Chapter 2. Natural Language Basics
What Is Natural Language?
One of the most important faculties humanity has is language. Language is an essential part of how our society operates. Although it is such an integral function of humanity, it’s still a phenomenon that is not fully understood. It is primarily studied by observing usage and by observing pathologies. There has also been much philosophical work done exploring meaning and language’s relationship to cognition, truth, and reality. What makes language so difficult to understand is that it is ubiquitous in our experiences. The very act of producing and consuming statements about language contains the biases and ambiguity that permeate language itself. Fortunately, we do not need to go into such high philosophies! However, I like to keep in mind the grandeur and mystery of language as an anchor as we dive into the material in this book.
Many animals have complex communication systems, and some even have complex societies, but no animal has shown the ability to communicate such complex abstractions as humans do. This complexity is great if you are looking to survive the Neolithic period or to order a pizza, but if you are building an application that processes language, you have your work cut out for you. Human language appears to be much more complex than any other communication system. Not only do the rules of our language allow infinite unique sentences (e.g., “The first horse came before the second horse, which came before the third, which came before the fourth. . .”), they also allow us to create incredible abstractions. Both of these aspects relate to other human cognitive abilities.
Let’s take a brief foray into the origins of language and writing in order to appreciate this phenomenon that we will be working with.
Origins of Language
There is a lot of debate about the origins of human language. We’re not even entirely sure when or where modern human language first developed or if there is a single place and time where language originated. The gestural theory suggests that sign language originated first, followed later by verbal language, which developed alongside the physiological traits necessary for making more and more complex sounds. Another interesting debate is whether language developed in stages or all at once.
Even the mechanisms children use to acquire language are not fully understood. In the Middle Ages, it was thought that if a child was not taught language they would speak the “original” or “natural” language. There are stories of such intentional and unintentional experiments being performed, and various results have been claimed. In modern times, there have been some tragedies that have let us observe what happens when a human is not exposed to language in early childhood. When children are not exposed to language until after a critical period, they have a severe difficulty in learning and understanding complex grammar. There appears to be something special about young children’s language acquisition that allows them to learn our complex communication system.
In these tragic situations, in which a child doesn’t acquire a language in the critical period, the victims are still able to learn words, but they have difficulty learning complex syntax. Another tragedy that has taught us about language is the FOXP2 gene and its effect on those who have mutations in it. It appears that some mutations of this gene lead to verbal dyspraxia, a difficulty or inability to speak. One difficulty experienced by those with verbal dyspraxia is the inability to form long or complex sequences of sounds or words. The existence of this gene, which appears to allow us to create complex sequences, raises questions about the origins of language. If we did not have complex language before evolving the FOXP2 gene, what advantage could this gene have imparted that led to it being selected?
In the 1980s, a number of schools for deaf children were built in Nicaragua. Initially, these children communicated using “home signs,” or rudimentary and highly motivated signs. A motivated sign is one whose form is determined, or at least influenced, by that which it represents—for example, pantomiming the act of putting something in one’s mouth to represent food. Over time, the younger children combined these different sign systems into a more and more complex, and abstract, sign language. Eventually, a completely new language was born, with fully complex grammar and abstract unmotivated signs.
Regardless of how, when, and where language originated, we know that the written form came much later.
Spoken Language Versus Written Language
Written language was developed only a few thousand years ago. Written language does not, and cannot, represent all the nuances possible in spoken or gestured language. Language is more than a sequence of sounds or gestures. It is combined with facial gestures and changes in the manner of the production of sounds or gestures. These are called paralinguistic features.
There are a few ways in which paralinguistic features can be written. When they are present, they can be used to access complex intents.
Click sounds are often seen as an exotic feature of some languages in southern Africa, but they are also used as a paralinguistic feature in some European languages. In English, the “tsk tsk” or “tut tut” sound indicates disappointment, annoyance, or even disgust. Although there are agreed-upon written representations, these aren’t true words. Outside of depictions of spoken language, you will rarely find these represented in text.
