Security and Privacy in Big Data
Abstract
In the Big Data era, it is more and more important and challenging to store massive data securely and process it effectively. Generally, Big Data is processed and queried on the cloud computing platform. Cloud computing can provide various elastic and scalable IT services in a pay-as-you-go fashion, but also it brings privacy and security problems. Additionally, adversaries can utilize correlation in Big Data and background knowledge to steal sensitive information. But the data correlations in Big Data are very complex and quite different from traditional relationships between data stored in relational databases. So it is more and more challenging to ensure security and protect privacy in Big Data. In this chapter, we will discuss important security and privacy issues about Big Data from three aspects. One is secure queries over encrypted cloud data; the second is security technology related to Big Data; the last is the security and privacy of correlative Big Data.
Keywords
Encrypted data; Correlated data; Security; Secure search; Privacy; Big Data; Cloud computing
12.1 Introduction
The term “Big Data” refers to the massive amounts of digital information companies and governments collect about us and our surroundings. Human beings now create 2.5 quintillion bytes of data per day. The rate of the data creation has increased so much that 90% of the data in the world today has been created in the last 2 years alone. How to securely store these massive data and how to effectively process them have been more and more important and challenging tasks. An effective method is for institutions to adopt the emerging cloud computing commercial service schema to outsource their massive data sets at remote cloud storage and computing centers. On the other hand, authorized data users can utilize the powerful computation capability of the cloud sever to search and process data. For example, a hospital creates vast data sets of patients’ medical records every day, such as EMR (electronic medical records) including X-rays, electrocardiograms, clinical histories, and so on. Facing such a huge amount of data files, hospitals have to resort to third-party data storage and management centers to maintain the massive data sets. Later, authorized physicians can search and obtain individual records through public communication channels.
Generally, Big Data is processed and queried on the cloud computing platform (Fig. 1). Cloud computing, the new term for the long-dreamed of vision of computing as a utility, enables convenient, on-demand network access to a centralized pool of configurable computing resources that can be rapidly deployed with great efficiency and minimal management overhead. The amazing advantages of cloud computing include: on-demand self-service, ubiquitous network access, location-independent resource pooling, rapid resource elasticity, usage-based pricing, transference of risk, etc. Thus, cloud computing could easily benefit its users in avoiding large capital outlays in the deployment and management of both software and hardware. Undoubtedly, cloud computing brings unprecedented paradigm shifting and will be a major part of IT history, especially the Big Data era.
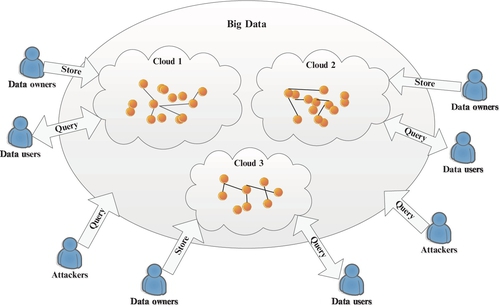
Cloud computing can provide various elastic and scalable IT services in a pay-as-you-go fashion; however, once the massive data sets are outsourced to a remote cloud, the data owners would lose direct control of these data, which raises a major concern of using the cloud—data privacy and security problems. Gartner listed seven security issues in cloud computing and claimed that 85% of large companies refuse to adopt cloud computing just due to data security. For example, the hospital may be reluctant to outsource their data to the cloud because EMRs contain a huge amount of confidential sensitive information that patients are reluctant to publish, such as information about one’s lifestyle, medical history, history of drug allergies, etc. To effectively solve the data security problem and promote the development of cloud computing, the Gartner Group thinks that an encryption scheme must be available to protect the outsourced cloud data, which should be encrypted before uploading it to the cloud. However, data encryption makes cloud data utilization a very challenging problem. In particular, performing a data search is a key challenge because the encrypted data disable the traditional plaintext keyword query. Thus, enabling an encrypted cloud data search service is of paramount importance.
In addition, adversaries can also utilize correlations in Big Data and in background knowledge to steal sensitive information. There are some existing technologies that are designed to prevent adversaries from stealing sensitive information from relational data. But the correlation in Big Data is quite different from the traditional relationship between data stored in relational databases. Correlation in Big Data does not imply causation. Causality means A causes B, where correlation, on the other hand, means that A and B tend to be observed at the same time. These are very, very different things when it comes to Big Data; however, the difference often gets glossed over or ignored, so sensitive information will be exposed and in more danger.
Based on the previous description, in this chapter, we will discuss important security and privacy issues about Big Data from three aspects. One is secure queries performed over encrypted cloud data; the second is security technology related to Big Data; the last is the security and privacy in correlative Big Data. The rest of this chapter is organized as follows. In Section 12.2, we introduce the related topics of secure queries in cloud computing, including system models, security models, and outstanding secure query techniques. In Section 12.3, we introduce other Big Data security, including data watermarking and self-adaptive risk access control. In Section 12.4, we comb the related research about privacy protection on correlated Big Data. This research is divided into two categories, including anonymity and differential privacy. At last, we propose future work in Section 12.5 and conclude this chapter in Section 12.6.
12.2 Secure Queries Over Encrypted Big Data
12.2.1 System Model
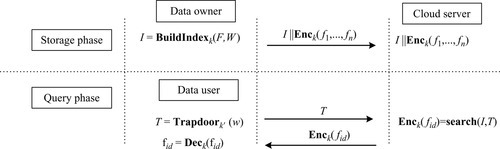
The popular secure query architecture with privacy protection in cloud computing involves three entities: the data owner, data users, and the cloud, as shown in Fig. 2A. The system framework expresses the following application scenario: the data owner decides to employ the cloud storage service to store massive data files, which are encrypted with the guarantee that no actual data contents are leaked to the cloud. On the other hand, to enable an effective keyword query over encrypted data for data utilization, the data owner needs to construct confidential searchable indexes for outsourced data files. Both the encrypted file collection and index are outsourced to the cloud server. An authorized data user can obtain data files of interest by submitting specified keywords to the cloud. The query process includes the following four steps. First, the data user sends query keywords of interest to the data owner via secret communication channels. Second, upon receiving query keywords, the data owner encodes these keywords to generate a query token in the form of ciphertexts and then returns it to the authorized user via the same secure channels. Third, the data user submits a query token to the cloud server to request data files via the public communication channels, such as the Internet. Fourth, upon receiving the query token submitted by the data user, the cloud server is responsible for executing the search algorithm over the secure index and returns the matched set of files to the user as the search result.
