A Framework for Mining Thai Public Opinions
C. Deerosejanadej; S. Prom-on; T. Achalakul
Abstract
User-generated textual opinions strongly influence humans’ beliefs and decisions. Due to the rapid growth of social data, readers cannot capture major opinions on particular topics by reading through all texts. To provide informative supporting evidence for sentiment analysis results, we integrate an opinion summarization framework into a Data and Opinion Mining (DOM) engine, which is an extension of a mobile Big Data analytics engine for mining Thai public opinions (XDOM). This opinion summarization framework is based on a modified genetic sentence clustering and sentence selection. This chapter presents the development of XDOM, which takes in data from multiple well-known social network sources, and then processes them using MapReduce, a keyword-based sentiment analysis technique, a clustering-based text summarization, and an influencer analysis algorithm. The XDOM engine is capable of identifying overall sentiments, representative text summaries, and influential authors of certain topics. The system’s sentiment prediction accuracy was evaluated by matching the predicted result with human sentiment and tested in various case studies. The effectiveness of both approaches demonstrates the practical applications of the engine.
Keywords
Opinion mining; Big Data analytics; MapReduce; Public sentiment; Opinion summarization; Sentence clustering
Acknowledgments
We would like to thank for the financial support of the Faculty of Engineering, King Mongkut’s University of Technology Thonburi through the research grant (to SP) and the Office of Higher Education Commission through the National Research University (NRU) grant, fiscal year 2011–2013 (to TA).
14.1 Introduction
Social networks connect human beings. Social networks, in terms of both data and users, have been exponentially growing and connecting our lives in various dimensions. We can connect with people across the planet with the touch of a finger. In every second, hundreds of thousands of messages are shared through social media and websites such as Facebook, Twitter, Foursquare, Pantip, etc. They contain stories about our lives, feelings, experiences and opinions.
Social media networks generate a huge volume of data. They have been used in various types of applications including public health [1], emergency coordination [2], news recommendation [3], and stock market prediction [4]. These social media data are gathered under the catch-all term, “Big Data.” However, the data stored is usually in the unstructured format, meaning that it is spontaneously generated and not easily captured and classified. Big Data is only valuable if its content can be utilized. The better the content is used, the better you will be able to take advantage of that data. Understanding the cause behind that trend is crucial to better decision making. This is necessary for the next-generation organizations that utilize intelligence in Big Data.
The major challenge of opinion mining in Thai is in the inherent nature of the language. Unlike English, Thai sentences use neither white space to mark words nor punctuation to mark the end of the sentence. With the lack of research in computational linguistics for the Thai language, these characteristics pose a great challenge in analyzing Thai textual data. In addition, most social media text is written in the form of spoken Thai, which is not included in the existing Thai lexicon. For example, there are some informal words which are used by some people or groups (eg, slang words and local words). Therefore, these characteristics raise difficulty in segmenting Thai sentences based on a dictionary. Another problem is the lack of a system that can automatically extract entities from the text. Without such a system, it is impossible to identify relevant objects within the textual data. Though lots of text mining tools are available in the market, most of them are not applicable to the Thai language due to these two difficulties. Simply speaking, these tools do not understand Thai textual data, especially in the spoken form.
Data and Opinion Mining (DOM) [5] was developed to analyze Thai public opinions on topics of interest. DOM aggregated sentiments and impact positions of authorities in order to facilitate decision making. Though all related sentences of each topic were displayed along with sentiment results, readers usually struggled with reading all relevant opinions in order to seek underlying reasons for supporting their beliefs. Furthermore, the screens of mobile devices usually provides limited space to display content. Thus, a summarization system was utilized to compress opinion text in an informative way; that is, a text summary representing majority opinions and also containing less redundant information. To generate the economical and representative summary, Ly et al. [6] selected representative sentences from the generated clusters. They applied two clustering techniques to group sentences, including agglomerative hierarchical clustering and hill-climbing clustering. The hierarchical method began with single-sentence clusters and continuously merged two clusters with the minimum distance in their combination. For the hill-climbing method, the clusters were randomly generated for the first iteration. In subsequent iterations, the algorithm greedily swapped cluster members which minimize an average similarity within clusters (ie, intracluster dissimilarity). Since these two methods suffer from local-optima and computation problems, they could not produce effective opinion clustering of large data in an acceptable timeframe.