Tone is another sound used as a linguistic feature in some languages, and as a paralinguistic feature in others. Mandarin uses four tones, but English uses tone as a paralinguistic feature. Chinese logograms represent entire words and so don’t need to represent tone separately, but the Latin-based Pinyin writing system used to phonetically represent Mandarin represents tone by marks over the vowels. English has some ways to represent these sort of paralinguistic features. Consider the difference between the following:
- You know the king.
- You know the king?
The difference between these two sentences is purely tone and pitch. The question mark indicates that the sentence should be interpreted as a question, and so it also indicates the general tone and pitch of the sentence.
Facial gesturing is an example of a paralinguistic feature that is not possible to represent in traditional text. In modern writing, facial gestures are arguably represented by emojis or emoticons. There is still much nuance that is difficult to interpret.
Let’s consider the scenario in which you ask to reschedule a lunch with a friend. Say they respond with the following:
- OK :)
In that response, you can’t tell what the smile indicates. They could be using it because you are known for rescheduling, so this is humorously expected. They could be using it out of habit. On the other hand, say they respond with the following:
- OK. . .
In this response, the ellipsis is much harder to interpret. It could represent annoyance, or it could simply be an indicator that there is another message forthcoming. If this exchange had been communicated in person, there would be less ambiguity, because these things can be perceived in facial gestures and other paralinguistic features.
Let’s look now at the field of linguistics, as this will give us a structured way of exploring these considerations when looking at language data.
Linguistics
Linguistics is the study of human language. There are many subfields of linguistics, but there are generally two types: one focused around elements of language and one focused around how language is used. There are also a number of interdisciplinary fields that connect linguistics and another field. Let’s look at a few subfields.
Phonetics and Phonology
Phonetics is the study of the sounds used in verbal languages. Because we will be focusing on text data, we will not be using this subfield much. The fundamental unit is the phone or phoneme (these are different things but are used in different kinds of analysis). These units are represented using the International Phonetic Alphabet (IPA). The IPA uses symbols to represent a great variety of sounds. I will use it in this section without much explanation, but if you are interested in learning more about IPA and its symbols, there are plenty of great resources online.
Languages have phonologies, which are collections of phonemes and rules about how to use and realize the phonemes. When a phoneme is realized it is a phone. In English, /t/ is a phoneme (/*/ is the convention for writing phonemes, and [*] is the convention for phones), and /t/ has multiple possible realizations:
- [tʰ]
- At the beginning of a stressed syllable: “team,” “return”
- [t]
- After an /s/ like “stop,” at the end of a word like “pot,” and even between vowels in some dialects (UK, India), or at the beginning of an unstressed syllable like “matter” or “technique”
- [ɾ]
- A flap sound in some dialects (North America, Australia, New Zealand) between vowels
- [ʔ]
- A glottal stop in some dialects (UK) between vowels
Generally when working with text data, we are not concerned with phonetics, but it can be useful if we want to search using sound similarity. For example, we may want to search a list of names for someone named Katherine, but Katherine can be spelled in many different ways (Katheryn, Catharine, Katharine, etc.). Using an algorithm called Soundex we can search for similar sounding names by representing the query phonetically.
Morphology
Morphology is the study of morphemes. Morphemes are the smallest element that can carry meaning. There are four kinds of morphemes, defined by unbound versus bound and content versus functional:
- Unbound content morphemes, content morphemes, or lexical morphemes
Words that represent things or concepts themselves
Examples: “cat,” “remember,” “red,” “quickly”
- Unbound functional morphemes or functional morphemes
Words that perform a function in a sentence
Examples: “they,” “from,” “will” (when used to make the future tense)
- Bound content morphemes or derivational affixes
Affixes that turn one word into another
Examples: “-ty” (“royal” + “-ty” = “royalty”), “-er” (“call” + “-er” = “caller”)
- Bound functional morphemes or inflectional affixes
Affixes that indicate the function of a word in a sentence
Examples: “-(e)s” (plural, “cat” + “-(e)s” = “cats,” “pass” + “-(e)s” = “passes”), “-ed” (past tense, “melt” + “-ed” = “melted”)
There are some text processing algorithms that can be easily explained as removing or simplifying some kind of morpheme. Understanding these differences is a good start to understanding where you want to look for information in your text data. This information is language specific. What are functional morphemes in some languages are inflectional affixes in other languages, so understanding these distinctions can help inform your decisions in the basic processing for different languages.