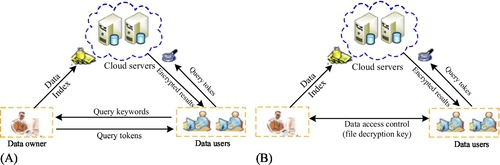
A fatal drawback of this architecture is that the data owner must always be online to handle query requests of authorized users. If the data owner is offline, outsourced data cannot be retrieved in time. To improve the availability, an enhanced system architecture is proposed as shown in Fig. 2B.
In Fig. 2B, there is an important difference compared with Fig. 2A: data users can encode keyword(s) to query tokens locally using keys assigned by the data owner through data access control. Queries are performed independently of the state of the data owner. Consequently, the improved system model more rigidly protects user query privacy, eliminates real-time communication overhead, and greatly enhances the availability and scalability of the whole system.
12.2.2 Threat Model and Attack Model
In this section, we introduce the threat model and attack model based on the aforementioned secure query model for cloud computing.
(1) Threat Model
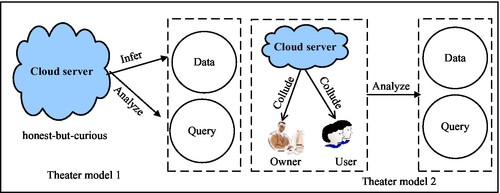
Since the massive data set is stored at a remote cloud center, the cloud may not be fully trusted for the following reasons. First, clouds may be vulnerable to corrupt employees who do not follow data privacy policies. Second, cloud computing systems may also be vulnerable to external malicious attacks, and when intrusions happen, cloud customers may not be fully informed about the potential implications on the security of their data. Third, clouds may base services on facilities in some foreign countries where privacy regulations are difficult to enforce. Based on these facts, generally, the cloud server is considered an “honest-but-curious” semitrusted threat model. More specifically, the cloud server acts in an “honest” fashion and correctly follows the designated protocol specification and promises that it always securely stores data and performs computations. However, the cloud server may intentionally analyze contents of data files, or curiously infer the underlying query keyword(s) submitted by the data user. Recently, besides the cloud, researchers have begun to consider some internal adversaries such as a malicious data owner or a compromised data user in the multiowner and multiuser cloud environments, such that the cloud can collude with these internal adversaries to analyze useful information of data files and query keyword(s). Fig. 3 shows the two threat models in cloud computing.
(2) Attack Model
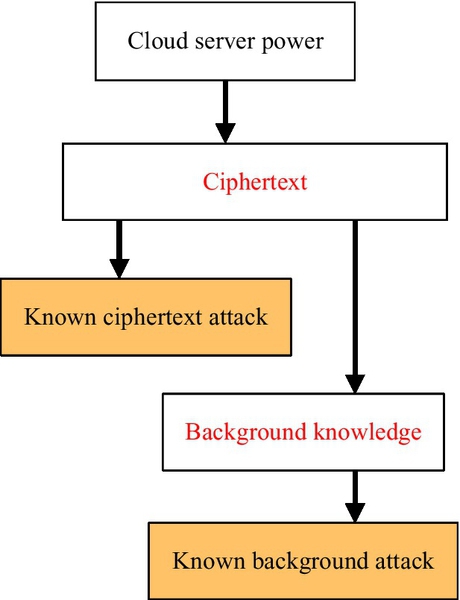
In addition to the threat model, based on what information the cloud server knows, secure query schemes in the cloud environment mainly consider two attack models with different attack capabilities; they are the Known Ciphertext Model and Known Background Model [1,2]. In the Known Ciphertext Model, the cloud is only permitted to access the encrypted data files and the searchable secure indexes. In the Known Background Model, as a stronger attack model, the cloud server is supposed to possess more background knowledge than what can be accessed in the Known Ciphertext Model. This background knowledge information may include the keywords and related statistical information, correlation relation of different data sets, as well as the correlation relationship of given search requests. For example, the cloud server could use the known query token’s information combined with previous query results to deduce the plaintext information of certain keywords in the query. Fig. 4 shows the two attack models.
12.2.3 Secure Query Scheme in Clouds
In fact, as early as 2000, Song et al. set out to research the problem of how to correctly perform a search over an encrypted document via encrypted keywords, and first introduced a practical technique that allows a user to securely perform a search over encrypted documents through specified keywords [3]. In 2006, Curtmola et al. formally named this query technique “searchable encryption (SE)” and presented explicit security requirements and definitions [4]. Meanwhile, they adopted the inverted index data structure [5] (which is widely used in the plaintext information retrieval fields), symmetric encryption schemes [6], and hash table to design a novel searchable encryption scheme named SSE (searchable symmetric encryption). The key goal of an SSE scheme is to allow a server to search over encrypted data on behalf of data users without learning any useful information about the data files or the query contents of data users other than encrypted query results.
The recent rapid development of cloud computing and the sharp increase in organizational, or, enterprise business data, has necessitated that the data outsourcing service model promote further study on secure searches in the cloud computing environment. Researchers have proposed many secure schemes to improve query efficiency, enrich query functionalities, and enhance security. In these secure query schemes, the encrypted searchable indexes are constructed by the data owner, through which an authorized data user can obtain qualified data by submitting encrypted keyword(s) to the cloud.
We will introduce secure query techniques based on the index construction in the symmetric encryption setting in this section. (Note that some public key-based secure query schemes are also proposed by researchers [7], however, which are not suitable for the massive data collection in the cloud environment due to the much more expensive computation overhead of the asymmetric encryption.)
