One way to tackle this problem is to make up a new field from the URL using rex.
Perhaps you only really care about the hits by directories. We can accomplish this with rex, or if needed, multiple rex statements.
Looking at the fictional source type impl_splunk_web, we see results that look like the following:
2012-08-25T20:18:01 user=bobby GET /products/x/?q=10471480 uid=Mzg2NDc0OA 2012-08-25T20:18:03 user=user3 GET /bar?q=923891 uid=MjY1NDI5MA 2012-08-25T20:18:05 user=user3 GET /products/index.html?q=9029891 uid=MjY1NDI5MA 2012-08-25T20:18:08 user=user2 GET /about/?q=9376559 uid=MzA4MTc5OA
URLs are tricky, as they might or might not contain certain parts of the URL. For instance, the URL may or may not have a query string, a page, or a trailing slash. To deal with this, instead of trying to make an all-encompassing regular expression, we will take advantage of the behavior of rex, which is used to make no changes to the event if the pattern does not match.
Consider the following query:
sourcetype="impl_splunk_web" | rex "s[A-Z]+s(?P<url>.*?)s" | rex field=url "(?P<url>.*)?" | rex field=url "(?P<url>.*/)" | stats count by url
In our case, this will produce the following report:
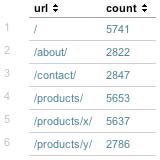
Stepping through these rex statements, we have:
- rex "s[A-Z]+s(?P<url>.*?)s": This pattern matches a space followed by uppercase letters, followed by a space, and then captures all characters until a space into the field url. The field attribute is not defined, so the rex statement matches against the _raw field. The values extracted look like the following:
- /products/x/?q=10471480
- /bar?q=923891
- /products/index.html?q=9029891
- /about/?q=9376559
- rex field=url "(?P<url>.*)?": Searching the field url, this pattern matches all characters until a question mark. If the pattern matches, the result replaces the contents of the url field. If the pattern doesn't match, url stays the same. The values of url will now be as follows:
- /products/x/
- /bar
- /products/index.html
- /about/
- rex field=url "(?P<url>.*/)": Once again, while searching the field url, this pattern matches all characters until, and including, the last slash. The values of url are then as follows:
-
- /products/x/
- /
- /products/
- /about/
This should effectively reduce the number of possible URLs and hopefully make our summary index more useful and efficient. It may be that you only want to capture up to three levels of depth. You can accomplish that with the following rex statement:
rex field=url "(?P<url>/(?:[^/]/){,3})"
The possibilities are endless. Be sure to test as much data as you can when building your summary indexes.