Figure 5.1 Areal density increase over time

Chapter 5
Designing a Successful Exchange Storage Solution
Over the last 16 years, the adoption of Microsoft Exchange Server, which began in earnest with Exchange 5.5, has expanded dramatically. In the beginning, email was not a critical service for all organizations, and web access and email were sometimes reserved for those at higher levels in the organization who were trusted not to misuse it. Over time, email has become a pervasive application, and it is now a primary communication medium for most organizations.
Exchange storage has undergone a similar evolution. Back in 1996, the focus was primarily on making the best use of costly hard disk capacity. In recent years, however, the focus has shifted toward being able to make use of larger and, most significantly, cheaper disks.
Before diving into the process of Exchange Server storage design, we will spend some time discussing the history of the product and why storage has been the subject of such intense focus from both the Exchange product group and the IT community. We will then examine how to approach Exchange storage design in Exchange Server 2013, including the data you will need, the tools that are available, and how to validate the solution that you propose.
As mentioned, Exchange has been around for quite a while, and it has been adapted to the changing landscape of email. Quite often, especially if they have skipped a few versions of Exchange, people are shocked at how the storage recommendations for the latest version have evolved. We find the best way to remedy this situation is a brief walkthrough of the history of Exchange and how it has evolved to meet changing demands. This helps us identify trends in email usage and understand why Exchange has progressed as it has.
These versions represented the very early days of Exchange Server outside of Microsoft. Usage increased rapidly with the release of Exchange Server 5.5, and many IT shops struggled to deal with Exchange storage for the very first time. The most common approach to Exchange storage design during this time frame was to fill the server chassis with hard disk drives and then to create a RAID 5 array for the large Exchange databases and a RAID 1 mirror to hold the log files. If a performance bottleneck occurred, more Exchange 5.5 servers were deployed and the workload was shared among the servers until the end-user experience became acceptable.
The Exchange database schema in this time frame was optimized to make extremely efficient use of free space on hard disk drives because of their small capacity and very high cost. The primary goal for Exchange versions 2000 and beyond was to improve the performance of Exchange in order to take better advantage of hardware and to better utilize the new clustering technology to provide higher availability with fewer servers.
Exchange 2000 allowed more and larger databases on each server, but it retained the goal of making the best use of available hard disk space. The enhancements brought with them new challenges for Exchange storage design, such as having to provide a backup solution for the additional data that Exchange could now store and meeting the increased storage Input/Output Operations Per Second (IOPS) performance requirements that were the result of being able to store more mailboxes in each database on each Exchange server or cluster.
Microsoft also began to encourage clustered high availability with Exchange 2000 and Windows 2000. This brought with it the additional requirement for shared storage that often resulted in a complex storage area network (SAN).
Exchange 2000 caused design teams and storage vendors to deal with storage complexity for the very first time, and many service delivery managers were forced to address the inevitable consequences of operating a complex infrastructure—even one that was allegedly highly available and that could never fail. When things did go wrong, they typically did so with exquisite complexity.
Shared storage clustering required a precise recipe of a particular Windows version, host bus adapter (HBA) device drivers, HBA firmware, SAN fabric switch firmware, and SAN storage firmware to remain even vaguely reliable in the early days. Embarrassingly, it was not unheard of that customers would attempt to implement such solutions in order to increase their Exchange service availability, only to discover that they had actually made things worse than with their previous Exchange Server 5.5 installations, and they did so at great cost.
Exchange 2007 provided a solution that materially improved service availability and performance at a much lower cost. It was also capable of meeting the growing need for much larger mailbox sizes.
Exchange 2007 brought about a radical change in storage technology. Continuous cluster replication (CCR) was a new high-availability model that did not require a shared storage solution. Combined with an I/O reduction of up to 70 percent (when compared to Exchange Server 2003) and site resiliency technology, this enhancement produced a paradigm shift in Exchange storage design.
The reduction in I/O and the introduction of CCR meant that it was no longer necessary to deploy a shared storage solution to achieve high availability. This allowed Exchange to make use of less complex and, more crucially, less expensive storage solutions than in previous Exchange versions. This not only reduced the capital expenditure required for Exchange 2007 hardware, but it also reduced deployment and operational costs due to the reduction in storage complexity.
CCR also brought with it support for up to 200 GB databases. It also provided for two copies of each database plus a third copy maintained by standby continuous replication (SCR) in a secondary site. The introduction of multiple database copies stored on physically independent storage resulted in a measurable increase in Exchange service availability for most customers plus the ability to provide end users with much larger mailboxes.
