers and developers sit together. The test engineers should be writing the test automation code in parallel with the developers writing the functional code. When the two functions work together, it is much easier to write testable code that can be automated. This is one of the critical aspects to make test automation successful and affordable.
If you have a test automation team that owns the framework, the test engineers will leverage this during development, providing feedback to the framework team. Additionally, the test engineers will work with the tooling platform team to integrate the right test scripts, so that during the automated build and deploy process, only the required scripts are executed. We are aiming for fast feedback here, not for full coverage. We can do a full run off-cycle on a weekend or overnight.
During development, we also want to check for performance and security concerns. While this might not be exactly the same as in production or preproduction environments due to environment constraints, we are happy to accept the fast feedback we get as indication. We actually prefer speed over accuracy. If we can find defects 70% of the time earlier in the life cycle and find the other 30% in the later phases, where we would normally find them, then that is actually fine. Remember: we are automating all aspects of quality checks, so we can run them a lot more frequently. From a performance perspective, we might not have accurate performance results; but if an action is becoming slower over time, we know we have something to look at that indicates a possible problem later on.
This fast feedback allows the developer to try different approaches to tune performance while he still has the context instead of weeks later, when the final performance testing fails and the developer has built a whole solution on top of his first design idea. The same is true for security testing: take the early feedback wherever you can get it.
Hardening
As much as I wish that all testing could be done within the Agile team, it is often not possible due to a number of factors. We therefore introduce a hardening phase to run tests involving external systems, time-consuming batch runs, and security testing by a third party. This hardening happens right before going to production. I personally think that you want to do some testing with the business users in a user-acceptance testing activity as well, which cannot be automated. You don’t want your business stakeholder to test based on the test cases already performed but for usability and fit-for-purpose.
Running in Production
I won’t spend much time here, as I will talk about keeping a system running in a later chapter, but it should be clear that certain quality assurance activities should happen for the service in production. You want to monitor your servers and services, but you also want to look for performance, availability, and functional accuracy concerns in production. All of this should still be part of the overall quality plan.
A Few Words on Functional Test Automation
As I said before, test automation is the one DevOps-related activity that tends to challenge organizations, requiring a real mind-set shift in the people involved. However, I have seen a few common failure patterns that I want to share with you so that you can avoid repeating them in your organization.
Don’t Underestimate the Impact on Infrastructure and the Ecosystem
There is a physical limit to how much pressure a number of manual testers can put on your systems; automation puts very different stress on your system. What you otherwise do once a week manually you might now do a hundred times a day with automation. Add into the mix an integrated environment, and your external systems need to respond more frequently too. So, you really have to consider two different aspects: Can your infrastructure in your environments support a hundred times the volume it currently supports? And are your external systems set up to support this volume? Of course, you can always choose to reduce the stress on external systems by limiting the real-time interactions and stub out a certain percentage of transactions, or you can use virtual services.
Don’t Underestimate the Data Hunger
Very often, automated test scripts are used in the same environment where manual testing takes place. Test automation is data hungry, as it needs data for each run of test execution; and remember, this is happening much more frequently than the manual testing does. Therefore, you cannot easily refresh all test data whenever you want to run your automated scripts, as manual testing might still be in progress; you will have to wait until manual testing reaches a logical refresh point. This obviously is not good enough for multiple reasons; instead, you need to be able to run your test automation at any time. Fortunately, there are a few different strategies you can use to remedy the situation (and you will likely use a combination):
Consider the Whole System, Not One Application
Test automation is often an orchestration exercise, as the overall business process in testing flows across many different applications. If you require manual steps in multiple systems, then your automation will depend on orchestrating all of those. By just building automation for one system, you might get stuck if your test automation solution is not able to be orchestrated across different solutions. Also, some walled-garden test automation tools might not play well together, so think about your overall system of applications and the business processes first before heavily investing in one specific solution for one application.
