Versioning
Up to this point, I have largely considered the design of an API as a discrete task that is finished once the API is fully specified and released to users. Of course, in reality, this is simply the beginning of a continuous and complex process. After an API has been released, that’s when the real work begins and when your API development process is put to the test.
Very few, if any, APIs stop development after the 1.0 product is released. There will always be bugs to fix, new features to integrate, workflows to refine, architecture to improve, other platforms to support, and so on.
The primary objective for all releases after the initial release of an API must be to cause zero impact on existing clients, or as close to zero as practically possible. Breaking the interface, or the behavior of the interface, between releases will force your clients to update their code to take advantage of your new API. The more you can minimize the need for this manual intervention on their part, the more likely your users are to upgrade to your new API, or even to keep using your API at all. If your API has a reputation for introducing major incompatible changes with each new release, you are giving your clients incentive to look for an alternative solution. However, an API with a reputation for stability and robustness can be the largest factor in the success of your product.
To this end, this chapter covers the details of API versioning, explaining the different types of backward compatibility and describing how you can actually achieve backward compatibility for your API.
8.1 Version Numbers
Each release of your API should be accompanied with a unique identifier so that the latest incarnation of the API can be differentiated from previous offerings. The standard way to do this is to use a version number.
8.1.1 Version Number Significance
Many different schemes are used to provide versioning information for a software product. Most of these schemes attempt to impart some degree of the scale of change in a release by using a series of numbers, normally separated by a period (.) symbol (Figure 8.1). Most commonly, either two or three separate integers are used, for example, “1.2” or “1.2.3.” The following list explains the significance of each of these integers.
1. Major version. This is the first integer in a version number, for example, 1.0.0. It is normally set to 1 for the initial release and is increased whenever significant changes are made. In terms of API change, a major version change can signal the backward compatible addition of substantial new features or it can signify that backward compatibility has been broken. In general, a bump of the major version of an API should signal to your users to expect significant API changes.
2. Minor version. This is the second integer in a compound version number, for example, 1.0.0. This is normally set to 0 after each major release and increased whenever smaller features or significant bug fixes have been added. Changes in the minor version number should not normally involve any incompatible API changes. Users should expect to be able to upgrade to a new minor release without making any changes to their own software. However, some new features may be added to the API, which, if used, would mean that users could not revert to an earlier minor version without changing their code.
3. Patch version. The (optional) third integer is the patch number, sometimes also called the revision number, for example, 1.0.0. This is normally set to 0 after each minor release and increased whenever important bug or security fixes are released. Changes in patch number should imply no change to the actual API interface, that is, only changes to the behavior of the API. In other words, patch version changes should be backward and forward compatible. That is, users should be able to revert to an earlier patch version and then switch back to a more recent patch version without changing their code (Rooney, 2005).
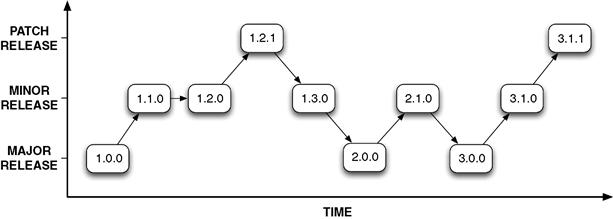
Figure 8.1 Illustrating the progression of version numbers using a standard MAJOR.MINOR.PATCH numbering scheme.
Some software products employ additional numbers or symbols to further describe a release. For example, an automated build number might be used so that every single build of the software can be differentiated from previous builds. This build number could be derived from the revision number of the last change checked into the revision control system or may be derived from the current date.
Software is often provided to users before the final release in order to get feedback and valuable field testing. In these cases, it is common to add a symbol to the version string to indicate the phase of the development process that the software relates to. For example, “1.0.0a” might refer to an alpha release, “1.0.0b” might refer to a beta release, and “1.0.0rc” might refer to a release candidate. However, you should note that once you start deviating from a purely numeric identification system, doing comparisons of version numbers starts to become more complicated (see Python PEP 0386 at http://www.python.org/dev/peps/pep-0386/ for an example of this complexity).
8.1.2 Esoteric Numbering Schemes
I’ve also decided to list some non-standard or imaginative versioning schemes that have been used by software projects in the past. This section is more for fun than actual practical advice, although each scheme obviously offers advantages for certain situations. For API development, though, I recommend sticking with the widely understood major, minor, patch scheme.
The TeX document processing system, originally designed by Donald Knuth, produces new version numbers by adding additional digits of precision from the value pi, π. The first TeX version number was 3, then came 3.1, then 3.14, and so on. The current version as of 2010 was 3.1415926. Similarly, the version numbers for Knuth’s related METAFONT program asymptotically approach the value e, 2.718281.
While this may seem at first to be simply the wry sense of humor of a mathematician, this numbering scheme does actually convey an important quality about the software. Even though Knuth himself recognizes that some areas of TeX could be improved, he has stated that no new fundamental changes should be made to the system and any new versions should only contain bug fixes. As such, use of a versioning scheme that introduces increasingly smaller floating-point digits is actually quite insightful. In fact, Knuth’s recognition of the importance of feature stability and backward compatibility, to the extent that he encoded this importance in the versioning scheme for his software, is food for thought for any API designer.
Another interesting versioning scheme is the use of dates as version numbers. This is obviously done explicitly for large end-user software releases such as Microsoft’s Visual Studio 2010 and games such as EA’s FIFA 10. However, a more subtle system is used by the Ubuntu flavor of the Linux operating system. This uses the year and month of a release as the major and minor version number, respectively. The first Ubuntu release, 4.10, appeared in October 2004 while 9.04 was released during April 2009. Ubuntu releases are also assigned a code name, consisting of an adjective and an animal name with the first same letter, for example, “Breezy Badger” and “Lucid Lynx.” With the exception of the first two releases, the first letter of these code names increases alphabetically for each release. These schemes have the benefit of imparting how recent an Ubuntu release is, but they do not convey any notion of the degree of change in a release. This may be fine for a continually evolving operating system, although you should prefer a more traditional number scheme for your API to give your users an indication of the degree of API change to expect in a release.