One important distinction in morphology is whether the language is synthetic or analytic. This can be considered as a ratio of inflectional affixes to functional morphemes. The more inflectional affixes are used, the more synthetic the language is. English is considered a mostly analytic language, as is Mandarin, and can be referred to as isolating. Russian and Greek are more middle-of-the-road and can sometimes be called fusional. Turkish and Finnish are quite synthetic and are referred to as agglutinative. The typology of a language is vital to determining how to do the basic text processing. We will cover this in more depth when we discuss building applications for multiple languages.
Morphology is very closely related to syntax; in fact, both are often considered under an umbrella concept of morpho-syntax.
Syntax
Syntax is the study of how words are combined into phrases and sentences. There are multiple competing models for syntax. The models that are popular in the field of linguistics are not necessarily the popular models in computational linguistics and NLP.
The most common way that syntax is introduced is with phrase structure trees (PSTs). Let’s look at the PST in Figure 2-1 for the following sentence:
- I saw the man with the hat.
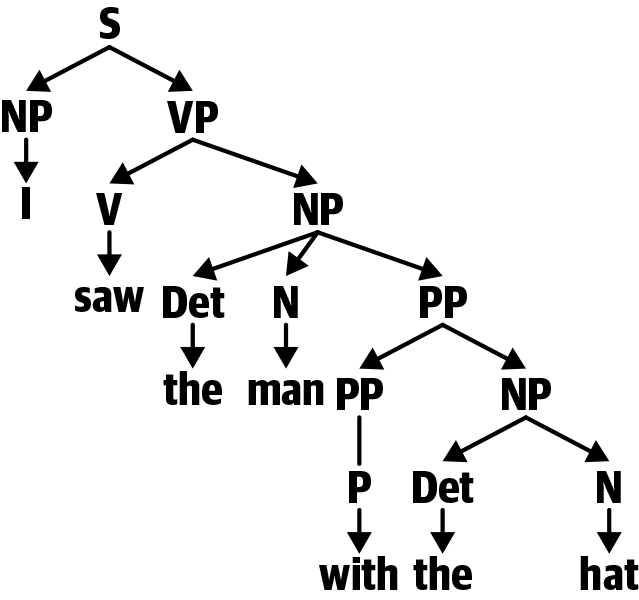
Figure 2-1. Phrase structure tree
PSTs are not really used outside of introducing syntax. Minimalist program grammars, tree-adjoint grammars, and head-driven phrase structure grammar are the popular models in linguistics, NLP, and computational linguistics, respectively. There are many different kinds of grammars, and we will go into them more when we cover syntactic parsers.
The difficult part of researching syntax is that models either are not sufficiently constrained—that is, they allow structures that are not observed in nature—or are excessively constrained, meaning they cannot express structures that are observed in nature. All the well-known grammars handle simple sentences, so theoretically for most NLP uses any model would work.
Syntax is a central aspect of human language, and extracting the information encoded with syntax can be computationally intensive. There are many ways to approximate the extraction. We will generally see that when we want to extract information, we will try and do so without actually creating a parsed structure. The reason for this is, as we said before, there are infinite potential phrases and sentences in the syntax of human languages. The algorithms that parse sentences are often quite expensive because of this.
Semantics
Semantics is the study of the meaning of linguistic elements. This field has close ties to various fields in philosophy, especially logic. One aspect of the field of semantics is modeling how meaning is composed from the structures of language, so semantics is most closely related to syntax. There are aspects of language meaning that can be seen as compositional; others are more complicated. Phrases and sentences can generally be decomposed, but dialogues, poems, and books are not so easily analyzed.
It would seem that we are always interested in extracting the semantics in text, and this is true after a fashion. What we should always keep in mind is that a text, a sentence, or even a word can have many different meanings. We’ll need to know what we are interested in before we build our NLP pipeline.
