24
It's the Uptime, Stupid
In 1992, campaign strategist James Carville coined the phrase, “it’s the economy, stupid.” At that time, Carville was attempting to emphasize the importance of the struggling economy in then-candidate Bill Clinton’s presidential campaign.30 The economy was in bad shape, and they knew without improving the economy, nothing else mattered. The same goes for IT: “It's the uptime, stupid.” As discussed in Chapter 5, Figure 5.1, if you can't keep your systems operational, achieving KTLO, the foundation level of the Laudato Hierarchy of IT Needs, the rest of your efforts are futile.
Somewhere along the way, I realized that IT could do more harm than good. You may have the best systems, processes, and people money can buy, but if your business isn't offering products or services people want, your business will still fail. On the other hand, if your products are amazing but your systems aren't up to the task, your business is on thin ice. In the digital age, hospitals, factories, warehouses, and retail stores can no longer operate without systems and networks. The hotdog cart in Central Park takes Apple Pay, and subway buskers accept donations via Venmo. All businesses are digital businesses.
Every CIO wants a seat at the table. Ensuring that systems are available, performant, and accurate is a critical first step. If you don't keep your emails emailing and your registers ringing, there's no way you're going to be invited to the CEO's office for a coffee chat.
When you do get a seat at the table, be careful not to become the resident audio-visual expert in the room. The moment the projector stops working, everyone in the room will turn to the CIO. You're the techie, so you need to fix the TV. While I'm sure that you know how to fix it (usually it's the Source button), I caution you against fixing it. It's hard to have a seat at the table when you're under the table. There is nothing executive about tracing HDMI cables or downloading drivers. I'm an advocate of rolling up my sleeves and working side-by-side with the team, but not at a board meeting. To avoid this, I always station an end-user technician outside the room for critical meetings. When you're asked to fix the projector, say sure, and summon the tech. When the board meeting is offsite, congrats: the tech will get to spend the day at a five-star hotel. Have the tech bring a supply of charging cables for every model of phone and laptop, so when someone needs one, it's there for the taking.
Measuring Uptime
Uptime is important, so you need to measure it. The first step in the process is to negotiate service-level objectives (SLOs) with your business partners. I prefer the term objectives instead of agreements internally. Service-level agreements (SLAs) are contractual obligations between a company and its service providers. Internally, we all work for the same company, and avoiding legal constructs feels more collaborative. When establishing SLOs, take into account the need for planned downtime. While your business partners don't ever want their systems to be down, they would much rather know in advance than be surprised. If you need to patch the servers once a month, schedule this in advance and negotiate a time that works best for your business.
Some systems require 24/7/365 availability. Hospitals, nuclear power plants, and Netflix all fall into this category. Just be aware that always up is much more expensive than almost always up. Establishing and publishing SLOs allows CIOs to match their infrastructure to the business need. Do you believe moving everything to the cloud solves your uptime issues? Think again. In 2020, Amazon, Google, IBM, Microsoft, and Oracle all had major outages.
Establish SLOs for all of your key systems, agree on an acceptable percent uptime, and make uptime a key performance metric for everyone in IT.
Nuances of Measuring Uptime
Should you measure, report, and hold your people accountable for software-as-a-service (SaaS) uptime? It's a complex debate. On the one hand, you have no control over their processes or technology stack. On the other hand, if you aren't responsible, who is? Your CEO? Your CFO? Nobody?
If your SaaS provider is down, it needs to be on the CIO. If CIOs abdicate responsibility for cloud and SaaS systems, what's the point of the CIO? CIOs negotiate the SLAs with the third parties, and CIOs should be actively involved in the recovery of SaaS apps. If it's a small provider, you should be in contact with the principals to ensure that your system takes priority over other customers. After the incident is resolved, meet with the provider to review what happened, and hold them accountable to make improvements. For larger providers, focus your attention on how the system was set up and configured. Your team may not have selected the most redundant or reliable option available during the initial setup.
What if the systems are up but the LAN is down? If the end-user can't access the system, it counts as an outage. If the system is up but inaccurate, that counts as an outage.
Measure report availably in a binary fashion. Daily reports should have an established delivery time. If sales reports are due at 6:00 a.m., they either made it or they didn't. Each day you missed counts against uptime. Being on time 29 of 30 days scores 96.6 percent. As with systems, if your report comes out on time but the data is inaccurate, your score is zero for that day.
Other edge cases can make uptime reporting complicated. If a system is up but has reduced capability or slow response time, I'll ask my business partner to select the impact. In the WMS example, if the system response time led to 30 minutes of extra work, I let the business owner decide how much to dock from the uptime calculation. They can pick 30 minutes or the entire day; it's their call.
Information Technology Infrastructure Library (ITIL)
Pronounced “eye-till,” ITIL is short for Information Technology Infrastructure Library. ITIL is a model that provides for implementing IT service management (ITSM) across all IT domains. ITSM software, including ServiceNow and EasyVista, is designed around ITIL workflows. I can't go deeper into this subject without boring you to death, but I encourage you to spend time exploring ITIL principles. ITIL is free, and it can be used as a framework to build your processes for incident management, problem management, and other IT services. ITIL is customer-centric, and it emphasizes getting to the root cause of problems. For more on ITIL, check out https://www.itlibrary.org/.