We assume that the data owner owns the file set F = {f1, f2, …, fn} and extracts a set of keywords W = {w1, w2, …, wn} from F. To realize an effective secure query scheme, the data owner constructs an encrypted searchable index for F by invoking an index generation algorithm called BuildIndex when taking as input a secret key K. In addition, the file set F should be encrypted for data confidentiality using an algorithm called Enc with the other key K´. Generally, the semantically secure symmetric encryption scheme DES or AES is a very good choice for Enc. Finally, the encrypted data files and encrypted indexes are stored on a remote cloud center in the following form:
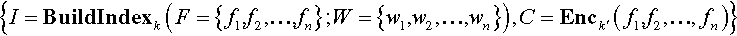
When an authorized data user wants to search data files that contain a certain keyword w, he/she invokes the algorithm Trapdoor under the same key K used to encrypted the index I to generate a so-called trapdoor (ie, query token) T = Trapdoork(w) and submits T to the cloud via public communication channels. With T, the cloud can search the index using an algorithm called Search and returns corresponding encrypted data files. Finally, the data user uses the algorithm Dec and takes as input the symmetric encryption key K´ to decrypt query results. Fig. 5 shows a general model of an index-based searchable encryption scheme in the cloud computing environment.
We formally give the definition of an index-based secure query scheme for cloud computing.
12.2.4 Security Definition of Index-Based Secure Query Techniques
The definition of secure query schemes in Section 12.2.3 indicates that the security of outsourced data files itself can be easily achieved due to the semantically secure AES or DES encryption. However, the cloud server may infer actual contents of the data files by attacking searchable indexes, since indexes are often embedded in useful information in data files. So, constructing semantically secure searchable indexes should be the most key security goal for an index-based secure query scheme. How to define the security of indexes? In Ref. [8], Eujin-Goh formally proposed the semantic security against adaptive chosen keyword attack (IND-CKA) security definition, which has been widely adopted in prior secure query schemes.
Simply speaking, when given two data files F1, F2 and their indexes I1 and I2, if the adversary (ie, the cloud server) cannot distinguish which index is for which data file, we say the indexes I1 and I2 are IND-CKA secure. In other words, the IND-CKA security definition guarantees that an adversary cannot deduce and obtain any useful plaintext information in data files from the searchable index.
12.2.5 Implementations of Index-Based Secure Query Techniques
In this section, we will introduce two effective and efficient query techniques over the encrypted data files, which have been widely used in cloud computing environments. One is a single-keyword secure query scheme based on the encrypted inverted index structure, and the other is a multikeyword secure query scheme based on the encrypted vector space model.
An efficient single-keyword secure query scheme
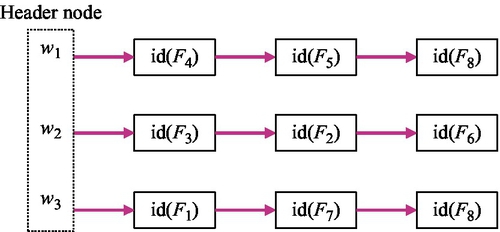
In Ref. [4], Curtmola et al. constructed an efficient single-keyword secure query scheme based on encrypted inverted indexes. In practice, the inverted index is widely used to perform the keyword search in the plaintext retrieval information system due to the simplicity of the construction and the high search efficiency. To the best of our knowledge, almost all modern search engines take advantage of the inverted index technique to design their internal index constructions. Fig. 6 shows a simple inverted index structure. In this construction, a linked list Li is used to represent a search index for a keyword item wi. In each Li, the header node HNi stores the specified keyword information wi and every intermediate node Ni,j stores the identifier of a data file that contains wi. For simplicity, Fig. 6 shows a simple index structure in which there are three keywords w1, w2, w3 and eight data files F1–F8.
Obviously, directly storing the inverted indexes to the cloud server in the plaintext form would cause inevitable information leakages because the cloud can see all plaintexts. To avoid gaining information from inverted indexes for any underlying attacker, Curtmola et al. used the symmetric encryption technique to encrypt inverted indexes and made them confidential while maintaining efficient searchable capabilities [4].
Now, we first introduce the proposed index encryption technique and make the indexes demonstrated in Fig. 7 secure, step-by-step, and then illustrate how to perform searches on these encrypted indexes with a simple example.
For ease of understanding, we introduce the implementation details of the index encryption technique by dividing the encryption processes into the following three steps.
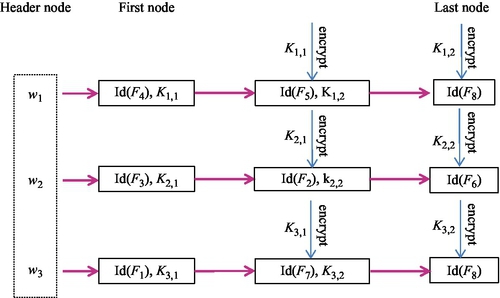
(1) Encrypt Nodes Except for the Header Node and the First Node
For a linked list Li of the distinct keyword wi, except for the header node HNi, each node Ni,j consists of three fields: the identifier of the data file containing the keyword wi, a pointer to the next node, and a random key Ki,j that is used to encrypt the next node. The pointer field and key field of the last node are set to be null and 0, respectively. Next, except for the first node Ni,1, each node Ni,j is encrypted by the key Ki,j − 1 using a semantically secure symmetric encryption scheme such as AES or DES. Fig. 7 shows the aforementioned encryption processes.
(2) Construct the Header Node and Encrypt the First Node
The header node of each linked list Li corresponding to the keyword wi contains two fields: the first field stores a random key Ki,0 that is used to encrypt the first node Ni,1, and the second field is a pointer to the first node Ni,1 in Li. Thus, the first node Ni,1 can now be encrypted by the key Ki,0. Now, except for the header node HNi, each node in Li is encrypted with a different key stored at the corresponding previous node.
