Figure 3.1 Client traffic and Layer 4 distribution

Chapter 3
Exchange Architectural Concepts
In Chapter 1, “Business, Functional, and Technical Requirements,” we spoke about the best practices that we tend to take for granted: that storage should be built in a certain way, that roles should be allocated in a certain ratio, and so forth. To this day, we often come across Exchange 2010 implementations that clearly reflect Exchange 2007 and even Exchange 2003 thinking. Exchange 2013 is a completely new version and, as such, the best ways for implementing it will develop as the product is deployed and it matures through various cycles of cumulative updates.
Exchange 2010 went through a similar cycle. The recommendations for implementation at RTM were very different than those made at SP2. These kinds of changes in guidance are natural for Exchange. Nevertheless, it means that those who don't keep up with the changes in guidance will implement Exchange according to some old guidance, and they will not be able to take advantage of the full capabilities, either of Exchange or the hardware platform on which it is deployed. Significant savings can also be achieved by deploying Exchange according to new guidance, because it takes advantage of the latest storage and application replication capabilities, which may be lost if deploying Exchange using outdated guidance.
The aim of this chapter is to define the concepts on which Exchange is built and then to extrapolate those concepts into the design choices that have resulted in the Exchange 2013 version.
If you are a messaging consultant or administrator faced with upgrading from an earlier version of Exchange, then the history section in this chapter will help you address the architectural changes and features required to guide your customer through an upgrade to Exchange 2013. Knowing which features have changed, which have been discontinued, and which have been de-emphasized is a critical skill for messaging administrators and consultants. Consider the example where significant applications have been developed to take advantage of WebDAV. As a consultant, you must be able to point out that this mechanism is no longer available to access mailbox contents and what the available alternatives are.
We will explore both the history of the product and specific areas that pertain to Exchange 2013. This chapter is built on the concepts and vocabulary for Exchange to increase your understanding of the product. Understanding Exchange fully will help you choose features and build a messaging system that meets the requirements put forth by a business. Understanding what and where Exchange starts and ends and what it does not do may also arm you with the necessary appreciation of how to choose products and features from the third-party ecosystem.
To appreciate fully where Exchange 2013 is today, it helps to examine where Exchange 2013 came from. As we explore the previous versions of Exchange, we can identify the best practices of yesteryear and how those practices no longer apply to Exchange 2013. In Chapter 1, we explored that the “long trail of obsolete best practices” is still being applied to current-day products such as Exchange 2013 through storage and other best practices that originated in earlier versions of Exchange. As a consultant, you must be able to understand and identify which best practices no longer apply and why when faced with the inevitable discussions surrounding best practices, including topics such as storage, security, high availability, and so forth.
Exchange started as Microsoft Mail in 1991. Microsoft Mail reflected the thinking of the day in terms of storing email in a post office and interoperating via a Message Transfer Agent (MTA) and connectors. Exchange 4.0 was released in April 1996 followed by Exchange 4.0 (a) in August of the same year. Five service packs later, Exchange 5.0 was released in March 1997 and Exchange 5.5 SP4 in November 2000. Though Exchange 5.5 scaled well as a departmental messaging solution, it did not scale well at all as a global enterprise solution by today's standards.
The most important piece of technology for our purposes was the birth of the Extensible Storage Engine (ESE). It is the only architectural concept that has been carried forward—in a vastly optimized version—from Exchange 5.5 and below to Exchange 2013.
ESE is the database engine used in Microsoft Exchange, Microsoft Active Directory, and a number of other Microsoft products. It was built as a non-hierarchical database so that it could store unstructured data. ESE was designed to survive system crashes and to cache data intelligently in order to provide high-speed access to data when required. These tenets of ESE design have been carried through its various offspring released with different versions of Exchange.
ESE was initially optimized for the scenario when disk speeds were very slow and disk storage was very expensive. Emails were single instanced wherever possible. This meant that an email received for several recipients was stored only once but referred to as many times as necessary, eliminating the need to write disparate copies for every recipient into the same database. Because of the single-instance scenario, ESE was also highly optimized for random access in its read/write profile.
Exchange 2000/2003 and later versions introduced a number of concepts that are carried forward into the current product in one form or another. We will briefly introduce each concept in order to add context to the overall architectural view of Exchange 2013. Unless otherwise noted as discontinued, the features discussed in previous versions of Exchange continue into Exchange 2013. These versions of Exchange moved the product out of the departmental email space and firmly into a datacenter-based enterprise-messaging solution. They supported high availability and a scale that was impressive for their time. Exchange had moved from a “garage” mentality to a datacenter approach.
We will consider Exchange 2000 and Exchange 2003 together, because these versions introduced one of the key features of Exchange to this day: Active Directory integration. Exchange 2000 was the first product to integrate directly into Active Directory. Previous versions of Exchange, including version 5.5, maintained a separate directory that defined configuration data, recipient data, and authentication data for recipients. With Active Directory integration, Exchange 2000 natively integrated recipient and authentication information so that virtually all pertinent recipient information and configuration data resided in one place. This was a huge leap forward, and it allowed Exchange to scale to the limits of Active Directory. We are aware of Exchange implementations within the confines of a single forest that number into the millions of mailboxes. Moving forward in time, Exchange is now able to take advantage of the authentication mechanisms provided by Active Directory, including NTLM and Kerberos.
Exchange 2000/2003 used administrative and routing groups as administrative and message routing boundaries, respectively. Administrators were required to plan both the administrative layout of Exchange servers as well as the message routing topology. Limited delegation of responsibilities could be achieved using administrative groups and Exchange-specific groups.
Exchange incorporated message transport standards early on using the dominant standards of the day to route mail. Exchange 2000 was no exception, introducing SMTP as the standard for message routing.
Exchange 2003 had limited management capability, with only three roles available for delegation via a Microsoft Management Console (MMC)-based administration console. No granular delegation models existed via the Exchange management utilities, and Exchange administrators tended to set very high levels of rights in Active Directory. Significant management overhead existed in order to build and maintain a granular delegation structure.
