System Optimization for Big Data Processing
R. Li; X. Dong; X. Gu; Z. Xue; K. Li
Abstract
With the development and popularization of cloud computing, the Internet-of-Things, and mobile communications, the amount of data grows faster than ever before, which drives people to step into the age of Big Data. Hadoop and MapReduce programming frameworks have powerful data processing capability, and become more mature solutions in the field of text analysis, natural language processing, and business data processing. Therefore, Hadoop has become a key component of the Big Data processing system. Although Hadoop can support large-scale parallel data processing, there are still drawbacks to its underlying architecture and processing model in product environments, which caused the bottleneck in processing efficiency and performance. In terms of these shortcomings, various optimization techniques of Hadoop are proposed accordingly. In this chapter, the basic framework of the Hadoop ecosystem is described first. Next, we discuss the optimization of the parallel computing framework MapReduce, along with job scheduling, HDFS, HBase, etc. Finally, the directions of future optimization are discussed.
Keywords
Big Data; Hadoop; Performance optimization; MapReduce; Job scheduling; HDFS
9.1 Introduction
With the accelerated growth of digital information, a large amount of data is generated every day, from industrial productions to electronic commerce in life; from enterprise information management systems to e-government affairs of government departments; from social media to online video image data. According to incomplete statistics, new daily transactions of Taobao could reach 10 TB; the analysis processing data of eBay platform could go up to 100 PB; 10 million active users of Facebook [1], generate photos that can stack up at 80 Tour Eiffel daily; YouTube users upload 60 h video data every minute. According to the IDC forecasts, the amount of data stored in electronic form could reach 32ZB globally by 2020. If one burned it to DVD discs, one could stack up dozens of back and forth from the earth to the moon base.
In recent years, Big Data [2] has become a sweeping global phenomenon and a hot topic in international academic circles. The application industries set off an unprecedented upsurge of research in this field. The data scientists, research institutes, and related companies all have proposed the concept of Big Data. However, they have not formed a unified definition of Big Data so far. The “4 V” features of Big Data implied the large quantity (volume), multimode (variety), speed (velocity), and low-density value (value). They increase the difficulty and complexity of data management and information extraction and lead that the conventional data processing is unable to meet the needs of the urgent change of data processing mode. Accordingly, the storage and management of Big Data have become a hot topic.
There are various types of real-world Big Data applications. The main processing mode can be divided into batch processing and stream processing. Batch processing is store then process, and the stream processing is straight-through processing. The processing mode of the stream processing treats the data as a stream. The data stream is composed of a constant stream of data. When new data arrive, it will be processed and returned immediately. The MapReduce programming model proposed by Google in 2004 is the most representative of the batch processing. Whether it is a stream processing or batch processing model, it is a feasible way to deal with Big Data. In the practice of Big Data processing, the combination of the two models will be used.
The data sources of Big Data are extensive. The application requirements and data types are not the same; however, the most basic processing procedure is the same. The whole Big Data processing flow can be defined as follows: With the aid of suitable tools, the data source is extracted and integrated, and the results are stored in a certain standard. Using appropriate data analysis technology to analyze the data stored, extract useful knowledge and use the appropriate way to show the results to the end user. Specifically, the process can be divided into data extraction and integration, data analysis, and data interpretation.
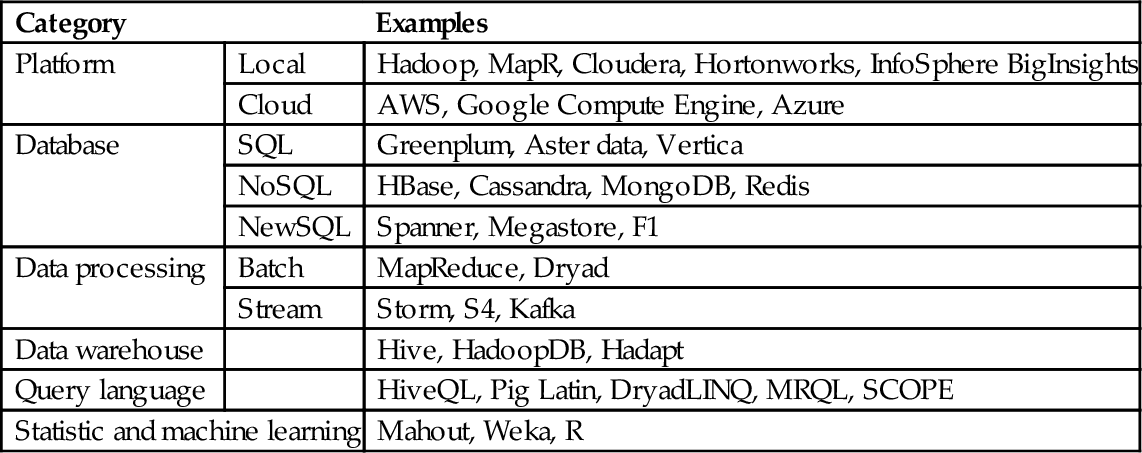
In the era of Big Data, data management, analysis, and other diverse needs to make the traditional relational database in many scenarios no longer apply. Therefore, a variety of Big Data processing tools came into being. Some of these tools are complete processing platforms, some of which are specifically tailored to the specific Big Data processing applications. Table 1 summarizes some of the mainstream processing platform and tools; most of them are based on the Hadoop function expansion or provide data interface with Hadoop. Hadoop is the most popular Big Data processing platform. Hadoop has developed into a complete ecosystem, including the file system (HDFS), database (HBase), data processing (MapReduce), and other functional modules. To some extent, Hadoop has become the de facto standard of Big Data processing tools.
Table 1
List of Big Data Tools
| Category | Examples | |
| Platform | Local | Hadoop, MapR, Cloudera, Hortonworks, InfoSphere BigInsights |
| Cloud | AWS, Google Compute Engine, Azure | |
| Database | SQL | Greenplum, Aster data, Vertica |
| NoSQL | HBase, Cassandra, MongoDB, Redis | |
| NewSQL | Spanner, Megastore, F1 | |
| Data processing | Batch | MapReduce, Dryad |
| Stream | Storm, S4, Kafka | |
| Data warehouse | Hive, HadoopDB, Hadapt | |
| Query language | HiveQL, Pig Latin, DryadLINQ, MRQL, SCOPE | |
| Statistic and machine learning | Mahout, Weka, R | |
Hadoop [3] has high-reliability, high-scalability, high-efficiency, and high-fault tolerance. While Hadoop has been adopted by many companies, it has some shortcomings, such as handling small files and the performance of data processing. For these problems, the study of Hadoop system performance optimization and enhancements could improve enterprise massive data processing capacity and real-time data processing, change data for the purpose of the assets, and provide references for the relevant technical personnel. In this chapter, we introduce the relevant technology of Hadoop and the system optimization of Hadoop-based Big Data processing technology, including the basic framework of Hadoop, parallel computation framework MapReduce, job scheduling of Hadoop, performance optimization of HDFS, performance optimization of HBase, and feature enhancements of Hadoop system.
