In this section, we're going to see how to use graphs to interpret the results of a machine learning model. Specifically, it's important to know what kind of data you have, because the type of data will determine the type of graph that you can create. This graph will then help you understand what goes into the predictions of a machine learning model. We will also understand how a machine learning model uses these different variables for the predictions and eventually use these predictions for our final interpretation.
For example, when we have an outcome variable that is a categorical variable and our predictor is also a categorical variable, we can use a bar chart or a web plot. We can use either type of graph to help us understand how the machine learning model is making its predictions. The following table represents data and graph combinations:
| Categorical | Continuous | |
| Categorical | Bar chart/web plot | Histogram |
| Continuous | Histogram | Scatter plot |
As we can see from the preceding table, when we have a categorical outcome variable but we have a continuous predictor, we might have to use a histogram. A histogram can help us to visually understand what's going on behind those predictions.
Now let's look into some other possibilities. Let's say that our outcome variable is actually a continuous variable but we had a categorical predictor, so here we could use a histogram. And finally, when we have an outcome variable that's a continuous variable and a predictor variable that's also a continuous variable, we can end up using a scatter plot. We will see examples related to this in the upcoming sections.
In the previous section, we built a neural net model. Let's take a look at the model that we built:
- Let's use the model that we created in the previous chapter:
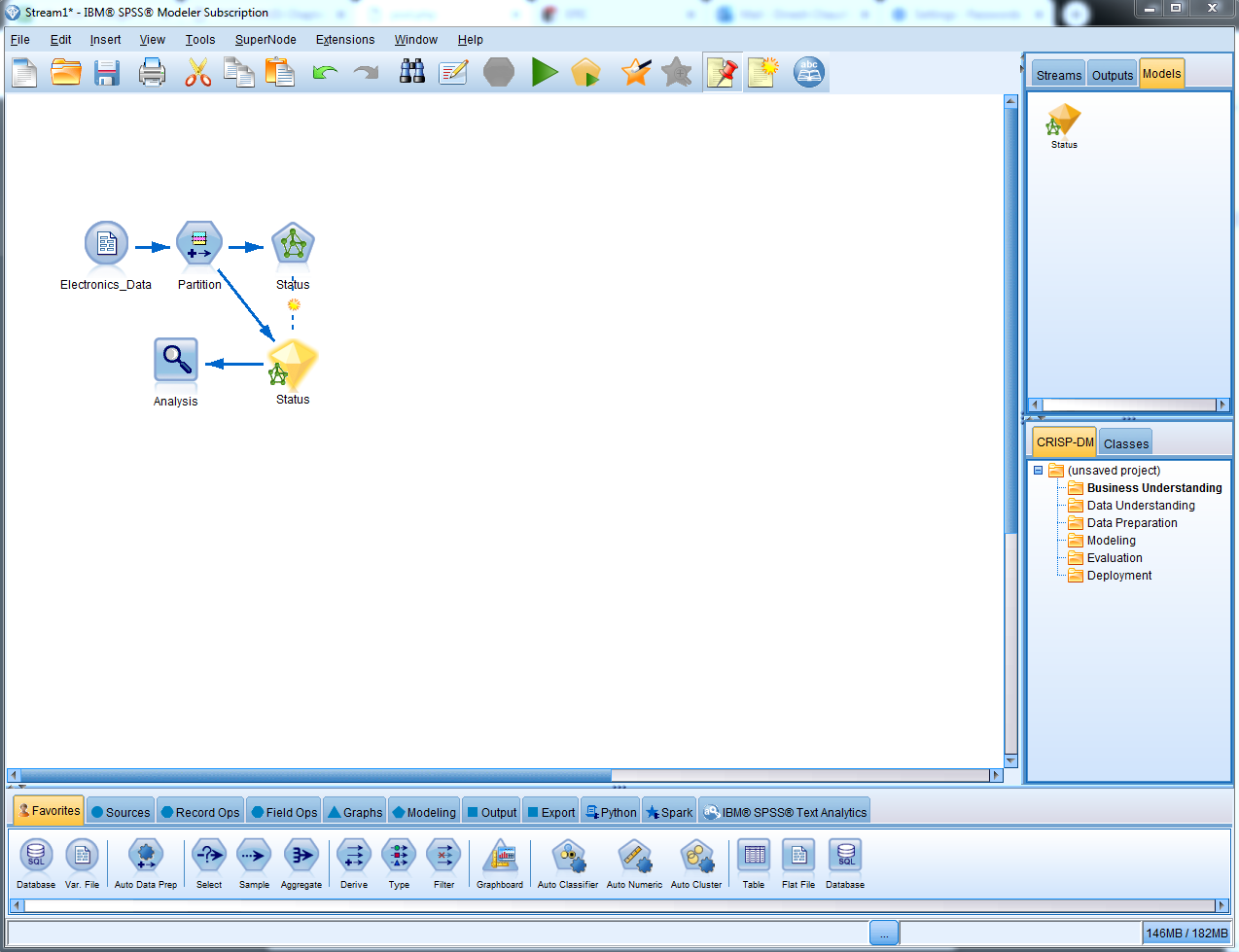
- Set the Random seed as 5000 and then run the model

- Click on the newly generated model and in the observations, we can see that the Premier variable is the most important predictor, followed by Years_as_customer, and then Stereos, TVs, and so forth:
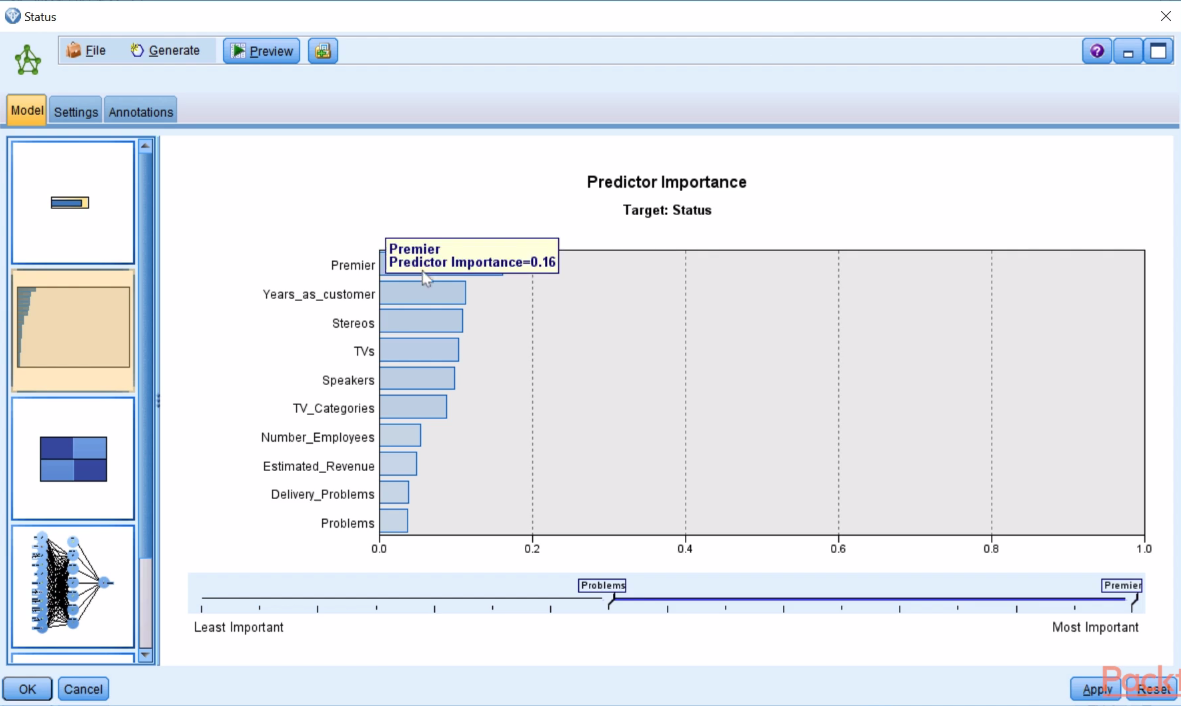
Now we know the most important predictors in this model, but we don't know how these predictors are being used by the model. Therefore, we will investigate their relationships.