Exchange 2000/2003 could achieve role separation. Servers had differing functions, such as email storage, email routing, public folder storage, and client access for some client protocols. The drawback in this version of Exchange, however, was that it achieved role separation via configuration, not via a dedicated role. Administrators needed to enable specific features or configurations in order for a server to be a dedicated client access endpoint, which in Exchange 2000/2003 terminology was called a front-end server.
Exchange 2000/2003 could be clustered in order to archive high availability. That is, a component could fail, but the availability of email remained unaffected. Clustering was dependent on expensive SAN-based storage that introduced a high level of complexity. Often, clustered implementations had lower uptime numbers when compared to standalone implementations. These solutions had no awareness of the nature of the data that they attempted to safeguard, and administrators needed to be highly proficient with both clustering and SAN technologies in order to maintain good uptime figures.
Storage groups are Exchange mailbox and public folder databases with a shared asynchronous database-logging mechanism per group. Exchange 2003 raised the limit of the number of databases to 20 to be contained in a maximum of four storage groups in the Enterprise version.
To this day, Exchange 2000/2003 storage recommendations surface incorrectly as “best practices,” specifically:
Sacrificial spindles were often needed, which allowed extra disks to be used in order to achieve the needed IOPS. This was accomplished at the expense of unused disk capacity.
Very few choices existed to the messaging administrator in terms of how to create storage solutions. RAID 5/10/50 for database volumes and RAID 1/10 for log volumes prevailed, both as SAN-attached volumes as well as locally attached volumes in the case of smaller implementations.
Exchange 2007 was a major milestone that introduced several new concepts while improving on others. Exchange 2007 was the first version of Exchange that mandated a 64-bit architecture, albeit with a limit of 32 GB of usable memory. Technically, more memory was addressable, although it was cheaper to add more servers than to double the memory from 32 GB to 64 GB. Exchange 2003 had significant scalability limitations, due to a 32-bit memory model, which severely restricted how many mailboxes a given server could serve. Exchange 2007 discontinued a number of features, including routing groups, administrative groups, support for network-attached storage, and the Exchange Installable File System (ExIFS), among others. Nonetheless, these features were still available for the Exchange 2003 server hosting a desired feature or connector, for example, GroupWise. Exchange 2007 was the first version of Exchange to move from a centralized storage model to an application-based replication model, and it introduced the replication concepts that led to the model available via Exchange 2013.
Exchange 2007 built on the model of using Active Directory by not only storing Exchange data in Active Directory but also through leveraging the Active Directory topology for message routing instead of using Exchange 2003 routing groups.
Exchange 2007 built on the foundation provided by Exchange 2003 and introduced new features that directly related to the scalability and availability of the platform:
Exchange 2007 introduced a new management paradigm with the use of PowerShell. Management capabilities were implemented via PowerShell first and afterward through the GUI. Just as Exchange 2000 was a trendsetter for its use of Active Directory, Exchange 2007 set the standard for future products in how PowerShell was used for administration.
Administrative roles were improved over Exchange 2003. However, granular delegation capabilities still did not exist natively. Split-permission models were available so that Exchange administrators had limited permissions in Active Directory. However, this required the implementation of custom access control lists at an Active Directory object and attribute level using tools such as ADSI Edit and DSACLS. Split-permission models were difficult to create and maintain, and they were by no means self-documenting.
Whereas Exchange 2000/2003 forced administrators to become storage experts, Exchange 2007 required administrators to learn new skills, specifically how to create and maintain X509 certificates. The following Exchange 2007 management features were significantly changed or introduced:
Exchange 2007 reintroduced role separation via the concept of Exchange roles, which could be deployed together on a single server, by themselves on dedicated servers, or a combination of the two models. Exchange 2007 introduced five roles:
The primary reason for role separation was that servers were “CPU bound,” such that CPU resources were exhausted first. Role separation allowed CAS to be separated from Hub and Mailbox roles, facilitating a scaling out of Exchange functions. An Exchange 2007 CAS server and Exchange 2007 Hub server were required in every Active Directory site hosting an Exchange 2007 Mailbox server.
Roles could be deployed autonomously from each other and thus facilitated flexibility in deployment, management, and engineering. Administrators no longer needed to deploy a full server and then disable the features that they did not want to use. Management tasks could now be grouped around a set of roles as opposed to a group of servers. An extra role could be deployed if required to bolster specific capacity that might be required. For example, if the existing CAS server could not handle all incoming HTTP client traffic, then another CAS role could be deployed. Although the roles could be split out, they still needed to be updated in sequence, specifically CAS, Hub, and then Mailbox roles.
In Exchange 2007, databases were grouped together via storage groups that contained the databases and the transaction logs. Single instance storage was available for databases within a storage group.
In Exchange 2007, roles could be combined such that CAS, Hub, and Mailbox roles could coexist, although if the Mailbox role was clustered in any way, then the CAS and Hub roles could no longer be combined with the clustered Mailbox role. A resulting role combination that became quite popular was combining CAS and Hub roles over two or more machines that were highly available, using either Windows Network Load Balancing or another load-balancing mechanism and clustered mailboxes on other machines.
Exchange 2007 introduced several mechanisms for ensuring that stored mail was highly available via the Mailbox role using either traditional shared storage clustering similar in nature to Exchange 2003 or log shipping. Log shipping allows an Exchange database to be replicated from one location to another by copying the transaction logs asynchronously generated by the primary database to another location. There the logs are replayed to construct another database. Exchange 2007 supported the following cluster or log shipping-based features:
Exchange 2007 Enterprise increased the number of databases to a maximum of 50 contained within 50 storage groups. Even though a storage group could contain up to five databases each, Microsoft recommended the use of one database per storage group.
Improvements in the ESE database in Exchange 2007 gave the administrator more storage choices. Specifically, it provided the administrator with the ability to choose between SAN-based storage or Direct Attached Storage (DAS) shelves. Because of the introduction of roles as well as the CCR HA model, Exchange could scale up and out as required. Flexibility in storage choices made both scaling up and out cheaper than ever before, since DAS storage is far cheaper than SAN-based storage.