Hence, we combine the clustering-based opinion summarization with the original version of DOM in order to provide a representative and economical summary, resulting in stronger evidence. In this work, we present the developments of XDOM (eXtension of DOM), a Big Data analytics engine that is capable of mining Thai public opinions regarding specific issues discussed on social network sites, and its corresponding mobile solution for answering public opinions about events and locations. For the data analytics engine, the opinion summary generation is proposed in this extended version. Software features and design will be discussed in Section 14.2. Section 14.3 explains how the software was implemented using cloud-based technology. Section 14.4 shows the evaluation of the XDOM effectiveness in predicting the sentiment score and in discovering sentence clusters of public opinions. Usages of XDOM for different tasks are presented in Section 14.5. Comparisons of XDOM with respect to others, and future steps in development are discussed in Section 14.6.
14.2 XDOM
14.2.1 Data Sources
We collected data from four different data sources: Twitter, Facebook, Foursquare and Pantip, as described in Table 1.
Table 1
Sources of Social Network Data
| Source | Data description |
| Twitter messages, also known as tweets, are short 140-character text messages. Tweets are all public | |
| Facebook data can only be retrieved if the privacy is set to public. They are in forms of status posts and Facebook Page posts | |
| Foursquare | Foursquare provides both text comments and review score of a number of places |
| Pantip | Pantip data are in forms of webboard threads. It is one of the prominent Thailand online social communities |
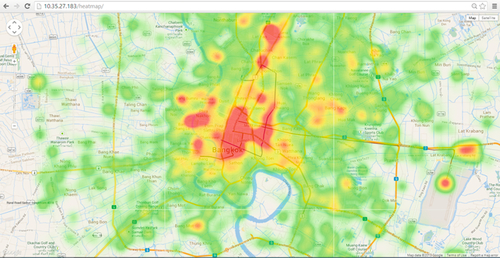
These social network data were collected in the Bangkok area. Different data sources require the use of different connectors. For Twitter data, we used Search API [7] provided from Twitter Inc. to collect tweets without any keywords. We collected approximately 15 million tweets, or, about 12GB of uncompressed data. Each tweet contains multiple data fields, including time, username, user followers, retweet, count, location, and the textual comment. The data collected from twitter can be represented as an activity heat map (Fig. 1). For Facebook, we used Graph API [8] developed by Facebook Inc. Unlike Twitter, we can only request and collect data from the Facebook fan page, which consists of posts and comments on specific topics. We collected Facebook data from about 5,000 messages, which is approximately 4 MB per fan page. Graph API provides attributes including time, username, number of Likes, location, and textual comments for each message. For Foursquare, the situation is like Graph API. Foursquare provides some useful APIs, named Venues and Tip search API [9], for developers to gather data. Foursquare provides comments of places. In each month we collected approximately 500 messages, or 0.4 MB per place. Foursquare data includes time, username, like count, location and the textual comment. Our last data source is Pantip.com, one of the prominent Thailand online social communities. We developed a web crawler to gather the data on this website, since they do not provide an API to gather data. The web crawler was designed to have features like Search API. First we simulated the browser by setting the user-agent to be Mozilla, and then assigned the keywords to the search form of web and submitted the request. We found that approximately 300 messages, or about 0.2 MB, were collected for each topic. Each Pantip thread contains time, username, like count and the text comment.
14.2.2 DOM System Architecture
The original version of DOM is composed of two basic modules: server-side and client-side modules. The architecture design of the DOM framework is shown in Fig. 2. The components of the DOM engine are classified into the server-side, which is a cloud-based cluster. The DOM engine is responsible for collecting, analyzing data and distributing the analyzed data to the client-side. AskDOM components are client-side. The client-side requests the analyzed data, queries, and displays them to end users.
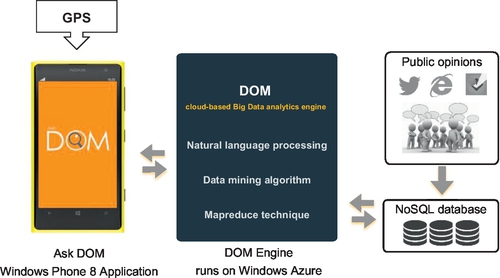
Workflow of our framework is as follows. Public messages are collected from social networks, blogs and forums using DOM’s crawler module. All collected messages are stored in MongoDB, a NoSQL database. After that, each message is processed using the basic Natural Language Processing (NLP) technique to parse the text data, categorize its topic, compute its sentimental score, select its representative text in order to form a summary and analyze its influences. DOM also uses the MapReduce technique based on the Apache Hadoop framework to reduce processing time. DOM periodically processed the data to compute their sentimental score as well as to summarize their opinion text. Finally AskDOM, the mobile application, gets the analyzed data, queries, and displays the information to users according to the inquired-upon topics.
