Preface
And there I was, waiting for the big door to open, the big door that stood between me and my archnemesis. I found little comfort and protection, if any, sitting in what seemed my thin tin tank, looking around and searching for people in my same dire straits. Then, with a deep rumble, the big steel door of the ship opened, engines were started, and I followed the slow stream of cars. I drove by rather uninterested police officers, and there it was, my archnemesis: the first roundabout in Dover.
For European continental drivers like me, used to drive on the right side of the street (and yes, I do mean right), the first driving experience in the Land of Albion has always been a challenge. That difficulty compounded with the lack of roundabouts in Italy at the time, turning the whole thing into sheer nightmare. Yet, after a surprisingly short timespan, maybe thanks to the understanding and discipline of the indigenous drivers, I got so used to driving there, and to roundabouts as well, that after my return to Calais I found driving back in supposedly familiar lanes somewhat confusing.
I had overcome my fear, but I am digressing, am I? Well, this book should indeed be approached like a roundabout: There are multiple entry and exit points, and readers are expected to take their preferred route among the many options, possibly spinning a bit for fun. I should also mention that, however dreadful that driving experience was to me, it was nothing compared with the exam labor of my students of the terrifying quantitative methods course. I hope that this book will help them, and many others, to overcome their fear. By the same token, I believe that the book will be useful to practitioners as well, especially those using data analysis and decision support software packages, possibly in need of a better understanding of those black boxes.
I have a long teaching experience at Politecnico di Torino, in advanced courses involving the application of quantitative methods to production planning, logistics, and finance. A safe spot, indeed, with a fairly homogeneous population of students. Add to this the experience in teaching numerical methods in quantitative finance master’s programs, with selected and well-motivated students. So, you may imagine my shock when challenged by more generic and basic courses within a business school (ESCP Europe, Turin Campus), which I started teaching a few years ago. The subject was quite familiar, quantitative methods, with much emphasis on statistics and data analysis.
However, the audience was quite different, as the background of my new students ranged from literature to mathematics/engineering, going through law and economics. When I wondered about how not to leave the whole bunch utterly disappointed, the “mission impossible” theme started ringing in my ears. I must honestly say that the results have been occasionally disappointing, despite my best efforts to make the subject a bit more exciting through the use of business cases, a common mishap for teachers of technical subjects at business schools. Yet, quite often I was delighted to see apparently hopeless students struggle, find their way, and finally pass the exam with quite satisfactory results. Other students, who had a much stronger quantitative background, were nevertheless able to discover some new twists in familiar topics, without getting overly bored. On the whole, I found that experience challenging and rewarding.
On the basis of such disparate teaching experiences, this possibly overambitious book tries to offer to a hopefully wide range of readers whatever they need.
- Part I consists of three chapters. Chapter 1 aims at motivating the skeptical ones. Then, I have included two chapters on calculus and linear algebra. Advanced readers will probably skip them, possibly referring back to refresh a few points just when needed, whereas other students will not be left behind. Not all the material provided there is needed; in particular, the second half of Chapter 3 on linear algebra is only necessary to tackle Parts III and IV.
- Part II corresponds to the classical core of a standard quantitative methods course. Chapters 4–10 deal with introductory topics in probability and statistics. Readers can tailor their way through this material according to their taste. Especially in later chapters, they can safely skip more technical sections, which are offered to more mathematically inclined readers. Both Chapter 9, on inferential statistics, and Chapter 10, on linear regression, include basic and advanced sections, bridging the gap between cookbook-oriented texts and the much more demanding ones. Also Chapter 11, on time series, consists of two parts. The first half includes classical topics such as exponential smoothing methods; the second half introduces the reader to more challenging models and is included to help readers bridge the gap with the more advanced literature without getting lost or intimidated.
- Part III moves on to decision models. Quite often, a course on quantitative methods is declined in such a way that it could be renamed as “business statistics,” possibly including just a scent of decision trees. In my opinion, this approach is quite limited. Full-fledged decision models should find their way into the education of business students and professionals. Indeed, statistics and operations research models have too often led separate lives within academia, but they do live under the same roof in the new trend that has been labeled “business analytics.” Chapter 12 deals mostly with linear programming, with emphasis on model building; some knowledge on how these problems are actually solved, and which features make them computationally easy or hard, is also provided, but we do not certainly cover solution methods in detail, as quite robust software packages are widely available. This part also relies more heavily on the advanced sections of Chapters 2 and 3. Chapter 13 is quite important, as it merges all previous chapters into the fundamental topic of decision making under risk. Virtually all interesting business management problems are of this nature, and the integration of separate topics is essential from a pedagogical point of view. Chapter 14 concludes Part III with some themes that are unusual in a book at this level. Unlike previous chapters, this is more of an eye-opener, as it outlines a few topics, like game theory and Bayesian statistics, which are quite challenging and can be covered adequately only in dedicated books. The message is that no one should have blind faith in fact-based decisions. A few examples and real-life cases are used to stimulate critical thinking. This is not to say that elementary techniques should be disregarded; on the contrary, they must be mastered in order to fully understand their limitations and to use them consciously in real-life settings. We should always keep in mind that all models are wrong (G.E.P. Box), but some are useful, and that nothing is as practical as a good theory (J.C. Maxwell).
- Part IV completes the picture by introducing selected tools from multivariate statistics. Chapter 15 introduces the readers to the challenges and the richness of this field. Among the many topics, I have chosen those that are more directly related with the previous parts of the book, i.e., advanced regression models in Chapter 16, including multiple linear, logistic, and nonlinear regression, followed in Chapter 17 by data reduction methods, like principal component analysis, factor analysis, and cluster analysis. There is no hope to treat these topics adequately in such a limited space, but I do believe that readers will appreciate the relevance of the basics dealt with in earlier chapters; they will hopefully gain a deeper understanding of these widely available methods, which should not just be used as software black boxes.