(3) Encrypt Header Node and Create Encrypted Look-Table
Obviously, the header node still discloses the key information Ki,0 for Li, by which the cloud can decrypt all nodes of Li and make the index very easy to crack. To hide the header node information while keeping searchability, the proposed scheme uses an encrypted look-up table T to store the encrypted header node information. We use HNi = (Ki,0, addr(Ni,1)) to denote the header node of Li, where addr(Ni,1) represents the pointer or address of the first node Ni,1 in Li. To make the header node secure, and to protect the key Ki,0, the scheme uses a pseudorandom function [6] f with the key k2 to calculate the keyword wi as f(k2, wi) and then encrypt the header node HNi = (Ki,0, addr(Ni,1)) by computing f(k2, wi)⊕ HNi, where ⊕ is an exclusive or operation. Next, the scheme generates a look-up table T and uses another pseudorandom function π with the key k1 to calculate the keyword wi as πk1 (wi) and stores the encrypted header node f(k2, wi)⊕HNi to the corresponding position T[π(k1,wi)] in T.
So far, according to these three steps, the linked list Li of keyword wi has been totally encrypted. In the next section, we will give a simple example to illustrate how to perform a query on encrypted indexes. Fig. 8 shows a simple example of a head node encryption and look-up table structure.
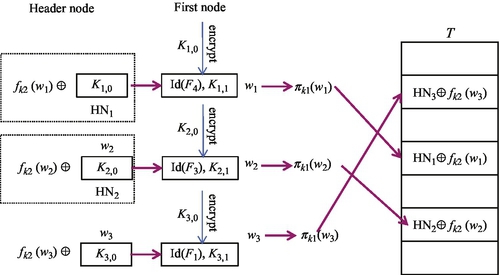
Last, we provide a secure search example. Suppose that a data user wants to search data files containing the keyword w2, he/she first encrypts the query keyword w2 using the keyed hash functions f and π to generate a query trapdoor as trap = (πk1(w2), fk2(w2)) and submits the trap to the cloud server. Upon receiving the trap, the cloud accesses the look-up table T and takes the encrypted value val = HN2 ⊕ fk2(w2) from the position T[πk1(w2)] and then decrypts the header node HN2 by calculating val ⊕ fk2(w2). Last, the cloud decrypts the whole linked list L2 starting with the header node HN2 and outputs the list of data file identifiers in L2.
An efficient multikeyword secure query scheme
Obviously, the inverted index-based secure query scheme efficiently supports a single-keyword query, which needs to perform multiple rounds of queries to implement a multikeyword conjunction query. In this section, we will introduce an efficient multikeyword query scheme based on the encrypted vector space model. The scheme can effectively perform multikeyword ranked and top-k secure queries over the encrypted cloud data.
The basic idea behind the query scheme is to use an n dimension binary data vector to represent a query index of a data file. In a multikeyword query, the query is also denoted as an n dimension binary vector; meanwhile, the query operation is converted into the inner product computation between the query vector and each file index vector. In this scheme, one can determine which data files are more relevant than others by sorting the inner product values in descending order to implement a multikeyword ranked and top-k query.
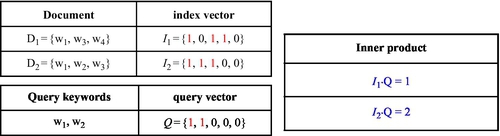
We first provide a simple example to illustrate how to create the data file index vector, the query vector, and how to perform a multikeyword ranked query in the plaintext setting. For ease of understanding, we assume that there are two documents D1 (containing three keywords, w1, w3, and w4) and D2 (containing three keywords, w1, w2, and w3), which are denoted as D1 = {w1,w3,w4} and D2 = {w1,w2,w3}, respectively. To create the n dimensions binary vector indexes for D1 and D2, the scheme needs to predefine a keyword dictionary consisting of n keywords, denoted as W = {w1,w2,w3,w4,w5} (For simplicity, we set n = 5). The binary index vector I of the data file D can be created according to the dictionary W as follows: if wi (1 ≤ i ≤ 5) in W appears in the data file D, the corresponding ith position is set to be 1; otherwise, the position is set to be 0. Thus, the five-dimension vector indexes of D1 and D2 can be denoted as I1 = {1,0,1,1,0} and I2 = {1,1,1,0,0}, respectively. Suppose that a data user uses the keywords w1 and w2 to request data files, the query is also converted into a five-dimension query vector by adopting the same method, denoted as Q = {1,1,0,0,0}. Now the query is performed by computing the inner product between the query vector and each data index vector. In this example, I1∙ Q = 1 and I2∙ Q = 2, which indicates D2 is more relevant than D1. If this is a top-1 query, the D2 should be regarded as the only query result.
We can observe from Fig. 9 that the scheme can achieve relevant ranked queries by comparing the inner product between the index vector and query vector. To implement the secure search over encrypted cloud data, the basic goal is to design an encryption function E to encrypt the file index vector and query vector while still comparing the inner product. We call the encryption function E the innerproduct preserving encryption function (Fig. 10).

In Ref. [9], based on the space vector model, Wong et al. proposed a secure k-nearest neighbor query scheme over an encrypted database and Cao et al. improved this technique and made it suitable for secure queries over encrypted cloud data [10]. In this section, for simplicity, we introduce a simple version of the encryption function E which can preserve the inner product between two encrypted vectors. First, we need to define two encryption functions: E1 which is used to encrypt the n dimensions index vector I, and E2 which is used to encrypt the n dimensions query vector Q. The I and Q are represented by column vectors. Given a secret n × n invertible matrix M as the encryption key, encrypt the index vector I by computing E1(I) = MT × I and encrypt the query vector Q by computing E2(Q) = M− 1 × Q. Given an encrypted index E1(I) and an encrypted query E2(Q), the search system can get the correct inner product value between I and Q by computing [E1(I)]− 1 × E2(Q). This is because:
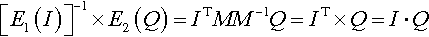
Thus, the search system can correctly perform ranked queries over the encrypted data index according to the inner product. Many security-enhanced versions based on this technique have been widely used in the multikeyword secure query system for cloud computing.
12.3 Other Big Data Security
Big Data shows promise for enterprises across industries. If there are not the suitable encryption and security solutions for Big Data, Big Data may be in big trouble. Fortunately, there are existing technologies for Big Data security, as follows.
12.3.1 Digital Watermarking
Digital watermarking is a technology in which identification information is embedded into the data carrier in ways that cannot be easily noticed, and in which the data usage will not be affected. This technology often protects copyright of multimedia data, and protects databases and text files.
