Spatial Privacy Challenges in Social Networks
Abstract
New technology supporting large-scale (big) data collection and associated data analytics is challenging personal privacy in unprecedented and unforeseen ways. Big Data is typically high volume, high velocity, heterogeneous, and distributed with varying degrees of veracity. Big Data can be created and collected by individuals, organizations, or external agencies, often with the aim of applying data analytics to improve services, products, or decision-making functions that can potentially add competitive advantages. The tools and infrastructure for supporting the capture and analysis of Big Data are widespread, for example, MapReduce and ElasticSearch are algorithms now taught at the undergraduate level that allow processing of extensive and heterogeneous data. Data analytics is increasingly being used to derive meaningful patterns from such data. However such approaches have a potential downside with regard to privacy. Social media is one example of Big Data that raises many challenges in terms of an individual’s privacy. Many consider that the privacy issues for data that is randomly posted by individuals in tweets, blogs, and through images onto the Internet are less important; however, many social media data sets contain extensive data that can reveal information that users may be unaware of, including their geospatial location. In this chapter we explore these issues, focusing especially on the challenges of privacy, with a specific focus on location privacy. We outline how Cloud infrastructures and related technologies can be used to explore and highlight the issues that can arise with the privacy of locations and the consequences of this on an individual’s privacy.
Keywords
Social media; Cloud; Privacy; Security; Geospatial; Location-based services; Big Data
Acknowledgments
The authors are grateful to the National eResearch Collaboration Tools and Resources (NeCTAR) project for the Cloud resources that were used in undertaking this work.
11.1 Introduction
New technology supporting large-scale (big) data collection and associated data analytics is challenging personal privacy in unprecedented and unforeseen ways. Big Data is typically high volume, high velocity, heterogeneous, and distributed with varying degrees of veracity [1]. Big Data can be created and collected by individuals, organisations, or external agencies, often with the aim of applying data analytics to improve services, products, or decision-making functions that can potentially add competitive advantages [2]. The tools and infrastructure for supporting the capture and analysis of Big Data are widespread, for example, MapReduce and ElasticSearch are algorithms now taught at the undergraduate level that allow processing of extensive and heterogeneous data. Data analytics is increasingly being used to derive meaningful patterns from such data. However, such approaches have a potential downside with regard to privacy. Social media is one example of Big Data that raises many challenges in terms of privacy. Many consider that the privacy issues for data that is randomly posted by individuals in tweets, blogs, and through images onto the Internet are less important; however, many social media data sets contain extensive data that can reveal information that users may be unaware of, including their geospatial location. In this chapter we explore these issues, focusing especially on the challenges of privacy, with a specific focus on location privacy.
11.2 Background
Social media data differs from other Big Data applications such as astrophysics since, by its very nature, it operates on personal/organizational information, and hence there are often significant privacy concerns [3]. The availability of information in social networks is commonplace and users are often unaware of just how much information they reveal when they use resources such as Twitter. A single 140-character tweet can contain 9 kb of metadata about the user, including their followers, their background, and potentially their location. To make matters worse, it is easy to find patterns in these data sets through data mining and exploitation of Big Data infrastructures. This can be done directly through the content of data, or indirectly from the metadata and geospatial information that is often associated with data. This is in an increasingly common phenomenon due to the ubiquity of mobile devices with location-based services that are now available. To illustrate this issue, consider the unforeseen use of Twitter data in Fig. 1 where individuals can be tracked through the day moving around Melbourne. Here, colour codes are used to represent the daily movements of individual tweeters and the height of the lines represents the time of day of the tweet. The contents of a given tweet are also displayed.