In this work, we focus on the usage of XDOM as a Thai public opinion mining framework to track social issues and provide sentiment ratings and information on points of interest (POI) based on public opinions. However, the core functions of the DOM engine were designed to support dynamic data. There are several features that could be added or further developed to provide additional functionality (eg, adding more data sources, supporting other languages). Since DOM is a cloud-based engine, scalability is also available.
Furthermore, DOM can be easily applied in various types of usage, on either the community side or the commercial side. There are case studies in Section 14.5 that show some potential usages of DOM. The current version of DOM consists of five modules, which are MapReduce framework, sentiment analysis, clustering-based summarization framework, influencer analysis, and AskDOM mobile application.
14.2.3 MapReduce Framework
Since huge data are involved in this project, MapReduce [10] is used. If the data is processed sequentially, the processing time would be too large for the practical application. The MapReduce technique on the Apache Hadoop framework is therefore the best way to accelerate the analysis speed.
In our research, we apply MapReduce to distribute the computational workload of sentiment analysis and summarization tasks across a flexible number of worker machines. The MapReduce technique separates the mining process of both analysis tasks into two main steps: Map and Reduce, as follows:
For the sentiment analysis, the map function takes the entire text input, breaks it into subsets to be evaluated for their sentiment scores, and distributes them to worker nodes. The reduce function combines the resulting sentiment scores from each small worker node by grouping keywords of specific topics of interest and aggregating the sentiment scores into final results.
For the opinion summarization, for each keyword group, the map function divides sentences into two subgroups according to their polarity sentiments; that is, each keyword group contains three sentence subgroups, including positive, negative and neutral. Then, all subgroups are sent to worker nodes to cluster sentences and select representatives from the generated clusters. The reduce function merges the selected representatives by their keyword groups in order to form a final summary.
14.2.4 Sentiment Analysis
In this work we targeted words in which opinions are expressed in each sentence. A simple observation was that these sentences always contain sentiment words (eg, great, good, bad, worst). To simplify the process, if the sentences do not contain any sentiment words, their sentiment values will be neutral (non-opinions). So we designed our framework to classify the sentiment of each sentence based on its sentiment words and the combination of them.
Furthermore, we designed the system to be able to process Thai conditional sentences, which are sentences that describe implications or hypothetical situations and their consequences, for example, the sentence “I like the location of this company but I do not like their staff.” The sentiment of “location” is positive but for “staff” it’s negative. We found that most conditional sentences contain modifiers and conjunctions (eg, but, and, or).
To classify each message as positive, neutral or negative, we employed a lexicon-based algorithm to measure the sentiment score of each message. We defined five corpora, including positive words, negative words, modifiers, conjunctions, as well as the names of points of interest. Each word in the two sentiment corpora, positive words and negative words, contains sentiment ratings ranging from − 5 to 5. The examples of our corpuses are shown in Table 2.
Table 2
The Examples of Sentences in the Corpora
| # | Type of Corpus | Word | Value |
| 1 | Positive words | เท่ห์ (smart) | 3 |
| ดี (good) | 3 | ||
| เยี่ยม (best) | 4 | ||
| 2 | Negative Words | เสอมโทรม (decadent) | -3 |
| แย่ (bad) | -3 | ||
| ห่วยแตก (worst) | -4 | ||
| 3 | Modifiers | ไม่ (not) | -1 |
| ค่อนข้าง (likely) | 0.5 | ||
| ที่สุด (best) | 1.5 | ||
| 4 | Conjunctions | แต่ (but) | 2 |
| และ (and) | 1 | ||
| รวมไปถึง (including) | 1 | ||
| 5 | Names of places | สวนลุมพินี (Lumphini Park) | – |
| สยาม (Siam) | – | ||
| จตุจักร (Chatuchak market) | – |

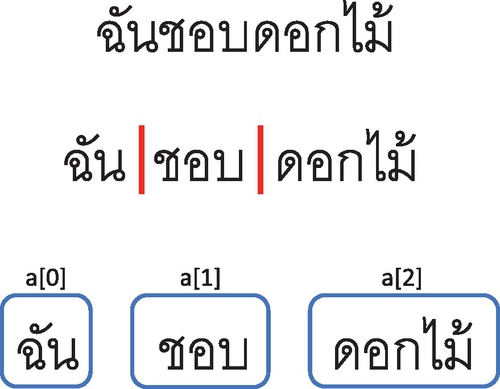
DOM detects and matches words and their sentiment polarity by using these corpora. Since the nature of Thai sentence structure is continuous without any white space breaks between words, we need to tokenize each sentence into a group of words. In this process, we used “LexTo” [11], the open source Thai word tokenizer, to tokenize words in each sentence and then store them as an array using the longest word matching algorithm [12]. An example of this procedure is shown in Fig. 3.
