Examples:
A: all/every F is G
I: some F is/are G
E: no F is G
O: not every F is G; some F is/are not G
3
Later Approaches to Implicature
Whereas Grice’s theory laid the groundwork for all later work in implicature, several current approaches have attempted to improve on Grice’s formulation, in part by consolidating the four maxims and their many submaxims into a smaller number of principles. The two best known of these camps are neo-Gricean theory and Relevance theory. There are two leading neo-Gricean theories; these were developed primarily by Laurence Horn and Stephen Levinson and reduce the system of maxims down to two and three principles, respectively. Relevance theory, on the other hand, reduces the system of maxims down to a single principle of Relevance. Described in these terms, the argument sounds rather inconsequential; who cares how we slice up the maxim pie? But behind this disagreement lie important questions concerning the nature of pragmatic processing, generalized vs. particularized inferential processes, and the question of whether there is a need for any maxims at all. We will begin by describing each of the theories, and will then compare and contrast them in terms of these deeper theoretical issues.
As we saw in Chapter 2, there are significant areas of overlap among the maxims and submaxims as formulated by Grice. For example, the second submaxim of Quantity (henceforth Quantity2) tells the speaker not to say any more than is necessary, while the maxim of Relation tells the speaker to be relevant. As we have seen, these two frequently come out to the same thing: To say more than is necessary is to say what is not truly relevant, and to say what is not relevant is to say more than is necessary. Likewise, the third submaxim of Manner (Manner3) enjoins the speaker to be brief – but again, to say no more than is necessary (observing Quantity2) is to be appropriately brief; similarly, offering only relevant information will tend to result in appropriate brevity. The maxims are assumed to be in a certain amount of tension with each other; for example, there are times when the only way to observe Quantity1 (i.e., to say as much as is needed) is to fail to be brief, and being relevant can work both in favor of brevity (by limiting the speaker to conveying only relevant information) and also against it (by ensuring that all sufficiently relevant information is conveyed).
There is, then, an interaction between the maxims of Quantity, Relation, and Manner with respect to whether they encourage brevity or verbosity. Brevity is encouraged by Quantity2 (say no more than necessary), Relation (say only what is relevant), and Manner3 (be brief). Verbosity is encouraged by Quantity1 (say as much as is necessary), Relation (say what is relevant), and Manner1/2 (to the extent that they encourage clarity). Speakers thus find themselves needing to strike a balance between saying as much as necessary and saying no more than necessary (and only what’s relevant), between brevity and clarity, and so on.
Recognizing these two interacting aspects of the Cooperative Principle, Horn (1984, drawing on Zipf 1949) presents a simplified system consisting of two principles, the Q-Principle and the R-Principle, which subsume most of the maxims and submaxims of Grice’s system. Simply stated, they are as follows:
The Q-Principle maps onto Grice’s first submaxim of Quantity, while the R-Principle subsumes Grice’s second submaxim of Quantity, the maxim of Relation, and the maxim of Manner. Quality is considered a sort of super-maxim that is assumed to operate above the level of Q and R and without which the system cannot function.
Some examples of Q and R at work follow:
| (59) | a. I love most Beatles songs.
+> I don’t love all Beatles songs. b. Janet likes Sylvester.
+> Janet does not love Sylvester. c. Steve will register for biology or chemistry.
+> Steve will not register for both biology and chemistry. d. Mary’s jacket is light red. +> Mary’s jacket is not pink. |
| (60) | a. John was able to fix the broken hinge.
+> John fixed the broken hinge. b. I broke a fingernail.
+> I broke one of my own fingernails. c. I need a drink.
+> I need an alcoholic drink. d. Cathy and Cheryl sang the National Anthem. +> Cathy and Cheryl sang the National Anthem together. |
In Horn’s theory, the examples in (59) are all cases of Q-implicature. In (59a) we have a garden-variety scalar implicature of the type we’ve seen in Chapter 2. In Horn’s theory, the hearer reasons that since the Q-Principle tells the speaker to say as much as possible, by choosing to say most the speaker will implicate not all. Similarly, in (59b) the choice to say likes licenses the inference to does not love, where like and love constitute values on a scale (hence if the speaker believes Janet loves Sylvester, they should have said so). As discussed in Chapter 2, the use of or in (59c) implicates that and does not hold, because and conveys more information than or (in that to know both p and q is to know more than simply knowing that one or the other holds); therefore or constitutes a lower value than and on a scale, inducing the scalar implicature. Example (59d) is a bit more interesting, in that pink is the default shade of light red, and it’s easier to utter the word pink than light red; hence, again, if the speaker wanted to convey that Mary’s jacket is pink, they should have simply said so. Since they did not, they implicate that the jacket occupies some area in the range of light red other than that denoted by pink. In all of these examples, Q’s admonition to say as much as possible licenses the hearer to infer that the speaker could not have intended any more than was said.
In (60), on the other hand, the inference is indeed to more than was said; here, the admonition from R to say no more than necessary licenses the hearer to infer beyond what has been said. Thus, in (60a), given John’s ability to fix the broken hinge, we can infer that he in fact did so. In (60b), the hearer can infer that I broke my own nail unless I specify that it belonged to someone else. In (60c), the hearer infers that the type of drink I need is the prototypical type of drink needed by someone who expresses a need for a drink – that is, an alcoholic drink. And finally, in (60d), in the absence of any indication that the singing occurred separately, the hearer can infer that Cathy and Cheryl sang together. In each case, what is inferred expands upon and adds to what was explicitly stated.
Horn notes that the Q-Principle is a “lower-bounding” principle (since it puts a lower limit on what should be said, by effectively telling the speaker, “say no less than this”) and induces “upper-bounding” implicatures (if the speaker is saying as much as possible, I can infer that anything beyond what has been said doesn’t hold). These include the scalar implicatures discussed above, whereby the use of some, for example, implicates “not all.”
The R-Principle, on the other hand, is an “upper-bounding” principle (since it puts an upper limit on what should be said, by telling the speaker to say no more than necessary) and induces “lower-bounding” implicatures (if the speaker is saying as little as possible, I can infer that what has been said represents merely the lower limit of what holds).
In short, an R-inference is an inference to more than was said (e.g., I’ve asked where I can buy a newspaper and the speaker has told me there’s a gas station around the corner; hence I infer that the gas station sells newspapers), whereas a Q-inference is an inference to NO more than was said (e.g., the speaker has said she had two pancakes for breakfast; hence I infer that she had no more than two).
The Q-Principle is a hearer-based principle: It’s in the hearer’s interest for the speaker to explicitly express as much information as possible, to save the hearer processing effort. The R-Principle, on the other hand, is speaker-based: It’s in the speaker’s interest to say as little as possible and save speaking effort. Thus, the hearer’s interests push language toward maximal explicitness, whereas the speaker’s interests push language toward minimal explicitness, with the optimal language from the speaker’s point of view presumably consisting of a single phoneme/word (such as uhhhh), standing for all possible meanings (Zipf 1949). Real language, needless to say, has to strike a balance between these two conflicting interests, being explicit enough to enable the hearer to understand the intended meaning while leaving enough to inference that the speaker’s job can be done in a reasonable amount of time.
Now, since you’ve read Chapter 1, your scientific antennae may be up: You might wonder where the falsifiable claim is in this theory. After all, any upper-bounding implicature can be attributed to Q, and any lower-bounding implicature to R, leaving us without a testable claim – without a sense of what sort of situation would result in the “wrong” implicature, that is, an implicature that would violate the predictions of the system. To put it another way, the system as described thus far doesn’t appear to make any predictions about which sort of implicature will arise in a given case. More importantly, perhaps, you might well wonder how the hearer is to know whether to draw a Q-based or R-based inference in a given context – that is, whether to infer more than was said or to infer that no more holds.
Enter Horn’s Division of Pragmatic Labor. The Division of Pragmatic Labor says, in essence, that an unmarked utterance licenses an R-inference to the unmarked situation, whereas a marked utterance licenses a Q-inference to the effect that the unmarked situation does not hold. (An “unmarked” expression is in general the default, usual, or expected expression, whereas a “marked” expression is non-default, less common, or relatively unexpected. All other things being equal, longer expressions and those that require more effort are also considered more marked than those that are shorter and easier to produce.) Consider again the examples in (59) and (60). Examples (59a–c) are all cases of scalar implicature, in which one may infer from the utterance of p that no more than p holds (since if it did, Q requires the speaker to say so). In (59d), however, we have a slightly different situation. Here, “pink” is a subtype of “light red”; that is, pink is a shade of light red, but not all shades of light red are pink. Nonetheless, pink is the default, prototypical variety of light red (as suggested by the fact that it has been lexicalized). The range of shades describable as light red, then, has pink at the core, surrounded by various other shades that count as light red but not as pink. Thus, when a speaker chooses to describe something as light red, as in (59d), we can infer that it is not pink, on the grounds that pink is the unmarked way to refer to any color that counts as pink. To refer to a color as light red (using a marked expression) suggests that the color could not have been described as pink (using the unmarked expression), since if it could, the Q-Principle dictates that it should have been. That is to say, the use of the marked utterance Q-implicates that the unmarked case does not hold.