Building on the success of Exchange 2007, Exchange 2010 introduced many new features that form the basis of our understanding of Exchange 2013. Exchange 2003 and Exchange 2007 could still be upgraded from within the organization. While Exchange 2010 deprecated a number of features from both Exchange 2003 and Exchange 2007, such as Lotus Notes migration, by retaining the Exchange 2007 server hosting of the Microsoft Transporter Suite as part of the organization, these features can still be accessed. Exchange 2010 deprecated non-GUI features in the replication model, such as SCR, and it consolidated the various high-availability models available into one model. It also became the easiest version of Exchange ever to achieve a multiple-copy, highly available Exchange installation. It did so without having to reinstall Exchange (unlike every previous version of Exchange).
Exchange 2013 requires Exchange 2003 to be removed completely from the organization as an installation prerequisite. This means that a “double-hop” migration from Exchange 2003 to Exchange 2007/2010 and then from Exchange 2007/2010 to Exchange 2013 is the most natural upgrade path. As mentioned in the introduction, a consultant must be able to identify which features or product capabilities will be left behind during such an upgrade.
Exchange 2010 discontinued a number of features and concepts from Exchange 2007, some of which had been in place as far back as Exchange 2003. Thus, a number of features stand out architecturally from those that were deprecated, discontinued, or replaced:
Every version of Exchange has brought with it new features while discontinuing others. The lack of single-instance storage is still mourned by the storage community to this day. Nevertheless, this concern is only valid when thinking about high-cost storage. Single-instancing messages made a lot of sense when storage was expensive and needed to be very fast. Exchange 2010 introduced a new storage paradigm, which administrators still struggle with to this day—the ability to place databases on relatively slow and cheap disks. In Chapter 5, “Designing a Successful Exchange Storage Solution,” we will cover what changed and why, in order to leave single instancing behind and why it is no longer desirable.
Exchange 2010's use of Active Directory to store configuration and directory information is similar to that of Exchange 2007. Every subsequent version of Exchange continued extending the Active Directory schema as features were added to Exchange.
Exchange 2010 introduced a number of new features designed to prevent a particular service from abuse or from becoming overwhelmed to the point of failure:
Integrating transport rules with an Active Directory Rights Management server allowed the administrator to encrypt messages in transit, even after they had left the user's mailbox, if defined conditions were met.
Exchange 2010 delivered a new set of management tools built on the remote PowerShell features introduced with PowerShell 2.0. The GUI capabilities were enhanced via the new Exchange Management Console with greater capabilities in the MMC-based tools and a new web-based administration portal, the Exchange Control Panel.
Similar to Exchange 2007, the Exchange 2010 Exchange Management Console was built on a PowerShell-based foundation in that it executed PowerShell in order to manage Exchange. However, the 2010 version of the Exchange Management Console exposed PowerShell, which it would execute via the properties dialog box via these features. Exchange 2010 introduced a number of new management features or improvements over Exchange 2007. A description of these features follows:
The role separation concepts introduced in Exchange 2007 were maintained in Exchange 2010. However, a new high-availability model meant that the Exchange 2010 CAS, Hub, and Mailbox roles could now be combined, even if the Mailbox role was highly available. The combination of these roles onto one machine became the default guidance for Exchange 2010 in order to maximize hardware utilization. It should be noted that this guidance evolved over the life cycle of Exchange 2010 as hardware became more powerful.
Technically, the Unified Messaging role could also be combined with the CAS, Hub, and Mailbox roles, although it was not best practice to do so. An Exchange 2010 CAS server and Exchange 2010 Hub server were still required in every Active Directory site hosting an Exchange 2010 Mailbox server.
Deployment guidance has evolved significantly over the life cycle of Exchange 2010. However, there are still a significant number of deployments based on Exchange 2010 RTM or Exchange 2007 guidance. Old guidance is reflected in how roles are either fully split out to individual machines or combined so that the CAS and Hub roles share a server, while Mailbox roles that are part of a DAG are deployed separately. While the latter instance does make sense when Windows NLB is the load-balancing mechanism, since two types of clustering cannot coexist within the same OS, it should not be the default deployment option for an enterprise.
Client Access servers gained a new service, the RPC Client Access service, which allowed users to connect to their mailboxes, regardless of the location of their active database. Since databases were no longer connected to specific servers (more on this later in this section), CAS servers now acted as the MAPI endpoint, introducing near-seamless database failover.
Exchange 2010 changed the high-availability model used in previous versions of Exchange from a server-based availability model to a database-based availability model. Database availability groups (DAGs) replaced all other continuous log-based shipping mechanisms and became the most flexible database high-availability model to date, with up to 100 databases potentially participating in a 16-node DAG.
CAS arrays introduced a MAPI-based name space alongside the other HTTP-based workloads, each having their own name space. This meant that, with only two datacenters participating in a site-resilient design, Exchange 2010 administrators could define up to nine disparate types of name spaces, specifically:
Exchange 2010 Enterprise increased the number of databases to a maximum of 100. Improvements in the ESE database in Exchange 2010 gave the administrator even more storage choices, specifically the ability to choose between SAN-based storage, direct-attached storage (DAS) shelves, near-line SAS, and SATA drives. Low-cost disks could now be attached in a JBOD (just a bunch of disks) configuration.
Exchange 2010 Service Pack 1 introduced features that could integrate an on-premises Exchange deployment into Office 365 Exchange organizations. These hybrid deployments achieved a level of integration that provided a seamless experience for users. The introduction of Exchange 2010 CAS and Hub servers into an existing Exchange 2003 or Exchange 2007 organization meant that older Exchange versions could participate in, and migrate to, Office 365 Exchange.
The hybrid model required extensive configuration of both the CAS and Hub roles. However, the effort required to achieve this was massively reduced by the introduction of the Hybrid Configuration Wizard in Exchange 2010 Service Pack 2.