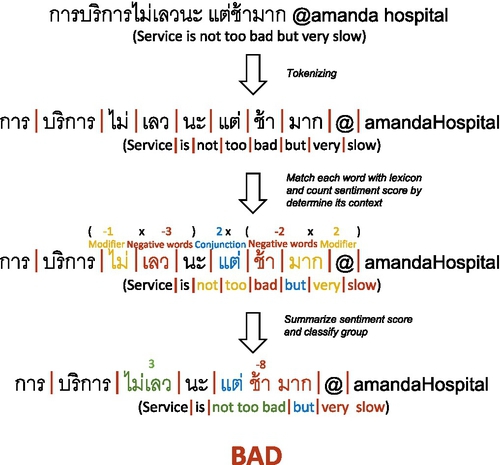
DOM generates small jobs to detect words of each sentence in parallel. First of all, DOM filters the nonrelated sentences out by matching words with the names of POI corpus. After that, only sentences that relate to specific topics of interest (in this case, points of interest) would remain. DOM then iteratively matches sentiment keywords with remaining corpuses. If there are sentiment words in an array, DOM collect its sentiment score and summarizes it at the end of each sentence. DOM then automatically classifies each sentence into a sentiment group: positive, neutral or negative, depending on its score band (the range of distributed sentiment score). DOM not only determines keywords from sentences, but also determines the context of each sentence. The positions of words, modifiers, conjunctions, and emoticons are also determined in our framework. In some cases these words can be important clues to emphasizing the mood of the sentences. Especially for the modifier keywords, they can invert the sentiment score if their positions are adjacent to the sentiment words as illustrated in Fig. 4.
14.2.5 Clustering-based Summarization Framework
Due to the high impact of textual opinions on decision making, a review summarization system is inevitable, as the system provides a shorter version of informative text apart from overall numerical sentiments. As a result, readers can quickly understand major authors’ opinions without losing any key points.
The opinion summarization framework is able to produce a representative and non-duplicate textual summary. Fig. 5 presents a framework architecture which is composed of three processes—a sentence similarity calculation, a modified genetic algorithm (GA) sentence clustering, and a sentence selection.
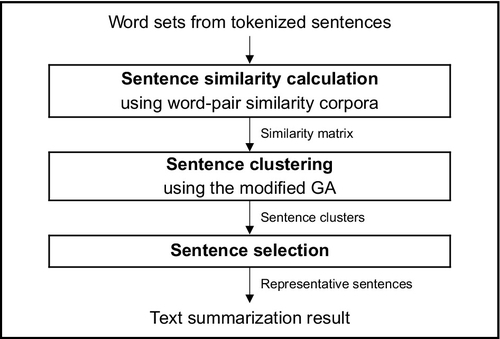
After completing the sentence analysis task, each sentence is represented with its tokenized words. First, the framework takes these preprocessed sentences to generate a semantic similarity matrix through a sentence similarity calculation process. This matrix reflects semantic similarity relations between sentences. Unlike existing works, we create a semantic similarity corpora in order to identify similarity levels between Thai word pairs. Subsequently, the modified GA assigns sentences into clusters based upon the similarity matrix. In a sentence selection process, a final summary is created by selecting a representative sentence of each generated cluster. The following subsections present the details of each component.