There are several ways in which we can know about the relationships between components of the model. We can use graphs or tables. Let's go through a few examples:
- Select the Record Ops palette.
- Connect the generated model over to a Select node.
- Let's look at the data for the training dataset. We will keep the testing dataset separate because we will use that data later to confirm the findings.
- Click on the Select node to edit it.
- Click on the Expression Builder:
- Select any variable. For example, the Partition variable, select =, and the training dataset:
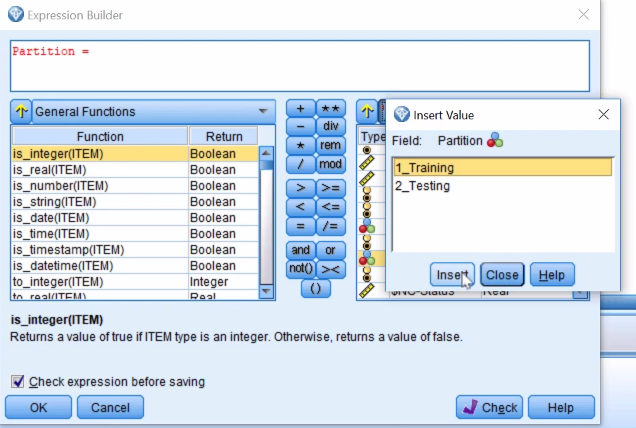
- This is how a expression will look also, click on OK:
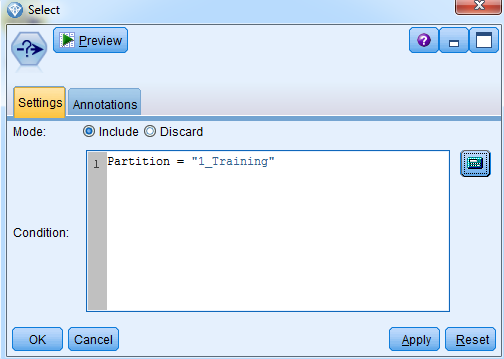
We have selected only the people in the training dataset. Now, let's take a look at the relationships between the actual predictions and the important variables in this model to figure out exactly how these variables are used by the model:
- Go to the Graphs palette and connect the Select node to a Distribution node. The Distribution node is basically a bar chart, as shown in the following screenshot:

- Edit the Distribution node. Select the Premier field:
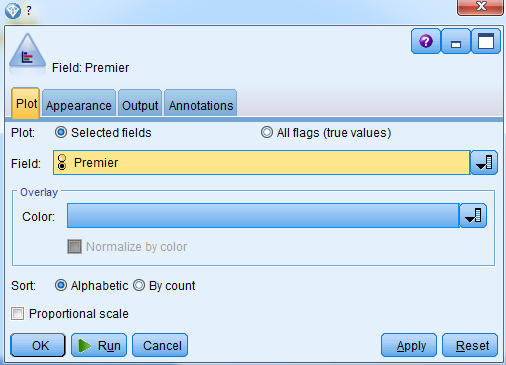
Notice that only categorical fields are available here:
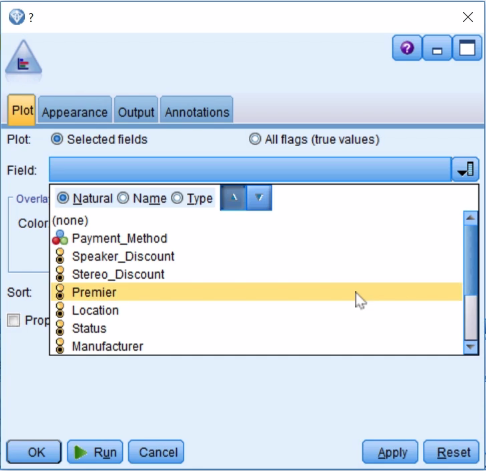
We are selecting the Premier variable because that was the most important predictor in the model and we will see how that variable is used in its predictions:
- Click on the overlay button:
- Select the variable $N-Status, which is our actual prediction:
- To make comparisons a little easier, click on normalize by Color:
- Click on Run and you can see what was done here:
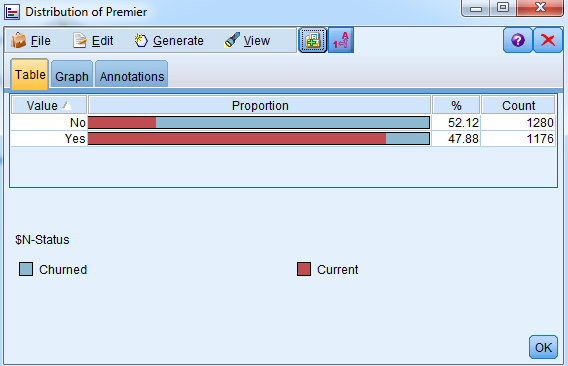