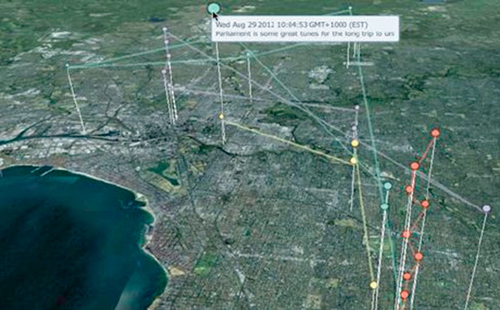
It could be argued that location-based information itself should be removed at the source, for example, by Twitter; however, there is an increasing demand to localise the aggregated analysis of such data. This can be true for real-time information on a variety of issues: congested transport routes around cities [4], using Twitter data as the basis for early warning health outbreaks (eg, avian flu, ebola virus outbreaks) [5], natural hazards (bushfires, earthquakes, floods) [6] amongst many other scenarios.
Despite the obvious privacy issues, Big Data and data analytics can provide significant benefits to society. A key element of this is increasing public understanding of the enormous growth in data collection and retention, borne in part by mobile technologies and the Internet-of-Things [7]. Society is becoming increasingly aware and suspicious of data collection techniques that exploit individuals’ own data for often undisclosed and/or unforeseen purposes. Some individuals may view the loss of privacy as giving away a few personal demographics; however, the aggregation of these resources can be used to profile individuals and society as a whole [8,9]. Furthermore, data analytics and visualization, and the use of large-scale computational infrastructures and algorithms now allow for probing far more deeply into personal privacy than ever before [10,11].
An investigation of social network users’ privacy management regarding their awareness of privacy issues and configurations of associated social media systems was carried out by Ref. [12] through a survey involving over 2000 randomly selected adults. The research revealed the complexity of different social network privacy settings, as half of users expressed difficulties in configuring the information access rules when using their social network privacy settings. It identified that the settings of some social networking solutions were “overly complex, ever-changing, and even obscure.”
It is now widely recognized that privacy issues are exacerbated in the Big Data era. A user’s privacy can be lost if he or she is tagged in an uploaded photo without his or her knowledge or permission. There are no privacy rules for dealing with such issues. Apart from the lack of awareness of losing privacy, [13] stated the (worrying!) ease of finding meaningful patterns in Big Data to predict one’s future behavior given the ubiquitous amount of analytic tools and the extreme richness of such information.
Rather than focusing on the social network itself, there are a number of researchers investigating the privacy of location-based services since increasing numbers of social networks have integrated geospatial content. Metrics accessing the location privacy issues, including the precision of positioning users, were suggested by Kang et al. [14]. In addition, Tang et al. [15] explored a number of means of privacy attacks and provided corresponding protection methods. The worryingly high number of location-based services and the threat to privacy was revealed by De Montjoye’s research [16]. They showed how it was possible to identify a person using just four spatiotemporal data points.
All of the aforementioned research presumes that the victim of information leakage is the end user—either an individual or organizational user of social networks using location-based services. Given the increasing capability for mining sensitive social network content and its associated location information, it is directly possible to draw patterns between the sets of information and reveal privacy information of certain locations and, hence, of individuals. One example of location privacy information is the usage of a certain building, for example, for scientific research, entertainment activity, or indeed to know what individuals in a specific household are doing. Losing the location privacy of a building obviously raises many issues, especially when linked with the users and/or usage of that building. Therefore, not only users but also locations need privacy protection, and there is a clear need for assessing the privacy issues regarding locations as well as the privacy of users and organizations. This is a different philosophy compared with the work on privacy thus far that has largely considered the individual whose rights might be violated; however, with the technologies and Big Data processing platforms now, it is actually the privacy that can arise out of a given location that is of concern. Thus, knowing what a given person tweets about is one thing, but knowing who has ever sent a tweet from a given building or indeed any specific location, for example, outside the Houses of Parliament in London, is another thing.
The chapter seeks to answer the following questions: in which form does location privacy occur when using social networks, including location-based services, and what is the consequence of this? As such, we first examine the feasibility of extracting social media content based on locations instead of users and then analyze how the extracted content may reveal the location identity, such as the name of the location, the general purpose of the location, or the events that might have happened in that location. The severity of spatial privacy issues will be assessed in terms of how critical the extracted information is and how losing spatial privacy can lead to privacy issues to users themselves.