The Linux kernel currently uses an even/odd numbering scheme to differentiate between stable releases (even) and development releases (odd). For example, Linux 2.4 and 2.6 are stable releases, whereas 2.3 and 2.5 are development releases. This numbering scheme is also used by the Second Life Server releases.
8.1.3 Creating a Version API
Version information for your API should be accessible from code to allow your clients to write programs that are conditional on your API’s version number, for example, to call a new method that only exists in recent versions of your API or to work around a bug in the implementation of a known release of your API.
To offer maximum flexibility, users should be able to query your API’s version at compile time as well as run time. The compile-time requirement is necessary so that the user can use #if preprocessor directives to conditionally compile against newer classes and methods that would cause undefined reference errors if linking against older versions of your API. The run-time requirement allows clients to choose between different API calls dynamically or to provide logistical logging with your API version number included. These requirements suggest the creation of a version API. I present a simple generic API for this purpose here.
static std::string GetVersion();
static bool IsAtLeast(int major, int minor, int patch);
There are a few features of note in this Version class. First, I provide accessors to return the individual major, minor, and patch numbers that comprise the current version. These simply return the values of the respective #define statements, API_MAJOR, API_MINOR, and API_PATCH. While I stated in the C++ usage chapter that you should avoid #define for constants, this is an exception to that rule because you need your users to be able to access this information from the preprocessor.
The GetVersion() method returns the version information as a user-friendly string, such as “1.2.0.” This is useful for the client to display in an About dialog or to write to a debug log in their end-user application.
Next I provide a method to let users perform version comparisons. This lets them do checks in their code, such as checking that they are compiling against an API that is greater than or equal to the specified (major, minor, patch) triple. Obviously you could add other version math routines here, but IsAtLeast() provides the most common use case.
Finally, I provide a HasFeature() method. Normally when a user wants to compare version numbers, they don’t really care about the version number itself but instead are using this designator as a way to determine whether a feature they want to use is present in the API. Instead of making your users aware of which features were introduced in which versions of your API, the HasFeature() method lets them test for the availability of the feature directly. For example, in version 2.0.0 of your API, perhaps you made the API thread safe. You could therefore add a feature tag called “THREADSAFE” so that users could do a check such as
While you probably don’t need to define any feature tags for your 1.0 release, you should definitely include this method in your Version API so that it is possible for a client to call it in any release of your API. The method can simply return false for 1.0, but for future releases, you can add tags for new features or major bug fixes. These strings can be stored in a std::set lazily (initialized on the first call) so that it’s efficient to determine whether a feature tag is defined. The source code that accompanies this book provides an implementation of this concept.
The use of feature tags is particularly useful if you have an open source project where clients may fork your source code or an open specification project where vendors can produce different implementations of your specification. In these cases, there could be multiple versions of your API that offer different feature sets in releases with the same version number. This concept is employed by the OpenGL API, where the same version of the OpenGL API may be implemented by different vendors but with different extensions available. For example, the OpenGL API provides the glGetStringi(GL_EXTENSION, n) call to return the name of the nth extension.
8.2 Software Branching Strategies
Before I talk in more depth about API versioning, let’s cover some basics about the related topic of software branching strategies. While small projects with one or two engineers can normally get by with a single code line, larger software projects normally involve some form of branching strategy to enable simultaneous development, stabilization, and maintenance of different releases of the software. The next couple of sections cover some things to consider when choosing a branching strategy and policy for your project.
8.2.1 Branching Strategies
Every software project needs a “trunk” code line, which is the enduring repository of the project’s source code. Branches are made from this trunk code line for individual releases or for development work that must be isolated from the next release. This model supports parallel development where new features can be added to the project while imminent releases can lock down changes and stabilize the existing feature set.
Many different branching schemes can be devised. Each engineering team will normally adapt a strategy to its own individual needs, process, and workflow. However, Figure 8.2 provides one example branching strategy that is frequently seen. In this case, major releases are branched off of trunk, and minor releases occur along those branch lines. If an emergency patch is required while work is happening for the next minor release, then a new branch may be created for that specific “hotfix.” Longer-term development work that needs to skip the next release because it won’t be ready in time is often done in its own branch and then landed at the appropriate time. Note the resemblance between Figures 8.1 and 8.2. This similarity is of course not accidental.
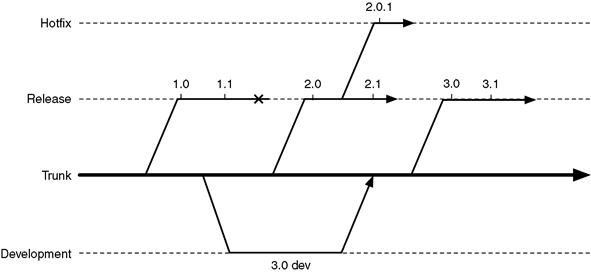
Figure 8.2 An example branching diagram for multiple releases of a software product.
8.2.2 Branching Policies
This basic structure is used by many projects to support parallel development and release management. However, many policy decisions can be used to customize the actual workflow, for example, which branches developers work in, how many development branches are in flight at once, at what point in the process are release branches created, how often changes are merged between branches, whether automatic merges between branches are attempted, and so on.