Notice that the blue color is associated with those who were predicted as going to churn, and the red color is associated with people who were predicted as current customers. You can also see that the people that are Premier customers we are associating them with being a current customer. The people that are not Premier customers we are associating them with the blue color which means that we're predicting that they're going to churn.
So that's how you investigate the relationship between a categorical predictor and a categorical outcome variable. We could use something similar to a bar chart, in this case, it's called the Distribution node in Modeler; it would be called as a bar chart in other software packages, but you're looking at the relationship between these two categorical variables and now you can see what's going on with these relationships. Let's use a Web node to look at the relationship between the two categorical variables:
- Go down to the Graphs palette and connect the Select node to the Web node:

- Edit the Web node, you can either build this as a Web, which basically allows us to take a lot of categorical variables and put them all together, or we can create a Directed web so that all the categorical variables in those categories are all directed towards one specific variable, which is what we are going to do here. Choose the Directed web.
- Click on the field box
- Add your prediction, which is the $N-Status variable, add all other categorical variables:

- The following screenshot shows all the selected flag fields:
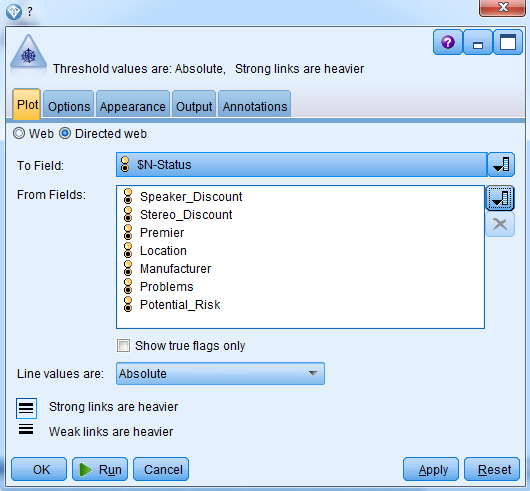
- Add other categorical fields. Select Payment_Method:
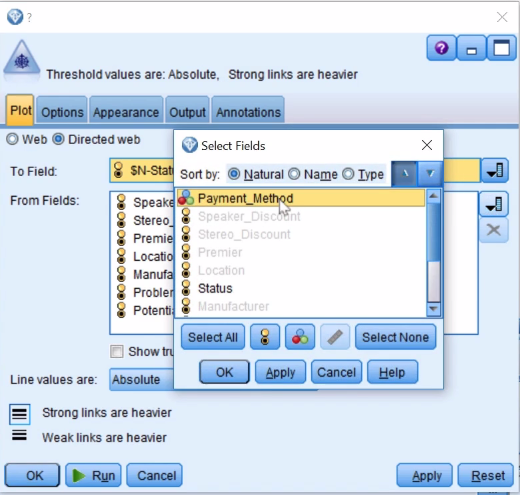
- Hold the Ctrl key and scroll down and select TV_Categories and click on OK:

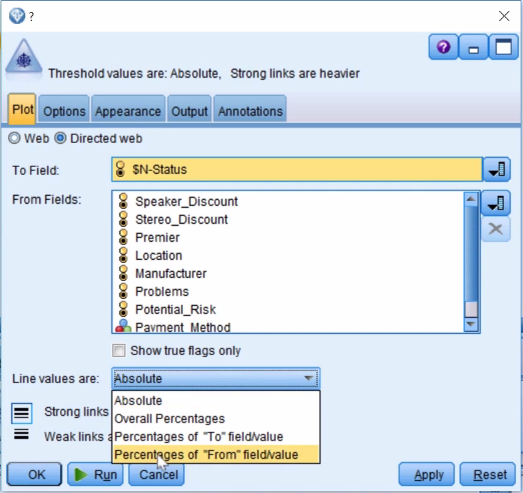
