Understanding what dynamic means when used with programming
Using memoization effectively for dynamic programming
Discovering how the knapsack problem can be useful for optimization
Working with the NP-complete traveling salesman problem
Instead of using brute force, which implies trying all possible solutions to a problem, greedy algorithms provide an answer that is quick and often satisfying. In fact, a greedy algorithm can potentially solve the problem fully. Yet, greedy algorithms are also limited because they make decisions that don’t consider the consequences of their choices. Chapter 15 shows that you can’t always solve a problem using a greedy algorithm. Therefore, an algorithm may make an apparently optimal decision at a certain stage, which later appears limiting and suboptimal for achieving the best solution. A better algorithm, one that doesn’t rely on the greedy approach, can revise past decisions or anticipate that an apparently good decision is not as promising as it might seem. This is the approach that dynamic programming takes.
Dynamic programming is an algorithm approach devised in the 1950s by Richard Ernest Bellman (an applied mathematician also known for other discoveries in the field of mathematics and algorithms, you can read more at https://en.wikipedia.org/wiki/Richard_E._Bellman) that tests more solutions than a corresponding greedy approach. Testing more solutions provides the ability to rethink and ponder the consequences of decisions. Dynamic programming avoids performing heavy computations thanks to a smart caching system (a cache is a storage system collecting data or information) called memoization, a term defined later in the chapter.
This chapter offers you more than a simple definition of dynamic programming. It also explains why dynamic programming has such a complicated name and how to transform any algorithm (especially recursive ones) into dynamic programming using Python and its function decorators (powerful tools in Python that allow changing an existing function without rewriting its code). In addition, you discover applications of dynamic programming to optimize resources and returns, creating short tours between places and comparing strings in an approximate way. Dynamic programming provides a natural approach to dealing with many problems you encounter while journeying through the world of algorithms.
Explaining Dynamic Programming
Dynamic programming is as effective as an exhaustive algorithm (thus providing correct solutions), yet it is often as efficient as an approximate solution (the computational time of many dynamic programming algorithms is polynomial). It seems to work like magic because the solution you need often requires the algorithm to perform the same calculations many times. By modifying the algorithm and making it dynamic, you can record the computation results and reuse them when needed. Reusing takes little time when compared to recalculating, thus the algorithm finishes the steps quickly. The following sections discuss what dynamic programming involves in more detail.
Obtaining a historical basis
You can boil dynamic programming down to having an algorithm remember the previous problem results where you’d otherwise have to perform the same calculation repeatedly. Even though dynamic programming might appear to be quite complex, the implementation is actually straightforward. However, it does have some interesting historical origins.
Bellman described the name as the result of necessity and convenience in his autobiography, In the Eye of the Hurricane. He writes that the name choice was a way to hide the true nature of his research at the RAND Corporation (a research and development institution funded by both the U.S. government and private financers) from Charles Erwin Wilson, the Secretary of Defense under the Eisenhower presidency. Cloaking the true nature of his research helped Bellman remain employed at the RAND Corporation. You can read his explanation in more detail in the excerpt at: http://smo.sogang.ac.kr/doc/dy_birth.pdf. Some researchers don’t agree about the name source. For example, Stuart Russell and Peter Norvig, in their book Artificial Intelligence: A Modern Approach, argue that Bellman actually used the term dynamic programming in a paper dating 1952, which is before Wilson became Secretary in 1953 (and Wilson himself was CEO of General Motors before becoming an engineer involved in research and development).
Computer programming languages weren’t widespread during the time that Bellman worked in operations research, a discipline that applies mathematics to make better decisions when approaching mainly production or logistic problems (but is also used for other practical problems). Computing was at the early stages and used mostly for planning. The basic approach of dynamic programming is the same as linear programming, another algorithmic technique (see Chapter 19) defined in those years when programming meant planning a specific process to find an optimal solution. The term dynamic reminds you that the algorithm moves and stores partial solutions. Dynamic programming is a complex name for a smart and effective technique to improve algorithm running times.
Making problems dynamic
Because dynamic programming takes advantage of repeated operations, it operates well on problems that have solutions built around solving subproblems that the algorithm later assembles to provide a complete answer. In order to work effectively, a dynamic programming approach uses subproblems nested in other subproblems. (This approach is akin to greedy algorithms, which also require an optimal substructure, as explained in Chapter 15.) Only when you can break down a problem into nested subproblems can dynamic programming beat brute-force approaches that repeatedly rework the same subproblems.
As a concept, dynamic programming is a huge umbrella covering many different applications because it isn’t really a specific algorithm for solving a specific problem. Rather, it’s a general technique that supports problem solving.