(1) Sentence Similarity Calculation
Since the sentence clustering process aims to assign semantically similar sentences into the same clusters, and vice versa, the similarity values between every sentence pair must be calculated before performing the next process. In this work, we adopt a sentence similarity measure of Li et al. [13] to compute a similarity score between two sentences. Unlike the original method, we create a similarity corpora for Thai language to determine word-pair similarity scores, which range from 0 to 1. The lower values between two comparing words indicate the lower similarity relations. The example of the corpora is shown in Table 3.
According to the preprocessed data of the sentiment analysis in Section 14.2.4, each sentence Si is represented with its tokenized words, Wi = {w1,w2,…,wn} where n is number of words in sentence Si. The similarity score, sim(S1,S2), is derived from a cosine similarity between two semantic vectors (V1 and V2) which represent similarity relations of a sentence pair (S1 and S2), denoted as
Table 3
The Examples of the Word-Pair Similarity Corpora
| # | Word 1 (r) | Word 2 (s) | Sim_Word(r,s) |
| 1 | ดี (good) | เยี่ยม (best) | 0.8 |
| 2 | เก่ง (smart) | ฉลาด (clever) | 1.0 |
| 3 | ดี (good) | หนาว (cold) | 0.0 |
| 4 | ใหญ่ (big) | กว้าง (wide) | 0.4 |


To create the semantic vectors (V1 and V2), a union word set U is constructed by merging two word sets, U = W1 ∪ W2 = {u1,u2,…,uq} where q = |U|, of two comparing sentences (S1 and S2). After that, each element of two semantic vectors, V1 = {v11,v12,…,v1q} and V2 = {v21,v22,…,v2q}, is created from the similarity scores, Sim_Word(r,s), between a word pair (r and s) in the similarity corpora, denoted as
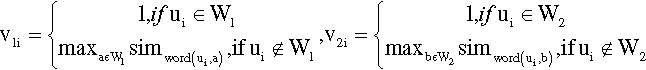
where i ∈{1,2,…,q} and ui ∈ U. At the end of this process, the similarity values of all sentence pairs are assembled into the semantic similarity matrix, M = {m00, m01,…, mhh} where h is the number of opinion sentences. For example, a value of element m02 in a similarity matrix indicates the similarity score between two sentences, S0 and S2.
(2) Sentence Clustering
The objective of our summarization framework is to select underlying text from each cluster. In order to achieve the expectation, the sentence clustering process assists in dividing semantically similar sentences into the same clusters based on the similarity matrix generated in the previous process. In this work, we formulate the sentence clustering problem as an optimization problem which attempts to minimize dissimilarity between sentences in the same clusters. To solve the optimization problem, we apply the genetic algorithm to find near globally optimal results. As the sentence clustering problems contain few good results, the GA suffers from slow convergence. To boost up the algorithm, we utilize the concept of membership degree in data clustering to form an additional solution reassignment operation of our modified GA. In general, a sentence has different degrees of being a member in any cluster. The degree is defined as the similarity level of any sentence to all members in a particular cluster. The higher degrees of sentences in any cluster reflect a higher likelihood that they will be in that cluster. Thus, a sentence should be assigned to the cluster that has the highest degree of belonging. With this clustering characteristic, we reassign all feasible solutions of the modified GA in every generation. By doing this, the algorithm considers only the solutions which satisfy with this clustering characteristic, resulting in faster convergence.
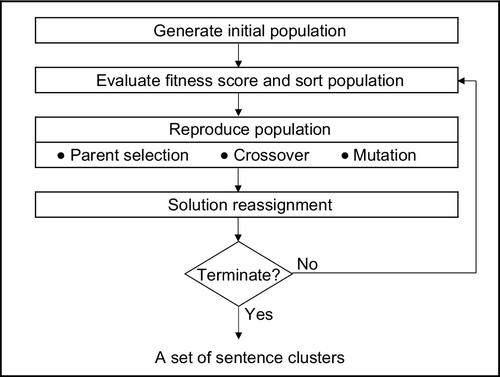
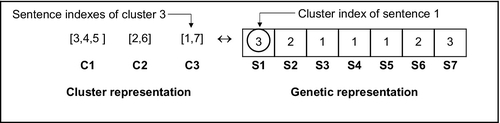
The overall flowchart of the modified GA is shown in Fig. 6. First, the algorithm randomly generates feasible solutions (ie, individuals) and encodes them into the genetic representation. To represent a sentence clustering solution, we use a string of n-digit integers where n is the number of sentences. Each digit presents the cluster index of the corresponding sentence, as illustrated in Fig. 7.
