Build, buy, or borrow. It’s a choice we all have to make when we develop software. Many times when we’re working on an application, we suspect that we can save ourselves some time and effort by buying some vendor library, using some open source, or even just using significant chunks of code from libraries that come bundled with our platform (J2EE, .NET, and so on). There are many different things to consider when choosing to integrate code we can’t change. We have to know how stable it is, whether it is sufficient, and how easy it is to use. And, when we do finally decide to use someone else’s code, we’re often left with another problem. We end up with applications that look like they are nothing but repeated calls to someone else’s library. How do we make changes in code like that?
The immediate temptation is to say that we don’t really need tests. After all, we aren’t really doing anything significant; we’re just calling a method here and there, and our code is simple. It’s really simple. What can go wrong?
Many legacy projects have started from those humble beginnings. The code grows and grows, and things aren’t quite as simple anymore. Over time, we might still be able to see areas of code that don’t touch an API, but they are embedded in a patchwork of untestable code. We have to run the application every time we change something to make sure that it still works, and we are right back in the central dilemma of the legacy system programmer. Changes are uncertain; we didn’t write all of the code, but we have to maintain it.
Systems that are littered with library calls are harder to deal with than home-grown systems, in many respects. The first reason is that it is often hard to see how to make the structure better because all you can see are the API calls. Anything that would’ve been a hint at a design just isn’t there. The second reason that API-intensive systems are difficult is that we don’t own the API. If we did, we could rename interfaces, classes, and methods to make things clearer for us, or add methods to classes to make them available to different parts of the code.
Here is an example. This is a listing of very poorly written code for a mailing list server. We’re not even sure it works.
import java.io.IOException;
import java.util.Properties;
import javax.mail.*;
import javax.mail.internet.*;
public class MailingListServer
{
public static final String SUBJECT_MARKER = "[list]";
public static final String LOOP_HEADER = "X-Loop";
public static void main (String [] args) {
if (args.length != 8) {
System.err.println ("Usage: java MailingList <popHost> " +
"<smtpHost> <pop3user> <pop3password> " +
"<smtpuser> <smtppassword> <listname> " +
"<relayinterval>");
return;
}
HostInformation host = new HostInformation (
args [0], args [1], args [2], args [3],
args [4], args [5]);
String listAddress = args[6];
int interval = new Integer (args [7]).intValue ();
Roster roster = null;
try {
roster = new FileRoster("roster.txt");
} catch (Exception e) {
System.err.println ("unable to open roster.txt");
return;
}
try {
do {
try {
Properties properties = System.getProperties ();
Session session = Session.getDefaultInstance (
properties, null);
Store store = session.getStore ("pop3");
store.connect (host.pop3Host, -1,
host.pop3User, host.pop3Password);
Folder defaultFolder = store.getDefaultFolder();
if (defaultFolder == null) {
System.err.println("Unable to open default folder");
return;
}
Folder folder = defaultFolder.getFolder ("INBOX");
if (folder == null) {
System.err.println("Unable to get: "
+ defaultFolder);
return;
}
folder.open (Folder.READ_WRITE);
process(host, listAddress, roster, session,
store, folder);
} catch (Exception e) {
System.err.println(e);
System.err.println ("(retrying mail check)");
}
System.err.print (".");
try { Thread.sleep (interval * 1000); }
catch (InterruptedException e) {}
} while (true);
}
catch (Exception e) {
e.printStackTrace ();
}
}
private static void process(
HostInformation host, String listAddress, Roster roster,
Session session,Store store, Folder folder)
throws MessagingException {
try {
if (folder.getMessageCount() != 0) {
Message[] messages = folder.getMessages ();
doMessage(host, listAddress, roster, session,
folder, messages);
}
} catch (Exception e) {
System.err.println ("message handling error");
e.printStackTrace (System.err);
}
finally {
folder.close (true);
store.close ();
}
}
private static void doMessage(
HostInformation host,
String listAddress,
Roster roster,
Session session,
Folder folder,
Message[] messages) throws
MessagingException, AddressException, IOException,
NoSuchProviderException {
FetchProfile fp = new FetchProfile ();