In the cases in (60), on the other hand, we see unmarked expressions licensing R-inferences to the unmarked situation: In the unmarked case, if John was able to fix something, he in fact did fix it (otherwise we’d generally be violating Relation to mention this ability at all); likewise, the unmarked case of breaking a nail is to break one’s own, and to need a drink is to need an alcoholic drink, and for two people to sing is for them to sing together. As usual, context can override: If I come in from mowing the lawn on a 95-degree day and utter I need a drink, my hearer is more likely to infer that I need liquid refreshment, and that lemonade would serve the purpose; and if I’m listing the contestants in a karaoke contest and what they sang, uttering Cathy and Cheryl sang the National Anthem will not implicate that they sang it together. Thus, the usual contextual considerations, cancellations, floutings, scalar implicatures, and so on, remain in force, while the Division of Pragmatic Labor steps in to handle the use of unmarked expressions in unmarked contexts (where R holds sway) and the use of marked expressions in otherwise unmarked contexts (where Q takes over).
Notice, then, that replacing the unmarked utterances in (60) with marked utterances with the same semantic content eliminates the R-inference, and instead may license a Q-inference to “no more than p”:
| (61) | a. John had the ability to fix the broken hinge.
+> (For all the speaker knows,) John did not fix the broken hinge. b. A fingernail was broken by me.
+> It wasn’t one of my own fingernails. c. I need to consume liquid.
+> I need any sort of drink. d. Cathy sang the National Anthem, and Cheryl sang the National Anthem. +> Cathy and Cheryl did not sing the National Anthem together. |
Similarly, consider the difference between (62a–b):
| (62) | a. Gordon killed the intruder.
b. Gordon caused the intruder to die. |
In (62a), the use of the unmarked, default expression killed R-implicates that the killing happened in the unmarked, default way – that is, through some purposeful, direct means, as in the case where Gordon has pointed a loaded gun at the intruder and pulled the trigger. In (62b), on the other hand, the speaker has specifically avoided the default expression killed; here, the use of the marked expression caused … to die Q-implicates that the unmarked situation does not hold (since if it did, the speaker would have said killed), and thus that the death was caused in some marked way (cf. McCawley 1978): For example, the death may not have been purposeful (if, e.g., Gordon had set out poisoned food in hopes of killing mice, but the intruder ate it instead), or it may have been purposeful but indirect (if, e.g., Gordon had a vicious dog that he had trained to attack intruders). Here again, the Division of Pragmatic Labor suggests that the use of a marked expression Q-implicates a marked meaning.
While Horn’s Q- and R-principles reduce the Gricean framework to two opposing forces (under the umbrella of Quality, whose operation one might consider to be qualitatively different), Levinson (2000, inter alia) presents a similar but distinct framework, retaining the notion of opposing speaker-based and hearer-based forces in language but distinguishing between semantic content and linguistic form, and separating these two aspects of Horn’s Q-Principle. Levinson’s system is based on three heuristics for utterance interpretation:
Corresponding to each of these heuristics is a more fully fleshed-out principle based on it, comprising a speaker’s maxim and a hearer’s corollary; for example, the Q-principle (corresponding to the Q-heuristic) includes the following speaker’s maxim:
Do not provide a statement that is informationally weaker than your knowledge of the world allows, unless providing an informationally stronger statement would contravene the I-principle. Specifically, select the informationally strongest paradigmatic alternate that is consistent with the facts.
(Levinson 2000: 76)
The hearer’s corollary, briefly summarized, tells the hearer to assume that the speaker made the strongest statement consistent with their knowledge. Taken together, the speaker’s maxim and hearer’s corollary represent two aspects of the heuristic “what isn’t said, isn’t” – that is, a directive to the speaker to leave nothing relevant unsaid (in essence, “what is, should be said”), and a directive to the hearer to assume therefore that anything that’s both relevant and unsaid doesn’t hold (that is, “what isn’t said, isn’t”). In the same way, the I- and M-principles flesh out their corresponding heuristics, developing them into speaker- and hearer-based directives. Since the principles involve more detail than is necessary for our purposes, we will deal here with the formulation given in the heuristics, but the interested reader is referred to Levinson (2000) for more detailed discussion.
The Q-heuristic is related to both Grice’s first submaxim of Quantity and Horn’s Q-principle. It gives rise to scalar implicatures in the usual way (if I ate five donuts, I should have said so; thus my saying I ate four donuts implicates that I did not eat five). This heuristic is based on the notion of a contrast set – that is, a set of possible utterances the speaker could have made. In Levinson’s system, the choice of one option from among a salient set of others implicates that those others do not apply. This applies both to scales (uttering some implicates “not all”) and to unordered sets (uttering red implicates not blue; uttering breakfast implicates “not lunch,” etc.; see Hirschberg 1991 for a detailed discussion of scalar implicature in ordered and partially ordered sets).
The I-heuristic draws its name from “informativeness” (from Atlas and Levinson’s 1981 Principle of Informativeness, to which it closely corresponds), and is related to Grice’s second submaxim of Quantity and Horn’s R-principle. Thus, like Horn’s R-principle, it gives rise to an inference to the stereotypical situation, such as those in (60) above (from drink to “alcoholic drink” and so on), as well as the inference from p and q to “p and then q” and from if p then q to “if and only if p, then q” (again, like Horn’s R). The inference takes us from the more general utterance to the most specific, most informative default interpretation.
Finally, the M-heuristic is related to Grice’s maxim of Manner, specifically the first and third submaxims (“avoid obscurity of expression” and “be brief (avoid unnecessary prolixity)”). The I- and M-heuristics are in opposition in exactly the way that Horn’s Q- and R-principles are in opposition, and give a result similar to his Division of Pragmatic Labor: Unmarked expressions license inferences to the unmarked situation, while marked expressions license inferences to a marked situation. Horn’s Q-principle does the work of both Levinson’s Q-heuristic and his M-heuristic; the difference is that Levinson distinguishes between two types of contrast sets: semantic and formal. His Q-heuristic appeals to a contrast set of semantically distinct expressions (i.e., expressions that “say different things”), whereas his M-heuristic assumes a contrast set of formally distinct expressions that are semantically similar (i.e., they say nearly the same thing, but in different terms). Thus, in (59) above, repeated below as (63), Levinson’s Q handles phenomena such as those in (a–c), while his M handles phenomena such as that in (d):
| (63) | a. I love most Beatles songs.
+> I don’t love all Beatles songs. b. Janet likes Sylvester.
+> Janet does not love Sylvester. c. Steve will register for biology or chemistry.
+> Steve will not register for both biology and chemistry. d. Mary’s jacket is light red. +> Mary’s jacket is not pink. |
That is, in (a–c) the members of the contrast set differ semantically – most is semantically weaker than all, like is semantically weaker than love, and or is semantically weaker than and – but the two members of each pair are roughly equivalent in formal length and markedness. In (d), on the other hand, light red and pink cover similar semantic ground but differ both in formal length and in markedness; similarly, in (62a–b) above, we see M at work in the use of the longer and more marked cause to die rather than kill.
Nonetheless, what the Hornian and Levinsonian systems have in common is their reliance on a tension between a speaker-based principle and a hearer-based principle. Levinson’s I (“what is simply described is stereotypically exemplified”) and M (“a marked message indicates a marked situation”) interact in essentially the same way that Horn’s Q and R interact in the Division of Pragmatic Labor: For Horn, the R requirement to say no more than necessary suggests that a speaker wanting to indicate a stereotypical situation can stop after giving just the minimum amount of information necessary to point to that situation (essentially Levinson’s I), whereas the Q requirement to say as much as required suggests that if the speaker doesn’t want to indicate a stereotypical situation, they’d better say more than that minimum – that is, give a marked message to indicate the marked situation (Levinson’s M). Thus, whereas Levinson’s I and M stipulate the particular inferences licensed by more and less marked utterances, for Horn these inferences fall out from the more general principles of saying enough but no more than that much. Meanwhile, Levinson’s Q stipulates a distinct class of inference (“what isn’t said, isn’t”), whereas for Horn this is another fallout from the Q-principle of saying enough (i.e., if p were the case and the speaker knew it, they should have said so; if they chose not to, it must not be the case).