The downside of CCR was that design teams that stuck with their expensive storage infrastructure often could not justify the extra costs of deploying a CCR/SCR solution, or they had to limit the size of mailboxes to keep storage costs down. In many cases, customers kept using their SAN storage to take advantage of their enterprise backup infrastructure and to get the ever-growing amount of Exchange data backed up in an acceptable time frame.
For the first time, storage choice was significantly affected by the type and success of Exchange high-availability solutions. Customers staying with SAN storage were mostly using the legacy single copy cluster (SCC) that was available in previous versions of Exchange, while customers using cheaper directly attached storage were generally adopting the new CCR/SCR technology and benefitting from improved availability and reduced costs. In extreme cases, customers who had chosen expensive SAN storage, but who still wanted to use CCR, would store both the active and passive copies on the same storage array. This added both cost and complexity, but did not improve service availability.
Even though IOPS had been reduced by 70 percent from Exchange 2003, the IOPS requirements for Exchange Server 2007 were still relatively high and most deployments were still using 10K rpm disk spindles in RAID 10 to meet the combination of performance and capacity.
Exchange Server 2010 made better use of cheap, directly attached storage in order to entice more enterprise customers into using the new continuous replication cluster technology. Exchange Server 2010 matured the CCR/SCR model in database availability groups (DAGs). A DAG allowed up to 16 copies of each database and enabled each database to have multiple database copies. IOPS requirements were reduced an additional 70 percent, and the I/O profile for Exchange was modified to make much better use of cheaper 7.2K rpm hard disk drives.
With Exchange Server 2010, for the first time customers could also choose to design Exchange storage to use 7.2K rpm SAS hard drives with no RAID JBOD (just a bunch of disks). They also could now rely entirely on the Exchange continuous replication solution (DAG) to provide database availability.
Being able to use cheaper and slower 7.2K rpm hard disk drives came at a cost. The database schema and internal tables within the database were optimized to improve I/O performance by organizing items in a sequential manner. This change caused single-instance storage to be lost and Exchange to prefer sequential positioning of data to making use of every tiny morsel of free space within the database. The impact of this change was that Exchange databases were now larger than in previous versions despite the Exchange product group having introduced database compression that was intended to compensate for the growth.
Design teams now had more flexibility than ever before because SAN, DAS, and JBOD were all viable options depending on the solution requirements. The storage and database copy layout flexibility provided by Exchange DAGs complicated the Exchange storage design process. Design teams began to ask the obvious questions:
The increased flexibility provided by the database availability group model placed increasing importance on a good design process and requirements definition. With Exchange Server 5.5, storage choices were limited, and thus it was difficult to get it wrong. With Exchange Server 2010, the available storage choices ranged from expensive SAN storage arrays with multiple parity, right down to cheap, locally attached JBOD 7.2K SAS spindles.
For customers who did adopt the simple and cheap JBOD model, one problem became increasingly apparent. JBOD disk spindles were increasing in size, with some manufacturers listing 3 TB–4 TB disk spindles in 2012. Yet the maximum recommended Exchange 2010 database size was 2 TB.
The IEEE suggests that mechanical disk platter areal density will increase 20 percent per year for the rest of the decade. Both Hitachi and IBM are predicting that 6 TB hard disks will be commonly available during 2013. In contrast, random IOPS performance for mechanical hard disks has remained almost static over the last 10 years. Random IOPS performance is mostly governed by hard drive rotation speed; however, increases in rotational speed also bring with them large increases in cost and power. The most common format for capacity and performance in Exchange 2010 storage is 7.2K rpm 3.5”. These disk drives vary in performance from 50–65 random IOPS per spindle depending on the manufacturer. There is no expectation that IOPS per-spindle performance will increase in the near future, and so Exchange Server 2013 must be able to make use of these larger capacity disk spindles.
Exchange Server 2013 is a major new release and, as such, the Exchange product group invested in the key development areas that were projected to yield the largest benefits to both customers and the teams that run Exchange Online. A number of the product revisions centered on database and storage issues, many of which were needed to address problems in Exchange Server 2010, while others were added to deal with trends within the industry that Exchange 2013 would need during its 10-year life cycle. For example, the following issues existed in Exchange Server 2010 and needed to be resolved.