While different branching policies make sense for different situations, I will comment that in my experience, ongoing development work should happen in the trunk code line, with development branches used where necessary for longer-term work. While QA will necessarily focus on a specific release branch in the run up to a particular release, they should always be focused on trunk, particularly so during periods of development between releases. The trunk is where your project’s crown jewels live: this is the code that will live on past individual releases. If no developers or QA engineers are actually working in trunk, and merges are allowed to take place into trunk unattended, the trunk will soon become unstable and buggy.
Your choice of revision control system also has an impact on your branching policy, as different source control management (SCM) products make certain branching strategies easier than others. For example, supporting and merging between branches in Subversion can be a painful endeavor, whereas in distributed SCM systems such as Mercurial or git, branching is designed into the core of the system. For example, using an SCM such as Mercurial, it’s possible to consider merging between branches on a daily basis as this is an easy and low-impact operation. The more often you merge between branches, the less code divergence occurs and the easier it will be to eventually land the branch into trunk, if that is the end goal. Release branches will normally just be “end of lifed” when the release is done, as represented by the X symbol after the 1.1 release in Figure 8.2. Another decision factor that relates to your SCM system is whether all your engineers are on-site, in which case a server-based solution such as Perforce is acceptable, or whether you have open source engineers working out of their homes, in which case a distributed solution such as git or Mercurial will be more appropriate.
8.2.3 APIs and Parallel Branches
Once an API has been released, changes to that API should appear (at least externally) to follow a serialized process. That is, you do not release incompatible non-linear versions of your API: the functionality in version N should be a strict superset of the functionality in version N-1. While this may seem obvious, large software projects tend to involve developers working in several parallel branches of the code, and there can be several concurrently supported releases of an API. It is therefore important that teams working in different parallel branches do not introduce incompatible features. There are several policy approaches to deal with this potential problem.
• Target development branches. Your project will generally have development branches and release branches. By enforcing that no API changes occur directly in release branches, you minimize the chance that an API change is made in one release but is “lost” in the next release because it was never merged down to trunk. If an API change is needed in a release branch, it should be committed to trunk and then merged up from there. This is generally true of any change in a release branch, but interface changes have a higher cost if they are lost between releases.
• Merge to trunk often. Any changes to a public API should either be developed in the common trunk code line or be merged into trunk as early as possible. This also assumes that teams are regularly syncing their development branches to the trunk code, which is good practice anyway. This avoids surprises further down the line when two teams try to merge development branches with conflicting APIs.
• Review process. A single API review committee should oversee and vet all changes to public APIs before they are released. It is the job of this committee to ensure that no conflicting or non-backward-compatible changes have been made to APIs. They are the gatekeepers and the last line of defense. This group should be sufficiently empowered to slip release deadlines if necessary to address API problems. I will discuss how to run an API review process later in this chapter.
These solutions attempt to keep one true definition of the API in the trunk code line rather than fracture changes across multiple branches. This may not always be possible, but if you strive for this goal you will make your life easier later.
The problems become more difficult if you have an open source product where users may create forks of your source code and make changes to your APIs that are beyond your control. You obviously cannot do too much about this situation. However, if these changes are to be merged back into your source repository, then you can, and should, apply the same thoughtful review process to community patches as you would to internally developed changes. It can be difficult or awkward to deny changes from open source developers, but you can minimize any hurt feelings by clearly documenting the review process and expectations, offer advice on technical direction early on, and provide constructive feedback on how a patch can be changed to make it more acceptable.
8.2.4 File Formats and Parallel Products
A colleague once described a project that he worked on to me where a decision was made to support two different variants of their product: a Basic version and an Advanced version. Up until that point, there was a single variant of the product and a single file format. The team had a policy of increasing the file format major version number when an incompatible change was introduced into the format, with the last single-variant version being 3.0. The file format was XML based and included a version tag, so it was known which version of the product generated the file. The file format reader would ignore tags that it didn’t understand in versions that only differed by minor version number so that it could still read files that were generated from newer but compatible versions of the product. Both the Basic and the Advanced variants could read all files from 3.0 and earlier.
This all seems reasonable so far.
It wasn’t long before the Advanced variant introduced new features that required non-backward-compatible additions to the file format so the team decided to increment the major version number to 4.x. However, then there was a need to evolve the entire file format in an incompatible way, that is, to require a major version bump for Basic and Advanced files. To deal with this, the Basic variant format was updated to 5.x and the Advanced variant was bumped to 6.x. The meant that
- 3.x builds couldn’t read any of 4.x through 6.x formats, which is fine.
- 4.x builds (old Advanced) couldn’t read 5.x files (new Basic) or 6.x files (new Advanced).
- 5.x builds (new Basic) couldn’t read 4.x files (old Advanced).
- 6.x builds (new Advanced) could read any existing format, which is also fine.
Then, of course, eventually another major version bump was required, introducing a 7.x (newer Basic) and 8.x (newer Advanced). Things started to get really messy.
With the benefit of hindsight, we talked about how this situation could’ve been avoided. The key observation is that in this case, the information about which variant had created the file was being conflated with the file format version. One solution would have been to tease apart those two concepts and to write both into the file, that is, a version number, such as “3.2,” and a variant name such as “Basic.” In this way, the Basic variant could easily know whether it could read a format: it could read any file with an empty or “Basic” variant name. This essentially creates two version number spaces, where the version numbers for the two variants can advance independently of each other. A product first checks the variant name for compatibility and then version number compatibility works in the usual linear fashion.
Learning from this experience, I proffer this advice: when supporting different variants of a product, store the variant’s name in any files that should be shared between the variants in addition to the version number of the variant that wrote the file.
8.3 Life Cycle of an API
This section examines the life of an API and the various phases that it goes through from conception to end of life.