Thus, Horn’s system is more general in both a positive sense and a negative sense – positive both in that it captures a generalization concerning the source of two different types of inferences (the inference to the marked situation and the inference to the non-applicability of what hasn’t been uttered) and in the appealingly parallel nature of the Q- and R-principles, but negative in that the conflation of those two different types of inferences results in the loss of a potentially useful distinction between formal and semantic contrasts. Levinson’s system, on the other hand, is more specific, again in both a positive sense and a negative sense – positive in that it incorporates a potentially important distinction between contrast sets of semantically distinct but formally similar items (giving rise to Q-inferences) and contrast sets of semantically similar but formally distinct items (giving rise to M-inferences), but negative in that it loses the parallelism and direct tension between Horn’s Q and R (say enough but not too much) as well as the insight that both types of contrast sets interact with the R-principle in essentially the same way. That is to say, Horn’s system tidily captures the fact that “say enough, content-wise” and “say enough, form-wise” are in essentially the same sort of tension with “don’t say any more than you need to, either form-wise or content-wise.” It’s interesting to note that Levinson’s I-heuristic to some extent retains the conflation of form and meaning on the “speaker-based” side that his Q/M contrast exploits on the “hearer-based” side, in that “what is simply stated” seems to make reference to simplicity of both form and semantic content. Although Huang (2006) suggests that the I-heuristic operates primarily on the level of semantic content, for a situation to be “simply described” stands in contrast to a “marked message” in such a way that a formally simple description will give rise to the unmarked situation by virtue of not constituting a marked message – again, in the same way as seen in Horn’s Division of Pragmatic Labor.
Levinson’s theory is in some ways not as directly Gricean as Horn’s; for instance, Levinson adopts an intermediate level of default interpretations for generalized conversational implicatures, based on the Q-, I-, and M-heuristics. This intermediate level represents a departure from Grice’s binary distinction between truth-conditional meaning and inferred meaning. Nonetheless, both Horn’s approach and Levinson’s approach involve a small number of distinct principles for cooperative linguistic behavior, with the tension between (or among) these principles potentially giving rise to implicatures. Grice made it clear in his original formulation that each of the maxims is in tension with each of the others – so that for a speaker to obey the maxim of Quantity is really to obey two distinct submaxims that are in direct tension (say as much as you can, but not too much) while simultaneously negotiating the tension between those submaxims and the maxim of Relation (say as much as you can without being irrelevant, but not too much) as well as the maxims of Quality and Manner (say as much as you can without being either irrelevant or untruthful, but not too much or with too much prolixity, unclarity, or ambiguity). Horn and Levinson, in short, have retained Grice’s original insight that language use is essentially a matter of negotiating distinct and conflicting demands, and of licensing inferences by means of one’s resolution of that negotiation, and that is the sense in which both theories can be thought of as neo-Gricean.
Lexical pragmatics deals with the relationship between pragmatics and the lexicon, including such issues as those described in the discussion of (62a–b), repeated below as (64).
| (64) | a. Gordon killed the intruder.
b. Gordon caused the intruder to die. |
Let us consider again how such cases are handled by Horn’s Division of Pragmatic Labor. (The discussion that follows uses Horn’s approach, but it should be clear how Levinson’s approach might deal with many of these cases.) As we saw above, the interpretation of killed in (64a) is influenced by an R-inference to the stereotypical situation. Notice that the truth-conditional meaning of kill does not include anything about intentionality or directness; thus, to say (65) is in no way contradictory:
| (65) | Gordon killed the intruder, but it was accidental and indirect. |
In the scenario described above in which Gordon has left out poisoned food for mice and the intruder has eaten it, Gordon killed the intruder would strictly speaking be true; however, it would be a misleading way to express the situation. Thus, the semantic meaning of the lexical item kill is, essentially, “cause to die,” but the pragmatic meaning includes intentionality and directness of causation.
Horn notes that a similar account can be given for a wide range of cases of autohyponymy – that is, cases in which a single lexical form serves as its own hyponym. Consider the italicized examples in (66):
| (66) | a. I need a drink.
b. The actor just landed a new role.
c. I prefer photos in color.
d. I had a slice of bread with my lunch.
e. I need to mow the grass. |
In (a), drink is typically taken to mean “alcoholic drink”; here, this drink is a hyponym of the more general drink, whose meaning encompasses both alcoholic and non-alcoholic drinks. Similarly, the use of actor as in (b) is commonly taken to refer to males (in contrast to actress); nonetheless, both men and women are considered actors, making the male-specific actor a hyponym of the more general gender-neutral actor. (Notice that one might say, at the Academy Awards, that many actors have gathered in the audience, and they wouldn’t be taken to be referring only to the males.) In (c), the word color is used to refer to colors other than black, white, and gray, which are of course also “colors” in the broader sense of the term. In (d), bread is taken to mean a particular subtype of bread; it would be odd to utter this sentence in reference to a slice of banana bread, for example (in which case the Q-Principle would demand that you use the more marked expression to indicate the marked situation). And finally, grass in (e) is taken to indicate a particular type of grass, the type that carpets yards all over America and is cut when it exceeds a couple of inches, and not any of the tall ornamental varieties that the more general term also encompasses. In each case, then, an R-inference takes us from the more general meaning of the term to a more specific meaning denoting the stereotypical instance. The same is true of kill above, in which the narrower sense of the term (indicating direct and intentional causation) is hyponymically related to the broader sense; thus, kill is its own hyponym.
Note that in this way, the Division of Pragmatic Labor may affect the historical development of a term’s lexical semantics, as a lexical form becomes more and more tightly identified with the R-affected meaning; thus, Horn notes, corn has shifted from its more general meaning of “grain” to denote the most important grain in a particular culture (maize in the United States, but wheat in England and oats in Scotland).
Scalar implicature is another case in which the meaning of a lexical item is affected by pragmatics. We saw above, for example, that and and or can be placed on a scale of degree of informational content, with the use of or Q-implicating “not and”:
| (67) | You may have a slice of pie or a scoop of ice cream for dessert.
+> You may not have both a slice of pie and a scoop of ice cream for dessert. |
The italicized utterance is truth-conditionally compatible with a situation in which the implicature does not hold; that is, it is true in a situation in which the addressee is free to have both desserts. Thus, the implicated meaning (which in Chapter 1 was called “exclusive or”) is pragmatic rather than semantic; nonetheless, it is the meaning generally associated with or, and hence constitutes a generalized conversational implicature – specifically, a generalized scalar implicature, due to the fact that the contrast set in question constitutes a Horn scale, with p and q entailing p or q.
Pragmatics affects the development of the lexicon in additional ways as well. Horn points out that two tendencies of languages – first, to avoid synonymy, and second, to avoid homonymy – can be explained in terms of the Q/R tension. Avoid Synonymy (Kiparsky 1983) is a speaker-based (hence R-based) principle, since it’s in the speaker’s interest not to have to develop and keep track of a lot of different ways of saying the same thing. Avoid Homonymy, on the other hand, is a hearer-based (hence Q-based) principle, since it’s in the hearer’s interest not to have to hear a lot of homonyms and try to figure out which meaning the speaker intended for each one. Thus, once the language has a word like typist, it will tend not to also develop a word like typer to mean the same thing (in a process known as “lexical blocking” (Aronoff 1976)), even though the agentive –er morpheme would seem to be available for such a use; to develop typer would be to develop a set of synonyms, violating R. For this reason, when processes of morphological derivation do result in the development of a new word that would seem, by virtue of its constituent morphemes, to duplicate the meaning of an existing word, the new word will generally take on a meaning that excludes that of the existing word. For example, the word refrigerant morphologically suggests the meaning “something that refrigerates,” and this is in fact what a refrigerant does – except that its meaning specifically excludes the ground covered by the word refrigerator (Kiparsky 1983). A refrigerant may chill things, but it may not be a container that chills what is contained within it, because the word refrigerator already has that territory covered. Where there is no additional territory for the new word to cover, its development is blocked; hence, the existence of inhabitant blocks the development of *inhabiter; the difference between refrigerant/refrigerator and inhabitant/*inhabiter is that there is semantic ground left over within the range of “that which refrigerates” beyond what is covered by the term refrigerator, whereas there is no semantic ground left over within the range of “one who inhabits” that is not already covered by the word inhabitant. Similarly, a cooker is a thing that cooks, but never a person who cooks, since that semantic ground is already covered by the noun cook: To allow cooker and cook to mean the same thing would violate “avoid synonymy,” while to allow cooker to mean both things would violate “avoid homonymy.” As we have seen in Chapter 1, synonymy and homonymy do of course exist in language (although many have argued that true synonymy in the sense of complete identity of meaning doesn’t exist within a given language), but the countervailing speaker and hearer interests tend to keep them to at least a workable minimum.