All generated individuals are then formed to a population. After that, a fitness score of each individual is calculated by using the intracluster dissimilarity function in [6]. Then, all individuals are sorted by their fitness scores. The population of the next generation is derived from the best individuals (ie, elitisms) and the reproduced individuals (ie, offspring). To generate each offspring, two individuals from the current population are selected as parents in order to perform a crossover operation. In the crossover operation, the parents exchange their genes based on random probability in order to create new individuals (ie, offspring). Subsequently, the mutation operation is applied only on offspring in which the random values of mutation exceed the predefined values. The mutated offspring are randomly changed in the cluster index at a random point.
After the population of the next generation is generated, each individual F represents a clustering solution, C = {c1, c2,…, ce} where e = |C|, of sentences S = {S1, S2,…, Sn} where n = |S|. To refine the current solution, the individual is then fetched into the solution reassignment process. In this process, the value of each digit of an individual is altered according to a reassignment function φ(Si) which determines new cluster index for sentence Si. This function will reassign a sentence Sx to the cluster Cy that has the highest membership degree, dxy∈[0,1] where x and y are the sentence index and cluster index respectively, denoted as
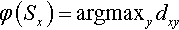
According to the similarity matrix, each element mij indicates a similarity score sim(Si,Sj) between two sentences (Si and Sj). The membership degree dxy is derived from weighted sums of total similarity scores between sentence Sx and all sentence members in cluster Cy, denoted as
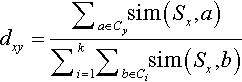
Where 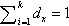 and x ϵ {1, 2, …, n}. Later, all reassigned individuals are formed to the population of the next generation. The algorithm iteratively performs until a termination criteria is met. After termination, the final clustering solution is described by the best-scored individual.
and x ϵ {1, 2, …, n}. Later, all reassigned individuals are formed to the population of the next generation. The algorithm iteratively performs until a termination criteria is met. After termination, the final clustering solution is described by the best-scored individual.
(3) Sentence Selection
Owing to the large number of opinion texts, it becomes difficult for readers to read all relevant text and draw conclusions. Taking the generated clusters from the sentence clustering process, the sentence selection assists in selecting an underlying sentence from each cluster based on a representative score in [6]. The higher scores reflect the sentences that are more similar to other sentences in the same cluster. In this work, the representative sentence of a cluster is defined as the most similar sentence. Thus, for each cluster, we select a sentence which has the highest score as the representative sentence. After all representatives are selected, a list of representatives with their cluster sizes is presented in the final summary. The size of each cluster can indicate its impact on the opinion data; that is, the larger clusters reflect more impact opinions.
The textual summary of this framework provides underlying reasons to support the sentiment analysis. This additional information helps readers make better and stronger decisions, resulting in business success. In other words, the opinion summarization framework is added to increase the reliability of making decisions in a DOM engine.
14.2.6 Influencer Analysis
The rise of social media platforms such as Twitter, with their focus on user-generated content and social networks, has brought about the study of authority and influence over social networks to the forefront of current research. For companies and other public entities, identifying and engaging with influential authors in social media is critical, since any opinions they express can rapidly spread far and wide. For users, when presented with a vast amount of content relevant to a topic of interest, sorting content by the source’s authority or influence can also assist in information retrieval. In the social network community, a variety of measures were designed for the measurement of importance or prominence of nodes in a network [14,15]. In the following, we will briefly summarize the centrality measure that we have used to describe possible candidate indicators for the power of influential in message diffusion. For the DOM engine, we have used “Degree centrality” to identify influential users in Twitter’s networks.
Degree centrality is the simplest centrality measure, as illustrated in Fig. 8. The degree of a node i denoted by ki, is the number of edges that are incident with it, or the number of nodes adjacent to it. For networks where the edges between nodes are directional, we have to distinguish between in-degree and out-degree. The out-degree centrality is defined as
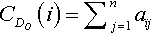
where aij is 1 in the binary adjacency matrix A if an edge from node i to j exists, otherwise it is 0. Similarly, the in-degree centrality is defined as
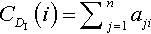
where i describes the node i and aji is 1 if an edge from node j to i exists, otherwise it is 0.