Most projects that use NLP are looking for the meaning in the text being analyzed, so we will be revisiting this field multiple times.
There are a couple of other subfields we should keep in mind—sociolinguistics and pragmatics.
Sociolinguistics: Dialects, Registers, and Other Varieties
Sociolinguistics is the study of language in society. It is an interdisciplinary field between sociology and linguistics. Understanding the social context of text is important in understanding how to interpret the text. This field also gives us a framework to understand how different data sets might be related to each other. This will be useful when we look at transfer learning.
A useful concept from sociolinguistics is the idea of language varieties, which covers the subjects of dialects and slang. The idea is that a language is a collection of varieties, and people have their own individual collection of varieties. The collection of varieties that an individual speaks can be considered an idiolect. The different varieties that an individual uses are called registers. Registers covers the concept of formality as well as other manners of speech, gesture, and writing.
Formality
Because language is a fundamental tool of human social interaction, many aspects of social behavior have representations in language. One aspect is the idea of formality. Formality is often talked about as a single spectrum from casual to formal, but it is more complex than this. The level of formality that a person working in retail is required to use with a customer is different from the levels of formality required when someone is applying for graduate school or talking to a grandparent. Very formal and very informal registers can lead to complications.
Highly formal registers often include content that doesn’t convey much meaning but is there to indicate formality. Consider the following hypothetical dialogue between a retail worker and a customer:
- Customer: Hello. Do you have any mangoes?
- Retail worker: Hmmm. . .I don’t think so, sir.
The customer’s question is relatively straightforward. Most people interpret the retail worker’s response as effectively equivalent in meaning to “No.” The initial “Hmm. . .” is either because the retail worker does not know and needs to consider whether the store carries mangoes, or because they are pretending to consider the request. An abrupt answer of “I don’t think so, sir” could be considered rude or dismissive. Similarly, the retail worker can’t just say “Hmm. . .no, sir” because that could be considered curt. The “sir” is purely a formal marker called an honorific.
Informal registers can be difficult to parse because shorthand and slang are commonly used within them. Additionally, we often use informal contexts with people we are closest to. This means that much of our communication in informal registers is in a deeply shared context. This can make using the most informal communication difficult.
Context
Registers are based not only on formality but also on context. Registers affect the pronunciation, morphosyntax, and even word meanings. When working with text data sets with language from different varieties, we must always keep in mind how the different varieties in our data set may be expressed.
Consider the meaning of the word “quiet” in two different kinds of reviews:
- The hotel room was quiet.
- The headphones are quiet.
In the first, “quiet” is a positive attribute, whereas it is likely negative in the second. This is a relatively straightforward example; the differences can be much more subtle, and they need to be taken into consideration when attempting to combine data sets or do transfer learning.
There is an entire subfield dedicated to understanding the use of language in context: pragmatics.
Pragmatics
Pragmatics is a subfield that looks at the use and meaning of language in context. Understanding pragmatics will help us understand the intent behind the text data we have. Pragmatics is a subfield that I think any NLP practitioner will come back to again and again.
Roman Jakobson
Although it is now somewhat old, I like the Roman Jakobson model of pragmatics (see Figure 2-2). The model is built around a simple abstract model of communication. The idea is that there are six different parts or factors to communications.

Figure 2-2. Roman Jakobson’s functions of language
In this model, there are six factors in communication, along with six functions. Each function focuses on its associated factor. Following are the six functions (with the associated factor):
- Emotive (the addresser)
- Messages that communicate the state of the addresser (“uh-oh!”)
- Conative (the addressee)
- Messages that have an intended effect on the addressee (“Open the window.”)
- Poetic (the message)
- Messages that are for the message’s own sake (poetry, scatting)
- Metalingual (the code)
- Messages about the code in which the message is encoded (“What do you call this?”)
- Phatic (the channel)
- Messages that establish or relate to the communication channel (“Hello!”, small talk)
- Referential (the context)
- Messages that convey information from the context (“It’s raining.”)