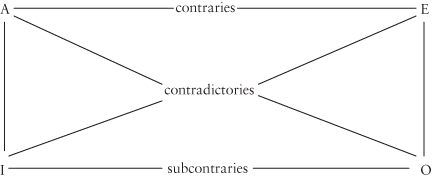
Pragmatic factors also play an interesting role in determining what meanings end up not getting lexicalized at all. Horn (2009 and elsewhere) cites the Aristotelian Square of Opposition, illustrated in (68):
| (68) | The Square of Opposition: Examples:
A: all/every F is G
I: some F is/are G
E: no F is G
O: not every F is G; some F is/are not G |
You could be forgiven for not immediately seeing the import of this square; however, it encapsulates a nice point about the workings of language. First, notice that the left edge is the “positive” side of the square, with the A corner representing positive “universal” values such as all and every and the I corner representing positive “particular” values such as some and sometimes, while the right edge is the “negative” side, with the E corner representing negative “universal” values such as no and never and the O corner representing negative “particular” values such as not every and not always.
Now consider again the left, positive, edge of the square; a consideration of some sample A and I values will demonstrate that the relationship between A and I along this edge gives us our old friend the scalar implicature, where A in each case expresses a universal, and I expresses a particular. As expected, the A cases entail their corresponding I cases, and the utterance of I implicates that A does not hold, as in (69–73):
| (69) | a. All dogs are friendly. → Some dogs are friendly.
b. Some dogs are friendly. +> Not all dogs are friendly. |
| (70) | a. Everyone painted the shed. → Someone painted the shed.
b. Someone painted the shed. +> Not everyone painted the shed. |
| (71) | a. I always feel like crying. → I sometimes feel like crying.
b. I sometimes feel like crying. +> I don’t always feel like crying. |
| (72) | a. Both of my parents are Irish. → One of my parents is Irish.
b. One of my parents is Irish. +> It’s not the case that both of my parents are Irish. |
| (73) | a. Chris and Jane will sing alto. → Chris or Jane will sing alto.
b. Chris or Jane will sing alto. +> It’s not the case that Chris and Jane will sing alto. |
We see that in the (a) cases, the universal entails the particular (all dogs are friendly entails some dogs are friendly, as long as the world contains dogs), while in the (b) cases, use of the particular implicates that the universal does not hold (use of some dogs are friendly implicates that not all dogs are friendly).
The same is true on the right, negative, edge of the square, where universal negation entails particular negation, while use of the particular negation implicates that universal negation does not hold:
| (74) | a. No dogs are friendly. → Not every dog is friendly.
b. Not every dog is friendly. +> It’s not the case that no dogs are friendly. |
| (75) | a. Nobody painted the shed. → Not everybody painted the shed.
b. Not everybody painted the shed. +> It’s not the case that nobody painted the shed. |
| (76) | a. I never feel like crying. → I don’t always feel like crying.
b. I don’t always feel like crying. +> It’s not the case that I never feel like crying. |
| (77) | a. Neither of my parents is Irish. → It’s not the case that both of my parents are Irish.
b. It’s not the case that both of my parents are Irish. +> It’s not the case that neither of my parents is Irish. |
| (78) | a. Neither Chris nor Jane will sing alto. → Chris and Jane will not both sing alto.
b. Chris and Jane will not both sing alto. +> It’s not the case that neither Chris nor Jane will sing alto. |
Here again, we see that the universal E entails the particular O (no dogs are friendly entails not every dog is friendly), while the use of the particular O implicates that the universal E does not hold (use of not every dog is friendly implicates that it’s not the case that no dogs are friendly – or, to put it more simply, at least some dogs are friendly).
The terms contraries, contradictories, and subcontraries in (68) are simply labels given to relations between items at various corners of the square; thus, A and E (all dogs are friendly and no dogs are friendly) are said to be contraries, I and O (some dogs are friendly and not every dog is friendly) are said to be subcontraries, and opposing corners of the square (all dogs are friendly and not every dog is friendly, and no dogs are friendly and some dogs are friendly) are said to be contradictories. Contraries are characterized by the fact that both items in the pair cannot be simultaneously true; it cannot be simultaneously true that all dogs are friendly (A) and that no dog is friendly (E). Thus, the truth of one sentence guarantees the falsity of its contrary. Notice, however, that both may be simultaneously false; it could be that neither all dogs are friendly nor no dogs are friendly is true. Contradictories, on the other hand, are characterized by not only the fact that both items in the pair cannot be simultaneously true (as for contraries), but also by the fact that both items in the pair cannot be simultaneously false; not only is it impossible for no dogs are friendly and some dogs are friendly to be simultaneously true, it is also impossible for them to be simultaneously false. Thus, given a pair of contradictories, the truth of one will guarantee the falsity of the other, while the falsity of one will guarantee the truth of the other. Finally, in the case of subcontraries, it is not the case that the truth of one guarantees the falsity of the other; it may be simultaneously true that some dogs are friendly (I) and that not every dog is friendly (O). However, the falsity of one guarantees the truth of the other; it is not possible for both some dogs are friendly and not every dog is friendly to be simultaneously false.
Thus, the Square of Opposition captures some interesting regularities about language, and about the relationships among entailments, contradictions, and implicatures. Even more interesting, however, is the resulting set of constraints on lexicalization (Horn 1972, 2009, inter alia): While languages regularly contain lexical items corresponding to the A, I, and E corners of the square (e.g., all, some, none), they tend not to contain lexical items for the fourth, O corner. Consider again the examples above in (74)–(78); notice that while the E sentences contain lexicalized (one-word) negations, the O sentences need multiple words to express the parallel meaning: Corresponding to E’s no in (74), we have O’s not every; corresponding to E’s nobody in (75), we have O’s not everybody, corresponding to E’s never in (76), we get O’s not always, and corresponding to E’s neither in (77) and (78), we get O’s not both – and there’s no evident way in which these could be replaced with one-word alternatives. As Horn notes, full lexicalization would lead us to expect the paradigm in (79):
| (79) | A: all dogs
I: some dogs
E: no dogs
O: *nall dogs (= not all dogs) |
But we don’t get a single-word option for O. Why not?
Notice – if you haven’t already – that O is exactly the negation of A, and that I is exactly the negation of E. Now recall that the use of I implicates the negation of A (some dogs implicates “not all dogs”), and that the use of O implicates the negation of E (not all dogs implicates “not no dogs”). Therefore, loosely speaking, I (some) and O (not all), the subcontraries, implicate each other: Some dogs implicates not all dogs and vice versa. That being the case, there is no need to lexicalize both corners, since to utter one conveys both. Once a language has a lexical item corresponding to the positive I, there is no need for it to also have an item corresponding to the negative O, since uttering I will convey O. Since a given language needs only one or the other corner lexicalized, and since negation is the relatively marked member of the pair, the principle of speaker’s economy predicts both that only one or the other will be lexicalized, and also that the one lexicalized will be the less marked member, that is, the positive member. Hence, languages should tend not to have lexical items corresponding to *nall (“not all”), *neveryone (“not everyone”), *nalways (“not always”), *noth (“not both”), and *nand (“not and”) – and this is precisely what has been found to be the case.
The above discussion of Hornian Q-/R-implicature, Levinsonian Q-/I-/M-implicature, and Hornian lexical pragmatics has looked at the data from a neo-Gricean perspective. The primary competitor to neo-Gricean theory in current pragmatics is Relevance theory, initially developed by Sperber and Wilson (1986). As its name suggests, Relevance theory takes relevance to be central to human communication, and indeed takes it to be so central to human cognition in general that no set of distinct communication-specific maxims is necessary. Notice that Grice in fact made the same point about the maxims of the Cooperative Principle, that is, that they are not language-specific: Thus, if I ask you for a wrench, I’ll expect you to give me as much as I asked for, no more than I asked for, to do it in a straightforward manner, and so on. However, whereas Grice considered the four maxims to be independently necessary, and Horn and Levinson have minimized and/or reorganized them, Sperber and Wilson argue that the maxims should be eliminated altogether, that relevance alone is sufficient, and that it needn’t be considered an independent communicative principle so much as a basic feature of our more general cognitive processes.
Relevance theory assumes a single Communicative Principle of Relevance:
Communicative Principle of Relevance: Every ostensive stimulus conveys a presumption of its own optimal relevance.
(Wilson and Sperber 2004)
An “ostensive stimulus” is a stimulus intended to convey meaning. Because human communication is considered merely an outgrowth of the natural processes of cognition, the Communicative Principle of Relevance in turn is seen as following from the more general Cognitive Principle of Relevance:
Cognitive Principle of Relevance: Human cognition tends to be geared to the maximization of relevance.
(Wilson and Sperber 2004)
What the Principle of Relevance tells us, in short, is that the hearer assumes that what the speaker intends to communicate is sufficiently relevant to be worth the trouble of processing it, and also that this is the most relevant communication the speaker could have used to convey the intended meaning. That is, the mere act of communicating carries an assurance of relevance.