As shown in Figure 5.1, magnetic disk areal density has been increasing dramatically. This directly affects how much capacity each drive platter can store and thus how much capacity a drive of each form factor can provide. Historically, areal density increased by 40 percent a year. In 2010, however, the IEEE suggested that this increase had slowed to 20 percent a year.
Figure 5.1 Areal density increase over time
Exchange Server 2010 had started to make better use of larger capacity disks. However, trying to use a spindle much larger than 2 TB JBOD was problematic because of Microsoft's recommendation not to exceed a 2 TB mailbox database and not to store multiple mailbox databases on a single spindle.
During the life cycle of Exchange Server 2013, most storage vendors are predicting that they will be making 6 TB–8 TB 3.5” 7.2K rpm disk drives. Ideally, this means that Exchange Server 2013 should be able to use an 8 TB 7.2K rpm spindle.
Despite constant increases in areal density and storage capacity, the random IOPS performance for mechanical disk drives has remained fairly static. This is largely due to the physics involved in mechanical hard drive I/O performance. The obvious question is, why don't we use solid-state (SSD) technology, which can provide extremely high IOPS for each device? Not surprisingly, the answer is cost, as shown in Table 5.1.
Table 5.1 SSD vs. mechanical hard drive cost (at time of writing)

The prices in Table 5.1 show that solid-state drives are almost 15 times more expensive than mechanical hard disk drives when compared on a price-per-GB rating. Additionally, there are concerns about the longevity of solid-state memory for use with enterprise database workloads such as Exchange Server. There are storage solutions where a small number of high-speed SSD devices can be used as a form of secondary disk cache that provides higher performance without the high cost. In most cases, however, these solutions are extremely expensive when compared with an equal-size, directly attached storage solution. They may also result in unpredictable performance for random workloads. We will compare storage solutions later in this chapter.
Given this difference in cost between SSD and mechanical hard disk drives, SSDs are not recommended for Exchange Server storage. This leaves design teams with a common problem, that is, how to calculate the random IOPS capability for a mechanical hard disk drive. As a matter of fact, there is a relatively simple method for deriving random IOPS per spindle given two commonly available metrics.
Once these values are known, it is possible to determine how many random IOPS the disk spindle can accommodate. Review the following example:
The number of random read and write operations that a hard disk drive can complete is a function of how fast the disk spins and how quickly the head can move around. Given a few metrics about the disk drive, we can calculate the theoretical maximum random IOPS as follows:
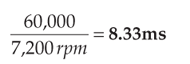



Why is this important? We are mainly interested in this because the two factors that govern random disk IOPS for mechanical disk drives are rotation speed and seek time. Neither of these factors is likely to improve dramatically in the near future. Disks have been available at up to 15K rpm spindle speeds for the last five years or more. Nonetheless, these high-speed spindles are very costly, and they require more power and generate more heat (thus requiring additional cooling) than slower spindle speeds. It is also difficult to spin a large disk platter at such high speeds, and so most manufacturers only offer high spindle speed drives in smaller capacities, because they require a smaller platter diameter to maintain the high spindle speed. Minor improvements in average seek time have been achieved as manufacturing and engineering processes have matured. However, most storage vendors report that they do not expect to see any significant improvements in this area.
This leaves Exchange design teams with a problem. Disk capacities are increasing and costs per megabyte are declining, but random IOPS performance is relatively static. This means that we are unable to take advantage of these newer, high-capacity hard disk drives effectively. Thus, Exchange 2013 must be able to make better use of 7.2K rpm mechanical disk drives with greater than 2 TB capacities.
Exchange 2010 allowed the use of JBOD. Though initially this term was confusing within the Exchange community, for our discussion the term JBOD will refer to the presentation of a single disk spindle to the operating system as an available volume.
JBOD represents a very cheap and simple way to provide Exchange storage. Ideally the JBOD spindles will be slow, cheap disks and directly attached to each DAG node to provide the best-cost model. The JBOD model requires three or more copies of each database to ensure sufficient data availability in the event that a disk spindle fails.
The most common problem area for JBOD is not in the technology. Rather, it is what has to occur operationally when a disk spindle inevitably fails. Since there is no RAID array, every single disk spindle failure will result in a predictable series of events:
If the failed spindle was hosting the active copy of the database at the time of failure, there may be a minor interruption in service to the end user. However, typically the failover times are brief enough so that Outlook clients in cached mode will not notice this kind of failure.