11.3 Spatial Aspects of Social Networks
Exploring spatial privacy demands of social media through Big Data approaches implies that the social media content can be geolocated at a degree of accuracy and that large-scale data is available. Manually collecting such data is impractical, for example, by scraping web sites for data, hence open APIs to collect information (data) from the social network are essential. Let us consider an analysis of the APIs of different social networks. There are many potential social media software systems; however, here we focus on those that are mainstream and have known APIs. Specifically, we consider Google Plus, Facebook, Twitter, Instagram, and Flickr as representative of the wider social networking software systems for text, tweets, and images that are shared in vast quantities online.
Google Plus provides a representational state transfer (REST)-based API interface to perform basic create-read-update-delete (CRUD) operations on a given user’s personal information, comments, and activities [17]. There are limits imposed on the amount of daily API calls that can be made to the Google Plus API. Furthermore, the location-based query capabilities available through this API are limited to the scale of a city instead of an exact location, for example, down to the precise location of a building block. As such, Google Plus does not support disaggregated data harvesting that can be used to explore fine-grained location privacy issues.
Facebook offers a graph-based API that can be used to extract user information, including a users’ profile and his/her timeline/posts with location filters available [18]. However, the privacy policy of Facebook places constraints on use of this API such that the detailed information can only be extracted if the owner of the information is a friend of the API holder. For exploring location privacy issues for arbitrary individuals, this model does not satisfy the demand for large amounts of geospatially coded information.
Twitter provides a Streaming and a Search API that can be used to collect (harvest) tweets [19]. Importantly, users and developers can filter tweets based on a range of coordinate properties—typically through a bounding box, for example, tweets inside of a given set of coordinates, or a point/radius, for example, tweets within a circle of radius of 100 m from a given point. Tweets themselves can include an exact latitude/longitude (point) when the location-based service of the device is activated. If the location-based service is not activated, then the location is typically aggregated to the user’s profile information, for example, the user is from Melbourne, and therefore the tweet is identified as being sent from Melbourne. Twitter imposes a limit on the data rates and will blacklist accounts streaming tweets faster than approximately 120 tweets per minute. Nevertheless, through use of multiple Twitter developer accounts and the Cloud, it is possible to parallelize the harvesting of Twitter data to get Big Data.
Instagram provides a RESTful API that can be used to retrieve uploaded photos including their description, comments, and metadata such as tagged users [20]. Like Twitter, photos can be filtered according to their coordinate properties. All photos created within a 3-km radius from a given user-defined point can be retrieved. As such, Instagram does not provide the disaggregated level of data necessary for exploration of location privacy.
Flickr also offers a RESTful API, with limited features for location-based querying supported by the API [21]. The spatial aspects of social media networking software are summarized in Table 1.
Table 1
API Features of Different Social Networking Software
| SNS | API Type | Location Filters | Limitations |
| Google + | REST | Location name with the scale of city (eg, New York) | Numbers of daily requests are capped. Location filter is not precise |
| REST & SDKs supporting different languages | Location name precise to the scale of a building block | Only detailed information available to Facebook friends | |
| REST | Location name and coordinate filters available | Stream speed is capped; however location data can be very disaggregated | |
| REST | Location name and coordinate filters available | Location is only down to 3 km, which is not sufficient for many privacy aspects | |
| Flickr | REST | Not available | No geolocation information retrievable |

As seen, Twitter is the only social networking software that supports truly disaggregated spatial data that can lead to location privacy issues arising. This can be to a very specific latitude/longitude to within a few centimeters’ degree of accuracy [22]. This chapter thus focuses on the privacy challenges of social media data from Twitter.