You can trace dynamic programming to two large families of solutions:
Bottom-up: Builds an array of partial results that aggregate into a complete solution
Top-down: Splits the problem into subproblems, starting from the complete solution (this approach is typical of recursive algorithms) and using memoization (defined in the next section) to avoid repeating computations more than once
Typically, the top-down approach is more computationally efficient because it generates only the subproblems necessary for the complete solution. The bottom-up approach is more explorative and, using trial and error, often obtains partial results that you won’t use later. On the other hand, bottom-up approaches better reflect the approach that you’d take in everyday life when facing a problem (thinking recursively, instead, needs abstraction and training before application). Both top-down and bottom-up approaches aren’t all that easy to understand at times. That’s because using dynamic programming transforms the way you solve problems, as detailed in these steps:
Create a working solution using brute-force or recursion. The solution works but it takes a long time or won’t finish at all.
Store the results of subproblems to speed your computations and reach a solution in a reasonable time.
Change the way you approach the problem and gain even more speed.
Redefine the problem approach, in a less intuitive but more efficient way to obtain the greatest advantage from dynamic programming.
Transforming algorithms using dynamic programming to make them work efficiently makes them harder to understand. In fact, you might look at the solutions and think they work by magic. Becoming proficient in dynamic programming requires repeated observations of existing solutions and some practical exercise. This proficiency is worth the effort, however, because dynamic programming can help you solve problems for which you have to systematically compare or compute solutions.
Dynamic programming is especially known for helping solve (or at least make less time demanding) combinatorial optimization problems, which are problems that require obtaining combinations of input elements as a solution. Examples of such problems solved by dynamic programming are the traveling salesman and the knapsack problems, described later in the chapter.
Casting recursion dynamically
The basis of dynamic programming is to achieve something as effective as brute-force searching without actually spending all the time doing the computations required by a brute-force approach. You achieve the result by trading time for disk space or memory, which is usually done by creating a data structure (a hash table, an array, or a data matrix) to store previous results. Using lookup tables allows you to access results without having to perform a calculation a second time.
The technique of storing previous function results and using them instead of the function is memoization, a term you shouldn’t confuse with memorization. Memoization derives from memorandum, the Latin word for “to be remembered.”
Caching is another term that you find used when talking about memoization. Caching refers to using a special area of computer memory to serve data faster when required, which has more general uses than memoization.
To be effective, dynamic programming needs problems that repeat or retrace previous steps. A good example of a similar situation is using recursion, and the landmark of recursion is calculating Fibonacci numbers. The Fibonacci sequence is simply a sequence of numbers in which the next number is the sum of the previous two. The sequence starts with 0 followed by 1. After defining the first two elements, every following number in the sequence is the sum of the previous ones. Here are the first eleven numbers:
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
As with indexing in Python, counting starts from the zero position, and the last number in the sequence is the tenth position. The inventor of the sequence, the Italian mathematician Leonardo Pisano, known as Fibonacci, lived in 1200. Fibonacci thought that the fact that each number is the sum of the previous two should have made the numbers suitable for representing the growth patterns of a group of rabbits. The sequence didn’t work great for rabbit demographics, but it offered unexpected insights into both mathematics and nature itself because the numbers appear in botany and zoology. For instance, you see this progression in the branching of trees, in the arrangements of leaves in a stem, and of seeds in a sunflower (you can read about this arrangement at https://www.goldennumber.net/spirals/).
Fibonacci was also the mathematician who introduced Hindu-Arabic numerals to Europe, the system we daily use today. He described both the numbers and the sequence in his masterpiece, the Liber Abaci, in 1202.
You can calculate a Fibonacci number sequence using recursion. When you input a number, the recursion splits the number into the sum of the previous two Fibonacci numbers in the sequence. After the first split, the recursion proceeds by performing the same task for each element of the split, splitting each of the two numbers into the previous two Fibonacci numbers. The recursion continues splitting numbers into their sums, until it finally finds the roots of the sequence, the numbers 0 and 1. Reviewing the two types of dynamic programming algorithm described in the previous paragraph, this solution uses a top-down approach. The following code shows the recursive approach in Python. (You can find this code in the A4D; 16; Fibonacci.ipynb file on the Dummies site as part of the downloadable code; see the Introduction for details.)