In this chapter, we first compare the differences of several MapReduce-like frameworks and describe the load balancing of MapReduce and job scheduling of Hadoop. Second, we summarize performance optimization methods of HDFS and HBase. Third, we analyze and discuss a performance enhancement of Hadoop system and some directions of future optimization.
The rest of the chapter is organized as follows: Section 9.2 describes the basic framework of Hadoop system, Sections 9.3–9.7 introduce MapReduce parallel computing, framework optimized job scheduling optimization, HDFS [4] performance optimization, HBase [5], and Hadoop performance optimization enhancements individually, and finally, the summary and further research is given.
9.2 Basic Framework of the Hadoop Ecosystem
Hadoop has evolved into an ecosystem from open source implementation of Google’s four components, GFS [6], MapReduce, Bigtable [7], and Chubby. The basic framework of Hadoop ecosystem is shown in Fig. 1.
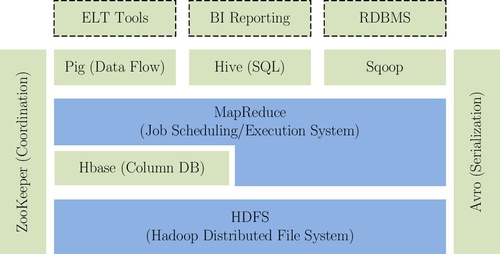
Fig. 1 describes each layer in the ecosystem, in addition to the core of the Hadoop distributed file system (HDFS) and MapReduce programming framework, including the closely linked HBase database cluster and ZooKeeper [8] cluster. HDFS is a master/slave architecture, which can perform a CRUD (create, read, update, and delete) operation on file by the directory entry. HDFS provides high reliability of the underlying storage support for the entire ecosystem. MapReduce adopts the “divide-and-conquer” ideas, which distributes operations of large data sets to each sub node, then merges the intermediate results of each node to get the final result. MapReduce can provide high-performance computing capacity for the system. HBase is located in a structured storage layer, and the Zookeeper cluster provides a stable service and failover mechanism for HBase.
Hadoop was originally used by applications like retrieval. However, with the advent of the era of Big Data, Hadoop was required to adapt to more extensive applications. For different types of applications, MapReduce parallel computing framework is inadequate and needs to be optimized. In order to make MapReduce process more tasks at the same time, we also need to consider the optimization of job scheduling. HBase is the open source database based on Hadoop. HBase has the problem of slow response speed and a single point of failure. In order to provide high performance, high reliability, and real-time reading and writing, we also need to optimize the performance of the HBase. HDFS is the underlying storage of Hadoop, which needs access to various sizes of files quickly in order to enhance its security performance. From the perspective of the overall balance of performance, efficiency, and availability, we can also further enhance Hadoop’s features.
9.3 Parallel Computation Framework: MapReduce
MapReduce is a distributed programming framework proposed by Google in 2004 for massive-scale parallel data analysis. It is applicable widely, which can reduce the difficulty of parallel programming. MapReduce is designed to deal with the massive data in the field of information retrieval based on the idea of divide and conquer. With the deepening of the research, the application arrangement of MapReduce is more and more extensive. At the same time, the shortage of MapReduce in handling other types of data processing is appearing progressively, such as in iterative or recursive type of applications. With a focus on this problem, researchers have proposed a lot of improvements and optimization for MapReduce.
9.3.1 Improvements of MapReduce Framework
Focusing on the deficiency of MapReduce on handling various types of applications, academicians and technicians did the following research: Yahoo! joined with the University of California, Los Angeles, and developed an improved model of MapReduce: Map-Reduce-Merge [9], which was used to handle multiple related heterogeneous data sets. The Map-Reduce-Merge adds a merge operation to combine the processing results of heterogeneous data sets. In order to solve the problem that MapReduce cannot adapt small-scale clusters well, the University of Oslo in Norway puts forward a parallel programming model named KPNs (Kahn process networks) [10]. KPNs are based on message-passing and shared-nothing models, which provide a simple and flexible tool for modeling parallel applications and could execute iterative computations automatically. However, their performance and scalability need to be verified.
The MapReduce framework itself still has some drawbacks, but some improvements have been proposed. The University of Illinois designed a parallel programming model named Barrierless MapReduce [11]. Focusing on the deficiency that the reduce operation needs to combine and sort the output key-value pairs of map tasks before processing, the model changes the features of reduce operations so that it can process the intermediate key-value pairs directly without sorting. However, it imposes new burdens on developers, who need to modify their custom reduce functions.
Limited by the design philosophy, iterative applications do not perform very well on the MapReduce framework. It is also a hot issue for researchers. The University of Tromso in Norway has improved the aforementioned Map-Reduce-Merge function and proposed Oivos [12]. It can manage and execute multiple MapReduce or Map-Reduce-Merge functions automatically so as to be more applicable for iterative applications. HaLoop [13,14] is a modified version of the Hadoop for iterative applications. The core idea of HaLoop is to improve the performance of iteration by caching static data locally. Each node caches the static data in a local file system, which remains the same in each iteration. HaLoop modifies the task scheduling strategy to take advantage of the static data caching. The tasks that process the same data input will be sent to the same node as the last iteration. However, the fixed task load allocation of reduce tasks between iterations might exist the load imbalance problem. Therefore, it is too inflexible to adapt heterogeneous clusters. Ekanayake et al. proposed a stream-based MapReduce framework that supports iterative programs, such as Twister [15]. In Twister, mappers and reducers are long running in a task pool to avoid building them repeatedly in iterations. The input and output of tasks are held in the distributed memory cache. However, in order to guarantee the same node in each iteration process, the same static data is cached in local memory; Twister uses a static scheduling strategy similar to HaLoop. Twister lacks the support of a distributed file system, and it still needs to improve its fault tolerance. Furthermore, based on the idea of asynchronous scheduling iterations, iMapReduce [16], PrIter [17], i2MapReduce [18], and iHadoop [19] were emerged in succession. They improve the execution efficiency of iterative applications. However, these achievements are still in an exploratory stage and have limitations that hinder their utilization in production.
Table 2 shows the comparison of several MapReduce-like frameworks we mentioned earlier. In conclusion, researchers make significant efforts to try to address the imperfection of MapReduce programming model. However, all these improvements are limited to one particular aspect that has not achieved a high level of abstraction. Their performance and scalability still need to be further verified; in fact, the original MapReduce model that was proposed by Google is still the most popular framework in the industry.