11.4 Cloud-Based Big Data Infrastructure
To support Big Data processing and data privacy analytics on a global scale, large-scale and scalable infrastructure is required. Clouds provide an ideal environment for data processing and storage demands through their flexibility and scalability. However, the outsourcing nature of Clouds has its own privacy issues that can impact many domains [23]. Furthermore, there are many Cloud flavors [24], including Infrastructure-as-a-Service (IaaS), Platform-as-a-Service, and Software-as-a-Service offered by a multitude of providers such as Amazon, Microsoft, and others. Across Australia, the National eResearch Collaboration Tools and Resources (NeCTAR—www.nectar.org.au) project offers an IaaS platform based on OpenStack Cloud technology (www.openstack.org). Many researchers use the NeCTAR Research Cloud for a variety of data processing tasks, from climate research [25], humanities research [26], genomics research [27], through targeted clinical data collection and processing [28].
In the NeCTAR IaaS model, researchers can request computing resources, including processors and Cloud storage, on demand. There are approximately 30,000 physical servers that are currently available through NeCTAR. These resources are distributed across eight sites throughout Australia. These are offered as availability zones to researchers who are to select the site/resources that best fits their needs. A variety of Cloud resource types are available from large-scale virtual machines with 64 Gb memory through small VMs with 4 Gb memory. Data storage is available from projects such as the Research Data Services project (RDS—www.rds.edu.au), which makes available multipetabytes of data storage to Australian researchers. The NeCTAR project itself is led by the University of Melbourne.
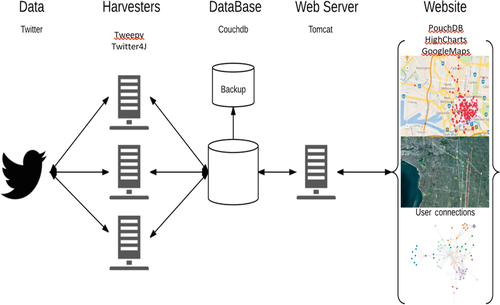
In collecting social media data for location privacy exploration, it is essential that extensive amounts of tweets are collected. Twitter offers APIs that allow access to streamed tweets or for targeted searches, for example, tweets from a particular user. Importantly, Twitter supports ongoing connections from Twitter clients (harvesters) and the API. This model supports continued harvesting of data. A range of existing libraries in Python and Java are freely available for accessing and using data from Twitter. At present, over 65 million tweets have been harvested on the NeCTAR Cloud for the cities of Australia and are used for a range of scenarios in a variety of projects at the University of Melbourne. This resource continues to grow—a key element of the scalability and flexibility offered by the Cloud.
The tweets themselves (and their metadata) are stored as JSON documents in a noSQL database. There are many noSQL solutions that are now available. CouchDB and CouchBase are two leading noSQL solutions [29]. CouchDB is an open source, non-SQL database dedicated to crossplatform, efficient data processing. All documents are stored in JSON format and RESTful APIs are provided to CouchDB as a consistent interface in performing CRUD operations on documents. CouchDB utilizes MapReduce in generating views of the data. All views are embedded in a B-tree structure for the sake of fast retrieval of data. Such features make CouchDB an ideal solution for storing and processing large amounts of semistructured documents such as tweets on the Cloud.
Twitter APIs cap the streaming rate and can make it challenging for harvesting large amounts of Twitter data through a single developer account to a single machine. To tackle this, multiple harvesters running on the Cloud can be used—each associated with their own Twitter developer account and with their own IP address. It is important to note that there can be many harvesters running continually and in parallel. To support the continuous data collection and indexing for rapid searches, ElasticSearch can be used.
It is also the case that visualization of data is an essential component of Big Data analytics. The ability to visualize data can help shed insight and, indeed, highlight issues with privacy as illustrated in Fig. 1. To accommodate this, PouchDB [30] and a range of Javascript libraries have been adopted. PouchDB is an open source in-browser database with a JavaScript interface. PouchDB offers features for synchronizing data with remote CouchDB servers. As such, PouchDB can be utilized as a JavaScript library for dynamically creating data views according to user requests. This functionality overcomes a limitation of CouchDB and its realization of MapReduce, since the mapping function does not take parameters as inputs.