Because of data’s randomness and dynamics, methods of watermarking imbedded into databases and text files and multimedia carriers are quite different. And the basic precondition is that there is redundant information in the data, and tolerable precision error. For example, Agrawal et al. embedded watermarking into the least important position of data, randomly based on the tolerance range of error in the numeric data in the database [11,12]. But Sion et al. proposed a schema based on the statistical property of a data set. Watermarking is embedded into a set of attribute data for preventing attackers from destroying watermarking [13,14]. Besides, fingerprint information of databases is embedded into watermarking in order to identify information owners and objects that are distributed [15]. It is beneficial to track leakers. And the public verification of watermarks can be achieved without secret keys through independent component analysis [16]. There are the other relevant works in Refs. [17,18]. If the fragile watermarking is embedded into the tables in databases, the change of data items will be discovered in time [19].
There are many generations of methods of text watermarking, which can be divided into three types. The first type is watermarking based on fine tuning of the document structure, relying on slight differences between the formats of word spacing and line spacing. The second kind is watermarking based on text contents, depending on the modifications of text contents, such as adding white spaces, modifying punctuation, and so on. The third kind is watermarking based on the nature of language, achieving changes by semantic understanding, such as synonym replacement or transformation of sentences, and so on.
Most watermarking described herein considers static data sets; however, the features of Big Data, such as high speed data generation and updating, are not considered sufficiently.
12.3.2 Self-Adaptive Risk Access Control
In the Big Data scene, security managers may lack sufficient expertise, and they sometimes cannot assign data which can be accessed by users correctly. To counter this, self-adaptive risk access control is proposed. The conception of risk quantification and access quotas are proposed in Jason’s report [20]. Subsequently, Cheng et al. proposed an access control solution based on a multilevel security model [21]. Ni et al. proposed another solution based on fuzzy inference, and the amount of information and the security levels of users and information are the main reference parameters for risk quantification. When risk value of the resources that users access is higher than some predetermined threshold, users will not continue accessing. However, in the Big Data application environment, the definition of risk and quantification are more difficult than before.
12.4 Privacy on Correlated Big Data
12.4.1 Correlated Data in Big Data
The data correlations in Big Data are very complex and quite different from traditional relationships between data stored in relational databases. Some research has been done on data correlations and their privacy problems.
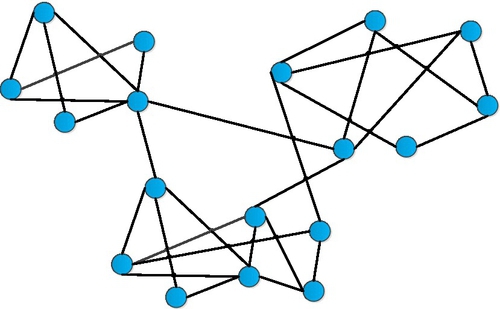
Generally, data correlations are described by social networks graphs. Fig. 11 shows that there is a simple data relationship in the social network. In Fig. 11, nodes represent people or other entities in social networks, and edges represent correlations between them. Adversaries may attack the privacy of people who have high correlations in social networks by using external information (ie, background knowledge) or the structural similarity between nodes and nodes, or graphs and graphs. For example, adversaries can analyze target individuals’ privacy according to the degree of target nodes, attributions of nodes, linking relationships between target individuals, neighborhood structures of target individuals, embedded subgraphs, the features of graphs, and so on [22,23]. Besides, adversaries can also utilize structural information of target individuals to violate their privacy [24].
In fact, adversaries can achieve data correlations easily from social networks, etc. For instance, the structure of the social network may be obtained when adversaries use a web crawler. Therefore, a person’s correlations in a social network could be ascertained by analyzing this structure. An adversary may achieve some query results, such as “the number of persons whose hobbies are smoking and drinking,” and then the adversary may try to analyze the hobby of one special person based on the high correlated persons with the same hobby [25]. Fig. 12 shows that adversaries attack sensitive information through utilizing data correlation.
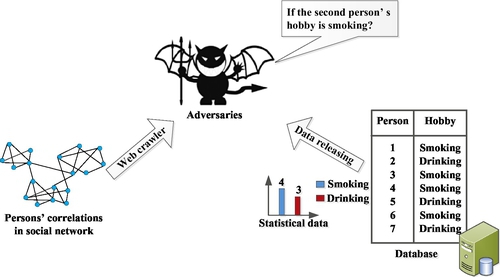
Many attributes about correlated data in social networks may be used to analyze the privacy of target individuals. Because correlated data privacy can be leaked more easily, we should pay much more attention to this problem.
However, there may be important, undetected relationships in Big Data. Reshef et al. proposed an approach called the maxim information coefficient to measure a wide range of correlations, both functional and not in large data sets [26]. But the amount of data sets in Big Data is huge, thus data correlations in Big Data are more complex. Besides, adversaries can also utilize the undiscovered data correlations to attack sensitive information. So correlated data privacy in Big Data is an important and growing challenge.
Furthermore, data correlations in Big Data do not mean that data A causes data B. On the other hand, these correlations imply that data A and B may be detected simultaneously. And, these correlations are quite different from the data correlations that existed before Big Data. However, the difference often is neglected, so sensitive information will be more exposed and vulnerable.
Research is ongoing on how to protect sensitive information in Big Data. And the research about data privacy protection focuses on anonymity and differential privacy, primarily.
12.4.2 Anonymity
Adversaries can utilize data correlation in Big Data to attack sensitive information. There are some existing technologies to prevent adversaries from stealing sensitive information in relational data. In this section, we will introduce the development of anonymity for data releasing, and data privacy protection for social networks.
(1) Anonymity for Data Releasing
For the structured data in Big Data, the key technologies and basic methods for achieving the anonymity of data releasing are still being developed and improved.