def fib(n, tab=0): if n==0: return 0 elif n == 1: return 1 else: print ("lvl %i, Summing fib(%i) and fib(%i)" % (tab, n-1, n-2)) return fib(n-1,tab+1) + fib(n-2,tab+1)
The code prints the splits generated by each recursion level. The following output shows what happens when you call fib() with an input value of 7:
fib(7) lvl 0, Summing fib(6) and fib(5) lvl 1, Summing fib(5) and fib(4) lvl 2, Summing fib(4) and fib(3) lvl 3, Summing fib(3) and fib(2) lvl 4, Summing fib(2) and fib(1) lvl 5, Summing fib(1) and fib(0) lvl 4, Summing fib(1) and fib(0) lvl 3, Summing fib(2) and fib(1) lvl 4, Summing fib(1) and fib(0) lvl 2, Summing fib(3) and fib(2) lvl 3, Summing fib(2) and fib(1) lvl 4, Summing fib(1) and fib(0) lvl 3, Summing fib(1) and fib(0) lvl 1, Summing fib(4) and fib(3) lvl 2, Summing fib(3) and fib(2) lvl 3, Summing fib(2) and fib(1) lvl 4, Summing fib(1) and fib(0) lvl 3, Summing fib(1) and fib(0) lvl 2, Summing fib(2) and fib(1) lvl 3, Summing fib(1) and fib(0) 13
The output shows 20 splits. Some numbers appear more than once as part of the splits. It seems like an ideal case for applying dynamic programming. The following code adds a dictionary, called memo, which stores previous results. After the recursion splits a number, it checks whether the result already appears in the dictionary before starting the next recursive branch. If it finds the result, the code uses the precomputed result, as shown here:
memo = dict() def fib_mem(n, tab=0): if n==0: return 0 elif n == 1: return 1 else: if (n-1, n-2) not in memo: print ("lvl %i, Summing fib(%i) and fib(%i)" % (tab, n-1, n-2)) memo[(n-1,n-2)] = fib_mem(n-1,tab+1 ) + fib_mem(n-2,tab+1) return memo[(n-1,n-2)]
Using memoization, the recursive function doesn’t compute 20 additions but rather uses just six, the essential ones used as building blocks to solve the initial requirement for computing a certain number in the sequence:
fib_mem(7) lvl 0, Summing fib(6) and fib(5) lvl 1, Summing fib(5) and fib(4) lvl 2, Summing fib(4) and fib(3) lvl 3, Summing fib(3) and fib(2) lvl 4, Summing fib(2) and fib(1) lvl 5, Summing fib(1) and fib(0) 13
Looking inside the memo dictionary, you can find the sequence of sums that define the Fibonacci sequence starting from 1:
Memoization is the essence of dynamic programming. You often find the need to use it when scripting an algorithm yourself. When creating a function, whether recursive or not, you can easily transform it using a simple command, a decorator, which is a special Python function that transforms functions. To see how to work with a decorator, start with a recursive function, stripped of any print statement:
def fib(n): if n==0: return 0 elif n == 1: return 1 else: return fib(n-1) + fib(n-2)
When using Jupyter, you use IPython built-in magic commands, such as timeit, to measure the execution time of a command on your computer:
%timeit -n 1 -r 1 print(fib(36)) 14930352 1 loop, best of 1: 15.5 s per loop
The output shows that the function requires about 15 seconds to execute. However, depending on your machine, function execution may require more or less time. No matter the speed of your computer, it will certainly take a few seconds to complete, because the Fibonacci number for 36 is quite huge: 14930352. Testing the same function for higher Fibonacci numbers takes even longer.
Now it’s time to see the effect of decorating the function. Using the lru_cache function from the functools package can radically reduce execution time. This function is available only when using Python3. It transforms a function by automatically adding a cache to hold its results. You can also set the cache size by using the maxsize parameter (lru_cache uses a cache with an optimal replacement strategy, as explained in the Chapter 15). If you set maxsize=None, the cache uses all the available memory, without limits.
from functools import lru_cache @lru_cache(maxsize=None) def fib(n): if n==0: return 0 elif n == 1: return 1 else: return fib(n-1) + fib(n-2)
Note that the function is the same as before. The only addition is the imported lru_cache (https://docs.python.org/3.5/library/functools.html), which you call by putting an @ symbol in front of it. Any call with the @ symbol in front is an annotation and calls the lru_cache function as a decorator of the following function.
Using decorators is an advanced technique in Python. Decorators don’t need to be explained in detail in this book, but you can still take advantage of them because they are so easy to use. (You can find additional information about decorators at http://simeonfranklin.com/blog/2012/jul/1/python-decorators-in-12-steps/ and https://www.learnpython.org/en/Decorators.) Just remember that you call them using annotations (@ + decorator function’s name) and that you put them in front of the function you want to transform. The original function is fed into the decorator and comes out transformed. In this example of a simple recursive function, the decorator outputs a recursion function enriched by memoization.