Table 2
Comparison of MapReduce-Like Frameworks
| Framework | Usability | Iterative Support | Main Features |
| MapReduce | Easy | No | Simple and valid, based on the thought of divide-and-conquer |
| Barrierless MapReduce | Complex | No | Modify the Reduce function to avoid combine-and-sort intermediate results |
| Map-Reduce-Merge | Easy | No | Add merge operation to process heterogeneous data sets |
| Oivos | Easy | Yes | Can execute multiple MapReduce or Map-Reduce-Merge automatically |
| KPNs | Easy | Yes | Can execute iterative computations automatically |
| HaLoop | Complex | Yes | Extend MapReduce API; Static data caching; Based on Hadoop |
| Twister | Easy | Yes | Import Task Pool mechanism to avoid rebuilding of tasks; lack support of DFS |

9.3.2 Optimization for Task Scheduling and Load Balancing of MapReduce
The primitive task scheduling strategy of MapReduce only considered the distribution of data storage in map phase that MapReduce tries to assign map tasks to a node where their input data stored on. While in the reduce phase, MapReduce partitions the intermediate data output by map tasks following the principle that the key-value pairs with the same key will be sent to the same reduce task. By default, MapReduce adopts hash partitioning to partition intermediate data, that is, it takes the hash code of each key modulo the number of reduce tasks.
The hash partitioning is based on an assumption that all nodes in the cluster are homogeneous (ie, the computing capability of each node is exactly the same). In fact, this assumption can hardly be set up. Experiments show that there are always some map or reduce tasks that execute much more slowly than others, therefore increasing the execution time of the whole job.
A mechanism called speculative execution is embedded into Hadoop to mitigate slow tasks. The JobTracker distinguishes slow tasks, which are called stragglers. When a tasktracker is applied for new tasks but all available tasks have already been assigned, the JobTracker would find out a straggler to launch a duplicate on the tasktracker. This mechanism tries to prevent some slow tasks or downed nodes to affect the performance of the whole job. However, in the real-world application, the mechanism is recognized as inefficient, especially in a dynamic environment.
Considering the heterogeneity and dynamics of the runtime environment, a self-adaptive scheduling policy may adapt better. Chen et al. proposed a scheduler called self-adaptive MapReduce (SAMR) [20]. By recording and analyzing the historical execution information of each node, SAMR looks up the slowest tasks dynamically. Kwon et al. at the University of Washington concentrated on the uneven distribution of input data and designed a runtime load balancing mechanism, SkewTune [21]. In a way that is similar to the speculative execution of Hadoop, when a tasktracker is idle, JobTracker will find a task with a heavy load and try to share its remaining processing with the idle tasktracker. However, in a different way from the speculative execution, SkewTune proposed a method to repartition the unprocessed input data of a task and to mitigate the subtask transparently instead of launching a duplicate of the whole task. Li et al. in National University of Defense Technology in China found the problem of an uneven data partition of hash partitioning in shuffle phase and put forward a skew-aware task scheduling iterative applications to mitigate the problem [22].
From another aspect, the spatial locality and temporal locality of the storage of input data and intermediate data would help to do a more balanced scheduling. Guo et al. proposed a scheduling policy based on the known data distribution [23]. The policy takes full account of the data distribution in the cluster and schedules tasks to proper nodes based on the priority of the tasks and nodes. Recognized that the longest approximate time to end (LATE) [24] scheduler, which is proposed and widely adopted before, did not take data locality into account, Li et al. put forward an improved version [25]. Fu et al. studied the load balancing mechanism of MapReduce framework in the environment of periodic applications [26]. Considering the similarity of its data distribution with history, they designed a load balancing strategy that partitioned intermediate data according to historical execution information in shuffle phase instead of hash partitioning to make the load more balanced. Heintz et al. at the University of Minnesota specialized in adopting MapReduce upon the geographically widely separated cluster and proposed a cross-phase optimization for MapReduce scheduling [27]. It built a feedback mechanism between the map and push phase and the shuffle and reduce phase, as well as adjusted the task scheduling scheme according to the feedback.
Generally speaking, researchers have made for fruitful discussion of the improvement of the MapReduce framework. However, for the applications that do not adopt a divide-and-conquer approach, the performance of MapReduce still needs to be promoted. In addition, there is still some room to further improve the performance of MapReduce, such as data transmission. More effective strategies for task scheduling, data caching, and load balancing are still hot topics for academics.
9.4 Job Scheduling of Hadoop
Hadoop job scheduling is the process in which JobTracker assigns tasks of submitted jobs to TaskTracker. Hadoop has a master-slave structure. This means that the master node, called JobTracker, controls the job scheduling of the whole cluster, while the rest of the slave nodes, called TaskTracker, request new tasks from the JobTracker if there are enough spare resources. In this section, we will discuss the job scheduling mechanism of Hadoop.
9.4.1 Built-in Scheduling Algorithms of Hadoop
Many scheduling algorithms were proposed for Hadoop. Hadoop uses a first-in-first-out (FIFO) scheduling algorithm as default. The execution sequence of jobs depends on their submission time. FIFO uses a Job Queue to maintain jobs, and it is JobTracker’s responsibility to assign tasks. The thought of the FIFO algorithm is very simple. However, it does not make any distinction between submitted jobs. Hadoop Fair Scheduling (HFS) [28,29] is a method that tries to allocate resources fairly, which makes each job share all resources equally. The purpose of the algorithm is to make Hadoop handle the requirements of different types of applications better. HFS adopts the thought of a hierarchical structure to assign tasks. It organizes jobs into several job pools and allocates resources fairly between pools. HFS will ensure that short jobs are completed within a reasonable amount of time and will not cause long jobs to starve to death. Capacity Scheduling [30] has a similar function to HFS, but it has obvious a difference in design and implementation. Capacity Scheduling uses multiple Job Queues to maintain jobs that are submitted by users. Each Job Queue can obtain a certain number of TaskTrackers to execute tasks according to the configuration.
Above are three common scheduling algorithms of the Hadoop platform. Generally speaking, each algorithm has its own advantages and disadvantages. The FIFO scheduling algorithm is still the most common one due to its simplicity, which is suitable for massive data processing. However, it ignores the different requirements of different type of applications. For real-time applications or interaction types of jobs, the FIFO scheduling algorithm always performs poorly. Because of this issue, HFS does better; nevertheless, it does not consider the capacity and current load of each node, which would lead to unbalanced load in a real environment. Compared with the FIFO algorithm, Capacity Scheduling algorithm supports multiuser and multijob scenarios, and it can adjust the allocation of cluster resources dynamically. However, it cannot configure and select a Job Queue automatically. If the users need to know the detailed information of a cluster, it will cause a bottleneck in the overall system performance in large-scale clusters.
Multiuser sharing and the diversification of job types put forward new requirements and ordeals for the scheduling strategy of a Hadoop cluster. Presently applied Hadoop job scheduling algorithms still have various problems, and these problems are mainly embodied in the following two aspects: (1) Job scheduling algorithms. Existing Hadoop scheduling algorithms still have some shortcomings. Considering the work characteristics, resource characteristics, and user requirements, improving fairness and efficiency of the scheduling algorithm is a key issue in the research of job scheduling. (2) Job scheduling architecture. Hadoop uses master-slave architecture to manage the resource of cluster, a master node named JobTracker is responsible for the entire cluster of job scheduling, and the rest of the nodes named TaskTrackers apply for tasks from the JobTracker when they are idle. There are two main problems with this architecture. First, one JobTracker takes charge of submitting, dispatching, and monitoring all jobs of the Hadoop cluster, as well as maintaining communication with huge numbers of TaskTrackers and monitoring the state information and statistics of all nodes in cluster. The JobTracker will be overwhelmed by the heavy load. In addition, all work of the job scheduling in the Hadoop cluster is concentrated on one JobTracker node, which increases the probability of a single-point failure (SPF). Once the JobTracker is down, the whole Hadoop platform will stop working altogether. As a result, many schemes have been proposed to improve the availability of Hadoop, many of which advise adding multiple JobTrackers to work together as backup nodes. Correspondingly, the distributed job scheduling method is also a hot area of research.