Other libraries that are used for data visualization include the High Chart API, which makes use of a distributed object model and supports JQuery capabilities to generate graphical results of analyses. This API is useful when analysis such as comparing and contrasting the number of tweets generated in different time periods is required.
Given that geospatial privacy is of concern here, the ability to collect, analyze, and visualize data based on its geospatial location is essential. The system utilizes the GoogleMaps API for this purpose, but we note that a range of other solutions are available, for example, OpenStreetMap [31].
The architecture for the Twitter harvesting, processing, and visualization is shown in Fig. 2. As noted, there can be multiple harvesters that are used for continually harvesting Twitter data on the Cloud. These harvesters can be pointed to certain locations, for example, Melbourne, or as identified in Table 1, by selecting a much more disaggregated region, for example, the tweets from a specific location.
It should be noted that the web application provides the interface to the system and supports the majority of the functionality offered by the system. The primary function of the web interface is to allow users to draw a bounding box on a map and retrieve tweet contents inside the region by creating views on the CouchDB according to the coordinates of the vertexes of the bounding box as shown in Fig. 3. For experimental purposes, the web application should also have the following features in addition to bounding-box based tweet retrieval:
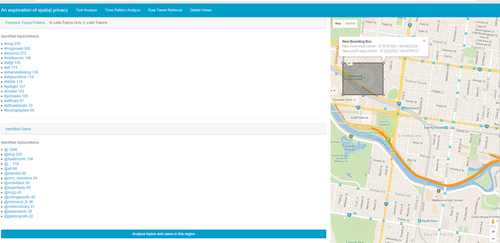
• Being able to filter tweets containing certain keywords;
• Being able to perform accumulative analyses, for example, the amount of tweets created over certain time periods;
• Finding tokens beginning with “#” and “@” in the content of tweets to identify the frequent topics and active users inside a region based on the term frequencies.
The server side of the web application uses CouchDB and makes use of the MapReduce architecture for parallel dataprocessing and hence is significantly faster in terms of computation power compared with browsers on the client side. Hence, the web application follows the “thin client” paradigm to allocate most of the computation, including splitting tweet contents into tokens, and preprocessing the tokens by removing non-ASCII characters, to name but a few activities in the MapReduce task of CouchDB. This avoids long-running scripts affecting the functionality of the browser. However, jobs such as sorting the term frequencies cannot be done through MapReduce and have to be executed on the client side since MapReduce produces key-value pairs in random order. Fortunately, the execution time of sorting the list of term frequencies is insignificant compared with the time taken for retrieving and processing large amounts of tweets on the server side.
11.5 Spatial Privacy Case Studies
As described previously, we wish to explore a range of questions related to location privacy:
• How can a location lose privacy?
• How easily can we reveal location privacy?
• What are the potential consequences of a loss of location privacy?
It is obvious that location privacy can be easily given away as shown in Fig. 1. If location-based services are used, then the privacy of an individual’s exact location is immediately available. Users (tweeters) may be fully conscious of this and happy to release such data; however, other users may simply be unaware of exactly how much data they are releasing. The question arises, how are those users actually identified in the first place? Location privacy is one common route to discovering such individuals.
Given the general definition of privacy as the right of both being free from secret surveillance and regulating rules of accessing personal/organizational identity [32], a possible definition of a location losing privacy might be “actively revealing a location’s identity.” The obvious identity of a particular location includes the location name, the location’s usage, for example, is the location used for business activities or recreational activities, and the events that may have happened or be happening inside the location. Answers to the first two bullet points can be addressed by checking the feasibility and measuring and/or inferring the use of a certain location through the events that happen inside that location (based on the content of tweets generated inside the region). The third bullet point can be explored by finding scenarios where losing the location’s privacy essentially results in a loss of personal privacy. The process of exploring these issues is as follows:
• Harvest as many tweets from Twitter as possible for analytical use, including support for real-time data acquisition;
• Support (localized) location-based queries through the web application;
• From the retrieved results, perform accumulative analysis, including identifying the frequent topics, finding time patterns occurring at those locations;
• Identify patterns between the location identity and the identities of users inside the region, and
• Explore the consequences of the loss of location identity for users that might have been present in that location.