This model of pragmatics considers messages as focusing on some combination of these factors. It is often explained with examples of messages that focus mostly on one factor, but it should be kept in mind that most speech acts are a combination of focusing on several factors.
How To Use Pragmatics
When working with text data sets, it is worthwhile to consider why the messages were written. Understanding this requires a mix of pragmatics, sociolinguistics, and domain expertise. We might not always have access to a domain expert, but we can make educated interpretations of the pragmatics and social context of the data. These considerations should be made as early in the process as possible, because this will inform many decisions about how to work with our data.
Writing Systems
In this chapter we’ve discussed many aspects of language, but so far we’ve focused on aspects that are part of language that is either only spoken or both spoken and written. There is a great variety of writing systems, and they can strongly influence how we process our data.
Origins
Although writing is a recent development in human history, there still appears to be a physical adaptation. When a person becomes literate, part of the brain that specializes in character recognition, the letterbox, is activated. The letterbox is located in a similar place for all people regardless of which language they learn. There are different theories of its origin, but the existence of the letterbox is yet another example of how specialized humans and our language faculties are.
Writing appears to have been invented multiple times throughout history. There does appear to be a pattern of first creating highly motivated symbols that may not even correspond to words, also known as pictographs, which then get transformed and specialized.
The origin of the Latin alphabet has many interesting twists and turns. The generally accepted chain of cultures through which it evolved is as follows: The Latins borrowed from a Greek alphabet, but keep in mind that there were multiple Greek alphabets in the classical era. The Greeks in turn borrowed their characters from the Phoenicians, with the addition of some innovated letters. The Phoenicians were a tribe of Canaanites who lived on the coast of the Levant. The Canaanites all shared the same or similar characters in their writing system. This writing system appears to be based on simplified versions of Egyptian characters. Egyptian writing was a mix of logograms and phonetic symbols (similar to modern Japanese). The Canaanites took some of the phonetic symbols of Egyptian writing and adapted them to their own language, and then they simplified the appearance of these symbols until the pictographic elements were no longer noticeable. The Egyptians appear to have innovated their own writing system from a system of pictographs. At the same time, writing systems were being innovated in Sumer (modern-day Iraq), and China.
Figure 2-3 displays some letters and their origins in ancient pictograms.

Figure 2-3. Origins of some letters of the alphabet
Alphabets
An alphabet is a phonetic-based writing system that represents consonants and vowels. Here are some examples of alphabets:
- Latin
Latin is used throughout the world. Its use was spread during the colonial age. In order to be adapted to many different languages, many new characters were invented. The English alphabet is relatively simple (and arguably ill-fitted to English). Its modern form was defined in the early days of printing when special characters were more difficult or even impossible to represent.
English: “Hello!” pronounced /hɛˈloʊ/
- Cyrillic
Cyrillic is used in many countries in Eastern Europe, Central Asia, and North Asia. Its name comes from Saint Cyril, a ninth-century Byzantine monk who invented (or at least formalized) Glagolitic, the precursor alphabet to Cyrillic.
Russian: “Привет!” pronounced /prʲɪˈvʲet/
- Greek
Greek is used by modern Greek and its dialects, as well as by some minority languages in Greek-speaking majority areas. The Greek alphabet today is from the Attic (Athenian) Greek alphabet of the classical era.
Greek: “Γειά σου!” pronounced /ʝa su/
- Hangul
Hangul is used to write Korean and was invented in the 15th century under King Sejong. Korean is different from other alphabets in that the symbols are combined into syllable blocks. Consider the following example:
Korean: “ㅇ+ㅏ+ㄴ ㄴ+ㅕ+ㅇ” <- + a + n n + yeo + ng> becomes “안녕” pronounced /anɲjʌŋ/
Alphabetic scripts are generally straightforward, but be mindful of languages that use diacritics, marks on characters. Sometimes we may want to remove these as part of normalizing our data, and this can be complicated. However, this generally can be solved in a rule-based manner.