It’s time to test the function speed, as before:
%timeit -n 1 -r 1 print(fib(36)) 14930352 1 loop, best of 1: 60.6 µs per loop
Even if your execution time is different, it should decrease from seconds to milliseconds. Such is the power of memoization. You can also explore how your function uses its cache by calling the cache_info method from the decorated function:
The output tells you that there are 37 function calls that don’t find an answer in the cache. However, 34 other calls did find a useful answer in the cache.
Just by importing lru_cache from functools and using it in annotations in front of your heavy-duty algorithms in Python, you will experience a great increase in performance (unless they are greedy algorithms).
Discovering the Best Dynamic Recipes
Even dynamic programming has limitations. The biggest limitation of all relates to its main strength: If you keep track of too many partial solutions to improve running time, you may run out of memory. You may have too many partial solutions in store because the problem is complex, or simply because the order you use to produce partial solutions is not an optimal one and too many of the solutions don’t fit the problem requirements.
The order used to solve subproblems is something you must track. The order you choose should make sense for the efficient progression of the algorithm (you solve something that you’re going to reuse immediately) because the trick is in smart reuse of previously built building blocks. Therefore, using memoization may not provide enough benefit. Rearranging your problems in the right order can improve the results. You can learn how to correctly order your subproblems by learning directly from the best dynamic programming recipes available: knapsack, traveling salesman, and approximate string search, as described in the sections that follow.
Looking inside the knapsack
The knapsack problem has been around since at least 1897 and is likely the work of Tobias Dantzig (https://www.britannica.com/biography/Tobias-Dantzig). In this case, you have to pack up your knapsack with as many items as possible. Each item has a value, so you want maximize the total value of the items you carry. The knapsack has a threshold capacity or you have a limit of weight you can carry, so you can’t carry all the items.
The general situation fits any problem that involves a budget and resources, and you want to allocate them in the smartest way possible. This problem setting is so common that many people consider the knapsack problem to be one of the most popular algorithmic problems. The knapsack problem finds applications in computer science, manufacturing, finance, logistics, and cryptography. For instance, real-world applications of the knapsack problem are how to best load a cargo ship with goods or how to optimally cut raw materials, thus creating the least waste possible.
Even though it’s such a popular problem, this book doesn’t explore the knapsack problem again because the dynamic approach is incontestably one of the best solving approaches. It’s important to remember, though, that in specific cases, for such as when the items are quantities, other approaches, such as using greedy algorithms, may work equally well (or even better).
This section shows how to solve the 1-0 knapsack problem. In this case, you have a finite number of items and can put each of them into the knapsack (the one status) or not (the zero status). It’s useful to know there are other possible variants of the problem:
Fractional knapsack problem: Deals with quantities. For example, an item could be kilograms of flour, and you must pick the best quantity. You can solve this version using a greedy algorithm.
Bounded knapsack problem: Puts one or more copies of the same item into the knapsack. In this case, you must deal with minimum and maximum number requirements for each item you pick.
Unbounded knapsack problem: Puts one or more copies of the same item into the knapsack without constraints. The only limit is that you can’t put a negative number of items into the knapsack.
The 1-0 knapsack problem relies on a dynamic programming solution and runs in pseudo-polynomial time (which is worse than just polynomial time) because the running time depends on the number of items (n) multiplied by the number of fractions of the knapsack capacity (W) that you use on building your partial solution. When using big-O notation, you can say that the running time is O(nW). The brute-force version of the algorithm instead runs in O(2n). The algorithm works like this:
Given the knapsack capacity, test a range of smaller knapsacks (subproblems). In this case, given a knapsack capable of carrying 20 kilograms, the algorithm tests a range of knapsacks carrying from 0 kilograms to 20 kilograms.