Dealing with disk spindle failures in a JBOD deployment can be largely automated via a combination of PowerShell scripts and monitoring software. However, it does require a level of operational maturity both to capture the alerts and to execute the correct remediation processes once the alert is received. Compared to a RAID based solution where a disk must be replaced, the level of involvement, resource skills, and access requirements necessary to repair a JBOD spindle failure is high.
Exchange Server 2013 must provide an easier way to deal with JBOD disk spindle failures and to reduce the operational maturity and process required to recover from such failures. We will discuss how the product group achieved this later in this chapter.
If there is one thing that is common to every release of Exchange Server, it is the expectation that the latest version will be able to support ever-larger mailbox sizes. In recent times, this expectation has also grown to include mailbox item counts.
With Exchange Server 2010, the ability to store ever more data in the Exchange database via features such as In-Place Hold and single-item recovery meant that mailbox sizes increased dramatically.
Many customers want to store all mailbox data within Exchange for both the real-time message service and compliance. Exchange Server 2013 must be able to maintain performance when clients are connected to these extremely large mailboxes.
A common thread in Exchange projects is cost reduction. This encompasses not only the cost of the hardware but also running costs, datacenter costs, and network, power, cooling, and migration costs as well. As customer requirements have increased, Exchange has had to meet these needs and do so without spiraling costs upward. This is particularly evident with storage, where the requirements for capacity and performance have expanded dramatically while the demands for cost reduction have been equally dramatic.
Recent trends have placed an increasing focus on power, heating, cooling, and datacenter space. Organizations are looking for new ways to reduce their operating costs. Exchange infrastructure can often contribute significantly in large deployments, especially when the storage and supporting functions are considered, such as backup, monitoring, publishing, and so on.
Consolidation of roles was a common theme for Exchange 2010 projects, with many customers taking advantage of high-density locally attached storage, such as the HP MDS 600, which could provide 70 × 3.5” SAS disks in 5U of rack space. Additionally, customers could take advantage of multi-role Exchange deployments to reduce the server footprint. This was a substantial improvement over previous versions of Exchange, and it allowed large-scale consolidation of servers and storage into fewer, more easily managed datacenters. However, power, cooling, and datacenter space costs are increasing. Exchange Server 2013 must continue this trend of consolidation while meeting the increasing business and operational demands for a robust enterprise-messaging product.
Table 5.2 outlines some of the most interesting changes in Exchange 2013 that have an impact on storage.
Table 5.2 Storage enhancements in Exchange Server 2013
| Change | Description | Benefits |
| Store rewritten in managed code | Store.exe is the Exchange Information Store. It was rewritten in managed code to provide efficiencies and allow developers to concentrate on logical data flow rather than code challenges. |
|
| Improved Extensible Storage Engine (ESE) cache allocation | This change allocates more ESE cache for active databases over passive databases. It makes better use of available memory in the server for servicing end users. |
|
| Database schema further improved | Further reduces random I/Os by storing more items within the database sequentially or on the same database page. |
|
| Multiple DB copies per disk spindle | I/O profile improved to make better use of cheaper SAS 3.5” spindles. This allows multiple databases to be hosted on a single spindle. |
|
| Automatic database reseed | Allows spare JBOD spindles to be prepared and used automatically in the event of a disk spindle failure. |
|
One of the interesting trends in Exchange Server 2010 and Exchange Server 2013 is that the Exchange product group will trade CPU utilization if it buys a reduction or smoothes out random disk I/O. This approach makes sense as we consider the hardware growth prediction during the Exchange Server 2013 life cycle. Moore's Law states that transistor densities double about every two years. This growth rate is expected to taper off to a doubling of transistor density every three years starting at the end of 2013. Regardless, the industry expects that available processor power will continue to rise, whereas mechanical disk random IOPS performance is expected to remain static. Exchange Server 2013 is designed to take best advantage of both the hardware resources currently available and those that are projected to be available during the life cycle of the product.
Exchange 2013 reduces IOPS by roughly 45 percent over Exchange Server 2010. If we consider active mailboxes only, Exchange Server 2010 required 0.0012 × user profile compared to Exchange Server 2013 requiring 0.00067 × user profile. If we plug in numbers for 100 messages sent and received per mailbox/per day/per user profile, this means that if the mailbox was hosted on Exchange Server 2010, it would require 0.12 IOPS/mailbox. But on Exchange Server 2013, it would need only 0.067 IOPS/mailbox.