fp.add (FetchProfile.Item.ENVELOPE);
fp.add (FetchProfile.Item.FLAGS);
fp.add ("X-Mailer");
folder.fetch (messages, fp);
for (int i = 0; i < messages.length; i++) {
Message message = messages [i];
if (message.getFlags ().contains (Flags.Flag.DELETED))
continue;
System.out.println("message received: "
+ message.getSubject ());
if (!roster.containsOneOf (message.getFrom ()))
continue;
MimeMessage forward = new MimeMessage (session);
InternetAddress result = null;
Address [] fromAddress = message.getFrom ();
if (fromAddress != null && fromAddress.length > 0)
result =
new InternetAddress (fromAddress [0].toString ());
InternetAddress from = result;
forward.setFrom (from);
forward.setReplyTo (new Address [] {
new InternetAddress (listAddress) });
forward.addRecipients (Message.RecipientType.TO,
listAddress);
forward.addRecipients (Message.RecipientType.BCC,
roster.getAddresses ());
String subject = message.getSubject();
if (-1 == message.getSubject().indexOf (SUBJECT_MARKER))
subject = SUBJECT_MARKER + " " + message.getSubject();
forward.setSubject (subject);
forward.setSentDate (message.getSentDate ());
forward.addHeader (LOOP_HEADER, listAddress);
Object content = message.getContent ();
if (content instanceof Multipart)
forward.setContent ((Multipart)content);
else
forward.setText ((String)content);
Properties props = new Properties ();
props.put ("mail.smtp.host", host.smtpHost);
Session smtpSession =
Session.getDefaultInstance (props, null);
Transport transport = smtpSession.getTransport ("smtp");
transport.connect (host.smtpHost,
host.smtpUser, host.smtpPassword);
transport.sendMessage (forward, roster.getAddresses ());
message.setFlag (Flags.Flag.DELETED, true);
}
}
}
It’s a pretty small piece of code, but it isn’t very clear. It’s hard to see any lines of code that don’t touch an API. Could this code be structured better? Could it be structured in a way that makes change easier?
Yes, it can.
The first step is to identify the computational core of code: What is this chunk of code really doing for us?
It might help to try to write a brief description of what it does:
This code reads configuration information from the command line and a list of e-mail addresses from a file. It checks for mail periodically. When it finds mail, it forwards it to each of the e-mail addresses in the file.
It seems that this program is mainly about input and output, but there is a little bit more. We’re running a thread in the code. It sleeps and then wakes up periodically to check for mail. In addition, we aren’t just sending out the incoming mail messages again; we’re making new messages based on the incoming one. We have to set all of the fields and then check and alter the subject line so that it shows that the message is coming from the mailing list. So, we are doing some real work.
If we try to separate the code’s responsibilities, we might end up with something like this:
1. We need something that can receive each incoming message and feed it into our system.
2. We need something that can just send out a mail message.
3. We need something that can make new messages for each incoming message, based on our roster of list recipients.
4. We need something that sleeps most of the time but wakes up periodically to see if there is more mail.
Now when we look at those responsibilities, does it seem like some are more tied to the Java Mail API than others? Responsibilities 1 and 2 are definitely tied to the mail API. Responsibility 3 is a little trickier. The message classes that we need are part of the mail API, but we can probably test the responsibility independently by creating dummy incoming messages. Responsibility 4 doesn’t really have anything to do with mail; it just requires a thread that is set to wake up at certain intervals.
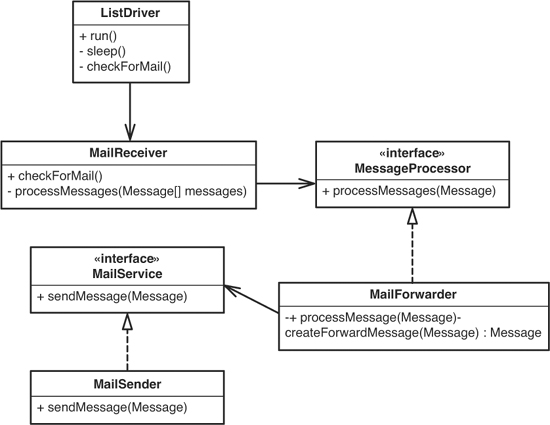
Figure 15.1 shows a little design that separates out these responsibilities.
Figure 15.1 A better mailing list server.
ListDriver drives the system. It has a thread that sleeps most of the time and wakes up periodically to check for mail. ListDriver checks for mail by telling the MailReceiver to check for mail. The MailReceiver reads the mail and sends the messages one by one to a MessageForwarder. The MessageForwarder creates messages for each of the list recipients and mails them using the MailSender.
This design is pretty nice. The MessageProcessor and MailService interfaces are handy because they allow us to test the classes independently. In particular, it’s great to be able to work on the MessageFowarder class in a test harness without actually sending mail. That’s easily achievable if we make a FakeMailSender class that implements the MailService interface.