Abjads
An abjad is a phonetic-based writing system that primarily represents consonants and only optionally vowels. These writing systems are almost entirely written right-to-left, which is something to keep in mind when creating UIs for languages that use these scripts. Here are some examples of abjads:
- Arabic
Arabic (writing system) is used in writing Arabic (language), Farsi, Punjabi, and Urdu. Its use was spread with the rise of Islam. Arabic (writing system) is descended from the Aramaic abjad, which spread into the Arabian peninsula and developed a cursive form that we see today.
Arabic: “مرحبا” <m + r + h + b + a> pronounced [mær.ħɑ.bæː]
- Hebrew
Hebrew (writing system) is used in writing Hebrew (language), Aramaic, Yiddish, Ladino, and other languages of the Jewish diaspora. It developed from the ancient Canaanite abjads.
Hebrew: “שלום” <sh + l + o + m> pronounced /ʃaˈlom/
It may seem that not writing vowels would make it difficult to read. However, it is difficult only for those learning the language. This is why most abjads have optional marks for indicating vowels to help children and second-language learners. When we talk about different morphosyntactic systems we will see why writing vowels is less of a hindrance for Semitic languages.
Abugidas
An abugida is a phonetic-based writing system in which each character represents a syllable. Instead of having a separate character for each possible syllable (which is what a syllabary is), an abugida has one character per starting consonant with a default vowel and marks that change the vowel. Consider the most widely used abugida today, Devanagari. There is a character, क, that represents /ka/. If we want to change the vowel to /u/, we add the necessary mark, कु, and that represents /ku/. It is also common for there to be a special mark that indicates no vowel, which is generally used to represent consonants that occur at the end of a syllable. Historically, some languages did not have such a mark and relied on various conventions to indicate syllable-final consonants. The following are some examples of abugidas:
- Devanagari
Devanagari originated some time before the 10th century AD, developed from the earlier Brahmi script. We are not sure where the Brahmi script comes from, though it is thought to be derived from the Aramaic abjad.
Hindi: “नमस्ते” <na + ma + s - + te> pronounced /nəˈmə.ste/
- Thai
Thai (writing system) also derives from the Brahmi script. One interesting thing about the Thai writing system is that it also represents tone. There are special characters to mark tone, as well as intrinsic tones that are associated with certain characters.
Thai: “สวัสดี” <s + wa + s + di> pronounced /sa˨˩.wat˨˩.di˧/
- Ge’ez
Ge’ez (writing system) is used in East Africa to write various languages of Ethiopia. It is developed from a South Arabian script, likely unrelated to modern Arabic (writing system), which itself is a descendant from the earliest Canaanite scripts. Originally, Ge’ez was an abjad, but over time a default vowel developed, and the vowel marks became mandatory. Because the marks that change the default vowel sometimes change the shape of the character, it can be argued that Ge’ez might be a syllabary.
Amharic: “ሰላም” <sə + la + mə> ppronounced /səlam/
Syllabaries
A syllabary is a phonetic-based system of writing in which there is a different symbol for each possible syllable in a language. Unlike the other phonetic-based systems, syllabaries are often invented, instead of being derived. There are not many still in use today. Syllabaries, like alphabets, are generally pretty simple and straightforward, which makes working with them as data easier. The following are some examples of syllabaries:
- Hiragana
Hiragana is one of the syllabaries used to write Japanese. The other is Katakana, which is also used to write Ainu, an interesting language spoken in northern Japan and unrelated to Japanese. Hiragana and Katakana were developed from simplified representations of Chinese logographs, similar to how the Canaanite writing system developed from Egyptian. Japanese uses Hanji, Chinese logographs, combined with Hiragana. This is necessary because Japanese and Chinese are such different languages, with Japanese being an agglutinative language and Chinese being highly analytic. Katakana is used to write borrowed words and onomatopoeia (like English “woof,” and “bang”).
Japanese: “今日は” <kon + nichi + ha> pronounced “konit͡ɕiwa
- Tsalagi
Tsalagi is the syllabary invented by Sequoyah for writing his native Cherokee language. If you speak English you will recognize some of the characters, but that will not help in pronouncing them. The characters’ pronunciation has no connection to their pronunciation in English.