This is the single most important change in Exchange Server 2013. Quite simply, automatic database reseed makes deploying a JBOD storage solution viable for many organizations that found JBOD too difficult to manage in Exchange Server 2010.
The fundamental idea behind automatic database reseed is that you allocate more disk spindles to each DAG node than you require for your active and passive databases. The additional spindles are formatted and mounted, but they are not used to store database or logs. In the event of the failure of a disk spindle that is being used for an active or passive database copy, Exchange will make use of the “spare” disk spindles and automatically perform the necessary database reseed operation.
So why is automatic database reseed better than RAID? JBOD plus AutoReseed requires fewer disks than RAID 10 and does not suffer from the same level of performance degradation inherent in RAID 5 during rebuild. It also doesn't require the same level of operational maturity to maintain data availability.
The change allowing multiple databases for each JBOD disk spindle was necessary to permit the use of larger disk capacities without increasing the maximum mailbox database size above 2 TB. This change is often confused with storing multiple databases per volume but it is subtly different. What this change actually means is that in Exchange Server 2013, there exists the ability to store multiple mailbox databases on a single JBOD spindle, that is, a single disk spindle presented to the server. We have always been able to store multiple databases on a RAID array, but storing multiple databases on a JBOD spindle was previously not supported.
Seemingly, this change is simple to understand since it gives us the ability to store multiple databases on each spindle. This lets us retain the 2 TB maximum recommended mailbox database limit yet still takes advantage of larger-capacity disk spindles. However, this represents only half of the benefit of this change. The other half is that, when we reseed the disk spindle, we may potentially have multiple JBOD disk spindles participating in the reseed operation. Testing so far with Exchange Server 2013 suggests that a single spindle reseed operation, like those that already exist in Exchange Server 2010, runs at around 20 MB/sec. Testing with Exchange Server 2013 and multiple databases for each spindle shows that the reseed operation runs at around 20 MB/sec per spindle used in the reseed operation. For example, if a spindle stored two database copies and the alternate copies of those databases were on different spindles, the reseed operation would take place at around 2 × 20 MB/sec = 40 MB/sec. Figure 5.2 shows you potentially how to store four databases for each disk spindle with a JBOD deployment in Exchange Server 2013.
Figure 5.2 Multiple databases for each JBOD spindle layout

Now let's examine the reseed scenario where we have lost the JBOD disk spindle in Server 1. In this case, active workload for DB1, as shown in Figure 5.3, has been moved to Server 2. All of the remaining workload has stayed in place. The disk in Server 1 has been replaced, and all databases are now being reseeded from the active copy, as shown in Figure 5.3.
Figure 5.3 Multiple databases for each JBOD spindle reseed

Testing shows that, for each reseed operation per source spindle, we can expect around 20 MB/sec performance. Where we have multiple reseed operations for each spindle, we can get around 24 MB/sec performance in total for that spindle. Let's see what this data yields for approximate reseed times.
When we combine the reseed performance benefit with being able to make use of larger disk spindle capacities and automatic database reseed, it makes JBOD in Exchange Server 2013 a compelling proposition from a cost/simplicity perspective and also from an operational perspective. Thus, it is a win/win scenario.
The fundamental design process for an Exchange storage solution normally follows these steps:
In the early days of Exchange design, it was rare to see anything other than step 4 and perhaps step 6 practiced, largely because the Exchange 2013 Server Role Requirements Calculator didn't exist and we didn't have a way to validate the solution. As Exchange has matured, so too has the design process. More recently, it is expected that a storage solution is designed to meet requirements and to avoid overdeploying and operating unnecessary storage hardware.
Over-deploying storage was a common practice with Exchange Server 2003 as design teams tried to make up for performance and architectural limitations within the product. Generally, this proved unsuccessful since Exchange 2003 was limited by its underlying 32-bit architecture and the resulting memory fragmentation that it caused. However, it didn't stop IT departments trying to make it go faster by using very expensive, high-performance storage.
The golden rule of Exchange storage design is first to understand the user profile requirements, which we will discuss later in this chapter. The goal is then to design a solution that will meet those requirements adequately.
Good quality user-profile analysis is vital to the design process. Attempting to perform Exchange storage design without having good quality user-profile data and clearly defined requirements is just costly guesswork. We will discuss the importance of this concept in further detail in the validation section of this chapter.
Every project should have a requirements-gathering phase, as we discussed in Chapter 1, “Business, Functional, and Technical Requirements.” However, it's worth examining which specific requirements are important for Exchange storage design and why we need them.