Exchange 2013 introduces some of the most significant changes to date in Exchange, including a single code base for customer, Office 365, or partner-hosted deployments. Quarterly cumulative updates, as opposed to service packs, allow customers and hosting partners to take advantage of new fixes and features as they become available in Office 365.
Architecturally, Exchange 2013 shares many concepts and features with previous versions of Exchange, especially Exchange 2010. While the Exchange server role functionality is present as in Exchange 2010, its implementation in Exchange 2013 is different.
Even though Exchange 2010 guidance recommended multi-role servers, many deployments still used individual physical or virtual servers per role, causing massive underutilization of CPU and memory resources on many of these servers. (See the sidebar in Chapter 1 called “Requirements Elicitation and the Long Trail of Obsolete Best Practices.”)
We hope that as we reviewed the history of Exchange, you gained an understanding of why role separation was introduced and where it and role amalgamation made sense. Exchange 2013 introduces a set of new paradigms, while a vast amount of functionality from previous versions of Exchange is retained or improved.
Exchange 2013 ships with the following design goals in mind:
The following list summarizes the major areas of change to Exchange 2013 architecture from Exchange 2010, which will be addressed in greater detail throughout the rest of this chapter:
Role Separation
Transport
Management
High Availability
Storage
Exchange 2013 also ships with new logic, which has been rewritten so that RPC calls between functionality tiers, such as Transport submitting email directly to the store via MAPI, and so forth, have been eliminated. This level of isolation builds on the design goal of failure isolation, since every server becomes an island.
Furthermore, moving away from five roles, each representing a potential building block in Exchange 2010, Exchange 2013 introduces a new model comprised of only two: the Client Access server and the Mailbox server roles.
Exchange 2013 offers a number of architectural benefits over previous versions of Exchange. These will be explored in greater detail throughout this chapter:
Exchange 2013 server roles overcome a number of boundaries introduced by Exchange 2007/2010 server roles. The following new capabilities are also introduced:
Throughout the rest of this chapter, we will explore the new architecture of Exchange 2013.
Exchange 2013 discontinued a number of features and concepts from Exchange 2010. While a number of individual features were deprecated, discontinued, or replaced, those that stand out architecturally are as follows:
While the loss of some features has been mourned more than others, the new GUI has been met with some criticism and disapproval. The Exchange 2010 MMC-based GUI relied on remote PowerShell, which massively increased its management and RBAC capabilities, while sacrificing speed. Exchange 2013 introduces a web-based GUI, which is fast and feature rich, giving the administrator more configurability than in any previous version of Exchange since Exchange 2007. However, the new GUI caused the loss of the ability to show the PowerShell-generated management operations, arguably one of the most popular management features of Exchange 2010. This feature is expected to return via a later service pack.
Exchange 2013 is available in two editions: Standard and Enterprise. These editions are limited to 5 and 50 databases, respectively. As with Exchange 2010, specific functionality is determined by the product key used to license the Exchange server. Standard and Enterprise editions can both take advantage of high-availability features such as DAGs, limited only by the number of databases available per edition.
The Exchange Hybrid edition is available for hybrid deployments, and while its name indicates that it could be could be considered a separate edition from the Standard or Enterprise editions, the license model by which it operates is its only distinguishing factor. Introduced with Exchange 2010, this edition is available for free when used as part of an Office 365 hybrid deployment. To obtain a Hybrid edition product key, contact Office 365 support.
Transport in Exchange 2013 has changed from Exchange 2010. Here is a brief summary of the changes and benefits in Exchange 2013:
For an examination of the Exchange 2013 transport pipeline and the transport components, please review the Exchange 2013 Client Access server and Mailbox server sections of this chapter. The following section examines the next-largest change in Exchange 2013: transport mail flow.
Earlier, we stated that messages, which originate externally to the organization, are handled by the Front End Transport service on the Client Access server role and proxied to the Transport service on the Mailbox server role. Messages from within the Exchange organization are received by the Transport service on the Mailbox server role via one of the following methods:
Similar to Exchange 2010, all messages sent or received must be categorized by the Transport service on the Mailbox server role in order to be routed or delivered. Mail routing is achieved using the same least-cost routing algorithm used in Exchange 2010. Exchange 2013 defines a delivery group as a collection of transport servers responsible for delivering messages to a routing destination. Post categorization, messages are placed in a delivery queue for one of the following delivery groups:
The routable DAG is a new routing destination, which is defined simply as a group of Exchange 2013 Mailbox servers that belong to the same DAG. Routable DAGs may span Active Directory sites as a routing destination. Messages will be delivered to the closest DAG member. The final delivery location within the routable DAG will be the server hosting the active database copy.
Exchange 2013 introduces a number of new management features or improvements over Exchange 2010. A description of these features follows.
The Exchange Administration Center (EAC) is a complete replacement for the MMC-based Exchange Management Console in Exchange 2010. With a few exceptions, all Exchange 2013 management operations can be performed via this new web-based GUI. PowerShell is required for those operations that cannot be performed within the GUI. The Exchange Administration Center presents a single, unified interface for Exchange Online and Exchange on-premises when operating in Hybrid mode.
The Outlook Web App has been completely rewritten to look and feel like a tablet-optimized application. It supports the Office Web App extensibility model so that it may be extended using web-based applications via the Office Marketplace or an on-premises equivalent. As with Exchange 2010, the Office Web App ships with support for multiple browsers. However, because of the capabilities of HTML5 and offline browser databases, the Office Web App ships with an offline mode, similar in concept to Outlook's cached mode.
Exchange 2013 introduced a new set of features based on improved transport rules, including prebuilt Data Leak Prevention (DLP) templates for common scenarios. DLP integrates with both Outlook MailTips and Transport Rules to offer a configurable experience to the end user. A range of actions may be chosen by the administrator, which range from a Non Delivery Report (NDR) of the message down to a MailTip, warning the user about sensitive information contained in the message body.