Personally, I do not believe too much in books featuring a lot of simple and repetitive exercises, as they tend to induce a false sense of security. On the other hand, there is little point in challenging students and practitioners with overly complicated problems. I have tried to strike a fair compromise, by including a few of them to reinforce important points and to provide readers with some more worked-out examples. The solutions, as well as additional problems, will be posted on the book Webpage.
On the whole, this is a book about fact- and evidence-based decision making. The availability of information-technology-based data infrastructures has made it a practically relevant tool for business management. However, this is not to say that the following simple-minded equation holds:
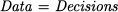
This would be an overly simplistic view. To begin with, there are settings in which we do not have enough data, because they are hard or costly to collect, or simply because they are not available; think of launching a brand-new and path-breaking product or service. In these cases, knowledge, under the guise of subjective assessments or qualitative insights, comes into play. Yet, some discipline is needed to turn gut feelings into something useful. Even without considering these extremes, it is a fact that knowledge is needed to turn rough data into information. Hence, the equation above should be rephrased as
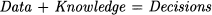
Knowledge includes plenty of things that are not treated here, such as good and sensible intuition or the ability to work in a team, which must be learned on the field. I should also mention that, in my teaching, the discussion of business cases and the practical use of software tools play a pivotal role, but cannot be treated in a book like this. Yet, I believe that an integrated view of quantitative methods, resting on solid but not pedantic foundations, is a fundamental asset for both students and practitioners.
Use of software. In writing this book, a deliberate choice has been not to link it with any software tool, even though the application of quantitative methods does require such a support in practice.1 One the one hand, whenever you select a specific tool, you lose a share of readers. On the other hand, there is no single software environment adequately covering the wide array of methods discussed in the book. Microsoft Excel is definitely a nice environment for introducing quantitative modeling, but when it comes, e.g., to complex optimization models, its bidimensional nature is a limitation; furthermore, only dedicated products are able to cope with large-scale, real-life models. For the reader’s convenience, we offer a nonexhaustive list of useful tools:
- MATLAB (http://www.mathworks.com/) is a numerical computing environment, including statistics and optimization toolboxes.2 Indeed, many diagrams in the book have been produced using MATLAB (and a few using Excel).
- Stata (http://www.stata.com/) and SAS (http://www.sas.com/) are examples of rich software environments for statistical data analysis and business intelligence.
- Gurobi (http://www.gurobi.com/) is an example of a state-the-art optimization solver, which is necessary when you have to tackle a large-scale, possibly mixed-integer, optimization model.
- AMPL (http://www.ampl.com/) is a high-level algebraic modeling language for expressing optimization models in a quite natural way. A tool like AMPL provides us with an interface to optimization solvers, such as Gurobi and many others. Using this interface, we can easily write and maintain a complex optimization model, without bothering about low-level data structures. We should also mention that a free student version is available on the AMPL Website.
- COIN-OR (http://www.coin-or.org/) is a project aimed at offering a host of free software tools for Operations Research. Given the cost of commercial licenses, this can be a welcome resource for students.
- By a similar token, the R project (http://www.r-project.org/) offers a free software tool for statistics, which is continuously enriched by free libraries aimed at specific groups of statistical methods (time series, Bayesian statistics, etc.).
Depending on readers’ feedback, I will include illustrative examples, using some of the aforementioned software packages, on the book Website. Incidentally, unlike other textbooks, this one does not include old-style statistical tables, which do not make much sense nowadays, given the wide availability of statistical software. Nevertheless, tables will also be provided on the book Website.
Acknowledgments. Much to my chagrin, I have to admit that this book would not have been the same without the contribution of my former coauthor Giulio Zotteri. Despite his being an utterly annoying specimen of the human race, our joint teaching work at Politecnico di Torino has definitely been an influence. Arianna Alfieri helped me revise the whole manuscript; Alessandro Agnetis, Luigi Buzzacchi, and Giulio Zotteri checked part of it and provided useful feedback. Needless to say, any remaining error is their responsibility. I should also thank a couple of guys at ESCP Europe (formerly ESCP-EAP), namely, Davide Sola (London Campus) and Francesco Rattalino (Turin Campus); as I mentioned, this book is in large part an outgrowth of my lectures there. I gladly express my gratitude to the authors of the many books that I have used, when I had to learn quantitative methods myself; all of these books are included in the end-of-chapter references, together with other textbooks that helped me in preparing my courses. Some illuminating examples from these sources have been included here, possibly with some adaptation. I have provided the original reference for (hopefully) all of them, but it might be the case that I omitted some due reference because, after so many years of teaching, I could not trace all of the original sources; if so, I apologize with the authors, and I will be happy to include the reference in the list of errata. Last but not least, the suffering of quite a few cohorts of students at both Politecnico di Torino and ESCP Europe, as well as their reactions and feedback, contributed to shape this work (and improved my mood considerably).
Supplements. A solution manual for the problems in the book, along with additional ones and computational supplements (Microsoft Excel workbooks, MATLAB scripts, and AMPL models), will be posted on a Webpage. My current URL is:
A hopefully short list of errata will be posted there as well. One of the many corollaries of Murphy’s law says that my URL is going to change shortly after publication of the book. An up-to-date link will be maintained on the Wiley Webpage:
For comments, suggestions, and criticisms, my e-mail address is
PAOLO BRANDIMARTE
Turin, February 2011
1 The software environments that are mentioned here are copyrights and/or trademarks of their owners. Please refer to the listed Websites.
2 The virtues of MATLAB are well illustrated in my other book: P. Brandimarte, Numerical Methods in Finance and Economics: A MATLAB-Based Introduction, 2nd. ed., Wiley, New York, 2006.