When discussing Exchange storage design, we are often asked how to obtain user profile values. For Exchange Server 2003 and Exchange Server 2007, the Exchange Server Profile Analyzer (EPA) will provide most of this information. However, this tool requires WebDAV, which was dropped in Exchange Server 2010 and so it will not work in later versions. Fear not; there is an alternative that is addressed in this article:
This article explains how to use a script to parse message-tracking log data in Exchange Server 2010 and Exchange Server 2013 to derive the important user profile metrics. Nevertheless, for Exchange Server 2003 or Exchange Server 2007, we still prefer the data from the Exchange Server Profile Analyzer rather than the message-tracking log analysis script since experience shows that EPA provides more accurate user profile values.
The bottom line for user profile metrics is to understand exactly what the metric is and then figure out a way to obtain that information in the best and most practical way possible. This is particularly applicable when migrating from foreign messaging systems, such as Lotus Domino. There is no easy way to obtain user profile data from Domino, but it is possible to calculate most items by estimation. For example, you could use the following formula:

Where user profile data is concerned, anything is better than making a random guess; that is, never guess your user profile information without some evidence to back it up. Always base user profile information on observed data, and record the process you used to derive it in your design documentation. This is especially important when you wish to engage in a design review cycle with a third-party consulting organization, because any good consultant will want to understand where the numbers came from that you put into the calculator. If the original source of data for those numbers is not recorded, it becomes impossible to provide any form of performance validation for your design.
The Exchange 2013 Server Role Requirements Calculator, or storage calculator as it used to be known, is basically a complicated Excel spreadsheet that contains the calculations necessary to take your design requirements, as discussed in Chapter 1, and turn them into some storage-specific requirements. In this book, we will concentrate on the interesting prediction values that emerge from the calculator rather than on how to use it. Ross Smith IV has written many articles on the Exchange Team Blog about using the calculator. We strongly recommend reading some of these posts before attempting to work with the calculator:
The Exchange 2013 Server Role Requirements Calculator can be downloaded here:
Let's begin by examining the Disk Space Requirements table, which is on the Role Requirements tab. The Disk Space Requirements table shows how much disk capacity the solution will require in the database, server, DAG, and the total environment (see Figure 5.4). This is very useful, since it shows us the capacity requirements for each database plus transaction log combination for the specific user profile and high-availability configuration specified.
In this example, you can see that for each volume used to store a mailbox database, its transaction logs and content index database needs to be at least 2264 GB in size to avoid running out of disk space. This amount comprises 1510 GB for the mailbox database and 37 GB for the transaction logs, and the rest is needed to account for content index and sufficient volume free space to avoid filling up the disk.
Figure 5.4 Disk Space Requirements table in the Mailbox Server Role Requirements Calculator

If we move to the Host IO and Throughput Requirements table, as shown in Figure 5.5, there is another deluge of interesting information. This table is of interest to us in understanding the IOPS requirements for our storage and the throughput requirements for background database maintenance (BDM).
Figure 5.5 Mailbox Server Role Requirements Calculator IOPS and BDM requirements

The values in this table map directly to the target values that will be required when you learn about storage performance validation with Jetstress. Jetstress is the tool we use to simulate an Exchange storage I/O workload to prove that our solution is capable of meeting the demands predicted using the Exchange 2013 Server Role Requirements Calculator.
The most important bits of information from the Host IO and Throughput Requirements table are the Total Database Required IOPS per database and per server plus the Background Database Maintenance Throughput Requirements.
The Background Database Maintenance Throughput Requirements value defines how much sequential read-only I/O will be required to support the background checksum process. Generally speaking, if you are deploying to direct attached storage (DAS), you do not need to consider BDM. However, if you are deploying on SAN or iSCSI, BDM throughput may be an issue. There are many cases where SAN storage, especially iSCSI, can be performance-limited by the throughput requirements of BDM on Exchange Server 2010. Exchange Server 2013 has dramatically reduced the throughput requirements for BDM down to 1 MB/sec from 7.5 MB/sec because of observations from the Office 365 service and the number of CRC errors that were detected during the process. Total Database Required IOPS per database and per server refer to the random IOPS required for the mailbox database. It is important to note that we do not usually consider Log IOPS when planning Exchange storage performance, since it is entirely sequential and easy on the disk. As a caveat to this, it is recommended that you speak with your storage vendor, since this approach may not apply to some SAN technologies and you will need to take their advice on IOPS performance scaling. Nonetheless, the approach is well proven for directly attached storage deployments.
