Introduction
This chapter uncovers some of the basic techniques to tackle text data using PySpark. Today's textual form of data is being generated at a lightning pace with multiple social media platforms offering users the options to share their opinions, suggestions, comments, etc. The area that focuses on making machines learn and understand the textual data in order to perform some useful tasks is known as Natural Language Processing (NLP). The text data could be structured or unstructured, and we have to apply multiple steps in order to make it analysis ready. NLP is already a huge contributor to multiple applications. There are many applications of NLP that are heavily used by businesses these days such as chatbot, speech recognition, language translation, recommender systems, spam detection, and sentiment analysis. This chapter demonstrates a series of steps in order to process text data and apply a Machine Learning Algorithm on it. It also showcases the sequence embeddings that can be used as an alternative to traditional input features for classification.
Steps Involved in NLP
- 1.
Reading the corpus
- 2.
Tokenization
- 3.
Cleaning /Stopword removal
- 4.
Stemming
- 5.
Converting into Numerical Form
Before jumping into the steps to load and clean text data, let’s get familiar with a term known as Corpus as this would keep appearing in the rest of the chapter.
Corpus
A corpus is known as the entire collection of text documents. For example, suppose we have thousands of emails in a collection that we need to process and analyze for our use. This group of emails is known as a corpus as it contains all the text documents. The next step in text processing is tokenization.
Tokenize
The method of dividing the given sentence or collection of words of a text document into separate /individual words is known as tokenization. It removes the unnecessary characters such as punctuation. For example, if we have a sentence such as:
Input: He really liked the London City. He is there for two more days.
Tokens:
He, really, liked, the, London, City, He, is, there, for, two, more, days
We end up with 13 tokens for the above input sentence.

We get a new column named tokens that contains the tokens for each sentence.
Stopwords Removal

As you can observe, the stopwords like ‘I’, ‘this’, ‘was’, ‘am’, ‘but’, ‘that’ are removed from the tokens column.
Bag of Words
This is the methodology through which we can represent the text data into numerical form for it to be used by Machine Learning or any other analysis. Text data is generally unstructured and varies in its length. BOW (Bag of Words) allows us to convert the text form into a numerical vector form by considering the occurrence of the words in text documents. For example,
Doc 1: The best thing in life is to travel
Doc 2: Travel is the best medicine
Doc 3: One should travel more often
Vocabulary:
The | best | thing | in | life | is | to | travel | medicine | one | should | more | often |
Another element is the representation of the word in the particular document using a Boolean value.
(1 or 0).
The | best | thing | in | life | is | to | travel | medicine | one | should | more | often |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
The | best | thing | in | life | is | to | travel | medicine | one | should | more | often |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
The | best | thing | in | life | is | to | travel | medicine | one | should | more | often |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 |
The BOW does not consider the order of words in the document and the semantic meaning of the word and hence is the most baseline method to represent the text data into numerical form. There are other ways by which we can convert the textual data into numerical form, which are mentioned in the next section. We will use PySpark to go through each one of these methods.
Count Vectorizer

As we can observe, each sentence is represented as a dense vector. It shows that the vector length is 11 and the first sentence contains 3 values at the 0th, 4th, and 9th indexes.
So, the vocabulary size for the above sentences is 11 and if you look at the features carefully, they are similar to the input feature vector that we have been using for Machine Learning in PySpark. The drawback of using the Count Vectorizer method is that it doesn’t consider the co-occurrences of words in other documents. In simple terms, the words appearing more often would have a larger impact on the feature vector. Hence, another approach to convert text data into numerical form is known as Term Frequency – inverse Document Frequency (TF-IDF).
TF-IDF
This method tries to normalize the frequency of word occurrence based on other documents. The whole idea is to give more weight to the word if appearing a high number of times in the same document but penalize if it is appearing a higher number of times in other documents as well. This indicates that a word is common across the corpus and is not as important as its frequency in the current document indicates.
Term Frequency: Score based on the frequency of word in current document.
Inverse Document Frequency: Scoring based on frequency of documents that contains the current word.