For each item, test how it fits in each of the knapsacks, from the smallest knapsack to the largest. At each test, if the item can fit, choose the best value from the following:
The solution offered by the previous smaller knapsack
The test item, plus you fill the residual space with the best valued solution previously that filled that space
The code runs the knapsack algorithm and solves the problem with a set of six items of different weight and value combinations as well as a 20-kg knapsack:
Item
1
2
3
4
5
6
Weight in kg
2
3
4
4
5
9
Profit in 100 USD
3
4
3
5
8
10
Here is the code to execute the dynamic programming procedure described. (You can find this code in the A4D; 16; Knapsack.ipynb file on the Dummies site as part of the downloadable code; see the Introduction for details.)
import numpy as np values = np.array([3,4,3,5,8,10]) weights = np.array([2,3,4,4,5,9]) items = len(weights) capacity = 20 memo = dict() for size in range(0, capacity+1, 1): memo[(-1, size)] = ([], 0)
for item in range(items): for size in range(0, capacity+1, 1): # if the object doesn't fit in the knapsack if weights[item] > size: memo[item, size] = memo[item-1, size] else: # if the objcts fits, we check what can best fit # in the residual space previous_row, previous_row_value = memo[ item-1, size-weights[item]] if memo[item-1, size][1] > values[item ] + previous_row_value: memo[item, size] = memo[item-1, size] else: memo[item, size] = (previous_row + [item ], previous_row_value + values[item])
The best solution is the cached result when the code tests inserting the last item with the full capacity (20 kg) knapsack:
best_set, score = memo[items-1, capacity] print ('The best set %s weights %i and values %i' % (best_set, np.sum((weights[best_set])), score)) The best set [0, 3, 4, 5] weights 20 and values 26
You may be curious to know what happened inside the memoization dictionary:
It contains 147 subproblems. In fact, six items multiplied by 21 knapsacks is 126 solutions, but you have to add another 21 naive solutions to allow the algorithm to work properly (naive means leaving the knapsack empty), which increases the number of subproblems to 147.
You may find solving 147 subproblems daunting (even though they’re blazingly fast to solve). Using brute force alone to solve the problem means solving fewer subproblems in this particular case. Solving fewer subproblems requires less time, a fact you can test by solving the accounts using Python and the comb function:
from scipy.misc import comb objects = 6 np.sum([comb(objects,k+1) for k in range(objects)])
It takes testing 63 combinations to solve this problem. However, if you try using more objects, say, 20, running times look much different because there are now 1,048,575 combinations to test. Contrast this huge number with dynamic programming, which requires solving just 20*21+21 = 441 subproblems.
This is the difference between quasi-polynomial and exponential time. (As a reminder, the book discusses exponential complexity in Chapter 2 when illustrating the Big O Notation. In Chapter 15, you discover polynomial time as part of the discussion about NP complete problems.) Using dynamic programming becomes fruitful when your problems are complex. Toy problems are good for learning but they can’t demonstrate the full extent of employing smart algorithm techniques such as dynamic programming. Each solution tests what happens after adding a certain item when the knapsack has a certain size. The preceding example adds item 2 (weight=4, value=3) and outputs a solution that puts items 0, 1, and 2 into the knapsack (total weight 9 kg) for a value of 10. This intermediate solution leverages previous solutions and is the basis for many of the following solutions before the algorithm reaches its end.
You may wonder whether the result offered by the script is really the best one achievable. Unfortunately, the only way to be sure is to know the right answer, which means running a brute-force algorithm (when feasible in terms of running time on your computer). This chapter doesn’t use brute force for the knapsack problem but you’ll see a brute-force approach used in the traveling salesman problem that follows.
Touring around cities
The traveling salesman problem (TSP for short) is at least as widely known as the knapsack problem. You use it mostly in logistics and transportation (such as the derivative Vehicle Routing Problem shown at http://neo.lcc.uma.es/vrp/vehicle-routing-problem/), so it doesn’t see as much use as the knapsack problem. The TSP problem asks a traveling salesperson to visit a certain number of cities and then come back to the initial starting city (because it’s circular, it’s called a tour) using the shortest path possible.
TSP is similar to graph problems, but without the edges because the cities are all interconnected. For this reason, TSP usually relies on a distance matrix as input, which is a table listing the cities on both rows and columns. The intersections contain the distance from a row city to a column city. TSP problem variants may provide a matrix containing time or fuel consumption instead of distances.
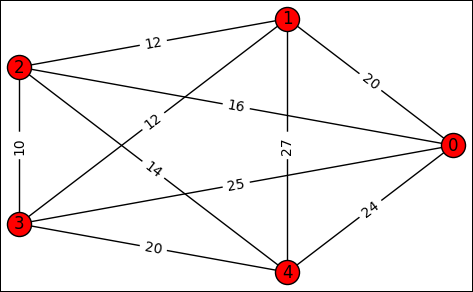
TSP is an NP-hard problem, but you can solve the problem using various approaches, some approximate (heuristic) and some exact (dynamic programming). The problem, as with any other NP-hard problem, is the running time. Although you can count on solutions that you presume optimally solve the problem (you can’t be certain except when solving short tours), you can’t know for sure with problems as complex as touring the world: http://www.math.uwaterloo.ca/tsp/world/. The following example tests various algorithms, such as brute force, greedy, and dynamic programming, on a simple tour of six cities, represented as a weighted graph (see Figure 16-1). (You can find this code in the A4D; 16; TSP.ipynb file on the Dummies site as part of the downloadable code; see the Introduction for details.)
