CHAPTER 12
The Cloud
Jay: It went up! It went up to the cloud!
Annie: And you can’t get it down from the cloud?
Jay: Nobody understands the cloud! It’s a f***ing mystery!
—Sex Tape (movie)
Unfortunately for many organizations, the cloud is still somewhat mysterious—not the concept of the cloud but why they are not seeing the benefits that were promised to them. In this chapter, I want to help demystify this aspect and discuss some of the challenges I see with cloud migration and what it takes for your organization to really benefit from leveraging the cloud. The focus in this chapter is on adopting cloud-based infrastructure and managing it. We already discussed the considerations for software as a service in chapter 3 and application architecture in chapter 10. Together, these give you good coverage of the different aspects of leveraging cloud-based services.
While we will discuss cost benefits primarily in this chapter, one should not forget the other benefits and risks of the cloud. Examples of additional benefits: the ease of setting up redundancy for resilience, the scalability of resources, and the strong ecosystem of related services that you would otherwise have to build yourself. On the risk side: the dependency on a third-party provider, the challenges with data sovereignty, and the risk of being attacked because you are on a popular platform.
Basic Principles of Cloud Economics
Before I discuss some of the considerations for cloud migration, it is probably helpful for us to level set on the economic model of the cloud. If you look at a straight comparison of cloud services and on-premises solutions, then at the very basic level, the cloud solution is going to be more expensive (e.g., having one fully utilized server on premises is cheaper than having one fully utilized service in the cloud). Some people have done modeling for this, and you can find a few models on the internet. It is inherently difficult to do the comparison, though, as the supporting costs from the ecosystem are hard to calculate. From my experience with my clients, I can tell you that migrating applications straight to the cloud often does not provide the expected significant savings unless you invest in some refactoring or re-architecting.
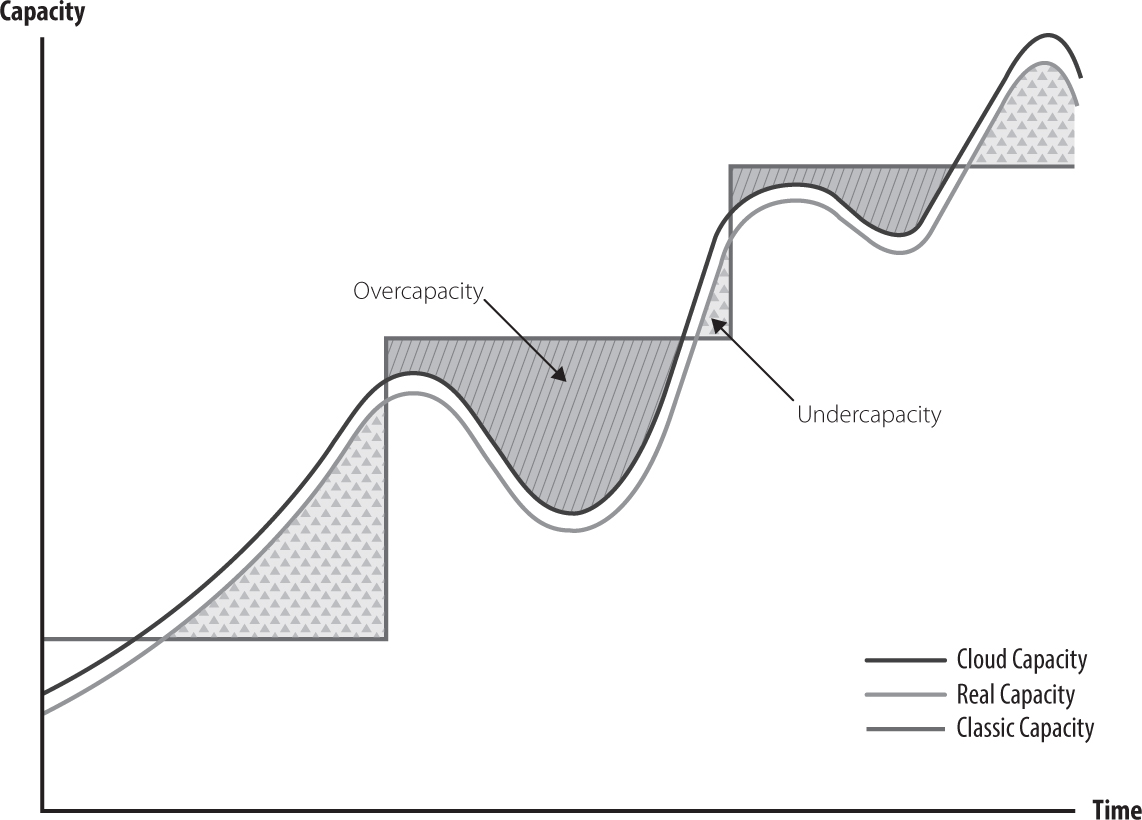
The economics of the cloud are based on the sharing of resources, so that everyone only pays for what they consume, and any excess capacity can be used by others. On the flip side, this means that services with high variability will benefit more from the cloud model. The benefit of this depends on how quickly the service can respond to a change in demand (see Figure 12.1).