Maintaining an API is not necessarily the same as maintaining a normal software product. This is because of the extra constraints that are placed on API development to not break existing clients. In a normal end-user software product, if you change the name of a method or class in your code, this doesn’t affect the user-visible features of the application. However, if you change the name of a class or method in an API, you may break the code of all your existing clients. An API is a contract, and you must make sure that you uphold your end of the contract.
Figure 8.3 provides an overview of the life span of a typical API. The most important event in this life span is the initial release, marked by the thick vertical bar in Figure 8.3. Before this pivotal point, it’s fine to make major changes to the design and interface. However, after the initial release, once your users are able to write code using your API, you have committed to providing backward compatibility and the extent of the changes you can make is greatly limited. Looking at the life span as a whole, there are four general stages of API development (Tulach, 2008).
1. Prerelease: Before the initial release, an API can progress through a standard software cycle, including requirements gathering, planning, design, implementation, and testing. Most notably, as already stated, the interface can go through major changes and redesigns during this period. You may actually release these early versions of your API to your users to get their feedback and suggestions. You should use a version number of 0.x for these prerelease versions to make it clear to those users that the API is still under active development and may change radically before 1.0 is delivered.
2. Maintenance: An API can still be modified after it has been released, but in order to maintain backward compatibility, any changes must be restricted to adding new methods and classes, as well as fixing bugs in the implementation of existing methods. In other words, during the maintenance phase you should seek to evolve an API, not change it incompatibly. To ensure that changes do not break backward compatibility, it is good practice to conduct regression testing and API reviews before a new version is released.
3. Completion: At some point, the project leads will decide that the API has reached maturity and that no further changes should be made to the interface. This may be because the API solves the problems it was designed to solve or may be because team members have moved on to other projects and can no longer support the API. Stability is the most important quality at this point in the life span. As such, only bug fixes will generally be considered. API reviews could still be run at this stage, but if changes are indeed restricted to implementation code and not public headers, then they may not be necessary. Ultimately, the API will reach the point where it is considered to be complete and no further changes will be made.
4. Deprecation: Some APIs eventually reach an end-of-life state where they are deprecated and then removed from circulation. Deprecation means that an API should not be used for any new development and that existing clients should migrate away from the API. This can happen if the API no longer serves a useful purpose or if a newer, incompatible API has been developed to take its place.
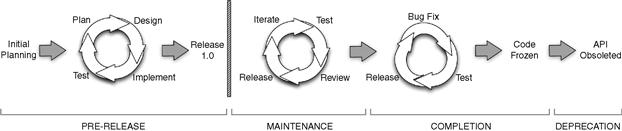
Figure 8.3 The life cycle of an API. Before the initial release, extensive redesign of the API can be performed. After the initial release, only incremental changes can be tolerated.
8.4 Levels of Compatibility
Up to this point I’ve talked only vaguely about what backward compatibility means. It’s now time to get concrete and define our terms more precisely. Accordingly, the next few sections detail what is meant by the specific terms backward compatibility, forward compatibility, functional compatibility, source (or API) compatibility, and binary (or ABI) compatibility.
Often you will provide different levels of compatibility promises for major, minor, and patch releases of your API. For example, you may promise that patch releases will be both backward and forward compatible (Subversion promises this) or you may promise to only break binary compatibility for major releases (KDE promises this for core libraries).
8.4.1 Backward Compatibility
Backward compatibility can be defined simply as an API that provides the same functionality as a previous version of the API. In other words, an API is backward compatible if it can fully take the place of a previous version of the API without requiring the user to make any changes.
This implies that the newer API is a superset of the older API. It can add new functionality, but it cannot incompatibly change functionality that is already defined by the older API. The cardinal rule of API maintenance is to never remove anything from your interface.
There are different types of API backward compatibility, including:
I will define each of these in more detail in the following sections.
In addition, there are also data-oriented, backward-compatibility issues, such as
For example, if your API involves communication over a network, then you also need to consider the compatibility of the client/server protocol that you use. This means that a client using an older release of the API will still be able to communicate with a newer version of the server. Also, a client using a newer release of the API will still be able to communicate with an older version of the server (Rooney, 2005).
Additionally, if your API stores data in a file or database, then you will need to consider the compatibility of that file format or database schema. For example, more recent versions of the API need to be able to read files generated by older versions of the API.
8.4.2 Functional Compatibility
Functional compatibility is concerned with the run-time behavior of an implementation. An API is functionally compatible if it behaves exactly the same as a previous version of the API. However, as Jaroslav Tulach notes, an API will hardly ever be 100% backward compatible in this respect. Even a release that only fixes bugs in implementation code will have changed the behavior of the API, behavior that some clients may actually be depending on.
For example, if your API provides the following function:
this function may have a bug in version 1.0 of your API, causing it to crash if you pass it a NULL pointer. In version 1.1, you fix this bug so that your code no longer crashes in this case. This has changed the behavior of the API, so it’s not strictly functionally compatible. However, it has changed the behavior in a good way: it’s fixed a crashing bug. So, while this metric is useful as a basic measure of change in the run-time behavior of an API, that functional change may not necessarily be a bad thing. Most API updates will intentionally break functional compatibility.
As an example of a case where functional compatibility is useful, consider a new version of an API that focused solely on performance. In this case, the behavior of the API is not changed at all. However, the algorithms behind the interface are improved to deliver exactly the same results in less time. In this respect, the new API could be considered 100% functionally compatible.
8.4.3 Source Compatibility
Source compatibility is a looser definition of backward compatibility. It basically states that users can recompile their programs using a newer version of the API without making any change to their code. This says nothing about the behavior of the resulting program, only that it can be successfully compiled and linked. Source compatibility is also sometimes referred to as API compatibility.