Not Following the Test Automation Pyramid
Automating testing should follow the test automation pyramid (Figure 7.2). Most tests should be fast-executing unit tests at component level. The heavy lifting is done in the service or functional layer, where we test through APIs and only a few tests are run through the user interface (UI). When considering manual testing, you usually need to work through the UI. Many test automation approaches try to emulate this by automating the same test cases through the UI. The reality is that the UI is slow and brittle. You want to refactor your testing approach to leverage the service layer instead; otherwise, you will pay for it by increasing amounts of rework of your automated test scripts.
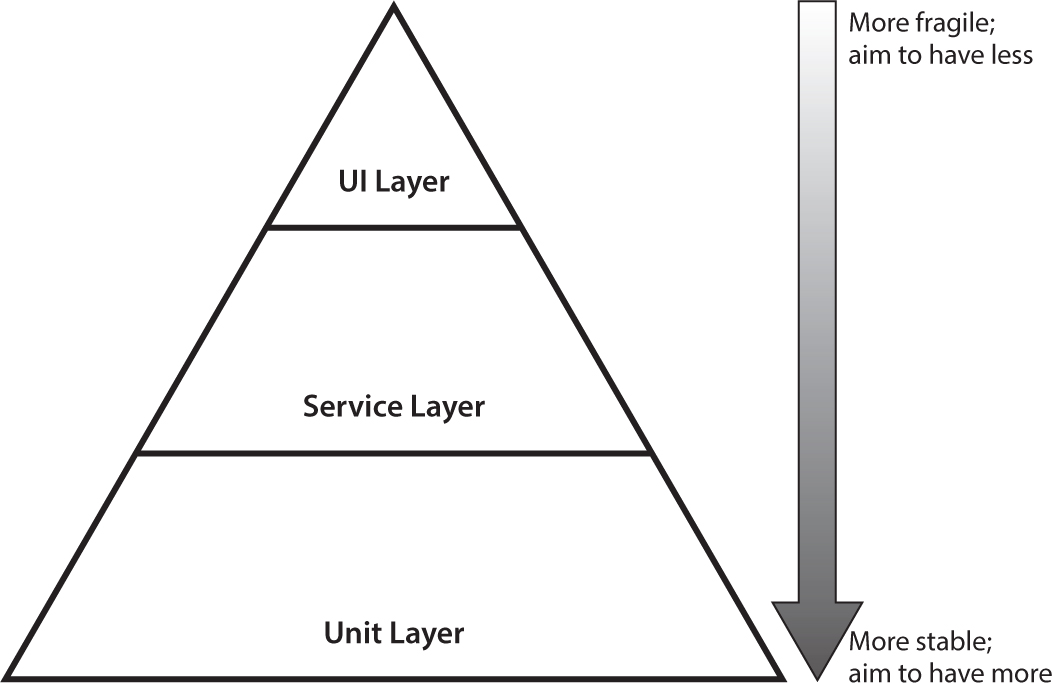
Figure 7.2: Test automation pyramid: The slower the layer, the less we should use it in automating tests
Test automation for legacy applications is a tricky business. You have so much functionality to cover, and it tends to not be economical to do that as a big bang. My advice is to start with a small set of regression tests for your legacy applications so that you can ensure the quality of the application for the higher-priority functionality. Then use changes to the application or areas for which you perform refactoring to build additional test cases. In the case of new functionality being built, get the set of new test cases built with the code changes. In the cases of refactoring, build the test case first, make sure it works and passes with the current application, and then, after refactoring, it should still work.†
Quality Management and Measurements
As I said earlier in this chapter, you will have to find overall measures for quality outcome and quality process. Measure how well your process is working to identify quality concerns automatically, and measure how fast and accurate it is. One thing that makes people stumble is when the automation is not well maintained; these process measures will help you keep that in control. Look for measures such as the duration of your regression run and the false positives coming from your test automation. The quality outcome measure should really be based on production incidents and perhaps defects found in the hardening phase. Don’t measure defects the delivery team finds itself, as the team is meant to find as many problems as possible. Documenting and measuring defects that the delivery team is finding themselves is of little benefit; let the team focus on finding and addressing them. Only when defects escape the delivery team into later phases do you need documentation to manage the handover between teams.