Site mailboxes have been introduced in Exchange 2013. They offer a way to share data between Exchange mailboxes and SharePoint team sites via a shared mailbox. Exchange 2013 and SharePoint 2013 have become aware of each other along this integration point. Documents submitted via Outlook into the site mailbox are uploaded to the correct SharePoint document library. Reciprocally, SharePoint users are able to view the shared email via OWA without requiring Outlook, while users who prefer to use Outlook may consume the relevant SharePoint documents without leaving the application. Outlook 2013 is required to participate in a site mailbox.
Lync 2013 is able to store compliance information into the Exchange mailbox dumpster as opposed to using SQL servers to store data. If a user is placed on hold in Exchange 2013, they are automatically placed on hold in Lync 2013, as long as Exchange and Lync are configured accordingly.
SharePoint is able to search and locate Exchange and Lync discovery data via a single integrated eDiscovery portal. Discovery capabilities in Exchange have been retained using the EAC. However, the eDiscovery portal introduces significant added functionality, such as real-time searching.
The hosting model based on Address Book Policies introduced in Exchange 2010 SP2 persists in Exchange 2013. Hosting in Exchange 2013 is based on one of a number of certified control panels, which are available along with published guidance at the following link:
http://technet.microsoft.com/en-us/exchange/jj720331.aspx
Role separation in Exchange 2013 still exists, but the architecture is quite different from Exchange 2010. Exchange 2013 has simplified the number of roles from five down to two in Exchange 2013: Client Access server and Mailbox server roles.
A significant change in Exchange 2013 over Exchange 2007 and Exchange 2010 is the banning of RPC for inter-role communications. This includes the RPC functionality used in what used to be Exchange 2010 CAS and Hub roles when communicating with the Exchange 2010 Mailbox role. In Exchange 2013, WAN-friendly protocols such as SMTP and HTTP are used for inter-server role communication, even if the servers are adjacent to each other within the same Active Directory site. For example, the Transport service in Exchange 2013 no longer uses RPC to write an email to the destination mailbox database on a mailbox server within the same Active Directory site. If an email needs to be submitted to an adjacent server, it will be done via SMTP. RPC is still used, but only within a Mailbox server role and no longer between servers.
Client Access servers in Exchange 2013 are quite different than the functionality rich, code-laden CAS role in Exchange 2010. The Exchange 2013 Client Access server role (CAS 2013) is a thin, stateless Layer 7 protocol proxy that requires very few server resources and may be deployed together with the Exchange 2013 Mailbox role or by itself. No files or data will ever be written or stored on the CAS 2013 role. Similar to Exchange 2010, CAS 2013 must be deployed on a domain-joined machine and not placed in a DMZ.
By itself, CAS 2013 without a Mailbox role is unable to service requests of any sort, because the Client Access server logic now resides on the Exchange 2013 Mailbox server role. CAS 2013 performs three major functions:
These three functions are performed for the two components hosted by CAS 2013: client protocols (HTTP, POP, IMAP, or SIP) and SMTP.
A fundamental concept for CAS 2013 and Mailbox 2013 is that the Mailbox server hosting the active database copy for a given mailbox is always the connection endpoint. CAS 2013 determines the correct endpoint for all incoming protocols, and it proxies traffic to the same Mailbox server that is hosting the active copy, irrespective of which CAS 2013 server the session originated, and it will do that for Mailbox servers inside or outside its own Active Directory site. The Exchange 2013 Mailbox server hosts the logic, and it is the endpoint for all protocols, including client and transport traffic. These concepts are illustrated in Figure 3.1, which shows client traffic passing through a Layer 4 load-balancing device before reaching the Exchange 2013 CAS server role.
Figure 3.1 Client traffic and Layer 4 distribution
The Mailbox server hosting the active database copy, as opposed to the Client Access server, now maintains affinity and persistence for a user's session. In this model, CAS servers are loosely coupled to Mailbox servers. The same Mailbox server is responsive to the user's requests, irrespective of which CAS server the request originates from. Effectively, this means that as long as traffic can reach the Exchange 2013 CAS server at a Layer 4 level, it will make the networking decisions previously required by a Layer 7 load balancer. The advantage of this model is that a number of Layer 4 load-balancing mechanisms become available, including the following:
The available range of load-balancing mechanisms as well as how to make a choice for your organization will be discussed in Chapter 4, “Defining a Highly Available Messaging Solution.”
Earlier in this chapter, we stated that Exchange 2013 has reduced the potential number of name spaces required by two: the RPC client access name space for the primary and secondary datacenters. This does not mean that client-side MAPI has been discontinued as a protocol. Rather, it means that MAPI over TCP has been discontinued and that RPC over HTTP (Outlook Anywhere) is the only remaining connectivity option. Clients have had the option of using MAPI via either TCP or HTTP since Exchange 2003. Exchange 2013 reduces the available transport mechanisms for MAPI down to TCP.
An Outlook client connecting to Exchange for the first time is supplied with several connection endpoints that appear to be quite similar to an Exchange 2010 Autodiscover request. The connection endpoint, however, is no longer an Exchange server's name. It is now in the form of a GUID and a UPN suffix, for instance, GUID@UPN similar to b0f54714-5af0-4564-a71b-ebe8b780f0ca@exchange-D3.com. Autodiscover will also supply the HTTP connection endpoints required for Outlook.
Once Outlook is configured, it will connect to the Exchange 2013 CAS via HTTP, supplying the GUID@UPN endpoint with which it has been configured. Remember that CAS is loosely coupled to Mailbox. Using the supplied endpoint, CAS will query Active Directory for location information as well as the Active Manager component to determine which Mailbox server is currently hosting the active database copy. Once CAS has the required information, it is able to proxy the request to the correct Mailbox server or redirect it to another CAS server in the same forest.