For example, the following two functions are source compatible, even though their function signatures are different:
This is because any user code that was written to call the 1.0 version of the function will also compile against version 1.1 (the new argument is optional). In contrast, the following two functions are not source compatible because users will be forced to go through their code to find all instances of the SetImage() method and add the required second parameter.
Any changes that are completely restricted to implementation code, and therefore do not involve changes to public headers, will obviously be 100% source compatible because the interfaces are exactly the same in both cases.
8.4.4 Binary Compatibility
Binary compatibility implies that clients only need to relink their programs with a newer version of a static library or simply drop a new shared library into the install directory of their end-user application. This is in contrast to source compatibility where users must recompile their programs whenever any new version of your API is released.
This implies that any changes to the API must not impact the representation of any classes, methods, or functions in the library file. The binary representation of all API elements must remain the same, including the type, size, and alignment of structures and the signatures of all functions. This is also often called Application Binary Interface (ABI) compatibility.
Binary compatibility can be very difficult to attain using C++. Most changes made to an interface in C++ will cause changes to its binary representation. For example, here are the mangled names of two different functions (i.e., the symbol names that are used to identify a function in an object or library file):
These two methods are source compatible, but they are not binary compatible, as evidenced by the different mangled names that each produces. This means that code compiled against version 1.0 cannot simply use version 1.1 libraries because the _Z8SetImageP5Image symbol is no longer defined.
The binary representation of an API can also change if you use different compile flags. It tends to be compiler specific, too. One reason for this is because the C++ standards committee decided not to dictate the specifics of name mangling. As a result, the mangling scheme used by one compiler may differ from another compiler, even on the same platform. (The mangled names presented earlier were produced by GNU C++ 4.3.)
Two lists of specific API changes follow, detailing those that will require users to recompile their code and those that should be safe to perform without breaking binary compatibility.
Binary-Incompatible API Changes:
• Removing a class, method, or function.
• Adding, removing, or reordering member variables for a class.
• Adding or removing base classes from a class.
• Changing the type of any member variable.
• Changing the signature of an existing method in any way.
• Adding, removing, or reordering template arguments.
• Changing a non-inlined method to be inlined.
• Changing a non-virtual method to be virtual, and vice versa.
• Changing the order of virtual methods.
• Adding a virtual method to a class with no existing virtual methods.
• Adding new virtual methods (some compilers may preserve binary compatibility if you only add new virtual methods after existing ones).
• Overriding an existing virtual method (this may be possible in some cases, but is best avoided).
Binary-Compatible API Changes:
• Adding new classes, non-virtual methods, or free functions.
• Adding new static variables to a class.
• Removing private static variables (if they are never referenced from an inline method).
• Removing non-virtual private methods (if they are never called from an inline method).
• Changing the implementation of an inline method (however, this requires recompilation to pick up the new implementation).
• Changing an inline method to be non-inline (however, this requires recompilation if the implementation is also changed).
• Changing the default arguments of a method (however, this requires recompilation to actually use the new default argument).
• Adding or removing friend declarations from a class.
• Adding a new enum to a class.
Restricting any API changes to only those listed in this second list should allow you to maintain binary compatibility between your API releases. Some further tips to help you achieve binary compatibility include the following.
• Instead of adding parameters to an existing method, you can define a new overloaded version of the method. This ensures that the original symbol continues to exist, but provides the newer calling convention, too. Inside of your .cpp file, the older method may be implemented by simply calling the new overloaded method.
void SetImage(Image *img, bool keep_aspect)
(Note that this technique may impact source compatibility if the method is not already overloaded because client code can no longer reference the function pointer &SetImage without an explicit cast.)
• The pimpl idom can be used to help preserve binary compatibility of your interfaces because it moves all of the implementation details—those elements that are most likely to change in the future—into the .cpp file where they do not affect the public .h files.
• Adopting a flat C style API can make it much easier to attain binary compatibility simply because C does not offer you features such as inheritance, optional parameters, overloading, exceptions, and templates. For example, the use of std::string may not be binary compatible between different compilers. To get the best of both worlds, you may decide to develop your API using an object-oriented C++ style and then provide a flat C style wrapping of the C++ API.
• If you do need to make a binary-incompatible change, then you might consider naming the new library differently so that you don’t break existing applications. This approach was taken by the libz library. Builds before version 1.1.4 were called ZLIB.DLL on Windows. However, a binary-incompatible compiler setting was used to build later versions of the library, and so the library was renamed to ZLIB1.DLL, where the “1” indicates the API major version number.
8.4.5 Forward Compatibility
An API is forward compatible if client code written using a future version of the API can be compiled without modification using an older version of the API. Forward compatibility therefore means that a user can downgrade to a previous release and still have their code work without modification.
Adding new functionality to an API breaks forward compatibility because client code written to take advantage of these new features will not compile against the older release where those changes are not present.
For example, the following two versions of a function are forward compatible:
because code written using the 1.1 version of the function, where the second argument is required, can compile successfully in the 1.0 version, where the second argument is optional. However, the following two versions are not forward compatible:
This is because code written using the 1.1 version can provide an optional second argument, which, if specified, will not compile against the 1.0 version of the function.
Forward compatibility is obviously a very difficult quality to provide any guarantees about because you can’t predict what will happen to the API in the future. You can, however, give this your best effort consideration before the 1.0 version of your API is released. In fact, this is an excellent activity to engage in before your first public release to try to make your API as future proof as possible.
This means that you must give thought to the question of how the API could evolve in the future. What new functionality might your users request? How would performance optimizations affect the API? How might the API be misused? Is there a more general concept that you may want to expose in the future? Are you already aware of functionality that you plan to implement in the future that will impact the API?
Here are some ways that you can make an API forward compatible.