- Set the Line values to Absolute, as shown in the following screenshot:

- Set Line values are to Percentages of "From" the field/value. From these Predictor fields, we will see how these values are related to the Outcome field and click on Run:
Notice that there are two lines that are a little thicker than the others:

You can see that one of the line values says Yes. The other line value says No and they're both related to the field current and churned as we can see in the following output
Let's take a look at the thickest Yes line:
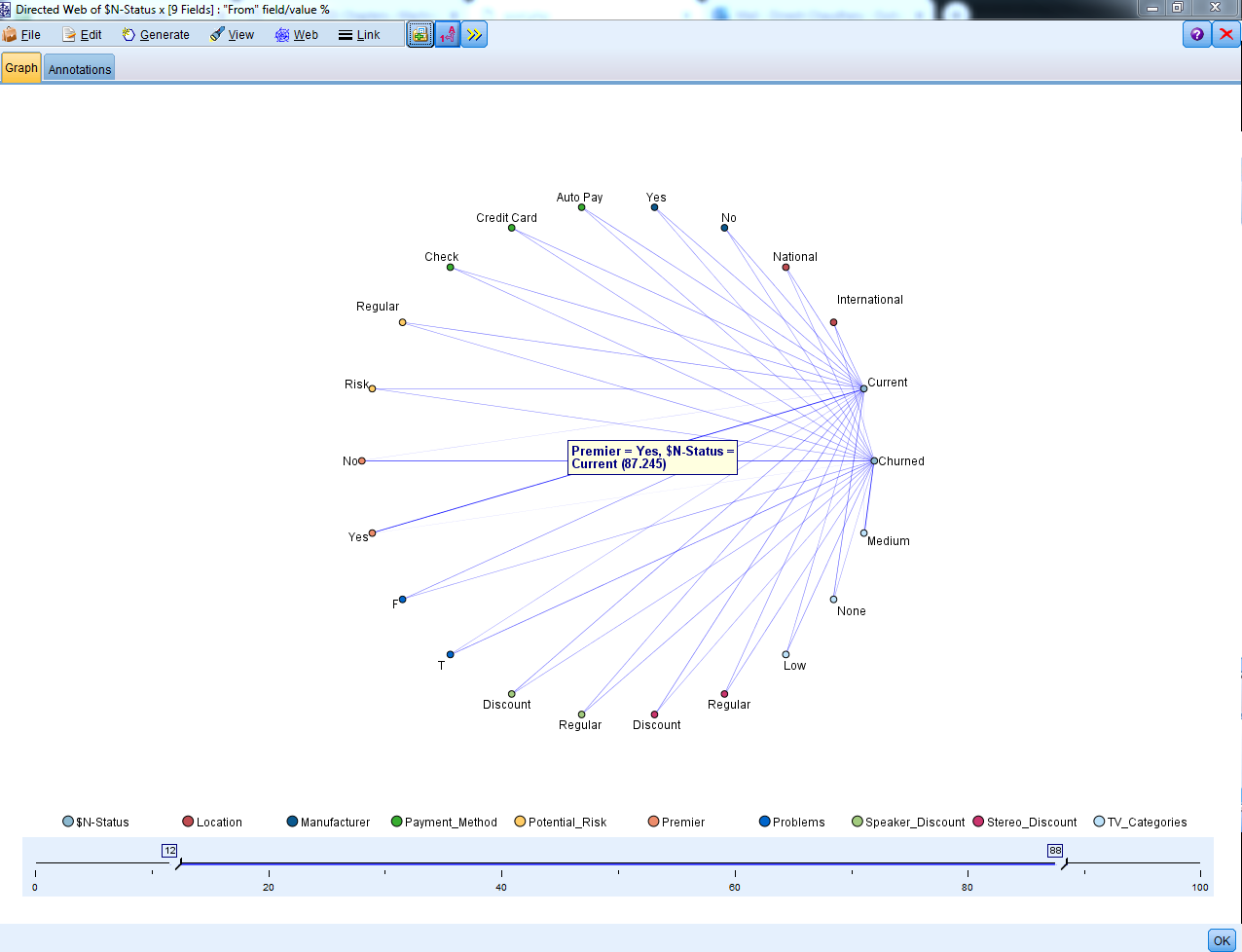
We can see that this line is showing us that these are people that on the Premier variable had a value of Yes and the prediction is associated with being a current customer and then we can see that 87% of the people that are predicted to be current customers they had a value of Yes on the variable Premier.
Similarly, the next thickest line would be the one where we're on the Premier variable. We have a value of no and that's associated with churning and that value ended up being 80%:
- Here is another way we can look at the relationship between a categorical Predictor and a categorical Outcome variable. The strongest relationship is between the Premier variable and the Outcome variable:

- Let's look at the relationship between a continuous Predictor and a categorical Outcome variable. To do that, we are going to go down to the Graphs palette and connect the Select node to a histogram:
- Edit the Histogram, In the field box, select the TVs field . Choose the TVs field because this is one of the most important predictors in the mode:
- In the overlay color box, enter the prediction, which is the variable $N-Status:
- Go to the Options tab and click on Normalize by color to make your comparisons a little easier and click on Run:
