The best practice is to use a standalone syslog receiver to write events to the disk. Examples of syslog receivers include syslog-ng or rsyslog. Splunk is then configured to monitor the directories written by the syslog receiver.
Ideally, the syslog receiver should be configured to write one file or directory per host. inputs.conf can then be configured to use host_segment or host_regex to set the value of the host. This configuration has the advantage that props.conf stanzas can be applied by host, for instance, setting TZ by hostname pattern. This is not possible if the host is parsed out of the log messages, as is commonly the case with syslog.
The advantages of a standalone process include the following:
- A standalone process has no other tasks to accomplish, and is more likely to have the processor time to retrieve events from the kernel buffers before the data is pushed out of the buffers
- The interim files act as a buffer so that, in the case of a Splunk slowdown or outage, events are not lost
- The syslog data is on disk, so it can be archived independently or queried with other scripts, as appropriate
- If a file is written for each host, the hostname can be extracted from the path to the file, and different parsing rules (for instance, time zone) can be applied at that time
A small installation would look like the following diagram:
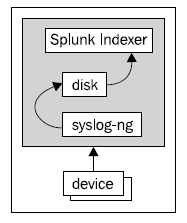
Since the configuration of the native syslog process is simple and unlikely to change, simply using another process on your single Splunk instance will add some level of protection from losing messages. A slow disk, high CPU load, or memory pressure can still cause problems, but you at least won't have to worry about restarting the Splunk process.
The next level of protection would be to use separate hardware to receive the syslog events and to use a Splunk forwarder to send the events to one or more Splunk indexers. That setup looks like the following diagram:
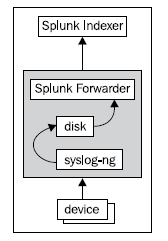
This single machine is still a single point of failure, but it has the advantage that the Splunk server holding the indexes can be restarted at will, and will not affect the instance receiving the syslog events.
The next level of protection is to use a load balancer or a dynamic DNS scheme to spread the syslog data across multiple machines receiving the syslog events, which then forward the events to one or more Splunk indexers. That setup looks somewhat like the following diagram:

This setup is complicated but very resilient, as only a large network failure will cause loss of events.