Following the success of AlexNet in this competition, many other deep learning architectures have been submitted to the ImageNet challenge in order to accomplish better performance. In this sense, the next diagram shows one-crop accuracies of the most relevant deep learning approaches submitted to the ImageNet challenge, including the AlexNet (2012) architecture on the far left, to the best performing Inception-V4 (2016) on the far right:
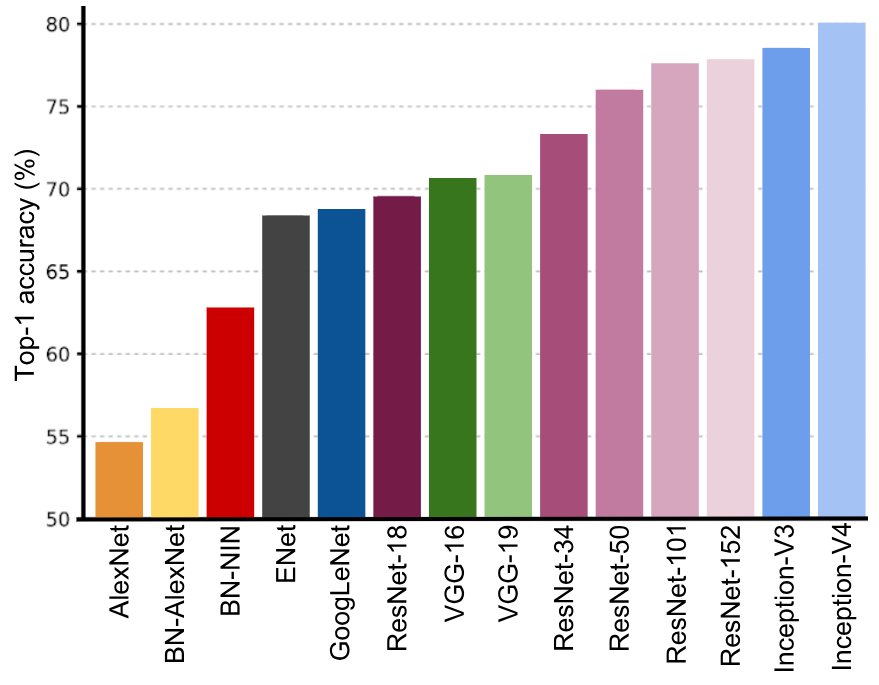
The main aspects of these deep learning architectures are briefly commented on as follows, highlighting the key aspects they introduce.
Additionally, we also include the reference to each publication in case further details are required:
- AlexNet (2012):
- Description: AlexNet was the winner of LSVRC-2012, and is a simple, yet powerful, network architecture with convolutional and pooling layers one on top of the other, followed by fully connected layers at the top. This architecture is commonly used as a starting point when applying a deep learning approach to computer vision tasks.
- Reference: Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. ImageNet classification with deep convolutional neural networks. In Advances in neural information processing systems, pp. 1097–1105, 2012.
- VGG-16 and -19 (2014):
- Description: VGGNet was proposed by the Visual Geometry Group (VGG) from the University of Oxford. The VGGNet model was placed second in the LSVRC-2014 by using only 3 x 3 filters throughout the whole network instead of using large-size filters (such as 7 x 7, and 11 x 11). The main contribution of this work is that it shows that the depth of a network is a critical component in achieving better recognition or classification accuracy in convolutional neural networks. VGGNet is considered a good architecture for benchmarking on a particular task. However, its main disadvantages are that it is very slow to train and its network architecture weights are quite large (533 MB for VGG-16 and 574 MB for VGG-19). VGGNet-19 uses 138 million parameters.
- Reference: Simonyan, K., and Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
- GoogLeNet/Inception V1 (2014):
- Description: GoogLeNet (also known as Inception V1) was the winner of LSVRC-2014, achieving a top-5 error rate of 6.67%, which is very close to human-level performance. This architecture is even deeper than VGGNet. However, it uses only one-tenth of the number of parameters of AlexNet (from 60 million to only 4 million parameters) due to the architecture of 9 parallel modules, the inception module, which is based on several very small convolutions with the objective of reducing the number of parameters.
- Reference: Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Dumitru, .E, Vincent, .V, and Rabinovich, A. (2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1-9).
- ResNet-18, -34, -50, -101 and -152 (2015):
- Description: Microsoft's Residual Networks (ResNets) was the winner of LSVRC-2015, and is the deepest network so far, with 153 convolution layers achieving a top-5 classification error of 4.9% (which is slightly better than human accuracy). This architecture includes skip connections, also known as gate units or gated recurrent units, enabling incremental learning changes. ResNet-34 uses 21.8 million parameters, ResNet-50 uses 25.6 million parameters, ResNet-101 uses 44.5 million, and, finally, ResNet-152 uses 60.2 million parameters.
- Reference: He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
- Inception V3 (2015):
- Description: As shown before, the inception architecture was introduced as GoogLeNet (also known as Inception V1). Later, this architecture was modified to introduce batch normalization (Inception-V2). The Inception V3 architecture includes additional factorization ideas whose objective is to reduce the number of connections/parameters without decreasing network efficiency.
- Reference: Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., and Wojna, Z. (2016). Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2818-2826).
- Inception V4 (2016):
- Description: Inception V4, evolved from GoogLeNet. Additionally, this architecture has a more uniform simplified architecture and more inception modules than Inception-V3. Inception-V4 was able to achieve 80.2% top-1 accuracy and 95.2% top-5 accuracy on the LSVRC.
- Reference: Szegedy, C., Ioffe, S., Vanhoucke, V., and Alemi, A. A. (2017, February). Inception-V4, inception-resnet and the impact of residual connections on learning. In AAAI (Vol. 4, p. 12).