Nearly every system has some core logic that can be peeled away from API calls. Although this case is small, it is actually worse than most. MessageForwarder is the piece of the system whose responsibility is most independent of the mechanics of sending and receiving mail, but it still uses the message classes of the JavaMail API. It doesn’t seem like there are many places for plain old Java classes. Regardless, factoring the system into four classes and two interfaces in the diagram does give us some layering. The primary logic of the mailing list is in the MessageForwarder class, and we can get it under test. In the original code, it was buried and unapproachable. It’s nearly impossible to break up a system into smaller pieces without ending up with some that are “higher level” than others.
When we have a system that looks like it is nothing but API calls, it helps to imagine that it is just one big object and then apply the responsibility-separation heuristics in Chapter 20, This Class Is Too Big and I Don’t Want It to Get Any Bigger. We might not be able to move toward a better design immediately, but just the act of identifying the responsibilities can make it easier to make better decisions as we move forward.
Okay, that was what a better design looks like. It’s nice to know that it’s possible, but back to reality: How do we move forward? There are essentially two approaches:
2. Responsibility-Based Extraction
When we Skin and Wrap the API, we make interfaces that mirror the API as close as possible and then create wrappers around library classes. To minimize our chances of making mistakes, we can Preserve Signatures (312) as we work. One advantage to skinning and wrapping an API is that we can end up having no dependencies on the underlying API code. Our wrappers can delegate to the real API in production code and we can use fakes during test.
Can we use this technique with the mailing list code?
This is the code in the mailing list server that actually sends the mail messages:
...
Session smtpSession = Session.getDefaultInstance (props, null);
Transport transport = smtpSession.getTransport ("smtp");
transport.connect (host.smtpHost, host.smtpUser,
host.smtpPassword);
transport.sendMessage (forward, roster.getAddresses ());
...
If we wanted to break the dependency on the Transport class, we could make a wrapper for it, but in this code, we don’t create the Transport object; we get it from the Session class. Can we create a wrapper for Session? Not really—Session is a final class. In Java, final classes can’t be subclassed (grumble, grumble).
This mailing list code is really a poor candidate for skinning. The API is relatively complicated. But if we don’t have any refactoring tools available, it could be the safest course.
Luckily, there are refactoring tools available for Java, so we can do something else called Responsibility-Based Extraction. In Responsibility-Based Extraction, we identify responsibilities in the code and start extracting methods for them.
What are the responsibilities in the preceding snippet of code? Well, its overall goal is to send a message. What does it need to do this? It needs an SMTP session and a connected transport. In the following code, we’ve extracted the responsibility of sending messages into its own method and added that methodb to a new class: MailSender.
import javax.mail.*;
import javax.mail.internet.InternetAddress;
import java.util.Properties;
public class MailSender
{
private HostInformation host;
private Roster roster;
public MailSender (HostInformation host, Roster roster) {
this.host = host;
this.roster = roster;
}
public void sendMessage (Message message) throws Exception {
Transport transport
= getSMTPSession ().getTransport ("smtp");
transport.connect (host.smtpHost,
host.smtpUser, host.smtpPassword);
transport.sendMessage (message, roster.getAddresses ());
}
private Session getSMTPSession () {
Properties props = new Properties ();
props.put ("mail.smtp.host", host.smtpHost);
return Session.getDefaultInstance (props, null);
}
}
How do we choose between Skin and Wrap the API and Responsibility-Based Extraction? Here are the trade-offs:
Skin and Wrap the API is good in these circumstances:
• The API is relatively small.
• You want to completely separate out dependencies on a third-party library.
• You don’t have tests, and you can’t write them because you can’t test through the API.
When we skin and wrap an API, we have the chance to get all of our code under test except for a thin layer of delegation from the wrapper to the real API classes.
Responsibility-Based Extraction is good in these circumstances:
• The API is more complicated.
• You have a tool that provides a safe extract method support, or you feel confident that you can do the extractions safely by hand.
Balancing the advantages and disadvantages of these techniques is kind of tricky. Skin and Wrap the API is more work, but it can be very useful when we want to isolate ourselves from third-party libraries, and that need comes up often. See Chapter 14, Dependencies on Libraries Are Killing Me, for details. When we use Responsibility-Based Extraction, we might end up extracting some of our own logic with the API code just so that we can extract a method with a higher-level name. If we do, our code can depend on higher-level interfaces rather than low-level API calls, but we might not be able to get the code we’ve extracted under test.
Many teams use both techniques: a thin wrapper for testing and a higher-level wrapper to present a better interface to their application.