Tsalagi: “ᏏᏲ” <si + yo> pronounced /sijo/
Logographs
A logographic (also logosyllabic) system is a system based on a combination of semantics and phonetics. This is a somewhat miscellaneous category, since these systems often work very differently from one another. There is only one such system widely used today—Han Chinese characters. It is used to write most of the languages of China, as well as Japanese (Hanji, mentioned previously). These writing systems can make processing easier, because there is generally less decomposition possible, so basic text processing can be simplified. They can also complicate matters because they are often written without word separators (e.g., the space character), and they require more in-depth knowledge of the language to deal with nuanced processing.
- Han Chinese
Han Chinese characters use a logographic writing system in which each character generally represents a syllable in Chinese languages, though this is not necessarily the case in Japanese.
Chinese: “你好” <“you” + “good”> pronounced “ni˨˩ hau˨˩” in Mandarin Chinese, “nei˩˧ hou˧˥” in Cantonese
Encodings
When we work with text data, we are working with written data that has been encoded into some binary format. This may seem like a small matter, but it is a frequent source of difficulties, especially when working with non-English languages. Because the English-speaking world played such a large part in the development of modern computers, many defaults make sense only for English.
Let’s go over some details about encoding to keep in mind when (not if) we run into encoding issues.
ASCII
American Standard Code for Information Interchange (ASCII) is a mapping of control characters, Latin punctuation, Arabic numerals (as used in Europe), and English characters. It was originally designed for representing characters in teleprinters, aka teletypewriters, which is the origin of the abbreviation TTY.
Although this is an old standard, some legacy systems still support only ASCII.
Unicode
Since text is ultimately represented using bytes, there must be some mapping between numbers and characters. Your computer has no notion of “a,” it knows only numbers. Unicode is the standardized set of character-number mappings maintained by the Unicode Consortium. For example, “a” is mapped to 97. Characters are generally represented with a specific formatted hexadecimal number—for example “a” is U+0061. U+#### is the standard format for representing Unicode values. The characters are grouped by language generally. Here are some examples of blocks:
- Basic Latin (U+0000–U+007F): ASCII characters
- Latin-1 Supplement (U+0080–U+00FF): additional control codes, additional European punctuation, and common Latin characters used in Europe
- Cyrillic (U+0400–U+04FF): the characters for most languages that use a Cyrillic writing system
Unicode is implemented in different encodings. The most common of these encodings are maintained by the Unicode Consortium itself, and some by ISO and IEC.
UTF-8
8-bit Unicode Transformation Format (UTF-8) is variable width implementation of Unicode. It is variable width because characters in different ranges require a different number of bytes. It uses one byte to represent the ASCII characters. It uses two bytes to represent U+0080 to U+07FF, which covers the most commonly used alphabets and abjads (except Hangul). Three bytes covers CJK (Chinese-Japanese-Korean) characters, South Asian scripts, and most other currently used languages. Four bytes covers the rest of Unicode. It supports this by using a prefix of bits on a byte to indicate that it is part of a multibyte pattern.
UTF-8 has taken over as the most common encoding from ASCII and ISO-8859-1 (aka Latin-1). Unlike ASCII and ISO-8859-1, it supports languages outside of Western Europe. Data that is ASCII encoded is not a problem, since that represents the one-byte UTF-8 characters. However, ISO-8859-1 represents the Latin-1 Supplement with one byte as well. This leads to a common problem of data being encoded one way and decoded another. Let’s look at how “ñ” is represented and potentially mangled.
| char | latin1 enc | utf-8 enc | latin1 enc to utf-8 dec | utf-8 enc to latin1 dec |
|---|---|---|---|---|
| a | 61 |
61 |
a |
a |
| ñ | F1 |
C3 B1 |
INVALID |
ñ |
We’ll cover this topic more when we talk about productionization and multilanguage systems.