9.4.2 Improvement of the Hadoop Job Scheduling Algorithm
Focusing on the deficiency of the present Hadoop job scheduling algorithms, academia has conducted various studies. In order to make the job scheduling matchup to the expected performance requirement, some scholars proposed performance-driven schedulers to allocate resources properly in a limited-resource cluster so as to try their best to meet the performance requirement. The University of Northern California designed a job scheduling method based on job deadlines [31]. This method schedules jobs depending on the deadlines that are set by the users, but not on the number of jobs running in the cluster. According to job deadlines, they built an activity-based cost model to guide the scheduling. Polo et al. came up with a performance-driven job scheduler [32]. The scheduler could evaluate the completion time of jobs under a different resource allocation. According to the evaluated completion time, it schedules jobs with the goal of making each job meet the deadline requirements. Tang et al. oriented to the jobs with a deadline requirement upon the Hadoop platform and proposed a new job scheduler named MTSD [33]. MTSD considered the environment of heterogeneous clusters and the features of different map and reduce tasks. They classified the nodes according to the characteristics of resources and proposed different methods to evaluate the execution speed of tasks for different types of jobs. Then they built a model to predict the completion time of tasks based on the methods, scheduled jobs in the guarantee of completing before their deadline, and maximized the throughput of the cluster at the same time. Verma et al. in the University of Illinois invented a heuristic algorithm BalancedPool [34] with the goal of minimizing the execution time of the whole job set. They learned from the idea of an optimal two-stage job scheduling algorithm (Johnson) proposed in 1953. The BalancedPool can find the optimal scheduling scheme automatically based on the performance attributes of jobs in specific clusters.
In order to adapt the heterogeneity and dynamic of the runtime environment, some scholars explored self-adaptive scheduling policies. Tian et al. proposed a dynamic scheduling method for heterogeneous clusters [35]. This method classifies applications into compute-intensive and I/O-intensive; similarly, computing nodes are classified according to the CPU and I/O utilization. The classification will be determined and changed dynamically on the basis of the state information of the nodes. The research designed a policy to balance the execution of different types of applications upon different types of nodes so as to improve resource utilization efficiency. Yu et al. improved the job scheduling of Hadoop through the method of machine learning [36]. They adopted a Naive Bayes Classifier based on a feature weighting technique to classify the jobs. The research used the historical execution information as training samples and treated the usage of resources of all jobs and the state and quality of computing resources of all nodes as feature attributes.
Focusing on some specific problems, researchers have conducted representative research. Sandholm et al. came up with a scheduler based on the dynamic priority of a user-oriented cloud platform provider of acomputing service [37]. The allocation of the computing capacity was represented by the number of map or reduce task slots. This scheduler allocated task slots in proportion to the bidding of users. The more prices offered, the more capacity you get. Guyu et al. improved the scheduling model based on priority [38]. The improved model imported task priority and node priority by two parameters on the basis of the original job priority. The task priority is used to guide the scheduling of tasks inside the execution of a job. The node priority is determined by its load and historical success rate. Li et al. have put forward a fair scheduler based on the idea of data flow [39]. The scheduler organizes jobs into several data flows, and each data flow is represented by a directed acyclic graph so that each node in the graph expresses a job and each edge expresses the dependency between the two jobs. The scheduling among data flows basically adapted the idea of HFS. Ghodsi et al. proposed dominant resource fairness (DRF) [40] with the goal of a fair allocation scheme of multiple resources for multiusers in large-scale clusters. The research defined the resource with the highest usage percentage of the amount of cluster as its dominant resource. DRF achieved fairness scheduling by balancing the dominant resource of all users. Although this method pursued fairness so much that it did not meet the practical demand, its core idea of resource management was accepted and improved by Mesos and YARN.
9.4.3 Improvement of the Hadoop Job Management Framework
Considering the problem of SPF in Hadoop job management framework, experts and scholars have done much research. One of the most mainstreamed ideas is to share the work of JobTracker to several nodes so as to reduce the probability through lightening the burden on the nodes.
Industry invested massive experiments in this research field. In Apache’s project of the next generation of MapReduce (MRv2 or YARN) [41,42], engineers advocated to divide the responsibility of JobTracker into two parts (ie, task monitoring and resource management) and to distribute them into the cluster. YARN will launch an ApplicationMaster (AM) for each application to schedule and monitor tasks of its own, as well as to apply resources for execution from a global ResourceManager (RM). The global RM’s responsibility is to manage and assign the resource of the whole cluster. In this way, the JobTracker in original Hadoop is divided into AM and RM two modules, and the AMs are distributed into the cluster. Facebook had made an open source code of its next generation of distributed computing platform Corona [43]. Its design motive and implementation strategy are almost the same with YARN. A Corona Manager is in charge of the management and assignment of cluster resource like RM in YARN. Corona JobTracker is similar to AM in that it undertakes the monitoring and fault-tolerance of applications. As with YARN, each Corona JobTracker is responsible for one application.
Academia also launched research for many years on such an issue. To optimize the performance of JobTracker, the IBM Almaden research center came up with a more flexible scheduler policy on the basis of HFS [44]. The scheduler has the traits of HFS. Moreover, it allows users to choose and optimize various parameters. Xu et al. drew lessons from YARN that decompose the work of JobTracker [45], which leads to the separation of task monitoring and resource management. They added a new ResManageNode to manage the resource of the cluster, while the function of task monitoring was reserved to the JobTracker. The JobTracker would synchronize dynamically a message necessary for task scheduling to the ResManageNode by a heartbeat mechanism. The ResManageNode would allocate resources to tasks and report the allocating results to the JobTracker. This scheme used two nodes to share the work of the original JobTracker; while it lightened the burden of the master node, it did not solve the problem of SPF completely.
The job scheduling algorithm has become pluggable components of the Hadoop platform, which benefits researchers as they carry out further exploration and helps to raise creative suggestions. Fairer and more efficient scheduling algorithms are still a hot issue for scholars and engineers; moreover, the master-slave scheduling framework will be another bone of contention. On the one hand, the load is too heavy for one master node to control all of the management of the whole system, which will certainly become a bottleneck in large-scale clusters. On the other hand, once the master node goes down, the whole system will be paralyzed. Thus, the resource management and scheduling will be conducted through the collaboration of multiple nodes, so that those nodes can back each other up.