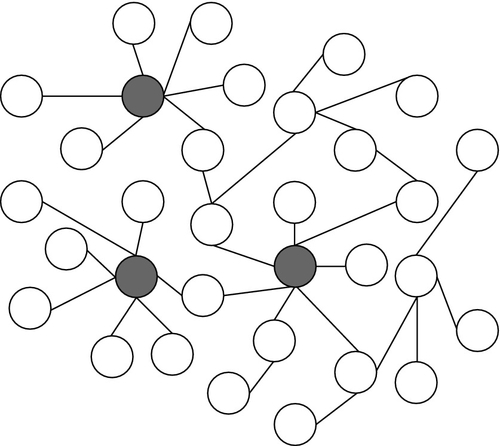
14.2.7 AskDOM: Mobile Application
To utilize DOM to its fullest extent, we developed AskDOM (Fig. 9), a mobile solution designed to use DOM to provide a means for the general public to help improve their own communities by providing reviews, feedback, and ratings of service providers automatically analyzed from public opinions on social networks (Twitter, Facebook, Pantip and Foursquare). AskDOM comprises two important modules: (a) a front-end interface with features designed to connect users to service providers such as I-Share (direct feedback), Map (traffic and incident map), Anomaly (abnormal situations reports), and (b) the DOM Engine, the back-end system that periodically gathers and processes social network data, performs public sentiment analysis, discovers underlying textual opinions, determines relationship influencers, and conducts natural language processing for both Thai and English. The integration of both modules will increase the transparency of the service businesses, making the agencies more accountable for their service quality, and provide a means for general citizens to become involved with the improvement of public services in terms of both information availability and general improvement. Such involvement will improve not only the quality of service, but also create a sense of community for general citizens that are part of the social function.
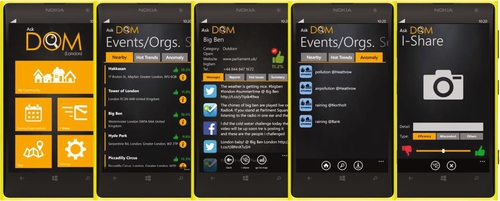
14.3 Implementation
Fig. 10 shows the overall implementation architecture of the DOM engine. The structure has three main components which are Server, Core Service and I/O.
14.3.1 Server
The server section consists of three components: the Ubuntu server, MongoDB, and Apache Hadoop. We implemented the DOM engine based on Apache Hadoop MapReduce, which runs on the Ubuntu server. MongoDB, the famous NoSQL database, was also used in this framework. This type of database often includes highly optimized key value stores intended for simple retrieval and appending operations to improve the performance in terms of latency and throughput.
14.3.2 Core Service
Core Service, the main part of our framework, consists of three components.
(1) Data Crawler: This module automatcially provides a raw data feed from social networks and stores it in the database, MongoDB. Each crawler code is specific for each social network or website.
(2) Data Preprocessing: This component prepares raw data for analysis by tokenizing Thai and English words from sentences, removing outliers and reformatting data. Then the cleaned data will be sent to Data Analysis.
(3) Data Analysis: There are three data analyzers in this component:
(3.1) Sentiment Analysis evaluates sentiments in Twitter text and finds peoples’ moods on a particular topic. For example, how people think about traffic in Bangkok.
(3.2) Clustering-based Summarization organizes Twitter text into clusters and selects representative sentences from each one to form a text summary. The generated summary is presented as supporting evidence for the sentiment analysis results.
(3.3) Influencer Analysis determines people’s positions in network, which indicates how influential they are. The influential people are more likely to acquire connections and have more connections.
14.3.3 I/O
I/O, the web-service implemented using PHP, receives the result from Core Service and then sends them to the client-side to display in a JSON format. Since the amount of data in social networks is increasing every second, using the static resources (eg, static server) may not be practical. So we designed DOM to run on the cloud. The cloud provides the ability to add blob storage depending on the size of data. Furthermore, DOM has the ability to scale the number of processers. In other words, DOM can increase or decrease the number of mappers and reducers for running a job.
14.4 Validation
To validate the effectiveness of XDOM, we conducted a subjective experiment to assess the sentiment prediction accuracy. In the following, we will describe the validation procedure and discuss validation results.
14.4.1 Validation Parameter
• 184,184 messages from Facebook, Twitter and Foursquare (both positive and negative messages) were divided into short and long messages, including 172,717 short messages (≤ 150 characters) and 11,467 long messages (> 150 characters).