Exercises: Tokenizing
One of the most fundamental text processing techniques is tokenization. This is the process of taking a string of characters and breaking it into pieces, often words. This seems like a simple task, but since it is such an early stage in any NLP pipeline, getting it correct is vital. It is also going to be affected by the writing system of the language you are working with.
Let’s look at what might be some challenges for tokenizing a language. Let’s start with some basic tokenizers.
- Whitespace tokenizer
- Tokens are defined as the non-whitespace character sequences on either side of a whitespace character sequence.
- ASCII tokenizer
- Tokens are defined as a sequence of ASCII letters or digits.
The gaps parameter tells us how the tokenizer is defining a token. If it is set to True, then the pattern argument is defining what separates tokens. If False, it represents the tokens themselves.
fromnltkimportnltk.tokenize.RegexpTokenizerwhitespace_tokenizer=RegexpTokenizer(r'\s+',gaps=True)ascii_tokenizer=RegexpTokenizer(r'[a-zA-Z0-9_]+',gaps=False)
Tokenize Greek
Greek uses the same space character as English to separate words, so the whitespace tokenizer will work here:
whitespace_tokenizer.tokenize('Γειά σου Kόσμε!')
['Γειά', 'σου', 'Kόσμε!']
The ASCII tokenizer won’t work here, since Greek is not supported by ASCII:
ascii_tokenizer.tokenize('Γειά σου Κόσμε!')
[]
# Define a regex with gaps=False that will tokenize Greek pattern = r'' greek_tokenizer = RegexpTokenizer(pattern, gaps=False)
#assert greek_tokenizer.tokenize('Γειά σου Κόσμε!') == ['Γειά', 'σου', 'Kόσμε']
Tokenize Ge’ez (Amharic)
Amharic does not use the same character to separate tokens as English does, so the whitespace tokenizer won’t work:
whitespace_tokenizer.tokenize('ሰላም፡ልዑል!')
['ሰላም፡ልዑል!']
# Define a regex with gaps=True that will tokenize Amharic pattern = r'' amharic_sep_tokenizer = RegexpTokenizer(pattern, gaps=True)
#assert amharic_sep_tokenizer.tokenize('ሰላም፡ልዑል!') in (['ሰላም', 'ልዑል!'], ['ሰላም', 'ልዑል'])
Similarly, the ASCII tokenizer doesn’t work here either:
ascii_tokenizer.tokenize('ሰላም፡ልዑል!')
[]
# Define a regex with gaps=False that will tokenize Amharic pattern = r'' amharic_tokenizer = RegexpTokenizer(pattern, gaps=False)
#assert amharic_tokenizer.tokenize('ሰላም፡ልዑል!') == ['ሰላም', 'ልዑል']
Resources
- International Phonetic Association: the home page of the organization that maintains the international phonetic alphabet
- Omniglot: an online encyclopedia of writing systems
- Unicode Consortium: the home page of the organization that maintains Unicode
- YouTube channels:
- Langfocus: this channel does explorations of different languages
- NativLang: this channel covers interesting aspects and histories of languages
- Wikitongues: this is the channel of a nonprofit that gathers videos of people speaking different languages from around the world
- The Cambridge Encyclopedia of Language by David Crystal (Cambridge University Press)
- This is a great resource for many aspects of language and linguistics. If you are trying to deal with an aspect of language that you are unfamiliar with, you can probably get a start on what to research here.
- Course in General Linguistics by Ferdinand de Saussure (Open Court)
- Saussure is the father of modern linguistics. Although many of the hypotheses are outdated, the approach he takes is very informative. The way in which he breaks phonemes into features is still useful today.
- Fundamentals of Psycholinguistics by Eva M. Fernández and Helen Smith Cairns (Wiley-Blackwell)
- This is a great textbook for approaching psycholinguistics from a linguistics perspective. It includes a great deal of information that will help an NLP data scientist better understand the natural phenomenon they wish to model.
- Handbook of the IPA (Cambridge University Press)
- If you are looking to go deeper into linguistics, you will need to have an understanding of IPA. This book can also be helpful if you want to focus on speech instead of text.
- Language Files by the Department of Linguistics (Ohio State University Press)