Relevance, in turn, is defined in terms of positive cognitive effects (that is, changes in how one sees the world), with one major type of positive cognitive effect being the contextual implication. Just as in standard Gricean theory implicatures were derived from a combination of the utterance, the context, and the maxims of the Cooperative Principle, in Relevance theory contextual implications are derived from a combination of the utterance (or other input), the context, and the human tendency to maximize relevance. Given this tendency, Sperber and Wilson argue, the other maxims are superfluous. One interesting thing to notice is the shift in focus from the Gricean and neo-Gricean theories to Relevance theory: For Grice, inferences were primarily due to an assumption of interpersonal cooperativity – an approach that was retained by Horn and Levinson in the cooperative negotiation between the needs of the speaker and of the hearer (although Horn acknowledges (2009, inter alia) that interlocutors’ recognition of the human tendency to avoid unnecessary effort is more likely attributable to rationality than to cooperation per se, and indeed Grice (1975) takes pains to argue that the maxims of the Cooperative Principle have their basis in rational behavior). In Relevance theory, this focus on the interactive aspect of communication has of course not vanished, but it has given up its prominence in favor of a central focus on general cognitive processes within a single human mind.
So is a contextual implication the same as a conversational implicature? No, although conversational implicatures are one type of contextual implication. A contextual implication is any positive cognitive effect that is derived from the interaction of the context, the input, and the search for that input’s relevance. The hearer’s task is to follow the “path of least effort” (Wilson and Sperber 2004) in identifying contextual implications and calculating cognitive effects until the expectation of relevance has been sufficiently met, at which point the calculation can stop and the hearer may assume they have found the intended meaning.
To illustrate, let’s look again at an example we considered in our discussion of the maxim of Relation in Chapter 2 (example (33b), here repeated as (80)):
| (80) | Once upon a sunny morning a man who sat in a breakfast nook looked up from his scrambled eggs to see a white unicorn with a gold horn quietly cropping the roses in the garden. The man went up to the bedroom where his wife was still asleep and woke her. “There’s a unicorn in the garden,” he said. “Eating roses.” She opened one unfriendly eye and looked at him. “The unicorn is a mythical beast,” she said, and turned her back on him. |
Upon encountering the wife’s utterance The unicorn is a mythical beast, the addressee (on one level, the fictional husband; on another, the reader) wishes to maximize the relevance of that utterance, which in turn means searching for possible positive cognitive effects in the form of contextual implications. The addressee can be assumed to have as background knowledge the fact that mythical beasts don’t exist in the real world. Combining that fact with the wife’s utterance yields the deduction that unicorns don’t exist in the real world, since it’s entailed by the premises “the unicorn is a mythical beast” and “mythical beasts don’t exist in the real world.” This result – the conclusion that unicorns don’t exist in the real world – seems like a positive cognitive effect, and therefore we will take it to be a contextual implication of the utterance. But there’s no reason to stop there; having derived a new proposition, let’s check it for further relevance. Can “unicorns don’t exist in the real world” be added to our context to yield further positive cognitive effects? As it happens, it can: Combining “unicorns don’t exist in the real world” with “the garden is a part of the real world” straightforwardly yields “unicorns don’t exist in the garden.” Again, a positive cognitive effect (in the sense of being a validly derived, relevant fact). So once again this can be combined with the context in the hope of finding further relevance, and the search is rewarded: From “unicorns don’t exist in the garden,” one can logically derive “no specific unicorn exists in the garden,” and from “no specific unicorn exists in the garden” in the context of the husband’s prior utterance of there’s a unicorn in the garden, one can derive “you are wrong,” at which point we might well decide we have arrived at a point of sufficient relevance (a yield of four contextual implications – not bad!) and stop.
There’s a hitch, however: As with neo-Gricean theory, we must ask ourselves how the claims of Relevance theory can be made falsifiable, that is, empirically testable and hence scientifically interesting. In the case of (80), we chose one path to travel down, but to be frank, that path was selected in part through the knowledge of where we wanted to end up. That is, we knew (somehow) that our goal was to arrive at “you are wrong,” and that guided us down the path of “unicorns don’t exist in the real world,” and so on. What if, instead of “mythical beasts don’t exist in the real world,” we had come up with “mythical beasts are often written about in books,” which constitutes background knowledge about mythical beasts that is at least as widely believed as the proposition that they don’t exist in the real world? Certainly the fact that mythical beasts are written about in books could have been the first fact about mythical beasts that we pulled out of our cognitive hat. What would have happened then?
Well, obviously we would not have gotten very far. We might straightforwardly have derived “unicorns are often written about in books” (which, you might note, is not actually entailed by “mythical beasts are often written about in books,” but it needn’t be entailed to be a potential contextual implication). At that point, however, we’d have to stop, since there’s no obvious way in which we could combine “unicorns are often written about in books” with the context to derive a positive cognitive effect. It’s not that no further effects are possible: We could certainly combine “unicorns are often written about in books” with “there’s a unicorn in the garden” to get “there’s a creature in the garden of a type often written about in books,” but it becomes immediately clear that we’re getting farther away from any truly relevant cognitive effects.
There is, then, a bit of a chicken-and-egg issue here: How do we know which “path” of contextual implications to travel without first knowing where we want to end up? Put another way, how do we determine which set of contextual implications will yield the most positive cognitive effects without trying out every possible set (an infinitely long procedure)? More fundamentally, how can we measure cognitive effects, or relevance more generally?
The answer is actually reminiscent of what we have already seen with neo-Gricean theory, in the sense that it involves a tension between the minimization of effort and the maximization of effect. Relevance itself is defined as a function of processing effort and cognitive effects (where cognitive effects include the drawing of new conclusions, rejection of old assumptions, and strengthening of old assumptions), with the most relevant result being the one that gives the highest cognitive payoff at the lowest processing price. More specifically, the higher the processing cost, the lower the relevance, and the greater the positive cognitive effects, the higher the relevance. Again, of course, this raises questions of how to measure processing cost and/or cognitive effects, which some (e.g., Levinson 1989) have argued is in fact impossible. Even if it were straightforward to measure one or both of these, it’s hard to imagine that the same unit of measurement could be used. What sort of measure could quantify both the degree of processing effort expended and the degree of cognitive effects achieved, so that they could be compared? Critics argue that if it’s impossible to measure processing effort or cognitive effects, or to compare them quantitatively, the theory cannot make any actual predictions.
Interestingly, however, we also find ourselves in a situation that is somewhat similar to the neo-Gricean Q/R and Q/M trade-offs; the difference is that in the case of Relevance theory, the trade-off is essentially built into a single complex concept – that of relevance – but it is worth remembering that the concept of relevance contains within it the same tension between effort and payoff that we’ve seen with Horn and Levinson. Again, however, we see a difference between the two theories in their focus: In neo-Gricean theory, the trade-off is between the speaker’s interests and the hearer’s interests, whereas in Relevance theory, the trade-off is within the cognitive system of an individual, who must balance his or her own cognitive payoff against the cognitive cost of attaining it. Thus, for Relevance theorists, the tension is a cost/benefit assessment within a single individual, whereas for neo-Griceans, the tension is between cost to the speaker in terms of production effort and cost to the hearer in terms of processing effort. Even within the neo-Gricean perspective, of course, speakers lack direct access to a hearer’s discourse model and thus have only their own model of the hearer’s model on which to base their judgment of the payoff to the hearer. In that sense, this tension as well exists only within a single individual. The difference is that the individual in question, in deciding how to frame their utterance, is balancing their interests against the other’s interests, whereas under Relevance theory the hearer balances their own cognitive payoff against its cognitive cost.
In addition to refocusing the Gricean apparatus in terms of a language user’s general cognitive processes, Relevance theory has contributed in an important way to the conversation that Grice began concerning the difference between what is said and what is implicated. On the original Gricean view, semantics operates on an utterance to provide the truth-conditional meaning of the sentence. With this truth-conditional meaning in mind, the hearer then considers the context in order to infer the speaker’s intended meaning. This two-stage model, however, has a critical flaw: There are a number of ways in which the truth-conditional meaning of a sentence cannot be fully determined without reference to contextual, inferential, and hence pragmatic information. Consider (81):
| (81) | After a while, he raised his head. (Rand 1957) |
The impossibility of assigning a truth value to this utterance in the absence of further context should be immediately clear, since the truth conditions are unavailable. The truth conditions, in turn, are unavailable for a number of reasons, including but not limited to the following:
Some of these difficulties are more obvious than others. Obviously we need to know who he refers to in order to know whether it’s true that he raised his head (even Grice noted that reference resolution and disambiguation might be required for a fully truth-conditional proposition). Likewise, we need to know whose head is being referred to: It could be the same individual, but it could also be someone different (e.g., perhaps he refers to a doctor, who is raising his patient’s head to give him a sip of water). A bit more subtly, a while could be five minutes or five days, depending on shared assumptions – and after truth-conditionally could allow the phrase after a while to denote any time after “a while” has passed, be it five minutes later, five days later, or five millennia later. Imagine a context in which your professor tells you he will be available to meet with you after class and then is unavailable until three hours after the class has ended. Would you say the professor had lied to you – that is, that the original utterance was false – or that what the professor had said was literally true? Do the truth conditions of after class depend on an enrichment of the meaning based on contextual inference? There are also subtle differences in various meanings of the words raise and head; to raise one’s head is a different sort of raising from raising someone else’s head or raising an object, and a head can be one’s own head, or the head on a glass of beer, or a skull, or a doll’s head. The intended senses of raise and head are clear only because the words appear together – that is, each word forms part of the textual context for the other, which in turn is part of the basis for our inference regarding the speaker’s intended meaning.