• 12 subjects (6 males and 6 females) participated in the experiment. They were students at the Computer Engineering Department, King Mongkut’s University of Technology Thonburi, Thailand.
14.4.2 Validation method
1. For the human end, 184,184 messages were divided into 12 parts, each of which was assigned to each subject. They classified the messages into positive and negative classes.
2. For the DOM engine, 184,184 messages were classified by the engine into positive and negative classes.
3. The results of both human and DOM were compared and analyzed together to assess the system’s prediction accuracy.
14.4.3 Validation results
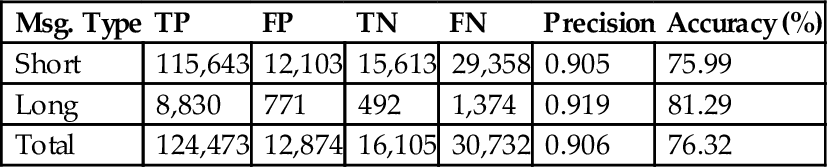
Tables 4 and 5 show the comparison results of 12 students and the DOM engine. We found that the DOM engine can classify messages and conduct sentiment analysis with an accuracy of over 75%. The accuracy of the DOM engine is in the standard of text classification [16], so the DOM engine is practical for use in social network analysis and can be applied to many dimensions in the real word.

14.5 Case Studies
In addition to the evaluation of the system effectiveness, we tested the XDOM engine further on various case studies that were of interest to the Thai public during the time periods. Each case study aims to explore either a specific social or political issue that people were discussing widely on the Internet, thus it offers a summary of Internet public opinions on that issue.
14.5.1 Political Opinion: #prayforthailand
Around the end of 2013, citizens of Bangkok were faced with multiple rounds of political protests, and violent acts toward both protesters and officers. Hashtag “#prayforthailand” is one that was frequently used in social media to express the concerns over the situation. Different opinions were expressed regarding this political issue. We used DOM to mine the general public opinions that were expressed in the social network to determine the political climate at that time. We collected tweets around the Bangkok area that contain the hashtag “#PrayForThailand.” There were over 100 K tweets collected from 29 November to 7 December 2013. We implemented the Naïve Bayes and Support Vector Machine (SVM) to the DOM engine to classify political opinions into six predefined categories as shown in Table 6. DOM can accurately put tweets into categories with more than 85% accuracy.
14.5.2 Bangkok Traffic Congestion Ranking
Bangkok’s traffic is one of the most serious problems that urban citizens have been facing in their daily lives. Knowing such information on which streets the traffic jams often occur would allow citizens to prepare to encounter the problem and allows the government to find a way to solve it.
We used the XDOM engine to track traffic jams keywords, name of streets, and intersections as well as famous places in Bangkok, Thailand that were contained in public tweets, and then rank the streets that were mostly mentioned in tweets about the traffic jam based on 22 K tweets collected from 17 February to 8 March 2014.
The results as shown in Table 7 are consistent with what Thailand’s Department of Highways hotline gathered from phone calls. However, using the XDOM engine is much faster and cheaper.
14.6 Summary and Conclusions
We discussed the development, evaluation, and case studies of XDOM, an extension of a Big Data analytics framework for assessing public sentiments and extracting salient opinions of specific social issues. The opinion summarization framework, which is based on a modified genetic algorithm clustering and sentence selection, is combined with the DOM engine. The XDOM is encapsulated as a mobile application known as AskDOM that allows users to interact and find information of places suggested by the sentiment ratings along with their supporting reasons. We have demonstrated both accuracy and generalizability of the engine in the analysis of various topics that are relevant to public interests.
Further improvements are still needed to make the XDOM engine more adaptive and robust. First, the sentiment score associated with each keyword is currently context independent and comes mainly from the manual adjustment by the administrator. A context-dependent keyword-score association study is needed for each of the tasks required. After obtaining these related associations from different contexts, rules can be derived so that the system can work effectively on different tasks. Second, public opinions usually contain a lot of personal messages that are irrelevant to the places under discussion. A filter that is capable of detecting the context of the message is required. Third, the sentence clustering in the summarization framework currently produces a compressed text only for current input sentences. It means that the analyzed data is also required to reprocess when new opinion data is fetched into the framework. Taking the clustering results, they can be treated as training data in supervised learning models. By doing this, the trained models are further used for classifying new incoming text without reprocessing all existing data.