import numpy as np import networkx as nx import matplotlib.pyplot as plt %matplotlib inline D = np.array([[0,20,16,25,24],[20,0,12,12,27], [16,12,0,10,14],[25,12,10,0,20], [24,27,14,20,0]]) Graph = nx.Graph() Graph.add_nodes_from(range(D.shape[0])) for i in range(D.shape[0]): for j in range(D.shape[0]): Graph.add_edge(i,j,weight=D[i,j]) np.random.seed(2) pos=nx.shell_layout(Graph) nx.draw(Graph, pos, with_labels=True) labels = nx.get_edge_attributes(Graph,'weight') nx.draw_networkx_edge_labels(Graph,pos, edge_labels=labels) plt.show()
FIGURE 16-1: Cities represented as nodes in a weighted graph.
After defining the D (distance) matrix, the example tests the first, simplest solution to determine the shortest tour starting and ending from city zero. This solution relies on brute force, which generates all the possible order permutations between the cities, leaving out zero. The distance from zero to the first city and from the last city of the tour to zero is added after the total distance of each solution is calculated. When all the solutions are available, you simply choose the shortest.
from itertools import permutations best_solution = [None, np.sum(D)] for solution in list(permutations(range(1,D.shape[0]))): start, distance = (0,0) for next_one in solution: distance += D[start, next_one] start = next_one distance += D[start,0] if distance <= best_solution[1]: best_solution = [[0]+list(solution)+[0], distance] print ('Best solution so far: %s kms' % str(best_solution)[1:-1]) Best solution so far: [0, 1, 2, 3, 4, 0], 86 kms Best solution so far: [0, 1, 3, 2, 4, 0], 80 kms Best solution so far: [0, 4, 2, 3, 1, 0], 80 kms
The brute-force algorithm quickly determines the best solution and its symmetric path. However, as a result of the small problem size, you obtain a prompt answer because, given four cities, just 24 possible solutions exist. As the number of cities increases, the number of permutations to test becomes intractable, even after removing the symmetric paths (which halves the permutations) and using a fast computer. For example, consider the number of computations when working with 13 cities plus the starting/ending point:
from scipy.special import perm print (perm(13,13)/2) 3113510400.0
Dynamic programming can simplify the running time. The Held–Karp algorithm (also known as the Bellman–Held–Karp algorithm because Bellman published it in 1962, the same year as Michael Held and Richard Karp) can cut time complexity to O(2nn2). It’s still exponential complexity, yet it requires less time than applying the exhaustive enumeration of all tours by brute force.
Approximate and heuristic algorithms can provide fast and useful results (even though the result may not always reflect the optimal solution, it’s usually good enough). You see TSP again later in the book (see Chapters 18 and 20), when dealing with local search and heuristics.
To find the best TSP solution for n cities, starting and ending from city 0, the algorithm proceeds from city 0 and keeps records of the shortest path possible, considering different settings. It always uses a different ending city and touches only a city subset. As the subsets become larger, the algorithm learns how to solve the problem efficiently. Therefore, when solving TSP for five cities, the algorithm first considers solutions involving two cities, then three cities, then four, and finally five (sets have dimensions 1 to n). Here are the steps the algorithm uses:
Initialize a table to track the distances from city 0 to all other cities. These sets contain only the initial city and a destination city because they represent the initial step.
Consider every possible set size, from two to the number of tour cities. This is a first iteration, the outer loop.
Inside the outer loop, for each set size, consider every possible combination of cities of that size, not containing the initial city. This is an inner iteration.
Inside the inner iteration (Step 3), for every available combination, consider each city inside the combination as the ending city. This is another inner iteration.
Inside the inner iteration (Step 4), given a different destination city, determine the shortest path connecting the cities in the set from the city that starts the tour (city 0). In finding the shortest path, use any useful, previously stored information, thus applying dynamic programming. This step saves computations and provides the rationale for working by growing subsets of cities. Reusing previously solved subproblems, you find the shorter tours by adding to a previous shortest path the distance necessary to reach the destination city. Given a certain set of cities, a specific initial city, and a specific destination city, the algorithm stores the best path and its length.
When all the iterations end, you have as many different shortest solutions as n-1 cities, with each solution covering all the cities but ending at a different city. Add a closing point, the city 0, to each one to conclude the tour.