Figure 12.1: Capacity versus time: When done correctly, cloud capacity moves according to the need
It is important to understand this basic model of fluid capacity that responds to the need of the application when considering an adoption of the cloud and the impact your architecture will have on the benefits of the cloud.
Cloud Architecture Considerations
If you think through the considerations above, you realize that a monolithic application provides a lot less opportunity to respond with the same level of variability. If any part of the application is running out of capacity, the whole application needs to be replicated; hence a new instance needs to be created. Imagine you have several business channels, and only one of them is popular on the weekend (e.g., your internet channel). In that case, you only want to scale this business channel while the other ones run at minimum capacity during that same time. If everything is in one monolith, you will have to run your whole business at the same capacity and pay a lot more.
But if the architecture allows for separate services to be scaled independently (similar to how we described this for microservices in the architecture chapter), then the scaling becomes a lot more granular and therefore useful to optimize for cost. This is the major benefit of the cloud.
However, the more you break down the architecture to benefit from the above consideration, the more moving pieces you have to deal with. With more moving pieces, your ability to manage multiple versions needs to improve. Rather than managing twenty applications, you might have to manage 150 services, each with their own versioning. It is nearly impossible to deal with that unless you have a large level of automation in place—all the automation capabilities of the cloud-enabled delivery model.
The other challenge with so many moving parts is that it is very likely that things will fail. Actually, we are safe to assume that something will fail, so how can we reduce the points of failure in our architecture? The architecture concept for you to consider here is called graceful degradation. Think of a shopping site such as Amazon that provides you with personalized recommendations based on your previous purchases. If that service does not work for some reason, rather than not showing you the site or delaying the response for your request, Amazon might choose to show you some static recommendation. For you as a user, the experience is slightly worse (although many people wouldn’t notice), but it is still much better than getting a page error or time-out. Leveraging this idea of graceful degradation works in many contexts but not all, and it will usually be a cheaper alternative to keeping the whole end-to-end availability at very high availability.
Cloud-based architecture often involves using packages or templates (like Docker templates) from cloud repositories, which is great from a reuse perspective. But doing this does not mean you don’t have to manage those dependencies. For example, a very small package nearly caused major internet outages in 2016 when a developer named Azer Koçulu took a package off the internet that was reused in many other systems and subsequently broke those systems unintentionally.1 Another risk is that those templates you use contain vulnerabilities that you are not aware of. Josh Corman spoke about this at the 2015 DevOps Enterprise Summit using some research he had done to see how many open-source or third-party components are in Docker templates (many are unknown, similar to the example of the small package earlier). He found that over 20% of Docker templates had known vulnerabilities. This exposes you to a lot of risks.2 So, both unavailability (or version change) as well as known vulnerabilities (that are hidden in your templates) are things you need to actively manage for your application.
One of my clients decided on a very conservative strategy to create an internal repository of every component they leverage. With that in mind, they download and store a copy from the public cloud for every version they use and actively manage these versions. For them, new versions are not automatically used, and they need to spend the effort to monitor for new versions and then choose to pull them in. But it means they can prevent unavailability and version conflict, and they have the direct ability to scan for known vulnerabilities. This might not be a strategy for everyone due to the cost, but you can dial the risk up and down by choosing how actively you manage this part of your cloud architecture.