Observing frequent tweet topics inside a region is an effective way of inferring what the location is used for; however, this can require huge amounts of current and historic data. Indeed, the volume of data required is one of the major barriers in identifying the usage of location. Many consider that the volume of data that is now being created can allay privacy concerns. To explore this issue, we consider a scenario based on the major sporting venue in Melbourne: the Melbourne Cricket Ground, as shown in Fig. 4. Over 100,000 tweets were collected from the MCG. As can be seen, the tweets include a range of hashtags that correspond to sporting events and the location itself, for example, #MCGcrowd and #AFL (Australian Football League). Thus, the identity of use of this location can be identified solely by the tweets that are harvested from that location. This is unsurprising for a location like the MCG, but it is key to understanding location privacy. We can identify what a given location is used for, just by obtaining tweets from that location. We may not have known that this was a sporting location, but from analyzing the data we can establish this.
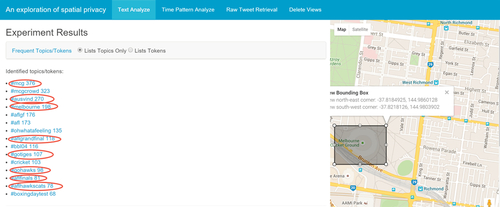
In relation to less obvious and more disaggregated locations, we consider a scenario based on student accommodations available at the University of Melbourne. Many students, and especially international students, stay in accommodations that are close to the University, for example, UniLodge on Swanston Street. Through harvesting Twitter data from those locations as shown in Fig. 5, it is possible to identify that these are indeed student accommodations. Many of the tweets are made with non-English language settings, for example, Chinese, so it is possible to establish the ethnic background of the individuals that are staying in this accommodation. Obviously, for smaller regions/locations, a reduced amount of tweets is available, but through machine learning algorithms and suitable known (training) data, it is possible to exploit analytical software to determine what the location is used for with increasing degrees of accuracy.
In this regard, case studies based on automatically identifying locations based on the frequencies of tweet content through machine learning approaches were explored. In all of these scenarios, data was collected through querying stored views in CouchDB to count the occurrences of words from particular regions. Detailed analysis in terms of the feasibility of automatically tagging a location’s usage and events using machine learning based on other known regions requires creation of associated classifiers.
In supporting this, a range of general classes were used to represent the usage of locations, for example, the class “Sports” covers all locations used for any sports events, regardless of whether the location is a stadium or a fitness center. The work began with a manual task where tweets from locations with known usages were revealed and representative attributes judged manually based on raw term frequencies. Once this training data set was created, it could be compared with the results from the machine learning algorithms. In undertaking this, the Weka software was used. [33]. It is noted that this supervised approach is only one possibility, and unsupervised machine learning can also be considered. Table 2 illustrates some sample comparisons between the expected class and the class assumed by Weka using a K-nearest neighbor algorithm [33] from which the classifier accurately reveals the location usage—despite the absence of formal feature selection processes using criteria such as F-scores and the often small size of the data sets [34].
