Changing code is great. It’s what we do for a living. But there are ways of changing code that make life difficult, and there are ways that make it much easier. In the industry, we haven’t spoken about that much. The closest we’ve gotten is the literature on refactoring. I think we can broaden the discussion a bit and talk about how to deal with code in the thorniest of situations. To do that, we have to dig deeper into the mechanics of change.
For simplicity’s sake, let’s look at four primary reasons to change software.
1. Adding a feature
2. Fixing a bug
3. Improving the design
4. Optimizing resource usage
Adding a feature seems like the most straightforward type of change to make. The software behaves one way, and users say that the system needs to do something else also.
Suppose that we are working on a web-based application, and a manager tells us that she wants the company logo moved from the left side of a page to the right side. We talk to her about it and discover it isn’t quite so simple. She wants to move the logo, but she wants other changes, too. She’d like to make it animated for the next release. Is this fixing a bug or adding a new feature? It depends on your point of view. From the point of view of the customer, she is definitely asking us to fix a problem. Maybe she saw the site and attended a meeting with people in her department, and they decided to change the logo placement and ask for a bit more functionality. From a developer’s point of view, the change could be seen as a completely new feature. “If they just stopped changing their minds, we’d be done by now.” But in some organizations the logo move is seen as just a bug fix, regardless of the fact that the team is going to have to do a lot of fresh work.
It is tempting to say that all of this is just subjective. You see it as a bug fix, and I see it as a feature, and that’s the end of it. Sadly, though, in many organizations, bug fixes and features have to be tracked and accounted for separately because of contracts or quality initiatives. At the people level, we can go back and forth endlessly about whether we are adding features or fixing bugs, but it is all just changing code and other artifacts. Unfortunately, this talk about bug-fixing and feature addition masks something that is much more important to us technically: behavioral change. There is a big difference between adding new behavior and changing old behavior.
In the company logo example, are we adding behavior? Yes. After the change, the system will display a logo on the right side of the page. Are we getting rid of any behavior? Yes, there won’t be a logo on the left side.
Let’s look at a harder case. Suppose that a customer wants to add a logo to the right side of a page, but there wasn’t one on the left side to start with. Yes, we are adding behavior, but are we removing any? Was anything rendered in the place where the logo is about to be rendered?
Are we changing behavior, adding it, or both?
It turns out that, for us, we can draw a distinction that is more useful to us as programmers. If we have to modify code (and HTML kind of counts as code), we could be changing behavior. If we are only adding code and calling it, we are often adding behavior. Let’s look at another example. Here is a method on a Java class:
public class CDPlayer
{
public void addTrackListing(Track track) {
...
}
...
}
The class has a method that enables us to add track listings. Let’s add another method that lets us replace track listings.
public class CDPlayer
{
public void addTrackListing(Track track) {
...
}
public void replaceTrackListing(String name, Track track) {
...
}
...
}
When we added that method, did we add new behavior to our application or change it? The answer is: neither. Adding a method doesn’t change behavior unless the method is called somehow.
Let’s make another code change. Let’s put a new button on the user interface for the CD player. The button lets users replace track listings. With that move, we’re adding the behavior we specified in replaceTrackListing method, but we’re also subtly changing behavior. The UI will render differently with that new button. Chances are, the UI will take about a microsecond longer to display. It seems nearly impossible to add behavior without changing it to some degree.
Design improvement is a different kind of software change. When we want to alter software’s structure to make it more maintainable, generally we want to keep its behavior intact also. When we drop behavior in that process, we often call that a bug. One of the main reasons why many programmers don’t attempt to improve design often is because it is relatively easy to lose behavior or create bad behavior in the process of doing it.
The act of improving design without changing its behavior is called refactoring. The idea behind refactoring is that we can make software more maintainable without changing behavior if we write tests to make sure that existing behavior doesn’t change and take small steps to verify that all along the process. People have been cleaning up code in systems for years, but only in the last few years has refactoring taken off. Refactoring differs from general cleanup in that we aren’t just doing low-risk things such as reformatting source code, or invasive and risky things such as rewriting chunks of it. Instead, we are making a series of small structural modifications, supported by tests to make the code easier to change. The key thing about refactoring from a change point of view is that there aren’t supposed to be any functional changes when you refactor (although behavior can change somewhat because the structural changes that you make can alter performance, for better or worse).
Optimization is like refactoring, but when we do it, we have a different goal. With both refactoring and optimization, we say, “We’re going to keep functionality exactly the same when we make changes, but we are going to change something else.” In refactoring, the “something else” is program structure; we want to make it easier to maintain. In optimization, the “something else” is some resource used by the program, usually time or memory.