A helpful way to embed this into your teams is by using differentiated terminology to distinguish the phase the problem has been found in. I like to use bug, defect, and incident. A bug is something the Agile team finds that prevents the story from being accepted by the product owner. In this case, there is no formal documentation; rather, the tester provides as much information as possible to the developer to fix the bug. Once the bug has been fixed, the story gets tested again, and the process repeats until the product owner can accept the story. We don’t measure bugs in any formal way. Once another team gets involved, like the hardening team, then we call problems defects and manage them with a defect life cycle, and we can measure how many defects “escape” from the Agile team. These defects can be used to analyse what limitations prevent the Agile team from finding them themselves and helps them to design countermeasures. In production, we call problems with the code incidents, and those are the quality concerns that we absolutely want to measure, as they impact our customers. Incidents are the ultimate quality measure of our product or service.
Then there are the production run metrics like uptime and functional availability, but we will cover this in the chapter about application management (chapter 11).
First Steps for Your Organization
Mapping the Quality Process of Your Organization
This activity is somewhat similar to the value mapping we did in chapter 1. Here again, you should prepare a whiteboard or other wall space, and be ready with Blu Tack and system cards.
First, create a high-level work flow on the wall, showing requirements to production, including all the relevant process steps represented on the cards. Then use a different color of cards or pen and list each quality activity where it happens in the life cycle.
To make sure the picture is complete, ask yourself whether you have covered all concerns, including performance, security, availability, and any other concerns. It’s okay if you have some aspects missing from the original list; simply highlight these on the side.
As a next step, your team needs to think about automation: What can be automated and hence be done earlier and more frequently? Consider breaking up activities into an automated part that can be completed earlier and more frequently, as well as a part that continues to require a manual inspection. Remember that automated activities are nearly free of effort once implemented, so doing them more often does not add much cost.
Now, you want to identify opportunities to check for quality aspects earlier, as this relates to manual inspection. For each activity think of possible ways to do the full scope or at least aspects of it earlier.
Finally, create a backlog in which your teams can make the required shifts toward quality engineering, and then start making the shift.
Measuring Quality
As discussed in this chapter, measuring quality is not easy. Many measures are only valid temporarily, while you are addressing specific concerns. Sit down with your quality or testing leadership and, on a piece of paper, list out at all the metrics and measures you use to determine quality. Then determine which ones are objective and automated.
If you don’t have a good set of automated and objective metrics, then workshop how to get to a small set of these. I think two of the easy ones to agree on are duration for a successful regression test run and incidents found in production per time period. These are pretty noncontroversial and applicable to all kinds of companies, but you will want to define a small number of additional metrics relevant to your business.
* I am very skeptical of number of defects as a quality metric. I was talking to a company in the United States who had gone through an IT improvement program because they had so many defects in their SDLC. After they told the IT department that number of defects is the key metric, the number of defects quickly reduced. When the number of defects reached a low point, the organization considered ramping down the testing function as quality was not a concern anymore. Yet before they could finalize such a decision, the number of defects started increasing again. The transformation lead called both the delivery team lead and the testing lead into his office and asked for an explanation of this pattern. The answer was obvious in hindsight: when defect was the key metric for development, the development team worked very closely with the testing team to make sure that functionality was “pretested” before the formal test, and any concerns were quickly rectified. They even introduced a new ticket type in their defect tracking system called “predefect query.” Once the testing department heard rumors that they would be downsized because of the increased quality level, they started to raise more defects and fewer “predefect queries.” The IT transformation lead told me that at this point, he realized the inherent quality in the delivery process itself had not changed at all during his program and that all the change was in the support process.
† At the DevOps Enterprise Forum in 2015, a group created some guidance about test automation for legacy application. The paper, Tactics for Implementing Test Automation for Legacy Code, is worth reading if you want to learn more.3