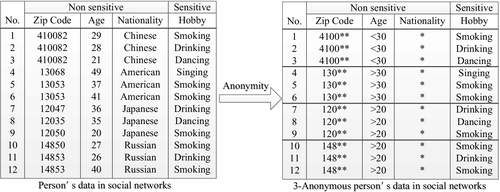
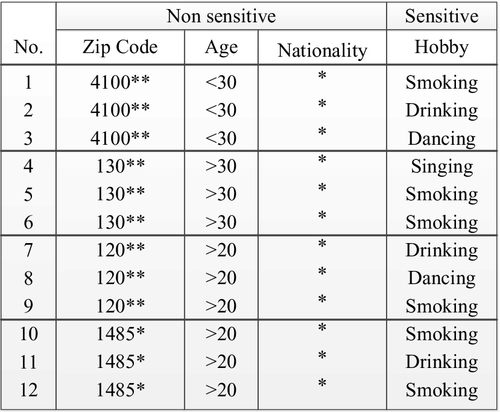
Take k-anonymity, for example. In schemas which are proposed at an early age [27,28] and optimization [29–31], data is processed by tuples generalization and restraint; thus, quasiidentifiers are divided into groups. Quasiidentifiers in every group are converted to be the same, and there are k tuples in every group. So every tuple cannot be identified by other k-1 tuples. Fig. 13 shows the example of k-anonymity.
Then l-diversity anonymity is proposed. The character of this method is that the diversity of sensitive data should be more than l. Implementations of l-diversity contain a scheme based on anatomy and a scheme based on data substitution [32]. Fig. 14 shows the example of l-diversity anonymity.
Additionally, there is another anonymity called t-closeness, which requires that the sensitive data distribution of the equivalence class is the same as data distribution of the whole data table [33]. And there are the other works about anonymity, which include (k, e)-anonymity [34], (X, Y)-anonymity [35], and so on.
The anonymity for data releasing in Big Data is more complex. Adversaries can aquire data from multiple channels, not just the same data publishing source. For example, people have discovered that adversaries can compare their data with public data on IMDB and then identify the account of the object in Netflix. This problem is being researched in more depth [36].
(2) Anonymity for Social Networks
The data produced by social networks is a Big Data source, and contains mass quantities of users’ private data. Because of the graph structure features of social networks, anonymity for social networks is quite different from structured data.
The typical requirements for anonymity in social networks are users’ identifiers anonymity and attributes anonymity (also called nodes anonymity). When data is released, users’ identifiers and attributes information are hidden. Furthermore, relationship anonymity (also called edges anonymity) is the other typical requirement for anonymity in social networks. The relationships between users are hidden when data is published.
Currently, edges anonymity schemes are mostly based on edges deleting and adding. And edges anonymity can be achieved by adding and deleting exchange-edges randomly. In Ref. [37], in the process of anonymity, characteristic values of adjacent matrixes and the second characteristic values of the according Laplace matrixes remain constant. In Ref. [38], nodes are classified according to the degree of nodes. Edges’ satisfied requirements are chosen from the nodes of the same degree. The solutions in Refs. [39,40] are similar to those in Ref. [41].
Additionally, it is important to note that the graph structure is partitioned and clustered based on super nodes. Examples include anonymity based on nodes clustering, anonymity based on genetic algorithm, anonymity based on a simulated annealing algorithm, and a schema for filling in the splitted super nodes [40]. In Ref. [42], the concept of k-security is proposed. It achieves anonymity by k isomorphism subgraphs. Anonymization based on super nodes can achieve edges anonymity, but deposed social structured graphs are quite different from the original ones.
However, a major problem of social networks anonymization is that adversaries can use the other public information to infer anonymous users, especially when there are connection relations between users. This creates problems, as follows. First, adversaries utilize weak connections to predict possible connections between users [42]. This is appropriate for networks in which there are sparse user relations. Second, attackers can regain and infer hierarchical relationships in the crowd, according to existing social networks structures [43]. Third, adversaries can analyze the complex social networks, such as Weibo, and infer relations [44]. And last but not least, adversaries can infer the probability of different connection relations based on the restricted random-walk mechanism. Researchers assert that the clustering feature of the social network significantly impacts the accuracy of subrelationship prediction.
12.4.3 Differential Privacy
Differential privacy [45,46] is a powerful tool for providing privacy-preserving noisy query answers over statistical databases. It is also the most popular perturbation for correlated data privacy protection. It guarantees that the distribution of noisy query answers changes very little with the addition or deletion of any tuple.
Definitions of differential privacy
There are two typical definitions of differential privacy, which are classified into unbounded and bounded [47]. The formal definitions of unbounded differential privacy [45] and bounded differential privacy [46] are Definition 3 and Definition 4, respectively.
Differential privacy optimization
To improve the precision of inquiry responses, a great deal of research has been done on differential privacy.
Blum et al. proposed a new approach which can respond to an arbitrary “querying class” [48]. The precision of the response relies on the VC dimension of the “querying class.” In Ref. [48], an efficient method is described for the querying of responsing domains, but precision is worse than that proposed in Refs. [49,50].
In regard to differential privacy for compound queries, Hardt et al. proposed a k-mod method based on linear query sets [51]. This method makes linear queries mapped to the L1 sphere, and then it is determined how much noise should be added. This method requires uniform sampling from high dimensional convex bodies. In Ref. [52], the cost of the algorithm is searching for the query schema, mainly. This procedure is preceded only once. Once the best schema is determined, its efficiency is the same as Laplace’s.
Roth et al. assert that queries will arrive in a chronological sequence in an interactive environment [53]. The condition in which the query will arrive is unknown, but it must be responded to immediately. Hence, the traditional Laplace mechanism is improved. The query response is acquired by computing prior query results using a median approach.
(1) Query Response Optimization Based on the Hierarchy Concept of the Matrix Mechanism
Relevant research about the best response schema for the count query in the related domain is rarely reported. Related researches are gotten down to research since 2010.
Xiao et al. applied the Haar wavelet transformation (WT) to differential privacy [49]. Data is carried out by wavelet transformation before noise is added so that the correctness of the counting query can be improved. At the same time, the applied range is expanded to the attributions of the nouns and the high-dimensional Histogram query. This approach is equivalent to the H query and is the equivalent of a query tree. The summarized data, which is more fine-grained, is on the every layer of this tree, from up to down.
