k-nearest neighbours (kNN) is considered one of the simplest algorithms in the category of supervised learning. kNN can be used for both classification and regression problems. In the training phase, kNN stores both the feature vectors and class labels of all of the training samples. In the classification phase, an unlabeled vector (a query or test vector in the same multidimensional feature space as the training examples) is classified as the class label that is most frequent among the k training samples nearest to the unlabeled vector to be classified, where k is a user-defined constant.
This can be seen graphically in the next diagram:
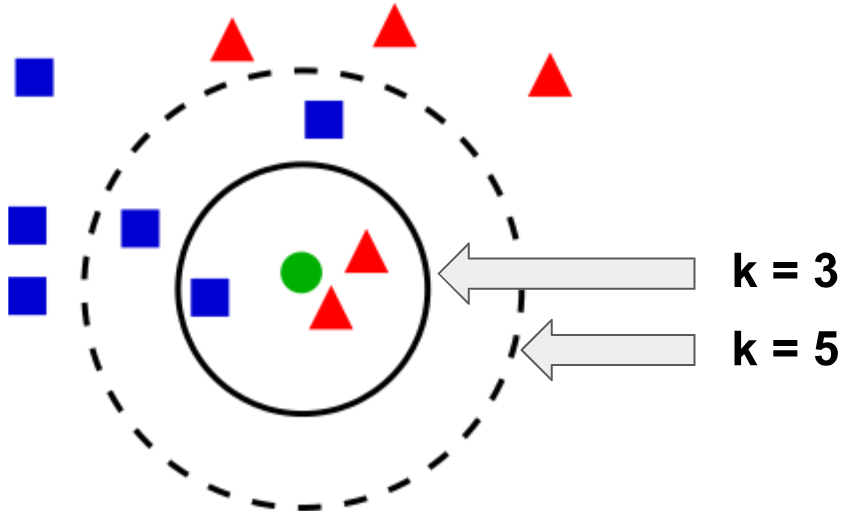
In the previous diagram, if k = 3, the green circle (the unlabeled test sample) will be classified as a triangle because there are two triangles and only one square inside the inner circle. If k = 5, the green circle will be classified as a square because there are three squares and only two triangles inside the dashed line circle.
In OpenCV, the first step to work with this classifier is to create it. The cv2.ml.KNearest_create() method creates an empty kNN classifier, which should be trained using the train() method to provide both the data and the labels. Finally, the findNearest() method is used to find the neighbors. The signature for this method is as follows:
retval, results, neighborResponses, dist=cv2.ml_KNearest.findNearest(samples, k[, results[, neighborResponses[, dist]]])
Here, samples is the input samples stored by rows, k sets the number of nearest neighbors (should be greater than one), results stores the predictions for each input sample, neighborResponses stores the corresponding neighbors, and dist stores the distances from the input samples to the corresponding neighbors.
In this section, we will see two examples in order to see how to use the kNN algorithm in OpenCV. In the first example, an intuitive understanding of kNN is expected to be achieved, while in the second example, kNN will be applied to the problem of handwritten digit recognition.