- We will see the following results:

We can see that the blue color is associated with those customers that we predicted we were going to lose. The red color is associated with those customers that we predicted we were going to keep. Notice that the people who bought fewer TVs we are predicting about 50%; basically that we're going to end up keeping these customers. As customers are buying more TVs, we're predicting that we're going to lose these customers. So that's how this variable is being used by the model, the model is depicting that if you're not buying many TVs there's about an equal chance that we're going to keep or lose you as a customer, but if you're buying a lot of TVs then we think that we're more likely to lose you as a customer.
In this example, we're going to look at the relationship between two continuous variables:
Let's work with a different dataset. Bring in the Var. File node:
- Edit this node and link it up to a dataset. Navigate to where our dataset, Bank_Data is located Select the file:
- Open the dataset. It's a comma-delimited file, as shown in the following screenshot:
- Go to the Types tab and click on Read Values and then select OK. You will see your variables:
salnow is our dependent variable. Hence make sure that it is a target variable. IF it isn't, then change its role to target. Set the role of id to None. All the other variables are going to be predictors for the current salary variable. Click on OK
- Let's look at the relationship between our outcome variable, which happens to be a continuous variable, and another continuous variable, which is a predictor. Go to the Graphs palette and connect the source node to the Plot node:

The Plot node will allow us create a scatter plot. So, let's edit the Plot node.