If we look at the Volume Requirements tab, we can see additional information about our storage requirements. This table shows the maximum number of mailboxes per DB, DB size, DB size plus overhead, and log size plus overhead (see Figure 5.6). This is useful for determining how many mailboxes can be stored for each database before it is considered full. It also shows how much space should be allocated for transaction log data.
Figure 5.6 Database and LOG Configuration / Server table

On the same tab, we can see the calculator's recommended volume layout. This shows how many databases are recommended per volume and the capacity requirements for each (see Figure 5.7).
The calculator provides a recommended layout. However, you should just view this as a starting point. The problem with all of the values that we have accumulated up to this point is that they are theoretical minimum values, and we need to map them to actual physical hardware that we can buy and deploy in real places. In most cases, the calculator does a very good job of getting you into the right ballpark, but you will need to apply common sense to turn the recommendation into something practical to deploy.
Figure 5.7 DB and Log Volume Design / Server table

Now we can move on to selecting appropriate hardware for our requirements. There are many aspects to this decision, and the requirements that we have identified so far represent only a few of them. Often there may be a hardware constraint in your requirements, which mandates that you use a specific storage technology or vendor. This technology may not be ideal for use with Exchange but may align with the organization's overall storage strategy. In some cases, this strategy has been mandated for all services, regardless of their requirements or function, and it will be necessary to use a particular storage platform. The other scenario is that you have free choice regarding the storage platform for Exchange, but then you will need to narrow down your choices. How do you narrow down your options? This section will discuss both scenarios and how to deal with them.
First, let's take on the scenario where your storage platform choice is fixed. Even though this decision has been made for you, you still have work to do. To start, you need to research the platform that has been designated. Begin this process by looking at the Exchange Solution Reviewed Program (ESRP) - Storage. Search for a submission from the same storage vendor and, hopefully, for the same platform that is to be used.
ESRP submissions vary in quality and the usefulness of the information provided, but they are almost always a great place to find specific configuration details for running Exchange on a particular platform. ESRP is grouped into versions that relate to the Exchange platform to which they apply:
If you cannot find an ESRP submission, look on the manufacturer's website for Exchange-specific configuration recommendations.
Next, evaluate your disk type options and RAID group configurations. Not all storage platforms allow all configurations, and so it is vital that you understand what you can and cannot do. Then try to map the data that you obtained from the Exchange 2013 Server Role Requirements Calculator, and try to make it fit the platform. Often, the best way to do this is to run a combined storage design workshop with the storage team, in order to evaluate the options, and then try to tweak the calculator accordingly.
Once this process is complete, try to define a validation approach. This is generally a small deployment of servers and storage on representative hardware that can be used for Jetstress testing. The goal of the Jetstress testing will be to validate that the proposed solution is capable of meeting the requirements identified by the calculator. This is where the marketing nonsense stops and the fun begins! We will discuss this process later in this chapter.
Recall that, in the second scenario, you have full control over the storage platform. This is often more challenging for a design team. Now you have to come up with a process for evaluating storage platforms and their ability to meet your requirements. To this end, the first things to define are your specification requirements. These are common areas of comparison; the aim for most team members is to grade the platform from 1 to 10 (where 1 is very poor and 10 is perfect for the task).
What is storage validation? Simply put, the goal of this process is to ensure that the storage platform is capable of meeting the demands of Exchange Server to service end-user requests in a timely manner. If the storage platform is incapable of meeting these demands, then the end-user experience will suffer. We know this from experience in the early days with Exchange Server 2003, where poor storage performance equaled poor Exchange Server performance.
There is an important aspect to the validation process that is rarely discussed, however, and that is that it must take place with a calibrated workload. A calibrated workload means that the test workload applied should be approved (calibrated) by the Exchange product group as not only being a representative one but also equal to the workload generated by Exchange Server. This point is important because it separates out tools that generate workload, such as Iometer and LoadGen, from tools that generate a defined and calibrated workload, such as Jetstress.