It won’t do to simply say that the truth conditions for (81) are something like “after a contextually determined, relatively brief amount of time, a salient male raised a salient head that stands in some salient relationship to him”; the utterance in (81) depends for its truth on the particular identifiable individual meant by he, even if there’s another salient male in the context, and similarly for the other aspects of the meaning listed above. In short, we can’t possibly establish the truth conditions for (81) without first establishing who he is, who his refers to, and so on.
Therefore, pragmatic information is required as an input to truth conditions – but at the same time, truth-conditional meaning is required as an input to pragmatic processes. For example, in order to determine that a speaker is flouting the maxim of Quality, a hearer must have access to the truth conditions of the sentence to determine that its truth value in a given case is false, and blatantly so. This leads to a circularity in the traditional two-stage plan: We can’t calculate the pragmatics without access to the semantics, and we can’t calculate the semantics without access to the pragmatics.
Relevance theory’s notion of explicature solves this problem. The explicature in an utterance is the result of enriching the semantic content with the sorts of pragmatic information necessary to provide us with a truth-evaluable proposition. This includes calculating the referents for pronouns, working out the intended interpretation for deictic phrases like here and later (see Chapter 4), disambiguating lexically and structurally ambiguous words and phrases, making any “bridging” inferences necessary for reference resolution (as when the speaker says I can’t ride my bike because a tire is flat and the hearer infers that the flat tire is one of the two tires on the bike (see Chapter 8)), and so on. In the case of (81), the resulting explicature might be something like (82):
| (82) | After something between a few moments and several minutes, Francisco d’Anconia lifted his own physical head off of the surface it had been resting upon. |
This represents (more or less) a proposition that can be evaluated in terms of truth or falsity in a given context. This need for pragmatic input into what is said – the truth-conditional content of an utterance – has been generally agreed upon, although scholars differ with respect to precisely how this pragmatic input interacts with semantic meaning. (Compare also Bach’s 1994, 1997, 2001 related notion of IMPLICITURE, which expands utterances such as I haven’t eaten breakfast to “I haven’t eaten breakfast yet today,” since the latter, unlike the former, returns the correct truth conditions for the speaker’s intended meaning.)
In Relevance theory, the enrichment from semantic meaning to explicature is achieved via the Principle of Relevance. Just as the search for implicated meaning is guided by the assumption of optimal relevance, so also the determination of explicature is guided by the assumption of optimal relevance. The semantic meaning in combination with the assumption of relevance gives rise to the explicature, which is the fully enriched truth-conditionally complete proposition; and this explicature in combination with the assumption of relevance gives rise to the inferred pragmatic meaning, complete with implicatures.
As we’ve seen above, there are a number of differences between neo-Gricean theory and Relevance theory, including the following:
With respect to the first point, it’s important to notice Relevance theory’s emphasis on the automatic nature of relevance-based inferences. For Grice, it was important that conversational implicatures be calculable – capable of being “worked out,” whether they actually were or not. The suggestion is that for many inferences, especially the particularized conversational implicatures, this calculation does in fact happen at some (presumably usually subconscious) level. Relevance theory also expects such a calculation, and in fact one fallout of the workings of the Relevance Principle is that virtually all (if not all) implicature becomes particularized, hence in need of working out (see Levinson 2000 for detailed discussion). But unlike Grice and the neo-Griceans who followed him, Relevance theorists argue that purposeful calculation and purposeful application of the Relevance Principle play no role in human communication: Humans have no choice but to pursue relevance, to assume the optimal relevance of a communicated message, and to draw whatever inferences follow from that assumption. There is no flouting of Relevance, no decision as to whether to violate it or to opt out altogether. The language user cannot consciously consider the cost/benefit tension and decide on a given occasion to err on the side of minimizing processing cost while accepting a lessened cognitive benefit; the idea would be akin to deciding to expend less cognitive effort processing the color red while accepting a lessened likelihood of recognizing it.
In short, underlying the most readily apparent differences between the two theories regarding their updated treatment of Grice’s maxims, there are more serious differences in the theories’ approaches to the nature of human communication, human cognition, and the role of semantic and pragmatic information in linguistic meaning. In the remainder of this chapter, we will consider in more detail the ways in which these theories treat two aspects of language, one largely theoretical and the other applied (in the sense of showing the result of applying the theories to a specific class of linguistic phenomena). As one focus of this book is the question of the semantics/pragmatics boundary, we will begin by considering the ramifications of the two theories for this issue; we will then consider scalar implicature and how these two theories view the inferences involved in scalar phenomena.
In standard Gricean theory, a central distinction is made between what is said and what is implicated. Consider again the taxonomy of meaning from Chapter 2, repeated here:
| (83) | 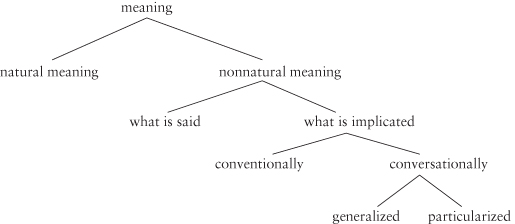 |
In this taxonomy, the dividing line between what is said and what is implicated maps onto the dividing line between truth-conditional and non-truth-conditional meaning, which in a truth-conditional semantics also constitutes the dividing line between semantics and pragmatics. (Natural meaning, including a wide range of non-linguistic and non-intentional phenomena, falls into neither category.) There is, however, another way to view the (neo-)Gricean world of nonnatural meaning (adapted from Neale 1992; Horn forthcoming):
| (84) | 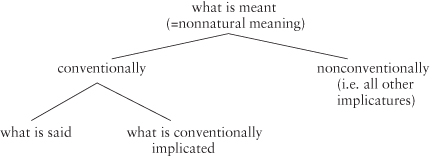 |
This diagram suggests a different semantics/pragmatics boundary, distinguishing between what is conventionally (hence semantically) encoded in language and what is nonconventionally conveyed, e.g., via conversational implicature (although Neale 1992 follows Grice in leaving the door open for other types of potential implicatures as well, based on other types of maxims, e.g., social or aesthetic norms). It’s not clear which view Grice himself would have embraced, but it is clear that conventional implicature lands on two different sides of the semantics/pragmatics fence under the two views.
Newer proposals allow specific types of pragmatic reasoning to affect “what is said,” in the sense that context-based inferences must figure into, for example, resolving ambiguities, deixis, and pronoun reference (e.g., who is meant by he in (81)). In both of these neo-Gricean world views, however, the “explicature” of Relevance theory is rejected: To the extent that reasoning based on contextual inference is required to establish an element of meaning, that element is not explicit in any obvious sense, and it moreover draws on the same inferential resources as implicatures; neo-Griceans therefore include it in the category of implicated meaning. A theoretician might choose to include such an element of meaning in the category of what is semantically encoded in the sentence (via, for example, syntactic co-indexing) or might instead choose to consider it pragmatic and thus allow pragmatics to figure into the calculation of semantic meaning, but for neo-Griceans, considering such meanings to constitute inferentially determined, explicit meaning is a contradiction in terms: If it’s inferentially determined, it’s not explicit.
Notice also that even if both sides of the semantics/pragmatics divide require inferential processing and reference to context, the types of enrichment that are necessary for a fully developed proposition are quite different from the types of implicatures that reside on the right side of the dividing line, in particular because the former serve as part of the input to the latter. The neo-Gricean perspective, then, retains the two-stage, largely linear Gricean process in which what is said combines with context and the maxims to give rise to what is implicated, while not requiring all semantic reasoning to precede all pragmatic reasoning.