Determine the shortest solution and output it as the result.
The Python implementation of this algorithm isn’t very simple because it involves some iterations and manipulating sets. It’s an exhaustive search reinforced by dynamic programming and relies on an iterative approach with subsets of cities and with candidates to add to them. The following commented Python example explores how this solution works. You can use it to calculate customized tours (possibly using cities in your region or county as entries in the distance matrix). The script uses advanced commands such as frozenset (a command that makes a set usable as a dictionary key) and operators for sets in order to achieve the solution.
from itertools import combinations memo = {(frozenset([0, idx+1]), idx+1): (dist, [0,idx+1]) for idx,dist in enumerate(D[0][1:])} cities = D.shape[0] for subset_size in range(2, cities): # Here we define the size of the subset of cities new_memo = dict() for subset in [frozenset(comb) | {0} for comb in combinations(range(1, cities), subset_size)]: # We enumerate the subsets having a certain subset # size for ending in subset - {0}: # We consider every ending point in the subset all_paths = list() for k in subset: # We check the shortest path for every # element in the subset if k != 0 and k!=ending: length = memo[(subset-{ending},k)][0 ] + D[k][ending] index = memo[(subset-{ending},k)][1 ] + [ending] all_paths.append((length, index)) new_memo[(subset, ending)] = min(all_paths) # In order to save memory, we just record the previous # subsets since we won't use shorter ones anymore memo = new_memo # Now we close the cycle and get back to the start of the # tour, city zero tours = list() for distance, path in memo.values(): distance += D[path[-1],0] tours.append((distance, path+[0])) # We can now declare the shortest tour distance, path = min(tours) print ('Shortest dynamic programming tour is: %s, %i kms' % (path, distance)) Shortest dynamic programming tour is: [0, 1, 3, 2, 4, 0], 80 kms
Approximating string search
Determining when one word is similar to another isn’t always simple. Words may differ slightly because of misspelling or different ways of writing the word itself, thus rendering any exact match impossible. This isn’t just a problem that raises interesting issues during a spell check, though. For example, putting similar text strings together (such as names, addresses, or code identifiers) that refer to the same person may help create a one-customer view of a firm’s customer base or help a national security agency locate a dangerous criminal.
Approximating string searches has many applications in machine translation, speech recognition, spell checking and text processing, computational biology, and information retrieval. Thinking about the manner in which sources input data into databases, you know there are many mismatches between data fields that a smart algorithm must solve. Matching a similar, but not precisely equal, series of letters is an ability that finds uses in fields such as genetics when comparing DNA sequences (expressed by letters representing nucleotides G,A,T, and C ) to determine whether two sequences are similar and how they resemble each other.
Vladimir Levenshtein, a Russian scientist expert in information theory (see http://ethw.org/Vladimir_I._Levenshtein for details), devised a simple measure (named after him) in 1965 that computes the grade of similarity between two strings by counting how many transformations it takes to change the first string into the second. The Levenshtein distance (also known as edit distance) counts how many changes are necessary in a word:
Deletion: Removing a letter from a word
Insertion: Inserting a letter into a word and obtaining another word
Substitution: Replacing one letter with another, such as changing the p letter into an f letter and obtaining fan from pan
Each edit has a cost, which Levenshtein defines as 1 for each transformation. However, depending on how you apply the algorithm, you could set the cost differently for deletion, insertion, and substitution. For example, when searching for similar street names, misspellings are more common than outright differences in lettering, so substitution might incur only a cost of 1, and deletion or insertion might incur a cost of 2. On the other hand, when looking for monetary amounts, similar values quite possibly will have different numbers of numbers. Someone could enter $123 or $123.00 into the database. The numbers are the same, but the number of numbers is different, so insertion and deletion might cost less than substitution (a value of $124 is not quite the same as a value of $123, so substituting 3 for 4 should cost more).