Text Classification Using Machine Learning




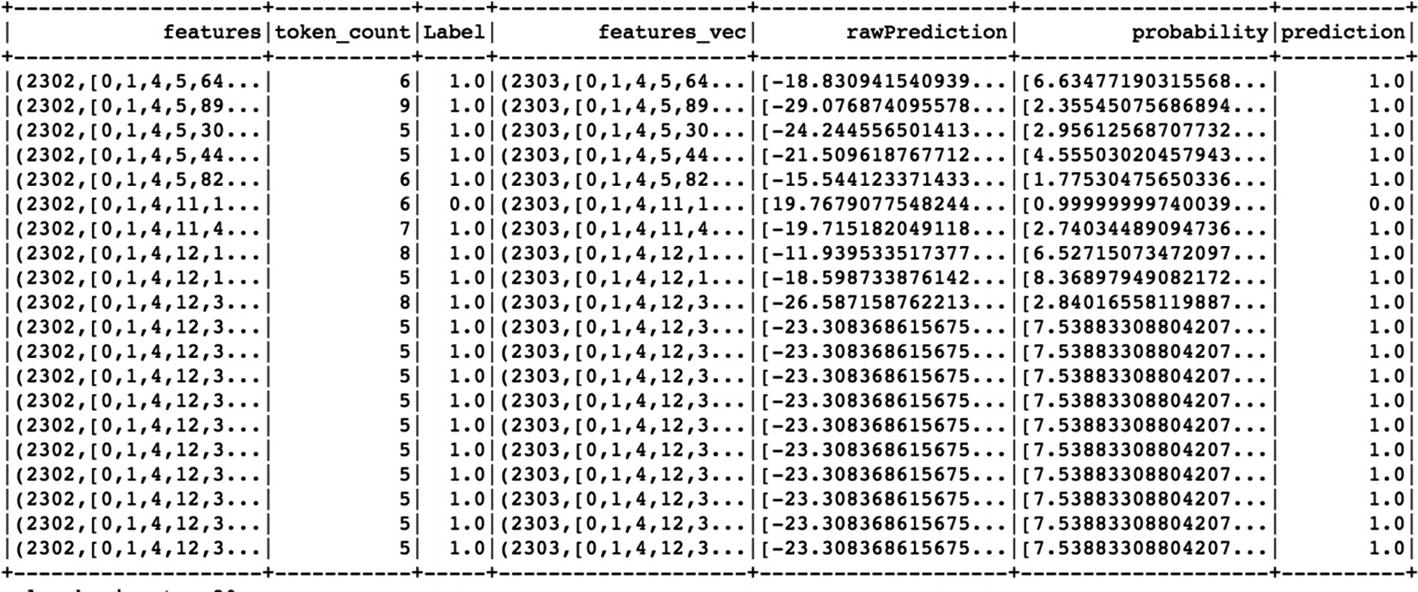
Sequence Embeddings
Millions of people visit business websites every day, and each one of them takes a different set of steps in order to seek the right information/product. Yet most of them leave disappointed or dejected for some reason, and very few get to the right page within the website. In this kind of situation, it becomes difficult to find out if the potential customer actually got the information that he was looking for. Also, the individual journeys of these viewers can’t be compared to each other since every person has done a different set of activities. So, how can we know more about these journeys and compare these visitors to each other? Sequence Embedding is a powerful way that offers us the flexibility to not only compare any two distinct viewers' entire journeys in terms of similarity but also to predict the probability of their conversion. Sequence embeddings essentially help us to move away from using traditional features to make predictions and considers not only the order of the activities of a user but also the average time spent on each of the unique pages to translate into more robust features; and it also used in Supervised Machine Learning across multiple use cases (next possible action prediction, converted vs. non-converted, product classification). Using traditional machine learning models on the advanced features like sequence embeddings, we can achieve tremendous results in terms of prediction accuracy, but the real benefit lies in visualizing all these user journeys and observing how distinct these paths are from the ideal ones.
This part of the chapter will unfold the process creating sequence embeddings for each user’s journey in PySpark.
Embeddings
- 1.
Skip Gram
- 2.
Continuous Bag of Words (CBOW)
Both methods give the embedding values that are nothing but weights of the hidden layer in a neural network. These embedding vectors can be of size 100 or more depending on the requirement. The word2vec gives the embedding values for each word where as doc2vec gives the embeddings for the entire sentence. Sequence Embeddings are similar to doc2vec and are the result of weighted means of the individual embedding of the word appearing in the sentence.