9.5 Performance Optimization of HDFS
The distributed file system is one of the core technologies in a cloud computing platform, and it is also the current research focus. There has emerged many distributed file systems in the industry, such as the GFS [6], HDFS [4], Haystack [46], and TFS [47], wherein HDFS is an open source version of GFS. It has been researched extensively, and it has been widely used in commercial enterprises such as Yahoo!, Cloudera, and Mapr. HDFS has good expansion capability, and it can store and process massive amounts of data reliably. It can also be used for low-cost business machines and for reducing development costs. Data can be processed in parallel to improve the efficiency of the system. It can automatically maintain the data copy, and after a failure, it can automatically rearrange computing tasks. Therefore, many large enterprises use HDFS to handle massive amounts of data. However, there are still many problems seriously restricting the further development of HDFS. HDFS is optimized through many ways in academia, including modifying the underlying traditional file system of HDFS. Its modification and some improvement in high-level optimization top on HDFS. We analyze the small file performance optimization and security performance optimization in the following.
9.5.1 Small File Performance Optimization
HDFS is designed for the efficient storage of and access to massive big files. It cuts large user files into a number of data blocks (such as 64 M). Metadata is stored in a metadata server while the data blocks are stored in the data servers. When dealing with small files, the number of data blocks in the file system increased dramatically. It also raises two issues: The first is the problem of a limited total number of files. A sharp increase of metadata results in the number of files and data blocks has limitations by the metadata server memory. The second is the performance problem. Traditional file systems have low performance when processing small files. As a consequence, there is a sharp performance decline in processing small files of data servers. Improving the ability of a distributed file system to handle a huge number of small files has become an urgent problem.
In recent years, Hadoop provides three solutions for the handle of small files, namely archive technology, sequence file technology, and merging file technology. These methods require users to write their own programs, which is why they are not widely adopted.
In view of the discrete random evenly distributed small file access, Fu et al. [48] proposed optimizing access efficiency of local blocks in data servers to optimize the performance of the distributed file system. They presented a flat lightweight file system called FlatLFS, in which the user data are managed flat in disks. FlatLFS is supposed to substitute the traditional file system when accessing user data for upper DFSs. With the improvement of the performance of small data block processing on the data servers by FlatLFS, the performance of the whole DFSs is greatly improved. But it is at the expense of flexibility in exchange for high efficiency and it is only fit for the data block management for a background data server, not for the general-purpose file directly to the user data management. Zhao et al. [49] proposed performance-optimized small file storage system access (SFSA) strategies, which not only enhance the access performance of small files, but also improve the utilization of disk space. According to the principle of locality, SFSA uses the policy of "sending high-frequency access bulk files in advance," which is also possible to optimize the performance of file transformation. Ma et al. [50] proposed a distributed file system based on distributed indexing and cataloging Polymerization—Ultra Virtual File System (HVFS) to manage billions of small files to support high-concurrency, high throughput, and low-latency access. As for the storage and retrieval of large amounts of small files, Yu et al. [51] designed and implemented a scalable, flexible distributed file system called MSFSS. It builds on the basis of the existing traditional file system. MSFSS automatically puts the file to the most appropriate file system based on the file access patterns and optimizes metadata size, separates the metadata operations from the file data transformation, and implements batch metadata operations to avoid the central bottleneck. At the same time, the system provides data migration, hot file caching, and replication to provide high scalability and throughput operation services. Mackey et al. [52] proposed a mechanism for effective storage of small files that improves metadata space utilization on HDFS—Har filing system, which has better metadata operations and more effectively HDFS usage. However, the mechanism is based on a quota of the file system’s allocating space for each client and the number of files. It optimized Hadoop compression methods to better utilize HDFS, and provided new job functions to allow jobs directory and file archiving to run MapReduce program that can be completed and not terminated by JobTracker because of the quota policy. It supports random access for internal files. However, handling Har small files remains inefficient.
These optimizations are all made on HDFS. Additionally, merging the small files into large files and then storing them on HDFS to reduce the I/O access are also much mentioned as an optimization method in academia. According to the characteristics of the WebGIS system, Liu et al. [53] presented a method to optimize the I/O performance of small files on HDFS. Small files are combined to form large files to reduce the number of files and create index for each file. At the same time, according to features of WebGIS access patterns, the files are nearly grouped and some of the latest version of the data is retained; as a result, the WebGIS system performance has greatly improved. According to the features of Bluesky System (China e-learning sharing system), Dong et al. [54] proposed solutions of small file storage options on HDFS. One is merging the files that belong to the same courseware into a large file to improve storage efficiency of small files. The other is the proposed two prefetching mechanism, namely, the index file and data file, prefetching to improve the reading efficiency of small files. Liu et al. [55] stored a large number of small files into one block and stored metadata information about these small files in the Datanode memory in order to optimize the I/O performance of small files on HDFS. Zhang et al. [56] proposed a method based on a small file merging HIFM (hierarchy index file merging), which considers the directory structure of small files and correlations between small files to merge the small files into large files and generate a stratification index. Index files are managed by the combination of centralized storage and distributed storage and realize the index file preloaded. Meanwhile, it uses a data prefetching mechanism to improve the efficiency of the sequential access of small files. HIFM can effectively improve the storage and reading efficiency of small files and significantly reduce the memory overhead of DataNode and NameNode. However, it does not support deletion and update operations on small files, and it is only suitable for the application scenarios, which have standardized directory structure and bulk data storage. Li et al. [57] proposed a new efficient approach named SmartFS. By analyzing the file access log to obtain the access behavior of users, SmartFS established a probability model of file associations. The model was the reference of a merging algorithm to merge the relevant small files into large files to be stored on HDFS. When a file was accessed, the related files were prefetched according to the prefetching algorithm to accelerate the access speed. At the same time, they put forward a cache replacement algorithm. It saved the metadata space of NameNode in HDFS and interaction between users and HDFS, as well as improved the storing and accessing efficiency of small files on HDFS. Zhang et al. [58] presented a small file based on a relational database consolidation strategy. It firstly creates a file for each user and then uploads the file’s metadata information to a relational database. The file is then written to the user’s file when the user uploads small files. Finally, the user reads small files via a streaming mode according to the metadata information. When the user reads a file whose size is smaller than the file block, DataNode takes a load balancing strategy and stores data transfers directly so as to reduce the pressure on the master server and improve the efficiency of file transfer. Yan et al. [59] proposed a middleware HMFS to improve the efficiency of storing and accessing small files on HDFS. It is made up of three layers: (a) file operation interfaces to make it easier for software developers to submit different file requests, (b) file management tasks to merge small files into big ones or extract small files from big ones in the background, and (c) file buffers to improve the I/O performance. HMFS boosts the file upload speed by using an asynchronous write mechanism and the file download speed by adopting prefetching and caching strategy.