Cloud Governance
All the flexibility that the cloud provides is fantastic. The typical bottleneck of projects (due to a lack of environments) all but disappears, and delivery capacity is freed up. But with all this flexibility come a few new problems. In the past, adding more cost to your infrastructure bill required detailed planning, and there was a high level of scrutiny. But now with the cloud, any developer with a company credit card can buy cloud services. One client I worked with opened public cloud infrastructure to their developers, and in the first month, the environment budget for the first half year was consumed. As you can imagine, that was a lesson for the organization.
At the same time, if instead of the lengthy procurement process of infrastructure you now have a lengthy approval process for cloud infrastructure, then you have not gained a lot with your transition. The trick is to find the right balance. You will have to find a new governance model that considers both cost and speed so that teams can make the right decision when provisioning environments.
Logical environment management remains a function required when you work with the cloud. In an on-premises model, the environment-management function manages who can use an environment at which point, and which configuration is being used in that environment at each point in time. With the cloud, you also want to make sure that certain standards of your organization are being followed and that templates are being provided for this. Additionally, you want to make sure that you have a strategy for how the individual environments are being used and where the applications are coming together to be tested against each other. After all, you want to make sure that the configuration of the applications that will be in production together gets tested somewhere. The proliferation of environments and associated application configurations can make that a real challenge unless someone keeps control over that.
Organizations can get around some of these aspects by leveraging a cloud-management system or broker system that allows you to reflect your organizational context within the management console. Such a system also makes sure that security standards are being followed, that only approved templates are being provisioned, and that budget constraints are considered. Ideally, such a system would also be able to identify the cheapest public cloud provider and provision the environment with that provider; but as of writing this book, the reality is that the ability to move between providers is a lot less realistic than one would hope. Each cloud provider offers idiosyncratic services that supply additional benefits but also create a level of lock-in. The management functions of such a broker system, however, are a significant benefit. Cloud is beneficial when you have more moving parts; with more moving parts comes the need for better governance. Ask yourself how good your environments’ management is at the moment and how many environments you have. Now consider yourself with a cloud architecture in which you have ten or a hundred times more environments. Would your current environment-management approach still work?
Site Reliability Engineering
When working with the cloud, the traditional operations idea also needs to be overhauled. The term that is most commonly associated with this change is site reliability engineering (SRE), which Google made popular.
Given that a cloud-based architecture works on many smaller components, which all operate with redundancy, it is very unlikely that you will suffer a complete outage (although you will if your cloud provider has a full outage). What this means in return is that instead of the traditional availability-measure time period:
(which made sense when you monitored a small number of components), you should move toward service availability (e.g., can a certain service be provided with the specific performance and quality):
To manage the results of this availability measure, the concept of error budgets is commonly used. The idea is that each service has a certain budget of times when the service does not work, either because of a planned activity (such as an upgrade or deployment) or due to a problem. With this budget set, the teams can, to some degree, choose how to use it (e.g., if they are sure a deployment will only consume 5% of that budget but it goes wrong and consumes 25%, then there will be less budget for other activities). This incentivizes the teams to find lower-impact solutions to upgrades and deployments and better ways to keep the service available over time. It is also frequently used in DevOps circles to align the incentives of the Dev and Ops teams by having this common budget of unavailability across both functions. Cloud-based solutions are often developed by both teams to minimize the impact on the budget.
A related measure that helps you to consume less error budget and is often called the key metric for DevOps is mean time to recovery (MTTR). This is the time it takes for service to become available again after a failure has been detected. Combined with mean time to discovery (MTTD), which is the time it takes from the time the service fails to the time the problem has been identified, these two metrics drive your unplanned unavailability. In your DevOps or SRE scorecard, you want these two metrics—together with the availability metric—to be really visible for everyone so that you can measure improvements over time.
Monitoring in an SRE model (and really, not only then) should fall into three categories:
Site reliability engineering has formalized the usage of the scientific method as part of the continuous improvement activities. So, for every improvement, you should predict what kind of impact it will have, measure the baseline, and after the implementation, check whether the improvement has really helped. As I mentioned earlier in the transformation governance chapter, this rigor is important to drive improvements.