Relevance theory, on the other hand, does not divide the world so neatly. For Relevance theorists, pragmatic and semantic meaning jointly contribute to an intermediate stage of what is explicated. Relevance theory, like Gricean (and neo-Gricean) theory, is modular, and retains a distinction between semantics and pragmatics; however, in Relevance theory, the semantic meaning is purely the output of linguistic decoding – working out the basic lexical meanings and morphological and syntactic relationships in the sentence as indicated by what is specifically encoded – and may fall short of a full proposition, as noted above. Pragmatics, therefore, contributes to the explicature (the full truth-conditional proposition) and also to the implicature (the intended non-truth-conditional meaning). For Relevance theory, then, the crucial distinction is not so much between semantics (linguistically encoded meaning) and pragmatics (contextually inferred meaning), but rather between explicature (which has both semantic and pragmatic components) and implicature (which is purely pragmatic). Thus, Relevance theory begins with a distinction between encoded and inferred meaning, and adds a distinction between explicit, truth-conditional meaning and implicit, non-truth-conditional meaning:
| (85) | 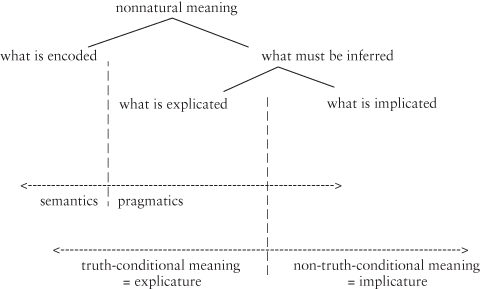 |
In this view, there is an important distinction between explicit and implicit meaning, but it does not map onto the distinction between semantics and pragmatics. It does, however, map onto the distinction between truth-conditional and non-truth-conditional meaning. One result of this way of placing the dividing line between semantics and pragmatics is that pragmatic inference no longer has to be seen as contributing to the semantics of an utterance. (Note also the absence of a notion of “what is said” here; see Carston 2009 for discussion of this point.)
In short, the quarrel over the status of the semantics/pragmatics boundary boils down to this: Should we draw the line on truth-conditional grounds, recalling that the entire impetus for Grice’s original theory of pragmatics (and indeed the field of pragmatics itself) grew out of the need to explain how we get from truth-conditional meaning to what the speaker actually intended? Or in view of his discussion of conventional implicatures, should we take conventionality to be the crucial factor? Or in view of the need for inferential meaning to seep into the determination of truth-conditional meaning, should we define the boundary in terms of inferential vs. non-inferential meaning? In short, should pragmatics be defined as implicated meaning (83), non-conventional meaning (84), or inferential meaning (85)? (See Neale 1992; Bach 1999; Horn forthcoming; and Carston 1999 for further discussion of possible ways to draw the semantics/pragmatics boundary.)
Notice what is conspicuously absent in (85) as compared with (83): the various subcategories of implicature, that is, all of the material that appears under “what is implicated” in (83). This isn’t just to save space; in Relevance theory, those categories are absent. Relevance theory defines semantics as meaning that is conventionally encoded, much as in the neo-Gricean model in (84). Both of these models, then, would take conventional implicatures as part of the semantic meaning of the sentence. But conventional implicature as a category is altogether absent from Relevance theory, on the grounds that the type of meaning that Grice put into this category simply counts as part of the semantic meaning. Grice’s need to create a separate category for conventional implicatures hinged on the intuition that a sentence such as (86) is true if Clover is both a labrador retriever and very friendly, regardless of whether labradors are generally friendly:
| (86) | Clover is a labrador retriever, but she’s very friendly. |
That is, the fact that labradors are typically friendly does not, in Grice’s view, affect the truth of (86). However, it must be acknowledged that for many people, this is not a robust intuition.
Relevance theory likewise lacks a category of generalized conversational implicatures. Recall that generalized conversational implicatures are those that generalize to an entire class of related utterance types, as in the examples from Chapter 2 repeated in (87):
| (87) | a. Jane served watercress sandwiches and animal crackers as hors d’oeuvres. She brought them into the living room on a cut-glass serving tray and set them down before Konrad and me … (= (21))
b. Most of the mothers were Victorian. (= (41a)) |
In (87a), the implicature is one of ordering: Jane first brought the hors d’oeuvres into the living room and then set them down. In (87b), the implicature is scalar: Not all of the mothers were Victorian. These constitute generalized conversational implicatures because although they are defeasible (hence not conventional), they nonetheless generalize to an entire class of usages of and and most, respectively. For Relevance theory, such a category is unnecessary; these inferences are part of the explicated meaning of the utterance, and their defeasibility is not an issue since defeasible pragmatic meaning is regularly and uncontroversially included in the category of explicature. For a neo-Gricean, however, the defeasibility of these implicatures makes a great deal of difference: The implicature of ordering in (87a) can be (rather clumsily) cancelled by adding … but not necessarily in that order, while the scalar implicature in (87b) can be cancelled by adding … and in fact all of them were, suggesting that these aspects of meaning behave like, and should be categorized with, other conversational implicatures.
In short, Relevance theory takes these two categories of meaning – what Grice called conventional implicature and generalized conversational implicature – and moves them out of the arena of implicature. Conventional implicatures are taken to be included in the category of what is encoded (hence part of semantic, truth-conditional meaning), and generalized conversational implicatures are taken to be included in the category of what is explicated (hence part of pragmatic but still truth-conditional meaning). We will next consider in somewhat more detail the category of scalar implicatures, which as a case of Gricean generalized conversational implicature receive quite different treatments in the two theories.
Let’s abandon the Victorian mothers for now and consider some additional cases of scalar implicature, all occurring within a page of each other in the same book:
| (88) | a. We know that the earth spins on its axis once every twenty-four hours …
b. But it is very difficult, if not impossible, for you to determine how many vibrations there are and what their rates are.
c. When you listen to a single note played on an instrument, you’re actually hearing many, many pitches at once, not a single pitch. Most of us are not aware of this consciously, although some people can train themselves to hear this. (Levitin 2007) |
Stripping out extraneous context, we get the following generalized conversational implicatures:
| (89) | a. the earth spins on its axis once every 24 hours
+> the earth spins on its axis no more than once every 24 hours b. it is very difficult
+> it is not impossible c. most of us are not aware of this consciously
+> some of us are aware of this consciously d. some people can train themselves to hear this +> not all people can train themselves to hear this |
By now, you should be able to see straightforwardly why these implicatures arise, why they are considered to be scalar implicatures within the Gricean framework, and why they are also considered (again, within the Gricean framework) to be generalized conversational implicatures. You might object that in (89a) the implicature is unnecessary, since the reader is almost certainly assumed to know that the earth spins on its axis once every 24 hours; however, a hearer who does not already happen to know this will effortlessly and reliably make the inference. Thus, since Grice requires only that the implicature be calculable, not that it actually be calculated, this stands as a case of scalar implicature. Note also that in (88b), the implicature is immediately cancelled: it is very difficult, if not impossible. As shown in (89b), it is very difficult implicates “it is not impossible”; however, by following up with if not impossible, the writer explicitly indicates that it may in fact be impossible, which cancels the scalar implicature generally associated with difficult (where difficult and impossible form a Horn scale in which impossible entails difficult, and the use of difficult therefore implicates not impossible). This defeasibility supports the status of this inference as resulting from a conversational implicature in the Gricean system (but not within the Relevance framework).
For Relevance theorists, no such class of generalized conversational implicature is warranted. There are no generalized classes of implicatures attending large classes of linguistic phenomena; there is only the Principle of Relevance, operating on sentential semantics to return optimal cognitive effects. Levinson (2000) criticizes Relevance theory on these grounds, arguing that Relevance theory reduces all inferences to particularized, essentially nonce inferences, ignoring obvious generalizations regarding classes of phenomena, and requiring more effort from the cognitive apparatus than is necessary (or likely). That is, upon encountering the phrase most of us in (88c), Levinson would argue that we infer the scalar reading “not all of us” due to our knowledge of the generalized scalar implicature from most to “not all,” without having to recalculate the inference (however subconsciously) in each individual instance. Indeed, the very frequency of cancellations such as some if not all and reinforcements such as some but not all support the notion that a generalized implicature of “not all” is associated with the use of words like some and most.
For Relevance theorists, on the other hand, utterances containing words like some and most are underspecified with respect to their upper bound, and hence are essentially ambiguous between two readings: “at least some/most” and “some/most but not all”; these two readings are illustrated in (90–91):
| (90) | a. Some people can train themselves to hear this.
b. You may have some of the cookies.
c. I got some of the exam questions wrong.
d. Most of us are unaware of this.
e. You may have most of the cookies.
f. I got most of the exam questions wrong. |
| (91) | a. I hope to see some of the Supreme Court justices while I’m visiting Washington.
b. You need to wash some of your clothes.
c. I’ve seen some wonderful sculptures by Rodin.
d. Most of my friends agree with me.
e. You should try to take most of your available vacation days.
f. Most men lead lives of quiet desperation. |
In (90), the most readily accessible readings for some and most are bidirectional, incorporating the meaning “not all”: Thus, (90a) suggests not only that there are people who can train themselves to hear this but also that not all people can train themselves to hear this, (90b) suggests that you may have some but not all of the cookies, and so on. In (91), on the other hand, the most accessible readings are unidirectional, meaning essentially “at least some/most” but remaining neutral on the status of “all”: Thus, the speaker in (91a) is not suggesting that they hope not to see all of the justices, the speaker in (91b) is not suggesting that you should not wash all of your clothes, the speaker in (91c) does not exclude the possibility of having seen all of Rodin’s wonderful sculptures, the speaker in (91d) does not exclude the possibility that all of their friends agree, the speaker in (91e) does not suggest that you should be sure not to take all of your available vacation days, and the speaker in (91f) does not exclude the possibility that in fact all men lead lives of quiet desperation.