This approach based on merging could theoretically increase the storage and reading speed of small files, reduce the write number of small files on data nodes, and reduce the frequently block allocation problem of the master server. However, the master server needs to open up an additional cache to integrate small files, and it needs to create index structure of small files, which brings the same master server bottlenecks. The client firstly needs to send small files to the master server to cache. When a problem arises with the master server, it will result in data loss security problems. In addition, the client needs to find the appropriate file block in the index structure based on the file name, and this process may need to read the corresponding index files on disk. The speed is very slow.
Due to increasing small file applications, the HBase based on HDFS is one of the small files problems solutions. However, as a structured data storage solution, it is not a good solution. Many NameNodes structures are a solution that is researched much now. However, if a particular NameNode caches excessive metadata and receives many clients’ requests, it will also cause single NameNode bottlenecks. Simultaneously, when the number of NameNode changes and a NameNode fails, it needs to move large amounts of metadata, which is a very complex process. During the migration process of metadata, it will seriously affect system performance.
9.5.2 HDFS Security Optimization
Cloud computing security and Big Data security are important topics; HDFS security has also become a research hotspot. The security and reliability of HDFS primarily lie in the following three areas: (1) In terms of certification, when a user logs in, as long as the user name and group name are consistent with the user information logged in the HDFS process, the authentication is successful. The attackers only set the user name and the group information with a legitimate user’s information unanimously. They could access the user's data on HDFS. While DataNode logs on to a specific HDFS cluster, NameNode has no certification to DataNode. (2) In terms of user authorization, when client interacts with NameNode, NameNode conducted nine bits permission judgment, the information is set by the file owner, and adopted by discretionary access control. This mechanism lacks high-level security. At the same time, users receive the file address information returned by NameNode so that they can directly access to Datanode, which has no permission judgment. (3) In terms of data disaster recovery, HDFS’s solution is mainly based on copying or mirroring backup. In order to prevent temporary disaster, more than doubled equipment and data resources are idle, which results in a great waste of resources and money. Many academic researchers conducted in-depth study of these issues.
O’Malley et al. [60] proposed a secure architecture of HDFS, which used the Kerberos protocol over SSL to ensure strong mutual authentication and access control. Cordova et al. [61] proposed the use of SSL and encrypted the distributed file system prototype. However, its write speed is slower than the general HDFS 10 times. Based on the study of Kerberos and RBAC model, Cai et al. [62] proposed token-based authentication mechanisms. The access control mechanism based on a token and access control model based on the domain and role is used to solve the problem of authentication and authorization on HDFS. There are four objectives, namely, (a) unauthenticated users cannot access the HDFS, (b) users can access a file if and only if they have permission to access the file, (c) Datanode needs to authenticate the user, and (d) refinement client access control grain to DataNode. In terms of the problems that the data cannot be completely destroyed and lead to data leakage in HDFS, Qin et al. [63] designed a multilevel secure data destruction mechanism on HDFS. On the one hand, the mechanism overwrites the original data by the overwritten algorithm before deleting them. This can effectively prevent malicious data recovery and data leakage in the cloud, so as to achieve the complete elimination of data. On the other hand, the mechanism utilizes a multiple security level definite to take a variety of overwriting data by destruction algorithms. Thus, it balances the security needs and performance requirements. In facing the environment of a private cloud expanding to a public cloud, Shen et al. [64] proposed architecture with implementation of security services, including data isolation service, secure cloud data migration in cloud services, and secure data migration services between cloud services. They implemented a prototype with three security policies based on HDFS systems. Majors et al. [65] proposed application-level encryption of MapReduce, which provides support to a secure file system. Lin et al. [66] proposed a hybrid encryption HDFS of HDFS-RSA and HDFS-Pairing. However, its read performance and write performance are lower than the general HDFS. Hadoop does not support encrypted storage for HDFS block. To tackle this problem, Park et al. [67] proposed Hadoop security architecture that adds encryption and decryption capabilities in HDFS. AES encryption and decryption compression codec in Hadoop to make HDFS even more secure, and the computational overhead that MapReduce jobs generated in the encryption HDFS is affordable.
Nguyen et al. [68] proposed a novel method to encrypt files while being uploaded. Data read from a file is transferred to HDFS across a buffer. The encryption, which is transparent to the user, is applied to the buffer's data before being sent to an out stream to write to HDFS. The time needed for the whole process is much less than what is needed for the conventional method. Qian et al. [69] proposed a novel model of cloud-secure storage, which combined the HDFS with symmetric and public-key cryptography. The model used the HDFS as the storage platform and the XML format as the logical storage structure. It not only solves the problem of storing massive data, but it also provides data access control mechanisms to ensure sharing data files with confidentiality and integrity among users in cloud environment. Shen et al. [70] proposed an architectural design for enforcing data security services on the layer of HDFS in the PSC, including secure data isolation service, secure intracloud data migration service, and secure intercloud data migration service. The prototype implemented as pluggable security modules in accordance with our custom security policies through AOP (aspect-oriented programming) method was given. Cohen et al. [71] described the threat against Hadoop in a sensitive environment, and how and why an advanced persistent threat (APT) could target Hadoop, as well as how standard-based trusted computing could be an effective approach to a layered threat mitigation. Later, they created a trusted Apache Hadoop Distributed File System and evaluated a threat model for HDFS [72]. They addressed a set of common security concerns within HDFS through infrastructure and software involving data-at-rest encryption and integrity validation.
As to the problems of low storage space utilization efficiency and low data recovery efficiency brought by HDFS’ multiple-copy disaster design, many scholars combined erasure codes, introduced coding and decoding modules, and designed file systems REPERA [73] and Noah [74]. They are both based on HDFS, which can ensure the cluster data security, improve data recovery speed, and reduce the cost of space and overall storage.
At present, most of the Hadoop clusters set up by major commercial companies are in private cloud architecture and are generally built for internal use. However, the cost of building private clouds is really high and would result in a waste of IT facilities. In order to enhance data security and increase user privacy protection in HDFS, they need to balance the premise of data security and high system efficiency, including the system memory space utilization and postdisaster data recovery efficiency.
From the above discussion, we can see that many researchers have conducted fruitful research on small file performance optimization and security enhancements in HDFS. While enhancing the HDFS security and privacy, we also need to optimize the performance of HDFS efficiency. Meanwhile, we need further research on low latency access, as well as maintain cache coherency and multiuser write and arbitrary modification in HDFS.
9.6 Performance Optimization of HBase
HBase [5] is a top Apache open source project, which is separated from Hadoop [3]. HBase is the database system, which possesses the characteristic of high-reliability, high-performance, column storage, scalable, and real-time read and write. It can directly use the local file system and HDFS file storage system. However, there are some problems in the applications. Carstoiu et al. [75] evaluated the performances of the HBase, including the random writing and reading of rows, sequential writing and sequential reading, and how are they affected by increasing the number of column families and using MapReduce functions. Rahman et al. [76] analyzed the performance of HBase, conducted comprehensive experiments, and identified different factors contributing to the overall latency of get and put operations. The experimental results showed that the HBase communication stack and associated operations need to be redesigned for high-performance networks like InfiniBand. In order to efficiently insert and read the massive data in business, HBase needs to be further optimized. We will discuss the optimization of HBase in three major aspects: framework, storage, and application optimization; load balancing; and configuration optimization.