Hay et al. proposed differential privacy based on layered summations and least squares [50]. The query sequence is divided into groups that are satisfied by consistency constraints. And noises are added group by group so that the precision of the query is satisfied and the amount of noise that should be added is reduced.
Li et al. proposed the concept of the matrix mechanism [52], and papers [49,50] have been written on the category of the matrix mechanism. Some relationship between the queries is analyzed, and each query is regarded as a linear combination of basic count operations. Then the queries containing relationships are expressed as the matrixes. The amount of added noise is reduced based on the existing Laplace noise distribution.
These three approaches are all based on the matrix mechanism. And special query questions are improved by them.
(2) The Precision Range of the Linear Query
The range of the precision of the query response that is satisfied by differential privacy is an important research field for researchers. And the most important area for study is the range of the precision of the linear query response.
In the noninteractive mode, Blum et al. proposed differential privacy for releasing synthetic data [48]. This algorithm obeys the error range of O(n2/3), where n is the size of the data set, and the error range will expand with the increase in data sets. Dwork et al. improved the algorithm [54,55] proposed in this paper [48]. Gupta et al. proposed a noninteractive query response based on multiplicative weights and agnostic learning [56]. Hardt et al. implemented these algorithms and evaluated them by conducting experiments in Ref. [57]. The experiments’ results show that this algorithm is not adjusted to the interactive mode, and, when the number of the query times is many times the size of the data sets, the efficiency of the algorithm is very low.
In the interactive mode, Roth et al. [53] assumed that the query was executed online, and that the query should be responded to before the upcoming query arrived. So that the error range will be: 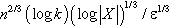 . Hardt et al. [58] adapted an approach based on additive and multiplicative weights, and the error edge of the query response is reduced to
. Hardt et al. [58] adapted an approach based on additive and multiplicative weights, and the error edge of the query response is reduced to 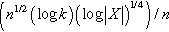 . The meaning of the parameters is: under ε-differential privacy protection, n is the size of the data sets, k is the query times, and X is the data domain.
. The meaning of the parameters is: under ε-differential privacy protection, n is the size of the data sets, k is the query times, and X is the data domain.
Gupta et al. composited the midvalue algorithm [53] and additive and multiplicative weights [58] in the interactive mode, and summarizes the multiplicative weights [56,57] in the noninteractive mode, as well as defining the iterative database construction (IDC) algorithm abstractly [59]. The IDC algorithm can respond to queries under differential privacy protection, either in the interactive mode or in the noninteractive mode. An assumed data structure is improved iteratively by the IDC algorithm so that this data structure can respond to all the queries. At the same time, the algorithm improves the precision range of the midvalue algorithm and the multiplicative weights algorithm.
Key approaches for differential privacy
(1) Differential Privacy for Histogram
As in the foundation of many data analysis approaches, such as contingency tables and marginals, the histogram query plays an important role in differential privacy protections.
Chawla et al. began to study privacy protections for histogram queries before differential privacy was proposed [60]. Dwork et al. analyzed the essential properties of the histogram query in depth, and pointed out that compared with the existing methods the biggest advantage of differential privacy is that the computation of the sensitiveness is independent of the dimension [46]. With regard to differential privacy for high-dimensional output contingency tables and the covariance matrix analysis, data privacy protection can be created on the premise that noise is added. Dwork et al. provided a complete summary of achieving differential privacy for the histogram query, and pointed out that although the histogram containing k units can be regarded as k independent counting queries, adding or deleting a line of data only effects the counting of the unit corresponding to that line of data, and at most, one count is affected [61]. Therefore, the sensitiveness of a histogram query is 1. This conclusion builds a foundation for applying the differential-private histogram protection to various problems.
(2) The Differential-Private K-Means Clustering
Blum et al. proposed that differential privacy was achieved by adding appropriate noises in the process of K-means clustering, and summarized the sensitiveness of the computing method of the query function and the main steps for achieving the ε-differential private K-means algorithm [62]. In K-means, privacy will be leaked by computing the central point, which is nearest to every sample point. However, for an unknown set, computing the average value only requires that the sum divide by the number. Therefore, as long as the approximate value of the set Sj is released, the set’s own information is not needed.
Dwork et al. replenished and improved the algorithm, and analyzed the sensitiveness of the computing method of each query function in the differential-private K-means algorithm in detail, and provided the total sensitiveness of the whole query sequence [61].
The PINQ framework
PINQ (privacy integrated queries) was developed by Dwork et al., and it is a framework for sensitive data privacy protection [63]. The PINQ framework is similar to the LINQ framework. It provides a series of APIs so that developers can develop the differential privacy protection system through using simple and expressive language. This framework includes rich application cases of the differential-private data analysis.
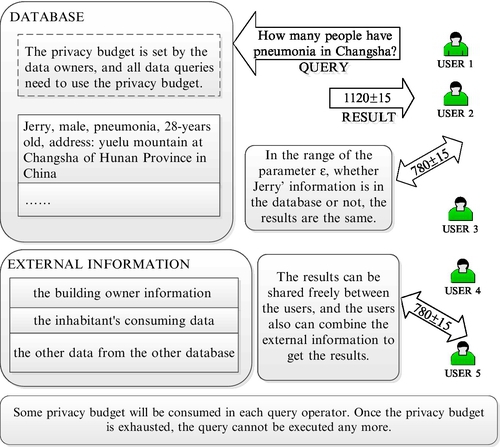
Fig. 15 shows an application example of releasing data by the PINQ framework. In the framework, a privacy budget is set by the owner of the database which needs to be protected. When users query data from the database, some budgets will be consumed. Once the budget is exhausted, users cannot query by the framework. Consider the following database record: “Jerry, male, pneumonia, 28-years old, address: Yuelu Mountain at Changsha of Hunan Province in China.” For data users, in the range of the parameter ε, whether Jerry is in the database or not will not affect the query results. The query results can be shared between users freely. Users can also integrate the external information (such as the building owner information, the inhabitant's consuming data and the other data from the other database). Privacy will not be leaked by these operations.
Differential privacy for correlated data publication
To protect correlated data, differential privacy is studied to solve this problem.