Table 2
Example Outputs of the Classifiers
| Location Name | Expected Output | Actual Output |
| Etihad Stadium | Sports | Sports |
| Melbourne Cricket Ground | Sports | Sports |
| Bourke Street Mall | Entertainment | Entertainment |
| Melbourne Convention & Exhibition Centre | Business | Entertainment |
| Rod Laver Arena | Sports | Entertainment |
| Alice Hoy Building @ UniMelb | Study | Study |
| Baillieu Library @ UniMelb | Study | Study |
| UniLodge @ Swanston Street | Apartment | Study |
| Arrow on Swanston | Apartment | Apartment |
It should be noted that incorrectly classifying the expected use of a location does not necessarily mean that the classifier is wrong. Rather, it can provide important information revealing some “hidden” usages of a location. For example, one reason for classifying “UniLodge on Swanston Street” as a study area instead of apartments is that most individuals inside the region are students and tend to tweet about their studies. Hence, such instances can also be classified as a study area or indeed as University accommodations. As such, although the model in the experiment might be highly biased due to the absence of in-depth feature selection and the small training set with (presumably) over-generalized classes, the fact that the classifier yields a high degree of correctness in classifying unexpected classes can reveal important information regarding the location identity and use. It can therefore be concluded that using location usage can indeed be predicted without contextual knowledge and as such is a serious privacy issue.
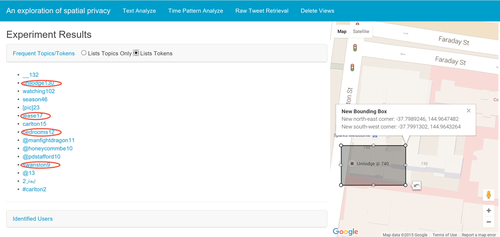
It might be considered that the knowledge that a location is used for sports or entertainment is not a major privacy concern; however, extending the system and scenarios can reveal potentially more sensitive location details, for example, identifying police stations or Australian defense locations and the individuals who might work there. Fig. 6 provides an example revealing “bioinformatics research” that is currently ongoing at the Walter and Eliza Hall Institute (WEHI). Events inside the location, such as research projects and the staff working on such projects, can reveal information that may disclose too much information and potentially be revealed to competitors.
It is noted that individuals may follow formal accounts for organizations, such as WEHI and others; however, the issue is that any staff member can tweet using their own account, and by identifying that this took place within WEHI, such information can be identified directly and associated with activities ongoing within WEHI. The small numbers of topic occurrences shown in Fig. 6 suggest that staff from WEHI have a high level of compliance regarding their code of conduct, and prevent information leakage by not sending tweets related to their work. However, the fact that the building’s usage is identified by analyzing tweets suggested that even small numbers of tweets relevant to the inside events can be critical in identifying the location’s usage and location privacy, and potentially result in negative consequences.
The seemingly harmless practice of revealing a nonconfidential location usage, as mentioned previously, may result in negative circumstances, especially if patterns are drawn between the location and the users identified in that region, for example, identifying policemen from a given police station can be used to subsequently track them as illustrated in Fig. 1. Furthermore, occupational and other interests can be inferred from location information, with some representative examples given as follows.
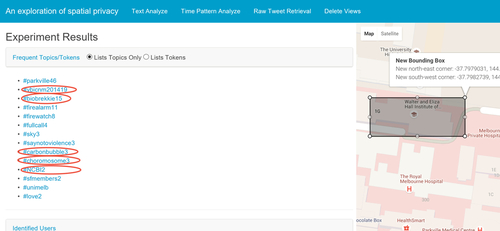
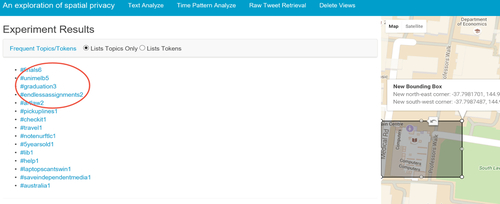
According to the frequent tweet topics from the University of Melbourne Baillieu Libraries shown in Fig. 7, all users identified inside the region can be assumed to be University of Melbourne students working on coursework programs, as the name of the university is revealed on the topics and the terms “assignments” and “finals” negate assumptions that non-Melbourne students are using these facilities.