9.6.1 HBase Framework, Storage, and Application Optimization
The current HBase is implemented by using the Java Sockets interface. Due to the overhead of the cross platform, HBase is difficult to provide high-performance services for data intensive applications. Huang et al. [77] presented a novel design of HBase for remote direct memory access (RDMA) capable networks via Java native nterface. Then they extended the existing open source HBase software and make it RDMA capable. The performance evaluation reveals that the latency of HBase get operations can be reduced. The existing interface of HBase for MapReduce to access speed is too low, so Tian et al. [78] offered an improved method. It splits the table that is not based on its logical storage element called “Region,” but on its physical storage element called “block” and uses a property scheduling policy, makes data reading and computing executes in the same node. Huang et al. [79] showed how to implement the set data structure and its operations in a scalable manner on top of Hadoop HBase, and then discussed the limitations of implementing this data structure in the Hadoop ecosystem. Their primary conclusion provided an excellent framework to implement scalable data structures for the Hadoop ecosystem.
The compression technology is commonly used to optimize HBase storage. Based on the existing compression system and the fact that column-oriented database stores information by column and the column property values are in high similarity, Luo et al. [80] proposed some lightweight introducing stored database of compression algorithm, which takes column property values as a coding units for data compression. In addition, based on the situation that different data matches different compression algorithm, they presented a method that is based on the dynamic selection strategy of a Bayesian classifier compression algorithm. According to the Bayesian formula, different data sections choose different compression algorithms, which make it possible to compress the data to reach the best compression effect. Cheng et al. [81] designed an inverted index table that includes a keyword, document ID, and position list; the table can save a lot of storage space. On the basis of the table, they provide key as dictionary compression with high compression ratio and high decompression rate for the data block.
In the aspect of HBase application, Karana [82] built a search engine, whose index is on Hadoop and HBase, to deploy in a cluster environment. Retrieval applications by nature involve read-intensive operations, which optimize the Hadoop and HBase. Ma et al. [83] proposed ST-HBase (spatiotextual HBase) that can deal with large-scale geotagged objects. ST-HBase can support high-insert throughput while providing efficient spatial keyword queries. In ST-HBase, they leverage an index module layered over a key-value store. The underlying key-value store enables the system to sustain high-insert throughput and deal with large-scale data. The index layer can provide efficient spatial keyword query processing. Awasthit et al. [84] explored the feasibility of introducing flash SSDs for HBase. They perform a qualitative and supporting quantitative assessment of the implications of storing the system components of HBase in flash SSDs. The proposed system performs 1.5–2.0 times better than a complete disk-based system. Zhang et al. [85] presented HBaseMQ, the first distributed message queuing system based on the bare-bones HBase. HBaseMQ directly inherits HBase’s properties such as scalability and fault tolerance, enabling HBase users to rapidly instantiate a message queuing system with no extra program deployment or modification to HBase. HBaseMQ effectively enhances the data processing capability of an existing HBase installation. These optimization methods can significantly improve the performance of the specific system; however, it is only optimized for specific applications, and the popularity is not high.
9.6.2 Load Balancing of HBase
The load balancing of HBase can be considered from two aspects of hardware and software. In terms of hardware, Facebook [1] built excellent physical architecture for Big Data services, such as the message service of an HBase cluster, which is divided into multiple clusters according to the user. Each cluster has 100 servers, including one NameNode and five racks, and each rack has a ZooKeeper [8] server. At the same time, the Facebook team adds a Bloom filter in HBase LSM Tree and optimizes the local read of DataNode and cache NameNode metadata, which achieve better disk-reading efficiency [86]. As for Taobao, which uses public HDFS [4] to minimize the impact of Compact, and each HDFS cluster is not more than 100 units in size. In HDFS cluster, multiple HBase clusters are built, and each HBase cluster has a master and a backup master. In addition, the Taobao team uses the ZooKeeper cluster to guarantee the independence of the HBase cluster. For the design of the software, in order to reduce the overload of the original database, a mirror database system is created for load balance. Researchers [87] designed HBase snapshot, and the proposed archive-on-delete function at the file level. That is to say, when a snapshot is created, the system only records all data files in a table without performing any copies of data. When the data file is to be deleted, and the system backups the data to ensure the normal access to the snapshot data. Therefore, the load balancing of HBase should be performed according to a specific application, a reasonable arrangement of cluster architecture, optimization software design, and avoidance of single database heavy load.
9.6.3 Optimization of HBase Configuration
According to the read-and-write optimization of HBase table, we usually do three types of settings: (1) A concurrent read/write of multiple HTable, in which we create multiple HTable clients to read/write, which improve the throughput of reading data. (2) A batch read/write, in which we can access/write multiple rows to reduce the I/O overhead of network. (3) A concurrent read/write using multiple threads, a method that not only ensures that a small amount of written data can be flushed in a relatively short period of time, but also ensures the large amount of written data to be flushed when the buffer is full.
According to the optimization of HBase table’s design, the common method is to precreate some empty regions in order to accelerate the batch write speed. Because the HBase data model is sorted by row-key storage, all of the continuous data will be loaded to the cache at the same time. Therefore, good row-key design can make batch read easily. In practical applications, a major compact can be used manually to form a large StoreFile with a row-key modification. At the same time, StoreFile can be set to reduce the incidence of split.
For the HBase block cache, there is a BlockCache and N Memstores in a RegionServer, and the size of the cache is not greater than the default value of HBase. The optimization of HBase block cache needs to consider the specific applications.
In summary, HBase is widely employed in many commercial production systems. The basic approach is to upgrade the business module on the foundation of original HBase. Then they develop the optimized patches of HBase. For the ordinary operators, they can adjust the configuration to achieve better performance of HBase. In recent years, the researchers focus on the optimization of framework, storage, applications, and load balance scheme of HBase.
9.7 Performance Enhancement of Hadoop System
In recent years, Hadoop is widely used as a Big Data processing platform in various applications. Many works have been proposed to enhance the performance of the Hadoop system, including the high efficiency of query processing, index construction and usage, construction of data warehouse, and applying Hadoop to database management, data mining, and recommendation systems. Xu et al. [73] present five kinds of research directions of Hadoop optimization, including enhancing the performance, increasing the utilization rate, improving the efficiency, improving the availability, and various problems of consistency constraints. In the following sections, we will discuss the most focused issues in this area.
9.7.1 Efficiency Optimization of Hadoop
To store and process large-scale data, the database management system (DBMS) and Hadoop have different merits. DBMS has outstanding performance in processing structured data, while it is relatively difficult for processing extremely large-scale data. Hadoop is suitable for processing large-scale data with a significant improvement of performance. The researchers believe that the combination of DBMS and Hadoop can effectively improve the performance of Hadoop.