When You Have a Problem, Proclaim It Loudly
My CEO loves calling me when we're having system problems. She's highly attuned to what is going on in our business. There's little that makes me unhappier than hearing about a problem from Sharon before I hear about it from my team. Our goal is perfection; when that is not achieved, the next most important task is promptly notifying our business partners and providing regular status updates. Whether it's the CEO or an intern, it's IT's job to detect issues and notify our partners before they notify us.
The best way to accomplish this is to develop and follow a formal incident reporting process. ITIL provides guidelines for creating this process. Create the process in advance, set up the notification groups, and train your IT team on the process so it is executed properly every time. ITIL recommends using a matrix that evaluates both impact and urgency to determine the severity of an outage. This is overkill. When is a major system outage not urgent? Use impact to create your severity levels. See Figure 24.1 for a sample incident reporting process.
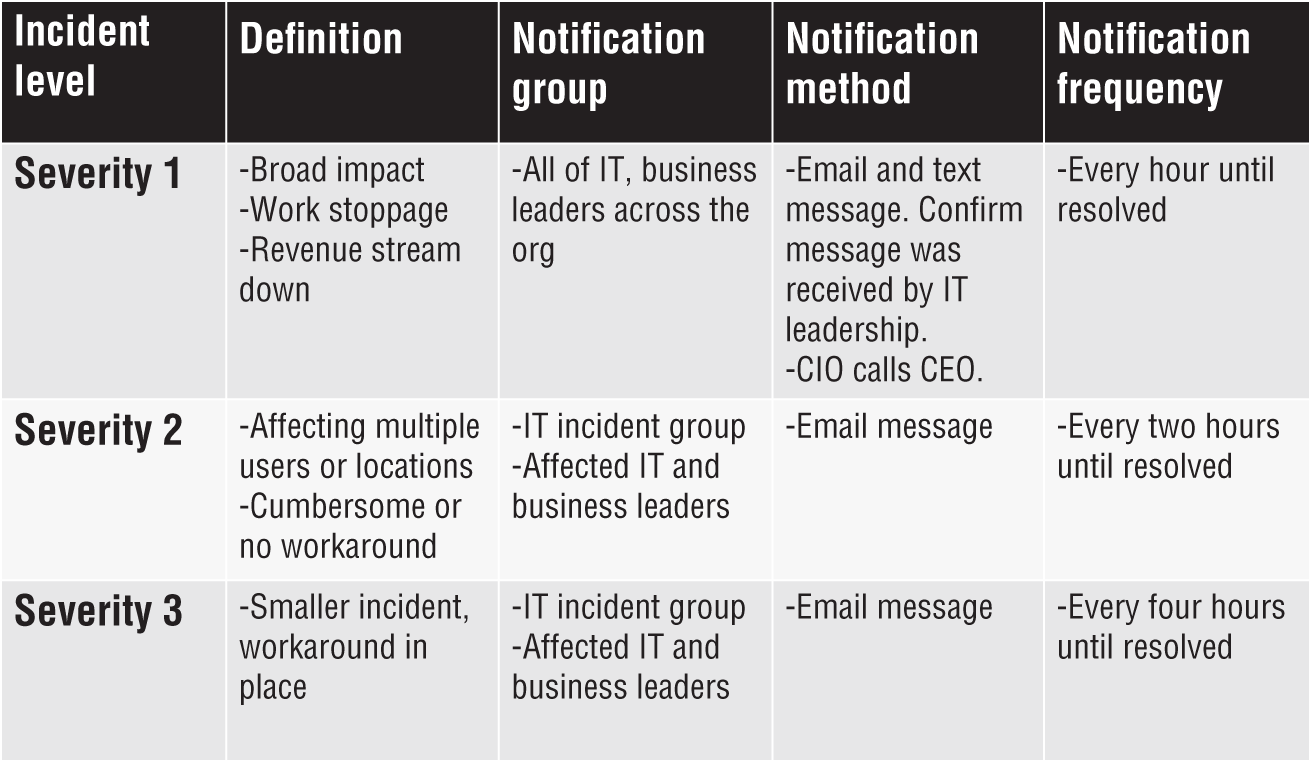
Figure 24.1: Sample ITIL Incident Reporting Process
Troubleshooting
Most IT problems take around five minutes to fix. Unfortunately, it could take hours to determine what the problem is and even longer to find the person with the skills to do that. A structured troubleshooting process will reduce these lead times. When something goes awry, follow these steps:
- Notify your business partners.
- Gather the right people.
- Appoint a “Storm Boss.”
- Appoint a comms person.
- Open a technical conference call.
- When the issue is resolved, hold a retrospective.