• If you know that you will need to add a parameter to a method in the future, then you can use the technique shown in the first example given earlier, that is, you can add the parameter even before the functionality is implemented and simply document (and name) this parameter as unused.
• You can use an opaque pointer or typedef instead of using a built-in type directly if you anticipate switching to a different built-in type in the future. For example, create a typedef for the float type called Real so that you can change the typedef to double in a future version of the API without causing the API to change.
• The data-driven style of API design, described in the styles chapter, is inherently forward compatible. A method that simply accepts an ArgList variant container essentially allows any collection of arguments to be passed to it at run time. The implementation can therefore add support for new named arguments without requiring changes to the function signature.
8.5 How to Maintain Backward Compatibility
Now that I have defined the various types of compatibilities, I’ll describe some strategies for actually maintaining backward compatibility when releasing newer versions of your APIs.
8.5.1 Adding Functionality
In terms of source compatibility, adding new functionality to an API is generally a safe thing to do. Adding new classes, new methods, or new free functions does not change the interface for preexisting API elements and so will not break existing code.
As an exception to this rule of thumb, adding new pure virtual member functions to an abstract base class is not backward compatible, that is,
This is because all existing clients must now define an implementation for this new method, as otherwise their derived classes will not be concrete and their code will not compile. The workaround for this is simply to provide a default implementation for any new methods that you add to an abstract base class, that is, to make them virtual but not pure virtual. For example,
In terms of binary (ABI) compatibility, the set of elements that you can add to the API without breaking compatibility is more restricted. For example, adding the first virtual method to a class will cause the size of the class to increase, normally by the size of one pointer, in order to include a pointer to the vtable for that class. Similarly, adding new base classes, adding template parameters, or adding new member variables will break binary compatibility. Some compilers will let you add virtual methods to a class that already has virtual methods without breaking binary compatibility as long as you add the new virtual method after all other virtual methods in the class.
Refer to the list in the Binary Compatibility section for a more detailed breakdown of API changes that will break binary compatibility.
8.5.2 Changing Functionality
Changing functionality without breaking existing clients is a trickier proposition. If you only care about source compatibility, then it’s possible to add new parameters to a method as long as you position them after all previous parameters and declare them as optional. This means that users are not forced to update all existing calls to add the extra parameter. I gave an example of this earlier, which I will replicate here for convenience.
Also, changing the return type of an existing method, where the method previously had a void return type, is a source compatible change because no existing code should be checking that return value.
If you wish to add a parameter that does not appear after all of the existing parameters or if you are writing a flat C API where optional parameters are not available, then you can introduce a differently named function and perhaps refactor the implementation of the old method to call the new method. As an example, the Win32 API uses this technique extensively by creating functions that have an “Ex” suffix to represent extended functionality. For example,

The Win32 API also provides examples of deprecating older functions and introducing an alternative name for newer functions instead of simply appending “Ex” to the end of the name. For example, the OpenFile() method is deprecated and instead the CreateFile() function should be used for all modern applications.
In terms of template usage, adding new explicit template instantiations to your API can potentially break backward compatibility because your clients may have already added an explicit instantiation for that type. If this is the case, those clients will receive a duplicate explicit instantiation error when trying to compile their code.
In terms of maintaining binary compatibility, any changes you make to an existing function signature will break binary compatibility, such as changing the order, type, number, or constness of parameters, or changing the return type. If you need to change the signature of an existing method and maintain binary compatibility, then you must resort to creating a new method for that purpose, potentially overloading the name of the existing function. This technique was shown earlier in this chapter:
Finally, it will be common to change the behavior of an API without changing the signature of any of its methods. This could be done to fix a bug in the implementation or to change the valid values or error conditions that a method supports. These kinds of changes will be source and binary compatible, but they will break functional compatibility for your API. Often, these will be desired changes that all of your affected clients will find agreeable. However, in cases where the change in behavior may not be desirable to all clients, you can make the new behavior opt-in. For example, if you have added multithreaded locking to your API, you could allow clients to opt-in to this new behavior by calling a SetLocking() method to turn on this functionality (Tulach, 2008). Alternatively, you could integrate the ability to turn on/off features with the HasFeature() method introduced earlier for the Version class. For example,
static bool HasFeature(const std::string &name);
static void EnableFeature(const std::string &name, bool);
With this capability, your clients could explicitly enable new functionality while the original behavior is maintained for existing clients, thus preserving functional compatibility. For example,
8.5.3 Deprecating Functionality
A deprecated feature is one that clients are actively discouraged from using, normally because it has been superseded by newer, preferred functionality. Because a deprecated feature still exists in the API, users can still call it, although doing so may generate some kind of warning. The expectation is that deprecated functionality may be completely removed from a future version of the API.
Deprecation is a way to start the process of removing a feature while giving your clients time to update their code to use the new approved syntax.
There are various reasons to deprecate functionality, including addressing security flaws, introducing a more powerful feature, simplifying the API, or supporting a refactoring of the API’s functionality. For example, the standard C function tmpnam() has been deprecated in preference to more secure implementations such as tmpnam_s() or mkstemp().
When you deprecate an existing method, you should mark this fact in the documentation for the method, along with a note on any newer functionality that should be used instead. In addition to this documentation task, there are ways to produce warning messages if the function is ever used. Most compilers provide a way to decorate a class, method, or variable as being deprecated and will output a compile-time warning if a program tries to access a symbol decorated in this fashion. In Visual Studio C++, you prefix a method declaration with __declspec(deprecated), whereas in the GNU C++ compiler you use __attribute__ ((deprecated)). The following code defines a DEPRECATED macro that will work for either compiler.