Pavlo et al. [88] conclude that MapReduce is the most important model to process and analyze large-scale data. They compare DBMS and MapReduce computation models and propose that DBMS has significantly better executive performance, although data loading and parallel proposing of DBMS requires more time than MapReduce system.
Du et al. [89] present that when facing Big Data challenges, the traditional DBMS cannot accomplish the task of Big Data analysis, while MapReduce technology has the advantage of large-scale parallel processing. However, there are still a series of performance bottlenecks in the MapReduce processing model. Integrating DBMS and MapReduce technologies and designing technical framework of containing both advantages are the trends of Big Data analysis technology. Wang et al. [90] discuss the integration of DBMS and MapReduce technologies and propose a hybrid framework to solve the Big Data problem.
Some researchers use the locality characteristics of Big Data to optimize Hadoop. Hadoop cannot coordinately adjust the relevant data on the same configuration node, which is a main bottleneck for Hadoop system. Eltabakh et al. [91] present CoHadoop, a lightweight extension of Hadoop, which allows the application program to control the storage location of data and keeps the flexibility of Hadoop. The users do not need to convert the data format. It performs better than the algorithms based on redistribution and map-only algorithms. He et al. [92] proposed a new MapReduce scheduling strategy, Matchmaking, to enhance the data locality of Map tasks. It needs no complex adjustment of parameters compared to the similar algorithms. Meanwhile, it has better data locality and less response time. Xie et al. [93] introduce a prefetch mechanism in the MapReduce model while maintaining the compatibility with traditional Hadoop. When running data intensive applications on Hadoop clusters, a certain amount of data are automatically loaded into memory before being assigned to computing nodes to ease the data transmission overload problem through estimating the execution time of each task.
In order to support the applications that are not programmed by Java, a flow mechanism is introduced in Hadoop. It allows for communicating with external programs through pipeline. Due to the additional costs of pipeline communication and context switching, the performance of the Hadoop flow is significantly worse than the traditional Hadoop. Lai et al. [94] propose ShmStreaming to solve this problem, which can achieve a 20–30% performance improvement of Hadoop flow through sharing the memory.
Fault tolerance is one of the primary concerns of a cloud computing platform. When many clients require services to a server concurrently, the server may be overloaded and result in errors. The dynamic load balancing can be used to avoid this problem. Roy et al. [95] study how to enhance the efficiency of cloud computing through dynamic load balancing technology. They propose an algorithm based on the CPU utilization rate. When the rate is less than the given value, the client requests will be served. Otherwise, the requests will be transferred to other servers through the load balancer.
Chen et al. [96] propose a prediction-execution strategy to improve the task execution time and the cluster throughput of MapReduce. Premchaiswadi et al. [97] improve the performance of large-scale data processing by adjusting and optimizing the MapReduce operations. Adjusting the Hadoop configuration parameters can directly affect the performance of MapReduce workflow.
Rao et al. [98] study the improved scheduling strategies of Hadoop/MapReduce in cloud environments and present the optimization directions of Hadoop scheduling. Cherniak et al. [99] present a series of optimization methods for MapReduce. Based on data dependency, query optimization, and Hadoop workload, they can allocate the appropriate amount of resources to parallel Hive tasks.
In a traditional cloud system, the energy efficiency is not very good for the typical CPU-intensive, I/O-intensive, and interactive tasks. Song et al. [100] propose an energy efficiency model and the measurement methods in the cloud environments. They discuss the mathematical expressions, measurement methods, calculation methods, energy-efficient models, and the energy-efficient characteristics of typical operations in cloud computing. Kim et al. [101] study the evaluation of Hadoop optimization and discuss the upper and lower bounds of optimization effect by identifying the related factors.
9.7.2 Availability Optimization of Hadoop
He et al. [102] propose a distributed Hadoop/MapReduce platform named HOG (Hadoop on the Grid). To relive the unreliability of a grid in Hadoop, HOG can provide a flexible, dynamic MapReduce environment. Through transplanting the modified Hadoop components to the existing MapReduce applications in order to conduct the assessment, HOG can be successfully extended to 1100 nodes on the grid and achieve the same reliability as the special Hadoop cluster.
In default, the computing nodes in the Hadoop cluster are isomorphic. However, Hadoop may meet problems in heterogeneous environments. Zaharia et al. [24] study the task of scheduling optimization for MapReduce in the heterogeneous environments and design a LATE algorithm. This algorithm has high robustness and can reduce the response time. Xie et al. [103] improve the data placement strategy under the heterogeneous Hadoop cluster so that each node had a relatively balanced load of data processing. It uses the locality characteristic of data to improve the performance of MapReduce. Ahmad et al. [104] study the poor performance problem of MapReduce under the heterogeneous cluster and present Tarazu to optimize MapReduce in the heterogeneous cluster. Hansen et al. [105] optimize the Hadoop cluster through adjusting the parameter configuration and verify the performance improvement in the actual Hadoop clusters. In the Hadoop family, in order to solve the problem of the heavy load of jobtracker, the basic design idea of Yarn is to split the JobTracker into two separate services: a global resource manager ResourceManager and each application specific ApplicationMaster. In order to further improve the real time of large data processing, Spark is a fast and general engine for large-scale data processing.
In summary, Hadoop becomes an essential platform for Big Data processing. Optimizing the Hadoop system is a meaningful work. The current work focuses on combining Hadoop with DBMS to improve the performance by optimizing the scheduling efficiency of Hadoop with load balancing, predictive execution, and parameter adjustment, as well as improving the performance of heterogeneous Hadoop system.
9.8 Conclusions and Future Directions
Hadoop becomes the most important platform for Big Data processing, while MapReduce on top of Hadoop is a popular parallel programming model. This chapter discusses the optimization technologies of Hadoop and MapReduce, including the MapReduce parallel computing framework optimization, task scheduling optimization, HDFS optimization, HBase optimization, and feature enhancement of Hadoop. Based on the analysis of the advantages and disadvantages of the current schemes and methods, we present the future research directions for the system optimization of Big Data processing as follows:
1. Implementation and optimization of a new generation of the MapReduce programming model that is more general. The improvement of the MapReduce programming model is generally confined to a particular aspect, thus the shared memory platform was needed. The implementation and optimization of the MapReduce model in a distributed mobile platform will be an important research direction.
2. A task-scheduling algorithm that is based on efficiency and equity. The existing Hadoop scheduling algorithms consider much on equity. However, the computation in real applications often requires higher efficiency. Combining the system resources and the current state of the workload, fairer and more efficient scheduling algorithms are still an important research direction.
3. Data access platform optimization. At present, HDFS and HBase can support structure and unstructured data. However, the rapid generation of Big Data produces more real-time requirements on the underlying access platform. Hence, the design of the access platform with high-efficiency, low-delay, complex data-type support becomes more challenging.
4. Hadoop optimization based on multicore and high-speed storage devices. Future research should consider the characteristics of the Big Data system, integrating multicore technologies, multi-GPU models, and new storage devices into Hadoop for further performance enhancement of the system.