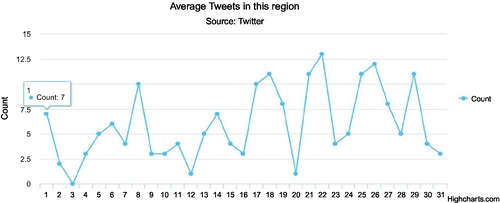
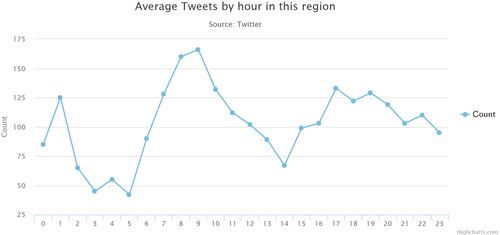
Furthermore, a more accurate prediction of the identified users’ behavior in given locations may be undertaken when analyzing temporal patterns in the data. Fig. 8 shows the amount of tweets made in Aug. 2015 from several study areas at the University of Melbourne, which reveals that the amount of tweets in the second half of the month generally overwhelms the figure in the first half, indicating approaching deadlines for assignments.
Again, this in itself is not a major privacy issue; however, when applied to residential locations, this can become a serious privacy issue. To demonstrate this, we consider the time distribution of tweets from a residential area of a suburb of Melbourne: Fitzroy. As seen in Fig. 9, there is a drop in the amount of tweets at 2 p.m. The discovery suggests that some houses inside the residential area are likely to be empty. The exposure of the resident’s possible daily schedule may be disastrous if such information is made known to potential thieves. It is quite possible to look at increasingly disaggregated data, for example, the social media use inside of a given house, but this was not explored for obvious ethical and security issues. The same capabilities in harvesting and analyzing data can be down to extremely disaggregated levels, for example, the rooms in a house!
In spite of these scenarios showing the severity of consequences of losing location privacy, it can be the case that performing tweet retrieval based on location can be beneficial despite the privacy issues, for example, for pandemics or other national disasters. To explore this issue, an analysis was undertaken in testing the feasibility of using the contents of geotagged tweets as a data source for applications that use such data to provide services. A heavily simplified application whose function was to retrieve tweet texts regarding an input topic within a bound-box was made for the purpose of stimulating the system providing location-based information, and observing whether the text provided information regarding the topic. The result was promising, as most retrieved texts contained detailed descriptions of certain events, which could possibly be useful for others. For example, tweets regarding traffic information from the city entrance of the freeway, detailed reporting of traffic events are shown (Fig. 10). Such observations suggest potential benefits of using geotagged tweets despite the potential privacy issues.

11.6 Conclusions
Privacy is of increasing concern for many people in the digital, and especially in the social media age. Many individuals use social media as a daily part of their lives. In this chapter we have explored the dangers of erosion of privacy and illustrated how seemingly innocuous information can reveal extensive privacy information related to the use and the activities taking place in that location. We have shown how Big Data infrastructures and technologies can now easily exploit geocoded information to reveal patterns in data that might otherwise have been lost in the noise. The scenarios demonstrated in this chapter have shown how locations can be automatically classified and how individuals can be identified from within those locations. The real danger in this is that once identified, the Big Data technologies now allow users to be tracked thereafter. As shown in Fig. 1, it is a quite straightforward process to track individuals and their use of social media.
Correlating the time of the events and other activities that might take place at those locations at that time might have benefits, for example, in the case of a national pandemic and being able to track who might have been infected; however, it is equally possible to use this data for other purposes which have grades of concern for many regarding personal privacy. Thus, should police be able to identify potential criminals or witnesses of crimes by correlating crime incidents with sources such as Twitter? The concerns of many are that such things are already happening without recall to privacy concerns of the unwitting individual. It is certainly the case that technology has far outpaced the legal frameworks that need to be in place to counterbalance the possibilities of data use and misuse. This is especially challenging given the global nature of the Internet and social media more generally.