#define DEPRECATED __attribute__ ((deprecated))
#define DEPRECATED __declspec(deprecated)
#pragma message("DEPRECATED is not defined for this compiler")
Using this definition, you can mark certain methods as being deprecated in the following way:
If a user tries to call the GetName() method, their compiler will output a warning message indicating that the method is deprecated. For example, the following warning is emitted by the GNU C++ 4.3 compiler:
As an alternative to providing a compile-time warning, you could write code to issue a deprecation warning at run time. One reason to do this is so that you can provide more information in the warning message, such as an indication of an alternative method to use. For example, you could declare a function that you call as the first statement of each function you wish to deprecate, such as
void Deprecated(const std::string oldfunc, const std::string newfunc="");
std::string MyClass::GetName()
The implementation of Deprecated() could maintain an std::set with the name of each function for which a warning has already been emitted. This would allow you to output a warning only on the first invocation of the deprecated method to avoid spewage to the terminal if the method gets called a lot. Noel Llopis describes a similar technique in his Game Gem, except that his solution also keeps track of the number of unique call sites and batches up the warnings to output a single report at the end of the program’s execution (DeLoura, 2001).
8.5.4 Removing Functionality
Some functionality may eventually be removed from an API, after it has gone through at least one release of being deprecated. Removing a feature will break all existing clients that depend on that feature, which is why it’s important to give users a warning of your intention to remove the functionality by marking it as deprecated first.
Removing functionality from an API is a drastic step, but it is sometimes warranted when the methods should never be called any more for security reasons, if that functionality is simply not supported any more, or if it is restricting the ability of the API to evolve.
One way to remove functionality and yet still allow legacy users to access the old functionality is to bump the major version number and declare that the new version is not backward compatible. Then you can completely remove the functionality from the latest version of the API, but still provide old versions of the API for download, with the understanding that they are deprecated and unsupported and should only be used by legacy applications. You may even consider storing the API headers in a different directory and renaming the libraries so that the two APIs do not conflict with each other. This is a big deal, so don’t do it often. Once in the lifetime of the API is best. Never is even better.
This technique was used by Nokia’s Qt library when it transitioned from version 3.x to 4.x. Qt 4 introduced a number of new features at the cost of source and binary compatibility with Qt 3. Many functions and enums were renamed to be more consistent, some functionality was simply removed from the API, while other features were isolated into a new Qt3Support library. A thorough porting guide was also provided to help clients transition to the new release. This allowed Qt to make a radical step forward and improve the consistency of the API while still providing support for certain Qt 3 features to legacy applications.
8.6 API Reviews
Backward compatibility doesn’t just happen. It requires dedicated and diligent effort to ensure that no new changes to an API have silently broken existing code. This is best achieved by adding API reviews to your development process. This section presents the argument for performing API reviews, discusses how to implement these successfully, and describes a number of tools that can be used to make the job of reviewing API changes more manageable.
There are two different models for performing API reviews. One is to hold a single prerelease meeting to review all changes since the previous release. The other model is to enforce a precommit change request process where changes to the API must be requested and approved before being checked in. You can of course do both.
8.6.1 The Purpose of API Reviews
You wouldn’t release source code to your users without at least compiling it. In the same way, you shouldn’t release API changes to your clients without checking that it doesn’t break their applications. API reviews are a critical and essential step for anyone who is serious about their API development. In case you need further encouragement, here are a few reasons to enforce explicit checks of your API before you release it to clients.
• Maintain backward compatibility. The primary reason to review your API before it is released is to ensure that you have not unknowingly changed the API in a way that breaks backward compatibility. As mentioned earlier, if you have many engineers working on fixing bugs and adding new features, it’s quite possible that some will not understand the vital importance of preserving the public interface.
• Maintain design consistency. It’s crucial that the architecture and design plans that you obsessed about for the version 1.0 release are maintained throughout subsequent releases. There are two issues here. The first is that changes that do not fit into the API design should be caught and recast, as otherwise the original design will become diluted and deformed until you eventually end up with a system that has no cohesion or consistency. The second issue is that change is inevitable; if the structure of the API must change, then this requires revisiting the architecture to update it for new functional requirements and use cases. As a caution, John Lakos points out that if you implement 1 new feature for 10 clients, then every client gets 9 features they didn’t ask for and you must implement, test, and support 10 features that you did not originally design for (Lakos, 1996).
• Change control. Sometimes a change may simply be too risky. For example, an engineer may try to add a major new feature for a release that is focused on bug fixing and stability. Changes may also be too extensive, poorly tested, appear too late in the release process, violate API principles such as exposing implementation details, or not conform to the coding standards for the API. The maintainers of an API should be able to reject changes that they feel are inappropriate for the current API release.
• Allow future evolution. A single change to the source code can often be implemented in several different ways. Some of those ways may be better than others in that they consider future evolution and put in place a more general mechanism that will allow future improvements to be added without breaking the API. The API maintainers should be able to demand that a change be reimplemented in more future-proof fashion. Tulach calls this being “evolution ready” (Tulach, 2008).
• Revisit solutions. Once your API has been used in real situations and you’ve received feedback from your clients on its usability, you may come up with better solutions. API reviews can also be a place where you revisit previous decisions to see if they are still valid and appropriate.
If your API is so successful that it becomes a standard, then other vendors may write alternative implementations. This makes the need for API change control even more critical. For example, the creators of OpenGL recognized this need and so they formed the OpenGL Architecture Review Board (ARB) to govern the standard. The ARB was responsible for changes to the OpenGL API, advancing the standard and defining conformance tests. This ran from 1992 until 2006, at which point control of the API specification was passed to the Khronos Group.