Chen et al. proposed an approach to protect correlated network data while the data is released. This approach proposes differential privacy by adding an extra correlation parameter. It is a noninteractive method of stopping adversaries from analyzing the presence of a direct link between two people. Meanwhile, research has given us the theorem of the ε-differentially private mechanism under correlations, see Theorem 1 [64].
Theorem 1
Let 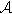 be private mechanism over a database, and k1 be a correlation parameter which is the database with, besides k2 is another correlation parameter and 1 ≤ k2 ≤ k1. So will be ε-differentially private for all databases with k2.
be private mechanism over a database, and k1 be a correlation parameter which is the database with, besides k2 is another correlation parameter and 1 ≤ k2 ≤ k1. So will be ε-differentially private for all databases with k2.
What’s more, Zhang et al. researched differential privacy for privacy-preserving data releasing via the Bayesian network and proposed a different solution called “PRIVBAYES” to deal with this problem [65]. To depict the correlations of the attribution in a dataset D, a Bayesian network is built. Then noise is added to a set of marginals of D for achieving differential privacy. An approximate data distribution is constructed by utilizing the noisy marginals and the Bayesian network. This data distribution has been published for the sake of research.
Yang et al. studied a perturbation method on correlated data called “Bayesian differential privacy” to deal with the privacy protection of correlated data. The definition of Bayesian differential privacy is as follows [25].
Definition 5
Let be an adversary and ℳ(x) be a randomized perturbation mechanism over a database D, 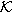 be the set of known tuples,
be the set of known tuples, 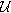 be the set of unknown tuples, i be the tuple adversaries want to attack, x be an instance of the database D, where an adversary with knowledge to attack xi, that is, = (i,) and ⊆ [n]\{i}, and ℳ(x) = Pr(r ∈ S|x). The privacy leakage of ℳ is
be the set of unknown tuples, i be the tuple adversaries want to attack, x be an instance of the database D, where an adversary with knowledge to attack xi, that is, = (i,) and ⊆ [n]\{i}, and ℳ(x) = Pr(r ∈ S|x). The privacy leakage of ℳ is 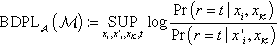 , there are two conditions as follows.
, there are two conditions as follows.
• x is continuous-valued: 
• x is discrete-valued: 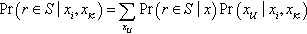
If 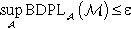 , ℳ is Bayesian differential privacy.
, ℳ is Bayesian differential privacy.
Then to depict the data correlation, the Gaussian Markov random field is adopted to build the Gaussian Correlation Model. The definition of Gaussian Correlation Model is as follows.
Definition 6
Let W = (wij) (wij ≥ 0) be the weighted adjacent matrix, G(x, W) be a weighted undirected graph, where each vertex xi represents a tuple i in the dataset and xi ∈ x, wij represents the correlation between tuples i and j. And let DI = diag(w1, w2, …, wn) be the weighted degree matrix of G(x,W) where wi = ∑j≠ iwij, and L be the Laplacian matrix of G(x,W),
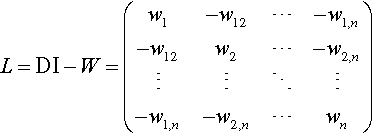
A Gaussian correlation model G(x, L) is the pair (x, L).
12.5 Future Directions
The existing research about security and privacy in Big Data is not perfect. There are some challenges to face. The following section describes the future of the research on this topic.
On the one hand, the secure query schemes which we introduce herein allow cloud users to obtain encrypted files by submitting query keywords of interest to the cloud server. However, there are still many important techniques and functionalities of secure searching worth further study for continuously improving the user query experience and perfecting query functionality, such as keyword fuzzy query, range query, subset query, and query expression relation operation, etc. In addition, recently, researchers have proposed new application requirements dictating that a secure query scheme should provide some mechanisms that allow data users to verify the correctness and completeness of query results returned by the cloud, based on the assumption that the cloud may intentionally omit some qualified query results for saving computation resources and communication overhead. Verifiable secure query schemes will be a research focus in the future.
On the other hand, with the increase of local link density in social network and the clustering coefficient, the link prediction algorithm between correlated data in social networks should be further enhanced. Thus, in the future, anonymity for correlated data in social networks can prevent these kinds of attacks by inferring. The amount of Big Data will be extremely large after years of data collection. The essence of differential privacy is adding noise to protect sensitive information so that the utility of Big Data and the efficiency of the differential privacy will all be affected. Thus additional research is required on how to perform differential privacy appropriately for Big Data.
12.6 Conclusions
With the growing popularity of cloud computing and sharp increase in data volume, more and more encrypted data is stored on cloud servers, which means the further development of secure query techniques are essential for data utilization in cloud environments. At present, secure query schemes over encrypted data can be classified into two categories: the symmetric-key based solutions and public-key based query schemes. Compared with the symmetric-key, due to the heavy computation cost and inefficiency of public-key cryptosystems, secure query schemes based on public-key setting are not suitable for cloud applications with mass users and mass data, and make those schemes based on symmetric-key preferable in all solutions.
We systemically illustrate the related concepts, models, definitions, and important implementation techniques of secure searching over encrypted cloud data based on symmetric-key setting, including system frameworks, threat models, attack models, etc. We provide the implementation principles and details of secure search techniques over encrypted data by introducing two concrete secure query schemes proposed in Refs. [4] and [10]. Additionally, we point out that if there are not suitable encryption and security solutions for Big Data, Big Data may be in big trouble. And we introduce data watermarking and self-adaptive risk access control in Big Data separately.
What’s more, correlated Big Data brings new security and privacy problems, but it is an important solution for these problems by itself. In this chapter, we systematically comb the related key research about correlated data privacy protection from different perspectives such as data releasing, social networks, correlated data publication, and so on. And we group the relevant research into two categories: anonymity and differential privacy, introduced, respectively. Additionally, we look forward to future developments in correlated data privacy in Big Data, as there is very little current research on the topic. Thus, we should pay more attention to studying technical means for preserving the privacy of correlated Big Data. The problem of privacy on correlated Big Data could be solved only through a combination of technical means and relevant policies and regulations.