For Relevance theorists, this is a case of ambiguity at the propositional level, with the correct choice of meaning to be contextually determined via the application of the Principle of Relevance, resulting in one or the other meaning as part of the explicature. For neo-Griceans, Occam’s Razor demands that the inferences to “not all” in (90) be treated as a single class rather than each case being evaluated individually; they are therefore taken as a case of generalized conversational implicature.
One immediate ramification of this difference is that the two approaches differ in their predictions for the truth conditions of the bidirectional cases. If “not all” is part of the explicature, it is also part of the truth-conditional meaning of the utterance; hence the cases in (90) should be false when the proposition holds not only of “some/most” but also of “all.” Thus, (90a) Some people can train themselves to hear this should be false if it turns out that all people can train themselves to hear it, (90b) You may have some of the cookies should be false if it turns out that you may have all of the cookies, and so on. On the neo-Gricean view, “not all” is only an implicated part of the meaning, hence not truth-conditional; therefore, these utterances remain true in the described situations in which the proposition holds not only of “some/most” but also of “all.”
For cardinal numbers, the situation is slightly more complicated. Carston (1988) and Ariel (2004, 2006) treat cardinals (like other scalars such as some and most) as semantically underspecified with respect to the status of higher amounts. Horn (2009, inter alia) agrees that even within a neo-Gricean account, the cardinal numbers involve underspecification; most people do not feel that someone who says I ate five of the brownies has said something true if they’ve actually eaten six of the brownies (unless the context specifically makes salient the question of whether five brownies were eaten), but they don’t seem to have said something quite false, either. However, he argues, in this sense the cardinals differ from the other scalars. Consider the exchanges in (92):
| (92) | a.
A: Did most of the brownies get eaten?
B: No. b. A: Do you have three children?
B: No. |
In (92a), B’s response conveys that either half the brownies or fewer than half the brownies were eaten. If “not all” were a possible part of the truth-conditional meaning of most (either under an ambiguity account or an underspecification account), then B’s denial could be construed as denying not only “most” but also “not all,” resulting in the meaning “either fewer than 51 percent of the brownies got eaten, or else all of them did.” But clearly B’s utterance in (92a) cannot be used to convey that all of the brownies got eaten.
Now compare (92a) with (92b). On the traditional Gricean view, three implicates “not four,” and indeed this can be taken as part of the truth-conditional meaning in some contexts; that is, in some contexts (e.g., providing census data), B’s denial can be construed as denying not only “three” but also “no more than three,” resulting in the meaning “I have either fewer than three children or else more than three children.” This is parallel to the meaning we discounted in (92a), but here it seems entirely plausible; that is, in (92a) B cannot reasonably be considered to be excluding only the semantic territory of some while leaving open the possibility of higher values such as “all,” but in (92b) B can reasonably be considered to be excluding only the semantic territory of three while leaving open the possibility of higher values such as “four.” Thus, on Horn’s view the cardinal numbers are amenable to an analysis in which the uttered cardinality is asserted while higher values are unspecified (hence are neither unidirectional nor bidirectional in their semantic meaning), whereas other scalar terms such as some and most receive a unidirectional semantic analysis (“at least some/most …”), with the bidirectional meaning (“… but not all”) contributed by a generalized scalar implicature.
Setting aside the cardinal numbers, we see that Relevance theory and neo-Gricean theory take very different approaches to the interpretation of scalars. The neo-Gricean position retains much of Grice’s original formulation in which the scalar form x has a semantic meaning of “at least x” and is subject to a generalized scalar implicature to the effect of “at most x,” whereas in Relevance theory the form x is ambiguous between explicatures of “at least x” and “exactly x.” Corresponding to this difference is an underlying difference in the truth-conditional nature of the “no more than x” component of the meaning, which for Relevance theorists is part of the explicature and hence truth-conditional but for neo-Griceans is an implicature and hence non-truth-conditional. Thus, your choice between these two perspectives will largely hinge on your reaction to examples like those in (90) when uttered in a case where the proposition holds of “all”: If some people x strikes you as true in a case where x in fact holds of all people, that is consistent with neo-Griceanism; if it strikes you as false, that is consistent with Relevance theory. Negation, not surprisingly, flips these intuitions: If B’s negative response in (92a) to the question Did most of the brownies get eaten? strikes you as true in a case where all of the brownies got eaten, that is consistent with Relevance theory, whereas if it strikes you as false, that is consistent with neo-Griceanism.
Chapter 2 described Grice’s original formulation of the Cooperative Principle and its maxims; in this chapter we have traced the two predominant lines of pragmatic theory that have developed since Grice. We first examined neo-Gricean theory in its two most prominent variants, the Q/R model of Horn and the Q/I/M model of Levinson. We saw that both approaches are based in a fundamental tension between speaker’s economy and hearer’s economy, from which implicatures are derived. These same principles were shown to play a role in the distribution and development of lexical meanings. We then turned our attention to Relevance theory, which emphasizes linguistic inference as being one aspect of a more general cognitive tendency to seek out relevance. Here the tension was between cognitive pressures toward minimization of processing and toward maximization of cognitive effect, which in turn give rise to both explicatures and implicatures. Neo-Gricean theory and Relevance theory were compared and contrasted, in particular with respect to their implications for the semantics/pragmatics boundary and their treatment of scalar implicature. Once again we saw that the choice between these two ways of drawing the semantics/pragmatics division hinges largely on one’s approach to truth conditions and their contribution to linguistic meaning.
3.5 Exercises and Discussion Questions
1. Chapter 1 discussed at some length the importance of using naturally occurring language data, yet this chapter has relied largely on constructed examples, which better suited the comparison of the three primary frameworks discussed. Having mastered the differences among these frameworks, go back to Chapter 2, select any two natural language examples of speaker-based inferences and any two natural language examples of hearer-based inferences, and explain how each of the four would be handled by Horn, by Levinson, and by Sperber and Wilson.
2. Relevance theorists have treated not only generalized conversational implicatures but also certain particularized conversational implicatures as part of the explicature. Examine the two cases of metaphor below. Describe how each would be treated within a Gricean framework, explain why a Relevance theorist might want to consider these meanings part of the explicature, and discuss the ramifications for the two theories’ views of the truth-conditional status of metaphorical meanings.
3. It was briefly noted that Bach (1994, 1997, 2001) introduced the notion of IMPLICITURE to cover the expansion of (a) to (b), and of (c) to (d):
The idea is that implicitures contribute to the truth-conditional content of the utterance but are not explicitly represented in the linguistic content of the utterance. Argue for or against the need for a notion of impliciture that is distinct from explicature and implicature, first in the neo-Gricean system and then in the Relevance system. To what extent can existing constructs in each theory account for the necessary inferences? How might the introduction of impliciture improve, or fail to improve, each theory?
4. Each of the three major theories discussed in this chapter (those of Horn, Levinson, and Sperber and Wilson) makes use of a tension between two opposing forces. Compare and contrast this aspect of the theories; what are the opposing forces in each case, and how does the tension help the hearer to identify the intended meaning? Which theory do you find most convincing in this respect?
5. Some theorists (Bach, Horn, and others) have objected to the term “explicature” on the grounds that, since the “explicated” meaning must be inferred, that meaning is by definition not explicit. In what ways is the explicated meaning like the encoded meaning, and in what ways is it like the implicated meaning? With which category does it fit more naturally, in your view?
6. Consult with a native (or near-native) speaker of a language other than English, and try to elicit lexical items representing each corner of the Square of Opposition. Is it true in their language that the O corner is not lexicalized – that is, that it can only be expressed using multi-word forms?
7. Which of the theories discussed in this chapter best meets our criterion of falsifiability? Why?
8. Based on what you have read in these first three chapters, decide where you think the line between semantics and pragmatics should be drawn, and argue for this position.
9. The fact that we say we have five fingers on each hand suggests that we consider the thumb to be a finger. Nonetheless, if I say I broke one of my fingers today, you are likely to infer that it was not my thumb. Give one account of this within the Q/R framework, and another within the Relevance framework.
10. It has been noted that sentences like those below seem to have different truth conditions:
What would be the implications for pragmatic theory of saying that the truth conditions of these sentences differ? Do you feel that their truth conditions differ? If so, why? If not, why not?