A significant advantage to using the GUID@UPN endpoint as opposed to an Exchange server name is realized during a switchover or a failover event. If the connection to the Mailbox server is lost due to a switchover or a failover event, and Outlook is reconnected via CAS to the new active database copy, the connection endpoint remains the same, that is, GUID@UPN as opposed to a new RPC connection endpoint. Outlook no longer displays the “The administrator has made a change which requires you to restart Outlook” message since, as far is it is concerned, no change has occurred.
Exchange 2013 reduces the number of name spaces required for a two-datacenter scenario by two name spaces: the primary and secondary client RPC name spaces. This also means that the minimum number of name spaces required for a given Exchange 2013 deployment is two: the Autodiscover name space and the Internet Protocol name space.
For example, in a single datacenter using the Exchange-D3.com name space, we need the following:
autodisover.exchange-D3.com mail.exchange-D3.com
A graphical representation of the minimum number of name spaces required is shown in Figure 3.2. The details of each potential protocol are found in Table 3.1.
Figure 3.2 Single name space

Table 3.1 Name spaces and protocols—single name space
| Name | Protocol |
| Autodisover.Exchange-D3.com | Autodiscover |
| Mail.Exchange-D3.com | SMTP |
| Mail.Exchange-D3.com | Outlook Anywhere |
| Mail.Exchange-D3.com | EWS |
| Mail.Exchange-D3.com | EAS |
| Mail.Exchange-D3.com | OWA |
| Mail.Exchange-D3.com | ECP |
| Mail.Exchange-D3.com | POP/IMAP |
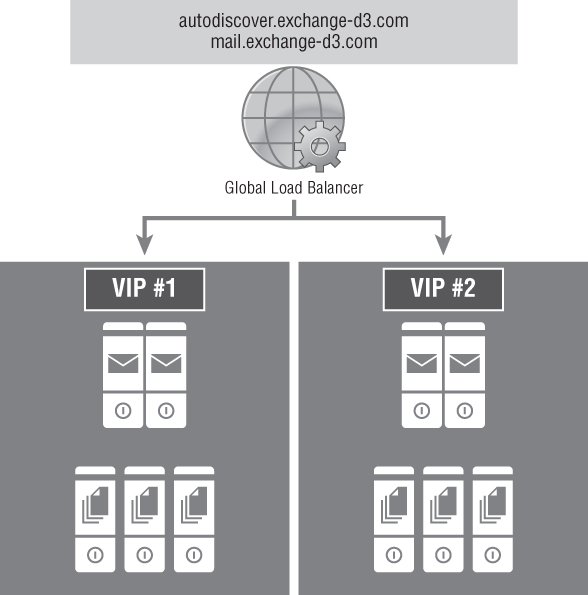
We previously stated that the Mailbox server hosting the active database copy for a given mailbox is always the connection endpoint. The Exchange 2013 Client Access server will proxy traffic to the active database copy even if it is in another Active Directory site. Understanding this logic allows us to build a single global Internet Protocol name space using a mechanism as simple as DNS round robin or a more advanced mechanism, such as a global load balancer. Assuming that connectivity from any point around the globe is roughly equal, and that connectivity between datacenters is high speed with acceptable latency in order to guarantee a positive user experience, we are able to build a two-datacenter scenario using the same two name spaces. This is illustrated in Figure 3.3 for a similar protocol breakdown as detailed in Table 3.1.
Figure 3.3 Single name space with global load balancer
Autodiscover is a major component of Outlook connectivity because, without it, Outlook would require manual configuration to connect to a mailbox. Outlook will perform an autodiscover under the following circumstances:
When planning Exchange name spaces, Autodiscover is the only name that needs to follow a number of potential conventions. You need to consider it if you are planning for external or internal Autodiscover.
External Autodiscover behavior will see Outlook attempt to connect to the following URLs in order, based on the SMTP domain specified in the user's email address:
https://<smtpdomain>/Autodiscover/Autodiscover.xml
https://autodiscover.<smtpdomain>/Autodiscover/Autodiscover.xml
http://autodiscover.<smtpdomain>/Autodiscover/Autodiscover.xml
If any of these fail, Outlook will perform a DNS SRV record lookup or a local registry query.
If Outlook manages to connect to Autodiscover, Autodiscover will supply the rest of the connection information required in order to connect to the user's mailbox. One aspect of using Autodiscover is that only one name space needs to be named in a predictable manner. The naming convention for other name spaces is largely open ended, as long as Autodiscover is able to reveal their location.
Internal Autodiscover behavior will see an authenticated Outlook client query Active Directory for service connection point (SCP) records pointing to Exchange CAS servers, filtering those SCP records for a well-known GUID. Every CAS server publishes an SCP record with Autodiscover information, which results in a list of available SCP records. Once a list of SCP records has been returned, Outlook will choose the oldest record and the following attributes:
Using the URL contained in serviceBindingInformation, Outlook will connect to Autodiscover and obtain the rest of its profile information to connect to the given mailbox.
Autodiscover returns the information required to configure the profile including EXCH and EXPR nodes, which point to internal and external configuration items, respectively. Traditionally EXPR points to the protocol used to connect a client to Exchange via RPC over HTTP. Exchange 2013 Autodiscover includes a new node type, EXHTTP, for Outlook 2013 clients. Autodiscover will return two EXHTTP nodes: an internal Outlook Anywhere URL (HTTP URL) and an external Outlook Anywhere URL (HTTPS URL).
Outlook 2013 will attempt to bind to each URL, running from the first to the last one. If it manages to bind via the HTTP URL, then it will establish an HTTP-based Outlook Anywhere session (as opposed to an HTTPS session). While you may be tempted to think that this eliminates certificate planning, you should note that the other services that Outlook requires, such as Exchange Web Services and the Offline Address Book among others, still require certificates.
As with the client protocol components, the SMTP component of CAS functions as a Layer 7 proxy. Since the Exchange 2013 Mailbox server role houses the equivalent of the Exchange 2010 Hub Transport role, a new component emerges on the CAS 2013 server role: the Front End Transport service. Similar to the client protocol components, all inbound and outbound SMTP protocol traffic passes through CAS 2013 for the Exchange organization and, if desired, all client SMTP traffic. The Front End Transport service is completely stateless. As a Layer 7 protocol proxy with full access to the conversation occurring within the SMTP protocol, it does not store any data on the server role, nor does it perform any sort of message bifurcation. The Front End Transport service can filter messages based on connections, domains, senders, and recipients.