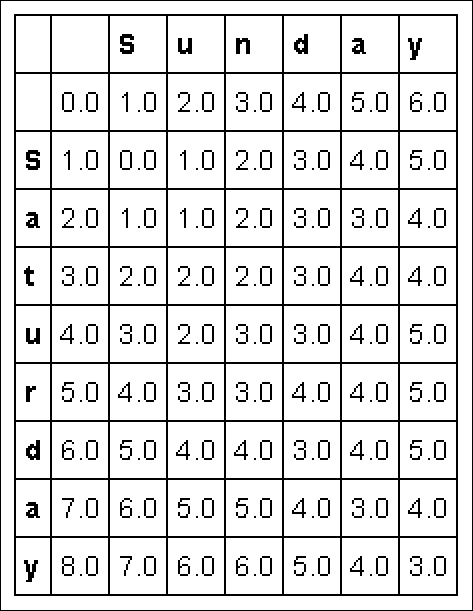
You can render the counting algorithm as a recursion or an iteration. However, it works much faster using a bottom-up dynamic programming solution, as described in the 1974 paper “The String-to-string Correction Problem,” by Robert A. Wagner and Michael J. Fischer (http://www.inrg.csie.ntu.edu.tw/algorithm2014/homework/Wagner-74.pdf). The time complexity of this solution is O(mn), where n and m are the lengths in letter of the two words being compared. The following code computes the number of changes required to turn the word Saturday into Sunday by using dynamic programming with a matrix (see Figure 16-2) to store previous results (the bottom-up approach). (You can find this code in the A4D; 16; Levenshtein.ipynb file on the Dummies site as part of the downloadable code; see the Introduction for details.)
import numpy as np import pandas as pd s1 = 'Saturday' s2 = 'Sunday' m = len(s1) n = len(s2) D = np.zeros((m+1,n+1)) D[0,:] = list(range(n+1)) D[:,0] = list(range(m+1)) for j in range(1, n+1): for i in range(1, m+1): if s1[i-1] == s2[j-1]: D[i, j] = D[i-1, j-1] else: D[i, j] = np.min([ D[i-1, j] + 1, # a deletion D[i, j-1] + 1, # an insertion D[i-1, j-1] + 1 # a substitution ]) print ('Levenshtein distance is %i' % D[-1,-1]) Levenshtein distance is 3
The algorithm builds the matrix, placing the best solution in the last cell. After building the matrix using the letters of the first string as rows and the letters of the second one as columns, it proceeds by columns, computing the differences between each letter in the rows compared to those in the columns. In this way, the algorithm makes a number of comparisons equivalent to the multiplication of the number of the letters in the two strings. As the algorithm continues, it accounts for the result of previous comparisons by looking at the solutions present in the previous matrix cells and choosing the solution with the least number of edits.
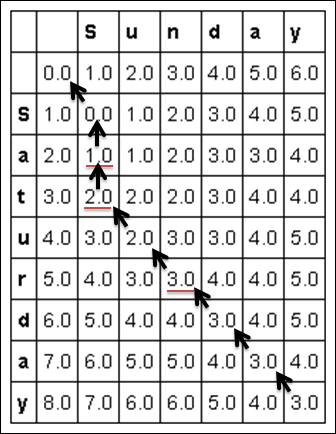
When the matrix iteration completes, the resulting number represents the minimum number of edits necessary for the transformation to occur — the smaller the number, the more similar the two strings. Retracing from the last cell to the first one by moving to the previous cell with the least value (if more directions are available, it prefers to move diagonally) hints at what transformations to execute (see Figure 16-3):
A diagonal backward movement hints at a substitution in the first string if the letters on the row and column differ (otherwise, no edit needs to be done)
An upward movement dictates a deletion of a letter in the first string
A left backward move indicates that an insertion of a new letter should be done on the first string
FIGURE 16-3: Highlighting what transformations are applied.
In this example, the backtracking points out the following transformations (two deletions and one substitution):
 Understanding what dynamic means when used with programming
Understanding what dynamic means when used with programming As a concept, dynamic programming is a huge umbrella covering many different applications because it isn’t really a specific algorithm for solving a specific problem. Rather, it’s a general technique that supports problem solving.
As a concept, dynamic programming is a huge umbrella covering many different applications because it isn’t really a specific algorithm for solving a specific problem. Rather, it’s a general technique that supports problem solving. Dynamic programming is especially known for helping solve (or at least make less time demanding) combinatorial optimization problems, which are problems that require obtaining combinations of input elements as a solution. Examples of such problems solved by dynamic programming are the traveling salesman and the knapsack problems, described later in the chapter.
Dynamic programming is especially known for helping solve (or at least make less time demanding) combinatorial optimization problems, which are problems that require obtaining combinations of input elements as a solution. Examples of such problems solved by dynamic programming are the traveling salesman and the knapsack problems, described later in the chapter. Using decorators is an advanced technique in Python. Decorators don’t need to be explained in detail in this book, but you can still take advantage of them because they are so easy to use. (You can find additional information about decorators at
Using decorators is an advanced technique in Python. Decorators don’t need to be explained in detail in this book, but you can still take advantage of them because they are so easy to use. (You can find additional information about decorators at