It is, however, important that the pursuit of improvements includes your team and is not some kind of punishment for not having done it before. The term blameless postmortem has been coined to symbolize the shift from root-cause analysis, where the organization tries to find out which team or person caused the problem, to a forward-looking culture in which a problem is used to identify a way to improve the system and make it harder for people to make the same mistake again. As I mentioned in chapter 8, Etsy is on record for having each of their new IT employees deploy into production. You might think this is risky, but Etsy argues that if a newbie can break production, they clearly have not built a system strong enough to find the simple problems that a newbie could cause. This focus on improving the system to make it better for people to use is similarly ingrained in the DevOps and SRE communities.
What helps with this culture shift is that the DevOps practices of DevOps and cloud make change management a lot less risky. After all, deployments into production can be seen as just another testing phase. If you only deploy to a small subset of production and test the new version with a small data flow from production—we call this canary testing, after the canaries used in coal mines to identify gas leaks—then any negative impact is contained by the amount of data we have pushed to the new version. We can regulate the speed of rollout against our appetite for risk and rollback changes if we really need to.
Additionally, the same technical setup that allows canary testing also enables us to do A/B testing, which means we can run two different configurations of a service in production and see which one produces better results; then we roll that one out to the full production environments once we are convinced that we have found the better alternative.
I want to mention two more things that differentiate a good cloud architecture and the organizations that run them. Firstly, the forecasting abilities: cloud providers will allow you to dynamically scale which will work for a certain range of your services. Different circumstances might still require you to do your own forecasting (and you should always be doing some forecasting yourself). In Australia, we have a horse race called the Melbourne Cup, which, by itself, generates approximately 140 million Australian dollars in bets for a race that lasts seconds and creates a huge spike in online betting.3 This spike of demand on the Melbourne Cup’s website is something the site’s DevOps team could not leave to the capabilities of the cloud provider; it had to come up with its own forecasting and scaling solution. Good organizations understand where they are different and define an architecture that can support them, while others just rely on the defaults provided by the cloud provider.
The second thing you need to look at is rehearsing problems. You can leverage something like Netflix’s Simian Army—which consists of, among other tools, Chaos Monkey (which takes out random servers), Chaos Gorilla (which takes out entire Amazon availability zones), and Latency Monkey (which introduces artificial delays in your client server communication)—to see whether you can survive these kinds of problems.4 Those tools can be used frequently and have increasingly become part of organizations’ resilience strategies. Another strategy is to simulate a drastic catastrophe (such as an earthquake or fire—some even use alien-invasion scenarios) to stress test your resiliency and identify weakness. To be clear, these activities are not to prove that you are ready for a catastrophe but to provide opportunities to improve. The better your system gets, the more effort you put into breaking it. There is always a weakest spot, and you want to find it. Good cloud architectures are resilient to those disruptions and get better by repeatedly trying to break them. Untested resilience architectures are at the risk of failing when it matters most—during a real-life issue. In short, good cloud architecture leverages what is provided by the platform and extended by the consuming organization with additional capabilities to reflect their business and their application architecture.
First Steps for Your Organization
Review Your Cloud Applications
With the understanding of how the cloud is benefiting you most (based on the two factors—granularity of the architecture and maturity of the application in regard to DevOps practices), review your existing cloud applications (or the ones you are planning to move). To do this, first analyze the architecture to identify the components that are decoupled from each other and have the potential to be scaled independently. Also identify services that should be decoupled for later architectural refactoring. For each of the decoupled components, review their maturity of DevOps practices (SCM, build and deployment management, test automation) to identify gaps that require closing.
Next, ask yourself whether you would really benefit from the flexibility of the cloud for these applications, because you can leverage the elasticity of the architecture. Only if you have the right architecture and automation capabilities will you be able to fully benefit from the cloud. You should start building these capabilities—either before moving to the cloud or once you are in the cloud—to reduce the cost of your cloud infrastructure and the risk of business disruptions from application issues.
Based on this analysis, you will have a list of applications that are cloud ready and a backlog of work to make more and more applications cloud ready through architecture refactoring and the building of additional DevOps capabilities.
Plan a Cloud Disaster Event
Pick a scenario (e.g., your cloud provider going bust and you losing access to all the systems and data stored on the cloud) and run a full rehearsal of what it would take to come back online. This will include activities such as creating a new infrastructure with a different cloud provider, installing the applications you need to run your business, and restoring data from an external backup. There are two things that you want to do: