Chapter 8: Reading Data from External Files
This chapter describes three of the most common methods that you can use to read raw text data using SAS. It also demonstrates how to create SAS data sets from CSV files. If you typically receive data that is already in SAS data sets, you can skip this chapter (unless you are just curious).
Reading Data Values Separated by Delimiters
One method of storing data in text files is to separate data values by a delimiter, usually blanks or commas. SAS refers to this as list input.
Let’s start out with a file where blanks (spaces) are used as delimiters. This is a good starting place because a blank is the default delimiter in SAS. In this example, the data file that you want to read contains an ID, first name, last name, gender, age, and state abbreviation. These data lines are stored in a file called Blank_Delimiter.txt and was uploaded to the MyBookFiles folder. Here is the listing.
File 8.1: Blank_Delimiter.txt (Previously uploaded to the MyBookFiles folder)
103-34-7654 Daniel Boone M 56 PA
676-10-1020 Fred Flintstone M
454-30-9999 Tracie Wortenberg F 34 NC
102-87-8374 Jason Kid M 23 NJ
888-21-1234 Patrice Marcella F . TX
788-39-1222 Margaret Mead F 77 PA
A program to read this data file is shown next:
Program 8.1: Reading Data with Delimiters (Blanks)
/* This is another way to insert a comment */
data Blanks /* the data set name is Blanks */;
infile “~/MyBookFiles/Blank_Delimiter.txt” missover;
informat ID $11. First Last $15. Gender $1. State_Code $2.;
input ID First Last Gender Age State_Code;
run;
title “Listing of Data Set Blanks”;
proc print data=Blanks;
run;
The first line of this program demonstrates another way to insert a comment in a SAS program. You begin the comment with a /* and end the comment with a */. Unlike a comment statement that begins with an asterisk, this type of comment can be placed within a SAS statement (as demonstrated in the DATA statement of this program.).
The INFILE statement tells the SAS program where to find the input data. In this example, the data file was already uploaded to the folder MyBookFiles. As discussed briefly in the previous chapter, the actual location of the file is more complicated. It is:
/home/ronaldcody/MyBookFiles/Blank_Delimiter.txt
Because this path is so complicated, you can use a notation common on many other operating systems and use a tilde (~) to specify your home directory.
Notice the keyword MISSOVER on this statement. This is not necessary if you have data values for every variable for every line of data. Line 2 of the data file (Fred Flintstone) is missing the last two values (Age and State_Code). Without the MISSOVER option, SAS would try to read these two values from the next line of data! Obviously, you never want this to happen. The MISSOVER option comes into play when there are missing values at the end of the data line and you are using list input. This option tells the program to set each of these variables to a missing value. Notice line 5 (Patrice Marcella). To indicate that there is a missing value for Age, you use a period. Without the period, SAS would try to read the next value (TX) as the Age and really screw things up. This is handled differently in the next section describing CSV (comma-separated values) files. One last point: SAS interprets multiple blanks as a single delimiter.
You list each of the variable names in the INPUT statement in the order in which they appear in the raw data file. When you use list input (the type of input that reads delimited data), the default length for character variables is 8. To specify how to read your character variables, you use an INFORMAT statement. Following the keyword INFORMAT, you list one or more variables (usually character variables) and follow the variable or variables with a dollar sign (that indicates a character variable) and the number of characters (bytes) of storage that you want, followed by a period. In this example, $11., $15., $1., and $2. are called character informats. Informats are used in other styles of input as well.
Use of these informats also determines the storage length of each of the variables listed in the INFORMAT statement. In this example, you are specifying a length of 11 for ID, a length of 15 for both the variables First and Last, a length of 1 for Gender, and a length of 2 for State_Code. You could also define the lengths of these character variables with a LENGTH statement. That statement would be similar to the INFORMAT statement—just replace the keyword INFORMAT with the keyword LENGTH and leave off the periods after the digits. An INFORMAT statement can also be used to tell SAS how to read other types of data such as dates and numbers with commas and dollar signs, therefore making it more flexible than a LENGTH statement for instructing SAS on how to read raw data.
To list the observations in the Blanks data set, you use PROC PRINT. Below are sections from the SAS log.
Figure 8.1: SAS Log from Program 8.1

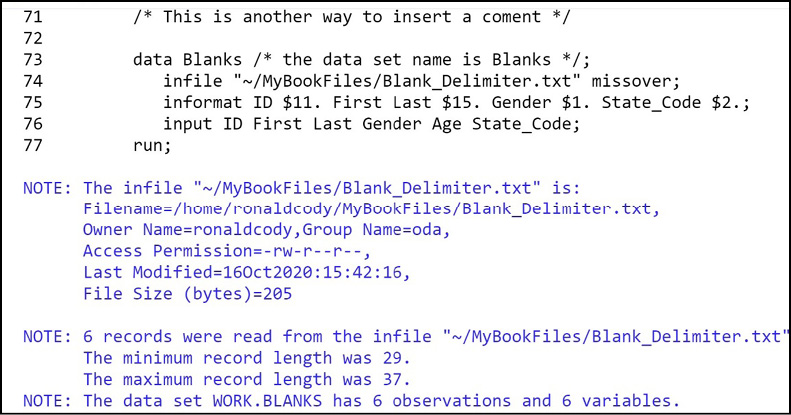

You see that there were no errors in the program, along with information about your input file. Finally, you see that your data set (Blanks) was created with 6 observations and 6 variables, along with the real and CPU time.
Even when you see the OUTPUT window after you submit a program, it is a good idea to check the SAS log for messages and warnings.
Here is the output.
Figure 8.2: Output from Program 8.1
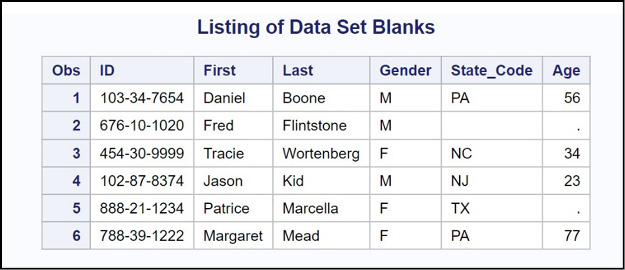
Everything looks fine. Notice the missing values in observations 2 and 5. In observation 2, the missing values for State_Code and Age result from the MISSOVER option in the INFILE statement. The missing value for Age in observation 5 results from the period in the input data.
Reading Comma-Separated Values Files
CSV files (comma-separated values) are one of the most common file types for delimited data. One common use of CSV files is to output data from an Excel workbook. CSV files use commas to separate data values and, unlike the default behavior of SAS when you use blank delimiters, CSV files interpret two commas in a row to mean that there is a missing value for that data field.
The CSV file in this example contains the same data as the file Blank_Delimiter.txt used in the last example. Here is a listing of the file:
File 8.2: Comma_Delimiter.txt
103-34-7654,Daniel,Boone,M,56,PA
676-10-1020,Fred,Flintstone,M
454-30-9999,Tracie,Wortenberg,F,34,NC
102-87-8374,Jason,Kid,M,23,NJ
888-21-1234,Patrice,Marcella,F,,TX
788-39-1222,Margaret,Mead,F,77,PA
Notice the two commas in a row for the fifth line of data (Patrice Marcella). Unlike the blank-delimited file where you needed a period to indicate a missing value for Age, the two commas in a row indicate that this value is missing.
To read data from a CSV file, you add the DSD (Delimiter-Sensitive Data) option in the INFILE statement. This option does several things: First, it understands that the data values in the file are separated by commas. Next, it understands that two commas indicate a missing value. Also, if you have a data value in quotation marks (for example, a state name like ‘New York’ that consists of two words separated by a blank space), it ignores any delimiters inside the quotation marks and strips the quotation marks when it assigns the value to a SAS variable. The program to read the data from the CSV file Comma_Delimiter.txt is shown next.
Program 8.2: Reading CSV Files
data Commas;
infile “~/MyBookFiles/Comma_Delimiter.txt” dsd missover;
informat ID $11. First Last $15. Gender $1. State_Code $2.;
input ID First Last Gender Age State_Code;
run;
title “Listing of Data Set Commas”;
proc print data=Commas;
run;
If you see the following message in your SAS log:
NOTE: SAS went to a new line when INPUT statement reached past the end of a line.
you probably need to add the MISSOVER option to your INFILE statement.
Output from this program is identical to the output from Program 8.1.
Reading Data Separated by Other Delimiters
By using the DLM= option in the INFILE statement, you can specify any delimiter you want, including non-printing characters such as tabs. Suppose you have a tab-delimited file that you want to read. Because a tab character is a non-printing character, you need to find the hexadecimal code for a tab in ASCII (the coding system used in Windows, UNIX, and Linux systems). In ASCII, the Hex representation for a tab is 09. You can specify a Hex character anywhere in a SAS program by using a Hex constant in the form ‘nn’x, where nn is the Hex value that you want (placed in single or double quotation marks) and the ‘x’ is in lowercase or uppercase. Also, there are no spaces between the quoted Hex value and the ‘x’. The program below reads an ASCII file where a tab was used as the delimiter.
Program 8.3: Reading Tab-Delimited Data
data Tabs;
infile “~/MyBookFiles/Tab_Delimiter.txt” dlm=’09’x missover;
informat ID $11. First Last $15. Gender $1. State_Code $2.;
input ID First Last Gender Age State_Code;
run;
title “Listing of Data Set Tabs”;
proc print data=tabs;
run;
The output is identical to the output from the previous two programs. You can use the DLM= option in the INFILE statement to specify any delimiter you want. If you want two consecutive delimiters to indicate a missing value, include the DSD option as well as the DLM= option. For example, if you have data that uses a pipe symbol (vertical bar) as a delimiter and you want to interpret two bars together to indicate that there is a missing value, your INFILE statement would look like this:
infile “file-location” dlm=’|’ dsd;
Another method of placing data in text files is to assign values to predefined columns.
This is much less common today than back in the “old days.” I’m talking about the time at which you entered your programs and data on punch cards. However, these types of file still exist and it’s a good thing that SAS can read them with ease.
SAS provides you with two methods of reading column data. One is called column input. With this method, you follow a variable name with a starting and ending column. If the variable only occupies one column, you do not specify an ending column. If the variable will be defined as a character variable, you place a dollar sign ($) between the variable name and the starting column number. This method is restricted to reading standard numeric data (numbers with or without decimal points) and character data.
The other method is called formatted input. With this method, you specify a starting column, the variable name, and what SAS calls an informat. SAS informats give SAS information about how to read data from one or more columns. Formatted input is much more flexible than column input because it can read data values such as dates and times. You will see examples of both of these methods in the sections that follow.
Reading Data in Fixed Columns Using Column Input
For this example, you want to read data from a file called Health.txt. This file contains the following variables:
Variables in the Health.txt Data File
|
Variable Name |
Description |
Starting Column |
Ending Column |
|
Subj |
Subject number |
1 |
3 |
|
Gender |
Gender (M or F) |
4 |
4 |
|
Age |
Age in years |
5 |
6 |
|
HR |
Heart rate |
7 |
8 |
|
SBP |
Systolic blood pressure |
9 |
11 |
|
DBP |
Diastolic blood pressure |
12 |
14 |
|
Chol |
Total cholesterol |
16 |
18 |
The data file looks like this:
File 8.3: health.txt
123456789012345678901234567890 (Ruler – this line is not in the file)
001M2368120 90128
002F5572180 90170
003F1858118 72122
004M8082 220
005F3462128 80
006F3878108 68220
Because the data values are in fixed columns, you can use column input to read it. Notice that blanks are used when there are missing values (although there are no blanks at the end of short lines). Below is a program that reads this data file using column input.
Program 8.4: Reading Data in Fixed Columns Using Column Input
data Health;
infile ‘~/MyBookFiles/health.txt’ pad;
input Subj $ 1-3
Gender $ 4
Age 5-6
HR 7-8
SBP 9-11
DBP 12-14
Chol 15-17;
run;
title “Listing of Data Set Health”;
proc print data=Health;
ID Subj;
run;
The INFILE statement tells the program where to find the health.txt data file. Following the file location, you see the keyword PAD. This is very important. Because some of the lines in the file are shorter than others (there is a carriage return after the last number in each line), SAS will not read the data correctly without it. This option pads each line with blanks.
When programming was done on mainframe computers (often using punch cards as input), data lines were automatically padded with blanks (typically up to 80 columns). Because a lot of data is now entered on personal computers, data lines can be much longer than 80 columns and they are not typically padded with blanks.
Notice the file name “health.txt” is in lowercase. The reason is that the file that was uploaded to SAS Studio was also in lowercase. Whenever you see a “physical file not found” error message in your SAS log, check to see whether the file name in the INFILE statement matches the file name in your SAS Studio folder.
Here is a listing of data set Health:
Figure 8.3: Output from Program 8.4
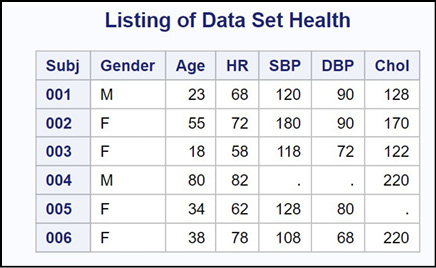
Notice that the blanks in the raw data file result in missing values in the listing.
Reading Data in Fixed Columns Using Formatted Input
Formatted input is the most common (and flexible) method for reading data in fixed columns. Let’s jump right to the program and then the explanation. Here it is.
Program 8.5: Reading Data in Fixed Columns Using Formatted Input
data Health;
infile ‘~/MyBookFiles/health.txt’ pad;
input @1 Subj $3.
@4 Gender $1.
@5 Age 2.
@7 HR 2.
@9 SBP 3.
@12 DBP 3.
@15 Chol 3.;
run;
title “Listing of Data Set Health”;
proc print data=Health;
ID Subj;
run;
The @ sign is called a column pointer. The number following the @ sign is the starting column for the value that you want to read. Following the variable name is an informat. There are lots of informats for reading and interpreting things like dates, times, and values with dollar signs and commas. This program only uses two: The informat $w. (w stands for width) reads w columns of character data; the informat w. reads w columns of numeric data.
The informat for numeric data is actually more general. You can specify a numeric informat that includes information about where to insert a decimal point in the value. For example, you might have numbers such as 10795 to represent 107 dollars and 95 cents. You could write an informat in the form of w.d, where w is the total number of columns to read and d indicates that there is a decimal place with d digits to the right. In the case of reading the dollars and cents value of 10795, you could use an informat of 5.2. The numeric value stored in the data set would be 107.95. When you use a w.d format, and the value that you are reading contains a decimal point, the d in the informat is ignored. The data set created by this program is identical to the data set produced by Program 8.4.
There are some shortcuts that you can use when employing formatted input. One of the most useful shortcuts uses variable lists and informat lists. If you have a group of variables that all share the same informat, you can list all the variables together (in a set of parentheses) and follow the list of variables by one or more informats (also in a set of parentheses). Here is Program 8.5, rewritten using this feature.
Program 8.6: Demonstrating Formatted Input
data Health;
infile ‘~/MyBookFiles/health.txt’ pad;
input @1 Subj $3.
@4 Gender $1.
@5 (Age HR) (2.)
@9 (SBP DBP Chol) (3.);
run;
title “Listing of Data Set Health”;
proc print data=Health;
ID Subj;
run;
In this program, Age and HR both use the 2. informat; SBP, DBP, and Chol all use the 3. informat.
If you have as many informats as you have variables names the variables and informats will “pair up” on a one-to-one basis. If there are fewer informats than variable names, SAS will go back to the beginning of the informat list and reuse the informats in order. If there is only one informat, it will apply to every variable in the variable list. This is by far the most common way variable lists and informat lists are used.
In this example, this shortcut only saved a few lines of typing. However, imagine that you had 50 character values (called Ques1-Ques50), each occupying one column. You could write a very compact INPUT statement like this:
input (Ques1-Ques50) ($1.);
The variable list also demonstrates a convenient way to reference all the variables from Ques1 to Ques50. Anywhere in a SAS program where you need to name variables that have the same alphabetic root (Ques in this example), you can use a single hyphen to indicate that you are referencing all the variables from the first to the last.
This chapter explored how to read external text data in almost any format. This is only the tip of the iceberg. For more information about the INPUT statement, please check out Learning SAS by Example: A Programmer’s Guide, Second Edition (Cody, 2018), published by SAS Press.
You can download all the files and programs you need for these problems from the author’s website: support.sas.com/cody. Programs and data for the problems are in a folder called Problems.
1. A quick survey was conducted, and the following data values were collected:
|
Variable |
Description |
|
Subj |
Subject number (3 digits – stored as character) |
|
Gender |
F=Female, M=Male |
|
DOB |
Date of birth in mm/dd/yyyy form |
|
Height |
Height in inches |
|
Weight |
Weight in pounds |
|
Income_Group |
Income group: L=Low, M=Medium, H=High |
The data values were saved in a blank-delimited file called Quick.txt. Copy this file to your SAS Studio folder (for example, Problems) and write a SAS program to read this data file, create a temporary SAS data set, and produce a listing of the file. The file appears as follows:
File 8.4: Quick.txt
001 M 10/21/1950 68 150 H
002 F 9/11/1981 63 101 M
003 F 1/1/1983 62 120 L
004 M 5/17/2000 57 98 L
005 M 7/15/1970 79 220 H
006 F 6/1/1968 71 188 M
Use the mmddyy10. informat to read the DOB. Also, include the following statement in your program:
format DOB mmddyy10.;
The reason for this is that, as you will see later in the chapter on dates, SAS stores dates as the number of days from January 1, 1960. The statement above is an instruction to print the DOB as a date and not the internal value (the number of days from 1/1/1960).
2. Use PROC FREQ and the data set in problem 1, to compute frequencies for the variables Gender and Income_Group.
3. Add options to your program in Problem 2 to have the table list values in decreasing order of frequency and omit the cumulative statistics from the tables.
4. Modify the program in Problem 1 to compute a new variable called BMI (body mass index). BMI is defined as the weight in kilograms divided by the height (in meters) squared. Conversions are:
1 kg. = 2.2 pounds
1 meter = 39.3701 inches
5. The same data described in Problem 1 was saved as a CSV file called Quick.csv. Write a program to create a SAS data set from this CSV file. Be sure to include the FORMAT statement mentioned in that problem.
6. The same data described in Problem 1 in Chapter 8 was entered with the forward slash (/) as a delimiter. Because the dates also include slashes, the dates were placed in quotation marks. Here is a listing of the file:
File 8.5: Quick_Slash.txt
001/M/”10/21/1950”/68/150/H
002/F/”/9/11/1981”/63/101/M
003/F/”1/1/1983”/62/120/L
004/M/”5/17/2000”/57/98/L
005/M/”7/15/1970”/79/220/H
006/F/”6/1/1968”/71/188/M
The variables in the file are ID (allow for 11 characters), First and Last name (each up to 15 characters), Gender (M or F), Age, and State code (2 characters). Write a program to read data from this file, create a temporary SAS data set (call it Slash), and produce a listing of the file.
Hints: 1) Some lines are missing values at the end of the line, and 2) Two slashes in a row indicate there is a missing value (think DSD).
7. An Excel workbook called Grades.xlsx contains data on student grades. Use the IMPORT task on the Utilities menu to read the spreadsheet and create a SAS data set.
8. The data from the quick survey was entered into a file called Quick_Cols.txt using fixed columns as follows:
|
Variable |
Description |
Columns |
|
Subj |
Subject number (3 digits) |
1-3 |
|
Gender |
F=Female, M=Male |
4 |
|
DOB |
Date of birth in mm/dd/yyyy form |
5-14 |
|
Height |
Height in inches |
15-16 |
|
Weight |
Weight in pounds |
17-19 |
|
Income_Group |
Income group: L=Low, M=Medium, H=High |
20 |
Using column input, create a SAS data set from this file. Important note: Because DOB is a date, you will have to read it as a character string.
9. Create a SAS data set from the file Quick_Cols.txt using formatted input. Read the DOB with the mmddyy10. informat. Also, include the FORMAT statement mentioned in Problem 1.
10. What’s wrong with this program?
1. data Names;
2. input Name $ Height Weight;
3. Height_CM = Heightx2.54;
4. *Note 1 inch = 2.54 cm
5. datalines;
Zemlachenko 73 190
Holland 63 100
;