It might seem strange that refactoring and optimization are kind of similar. They seem much closer to each other than adding features or fixing bugs. But is this really true? The thing that is common between refactoring and optimization is that we hold functionality invariant while we let something else change.
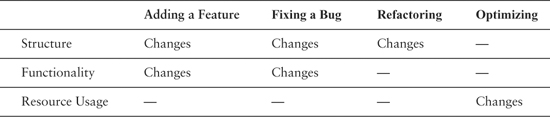
In general, three different things can change when we do work in a system: structure, functionality, and resource usage.
Let’s look at what usually changes and what stays more or less the same when we make four different kinds of changes (yes, often all three change, but let’s look at what is typical):
Superficially, refactoring and optimization do look very similar. They hold functionality invariant. But what happens when we account for new functionality separately? When we add a feature often we are adding new functionality, but without changing existing functionality.
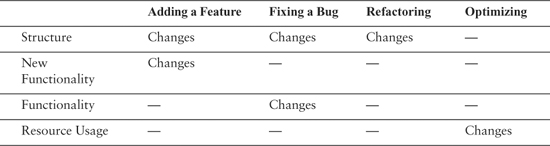
Adding features, refactoring, and optimizing all hold existing functionality invariant. In fact, if we scrutinize bug fixing, yes, it does change functionality, but the changes are often very small compared to the amount of existing functionality that is not altered.
Feature addition and bug fixing are very much like refactoring and optimization. In all four cases, we want to change some functionality, some behavior, but we want to preserve much more (see Figure 1.1).
Figure 1.1 Preserving behavior.
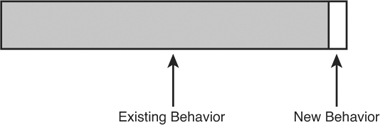
That’s a nice view of what is supposed to happen when we make changes, but what does it mean for us practically? On the positive side, it seems to tell us what we have to concentrate on. We have to make sure that the small number of things that we change are changed correctly. On the negative side, well, that isn’t the only thing we have to concentrate on. We have to figure out how to preserve the rest of the behavior. Unfortunately, preserving it involves more than just leaving the code alone. We have to know that the behavior isn’t changing, and that can be tough. The amount of behavior that we have to preserve is usually very large, but that isn’t the big deal. The big deal is that we often don’t know how much of that behavior is at risk when we make our changes. If we knew, we could concentrate on that behavior and not care about the rest. Understanding is the key thing that we need to make changes safely.
Preserving behavior is a large challenge. When we need to make changes and preserve behavior, it can involve considerable risk.
To mitigate risk, we have to ask three questions:
1. What changes do we have to make?
2. How will we know that we’ve done them correctly?
3. How will we know that we haven’t broken anything?
How much change can you afford if changes are risky?
Most teams that I’ve worked with have tried to manage risk in a very conservative way. They minimize the number of changes that they make to the code base. Sometimes this is a team policy: “If it’s not broke, don’t fix it.” At other times, it isn’t anything that anyone articulates. The developers are just very cautious when they make changes. “What? Create another method for that? No, I’ll just put the lines of code right here in the method, where I can see them and the rest of the code. It involves less editing, and it’s safer.”
It’s tempting to think that we can minimize software problems by avoiding them, but, unfortunately, it always catches up with us. When we avoid creating new classes and methods, the existing ones grow larger and harder to understand. When you make changes in any large system, you can expect to take a little time to get familiar with the area you are working with. The difference between good systems and bad ones is that, in the good ones, you feel pretty calm after you’ve done that learning, and you are confident in the change you are about to make. In poorly structured code, the move from figuring things out to making changes feels like jumping off a cliff to avoid a tiger. You hesitate and hesitate. “Am I ready to do it? Well, I guess I have to.”
Avoiding change has other bad consequences. When people don’t make changes often they get rusty at it. Breaking down a big class into pieces can be pretty involved work unless you do it a couple of times a week. When you do, it becomes routine. You get better at figuring out what can break and what can’t, and it is much easier to do.
The last consequence of avoiding change is fear. Unfortunately, many teams live with incredible fear of change and it gets worse every day. Often they aren’t aware of how much fear they have until they learn better techniques and the fear starts to fade away.
We’ve talked about how avoiding change is a bad thing, but what is our alternative? One alternative is to just try harder. Maybe we can hire more people so that there is enough time for everyone to sit and analyze, to scrutinize all of the code and make changes the “right” way. Surely more time and scrutiny will make change safer. Or will it? After all of that scrutiny, will anyone know that they’ve gotten it right?