8.6.2 Prerelease API Reviews
A prerelease API review is a meeting that you hold just before the API is finally released. It’s often a good activity to perform right before or during the alpha release stage. The best process for these reviews for your organization will obviously differ from what works best elsewhere. However, here are some general suggestions to help guide you. First of all, you should identify who the critical attendees are for such a review meeting.
1. Product owner. This is the person who has overall responsibility for product planning and for representing the needs of clients. Obviously this person must be technical because your users are technical. In Scrum terminology, the product owner represents the stakeholders and the business.
2. Technical lead. The review will generate questions about why a particular change was added and whether it was done in the best way. This requires deep technical knowledge of the code base and strong computer design skills. This person should be intimately familiar with the architectural and design rationale for the API, if they didn’t actually develop this themselves.
3. Documentation lead. An API is more than code. It’s also documentation. Not all issues raised in the review meeting need to be fixed by changing the code. Many will require documentation fixes. Because strong documentation is a critical component of any API, the presence of a person with technical writing skills at the review is very important.
You may decide to add further optional attendees to the review meeting to try and cast a wider net in your effort to assure that the new API release is the best it can be. At Pixar, we performed API reviews for all of the animation systems public APIs delivered to our film production users. In addition to the aforementioned attendees, we would also include representatives from QA, as well as a couple of senior engineers who work day to day in the source code. You will obviously also want someone from project management present to capture all of the notes for the meeting so that nothing gets forgotten.
Depending on the size of your API and the extent of the changes, these meetings can be long and grueling. We would regularly have several 2-hour meetings to cover all of the API changes. You shouldn’t rush these meetings or continue them when everyone is getting tired. Assume that they will take several days to complete, and ensure that developers and technical writers have time to implement any required changes coming out of the meeting before the API is released.
In terms of activities that should be performed during an API review, the most important thing is that the meeting should focus on the interface being delivered, not on the specifics of the code. In other words, the primary focus should be on documentation, such as the automatically generated API documentation (see Chapter 9 for specifics on using Doxygen for this purpose). More specifically, you are most interested in the changes in this documentation since the last release. This may involve the use of a tool to report differences between the current API and the previous version. I wrote the API Diff program to perform exactly this function. You can download it for free http://www.apidiff.com/.
For each change, the committee should ask various questions, such as:
• Does this change break backward compatibility?
• Does this change break binary compatibility (if this is a goal)?
• Does this change have sufficient documentation?
• Could this change have been implemented in a more future-proof manner?
• Does this change have negative performance implications?
• Does this change break the architecture model?
• Does this change conform to API coding standards?
• Does this change introduce cyclic dependencies into the code?
• Should the API change include upgrade scripts to help clients update their code or data files?
• Are there existing automated tests for the changed code to verify that functional compatibility has not been impacted?
• Does the change need automated tests and have they been written?
8.6.3 Precommit API Reviews
Of course, you don’t have to wait until right before release to catch these problems. The prerelease API review meeting is the last line of defense to ensure that undesirable changes aren’t released to users. However, the work of the API review can be decreased greatly if the API owners are constantly vigilant during the development process—watching checkins to the source code and flagging problems early on so that they can be addressed before they reach the API review meeting.
Many organizations or projects will therefore institute precommit API reviews. That is, they will put in place a change request process, where engineers wishing to make a change to the public API must formally request permission for the change from the API review committee. Implementation-only changes that do not affect the public API do not normally need to go through this additional process. This is particularly useful for open source software projects, where patches can be submitted from many engineers with differing backgrounds and skills.
For example, the open-source Symbian mobile device OS imposes a change control process for all Symbian platform public API changes. The stated goal of this process is to ensure that the public API evolves in a controlled manner. The process is started by submitting a change request (CR) with the following information:
• A description of the change and why it’s necessary.
• An impact analysis for any clients of the API.
This is then reviewed by the architecture council who will either approve or reject the request and provide the rationale for their decision. Once approved, the developer can submit their code, documentation, and test updates. Figure 8.4 provides an overview of this process.
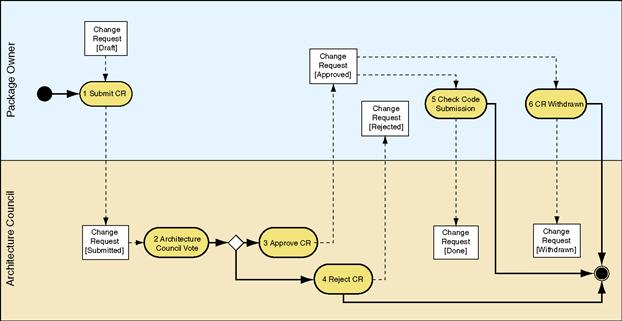
Figure 8.4 The public interface change request process for the Symbian platform. (Copyright © 2009 Symbian Foundation Limited. Licensed under the Creative Commons license 2.0 by Stichbury. See http://developer.symbian.org/.)
As another example, the Java-based NetBeans project defines an API review process for accepting patches from developers. This is done to supervise the architecture of the NetBeans IDE and related products. Changes to existing APIs, or requests for new APIs, are required to be reviewed before they are accepted into the trunk code line. This process is managed through the NetBeans bug tracking system, where requests for review are marked with the keyword API_REVIEW or API_REVIEW_FAST. The review process will result in a change being either accepted or rejected. In the case of rejection, the developer is normally given direction on improvements to the design, implementation, or documentation that would make the change more acceptable. Of course, similar feedback may still be provided for accepted changes. For details on this process, see http://wiki.netbeans.org/APIReviews.
Precommit reviews are a good way to stay on top of the incoming stream of API changes during the development process. However, it’s still useful to schedule a single prerelease API review meeting as well. This can be used to catch any changes that slipped through the cracks, either because an engineer was not aware of the process or didn’t realize that it applied to his or her change.