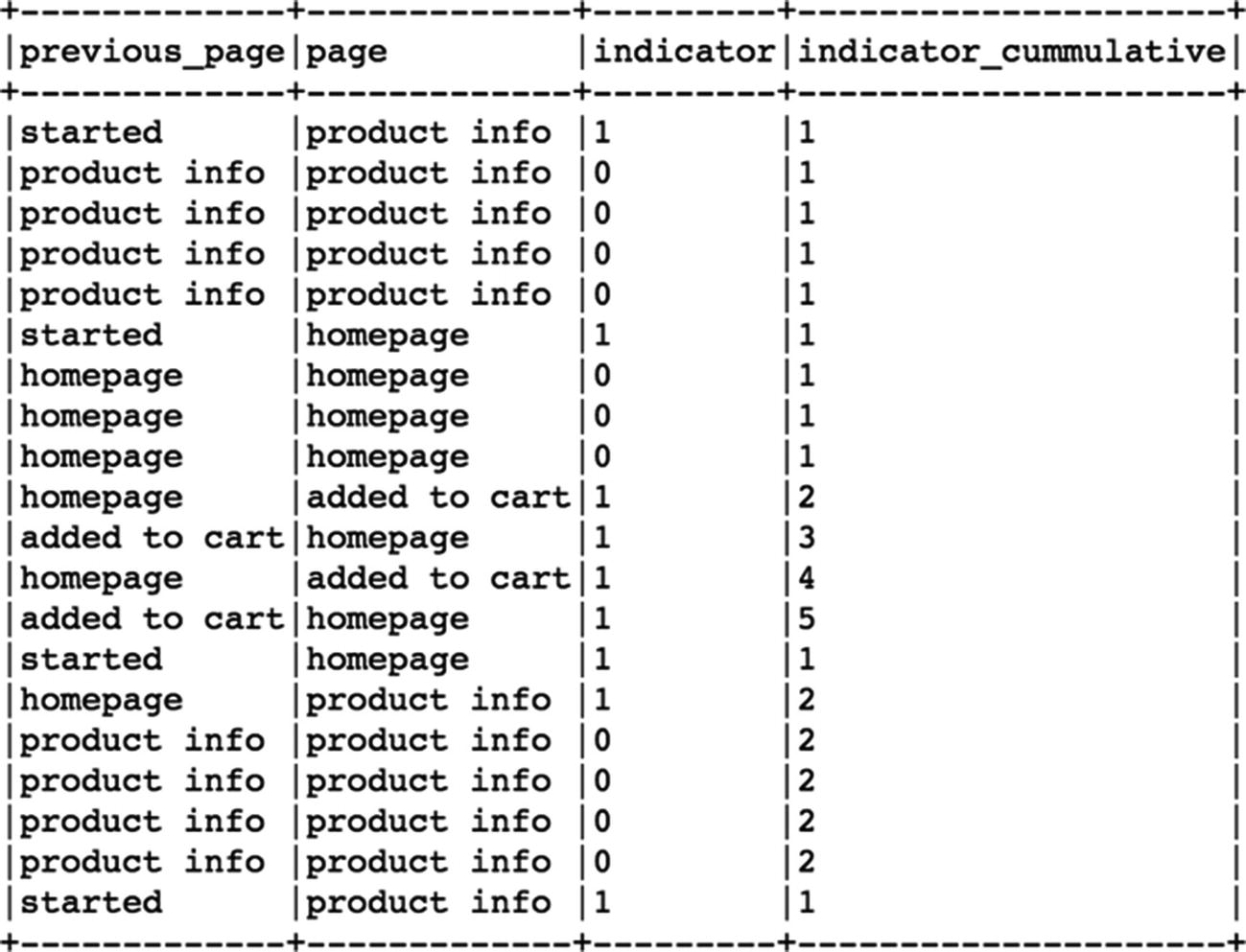
[Out]:
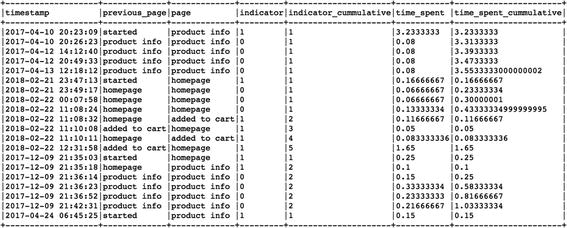
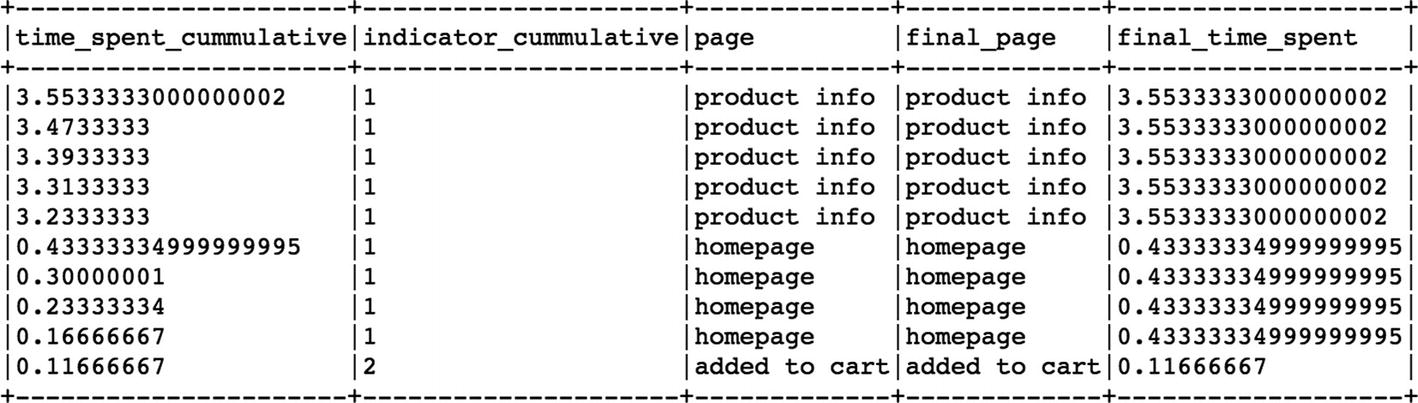

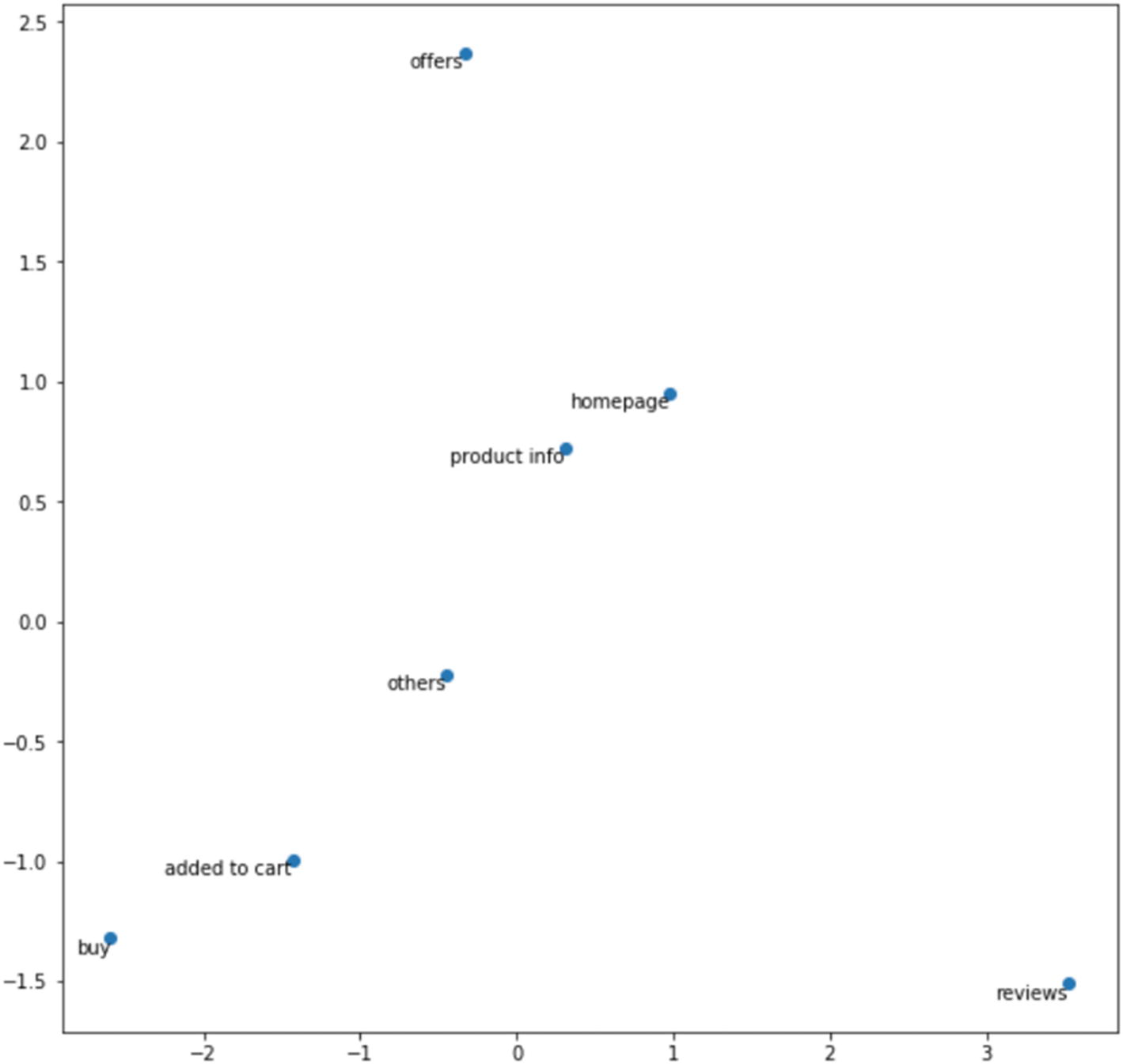
As we can clearly see, the embeddings of buy and added to cart are near to each other in terms of similarity whereas homepage and product info are also closer to each other. Offers and reviews are totally separate when it comes to representation through embeddings. These individual embeddings can be combined and used for user journey comparison and classification using Machine Learning.
Note
A complete dataset along with the code is available for reference on the GitHub repo of this book and executes best on Spark 2.3 and higher versions.
Conclusion
In this chapter, we became familiar with the steps to do text processing and create feature vectors for Machine Learning. We also went through the process of creating sequence embeddings from online user journey data for comparing various user journeys.