Sometimes, in a project where the design has been completed and the storage is failing to pass the Jetstress test, a storage team member will insist that Jetstress is not a good test because the requirements can be met with Iometer, and that's proof that Jetstress is broken. A slight variation on this occurs when a team will use LoadGen to simulate the expected production workload and find that it passes whereas Jetstress fails and thus will come to the same conclusion; that is, LoadGen passes where Jetstress fails and so Jetstress must be broken. Both situations are equally difficult to address since the explanation of the results is complex. By far the most compelling explanation is that Jetstress is a calibrated workload, and when used with the values derived from the Exchange 2013 Server Role Requirements Calculator, it represents the peak two hours of a working day as accurately as possible.
When it comes to storage validation, Jetstress is the only real tool for the job. Now let's see how it works.
The Jetstress test process itself is documented in the Jetstress Field Guide. This does not yet exist for Jetstress 2013; however, the general process outlined for Jetstress 2010 still applies. The test must be conducted as follows if it to be considered successful:
A common area of confusion about these tests is the 2-hour vs. 24-hour test recommendation. Jetstress runs in strict mode when the duration is less than six hours. A completed test run in strict mode is required to be sure that the storage is meeting the performance requirements. The lenient mode relaxes some of the peak latency spike requirements, and it is intended for longer duration testing. The 24-hour test is recommended to ensure that the storage platform is capable of operating at peak workload for an extended duration, since several cases have been logged where performance deteriorates over time when a storage platform is operating at or near its limits. If a storage platform passes all of these Jetstress tests, experience shows that the design is then good to go.
There is one more aspect to Jetstress validation work that is sometimes disregarded or overlooked, and that is build-time validation testing. Build-time validation testing involves running a Jetstress test on each production Mailbox server before it is accepted into production. When discussing this type of testing, the question often asked is, why bother with this test when we have already tested an identical solution in the test lab and it has passed? The answer is that, although the tests are the same, the purpose is different. Validation tests in the lab were designed to corroborate design assumptions and decisions about the storage platform. The build-time validation is designed to ensure that the hardware has been deployed and configured appropriately to meet the requirements, and it is operating according to expectations; that is, it is not faulty.
It is not unheard of for a storage platform to pass Jetstress with flying colors in the test lab, where it receives TLC from the vendor presales team, only to find out that it fails to pass the same Jetstress test in a production environment, where it has been deployed and configured by a completely different team. This can be addressed by adopting build and configuration standards. However, these are still not foolproof, and so adopting an automated Jetstress validation test prior to installing Exchange Server into a production environment is highly recommended. This recommendation is even stronger when a complex storage solution has been deployed. One thing to remember is that it is much easier to fix a problem when Jetstress is the only user of the service. If you first become aware of a problem when an end user reports it, your job becomes significantly harder.
Storage design has been a part of creating Exchange solutions since the very beginning. Although Exchange Server is a messaging application, at its heart it is actually a database of email messages. The increase in requirements to store more and perpetually larger messages for an ever-increasing amount of time means that storage design remains at the heart of designing a successful messaging solution on Exchange Server 2013.
The trend over the last five years has been toward increasing system availability by storing multiple, isolated copies of each mailbox database. This process enhances availability by being able to switch over to a virtually identical mailbox database in a matter of seconds. Nevertheless, it also increases the quantity of disks that a solution requires. Each copy that you add will increase your system availability but will also double your storage capacity requirements. This means that the type, and more important the cost factors, of the storage platform that you choose will impact the number of database copies that you can provide. Remember that Exchange Server 2013 was designed to make great use of cheap, locally attached disk spindles. As of June 2013, the Exchange Product Group at Microsoft is recommending 4 TB 3.5” 7.2K rpm disk spindles to provide the best capacity vs. cost ratio.
Exchange storage design should also begin with an accurate requirements definition. Once the requirements are understood, the single most important part of any storage design is performing good quality user-profile analysis. The user profile defines how many IOPS each mailbox will require, and so it is a fundamental part of your design. Even a relatively small change in the user profile can result in significant redesign.
If it is available, use the Exchange 2013 Server Role Requirements Calculator to help you with your storage sizing and design. If not, use the details provided in the following post by Jeff Mealiffe on the Exchange Team Blog:
Once you have your completed storage design, it is vital that you validate it with Jetstress. Jetstress simulates Exchange database I/O very closely, and it is the only recommended way to test that your storage solution will provide sufficient performance to meet your calculated demand.
The single most important piece of advice for Exchange storage design is to keep things simple. If there is one area that has historically been overdesigned and made overly complicated, it is Exchange storage design. Exchange Server 2013 thrives on cheap, local, directly attached storage. Go down this path for the simplest and most cost-effective experience.