The Front End Transport service listens for SMTP traffic on the following three ports:
The Front End Transport service receives an inbound message and locates a single destination, which is a healthy transport service on a Mailbox server role. Based on a number of rules in the Transport section of Exchange 2013 that will be discussed later in this chapter, it proxies the connection to the Transport service.
Exchange 2010 guidance recommended deploying CAS, Hub, and Mailbox server roles on the same Exchange server, as a multi-role or “brick” configuration. The term brick implies a standardized unit or building block, which may be replicated inexpensively. This model is used quite successfully in large datacenter or cloud-based configurations. Thus, the benefits of a brick or standardized configuration hold true with three or three hundred servers. The Exchange 2013 Mailbox role installed as a multirole server includes the following equivalent Exchange 2010 server roles:
No Exchange 2013 components may be deployed separately; that is, the Client Access, Hub, Mailbox, or Unified Messaging server roles cannot be installed on their own. However, additional Exchange 2013 Mailbox server roles can be deployed and used purely as Unified Messaging servers if required, or more servers can be added for the sake of additional capacity if additional roles are required.
The Information Store process has been completely rewritten in C# (a .NET-based language) from C and C++, thereby moving it to what is known as managed code as opposed to unmanaged code. As part of the rewrite, the Information Store service has been split into two processes: Microsoft.Exchange.Store.Service.exe and Microsoft.Exchange.Store.Worker.exe. Instead of having only one Information Store process responsible for all of the mounted databases as in previous versions of Exchange, the Worker process spawns a new Store service for every mounted database. If a store process were to suffer a catastrophic failure of some kind, only one database would be affected at any one time. Another effect of process isolation is that database failover times have been reduced.
Due to the rewrite and further optimization of the Mailbox database structure, a 50 percent drop in IOPS has been achieved over Exchange 2010. We will cover this in depth in Chapter 5, “Designing a Successful Exchange Storage Solution.”
Public folder databases have been discontinued in favor of storing public folders in public folder mailboxes. If these mailboxes participate in a database availability group, then public folders are as highly available as any other mailbox. All public folder PowerShell cmdlets are still available, but the public folder database cmdlets have been discontinued.
The first public folder mailbox contains the public folder hierarchy; successive public folder mailboxes contain a read-only copy of the hierarchy and the public folder contents. Administrators have the option of choosing the public folder mailboxes when creating or moving public folders. Public folder mailboxes are subject to the same management requirements as other mailboxes in terms of size and quota management.
A major shift for administrators is that public folders have moved to a single-master model. Previous versions of Exchange employed a multi-master model, where every instance of a public folder was writable and would replicate changes to all other public folder instances. In Exchange 2013, a public folder is writable to one network location only. Specifically, it will only be writeable in the mailbox database containing the public folder mailbox.
The Transport service on the Exchange 2013 Mailbox server role is similar to the Exchange 2010 Hub Transport server role, hosting both Send and Receive connectors, as well as the queuing and routing of the logic required to process messages. The Transport service listens for SMTP traffic on the following ports:
Typically, messages that originate from outside the Exchange organization are handled by the Front End Transport service and then proxied by the Front End Transport service to the Transport service on the Mailbox role. The Transport service is one of a number of transport-related services on this role that help process incoming and outgoing messages as follows:
The Transport service is included with every Mailbox server role and, for all intents, is a duplicate of the Hub Transport server role in Exchange 2007 and Exchange 2010. All SMTP mail flow for the Exchange organization is processed by the service, which includes message categorization and message content inspection. Reenforcing the concept that every server is an island, the Transport server no longer delivers email directly to mailbox databases via RPC. This task is now completed by the Mailbox Transport service. The Transport service is responsible for overall message routing among the Mailbox Transport service, the Front End Transport service, and itself.
The Mailbox Transport service is another service that is included with every Mailbox server. This service comprises two different services: the Mailbox Transport Submission service and the Mailbox Transport Delivery service. The Mailbox Transport Submission service builds on the concept that every server is an island by using RPC calls to retrieve messages from local mailbox databases, and it submits these messages via SMTP to the Transport service. It does this without queuing any messages in a local queue. The Mailbox Transport Delivery service receives SMTP messages from the Transport service and again, building on the concept that every Exchange 2013 server is an island, uses RPC to perform a delivery to a local mailbox database.
Unified Messaging is a standard feature of Exchange 2013. This functionality is split between the Exchange 2013 Client Access and Mailbox server roles. The Exchange 2013 Client Access server role includes the Microsoft Exchange Unified Messaging Call Router service, while the Exchange 2013 Mailbox server role includes the Microsoft Exchange Unified Messaging service. Neither of these services can be uninstalled. They may be disabled, however, if desired.
Unified Messaging ships with the following enhancements:
Exchange 2013 continues the trend that began with Exchange 2010 of a database-based availability model as opposed to the server-based availability models that were used in previous versions of Exchange. Along with the simplification of Exchange server roles, Exchange 2013 simplifies high availability planning down to two building blocks: the client access array and the database availability group.
Client access arrays are different than those in Exchange 2010 in that they do not represent RPC or MAPI endpoints. Exchange 2013 Client Access server arrays (CAS arrays) are a grouping of Exchange 2013 Client Access servers, represented by a single DNS-based name. In Exchange 2013, CAS arrays are no longer RPC endpoints. Rather, they are HTTP-based endpoints for all client protocols. CAS arrays are grouped behind a single DNS name and load-balanced using any of the supported Exchange 2013 load-balancing methods.
Database availability groups (DAGs) are the basis for all storage-based high availability in Exchange 2013. Though similar to DAGs in Exchange 2010, they offer some significant improvements:
These improvements will be covered further in Chapter 5.