- In the X field box, we will input our predictor and here we will add the education level, which is the number of years of education that a person has and in the Y field box, we will add our outcome variable which is salnow, that is, the current salary:

- Click on Run and we get the following graph as the result:
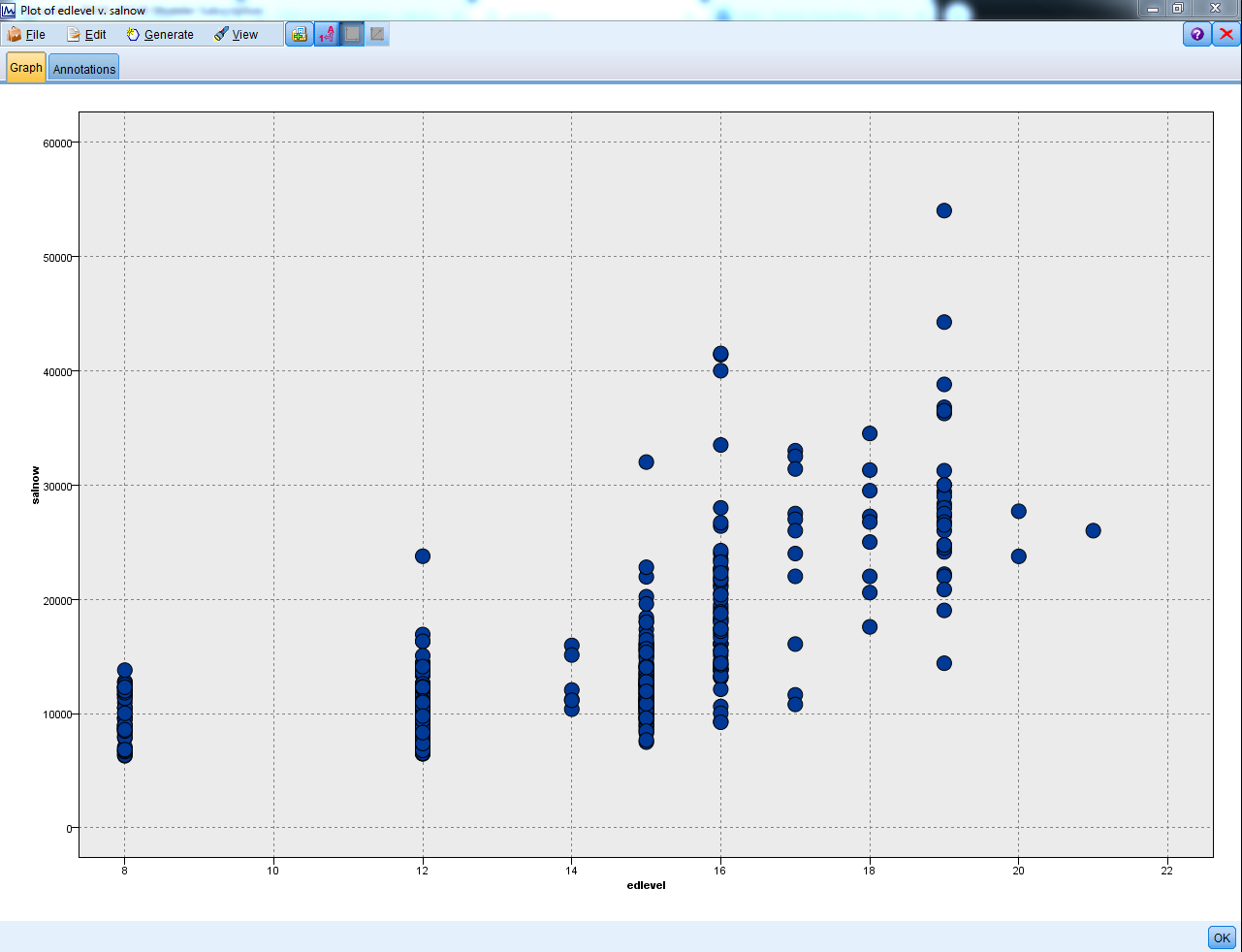
You can see that as the number of years of education increases, the current salary increases too. We have a positive linear relationship, which means that as one variable increases the other variable increases as well, so more education ends up leading to higher current salary, and less education is associated with a lower current salary.
So, this is a way in which we can represent the relationship between two continuous variables. In the next section, we will see how to use statistical tests to interpret the results of a machine learning model.