In today's world, most outages involve a third-party provider. You should have a list of key contacts and escalation points for all of your key vendors. Don't hesitate to call the highest-ranking person you know at the provider. Don't underestimate the power of salespeople in these scenarios. They are skilled connectors, and they know who's who in their organization.
Storm Boss is the person you put in charge of troubleshooting. The head of infrastructure or operations is ideal in this role. If it's a security-related incident, the CISO should be the Storm Boss. The Storm Boss is the decision-maker.
The best role for the CIO during a major outage is communications. Don't let your business partners on the technical conference call. Obsessed with transparency, I once thought this was a good idea. It backfired. You don't want your head of store operations or your warehouse manager talking directly to your engineers in the middle of a firefight. No need to elaborate further—the reasons for this are obvious.
The most likely cause of an incident is recent changes. The most cringe-worthy thing you'll hear in a change management meeting is, “This change will have no impact.” Call me superstitious, but teasing the IT gods is ill-advised, and a major outage is likely in your future.
When I learned to fly an airplane, the instructor drilled into me that when something goes wrong, undo the last thing you did. If you pull the mixture knob and the engine goes dead, push it back in. When users suddenly have trouble accessing apps, consider the firewall rules you just implemented the most likely culprit. If you use feature toggles, toggle any new features off and see if this resolves the problem.
I once worked for a boss, who will go unnamed, who wanted to know who was to blame in the middle of an outage. This is not the time to assign blame or dole out punishments. When the fire is still burning, focus 100 percent on fire fighting. After the problem is resolved, hold a retrospective. Learn from the incident so that it doesn't happen again. Don't punish your team for mistakes during or after an incident—turn mistakes into valuable learning experiences.
Let Them Eat Cake
If you're in the middle of a major outage, make sure your behavior is appropriate. A somber, humble demeanor is expected in these scenarios. Even if you aren't involved in the troubleshooting, joking, laughing, or heading out for an early happy hour is tone-deaf behavior. Cancel your dinner plans and stay at the office until the systems are operational again.
Change Management
Mature IT organizations have a change advisory board (CAB) that reviews and approves all changes. ITIL provides details on how to set up and run these meetings. I integrate the CAB meeting into the daily IT meeting that I discuss in detail in the next section. At The Vitamin Shoppe, we discuss IT changes with over 100 people daily. Everyone is well abreast of upcoming changes.
What constitutes a change? It's not just deploying new software. Operating system upgrades, patches, hotfixes, configuration changes, low-code/no-code deployments, and data fixes are all production changes, and they need to be reviewed and approved by the CAB before they move to production. If the change worked during testing, there's still a possibility it won't work in production. If you didn't test your change, it's guaranteed not to work in production. These are not only best practices; change management is a common Sarbanes-Oxley (SOX) control.
Daily Meeting
Communication is a critical component of leadership. With all or part of a team working remotely, intentional communication is even more necessary. For over 20 years and at three different companies, I've run a daily IT meeting to review incidents and discuss upcoming changes. For the first 20 years, this meeting included all of IT management. When the pandemic hit in 2020, the meeting moved to a video conference, allowing us to enlarge the invitation list. We expanded the meeting to include a sales update, an inventory update, a supply chain update, and even a health and wellness update. At The Vitamin Shoppe, every corporate office employee is invited to the meeting, and we average over 100 virtual attendees every single day. I am pleased and proud that our entire executive team regularly attends, including our CEO, Sharon Leite. This is a quick meeting, lasting no more than 15 minutes. It has been one of the tools we use to keep our culture strong while working remotely. Even when we go back to the office, we will keep the meeting open to all. Incidents and problems are openly discussed, changes are announced before they are deployed, and successes and milestones are celebrated on this call. Mike Provost, our emcee, expertly manages the flow of the call, keeping it crisp and fun. The chat feature in Microsoft Teams is a bonus, allowing participants to add information during the call.
Annual Readiness
Many businesses have a peak season. Retailers have a huge spike in sales at the end of the year. The peak day for pizza delivery is Super Bowl Sunday. Before the cloud gave us elastic capacity, we had to build our systems to handle the biggest day of the year. “Build the church for Easter Sunday” was the mantra. To prepare for the peak, CIOs established a peak-season readiness program. This includes technical tasks like capacity planning, stress testing, and performance enhancements. Peak-season planning also includes updating vendor and employee contact lists, creating a coverage schedule, and possibly setting up a war room for the biggest days. Most IT shops freeze production deployments during peak season because, as we know, changes cause incidents.
Some companies are less seasonal, or they have unpredictable peak sales days. Did Kylie Jenner just recommend your product on Instagram? Buckle up, because here comes your biggest sales day of the year. If you don't have a peak season, odds are you don't have a peak-season planning program. When was the last time you updated your contact list for your key partners? Take a page from the seasonal business and implement an annual readiness program for your steady business.
Note
- 30. “It’s the Economy, Stupid,” (Harvard Political Review, Oct 17, 2012).
https://harvardpolitics.com/its-the-economy-stupid/.