DAG networks in Exchange 2010 required administrators to collapse the networks created by deploying DAG members in multiple subnets with multiple network interfaces. These would be created automatically as DagNetwork01, DagNetwork02, and so on. Exchange 2013 requires the administrator to mark those networks that are used for MAPI and those that are used for replication. It then automatically collapses the DAG networks into their appropriate MAPI and replication networks. This behavior is enabled by default, and it may be configured using the EAC or using the Set-DatabaseAvailabilityGroup cmdlet and setting the ManualDagNetworkConfiguration parameter to $TRUE.
Best copy selection (BCS) is the algorithm used in Exchange 2010 to determine the best available mailbox database copy to activate based on copy queue length, replay queue length, database status, and content index status.
Best copy and server selection (BCSS) is the Exchange 2013 version of BCS, and it is still performed by the Active Manager component. Now, however, it includes four indicators of Exchange 2013 health status supplied by Managed Availability as part of the selection status. If BCSS detects that is was invoked as a result of Managed Availability, then an additional rule is added to BCSS, which mandates that the components that failed in the server that are currently holding the active copy (for example, OWA) must be healthy on the target server.
The four new status indicators are evaluated as part of database selection in the following order:
Exchange 2013 ships with the capability to monitor health and, based on the health of specific components, take remedial action. Health is monitored using several probes that inspect the health of Exchange at multiple levels. If a component is degraded or deemed unhealthy, then Managed Availability will attempt to recover the component via one or more actions. These actions may include a service restart, a server restart, or even marking the server as unavailable.
If OWA or other components fail on one of the nodes within a DAG, and Managed Availability is unable to restart OWA via recycling the OWA application pool, or it is unable to restart the affected services and return it to a healthy state, then it will select a node within the DAG and failover the databases affected by the OWA failure to the next available node where OWA is healthy.
Managed Availability runs on both the Client Access server and Mailbox server roles. Managed Availability comprises the following components:
Managed Availability manifests itself as two services: Exchange Health Manager Service (MSExchangeHMHost.exe) and Exchange Health Manager Worker process (MSExchangeHMWorker.exe), which are the controller and worker processes, respectively. The controller process builds, executes, starts, and stops the worker process so that, in the case of a worker process crash, no single worker process becomes a distinct point of failure. The worker process, as the name implies, performs the unit of work selected by the controller process.
Managed Availability health checks span the entire Exchange 2013 spectrum of workloads. They include the functionality that shipped as scripts in Exchange 2010, for example, the Exchange 2010 CheckDatabaseRedundancy.ps1 script, which checks that at least two healthy copies of a replicated database exist and generates an event log if they do not. As in Exchange 2010, Managed Availability still performs the same checks, and it alerts administrators using event log notifications. However, in Exchange 2013, it now includes the ability to generate an appropriate action.
Exchange 2013 builds on the Exchange 2010 concepts of shadow redundancy and the transport dumpster to ensure that messages are successfully delivered by keeping redundant copies of messages. Shadow redundancy is now aware of both Active Directory sites and DAGs as transport high-availability boundaries. The transport dumpster concept has been retained, improved, and renamed to Safety Net.
Safety Net stores messages that have been successfully processed by the server in a Transport service queue on a Mailbox server for a default period of two days. However, when compared with the Exchange 2010 transport dumpster, Safety Net does not require a DAG, and it will also function for individual Mailbox servers in the same Active Directory site.
The key differentiator for Safety Net is guaranteed mail delivery compared to best effort mail delivery for the transport dumpster. Thus, the only configurable parameter for Safety Net is the retention period of messages. Messages are stored on the destination Mailbox server as well as Mailbox servers that participated in shadow transport. These are known as the Primary and Shadow Safety Nets.
If required, messages are resubmitted from Safety Net automatically after a mailbox database failover within a DAG or a lagged mailbox database copy is activated. Message resubmission is initiated by the Active Manager component of the Replication service, and it requests message resubmission over a specific time period for a specific mailbox database. If the Primary Safety Net becomes unresponsive, or if it is unavailable within 12 hours, Active Manager will revert to the Shadow Safety Net.
We will discuss the implications of these features and how to apply them in Chapter 4.
Exchange 2010 Enterprise reduced the number of databases to a maximum of 50. Improvements in the ESE database in Exchange 2013 allow the administrator to retain the storage choices from Exchange 2010. Additional details on these improvements will be addressed in Chapter 5.
Building on the success of Exchange 2010, Exchange 2013 continues integration with Office 365, known as hybrid deployments, such that the on-premises organization and the Office 365 tenant appear to be a single Exchange organization. Exchange 2007 and Exchange 2010 organizations may also benefit from an Exchange 2013 hybrid configuration. In order to be deployed, however, it requires at least one Exchange 2013 CAS and Mailbox role running Exchange 2013 Cumulative Update 1 or later. A number of improvements and new configurations exist. These will be covered in Chapter 7, “Hybrid Configuration.”
Exchange 2013 is the newest messaging platform to be released by Microsoft, and it forms the basis for new enterprise as well as ongoing Office 365 deployments.
We started this chapter by noting that the history of Exchange is relevant in order to appreciate the feature set of Exchange 2013. We also made the point of stating that the features that were introduced and later deprecated in previous versions of Exchange have driven certain deployment patterns, which may no longer be relevant.
It is worth restating that, as a consultant, you should know which new and which deprecated features are relevant to your customer. If you're facing an Exchange 2000/2003/2007/2010 upgrade, or even an Exchange 5.5 upgrade, you should be able to articulate the gains and losses of moving to the newer platform.
If you are reading this chapter as background for building an Exchange organization using a structured approach, then we suggest that you review both Chapter 1 and Chapter 2 in this book to consolidate your approach. As the newest version of the Exchange platform, Exchange 2013 is feature and functionality rich. However, we suggest that you take the time to understand the deployment choices that are available and implement according to requirements and not features. Armed with the information provided in this book, you will be able to design and deploy a successful messaging solution.